前后端分离项目知识汇总(阿里云Oss,EasyExcel,视频点播,SpringCloud,Redis,Nuxt)
整合篇一
-
- 整合CRUD
-
- 前后端对接流程
-
- 添加路由
- 点击路由显示页面
- 在api文件夹创建js文件,定义接口地址和参数
- 创建vue页面引入js文件,调用方法实现功能
- 多条件查询
- 删除功能
- 增加功能
- 修改功能
-
- 修改是用put请求还是post请求?
- 整合阿里云OSS
-
- 环境部署
- Java操作OSS
- nginx反向代理
- EasyExcel
-
- 简介
- 写入测试
- 读取测试
- 整合课程分类
-
- 实现思路
- 表格数据导入数据库
- 树状图显示数据
- 树形数据与懒加载
- 整合课程发布
-
- 实现思路
- 课程基本信息
-
- 实现效果
- 后端编码
- 前端编码
- 数据回显
- 课程大纲
-
- 实现效果
- 后端编码
- 前端编码
- 课程最终发布
-
- 实现效果
- 后端编码
- 前端编码
- 整合视频点播
-
- 简介
-
- 功能介绍
- 基本使用
- 上传视频
- 获取视频播放地址
- 整合
-
- 后端编码
- 前端编码
- 整合SpringCloud
-
- 微服务简介
- Nacos
- 服务注册
- 服务调用-Feign
-
- Web Service
- 后端编码
- 前端编码
- 服务熔断-Hystrix
-
- Hystrix(豪猪哥)
- feign结合Hystrix使用
- 整合NUXT
-
- 什么是NUXT?
- 安装NUXT
- 幻灯片插件
- 页面布局
- 路由
- 封装axios
- 整合Redis
-
- 树状图整合
- banner整合
- 注意点
整合CRUD
前后端对接流程
我们这里拿查询所有user做实例
全栈开发流程



添加路由
模板中给的其实也有目录,我们看着复制粘贴根据自己的需求改改即可

点击路由显示页面
redirect:'/teacher/table’作用是当访问/teacher时会自动跳到/teacher/table
component是做布局的,就是页面做固定不动的部分

在api文件夹创建js文件,定义接口地址和参数

创建vue页面引入js文件,调用方法实现功能
我们先来了解一下response对象
以下是response对象的属性和方法
所以说,response就是代表接口返回的数据


在看我们后端定义的接口

这里的scope.row是获取行数据是固定写法

这样功能就实现了

补充下分页条实现方式
分页条
直接拿element-ui里面的来用就可以
因为我分页条和表单在同一页面,所以写在同一组件下

多条件查询
直接拿element-ui里面的来用就可以
因为我分页条和表单在同一页面,所以写在同一组件下
主要是js对象和java对象的问题,注意区分即可
其余的也是直接用element-ui组件直接拿过来改改数据

有了查询对象之后把查询对象传入我们写的获取讲师列表即可
我们在查询按钮绑定方法

测试

删除功能

增加功能

3、定义增加API

4、引入js,写vue页面

5、测试

6、补充

修改功能
我们想让增加和修改在同一页面下进行
增加和修改不同点在于,修改要做数据回显
那么如何区分这两个请求呢?
答案是修改的时候地址栏会有id,而保存没有
定义Api、定义路由、定义跳转路径

修改功能逻辑
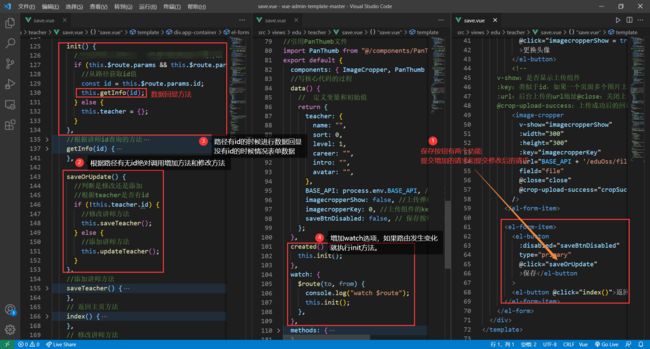
测试

修改成功

修改是用put请求还是post请求?
idempotent 幂等的
这两个方法看起来都是讲一个资源附加到服务器端的请求,但其实是不一样的。一些狭窄的意见认为,POST方法用来创建资源,而PUT方法则用来更新资源。
幂等(idempotent、idempotence)是一个抽象代数的概念。在计算机中,可以这么理解,一个幂等操作的特点就是其任意多次执行所产生的影响均与依次一次执行的影响相同。
POST在请求的时候,服务器会每次都创建一个文件,但是在PUT方法的时候只是简单地更新,而不是去重新创建。因此PUT是幂等的。
举一个简单的例子,假如有一个博客系统提供一个Web API,模式是这样http://superblogging/blogs/post/{blog-name},很简单,将{blog-name}替换为我们的blog名字,往这个URI发送一个HTTP PUT或者POST请求,HTTP的body部分就是博文,这是一个很简单的REST API例子。我们应该用PUT方法还是POST方法?取决于这个REST服务的行为是否是idempotent的,假如我们发送两个http://superblogging/blogs/post/Sample请求,服务器端是什么样的行为?如果产生了两个博客帖子,那就说明这个服务不是idempotent的,因为多次使用产生了副作用了嘛;如果后一个请求把第一个请求覆盖掉了,那这个服务就是idempotent的。前一种情况,应该使用POST方法,后一种情况,应该使用PUT方法。
整合阿里云OSS
我们想实现在添加讲师信息的时候加上头像上传功能,怎么办呢?
用阿里云的OSS对象存储即可
环境部署
首先我们打开阿里云注册个OSS对象存储

Java操作OSS
详细操作可查官方文档,下面只写关键代码
[SDK示例 (aliyun.com)](https://help.aliyun.com/document_detail/32008.html)
1、定义工具类读取配置文件
通过继承InitializingBean
当项目已启动,spring加载之后,执行接口一个方法。就是afterPropertiesSet
读取配置文件内容后,在通过执行接口里的一个方法,从而让外面能使用

2、编写上传文件接口
MultipartFile类是org.springframework.web.multipart包下面的一个类,如果想使用MultipartFile类来进行文件操作,那么一定要引入Spring框架。MultipartFile主要是用表单的形式进行文件上传,在接收到文件时,可以获取文件的相关属性,比如文件名、文件大小、文件类型等等。
我们对着官网实例进行修改



3、controller调用接口

4、前端部分
引入上传图片框也在save页面,所以


5、测试

上传成功


nginx反向代理
Nginx快速入门_小蜗牛耶的博客-CSDN博客_nginx 快速入门
首先知道nginx的配置文件是nginx.config
其次是nginx的配置文件是可以看成一个http请求处理的
然后是nginx的server服务。可以理解为每个服务监听不同的端口,分发不同的连接服务。如果是自己的可以直接删掉初始server ,直接新建自己的server。

配置文件如下:
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
client_max_body_size 1024m;
sendfile on;
keepalive_timeout 65;
server {
listen 81;
server_name localhost;
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
server {
listen 9001; #监听端口号
server_name localhost; #主机名称
location ~ /eduService/ { #匹配路径
proxy_pass http://localhost:8001;
}
location ~ /eduService1/ { #匹配路径
proxy_pass http://localhost:6001;
}
location ~ /eduUser/ {
proxy_pass http://localhost:8001;
}
location ~ /eduOss/ {
proxy_pass http://localhost:8002;
}
location ~ /eduVod/ {
proxy_pass http://localhost:8003;
}
location ~ /eduCms/ {
proxy_pass http://localhost:8004;
}
location ~ /ucenterService/ {
proxy_pass http://localhost:8006;
}
location ~ /eduMsm/ {
proxy_pass http://localhost:8005;
}
location ~ /orderService/ {
proxy_pass http://localhost:8007;
}
location ~ /staService/ {
proxy_pass http://localhost:8008;
}
location ~ /admin/ {
proxy_pass http://localhost:8009;
}
}
}

启动nginx

修改项目访问路径为nginx的ip


EasyExcel
简介
alibaba/easyexcel: 快速、简洁、解决大文件内存溢出的java处理Excel工具 (github.com)
1.Java领域解析、生成Excel比较有名的框架有Apache poi、jxl等。但他们都存在一个严重的问题就是非常的耗内存。如果你的系统并发量不大的话可能还行,但是一旦并发上来后一定会OOM或者JVM频繁的full gc。
2.EasyExcel是阿里巴巴开源的一个excel处理框架,以使用简单、节省内存著称。EasyExcel能大大减 少占用内存的主要原因是在解析Excel时没有将文件数据一次性全部加载到内存中,而是从磁盘上一行行读取数据,逐个解析
3.EasyExcel采用一行一行的解析模式,并将一行的解析结果以观察者的模式通知处理
(AnalysisEventListener)
写入测试

引入依赖
com.alibaba easyexcel 2.1.1

读取测试

1、创建实体类和excel对应

2、创建回调监听器

3、直接读


整合课程分类
实现思路
1、图解
树形控件考到前端页面,按需求更改

2、实现Excel表格数据导入数据库功能
前端找一个上传的组件
后端使用前面学的easyexcel功能来实现
3、树状图显示数据功能
前端找一个树状图组件
后端返回上传的表格数据课程分类集合给前端,传递给组件自动遍历
表格数据导入数据库
这个功能用前面学的easyExcel来实现
1、添加依赖
<dependency>
<groupId>com.alibabagroupId>
<artifactId>easyexcelartifactId>
<version>2.1.6version>
dependency>
2、创建excel对应实体类对象

3、通过代码生成器生成课程表代码

4、创建回调监听器
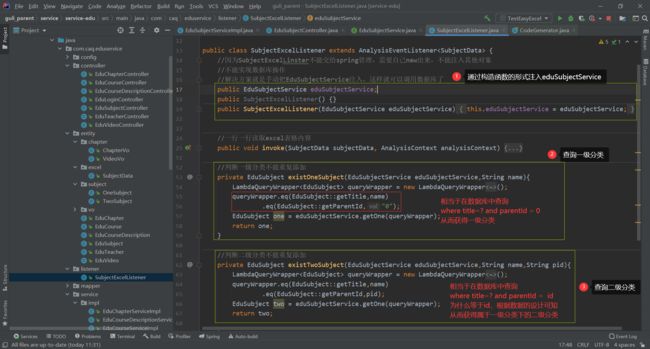

5、自定义接口方法

实现类完成读取功能

6、控制类完成调用

7、swagger完成测试


树状图显示数据
树状图由element-ui获取
1、树状图前端代码结构说明

2、设计思路
给el-tree返回一个集合对象就可以实现遍历
这个集合对象格式是,{一级分类对象,二级分类对象数组[],一级分类对象,二级分类对象数组[].......}
对应到实体类中就是这个形式

3、返回集合对象
在数据库中查询通过表格上传的数据,返回为集合对象

源码也放下来,供大家理解
@Service
public class EduSubjectServiceImpl extends ServiceImpl<EduSubjectMapper, EduSubject> implements EduSubjectService {
//添加课程分类
@Override
public void saveSubject(MultipartFile file, EduSubjectService subjectService) {
try {
//文件输入流
InputStream in = file.getInputStream();
//调用方法进行读取
EasyExcel.read(in, SubjectData.class, new SubjectExcelListener(subjectService)).sheet().doRead();
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public List<OneSubject> getAllOneTwoSubject() {
//查询所有一级分类 parentid=0
QueryWrapper<EduSubject> wrapperOne = new QueryWrapper<>();
wrapperOne.eq("parent_id", "0");
List<EduSubject> oneSubjectList = baseMapper.selectList(wrapperOne);
// this.list()也可以通过这种方式调用查询。
//查询所有二级分类 parentid!=0
QueryWrapper<EduSubject> wrapperTwo = new QueryWrapper<>();
wrapperOne.ne("parent_id", "0");
List<EduSubject> twoSubjectList = baseMapper.selectList(wrapperTwo);
//创建list集合,用于存放最终封装的数据
List<OneSubject> finalSubjectList = new ArrayList<>();
//封装一级分类
//查询出来所有的一级分类list集合遍历,得到每一级分类对象,获得每个一级分类对象值
//封装到要求的list集合里面
for (int i = 0; i < oneSubjectList.size(); i++) {
EduSubject eduSubject = oneSubjectList.get(i);
OneSubject oneSubject = new OneSubject();
// oneSubject.setId(eduSubject.getId());
// oneSubject.setTitle(eduSubject.getTitle());
//把eduSubject值复制到对应的oneSubject对象里面,两个对象里面的属性相同对应的的自动赋值
BeanUtils.copyProperties(eduSubject, oneSubject);
//在一级分类循环遍历查询所有的二级分类
//创建list集合封装每个一级分类的二级分类
List<TwoSubject> twoFinalSubjectList = new ArrayList<>();
//遍历二级分类list集合
for (int j = 0; j < twoSubjectList.size(); j++) {
EduSubject tSubject = twoSubjectList.get(j);
//如果二级分类的parentid和一级分类的id一样,就把它加入到一级分类
if (tSubject.getParentId().equals(eduSubject.getId())) {
TwoSubject twoSubject = new TwoSubject();
BeanUtils.copyProperties(tSubject, twoSubject);
twoFinalSubjectList.add(twoSubject);
}
}
//把一级下面所有的二级分类放到一级分类里面
oneSubject.setChildren(twoFinalSubjectList);
finalSubjectList.add(oneSubject);
}
return finalSubjectList;
}
}
4、控制类调用接口返回集合

5、Swagger测试

加黑的小标题就是前后端整合的过程
1、定义路由、跳转页面

2、定义API
定义的API就是后端写好的接口

3、添加上传组件
element-ui找

组件参数说明
template部分


数据部分

4、测试


树形数据与懒加载

整合课程发布
实现思路
1、图解

2、获取步骤条

3、代码思路
写三个vue组件,每个组件根据需要自定义内容
课程基本信息
实现效果

后端编码
提前生成课程相关表
通过代码生成器生成一键生成

1、创建vo封装每个步骤提交的数据

课程描述类id和课程类id是一样的,所以我们提前设置好

2、service
定义添加课程方法

3、controller
调用添加课程方法

前端编码
1、添加路由,做页面跳转
隐藏路由的目的是用来跳转步骤条

2、定义API

3、编写Vue页面
引入步骤条和表单

显示所有讲师列表
:label表示的是下拉列表的名字的名字
:value是此表单提交时名字对应的teacherid也会被提交
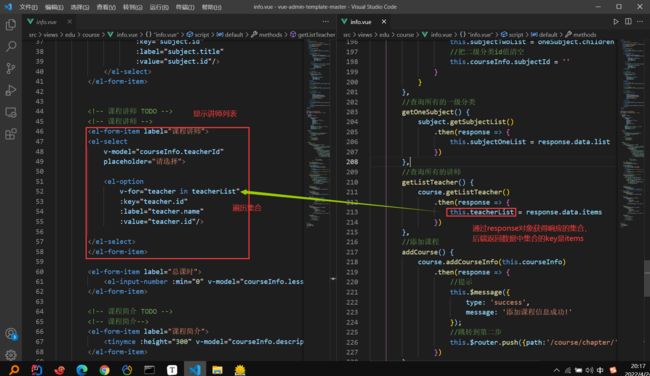

二级联动
这是重点!!!

bug提示:
其中this.courseInfo.subjectId要在每次一级分类的时候进行清空
整合文本编辑器

封面上传

数据回显


课程大纲
实现效果

后端编码
写后端接口处理数据
分别是章节相关的,小节相关的

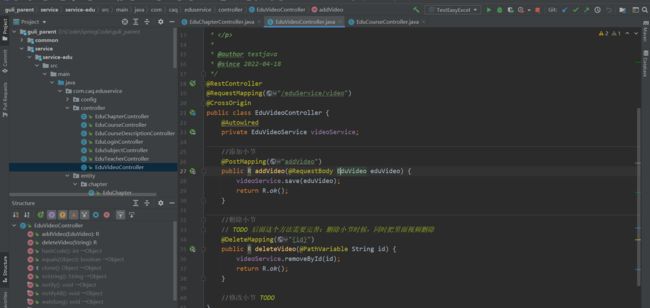
查询所有章节和小节方法
再次理解

前端编码
添加,修改之前我们使用的是跳到一个具体的页面
这次我们使用弹框,在弹框内进行操作
这里我们使用element-ui中的Dialog

前端定义API

增加章节
编码思路:
- 点击添加,出现弹框
- 填写内容,提交表单
- 刷新页面,展示数据

修改章节
- 点击修改,出现弹框
- 回显数据,修改提交
- 刷新页面,展示数据

章节删除
获取id,按id删除

小节增加删除修改
同上,不在一一截取


课程最终发布
实现效果

后端编码
后端主要是做数据回显了,如下:
- 根据id查询课程发布信息
- 根据id发布课程
1、根据id查询课程发布信息
方式一:业务层组装多个表多次的查询结果
方式二:数据访问层进行关联查询
我们使用第二种方式实现
定义VO

dao


业务层
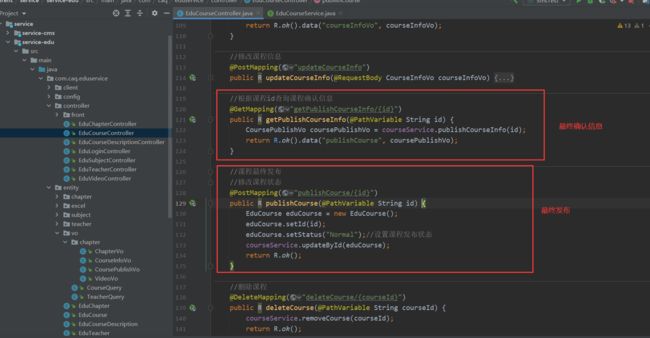
2、根据id发布课程
@PostMapping("publishCourse/{id}")
public R publishCourse(@PathVariable String id) {
EduCourse eduCourse = new EduCourse();
eduCourse.setId(id);
eduCourse.setStatus("Normal");//设置课程发布状态
courseService.updateById(eduCourse);
return R.ok();
}
前端编码
1、定义API

2、写页面



3、显示课程发布的信息
和前面显示讲师类似,不详细说明

Ending…
整合视频点播
简介
https://blog.csdn.net/qq_33857573/article/details/79564255
视频点播(ApsaraVideo for VoD)是集音视频采集、编辑、上传、自动化转码处理、媒体资源管理、分发加速于一体的一站式音视频点播解决方案。

应用场景
- 音视频网站:无论是初创视频服务企业,还是已拥有海量视频资源,可定制化的点播服务帮助客户快速搭建拥有极致观看体验、安全可靠的视频点播应用。
- 短视频:集音视频拍摄、特效编辑、本地转码、高速上传、自动化云端转码、媒体资源管理、分发加速、播放于一体的完整短视频解决方案。目前已帮助1000+APP快速实现手机短视频功能。
- 直播转点播:将直播流同步录制为点播视频,用于回看。并支持媒资管理、媒体处理(转码及内容审核/智能首图等AI处理)、内容制作(云剪辑)、CDN分发加速等一系列操作。
- 在线教育:为在线教育客户提供简单易用、安全可靠的视频点播服务。可通过控制台/API等多种方式上传教学视频,强大的转码能力保证视频可以快速发布,覆盖全网的加速节点保证学生观看的流畅度。防盗链、视频加密等版权保护方案保护教学内容不被窃取。
- 视频生产制作:提供在线可视化剪辑平台及丰富的OpenAPI,帮助客户高效处理、制作视频内容。除基础的剪切拼接、混音、遮标、特效、合成等一系列功能外,依托云剪辑及点播一体化服务还可实现标准化、智能化剪辑生产,大大降低视频制作的槛,缩短制作时间,提升内容生产效率。
- 内容审核:应用于短视频平台、传媒行业审核等场景,帮助客户从从语音、文字、视觉等多维度精准识别视频、封面、标题或评论的违禁内容进行AI智能审核与人工审核。
功能介绍
我们把视频点播服务加到我们的课程发布中
更详细说明可看官方文档
视频点播 (aliyun.com)

