计算机视觉——单目相机标定
计算机视觉——单目相机标定
文章目录
- 计算机视觉——单目相机标定
-
- 前言
- OpenCV相机标定流程
-
- 1. 数据集
- 2. 角点提取
- 3. 内参外参求解
- 4. 误差评估
- 实验分析
前言
什么是相机标定:在计算机视觉应用中,为确定空间物体表面某点的三维几何位置与其在图像中对应点之间的相互关系,必须建立相机成像的几何模型,这些几何模型参数就是相机参数。相机参数可以分为内参和外参。求解内参和外参的过程称之为相机标定。其中内参包括焦距,像主点坐标,畸变参数。外参包括旋转和平移。
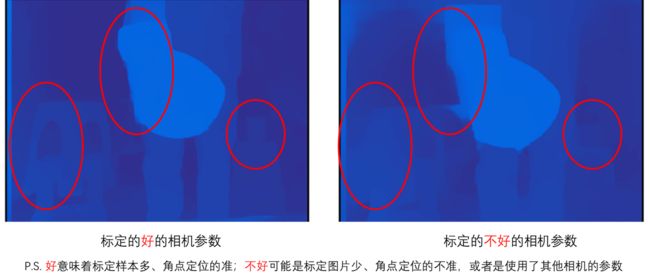
为什么要相机标定: 计算机视觉的基本任务之一是从摄像机获取的图像信息出发计算三维空间中物体的几何信息,并由此重建和识别物体,而空间物体表面某点的三维几何位置与其在图像中对应点之间的相互关系是由摄像机成像的几何模型决定的,这些几何模型参数就是摄像机参数。在大多数条件下,这些参数必须通过实验与计算才能得到。其标定结果的精度及算法的稳定性直接影响相机工作产生结果的准确性。说白了相机参数的准确性会影响算法的精度,如下图所示,当时同样的算法换了个镜头,但是效果差很多,最后检查原来是使用的是另一个相机的参数
本次实验代码可在OpenCV中文文档中找到详细过程,本次实验主要是想记录下镜头动和标定板动对标定结果的影响。
OpenCV相机标定流程
1. 数据集
手机型号:vivo S9
手机相机分辨率:3456×4608
标定板规格:GP340 12x9 25mm
第一组数据:固定镜头,动标定板:

第二组数据:固定标定板,动镜头:

2. 角点提取
下述阐述的详细步骤均由第一组数据,实验分析中会涉及到第二组数据的对比。
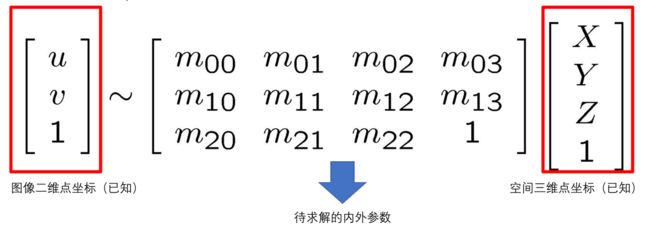
补充说明:整个标定过程的目的是利用已知的图像二维点坐标和空间中的三维点坐标来求解内外参数,如下图所示:
但是问题是怎么已知的?首先对于空间三维点坐标的已知:因为我们采用的是棋盘格,我所用棋盘格中的每个格子是25mm,所以我以棋盘格左上角点为世界坐标原点,然后就能知道每个角点的坐标,同时还消除了Z轴,代码如下所示:
cp_int = np.zeros((w * h, 3), np.float32)
cp_int[:, :2] = np.mgrid[0:w, 0:h].T.reshape(-1, 2)
array([[0. , 0. , 0. ],
[0.025 , 0. , 0. ],
[0.05 , 0. , 0. ],
[0.075 , 0. , 0. ],
[0.1 , 0. , 0. ],
[0.125 , 0. , 0. ],
[0.15 , 0. , 0. ],
[0.175 , 0. , 0. ],
[0.2 , 0. , 0. ],
[0.22500001, 0. , 0. ],
[0.25 , 0. , 0. ],
[0. , 0.025 , 0. ],
[0.025 , 0.025 , 0. ],
[0.05 , 0.025 , 0. ],
[0.075 , 0.025 , 0. ],
[0.1 , 0.025 , 0. ],
………………………………
那对于图像二维点坐标的已知,利用的就是角点检测,检测出了角点,就能知道角点所在第几行像素,在第几列像素,因此才需要做角点检测,具体代码如下:
for fname in tqdm(range(len(images))):
img = cv2.imread(img_dir+str(fname+1)+img_type)
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 内角数
