利用深度学习来预测股票价格变动
博客原文:http://www.360doc.com/content/19/0112/18/410279_808412489.shtml
完整架构概述
在这篇文章中,我将创建一个预测股票价格变动的完整过程。我们将使用生成对抗网络(GAN)与LSTM(一种循环神经网络)作为生成器,使用卷积神经网络CNN作为鉴别器。我们使用LSTM的原因很明显,我们正在尝试预测时间序列数据。为什么我们使用GAN,特别是卷积神经网络(CNN)作为鉴别器呢?这是一个很好的问题:稍后会有特别的部分。
当然,我们将详细介绍每个步骤,但最困难的部分是GAN:成功训练GAN的非常棘手的部分是获得正确的超参数集。出于这个原因,我们将使用贝叶斯优化(还有高斯过程)和深度强化学习(DRL)来决定何时以及如何改变GAN的超参数。在创建强化学习时,我将使用该领域的最新进展,例如Rainbow和PPO。
我们将使用许多不同类型的输入数据。除了股票的历史交易数据和技术指标,我们将使用NLP的最新进展(使用“BERT,对NLP进行迁移学习)来创建情感分析(作为基本面分析的来源) ),用于提取整体趋势方向的傅里叶变换,用于识别其他高级特征的栈式自动编码器,用于查找相关资产的特征投资组合,差分整合移动平均自回归模型(ARIMA))对于股票函数近似,以便捕获尽可能多的关于股票的信息,模式,依赖关系等。我们都知道,数据越多越好。预测股价走势是一项极其复杂的任务,所以我们对股票(从不同的角度)了解得越多,我们的系统就会越好。
为了创建所有神经网络,我们将使用MXNet和它的高级API - Gluon,并在多个GPU上训练它们。
注:尽管我试图深入探讨数学和几乎所有算法和技术背后的机制,但本文并没有明确地解释机器/深度学习或股票市场是如何运作的。其目的是展示我们如何使用不同的技术和算法来准确预测股票价格的变动,并给出每一步使用每种技术的原因和有用性背后的理论基础。
1.简介
准确预测股票市场是一项复杂的任务,因为有数百万种情况会影响它。因此,我们需要能够尽可能多地捕获这些前置条件。我们还需要做出几个重要的假设:1)市场不是100%随机,2)历史重复,3)市场遵循人们的理性行为,4)市场是“ 完美的 ”。
我们将尝试预测高盛(NYSE: GS)的价格走势。为此,我们将使用2010年1月1日至2018年12月31日的每日收盘价(七年数据用于训练,两年数据用于验证)。我们将交替使用“高盛”和“GS”这两个术语。
2.数据
我们需要尽可能多地合并信息(从不同方面和角度描绘股票)。我们将使用每日数据,1585天来训练各种算法(我们有70%的数据)并预测接下来的680天(测试数据),然后我们将把预测结果与测试数据进行比较。每种类型的数据(我们将其称为特征)将在后面的章节中进行更详细的解释,但是,作为一个高层次的概述,我们将使用的特征是:
- 相关资产 - 这些是其他资产(任何类型,不一定是股票,如商品,外汇,指数,甚至固定收益证券)。像高盛这样的大公司显然不会“生活”在一个孤立的世界中 - 它依赖于许多外部因素,并与之相互作用,包括竞争对手,客户,全球经济,地缘政治形势,财政和货币政策,获得资金等。详情将在后面列出。
- 技术指标 - 很多投资者都遵循技术指标。我们将最受欢迎的指标作为独立特征。如 - 7和21天移动平均线,指数移动平均线,momentum,布林线,MACD。
- 一个非常重要的特征,表明股票可能上涨或下跌。基本面分析有两个特征:1)使用10-K和10-Q报告分析公司业绩,分析ROE和P/E等(我们不会使用这个);我们将为高盛(Goldman Sachs)和阅读每日新闻提取总情绪是否对高盛(Goldman Sachs)在那一天是正面的,还是负面的(如得分从0到1)。由于许多投资者会仔细阅读新闻,并根据新闻(当然是部分依据新闻)做出投资决策,因此,如果高盛(Goldman Sachs)今天的消息非常正面,那么该股明天将大幅上涨的可能性在一定程度上是很高的。关键的一点是,我们将在以后对每个特征(包括这个特征)执行特征重要性(意思是它对GS波动的指示性),并决定是否使用它。我们将使用BERT - 谷歌最近公布的NLP方法,用于情感分类股票新闻情绪提取的迁移学习。
- 傅里叶变换 - 除了每日收盘价,我们还将创建傅里叶变换,以概括多个长期和短期趋势。使用这些变换,我们将消除大量噪声(随机游走)并创建真实股票移动的近似值。趋势近似可以帮助LSTM网络更准确地选择其预测趋势。
- 自回归整合移动平均线(ARIMA) - 这是预测时间序列数据未来值的最流行的技术之一(在pre-neural网络时代)。让我们添加它,看看它是否是一个重要的预测特征。
- 栈式自动编码器 - 上述大部分特征(基础分析、技术分析等)都是人们经过几十年的研究发现的。也许有一些隐藏的相关性,人们无法理解,因为有大量的数据点、事件、资产、图表等。通过栈式自动编码器(神经网络的类型),我们可以利用计算机的力量,可能会发现影响股票走势的新类型的特征。即使我们无法理解人类语言中的这些特征,我们也将在GAN中使用它们。
- 期权定价中异常检测的深度无监督学习。我们将再使用一项功能 - 每天我们都会为高盛股票增加90天看涨期权的价格。期权定价本身结合了大量数据。期权合约的价格取决于股票的未来值(分析师也试图预测价格,以便为看涨期权提供最准确的价格)。使用深度无监督机器学习(Self-organized Maps),我们将尝试发现每天定价中的异常情况。异常(例如价格的剧烈变化)可能表明一个事件可能对LSTM了解整个股票模式有用。
接下来,有这么多特征,我们需要执行几个重要步骤:
- 对数据的“质量”进行统计检查。如果我们创建的数据有缺陷,那么无论我们的算法多么复杂,结果都不会是正确的。检查包括确保数据不受异方差、多重共线性或序列相关性的影响。
- 创建特征的重要性。如果一个特征(如另一只股票或一个技术指标)对我们想预测的股票没有解释力,那么我们就没有必要在神经网络的训练中使用它。我们将使用XGBoost(eXtreme Gradient boost),一种boosted 树回归算法。
作为数据准备的最后一步,我们还将使用主成分分析(PCA)创建Eigen投资组合,以减少自动编码器创建的特征的维数。
from utils import *
import time
import numpy as np
from mxnet import nd, autograd, gluon
from mxnet.gluon import nn, rnn
import mxnet as mx
import datetime
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.decomposition import PCA
import math
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler
import xgboost as xgb
from sklearn.metrics import accuracy_score
import warnings
warnings.filterwarnings("ignore")
context = mx.cpu(); model_ctx=mx.cpu()
mx.random.seed(1719)
def parser(x):
return datetime.datetime.strptime(x,'%Y-%m-%d')
dataset_ex_df = pd.read_csv('data/panel_data_close.csv', header=0, parse_dates=[0], date_parser=parser)
dataset_ex_df[['Date', 'GS']].head(3)

print('There are {} number of days in the dataset.'.format(dataset_ex_df.shape[0]))
output >>> There are 2265 number of days in the dataset.
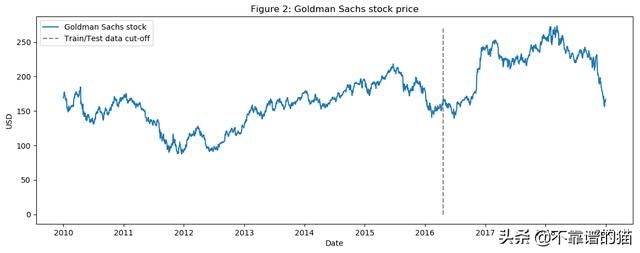
让我们想象一下过去九年的股票。垂直虚线表示训练和测试数据之间的分离。
plt.figure(figsize=(14, 5), dpi=100)
plt.plot(dataset_ex_df['Date'], dataset_ex_df['GS'], label='Goldman Sachs stock')
plt.vlines(datetime.date(2016,4, 20), 0, 270, linestyles='--', colors='gray', label='Train/Test data cut-off')
plt.xlabel('Date')
plt.ylabel('USD')
plt.title('Figure 2: Goldman Sachs stock price')
plt.legend()
plt.show()
num_training_days = int(dataset_ex_df.shape[0]*.7)
print('Number of training days: {}. Number of test days: {}.'.format(num_training_days,
dataset_ex_df.shape[0]-num_training_days))

Number of training days: 1585. Number of test days: 680.
