一文快速掌握Python基础语法
这是机器未来的第6篇文章
写在前面:
博客简介:专注AIoT领域,追逐未来时代的脉搏,记录路途中的技术成长!
专栏简介:本专栏的核心就是:快!快!快!2周快速拿下Python,具备项目开发能力,为机器学习和深度学习做准备。
面向人群:零基础编程爱好者
专栏计划:接下来会逐步发布跨入人工智能的系列博文,敬请期待
Python零基础快速入门系列
快速入门Python数据科学系列
人工智能开发环境搭建系列
机器学习系列
物体检测快速入门系列
自动驾驶物体检测系列
…
文章目录
- 1\. Python概述
- 2\. Python版Hello World
- 3. 变量与常量
-
- 3.1. 变量的定义
-
- 3.1.1 变量的构成
- 3.1.2 变量的命名规范
-
- 3.1.2.1 举例:数字,字母,下划线,并且不可以数字开头
- 3.1.2.2 举例:不能使用关键字
- 3.1.2.3 举例:区分大小写
- 3.1.3 编码规范
- 3.2 常量
- 4\. 输入与输出
-
- 4.1 输出print
- 图片 4.2 格式化输出
- 4.3 输入input
- 4.4. python对象的三板斧
- 5. 注释规则
- 6. 基础数据类型
-
- 6.1. 数值类型
-
- 6.1.1 整数类型
-
- 6.1.1.1 整数有四种进制类型
- 6.1.1.2 进制转换
- 6.1.2 浮点类型
- 6.1.3 复数类型
- 6.1.4 布尔类型
-
- 6.1.4.1 常见的逻辑表达式
- 6.1.5 空值类型
- 6.2. 字符串
-
- 6.2.1 创建
- 6.3 容器类型
- 7\. 运算符
-
- 7.1 算术运算符
- 7.2 比较运算符
- 7.4 位运算符
- 7.5 逻辑运算符
- 7.6 成员运算符
- 7.7 身份运算符
- 8\. 控制语句
-
- 8.1 分支语句(条件语句)
- 8.2 循环语句
-
- 8.2.1 while循环
- 8.2.1 while循环典型结构
- 8.2.2 while的特殊用法
- 8.2.2 for循环
- 8.2.3 break与continue:循环的跳出和继续执行
1. Python概述
Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。
-
可以干什么?
-
数据分析、WEB开发、爬虫、人工智能、科学计算、桌面软件等…
-
胶水语言
-
可以调用其他语言库, 适合搭框架,不适合构建核心
-
解释型语言
-
无需编译,边解释边执行,适合数据分析,不适合开发大型项目,运行效率低
-
语法简洁,代码量小
-
动态类型语言,代码量小
-
内存管理:有垃圾回收。代码量小
-
开源,好处:库丰富,出现问题有社区帮助解决或者遇到过。坏处:库不一定成熟或者经过生产环境测试,bug多
-
跨平台
Python最核心的优势就是:它是一个拉皮条的,自己不干活(不具体实现,搭框架),让别人干活(Python调用其它语言的实现库)。

2. Python版Hello World
-
启动vs code 在工作区目录(用于存储编程学习文档的目录)下右键,选择【通过VsCode打开】启动VsCode。
-
启动后,在左侧文件栏,右键新建文件,输入文件名note.ipynb,双击打开
-
在右侧的单元格内输入第一行python代码
print("hello world!"),点击左侧的三角按钮或按下【CTRL+ENTER】组合键,就会看到输出hello world。首次运行会有点慢,后续速度就很快了。
3. 变量与常量
-
变量、常量的区别
-
变量:在程序运行过程中,值会发生变化的量。
-
常量:在程序运行过程中,值不会发生变化的量。
3.1. 变量的定义
3.1.1 变量的构成
变量由变量名、变量值和变量类型构成。需要注意的是python中定义变量时不需要声明类型。这是根据Python的动态语言特性而来。变量可以直接使用,而不需要提前声明类型。
-
变量名类似于一个代号,指向具体的变量值。

-
多个变量名可以绑定一个变量值。
a = 'Jack'
b = a
a = 'Tom'
print(b)
print(a)


请牢记:Python中的一切都是对象,变量是对象的引用!
3.1.2 变量的命名规范
标识符的命名规范:
-
数字,字母,下划线,并且不可以数字开头
-
不能使用关键字
-
区分大小写
3.1.2.1 举例:数字,字母,下划线,并且不可以数字开头
-
例子1以数字开头,提示语法错误;
-
例子2、例子3以小写字母、下划线和数字构成,执行语法正确
-
例子4以大小写字母、下划线和数字构成,和name_2是不一样的变量,因此打印输出不一样。

3.1.2.2 举例:不能使用关键字
输入下列2行代码,可以查看Python的关键字列表,这些都不可以作为变量名使用。
import keyword
keyword.kwlist

3.1.2.3 举例:区分大小写
变量大写X和小写x是不同的变量
3.1.3 编码规范
-
变量,函数名称:小写,如果需要分割用下划线
-
常量:全大写
-
类名:大驼峰
扩展阅读:Python 编码规范(Google)
3.2 常量
Python中其实没有专门对常量的定义,对于常值一般采用全部大写的字母来定义,例如
PI = 3.14
4. 输入与输出
4.1 输出print
print("hello python")

4.2 格式化输出
本文均以python3为基础。
三种方式
name = "Joe"
sex = "man"
# 方法一,使用format格式化函数来实现
print("My name is {}, my sex is {}".format(name, sex) )
或
print("My name is {0}, my sex is {1}".format(name, sex) )
# 方法二:format的简写形式
print(f"My name is {name}, my sex is {sex}")
# 方法三:逗号分隔,这种方式输出格式会凌乱一些,推荐方法二
print(f"My name is “, {name}, "my sex is ", sex)
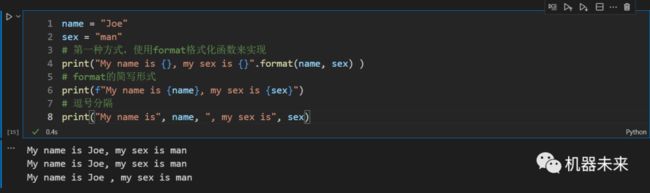
4.3 输入input
input的输入参数是提示字符串,返回值为输入的信息:
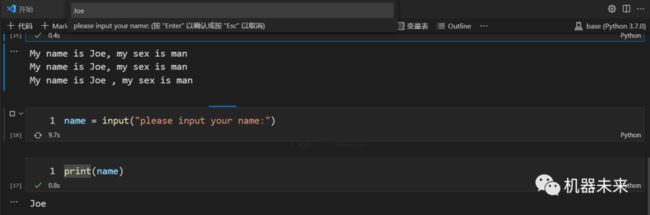
4.4. python对象的三板斧
-
print print打印对象的内容
-
type type输出对象的类型
-
dir dir输出对象支持的方法和属性

5. 注释规则
注释用于描述代码段的功能及使用说明之用。
Python的注释有2种:
- 井号注释# #注释常用来给代码行或代码块进行注释说明,常出现在代码上方或末尾
# 单行注释
print("#注释")
- 三引号注释 三引号注释常用来给函数或类做注释使用,因为涉及到多行。
三引号注释可分为单引号注释和双引号注释
def data_analyze(dat):
"""
函数描述:用于数据分析
参数描述:
- dat:输入的参数
"""
return
def data-analyze2(dat):
'''
函数描述:用于数据分析
参数描述:
- dat:输入的参数
'''
return
以上2个函数的注释功能上是一样的,单引号或双引号其本质上是一个字符串常量。
#注释和三引号注释总体区分就是单行注释归#,多行注释归三引号注释。
6. 基础数据类型
Python中的基础数据类型包括:
-
数值类型:整数类型,浮点类型,复数类型,布尔类型、空值
-
字符串
-
容器类型:列表,元组,字典,集合
6.1. 数值类型
6.1.1 整数类型
常见的整数
a = 101
6.1.1.1 整数有四种进制类型
- 二进制:定义需要使用0b或者0B作为前缀,每位取值范围0~1
x1 = 0b0001 # 十进制1
x2 = 0b1010 # 十进制10 = 1*2^3 + 0*2^2 + 1*2^1 + 0 = 10
print(x1, type(x1), x2, type(x2))
1
10
- 八进制:定义需要使用0o或者0O作为前缀,每位取值范围0~7
x1 = 0o17 # 十进制15 = 1*8 + 7 = 15
print(x1, type(x1))
15
- 十进制:默认定义的是十进制
x1 = 15
print(x1, type(x1))
15
- 十六进制:定义需要使用0x或者0X作为前缀,每位取值范围0~9 a/A-f/F
x1 = 0x59 # 十进制89 = 5*16 + 9 = 89
print(x1, type(x1))
89
6.1.1.2 进制转换
- bin(x):将x转换成二进制,返回值是str
x = 15
x2 = bin(x)
print(x2, type(x2))
0b1111
- oct(x):将x转换成八进制,返回值是str
x = 15
oct(x)
print(x2, type(x2))
0b1111
- int(x):将x转换成十进制,返回值是int,可以将字符串类型的整数转换成int类型
x = 0x0f
x2 = int(x)
print(x2, type(x2))
15
- hex(x):将x转换成十六进制,返回值是str
x = 15
x2 = hex(x)
print(x2, type(x2))
0xf
6.1.2 浮点类型
浮点类型是数学中的小数,浮点数在计算机中只能做到近似存储,这是浮点的不确定性。
f1 = 1.2
f2 = 1.4
f3 = f1 + f2
print(f3)
f3 == 2.6 # f3竟然不等于2.6,神奇吧
2.5999999999999996
False
从图中示例可知,在计算机中1.2+1.4不一定等于2.6,因为计算机中存储数据底层都是二进制存储,在转换过程中存在转换误差,因此避免使用浮点数做等值或不等值运算,如果必须使用,则使用如下函数形式。
import math
def is_float_equal(a, b, precision): # 第三个参数为精度
'''
a - 输入比较的浮点数1
b - 输入比较的浮点数2
precision - 可允许的浮点数误差
'''
return math.fabs(a - b) < precision
result = is_float_equal(f3, 2.6, 1e-3)
print(result)
True
float数据类型可表示的数据范围:
import sys
print(sys.float_info.max, sys.float_info.min)
1.7976931348623157e+308 2.2250738585072014e-308
超出浮点数表示范围上限,数据会表示为inf,低于浮点数表示范围下限,则直接表示为0.0
print(2.3e+400, 2.3e-400)
inf 0.0

6.1.3 复数类型
x1 = 3 + 4j
print(x1, type(x1))
(3+4j)
x1.real, x1.imag # 访问复数的实部和虚部
(3.0, 4.0)
#求复数的模长
abs(x1) # c = sqrt(a^2 + b^2)
5.0
6.1.4 布尔类型
布尔类型:True 和 False
6.1.4.1 常见的逻辑表达式
- and 与 两个为真才为真,一个为假则为假
True and True
True
True and False
False
False and False
False
- or 或 一个为真则为真,两个为假则为假
True or True # 两个均为真,则为真
True
True or False # 一个为真,则为真
True
False or False # 两个为假,则为假
False
- not 非 非假为真,非真为假
not False
True
not True
False
6.1.5 空值类型
None
6.2. 字符串
6.2.1 创建
- 字符串有三种创建方式:单引号、双引号、三引号
x1 = 'python'
x2 = "python"
x3 = """python"""
x4 = '''python'''
print(f"x1:{x1}, x2:{x2}, x3:{x3}, x4:{x4}")

-
其中三引号还有定义格式的能力,举例

-
字符串定义时,单引号、双引号出现在内容中的用法:

-
使用转义字符\
-
错位使用:内容包含单引号时,使用双引号定义;内容包含双引号时,使用单引号定义
6.3 容器类型
容器类型将在数据结构中描述。
7. 运算符
7.1 算术运算符
+(加)、 -(减)、 *(乘)、 /(除)、//(除法取整)、%(取模)等。
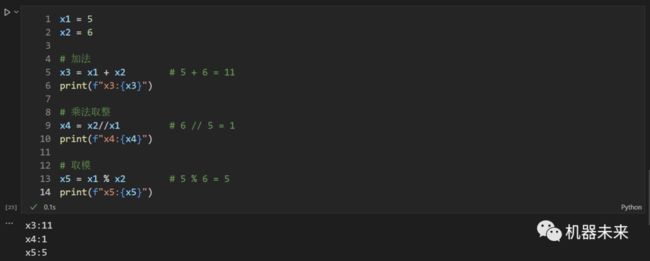
7.2 比较运算符
>(大于)、 <(小于)、==(等于)、 <=(小于等于), >=(大于等于), !=(不等于)等

7.3 赋值运算符=(赋值)、 +=(加法赋值)、-=(减法赋值)、*=(乘法赋值)、/=(除法赋值)、//=(除法取整赋值)、%=(取模赋值)等
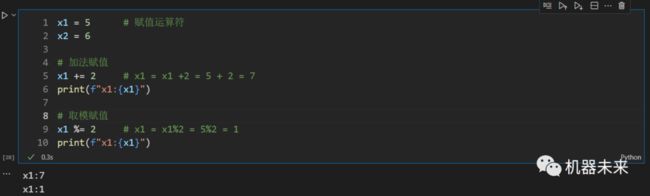
7.4 位运算符
- 与(&),按位与运算符:参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0
x1 = 0b0001
x2 = 0b0001
x3 = 0b0010
# 与运算&:对应位均为1,则为1;否则为0
x4 = x1 & x2
print(f"x4:{bin(x4)}")

- 或(|),按位或运算符:只要对应的两个二进位有一个为1时,结果位就为1
x1 = 0b0001
x2 = 0b0001
x3 = 0b0010
# 或运算|:对应位均为0,则为0;否则为1
x5 = x2 | x3
print(f"x5:{bin(x5)}")

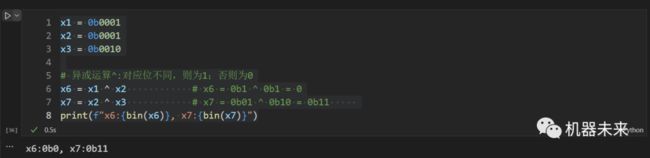
- 异或(^),按位异或运算符:当两对应的二进位相异时,结果为1
x1 = 0b0001
x2 = 0b0001
x3 = 0b0010
# 异或运算^:对应位不同,则为1;否则为0
x6 = x1 ^ x2 # x6 = 0b1 ^ 0b1 = 0
x7 = x2 ^ x3 # x7 = 0b01 ^ 0b10 = 0b11
print(f"x6:{bin(x6)}, x7:{bin(x7)}")
- 取反(~),按位取反运算符:对数据的每个二进制位取反,即把1变为0,把0变为1
x1 = 0b0001
# 异或运算^:对应位不同,则为1;否则为0
x4 = ~x1 # x4 = ~0b1= 0b1111110(补码表示:最高位为1,为负数,负数取反+1) = -0b10
print(f"x4:{bin(x4)}")

- 左位移(<<),运算数的各二进位全部左移若干位,由<<右边的数字指定了移动的位数,高位溢出舍弃,低位补0
x1 = 0b0001
# 异或运算^:对应位不同,则为1;否则为0
x4 = x1<<1 # x4 = 0b1 << 1 = 0b10
print(f"x4:{bin(x4)}")

- 右位移(>>),把‘>>’左边的运算数的各二进制位全部右移若干位,>>右边的数字指定了移动的位数,低位溢出舍弃,高位补
x1 = 0b1110
# 异或运算^:对应位不同,则为1;否则为0
x4 = x1>>1 # x4 = 0b1110 >> 1 = 0b111
print(f"x4:{bin(x4)}")

7.5 逻辑运算符
and布尔与、or布尔或、not布尔非
- and:表达式:x and y,即布尔的“与”,如果 x 或 y 任意一个值为 False,则返回为False的值,否则返回 y 的值。
x1 = 5
x2 = 6
x3 = 7
# x1 > x2 => 5 > 6为False,所以整个表达式为False
x4 = x1 > x2 and x3 > x2
print(f"x4:{x4}")
# x2 > x1 and x3 > x2 => 6 > 5 and 7 > 6,
# 第一个表达式的值为True,所以返回第二个表达式的值,第二个表达式的值为True
x5 = x2 > x1 and x3 > x2
print(f"x5:{x5}")
# x2 > x1 and 2 => 6 > 5 and 2,
# 第一个表达式的值为True,所以返回第二个表达式的值,第二个表达式的值为2
x6 = x2 > x1 and 2
print(f"x6:{x6}")

- or:表达式:x or y,即布尔的“或”,如果 x 或 y 任意一个值为 True,则返回为True的值,否则返回 x 的值。
x1 = 5
x2 = 6
x3 = 7
# x2 > x1 or x2 > x3 => 6 > 5 and 6 > 7
# 第一个表达式的值为True,所以返回True
x5 = x2 > x1 or x2 > x3
print(f"x5:{x5}")
# x1 > x2 or x2 > x3 => 5 > 6 or 6 > 7, 两个表达式均为False,所以整个表达式为False
x4 = x1 > x2 or x2 > x3
print(f"x4:{x4}")
# x1 > x2 or 0 => 5 > 6 or 0,
# 第一个表达式的值为False,所以返回第二个表达式的值,第二个表达式的值为0
x6 = x1 > x2 or 0 # 非0均为True
print(f"x6:{x6}") # 注意不是返回False喔

37
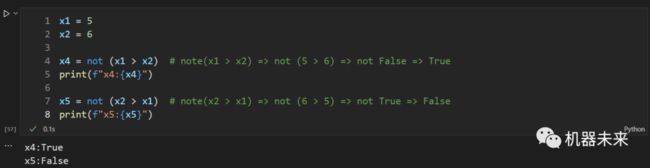
- not:表达式:not x,即布尔的“非”,如果 x 值为 True,则返回为False,否则返回True。
x1 = 5
x2 = 6
x4 = not (x1 > x2) # note(x1 > x2) => not (5 > 6) => not False => True
print(f"x4:{x4}")
x5 = not (x2 > x1) # note(x2 > x1) => not (6 > 5) => not True => False
print(f"x5:{x5}")
38
7.6 成员运算符
-
in:判断指定对象是否在序列中找到,是返回True,否返回False
-
not in:与in相反,判断指定对象是否不在序列中找到,是返回True,否返回False。
x = [1, 2, 4, 5, 8]
x1 = 5
x2 = 6
x3 = x1 in x # x1 = 5, 是列表x中的元素,所以为真,True
print(f"x3:{x3}")
x4 = x2 not in x # x2 = 6, 不是列表x中的元素,为假,not假,所以为真,True
print(f"x4:{x4}")

39
7.7 身份运算符
-
is:判断指定对象是否引用自同一对象,即是否具有相同的id地址,是返回True,否返回False。
-
is not:与is相反,判断指定对象是否引用自不同的对象,即是否具有不同的id地址,是返回True,否返回False。

备注:其实is或is not 与 == 或 != 类似,区别在于:is或is not判断的是指定对象id地址是否相等,而== 或 !=判断的是指定对象的值是否相等。
8. 控制语句
流程控制有三种结构:顺序结构、分支结构、循环结构。
-
顺序结构:按部就班执行
-
分支结构:根据条件不同执行
-
循环结构:重复执行
8.1 分支语句(条件语句)
两种分支结构:
- 二分支
if condition1:
statement1
else:
statement2
举例:
score = 85
if score >= 60.0:
print("你的成绩:及格")
else:
print("你的成绩:不及格")

简写:三元运算符
exp1 if condition else exp2
对应
if condition:
exp1
else:
exp2
举例:
# 求最大值
x1 = 50
x2 = 30
max_num = x1 if x1>x2 else x2
max_num

snipaste20220523_001136
- 多分支
if condition1:
statement1
elif condition2:
statement2
...
else:
statement3
举例:
score = 85
if score >= 90.0:
print("你的绩效为:A")
elif score >= 80.0:
print("你的绩效为:B+")
elif score >= 60.0:
print("你的绩效为:B")
else:
print("你的绩效为:C")

注:python3.10以下版本不支持switch-case语句。
8.2 循环语句
两种循环语句:while和for循环
8.2.1 while循环
- 适用场景 不清楚循环的具体次数,或者当条件一直为真的时候一般用while
8.2.1 while循环典型结构
while cycle_condition:
statement
condition_change_statement
-
while表达式以冒号作为行的结束
-
while循环体代码块缩进4个字节
举例:
# 以神经网络模型的训练迭代次数举例
MAX_EPOCHS_COUNT = 10
epoch = 0
while epoch < MAX_EPOCHS_COUNT:
print(f"train times {epoch}")
epoch += 1
print("train finish!")

image-20220523001217473
8.2.2 while的特殊用法
while…else…语句,在while退出时执行
while cycle_condition:
statement
condition_change_statement
else:
exit_statement
举例:
# 以神经网络模型的训练迭代次数举例
MAX_EPOCHS_COUNT = 10
epoch = 0
while epoch < MAX_EPOCHS_COUNT:
print(f"train times {epoch}")
epoch += 1
else:
print("train finish!")

image-20220523001228174
8.2.2 for循环
-
使用场景:遍历序列中的元素或已知循环次数
-
典型结构for … in …
for item in sets:
statement
举例:
x = [-1, 4, 6, 7, 9, -10, -13]
for i in x:
print(i)

image-20220523001741324
-
range可迭代对象 range(start,end,step):返回的是一个可迭代对象可迭代对象的优势是占用内存少,边使用边分配内存,不会一下子全部分配内存,在数据集较大时会特别便于使用。
-
start:表示开始,包含,默认是0
-
end:表示结束,不包含
-
step:表示步长,默认是1
X = range(1, 10, 1)
print(type(X))
for x in range(1, 10, 1):
print(x, end=', ')
print("")
1, 2, 3, 4, 5, 6, 7, 8, 9,
- enumerate()索引序列 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
适用场景:在需要提取数据结构对象索引的时候非常有用。
x = [-1, 4, 6, 7, 9, -10, -13]
# 原始列表输出
for i in x:
print(i, end=', ')
print("")
# 将原始列表的输出转换为索引-值的元组
for i in enumerate(x):
print(i, end=', ')
print("")
-1, 4, 6, 7, 9, -10, -13, (0, -1), (1, 4), (2, 6), (3, 7), (4, 9), (5, -10), (6, -13),
8.2.3 break与continue:循环的跳出和继续执行
- break 退出循环,使用场合:在某些条件满足后跳出循环
# 以神经网络模型的训练迭代次数举例
MAX_EPOCHS_COUNT = 10
epoch = 0
while True:
if (epoch >= MAX_EPOCHS_COUNT):
break # 执行后,从此处跳出循环
print(f"train times {epoch}")
epoch += 1

- continue 跳过循环体后面的语句,直接开始下一回循环
# 求列表中大于0的数值的和
x = [-1, 4, 6, 7, 9, -10, -13]
sum = 0
for item in x:
if item < 0:
continue # 执行continue后,本次循环,后面的代码块不再执行
sum += item
print(f"sum: {sum}")
《Python零基础快速入门系列》快速导航:
- Python快速入门系列(1) 人工智能序章:开发环境搭建Anaconda+VsCode+JupyterNotebook(零基础启动)
- Python快速入门系列(2)一文快速掌握Python基础语法
推荐阅读:
- 物体检测快速入门系列(1)-Windows部署GPU深度学习开发环境
- 物体检测快速入门系列(2)-Windows部署Docker GPU深度学习开发环境
- 物体检测快速入门系列(3)-TensorFlow 2.x Object Detection API快速安装手册
- 物体检测快速入门系列(4)-基于Tensorflow2.x Object Detection API构建自定义物体检测器