基本使用

上传视频
1、简介
sdk的方式将api进行了进一步的封装,不用自己创建工具类。
我们可以基于服务端SDK编写代码来调用点播API,实现对点播产品和服务的快速操作
2、功能介绍
- SDK封装了对API的调用请求和响应,避免自行计算较为繁琐的 API签名。
- 支持所有点播服务的API,并提供了相应的示例代码。
- 支持7种开发语言,包括:Java、Python、PHP、.NET、Node.js、Go、C/C++。
- 通常在发布新的API后,我们会及时同步更新SDK,所以即便您没有找到对应API的示例代码,也可以参考旧的示例自行实现调用。
3、安装


4、调用上传视频API

获取视频播放地址
同样是获取API

整合
后端编码
建module,改pom,yml,启动类,业务类
这里用的是properties,也可以改成yml形式

启动类

常量类

service

控制类
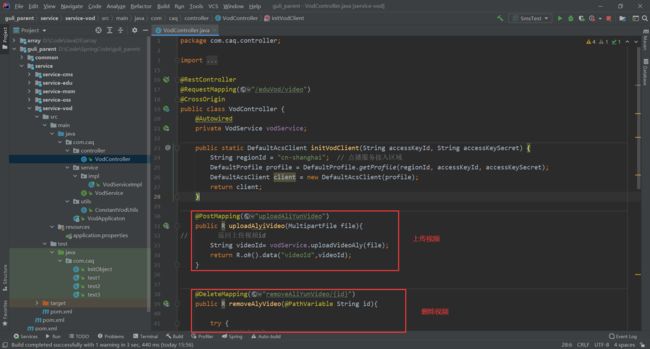
启动微服务,先用swagger测试一下在整合前端即可
前端编码
因为所有微服务前面我们用了nginx做反向代理,
所以第一件事就是加上vod微服务请求路径,
第二是要改变nginx允许上传最大body大小改成1G,
第三重启

二、上传视频组件


整合SpringCloud
简介
Spring全家桶–SpringCloud(初级)_小蜗牛耶的博客-CSDN博客_springcloud开源项目
Spring全家桶–SpringCloud(中级)_小蜗牛耶的博客-CSDN博客_springcloud
Spring全家桶–SpringCloud(高级)_小蜗牛耶的博客-CSDN博客
下面我们就简单的接受下
微服务简介
1、微服务的由来
微服务最早由Martin Fowler与James Lewis于2014年共同提出,微服务架构风格是一种使用一套小服务来开发单个应用的方式途径,每个服务运行在自己的进程中,并使用轻量级机制通信,通常是HTTP API,这些服务基于业务能力构建,并能够通过自动化部署机制来独立部署,这些服务使用不同的编程语言实现,以及不同数据存储技术,并保持最低限度的集中式管理。
2、为什么需要微服务
在传统的IT行业软件大多都是各种独立系统的堆砌,这些系统的问题总结来说就是扩展性差,可靠性不高,维护成本高。到后面引入了SOA服务化,但是,由于 SOA 早期均使用了总线模式,这种总线模式是与某种技术栈强绑定的,比如:J2EE。这导致很多企业的遗留系统很难对接,切换时间太长,成本太高,新系统稳定性的收敛也需要一些时间。
3、微服务与单体架构区别
(1)单体架构所有的模块全都耦合在一块,代码量大,维护困难。
微服务每个模块就相当于一个单独的项目,代码量明显减少,遇到问题也相对来说比较好解决。
(2)单体架构所有的模块都共用一个数据库,存储方式比较单一。
微服务每个模块都可以使用不同的存储方式(比如有的用redis,有的用mysql等),数据库也是单个模块对应自己的数据库。
(3)单体架构所有的模块开发所使用的技术一样。
微服务每个模块都可以使用不同的开发技术,开发模式更灵活。
4、微服务本质
(1)微服务,关键其实不仅仅是微服务本身,而是系统要提供一套基础的架构,这种架构使得微服务可以独立的部署、运行、升级,不仅如此,这个系统架构还让微服务与微服务之间在结构上“松耦合”,而在功能上则表现为一个统一的整体。这种所谓的“统一的整体”表现出来的是统一风格的界面,统一的权限管理,统一的安全策略,统一的上线过程,统一的日志和审计方法,统一的调度方式,统一的访问入口等等。
(2)微服务的目的是有效的拆分应用,实现敏捷开发和部署 。
(3)微服务提倡的理念团队间应该是 inter-operate, not integrate 。inter-operate是定义好系统的边界和接口,在一个团队内全栈,让团队自治,原因就是因为如果团队按照这样的方式组建,将沟通的成本维持在系统内部,每个子系统就会更加内聚,彼此的依赖耦合能变弱,跨系统的沟通成本也就能降低。
5、什么样的项目适合微服务
微服务可以按照业务功能本身的独立性来划分,如果系统提供的业务是非常底层的,如:操作系统内核、存储系统、网络系统、数据库系统等等,这类系统都偏底层,功能和功能之间有着紧密的配合关系,如果强制拆分为较小的服务单元,会让集成工作量急剧上升,并且这种人为的切割无法带来业务上的真正的隔离,所以无法做到独立部署和运行,也就不适合做成微服务了。
6、微服务开发框架
目前微服务的开发框架,最常用的有以下四个:
Spring Cloud:http://projects.spring.io/spring-cloud(现在非常流行的微服务架构)
Dubbo:http://dubbo.io
Dropwizard:http://www.dropwizard.io (关注单个微服务的开发)
Consul、etcd&etc.(微服务的模块)
7、什么是Spring Cloud
Spring Cloud是一系列框架的集合。它利用Spring Boot的开发便利性简化了分布式系统基础设施的开发,如服务发现、服务注册、配置中心、消息总线、负载均衡、 熔断器、数据监控等,都可以用Spring Boot的开发风格做到一键启动和部署。Spring并没有重复制造轮子,它只是将目前各家公司开发的比较成熟、经得起实际考验的服务框架组合起来,通过SpringBoot风格进行再封装屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂、易部署和易维护的分布式系统开发工具包
8、Spring Cloud和Spring Boot是什么关系
Spring Boot 是 Spring 的一套快速配置脚手架,可以基于Spring Boot 快速开发单个微服务,Spring Cloud是一个基于Spring Boot实现的开发工具;Spring Boot专注于快速、方便集成的单个微服务个体,Spring Cloud关注全局的服务治理框架; Spring Boot使用了默认大于配置的理念,很多集成方案已经帮你选择好了,能不配置就不配置,Spring Cloud很大的一部分是基于Spring Boot来实现,必须基于Spring Boot开发。可以单独使用Spring Boot开发项目,但是Spring Cloud离不开 Spring Boot。
9、Spring Cloud相关基础服务组件
服务发现——Netflix Eureka (Nacos)
服务调用——Netflix Feign
熔断器——Netflix Hystrix
服务网关——Spring Cloud GateWay
分布式配置——Spring Cloud Config (Nacos)
消息总线 —— Spring Cloud Bus (Nacos)
10、Spring Cloud的版本
Spring Cloud并没有熟悉的数字版本号,而是对应一个开发代号。
| Cloud代号 | Boot版本(train) | Boot版本(tested) | lifecycle |
|---|---|---|---|
| Angle | 1.2.x | incompatible with 1.3 | EOL in July 2017 |
| Brixton | 1.3.x | 1.4.x | 2017-07卒 |
| Camden | 1.4.x | 1.5.x | - |
| Dalston | 1.5.x | not expected 2.x | - |
| Edgware | 1.5.x | not expected 2.x | - |
| Finchley | 2.0.x | not expected 1.5.x | - |
| Greenwich | 2.1.x | ||
| Hoxton | 2.2.x |
开发代号看似没有什么规律,但实际上首字母是有顺序的,比如:Dalston版本,我们可以简称 D 版本,对应的 Edgware 版本我们可以简称 E 版本。
小版本
Spring Cloud 小版本分为:
SNAPSHOT: 快照版本,随时可能修改
M: MileStone,M1表示第1个里程碑版本,一般同时标注PRE,表示预览版版。
SR: Service Release,SR1表示第1个正式版本,一般同时标注GA:(GenerallyAvailable),表示稳定版本。
Nacos
(1)Nacos是什么
Nacos 是阿里巴巴推出来的一个新开源项目,是一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。
(2)常见的注册中心:
-
Eureka(原生,2.0遇到性能瓶颈,停止维护)
-
Zookeeper(支持,专业的独立产品。例如:dubbo)
-
Consul(原生,GO语言开发)
-
Nacos
相对于 Spring Cloud Eureka 来说,Nacos 更强大。Nacos = Spring Cloud Eureka + Spring Cloud Config
Nacos 可以与 Spring, Spring Boot, Spring Cloud 集成,并能代替 Spring Cloud Eureka, Spring Cloud Config
- 通过 Nacos Server 和 spring-cloud-starter-alibaba-nacos-discovery 实现服务的注册与发现。
(3)Nacos功能
Nacos是以服务为主要服务对象的中间件,Nacos支持所有主流的服务发现、配置和管理。
Nacos主要提供以下四大功能:
-
服务发现和服务健康监测
-
动态配置服务
-
动态DNS服务
-
服务及其元数据管理
(4)Nacos结构图

安装
解压安装包,进入cmd运行nacos即可


服务注册
我们把后面要用的service-edu、service-oss、service-vod都加入到nacos中
怎么加呢?
1、配置依赖
org.springframework.cloud
spring-cloud-starter-alibaba-nacos-discovery
2、添加服务配置信息