ret, cp_img = cv2.findChessboardCorners(gray_img, (w, h), None)
# 找到角点坐标的情况
if ret == True:
# 使用亚像素更准
cp_img = cv2.cornerSubPix(gray_img, cp_img, (11,11), (-1,-1), criteria)
obj_points.append(cp_world)
# 每个角点在图像中的位置
img_points.append(cp_img)
# 可视化每个角点
cv2.drawChessboardCorners(img, (w, h), cp_img, ret)
cv2.imwrite(save_dir+str(fname+1)+img_type, img)
值得注意的是,可以使用cv2.cornerSubPix进行迭代定位亚像素角点,使得角点的定位更为精确。角点可视化结果:
同理,每个角点在图像中的坐标为:
array([[[ 875.23474, 1233.4252 ]],
[[1046.5013 , 1226.9655 ]],
[[1218.783 , 1220.3584 ]],
[[1391.0924 , 1214.2686 ]],
[[1562.6665 , 1206.5886 ]],
[[1736.0254 , 1199.1523 ]],
[[1908.2211 , 1192.0359 ]],
[[2082.2131 , 1184.3872 ]],
[[2256.5217 , 1175.4783 ]],
[[2431.4773 , 1167.0223 ]],
[[2606.6807 , 1158.4791 ]],
………………………………
3. 内参外参求解
角点检测完毕后,我们能得到一堆的角点坐标加上空间三维点坐标,接着便利用
cv2.calibrateCamera求解相机内外参数,代码如下:
# ret 非0表示标定成功 mat_inter 内参数矩阵,coff_dis 畸变系数,v_rot 旋转向量,v_trans 平移向量
ret, mat_inter, coff_dis, v_rot, v_trans = cv2.calibrateCamera(obj_points, img_points, gray_img.shape[::-1], None, None)
标定结果如下:
内参矩阵:
array([[3417.42140189, 0. , 1743.95204043],
[ 0. , 3417.97234961, 2286.22201502],
[ 0. , 0. , 1. ]])
畸变参数:
array([[ 0.09184773, -0.02872326, -0.00071117, -0.00038616, -0.71625435]])
旋转向量:
array([[ 0.17634509],
[ 0.02250387],
[-0.03713366]]),
array([[-0.23622293],
[ 0.02199793],
[-0.04436764]]),
…………………………
平移向量:
array([[-0.12609051],
[-0.152743 ],
[ 0.50174438]]),
array([[-0.12217209],
[-0.16182343],
[ 0.54338983]]),
……………………
4. 误差评估
我们可以使用OpenCV内置的cv2.projectPoints()直接计算重投影误差。
total_error = 0
# 给定内外参,将三维点投影为二维点。
# 然后算和真实像平面坐标的距离,计算平均误差
for i in range(len(obj_points)):