2.1、相关资产
如前所述,我们将使用其他资产作为特征,而不仅仅是GS。
那么,还有哪些资产会影响高盛的股价走势呢?对公司、业务线、竞争环境、依赖关系、供应商和客户类型等的良好理解对于选择正确的相关资产集非常重要:
- 首先是类似于GS的公司。我们将把摩根大通(JPMorgan Chase)和摩根士丹利(Morgan Stanley)等公司加入数据集。
- 作为一家投资银行,高盛(Goldman Sachs)依赖于全球经济。经济不景气或不稳定意味着没有并购或IPO,也可能是有限的自营交易收益。这就是为什么我们将包括全球经济指数。此外,我们将包括LIBOR(美元和英镑计价)利率,因为分析师可能会考虑经济的冲击来设定这些利率以及其他FI证券。
- 每日波动率指数(VIX) - 由于前一点所述的原因。
- 综合指数 - 例如纳斯达克和纽约证券交易所(美国)、FTSE100指数(英国)、Nikkei225指数(日本)、恒生指数和BSE Sensex指数(亚太)。
- 货币 - 全球贸易多次反映货币如何变动,因此我们将使用一篮子货币(如美元兑日元,英镑兑美元等)作为特征。
总的来说,我们在数据集中有72个其他资产 - 每个资产的每日价格。
2.2、技术指标
我们已经讨论了什么是技术指标以及为什么使用它们,现在让我们直接跳到Python代码。我们将只为GS创建技术指标。
def get_technical_indicators(dataset): # Create 7 and 21 days Moving Average dataset['ma7'] = dataset['price'].rolling(window=7).mean() dataset['ma21'] = dataset['price'].rolling(window=21).mean() # Create MACD dataset['26ema'] = pd.ewma(dataset['price'], span=26) dataset['12ema'] = pd.ewma(dataset['price'], span=12) dataset['MACD'] = (dataset['12ema']-dataset['26ema']) # Create Bollinger Bands dataset['20sd'] = pd.stats.moments.rolling_std(dataset['price'],20) dataset['upper_band'] = dataset['ma21'] + (dataset['20sd']*2) dataset['lower_band'] = dataset['ma21'] - (dataset['20sd']*2) # Create Exponential moving average dataset['ema'] = dataset['price'].ewm(com=0.5).mean() # Create Momentum dataset['momentum'] = dataset['price']-1 return dataset dataset_TI_df = get_technical_indicators(dataset_ex_df[['GS']]) dataset_TI_df.head()


所以我们有每个交易日的技术指标(包括MACD、Bollinger bands等)。我们总共有12项技术指标。
让我们想象一下这些指标的最后400天。
def plot_technical_indicators(dataset, last_days):
plt.figure(figsize=(16, 10), dpi=100)
shape_0 = dataset.shape[0]
xmacd_ = shape_0-last_days
dataset = dataset.iloc[-last_days:, :]
x_ = range(3, dataset.shape[0])
x_ =list(dataset.index)
# Plot first subplot
plt.subplot(2, 1, 1)
plt.plot(dataset['ma7'],label='MA 7', color='g',linestyle='--')
plt.plot(dataset['price'],label='Closing Price', color='b')
plt.plot(dataset['ma21'],label='MA 21', color='r',linestyle='--')
plt.plot(dataset['upper_band'],label='Upper Band', color='c')
plt.plot(dataset['lower_band'],label='Lower Band', color='c')
plt.fill_between(x_, dataset['lower_band'], dataset['upper_band'], alpha=0.35)
plt.title('Technical indicators for Goldman Sachs - last {} days.'.format(last_days))
plt.ylabel('USD')
plt.legend()
# Plot second subplot
plt.subplot(2, 1, 2)
plt.title('MACD')
plt.plot(dataset['MACD'],label='MACD', linestyle='-.')
plt.hlines(15, xmacd_, shape_0, colors='g', linestyles='--')
plt.hlines(-15, xmacd_, shape_0, colors='g', linestyles='--')
plt.plot(dataset['log_momentum'],label='Momentum', color='b',linestyle='-')
plt.legend()
plt.show()
plot_technical_indicators(dataset_TI_df, 400)
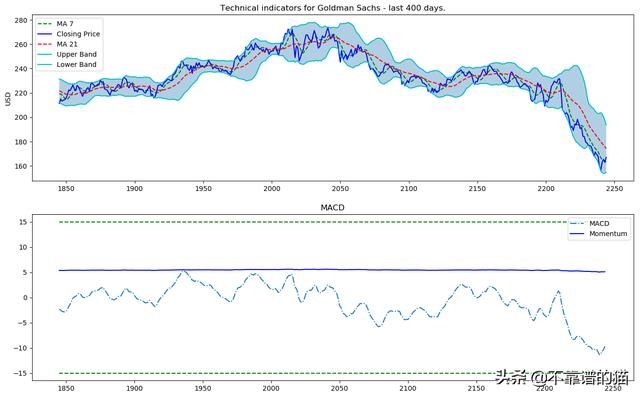
2.3、基本面分析
对于基本面分析,我们将对所有关于GS的每日新闻进行情感分析。最后使用sigmoid,结果将在0和1之间。分数越接近0 - 新闻越负面(接近1表示正面情感)。对于每一天,我们将创建平均每日得分(作为0到1之间的数字)并将其添加为特征。
2.3.1、 BERT
为了将新闻分类为正面或负面(或中性),我们将使用BERT,这是一种预训练的语言表示。
已经在MXNet / Gluon中提供预训练的BERT模型。我们只需要实例化它们并添加两个(任意数量)Dense层,softmax - 得分从0到1。
# just import bert import bert
2.4、傅立叶变换用于趋势分析
傅立叶变换采用函数并创建一系列正弦波(具有不同的幅度和帧)。组合时,这些正弦波接近原始函数。从数学上讲,变换看起来像这样:
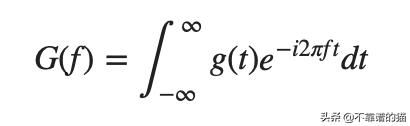
我们将使用傅里叶变换来提取GS股票的整体和局部趋势,并对其进行降噪。我们来看看它是如何工作的。
data_FT = dataset_ex_df[['Date', 'GS']]
close_fft = np.fft.fft(np.asarray(data_FT['GS'].tolist()))
fft_df = pd.DataFrame({'fft':close_fft})
fft_df['absolute'] = fft_df['fft'].apply(lambda x: np.abs(x))
fft_df['angle'] = fft_df['fft'].apply(lambda x: np.angle(x))
plt.figure(figsize=(14, 7), dpi=100)
fft_list = np.asarray(fft_df['fft'].tolist())
for num_ in [3, 6, 9, 100]:
fft_list_m10= np.copy(fft_list); fft_list_m10[num_:-num_]=0
plt.plot(np.fft.ifft(fft_list_m10), label='Fourier transform with {} components'.format(num_))
plt.plot(data_FT['GS'], label='Real')
plt.xlabel('Days')
plt.ylabel('USD')
plt.title('Figure 3: Goldman Sachs (close) stock prices & Fourier transforms')
plt.legend()
plt.show()
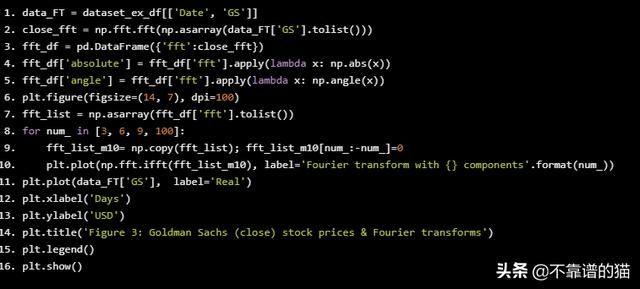
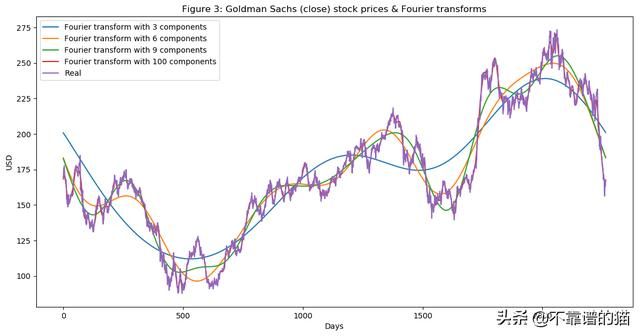
正如您在图3中看到的,我们使用傅里叶变换的成分越多,逼近函数越接近实际股票价格(100个成分变换几乎与原始函数相同 - 红色和紫色线几乎重叠)。我们使用傅立叶变换来提取长期和短期趋势,因此我们将使用具有3,6和9个成分的变换。您可以推断出具有3个成分的转换是长期趋势。
用于去噪数据的另一种技术是调用小波。小波和傅里叶变换给出了类似的结果,因此我们只使用傅里叶变换。
from collections import deque
items = deque(np.asarray(fft_df['absolute'].tolist()))
items.rotate(int(np.floor(len(fft_df)/2)))
plt.figure(figsize=(10, 7), dpi=80)
plt.stem(items)
plt.title('Figure 4: Components of Fourier transforms')
plt.show()
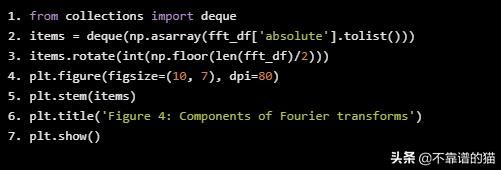
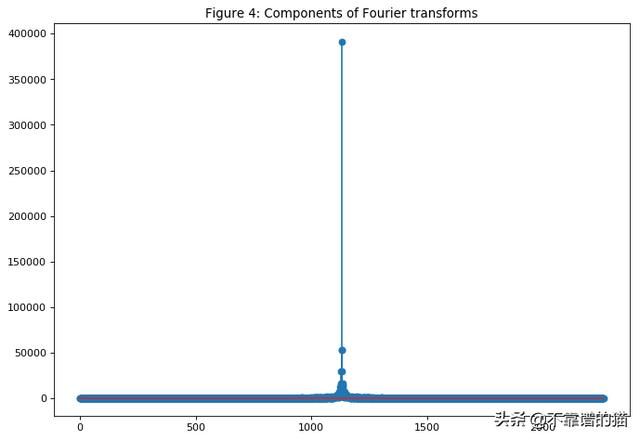
2.5、ARIMA作为一项特征值
ARIMA是一种预测时间序列数据的技术。我们将展示如何使用它,虽然ARIMA不能作为我们的最终预测,但我们将使用它作为一种技术来稍微降低噪声,并(可能)提取一些新的模式或特征。
from statsmodels.tsa.arima_model import ARIMA from pandas import DataFrame from pandas import datetime series = data_FT['GS'] model = ARIMA(series, order=(5, 1, 0)) model_fit = model.fit(disp=0) print(model_fit.summary())
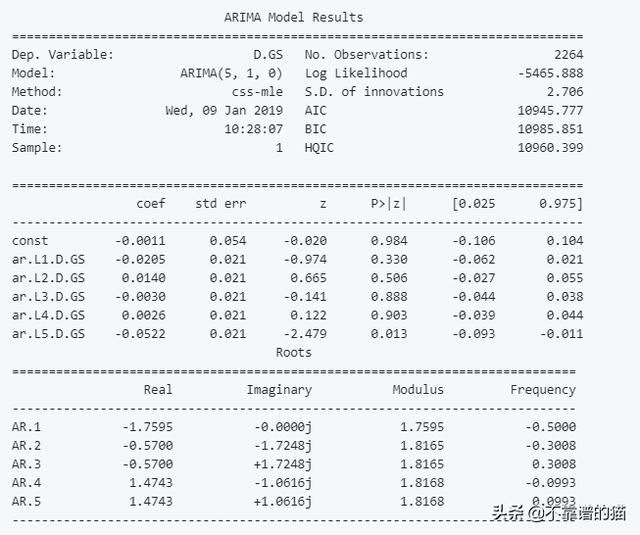
from pandas.tools.plotting import autocorrelation_plot autocorrelation_plot(series) plt.figure(figsize=(10, 7), dpi=80) plt.show()

from pandas import read_csv
from pandas import datetime
from statsmodels.tsa.arima_model import ARIMA
from sklearn.metrics import mean_squared_error
X = series.values
size = int(len(X) * 0.66)
train, test = X[0:size], X[size:len(X)]
history = [x for x in train]
predictions = list()
for t in range(len(test)):
model = ARIMA(history, order=(5,1,0))
model_fit = model.fit(disp=0)
output = model_fit.forecast()
yhat = output[0]
predictions.append(yhat)
obs = test[t]
history.append(obs)
error = mean_squared_error(test, predictions)
print('Test MSE: %.3f' % error)
Test MSE: 10.151
# Plot the predicted (from ARIMA) and real prices
plt.figure(figsize=(12, 6), dpi=100)
plt.plot(test, label='Real')
plt.plot(predictions, color='red', label='Predicted')
plt.xlabel('Days')
plt.ylabel('USD')
plt.title('Figure 5: ARIMA model on GS stock')
plt.legend()
plt.show()
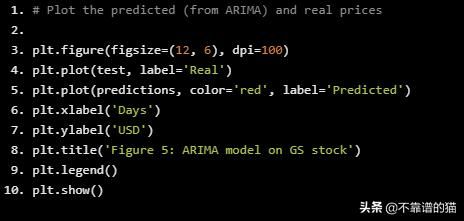
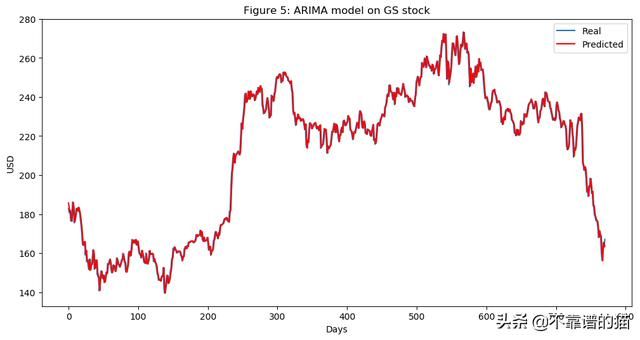
从图5中可以看出,ARIMA给出了一个非常接近实际股价的结果。我们将通过ARIMA使用预测价格作为LSTM的输入特征,因为正如我们前面提到的,我们希望尽可能多地捕获关于高盛的特征和模式。我们测试MSE(均方误差)为10.151,这本身并不是一个坏结果(考虑到我们有很多测试数据),但是我们仍然只将其作为LSTM中的一个特征。
2.6、统计检查
确保数据具有良好的质量对于机器学习模型非常重要。为了确保我们的数据拟合,我们将执行几个简单的检查,以确保我们实现和观察到的结果是真实的,而不是因为底层数据分布存在基本错误而受到损害。
2.6.1、异方差性,多重共线性,序列相关性
- 条件异方差发生在误差项(通过回归得到的预测值与实际值之间的差)依赖于数据时——例如,误差项随着数据点(沿x轴)的增长而增长。
- 多重共线性是指误差项(也称为残差)相互依赖的时间。
- 序列相关性是指一个数据(特征)是另一个特征的公式(或完全不相关)。
我们不会在这里进入代码,因为它很简单,我们的重点更多地放在深度学习部分,但数据是定性的。
2.7、特征工程
print('Total dataset has {} samples, and {} features.'.format(dataset_total_df.shape[0],
dataset_total_df.shape[1]))

Total dataset has 2265 samples, and 112 features.
因此,在添加了所有类型的数据(相关资产、技术指标、基础分析、傅立叶和Arima)之后,我们在这2,265天中总共有112个特征(如前所述,训练数据只有1,585天)。
我们还将从自动编码器生成更多特征。
2.7.1、XGBoost的重要性
有这么多的特征,我们必须要考虑它们是否真的代表了走势。例如,我们在机器学习数据集中包含了以美元计价的LIBOR利率,因为我们认为LIBOR的变化可能表明经济的变化,而经济的变化又可能表明GS的股票行为的变化。但我们需要测试。测试特征重要性的方法有很多,但是我们将使用XGBoost,因为它在分类和回归问题中都给出了最好的结果之一。
由于特征数据集非常大,出于演示目的,我们将仅使用技术指标。在真实特征重要性测试期间,所有选定的特征都证明有些重要,因此我们在训练GAN时不会排除任何内容。
def get_feature_importance_data(data_income): data = data_income.copy() y = data['price'] X = data.iloc[:, 1:] train_samples = int(X.shape[0] * 0.65) X_train = X.iloc[:train_samples] X_test = X.iloc[train_samples:] y_train = y.iloc[:train_samples] y_test = y.iloc[train_samples:] return (X_train, y_train), (X_test, y_test) # Get training and test data (X_train_FI, y_train_FI), (X_test_FI, y_test_FI) = get_feature_importance_data(dataset_TI_df) regressor = xgb.XGBRegressor(gamma=0.0,n_estimators=150,base_score=0.7,colsample_bytree=1,learning_rate=0.05) xgbModel = regressor.fit(X_train_FI,y_train_FI, eval_set = [(X_train_FI, y_train_FI), (X_test_FI, y_test_FI)], verbose=False) eval_result = regressor.evals_result() training_rounds = range(len(eval_result['validation_0']['rmse']))
让我们绘制训练和验证误差的曲线图,以便观察训练和检查过拟合(欠拟合)。
plt.scatter(x=training_rounds,y=eval_result['validation_0']['rmse'],label='Training Error')
plt.scatter(x=training_rounds,y=eval_result['validation_1']['rmse'],label='Validation Error')
plt.xlabel('Iterations')
plt.ylabel('RMSE')
plt.title('Training Vs Validation Error')
plt.legend()
plt.show()

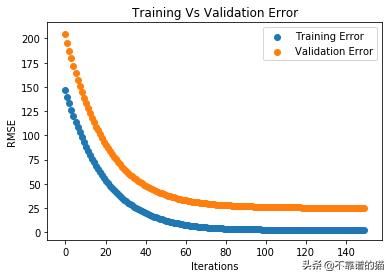
fig = plt.figure(figsize=(8,8))
plt.xticks(rotation='vertical')
plt.bar([i for i in range(len(xgbModel.feature_importances_))], xgbModel.feature_importances_.tolist(), tick_label=X_test_FI.columns)
plt.title('Figure 6: Feature importance of the technical indicators.')
plt.show()

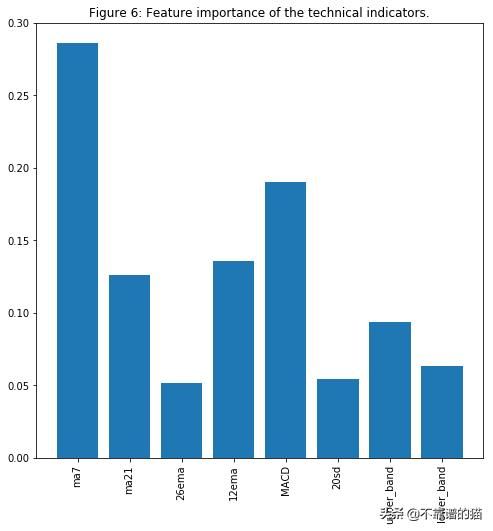
毫不奇怪,MA7,MACD和BB是其中的重要特征。
我遵循相同的逻辑来对整个数据集执行特征重要性 - 与仅少数几个特征相比,训练花费的时间更长,结果更难以阅读。
2.8、使用Stacked Autoencoders提取高级特征
在我们进入自动编码器之前,我们将探索激活函数。
2.8.1、激活功函数- GELU(高斯误差)
最近提出了GELU - Gaussian Error Linear Unites - link。在论文中,作者展示了使用ReLU作为激活的使用GELU的神经网络优于网络的几个实例。gelu也用于BERT,我们用于新闻情绪分析的NLP方法。
我们将使用GELU作为自动编码器。
注:下面的单元格展示了GELU数学背后的逻辑。它不是作为激活函数的实际实现。我必须在MXNet中实现GELU。如果您按照代码将act_type='relu'更改为act_type='gelu',那么它将不起作用,除非您更改MXNet的实现。对整个项目发出pull请求,以访问GELU的MXNet实现。
def gelu(x): return 0.5 * x * (1 + math.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * math.pow(x, 3)))) def relu(x): return max(x, 0) def lrelu(x): return max(0.01*x, x)
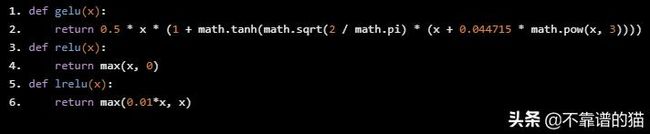
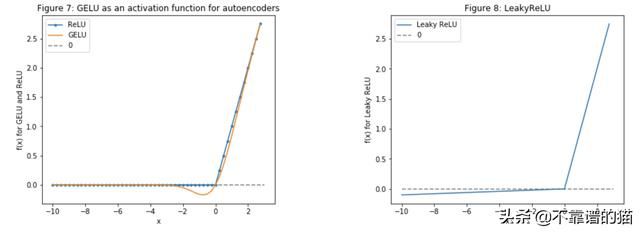
让我们来看看GELU、ReLU和LeakyReLU(最后一个主要用于GAN)。
plt.figure(figsize=(15, 5))
plt.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=.5, hspace=None)
ranges_ = (-10, 3, .25)
plt.subplot(1, 2, 1)
plt.plot([i for i in np.arange(*ranges_)], [relu(i) for i in np.arange(*ranges_)], label='ReLU', marker='.')
plt.plot([i for i in np.arange(*ranges_)], [gelu(i) for i in np.arange(*ranges_)], label='GELU')
plt.hlines(0, -10, 3, colors='gray', linestyles='--', label='0')
plt.title('Figure 7: GELU as an activation function for autoencoders')
plt.ylabel('f(x) for GELU and ReLU')
plt.xlabel('x')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot([i for i in np.arange(*ranges_)], [lrelu(i) for i in np.arange(*ranges_)], label='Leaky ReLU')
plt.hlines(0, -10, 3, colors='gray', linestyles='--', label='0')
plt.ylabel('f(x) for Leaky ReLU')
plt.xlabel('x')
plt.title('Figure 8: LeakyReLU')
plt.legend()
plt.show()
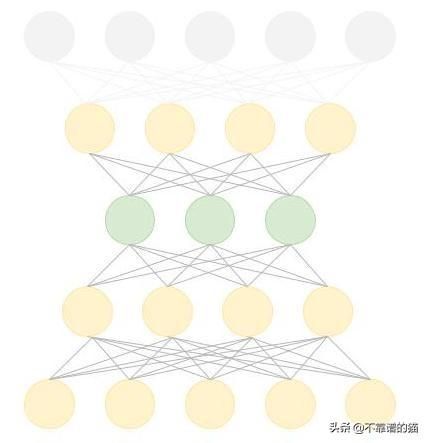
好的,回到自动编码器,如下所示(图像只是原理图,它不代表实际的层数,units等)
注意:通常,在自动编码器中编码器的数量==解码器的数量。但是,我们希望提取更高级别的特征(而不是创建相同的输入),因此我们可以跳过解码器中的最后一层。我们实现了这一点,在训练期间创建了具有相同层数的编码器和解码器。
batch_size = 64
n_batches = VAE_data.shape[0]/batch_size
VAE_data = VAE_data.values
train_iter = mx.io.NDArrayIter(data={'data': VAE_data[:num_training_days,:-1]},
label={'label': VAE_data[:num_training_days, -1]}, batch_size = batch_size)
test_iter = mx.io.NDArrayIter(data={'data': VAE_data[num_training_days:,:-1]},
label={'label': VAE_data[num_training_days:,-1]}, batch_size = batch_size)
model_ctx = mx.cpu()
class VAE(gluon.HybridBlock):
def __init__(self, n_hidden=400, n_latent=2, n_layers=1, n_output=784,
batch_size=100, act_type='relu', **kwargs):
self.soft_zero = 1e-10
self.n_latent = n_latent
self.batch_size = batch_size
self.output = None
self.mu = None
super(VAE, self).__init__(**kwargs)
with self.name_scope():
self.encoder = nn.HybridSequential(prefix='encoder')
for i in range(n_layers):
self.encoder.add(nn.Dense(n_hidden, activation=act_type))
self.encoder.add(nn.Dense(n_latent*2, activation=None))
self.decoder = nn.HybridSequential(prefix='decoder')
for i in range(n_layers):
self.decoder.add(nn.Dense(n_hidden, activation=act_type))
self.decoder.add(nn.Dense(n_output, activation='sigmoid'))
def hybrid_forward(self, F, x):
h = self.encoder(x)
#print(h)
mu_lv = F.split(h, axis=1, num_outputs=2)
mu = mu_lv[0]
lv = mu_lv[1]
self.mu = mu
eps = F.random_normal(loc=0, scale=1, shape=(self.batch_size, self.n_latent), ctx=model_ctx)
z = mu + F.exp(0.5*lv)*eps
y = self.decoder(z)
self.output = y
KL = 0.5*F.sum(1+lv-mu*mu-F.exp(lv),axis=1)
logloss = F.sum(x*F.log(y+self.soft_zero)+ (1-x)*F.log(1-y+self.soft_zero), axis=1)
loss = -logloss-KL
return loss
n_hidden=400 # neurons in each layer
n_latent=2
n_layers=3 # num of dense layers in encoder and decoder respectively
n_output=VAE_data.shape[1]-1
net = VAE(n_hidden=n_hidden, n_latent=n_latent, n_layers=n_layers, n_output=n_output, batch_size=batch_size, act_type='gelu')
net.collect_params().initialize(mx.init.Xavier(), ctx=mx.cpu())
net.hybridize()
trainer = gluon.Trainer(net.collect_params(), 'adam', {'learning_rate': .01})
print(net)
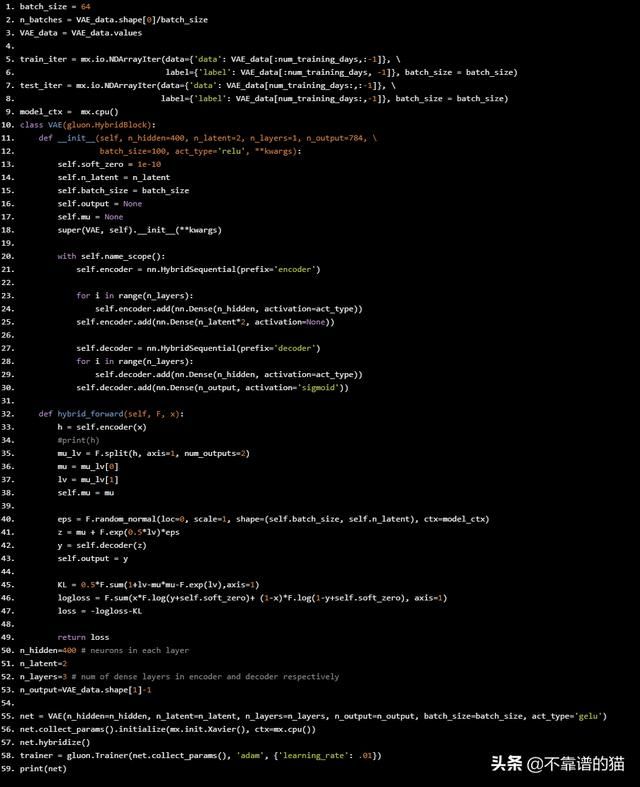
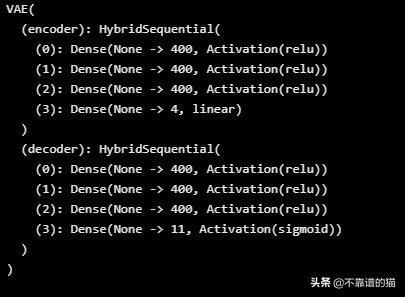
所以我们在编码器和解码器中都有3层(每个层有400个神经元)。
n_epoch = 150
print_period = n_epoch // 10
start = time.time()
training_loss = []
validation_loss = []
for epoch in range(n_epoch):
epoch_loss = 0
epoch_val_loss = 0
train_iter.reset()
test_iter.reset()
n_batch_train = 0
for batch in train_iter:
n_batch_train +=1
data = batch.data[0].as_in_context(mx.cpu())
with autograd.record():
loss = net(data)
loss.backward()
trainer.step(data.shape[0])
epoch_loss += nd.mean(loss).asscalar()
n_batch_val = 0
for batch in test_iter:
n_batch_val +=1
data = batch.data[0].as_in_context(mx.cpu())
loss = net(data)
epoch_val_loss += nd.mean(loss).asscalar()
epoch_loss /= n_batch_train
epoch_val_loss /= n_batch_val
training_loss.append(epoch_loss)
validation_loss.append(epoch_val_loss)
"""if epoch % max(print_period, 1) == 0:
print('Epoch {}, Training loss {:.2f}, Validation loss {:.2f}'.
