参考Go的CSP并发模型实现:M, P, G
Go语言是为并发而生的语言,Go语言是为数不多的在语言层面实现并发的语言。
并发(concurrency):多个任务在同一段时间内运行。
并行(parallellism):多个任务在同一时刻运行。
Go的CSP并发模型(goroutine + channel)
Go实现了两种并发形式。
- 多线程共享内存:Java或者C++等语言中的多线程开发。
- CSP(communicating sequential processes)并发模型:Go语言特有且推荐使用的。
不同于传统的多线程通过共享内存来通信,CSP讲究的是“以通信的方式来共享内存”。
普通的线程并发模型,就是像Java、C++、或者Python,他们线程间通信都是通过共享内存的方式来进行的。非常典型的方式就是,在访问共享数据(例如数组、Map、或者某个结构体或对象)的时候,通过锁来访问,因此,在很多时候,衍生出一种方便操作的数据结构,叫做“线程安全的数据结构”。
Go的CSP并发模型,是通过goroutine和channel来实现的。
- goroutine 是Go语言中并发的执行单位。可以理解为用户空间的线程。
- channel是Go语言中不同goroutine之间的通信机制,即各个goroutine之间通信的”管道“,有点类似于Linux中的管道。
1、goroutine
Go语言最大的特色就是从语言层面支持并发(goroutine),goroutine是Go中最基本的执行单元。事实上每一个Go程序至少有一个goroutine:主goroutine。当程序启动时,它会自动创建。我们在使用Go语言进行开发时,一般会使用goroutine来处理并发任务。
goroutine机制有点像线程池:
go 内部有三个对象: P(processor) 代表上下文(M所需要的上下文环境,也就是处理用户级代码逻辑的处理器),M(work thread)代表内核线程,G(goroutine)协程。
正常情况下一个cpu核运行一个内核线程,一个内核线程运行一个goroutine协程。当一个goroutine阻塞时,会启动一个新的内核线程来运行其他goroutine,以充分利用cpu资源。所以线程往往会比cpu核数更多。
example
在单核情况下,所有goroutine运行在同一个内核线程(M0)中,每一个内核线程维护一个上下文(P),任何时刻,一个上下文中只有一个goroutine,其他goroutine在runqueue中等待。一个goroutine运行完自己的时间片后,让出上下文,自己回到runqueue中。如下图左边所示,只有一个G0在运行,而其他goroutine都挂起了。
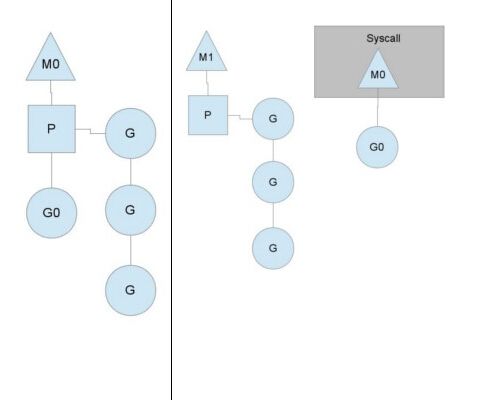
当正在运行的G0阻塞的时候(IO之类的),会再创建一个新的内核线程(M1),P转到新的内核线程中去运行。
当M0返回时(不再阻塞),它会尝试从其他线程中“偷”一个上下文(cpu)过来,如果没有偷到,会把goroutine放到global runqueue中去,然后把自己放入线程缓存中。上下文会定时检查global runqueue切换goroutine运行。
goroutine的优点:
1、创建与销毁的开销小
线程创建时需要向操作系统申请资源,并且在销毁时将资源归还,因此它的创建和销毁的开销比较大。相比之下,goroutine的创建和销毁是由go语言在运行时自己管理的,因此开销更低。所以一个Golang的程序中可以支持10w级别的Goroutine。每个 goroutine (协程) 默认占用内存远比 Java 、C 的线程少(*goroutine:*2KB ,线程:8MB)
2、切换开销小
这是goroutine于线程的主要区别,也是golang能够实现高并发的主要原因。
线程的调度方式是抢占式的,如果一个线程的执行时间超过了分配给它的时间片,就会被其它可执行的线程抢占。在线程切换的过程中需要保存/恢复所有的寄存器信息,比如16个通用寄存器,PC(Program Counter),SP(Stack Pointer),段寄存器等等。
而goroutine的调度是协同式的,没有时间片的概念,由Golang完成,它不会直接地与操作系统内核打交道。当goroutine进行切换的时候,之后很少量的寄存器需要保存和恢复(PC和SP)。因此gouroutine的切换效率更高。
总的来说,操作系统的一个线程下可以并发执行上千个goroutine,每个goroutine所占用的资源和切换开销都很小,因此,goroutine是golang适合高并发场景的重要原因。
生成一个goroutine的方法十分简单,直接使用go关键字即可:
go func();
2、channel
参考由浅入深剖析 go channel
channel的使用方法:声明之后,传数据用channel <- data,取数据用<-channel。channel分为无缓冲和有缓冲,无缓冲会同步阻塞,即每次生产消息都会阻塞到消费者将消息消费;有缓冲的不会立刻阻塞。
无缓存channel
ch := make(chan int) // write to channel ch <- x // read from channel x <- ch // another way to read x = <- ch
从无缓存的 channel 中读取消息会阻塞,直到有 goroutine 向该 channel 中发送消息;同理,向无缓存的 channel 中发送消息也会阻塞,直到有 goroutine 从 channel 中读取消息。
example
c := make(chan int) // Allocate a channel.
// Start the sort in a goroutine; when it completes, signal on the channel.
go func() {
list.Sort()
c <- 1 // Send a signal; value does not matter.
}()
doSomethingForAWhile()
<-c
主goroutine定义一个无缓存的channel,然后开启一个新的goroutine执行排序任务,接着主goroutine继续向下执行doSomethingForAWhile,接着要从channel中取值,但是channel是空的,因此主goroutine阻塞。等到新goroutine排序完毕,向channel中写值后,主goroutine从channel中取到值,然后才能继续向下执行。
有缓存channel
有缓存的 channel 的声明方式为指定 make 函数的第二个参数,该参数为 channel 缓存的容量
ch := make(chan int, 10)
当缓存未满时,向 channel 中发送消息时不会阻塞,当缓存满时,发送操作将被阻塞,直到有其他 goroutine 从中读取消息
ch := make(chan int, 3) // blocked, read from empty buffered channel <- ch
相应的,当 channel 中消息不为空时,读取消息不会出现阻塞,当 channel 为空时,读取操作会造成阻塞,直到有 goroutine 向 channel 中写入消息。
ch := make(chan int, 3) ch <- 1 ch <- 2 ch <- 3 // blocked, send to full buffered channel ch <- 4
通过 len 函数可以获得 chan 中的元素个数,通过 cap 函数可以得到 channel 的缓存长度。
channel 也可以使用 range 取值,并且会一直从 channel 中读取数据,直到有 goroutine 对改 channel 执行 close 操作,循环才会结束。
// consumer worker
ch := make(chan int, 10)
for x := range ch{
fmt.Println(x)
}
等价于
for {
x, ok := <- ch
if !ok {
break
}
fmt.Println(x)
}
3、Go并发模型的底层实现原理
参考Golang CSP并发模型
无论在语言层面用的是何种并发模型,到了操作系统层面,一定是以线程的形态存在的。而操作系统根据资源访问权限的不同,体系架构可分为用户空间和内核空间。
- 内核空间主要操作访问CPU资源、I/O资源、内存资源等硬件资源,为上层应用程序提供最基本的基础资源。
- 用户空间就是上层应用程序的固定活动空间,用户空间不可以直接访问资源,必须通过“系统调用”、“库函数”或“Shell脚本”来调用内核空间提供的资源。
golang使用goroutine做为最小的执行单位,但是这个执行单位还是在用户空间,实际上最后被处理器执行的还是内核中的线程,用户线程和内核线程的调度方法有:
- 1:1,即一个内核线程对应一个用户级线程(并发度低,浪费cpu资源,上下文切换需要消耗额外的资源)。
- 1:N,即一个内核线程对应N个用户级线程(并发度高,但是只用一个内核线程,不能有效利用多核CPU)。
- M:N,即M个内核线程对应N个用户级线程(上述两种方式的折中,缺点是线程调度会复杂一些)
golang 通过为goroutine提供语言层面的调度器,来实现了高效率的M:N线程对应关系
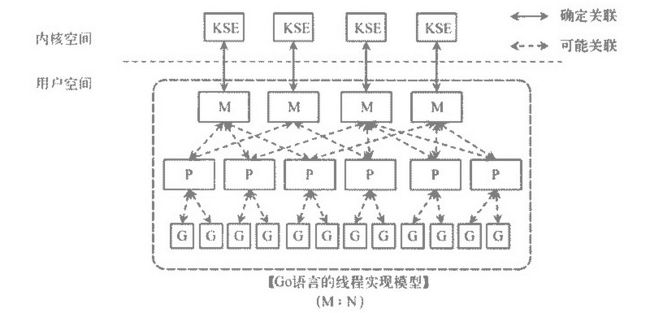

M:是内核线程
P : 是调度协调,用于协调M和G的执行,内核线程只有拿到了 P才能对goroutine继续调度执行,一般都是通过限定P的个数来控制golang的并发度
G : 是待执行的goroutine,包含这个goroutine的栈空间
Gn : 灰色背景的Gn 是已经挂起的goroutine,它们被添加到了执行队列中,然后需要等待网络IO的goroutine,当P通过 epoll查询到特定的fd的时候,会重新调度起对应的,正在挂起的goroutine。
Golang为了调度的公平性,在调度器加入了steal working 算法 ,在一个P自己的执行队列,处理完之后,它会先到全局的执行队列中偷G进行处理,如果没有的话,再会到其他P的执行队列中抢G来进行处理。
4、一个CSP例子
参考golang中的CSP并发模型
生产者-消费者Sample:
package main
import (
"fmt"
"time"
)
// 生产者
func Producer (queue chan<- int){
for i:= 0; i < 10; i++ {
queue <- i
}
}
// 消费者
func Consumer( queue <-chan int){
for i :=0; i < 10; i++{
v := <- queue
fmt.Println("receive:", v)
}
}
func main(){
queue := make(chan int, 1)
go Producer(queue)
go Consumer(queue)
time.Sleep(1e9) //让Producer与Consumer完成
}
生产者goroutine往channel传值,消费者goroutine往channel取值,这两个goroutine通过channel完成通信。
以上就是Go语言CSP并发模型goroutine channel底层实现原理的详细内容,更多关于go CSP并发模型goroutine channel的资料请关注脚本之家其它相关文章!