img_points_repro, _ = cv2.projectPoints(obj_points[i], v_rot[i], v_trans[i], mat_inter, coff_dis)
error = cv2.norm(img_points[i], img_points_repro, cv2.NORM_L2) / len(img_points_repro)
total_error += error
print(("Average Error of Reproject: "), total_error / len(obj_points))
Average Error of Reproject: 0.0410115862612222
误差越小意味着标定的参数更加准确。
实验分析
第一组数据与第二组数据内参比较:
# 动棋盘格
array([[3417.42140189, 0. , 1743.95204043],
[ 0. , 3417.97234961, 2286.22201502],
[ 0. , 0. , 1. ]])
# 动相机
array([[3457.63519185, 0. , 1753.27275535],
[ 0. , 3457.89708088, 2280.41687031],
[ 0. , 0. , 1. ]])
实验分析:首先这是很常见的两种标定方式,一种动相机,一种动棋盘格,理论上没有任何区别。但是实验结果存在偏差,原因可能是动相机在实践中会存在轻微的移动模糊,镜头抖动之类的问题,所以导致最后存在误差,所以在工程中做标定一般是推荐动棋盘格。而且标定是一个优化过程,不同次的采样也会有不一样的结果。但是对于上述可验证的参数:
手机分辨率为:3456×4608,真实的像主点坐标为1728,2304
第一组数据的 u c u_{c} uc = 1744(+16), v c v_{c} vc = 2286(-18)
第二组数据的 u c u_{c} uc = 1753(+25), v c v_{c} vc = 2280(-24)
第一组数据用OpenCV标定法和Matlab标定法内参对比:
标定过程中可以使用OpenCV标定,同时可用Matlab中的工具箱进行标定,标定过程大致如下:

同样用第一组数据进行标定,得到的内参对比如下:
# OpenCv
array([[3417.42140189, 0. , 1743.95204043],
[ 0. , 3417.97234961, 2286.22201502],
[ 0. , 0. , 1. ]])
# Matlab
array([[3413.63519185, 0. , 1740.37275535],
[ 0. , 3414.79708088, 2290.11687031],
[ 0. , 0. , 1. ]])
实验分析:一般可以认为,Matlab内置算法的标定结果更为精确,因此,我们可以再通过Matlab标定得到一组参数,来验证我们的参数是否靠谱。结果表明,是有一定的误差但也不至于太离谱,至少可以认为结果是相对可靠的。一般现在工程项目中,使用Matlab工具标定的多。
手机分辨率为:3456×4608,真实的像主点坐标为1728,2304
OpenCV标定结果的 u c u_{c} uc = 1744(+16), v c v_{c} vc = 2286(-18)
Matlab标定结果的 u c u_{c} uc = 1740(+12), v c v_{c} vc = 2290(-14)
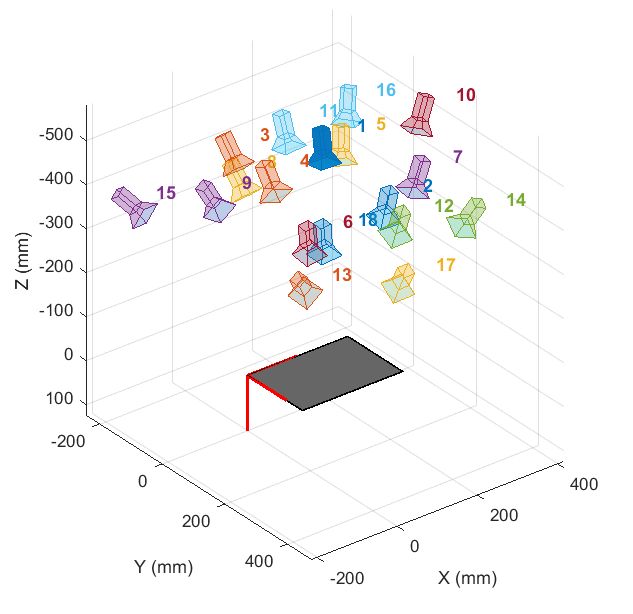
可视化棋盘格位姿+相机位姿
可视化棋盘格位姿的核心思路就是将世界坐标系下的棋盘坐标通过外参矩阵(旋转+平移)的逆变换转换到相机坐标系

可视化相机位姿的核心就是将相机坐标系下的相机坐标通过外参矩阵(旋转+平移)转换到世界坐标系: