DeepLearing—CV系列(十八)——图像分割之U-Net的Pytorch实现
文章目录
- 一、nets.py
- 二、Mydataset.py
- 三、Train.py
一、nets.py
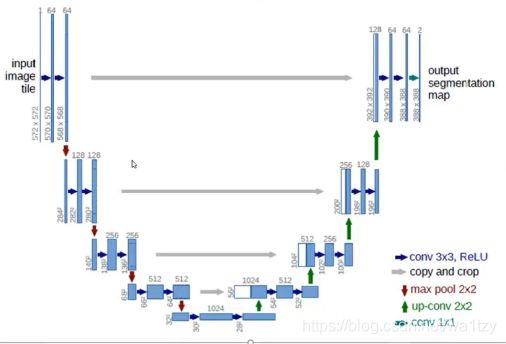
import torch
from torch.nn import functional as F
class CNNLayer(torch.nn.Module):
def __init__(self, C_in, C_out):
super(CNNLayer, self).__init__()
self.layer = torch.nn.Sequential(
torch.nn.Conv2d(C_in, C_out, 3, 1, 1),
torch.nn.BatchNorm2d(C_out),
torch.nn.Dropout(0.3),
torch.nn.LeakyReLU(),
torch.nn.Conv2d(C_out, C_out, 3, 1, 1),
torch.nn.BatchNorm2d(C_out),
torch.nn.Dropout(0.4),
torch.nn.LeakyReLU()
)
def forward(self, x):
return self.layer(x)
class DownSampling(torch.nn.Module):
def __init__(self, C):
super(DownSampling, self).__init__()
self.layer = torch.nn.Sequential(
torch.nn.Conv2d(C, C, 3, 2, 1),
torch.nn.LeakyReLU()
)
def forward(self, x):
return self.layer(x)
class UpSampling(torch.nn.Module):
def __init__(self, C):
super(UpSampling, self).__init__()
self.C = torch.nn.Conv2d(C, C // 2, 1, 1)
def forward(self, x, r):
up = F.interpolate(x, scale_factor=2, mode='nearest')
x = self.C(up)
return torch.cat((x, r), 1)
class MainNet(torch.nn.Module):
def __init__(self):
super(MainNet, self).__init__()
self.C1 = CNNLayer(3, 64)
self.D1 = DownSampling(64)
self.C2 = CNNLayer(64, 128)
self.D2 = DownSampling(128)
self.C3 = CNNLayer(128, 256)
self.D3 = DownSampling(256)
self.C4 = CNNLayer(256, 512)
self.D4 = DownSampling(512)
self.C5 = CNNLayer(512, 1024)
self.U1 = UpSampling(1024)
self.C6 = CNNLayer(1024, 512)
self.U2 = UpSampling(512)
self.C7 = CNNLayer(512, 256)
self.U3 = UpSampling(256)
self.C8 = CNNLayer(256, 128)
self.U4 = UpSampling(128)
self.C9 = CNNLayer(128, 64)
self.pre = torch.nn.Conv2d(64, 3, 3, 1, 1)
self.Th = torch.nn.Sigmoid()
def forward(self, x):
R1 = self.C1(x)
R2 = self.C2(self.D1(R1))
R3 = self.C3(self.D2(R2))
R4 = self.C4(self.D3(R3))
Y1 = self.C5(self.D4(R4))
O1 = self.C6(self.U1(Y1, R4))
O2 = self.C7(self.U2(O1, R3))
O3 = self.C8(self.U3(O2, R2))
O4 = self.C9(self.U4(O3, R1))
return self.Th(self.pre(O4))
if __name__ == '__main__':
a = torch.randn(2, 3, 256, 256).cuda()
net = MainNet().cuda()
print(net(a).shape)
二、Mydataset.py
本项目是在VOC数据集上进行操作的,我们的数据集依据其来构建。
import torch
from PIL import Image
import os
from torchvision import transforms
from torchvision.utils import save_image
import torch.utils.data as data
transform = transforms.Compose([
transforms.ToTensor()
])
class MyDataset(data.Dataset):
def __init__(self,path):
self.path = path
self.dataset = os.listdir(os.path.join(path,"SegmentationClass"))
def __len__(self):
return len(self.dataset)
def __getitem__(self, item):
black1 = transforms.ToPILImage()(torch.zeros(3,256,256))# 黑图做背景
black0 = transforms.ToPILImage()(torch.zeros(3,256,256))
name = self.dataset[item]
namejpg = name[:-3]+"jpg"# 标签是png,数据是jpg,这里取数据
img1_path = os.path.join(self.path,"JPEGImages")
img0_path = os.path.join(self.path,"SegmentationClass")
img1 = Image.open(os.path.join(img1_path, namejpg)) #(标签少2913个,数据多17125)
img0 = Image.open(os.path.join(img0_path, name))# 这样我们取到就都是标签对应的数据了
img1_size = torch.Tensor(img1.size) # WH
l_max_index = img1_size.argmax()
ratio = 256/img1_size[l_max_index.item()]
img1_re2size = img1_size * ratio
img1_use = img1.resize(img1_re2size)
img0_use = img0.resize(img1_re2size)
w, h = img1_re2size.tolist()
black1.paste(img1_use, (0, 0, int(w), int(h)))
black0.paste(img0_use, (0, 0, int(w), int(h)))
return transform(black1) , transform(black0)
if __name__ == '__main__':
i = 1
dataset = MyDataset(r"F:\数据集\VOC数据集\VOCdevkit\VOC2012")
for a, b in dataset:
print(i)
print(a.shape)
print(b.shape)
save_image(a,"./img/{0}.jpg".format(i),nrow=1)
save_image(b,"./img/{0}.png".format(i),nrow=1)
i+=1
三、Train.py
import torch
from torch import nn
from torch.utils import data
from torchvision import transforms
import os
import nets
import Mydataset
from torchvision.utils import save_image
class Trainer:
def __init__(self):
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.net = nets.MainNet().to(self.device)
self.optimizer = torch.optim.Adam(self.net.parameters())
self.loss_func = nn.BCELoss()
def train(self):
path = r"F:\数据集\VOC数据集\VOCdevkit\VOC2012"
model_save_path = r"models/unet.pth"
img_save_path = r"train_img/"
dataset = Mydataset.MyDataset(path)
dataloader = data.DataLoader(dataset,batch_size=4, shuffle=True)
epochs = 1
if os.path.exists(model_save_path):
self.net.load_state_dict(torch.load(model_save_path))
else:
print('No Params!')
if not os.path.exists(img_save_path):
os.mkdir(img_save_path)
if not os.path.exists("models"):
os.mkdir("models")
while True:
for i ,(xs,ys) in enumerate(dataloader):
xs = xs.to(self.device)
ys = ys.to(self.device)
xs_ = self.net(xs)
loss = self.loss_func(xs_,ys)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
if i % 5 == 0:
print('epoch: {}, iteration: {}-{}, loss: {}'.format(epochs, i,len(dataloader), loss))
torch.save(self.net.state_dict(), model_save_path)
print('module is saved !')
x = xs[0]
x_ = xs_[0]
y = ys[0]
# print(y.shape)
img = torch.stack([x, x_, y], 0)
# print(img.shape)
save_image(img.cpu(), os.path.join(img_save_path, '{}.png'.format(i)))
print("saved successfully !")
epochs += 1
if __name__ == '__main__':
t = Trainer()
t.train()