format(epoch, epoch_loss, epoch_val_loss))"""
end = time.time()
print('Training completed in {} seconds.'.format(int(end-start)))
Training completed in 62 seconds.
dataset_total_df['Date'] = dataset_ex_df['Date']
vae_added_df = mx.nd.array(dataset_total_df.iloc[:, :-1].values)
print('The shape of the newly created (from the autoencoder) features is {}.'.format(vae_added_df.shape))

The shape of the newly created (from the autoencoder) features is (2265, 112).
我们从自动编码器中创建了112个更多特征。由于我们只想拥有高级特征(整体模式),我们将使用主成分分析(PCA)在新创建的112个特征上创建特征投资组合。这将减少数据的维度(列数)。Eigen组合的描述能力将与原始的112个特征相同。
注意再一次,这纯粹是实验性的。我并非100%确定描述的逻辑将成立。作为人工智能和深度学习的其他一切,这是艺术和需要实验。
2.8.2、主成分分析的特征组合
# We want the PCA to create the new components to explain 80% of the variance pca = PCA(n_components=.8) x_pca = StandardScaler().fit_transform(vae_added_df) principalComponents = pca.fit_transform(x_pca) principalComponents.n_components_
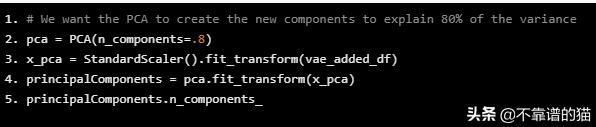
84
所以,为了解释80%的方差我们需要84个(112个)特征。这仍然是一个很大的问题。因此,目前我们不包括自动编码器创建的特征。我将致力于创建autoencoder架构,在该架构中,我们从中间层(而不是最后一层)获得输出,并使用30个神经元将其连接到另一个Dense 层。因此,我们将1)只提取更高级别的特征,2)提供更少的列数。
3.生成性对抗网络(GAN)

GAN的体系结构
GAN如何运作?
如前所述,本文的目的不是详细解释深度学习背后的数学,而是展示其应用。当然,在我看来,彻底和非常坚实的理解从基础到最小的细节,是极其必要的。因此,我们将尝试平衡并给出一个关于GAN如何工作的高级概述,以便读者充分理解使用GAN预测股价走势背后的原理。
GAN网络由两个模型组成 - Generator(G)和Discriminator (D)。训练GAN的步骤如下:
- 使用随机数据(噪声表示为z),Generator试图“生成”与真实数据无法区分或非常接近的数据。它的目的是学习真实数据的分布。
- 将随机、真实或生成的数据拟合到Discriminator 中,Discriminator 作为分类器,试图了解数据是来自Generator还是真实数据。
- 然后,G和D的损失被组合并通过Generator传播回来。因此,Generator的损失取决于Generator和Discriminator 。这是帮助Generator了解真实数据分布的步骤。如果Generator在生成真实数据(具有相同分布)方面做得不好,则Discriminator 的工作将很容易区分生成与实际数据集。因此,Discriminator 的损失将非常小。小的Discriminator 损失将导致更大的Generator损耗(参见下面的等式 L(D,G))。这使得创建Discriminator 有点棘手,因为Discriminator 太好会导致巨大的Generator损失,使得Generator无法学习。
- 该过程一直持续到Discriminator无法再将生成数据与实际数据区分开来。
当组合在一起时,D和G作为一种playing minmax游戏(Generator试图欺骗Discriminator ,使其增加假例子的概率,即最小化z〜pz(z)[log(1-D(G) z)))]。Discriminator 想要通过最大化x~pr(x)[logD(x)]来分离来自发生器D(G(z))的数据。但是,具有分离的损失函数,它是不清楚两者如何汇合在一起(这就是为什么我们使用普通GAN的一些进步,例如Wasserstein GAN)。总的来说,组合损失函数看起来像:
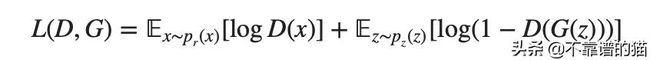
3.1、为什么GAN用于股市预测
生成对抗网络(GAN)最近主要用于创建逼真的图像,绘画和视频剪辑。在我们的案例中,没有多少GAN用于预测时间序列数据。然而,主要想法应该是相同的 - 我们希望预测未来的股票变动。在未来,GS股票的模式和行为应该或多或少相同(除非它开始以完全不同的方式运作,或者经济急剧变化)。因此,我们希望“生成”未来的数据,这些数据将具有与我们已有的相似(当然不完全相同)的分布 - 历史交易数据。所以,从理论上讲,它应该有效。
在我们的例子中,我们将使用LSTM作为时间序列生成器,并使用CNN作为Discriminator。
3.2、Metropolis-Hastings GAN和Wasserstein GAN
I. Metropolis-Hastings GAN
Uber的工程团队最近对传统GAN进行了改进,称为Metropolis-Hastings GAN(MHGAN)。优步的方法背后的想法(正如他们所述)与谷歌和加州大学伯克利分校创建的另一种方法有点类似,称为DRS。基本上,当我们训练GAN时,我们使用Discriminator(D)的唯一目的是更好地训练Generator(G)。通常,在训练GAN之后我们不再使用D. 然而,MHGAN和DRS尝试使用D来选择由G生成的接近实际数据分布的样本(MHGAN之间的微小差异是使用马尔可夫链蒙特卡罗(MCMC)进行采样)。
MHGAN采用从G生成的K个样本(从独立的噪声输入到下图中的G-z0到zK)。然后它依次运行K个输出(x'0到x'K)并遵循接受规则(从Discriminator创建)决定是接受当前样本还是保留最后接受的样本。最后保留的输出是被认为是G的实际输出的输出。
注意:MHGAN最初由优步在pytorch中实现。我只把它转移到MXNet / Gluon。
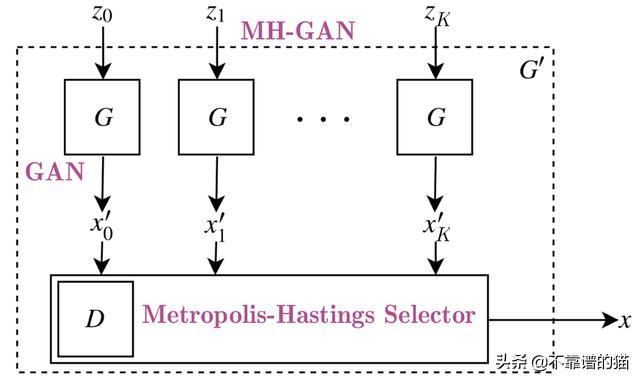
图10:MHGAN的视觉表示
II。Wasserstein GAN
训练GAN非常困难。模型可能永远不会收敛,模式崩溃很容易发生。我们将使用名为Wasserstein GAN - WGAN的GAN修改。
最值得注意的要点是:
- 我们知道GAN背后的主要目标是让Generator开始将随机噪声转换为我们想要模仿的某些给定数据。因此,在GAN中,比较两个分布之间的相似性的想法是非常必要的。这两个最广泛使用的指标是:
- KL散度(Kullback-Leibler) - DKL(p‖q)=∫xp(x)logp(x)q(x)dx。当p(x)等于q(x)时,DKL为零,
- JS Divergence(Jensen-Shannon)。JS散度以0和1为界,与KL散度不同,它是对称的,更平滑。当损失从KL转移到JS散度时,GAN训练取得了显著的成功。
- WGAN使用 Wasserstein距离,W(PR,PG)=1Ksup‖f‖L≤Kx~pr[F(X)] - x~pg[F(X)](其中supsup代表supremum),作为损失函数。与KL和JS的差异相比,Wasserstein度量提供了一个平滑的度量(没有突然的跳跃)。这使得它更适合在梯度下降期间创建稳定的学习过程。
- 此外,与KL和JS相比,Wasserstein距离几乎无处不在。众所周知,在反向传播过程中,我们会区分损失函数以创建梯度,从而更新权重。因此,具有可微分的损失函数是非常重要的。
3.4、Generator - One layer RNN
3.4.1、LSTM或GRU
如前所述,Generator是LSTM网络的一种循环神经网络(RNN)。RNN用于时间序列数据,因为它们跟踪所有先前的数据点,并且可以捕获随时间发展的模式。由于它们的性质,RNN很多时候都会受到梯度消失的影响 - 也就是说,在训练期间权重变化的变化变得如此之小,以至于它们不会改变,使得网络无法收敛到最小的损失(相反的问题也可以有时会观察到 - 当梯度变得太大时。这称为梯度爆炸,但解决方法很简单。两个方法解决了这个问题 - 门控循环单元(GRU)和长短期记忆(LSTM)。两者之间最大的区别是:1)GRU有2个门(update 和reset),LSTM有4个(update, input, forget, 和output),2)LSTM保持内部存储器状态,而GRU没有, 3)LSTM在输出门之前应用非线性(sigmoid),GRU不应用。
在大多数情况下,LSTM和GRU在准确性方面给出了类似的结果,但GRU的计算密集程度要低得多,因为GRU的可训练参数更少。然而,LSTM使用得更多。
严格地说,LSTM cell (gates)背后的数学是:

LSTM cell背后的数学
其中⊙是一个逐元素的乘法运算符,并且,对于所有x = [x1,x2,...,xk]⊤∈R^ k,激活函数:
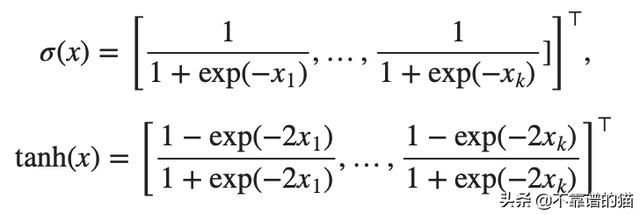
3.4.2LSTM架构
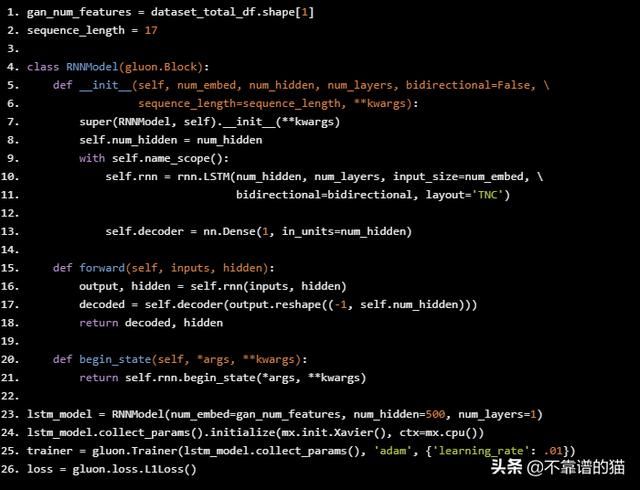
LSTM架构非常简单 - LSTM一层有112个输入单元(因为我们在数据集中有112个特征)和500个隐藏单元,Dense层有1个输出 - 每天的价格。初始化器是Xavier,我们将使用L1损失(这是L1正则化的平均绝对误差损失)。
注意 - 在Python代码中,您可以看到我们使用Adam(使用learning rate.01)作为优化器。
gan_num_features = dataset_total_df.shape[1]
sequence_length = 17
class RNNModel(gluon.Block):
def __init__(self, num_embed, num_hidden, num_layers, bidirectional=False,
sequence_length=sequence_length, **kwargs):
super(RNNModel, self).__init__(**kwargs)
self.num_hidden = num_hidden
with self.name_scope():
self.rnn = rnn.LSTM(num_hidden, num_layers, input_size=num_embed,
bidirectional=bidirectional, layout='TNC')
self.decoder = nn.Dense(1, in_units=num_hidden)
def forward(self, inputs, hidden):
output, hidden = self.rnn(inputs, hidden)
decoded = self.decoder(output.reshape((-1, self.num_hidden)))
return decoded, hidden
def begin_state(self, *args, **kwargs):
return self.rnn.begin_state(*args, **kwargs)
lstm_model = RNNModel(num_embed=gan_num_features, num_hidden=500, num_layers=1)
lstm_model.collect_params().initialize(mx.init.Xavier(), ctx=mx.cpu())
trainer = gluon.Trainer(lstm_model.collect_params(), 'adam', {'learning_rate': .01})
loss = gluon.loss.L1Loss()
我们将在LSTM层中使用500个神经元并使用Xavier初始化。为了正则化,我们将使用L1。让我们来看看LSTMMXNet打印的内容。
print(lstm_model)
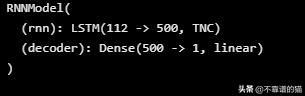
正如我们所看到的,LSTM的输入是112个特征(dataset_total_df.shape[1])然后进入LSTM层中的500个神经元,然后转换为单个输出 - 股票价格值。
LSTM背后的逻辑是:我们取17天(sequence_length)的数据(同样,这些数据是GS股票每天的股价+当天的所有其他特性——相关资产、情绪等),并尝试预测第18天。
3.4.3、学习率调度程序
最重要的超参数之一是学习率。在训练神经网络时,为几乎所有优化器(例如SGD,Adam或RMSProp)设置学习速率至关重要,因为它既能控制收敛速度,又能控制网络的最终性能。最简单的学习率策略之一是在整个训练过程中具有固定的学习率。选择较小的学习速率可以使优化器找到好的解决方案,但这是以限制初始收敛速度为代价的。随着时间的推移改变学习率可以克服这种权衡。
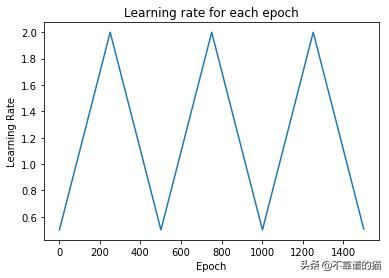
让我们绘制我们将在每个epoch使用的学习率。
class TriangularSchedule():
def __init__(self, min_lr, max_lr, cycle_length, inc_fraction=0.5):
self.min_lr = min_lr
self.max_lr = max_lr
self.cycle_length = cycle_length
self.inc_fraction = inc_fraction
def __call__(self, iteration):
if iteration <= self.cycle_length*self.inc_fraction:
unit_cycle = iteration * 1 / (self.cycle_length * self.inc_fraction)
elif iteration <= self.cycle_length:
unit_cycle = (self.cycle_length - iteration) * 1 / (self.cycle_length * (1 - self.inc_fraction))
else:
unit_cycle = 0
adjusted_cycle = (unit_cycle * (self.max_lr - self.min_lr)) + self.min_lr
return adjusted_cycle
class CyclicalSchedule():
def __init__(self, schedule_class, cycle_length, cycle_length_decay=1, cycle_magnitude_decay=1, **kwargs):
self.schedule_class = schedule_class
self.length = cycle_length
self.length_decay = cycle_length_decay
self.magnitude_decay = cycle_magnitude_decay
self.kwargs = kwargs
def __call__(self, iteration):
cycle_idx = 0
cycle_length = self.length
idx = self.length
while idx <= iteration:
cycle_length = math.ceil(cycle_length * self.length_decay)
cycle_idx += 1
idx += cycle_length
cycle_offset = iteration - idx + cycle_length
schedule = self.schedule_class(cycle_length=cycle_length, **self.kwargs)
return schedule(cycle_offset) * self.magnitude_decay**cycle_idx
schedule = CyclicalSchedule(TriangularSchedule, min_lr=0.5, max_lr=2, cycle_length=500)
iterations=1500
plt.plot([i+1 for i in range(iterations)],[schedule(i) for i in range(iterations)])
plt.title('Learning rate for each epoch')
plt.xlabel("Epoch")
plt.ylabel("Learning Rate")
plt.show()

3.4.4、如何防止过度拟合和偏差 - 方差权衡
有很多特征和神经网络,我们需要确保我们避免过拟合,并注意总损失。
我们使用几种技术来防止过度拟合(不仅在LSTM中,并且在CNN和自动编码器中):
- 确保数据质量。我们已经进行了统计检查,确保数据不受多重共线性或序列自相关的影响。进一步,我们对每个特征执行了特征重要性检查。最后,利用一些有关股票市场运作机制的领域知识进行了初始特征选择(例如,选择相关资产、技术指标等)。
- 正规化(或权重惩罚)。两种最广泛使用的正则化技术是LASSO(L1)和Ridge(L2)。L1增加了平均绝对误差,L2增加了平均误差。在没有涉及太多数学细节的情况下,基本区别是:LASSO回归(L1)同时进行变量选择和参数收缩,而Ridge归仅进行参数收缩并最终包括模型中的所有系数。在存在相关变量的情况下,岭回归可能是首选。此外,岭回归在最小二乘估计具有较高方差的情况下效果最佳。因此,这取决于我们的模型目标。两种类型的正则化的影响是完全不同的。虽然它们都会对大权重进行惩罚,但L1正则化会导致零不可微函数。L2正则化有利于较小的权重,但L1正则化有利于权重变为零。所以,使用L1正则化,您可以得到一个稀疏模型 - 一个参数较少的模型。在这两种情况下,L1和L2正则化模型的参数“收缩”,但在L1正则化的情况下,收缩直接影响模型的复杂性(参数的数量)。
- Dropout。Dropout层随机删除隐藏图层中的节点。
- ense-sparse-dense training
- Early stopping.
构建复杂神经网络时的另一个重要考虑因素是偏差 - 方差权衡。基本上,我们在训练网络时得到的误差是偏差,方差和不可减少误差的函数 - σ(由噪声和随机性引起的误差)。权衡的最简单公式是:Error=bias^2+variance+σ.
- 偏见。偏差衡量训练的(训练数据集)算法在看不见的数据上的表现。高偏差(欠拟合)意味着模型不能很好地处理看不见的数据。
- 方差。方差衡量模型对数据集变化的敏感性。高度差异是过度拟合。
3.5、Discriminator
为什么CNN作为Discriminator ?
我们通常将CNN用于与图像相关的工作(分类,上下文提取等)。例如,在狗的图像中,第一个卷积层将检测边缘,第二个将开始检测圆圈,第三个将检测到鼻子。在我们的例子中,数据点形成小趋势,小趋势形成更大,趋势形成模式。CNN检测特征的能力可用于提取有关GS股票价格变动模式的信息。
使用CNN的另一个原因是CNN在空间数据上运行良好 - 这意味着彼此更接近的数据点彼此之间的相关性更高,而不是数据点。对于时间序列数据,这应该适用。在我们的例子中,每个数据点(对于每个特征)是连续的每一天。很自然地假设彼此距离越近,彼此之间的相关性就越大。需要考虑的一件事(虽然没有涉及这项工作)是季节性以及它如何改变(如果有的话)CNN的工作。
3.5.1。CNN架构
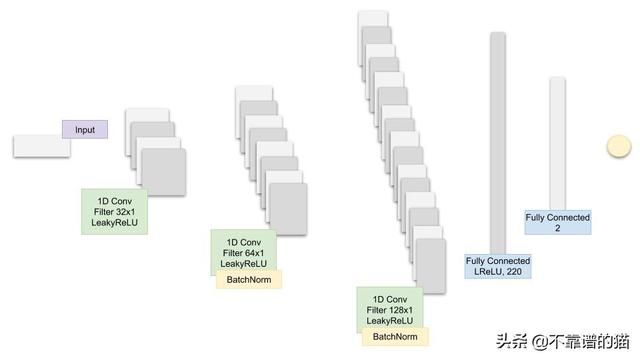
建议的CNN模型的架构
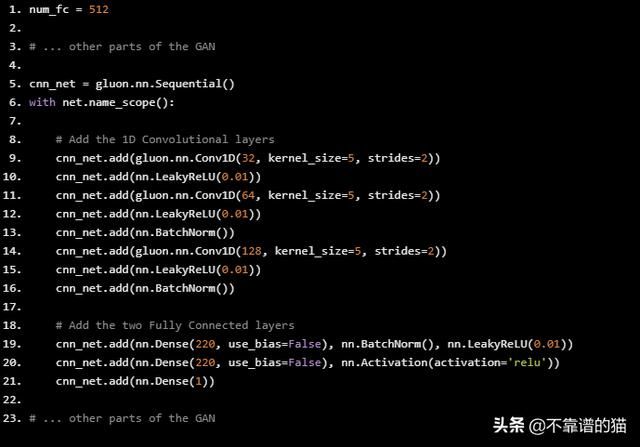
GAN中CNN的Python代码是这样的:
num_fc = 512 # ... other parts of the GAN cnn_net = gluon.nn.Sequential() with net.name_scope(): # Add the 1D Convolutional layers cnn_net.add(gluon.nn.Conv1D(32, kernel_size=5, strides=2)) cnn_net.add(nn.LeakyReLU(0.01)) cnn_net.add(gluon.nn.Conv1D(64, kernel_size=5, strides=2)) cnn_net.add(nn.LeakyReLU(0.01)) cnn_net.add(nn.BatchNorm()) cnn_net.add(gluon.nn.Conv1D(128, kernel_size=5, strides=2)) cnn_net.add(nn.LeakyReLU(0.01)) cnn_net.add(nn.BatchNorm()) # Add the two Fully Connected layers cnn_net.add(nn.Dense(220, use_bias=False), nn.BatchNorm(), nn.LeakyReLU(0.01)) cnn_net.add(nn.Dense(220, use_bias=False), nn.Activation(activation='relu')) cnn_net.add(nn.Dense(1)) # ... other parts of the GAN
让我们打印CNN。
print(cnn_net)
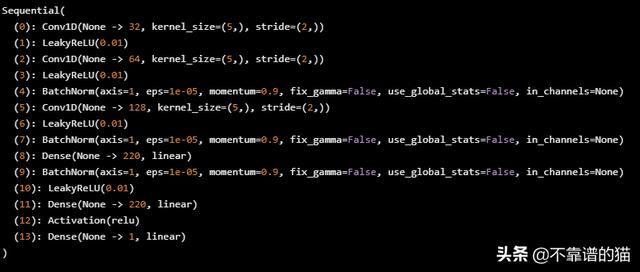
3.6、超参数
我们将跟踪和优化的超参数是:
- batch_size :LSTM和CNN的批量大小
- cnn_lr:CNN的学习率
- strides:CNN中的strides
- lrelu_alpha:GAN中LeakyReLU的alpha
- batchnorm_momentum:momentum for the batch normalisation in the CNN
- padding:CNN中的padding
- kernel_size':1:CNN中的核大小
- dropout:LSTM中的dropout
- filters:初始filters数量
我们将训练超过200个epochs。
4.超参数优化
在200个epochs的GAN训练之后,它将记录MAE(这是LSTM中的误差函数,GG)并将其作为奖励值传递给强化学习,该学习决定是否改变继续训练的超参数。
如果RL决定它将更新超参数,它将调用贝叶斯优化(下面讨论)库,它将提供下一个最佳预期的超级参数集
4.1、超参数优化的强化学习
为什么我们在超参数优化中使用强化学习?股市一直在变化。即使我们设法训练我们的GAN和LSTM以创建非常准确的结果,结果可能仅在一段时间内有效。意思是,我们需要不断优化整个过程。为了优化流程,我们可以:
- 添加或删除特征(例如添加可能相关的新股票或货币)
- 改善我们的深度学习模式。改进机器学习模型的最重要方法之一是通过超参数。一旦找到了一组超参数,我们就需要决定何时更改它们以及何时使用已知的集合(探索与利用)。此外,股市代表一个连续的空间,取决于数百万参数。
4.1.1、强化学习理论
在不解释RL的基础知识的情况下,我们将详细介绍我们在此实现的具体方法。我们将使用model-free RL算法,原因很明显我们不了解整个环境,因此没有明确的环境工作模型 - 如果我们不需要预测股票价格变动 - 它们只会按照该模型。我们将使用model-free RL的两个细分 - 策略优化和Q学习。
- Q-learning - 在Q-learning中我们学习从一个给定的状态采取动作的价值。Q值是采取动作后的预期回报。我们将使用Rainbow,它是七种Q学习算法的组合。
- 策略优化 - 在策略优化中,我们学习从给定状态采取的动作。(如果我们使用像Actor / Critic这样的方法),我们也会学习处于给定状态的值。我们将使用近端策略优化。
构建RL算法的一个关键方面是准确设置奖励。它必须捕获环境的所有方面以及代理与环境的交互。我们将奖励R定义为:
Reward=2∗lossG+lossD+accuracyG,
其中lossG,accuracyG和lossD分别是Generator的损失和准确性,以及Discriminator的损失。环境是GAN和LSTM训练的结果。不同代理可以采取的动作是如何更改GAN的D和G网络的超参数。
4.1.1.1、Rainbow
Rainbow(link)是一种基于Q学习的非策略深度强化学习算法,它将七种算法结合在一起:
- DQN。DQN是Q学习算法的扩展,其使用神经网络来表示Q值。与监督(深度)学习类似,在DQN中,我们训练神经网络并尝试最小化损失函数。我们通过随机抽样转换(状态、动作、奖励)来训练网络。例如,这些层不仅可以是全连接层,而且可以是卷积层。
- Double Q学习。Double QL处理Q学习中的一个大问题,即高估偏差。
- Prioritized replay。在vanilla DQN中,所有转换都存储在replay 缓冲区中,并均匀地对此缓冲区进行采样。然而,并非所有transitions在学习阶段都同样有益(这也使得学习效率低,因为需要更多的episodes )。Prioritized experience replay 不是均匀采样,而是使用分布,该分布为先前迭代中具有较高Q损失的样本提供更高的概率。
- Dueling networks。Dueling networks通过使用两个单独的流(即具有两个不同的微型神经网络)来稍微改变Q学习架构。一个流用于值,一个用于优势。它们都共享一个卷积编码器。棘手的部分是流的合并 - 它使用了一个特殊的聚合器(Wang et al.2016)。
- Multi-step learning。Multi-step learning背后的巨大差异在于它使用N步返回计算Q值(不仅是下一步的返回),这自然应该更准确。
- 分布式RL。Q学习使用平均估计的Q值作为目标值。但是,在许多情况下,Q值在不同情况下可能不同。分布式RL可以直接学习(或近似)Q值的分布,而不是对它们求平均值。再次,数学比这复杂得多,但对我们来说,好处是Q值的更准确的采样。
- Noisy Nets。基本DQN实现了一个简单的ε-贪婪机制来进行探索。这种探索方法有时效率低下。Noisy Nets解决这个问题的方法是添加一个有噪声的线性层。随着时间的推移,网络将学习如何忽略噪声(添加为嘈杂的流)。但是这种学习在空间的不同部分以不同的速度进行,允许进行状态探索。
4.1.1.2、PPO
近端策略优化(PPO)是一种无策略优化模型的强化学习。实现其他算法要简单得多,效果非常好。
我们为什么要使用PPO?PPO的一个优点是它直接学习策略,而不是间接地通过值(Q学习使用Q值来学习策略的方式)。它可以在连续动作空间中很好地工作,这在我们的使用案例中是合适的,并且可以(通过平均值和标准偏差)学习分布概率(如果将softmax作为输出添加)。
政策梯度方法的问题在于它们对步长选择极其敏感 - 如果它很小,则进度需要太长时间(很可能主要是由于需要二阶导数矩阵); 如果它很大,会有很多噪音会显著降低性能。由于政策的变化(以及奖励和观察变化的分布),输入数据是非平稳的。与监督学习相比,选择不当的步骤可能会更具破坏性,因为它会影响下次访问的整个分布。PPO可以解决这些问题。更重要的是,与其他一些方法相比,PPO:
- 例如,与ACER(它需要额外的代码来保持策略外相关性和replay 缓冲区)或TRPO(它对代理目标函数施加了约束,即新旧策略之间的KL差异)相比,前者要简单得多。这个约束用于控制过多更改的策略——这可能会造成不稳定。PPO减少了计算(由约束)利用 clipped 之间([1 -1 +])替代目标函数和修改目标函数用惩罚有太大的更新。
- 与TRPO相比,它与在值和策略函数或辅助损失之间共享参数的算法兼容(尽管PPO也具有信任区域PO的增益)。
注意:出于练习的目的,我们不会过多地研究和优化RL方法,PPO和其他方法。相反,我们将采用可用的方法,并尝试适应我们的GAN,LSTM和CNN模型的超参数优化过程。我们将重用和自定义的Python代码由OpenAI创建,可在此处获得(https://github.com/openai/baselines)。
4.1.2、进一步加强学习的工作
进一步探索强化学习的一些想法:
- 我接下来要介绍的第一件事是使用增强随机搜索(https://arxiv.org/pdf/1803.07055.pdf)作为替代算法。该算法的作者(在UC,Berkeley之外)已经设法获得与其他最先进的方法(如PPO)类似的奖励结果,但平均快15倍。
- 选择奖励函数非常重要。
- 使用好奇心作为探索政策。
- 根据伯克利的AI研究团队(BAIR)提出的建立多代理体系结构 - 链接(https://bair.berkeley.edu/blog/2018/12/12/rllib/)。
4.2、贝叶斯优化
我们将使用贝叶斯优化来代替网格搜索,这可能需要花费大量时间来找到超参数的最佳组合。我们将使用的库已经实现 - 链接(https://github.com/fmfn/BayesianOptimization)。
4.2.1、高斯过程
# Initialize the optimizer from bayes_opt import BayesianOptimization from bayes_opt import UtilityFunction utility = UtilityFunction(kind="ucb", kappa=2.5, xi=0.0)
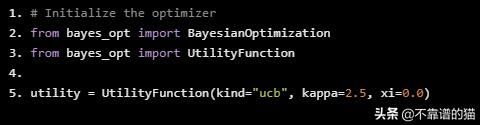
4.2.2、高斯过程结果
5.结果
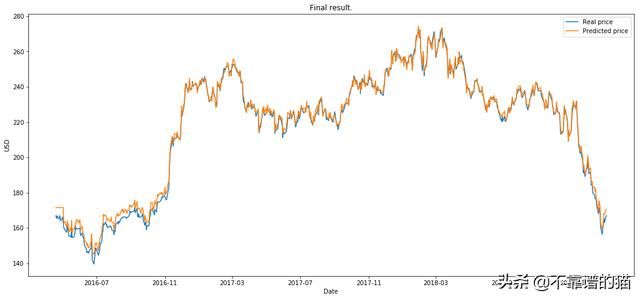
最后,当在过程的不同阶段之后将看不见的(测试)数据用作输入时,我们将比较LSTM的输出。
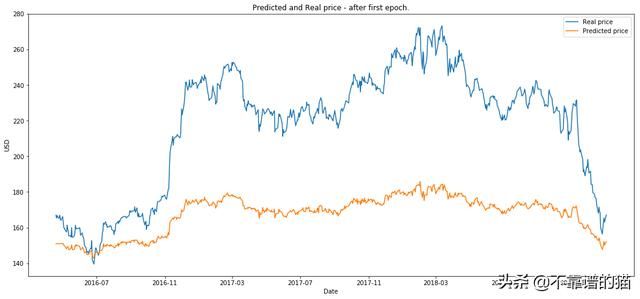
- 在第一个epoch之后绘制图像。
from utils import plot_prediction
plot_prediction('Predicted and Real price - after first epoch.')
2.绘制50个epochs后的图像。
plot_prediction('Predicted and Real price - after first 50 epochs.')
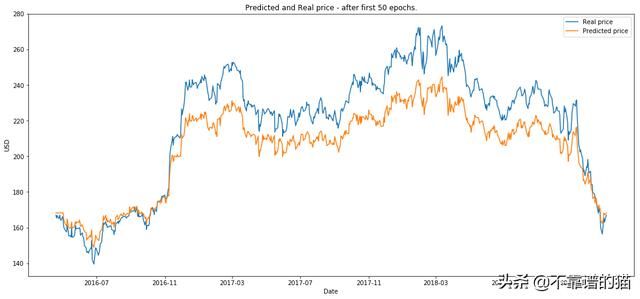
plot_prediction('Predicted and Real price - after first 200 epochs.')
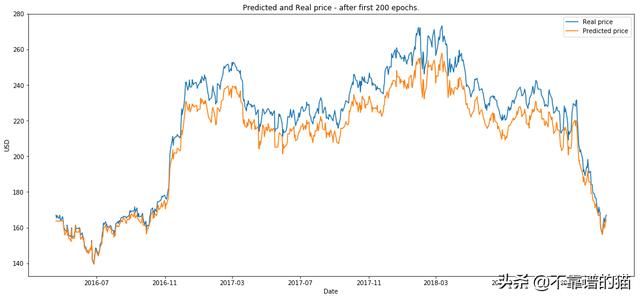
RL运行en episodes(我们将eposide定义为200个epochs上的一个完整GAN训练)。
plot_prediction('Final result.')