3、添加Nacos客户端注解
在客户端微服务启动类中添加注解

4、启动客户端微服务
启动注册中心
启动已注册的微服务,可以在Nacos服务列表中看到被注册的微服务

服务调用-Feign
feign
英 [feɪn] 美 [feɪn]
v. 假装,装作,佯装(有某种感觉或生病、疲倦等)
Feign是一个声明式WebService客户端。使用Feign能让编写Web Service客户端更加简单。它的使用方法是定义一个服务接口然后在上面添加注解。Feign也支持可拔插式的编码器和解码器。Spring Cloud对Feign进行了封装,使其支持了Spring MVC标准注解和HttpMessageConverters。Feign可以与Eureka和Ribbon组合使用以支持负载均衡。
Web Service
分布式的调用服务,多个客户端可以通过web配置来调用发布的服务。
例如:微服务A想调用微服务B,要想实现这个功能就要使用WebService
WebServic 很重要,但不被经常使用,它更多的是一种分布服务的方式,所以对它了解就好了。
Web 服务端提供的是服务或功能,继面向对象后,面向服务形成了新的特色。例如请求天气预报服务,如今很多手机、小网站等小成本的经营者都可以进行天气的预报,这是因为气象站将天气的预报的服务发布了出去,只要符合一定条件就都可以调用这个服务。简单说就是web服务就是一个URL资源,客户端可以调用这个服务。
后端编码
删除课时的同时删除云端视频
哎,这不就出现了微服务之间互相调用的情况了吗
1、pom文件
引用feign实现远程调用

2、调用端的启动类添加注解
feign 是通过接口+注解实现微服务调用
消费者添加@EnableFeignClients开启feign

3、创建包和接口
业务逻辑接口+@FeignClient配置调用provider服务
创建client包
@FeignClient注解用于指定从哪个服务中调用功能 ,名称与被调用的服务名保持一致。
@GetMapping注解用于对被调用的微服务进行地址映射。
@PathVariable注解一定要指定参数名称,否则出错
@Component注解防止,在其他位置注入CodClient时idea报错

前提是我们vod微服务中批量删除是可以用的

4、调用微服务
课程微服务调用视频微服务
目的是删除课程同时删除视频
1、注入vod微服务中删除视频接口vodClient

2、具体流程

前端编码
还是和前面一样,我们每次点击添加小节弹框要清空
//添加小节弹框的方法
openVideo(chapterId) {
//弹框
this.dialogVideoFormVisible = true;
//清空
this.video = {};
this.fileList = [];
//设置章节id
this.video.chapterId = chapterId;
},
这次我们多添加几个小节来测试能不能同时删除


发布课程后删除课程,看视频点播还有没有视频


服务熔断-Hystrix
Spring Cloud 在接口调用上,大致会经过如下几个组件配合:
接口调用的流程很重要,我们一定要理解
自己用过这些组件的话还是很好理解的
Feign ----->Hystrix —>Ribbon —>Http Client(apache http components 或者 Okhttp)` 具体交互流程上,如下图所示:

(1)接口化请求调用当调用被@FeignClient注解修饰的接口时,在框架内部,将请求转换成Feign的请求实例feign.Request,交由Feign框架处理。
(2)Feign :转化请求Feign是一个http请求调用的轻量级框架,可以以Java接口注解的方式调用Http请求,封装了Http调用流程。
(3)Hystrix:熔断处理机制 Feign的调用关系,会被Hystrix代理拦截,对每一个Feign调用请求,Hystrix都会将其包装成HystrixCommand,参与Hystrix的流控和熔断规则。如果请求判断需要熔断,则Hystrix直接熔断,抛出异常或者使用FallbackFactory返回熔断Fallback结果;如果通过,则将调用请求传递给Ribbon组件。
(4)Ribbon:服务地址选择 当请求传递到Ribbon之后,Ribbon会根据自身维护的服务列表,根据服务的服务质量,如平均响应时间,Load等,结合特定的规则,从列表中挑选合适的服务实例,选择好机器之后,然后将机器实例的信息请求传递给Http Client客户端,HttpClient客户端来执行真正的Http接口调用;
(5)HttpClient :Http客户端,真正执行Http调用根据上层Ribbon传递过来的请求,已经指定了服务地址,则HttpClient开始执行真正的Http请求
Hystrix(豪猪哥)
Hystrix 是一个供分布式系统使用,提供延迟和容错功能,保证复杂的分布系统在面临不可避免的失败时,仍能有其弹性。
比如系统中有很多服务,当某些服务不稳定的时候,使用这些服务的用户线程将会阻塞,如果没有隔离机制,系统随时就有可能会挂掉,从而带来很大的风险。SpringCloud使用Hystrix组件提供断路器、资源隔离与自我修复功能。下图表示服务B触发了断路器,阻止了级联失败

feign结合Hystrix使用
1、添加依赖
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-ribbonartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-hystrixartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discoveryartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-openfeignartifactId>
dependency>
2、配置文件中添加hystrix配置

3、在service-edu的client包里面创建熔断器的实现类

4、测试熔断器效果
我们模拟视频点播微服务宕机了,我们再去调用它,看看会不会触发hystrix

debug启动edu服务,关闭vod服务,会触发熔断器

整合NUXT
什么是NUXT?
一种服务端渲染技术
1、什么是服务端渲染
服务端渲染又称SSR (Server Side Render)是在服务端完成页面的内容,而不是在客户端通过AJAX获取数据。
服务器端渲染(SSR)的优势主要在于:更好的 SEO,由于搜索引擎爬虫抓取工具可以直接查看完全渲染的页面。
如果你的应用程序初始展示 loading 菊花图,然后通过 Ajax 获取内容,抓取工具并不会等待异步完成后再进行页面内容的抓取。也就是说,如果 SEO 对你的站点至关重要,而你的页面又是异步获取内容,则你可能需要服务器端渲染(SSR)解决此问题。
另外,使用服务器端渲染,我们可以获得更快的内容到达时间(time-to-content),无需等待所有的 JavaScript 都完成下载并执行,产生更好的用户体验,对于那些「内容到达时间(time-to-content)与转化率直接相关」的应用程序而言,服务器端渲染(SSR)至关重要。
2、什么是NUXT
Nuxt.js 是一个基于 Vue.js 的轻量级应用框架,可用来创建服务端渲染 (SSR) 应用,也可充当静态站点引擎生成静态站点应用,具有优雅的代码结构分层和热加载等特性。
官网网站:
https://zh.nuxtjs.org/
安装NUXT
1、下载压缩包
https://github.com/nuxt-community/starter-template/archive/master.zip
2、解压
将template中的内容复制到 guli
3、安装ESLint
将guli-admin项目下的.eslintrc.js配置文件复制到当前项目下
4、修改package.json
name、description、author(必须修改这里,否则项目无法安装)
"name": "guli",
"version": "1.0.0",
"description": "谷粒学院前台网站",
"author": "pyy <[email protected]>",
5、修改nuxt.config.js
修改title: ‘{{ name }}’、content: ‘{{escape description }}’
这里的设置最后会显示在页面标题栏和meta数据中
head: {
title: '谷粒学院 - Java视频|HTML5视频|前端视频|Python视频|大数据视频-自学拿1万+月薪的IT在线视频课程,谷粉力挺,老学员为你推荐',
meta: [
{ charset: 'utf-8' },
{ name: 'viewport', content: 'width=device-width, initial-scale=1' },
{ hid: 'keywords', name: 'keywords', content: '谷粒学院,IT在线视频教程,Java视频,HTML5视频,前端视频,Python视频,大数据视频' },
{ hid: 'description', name: 'description', content: '谷粒学院是国内领先的IT在线视频学习平台、职业教育平台。截止目前,谷粒学院线上、线下学习人次数以万计!会同上百个知名开发团队联合制定的Java、HTML5前端、大数据、Python等视频课程,被广大学习者及IT工程师誉为:业界最适合自学、代码量最大、案例最多、实战性最强、技术最前沿的IT系列视频课程!' }
],
link: [
{ rel: 'icon', type: 'image/x-icon', href: '/favicon.ico' }
]
},
6、在命令提示终端中进入项目目录
7、安装依赖
npm install
8、测试运行
npm run dev
9、NUXT目录结构
(1)资源目录 assets
用于组织未编译的静态资源如 LESS、SASS 或 JavaScript。
(2)组件目录 components
用于组织应用的 Vue.js 组件。Nuxt.js 不会扩展增强该目录下 Vue.js 组件,即这些组件不会像页面组件那样有 asyncData 方法的特性。
(3)布局目录 layouts
用于组织应用的布局组件。
(4)页面目录 pages
用于组织应用的路由及视图。Nuxt.js 框架读取该目录下所有的 .vue 文件并自动生成对应的路由配置。
(5)插件目录 plugins
用于组织那些需要在 根vue.js应用 实例化之前需要运行的 Javascript 插件。
(6)nuxt.config.js 文件
nuxt.config.js 文件用于组织Nuxt.js 应用的个性化配置,以便覆盖默认配置。
幻灯片插件
1、安装插件
npm install vue-awesome-swiper
2、配置插件
在 plugins 文件夹下新建文件 nuxt-swiper-plugin.js,内容是
import Vue from 'vue'
import VueAwesomeSwiper from 'vue-awesome-swiper/dist/ssr'
Vue.use(VueAwesomeSwiper)
在 nuxt.config.js 文件中配置插件
将 plugins 和 css节点 复制到 module.exports节点下

页面布局
1、复制静态资源
将静态原型中的css、img、js、photo目录拷贝至assets目录下
将favicon.ico复制到static目录下
2、定义布局
我们可以把页头和页尾提取出来,形成布局页
修改layouts目录下default.vue,从静态页面中复制首页,修改了原始文件中的资源路径为~/assets/,将主内容区域的内容替换成
内容如下:

3、定义首页面
修改pages/index.vue:
修改了原始文件中的资源路径为~/assets/
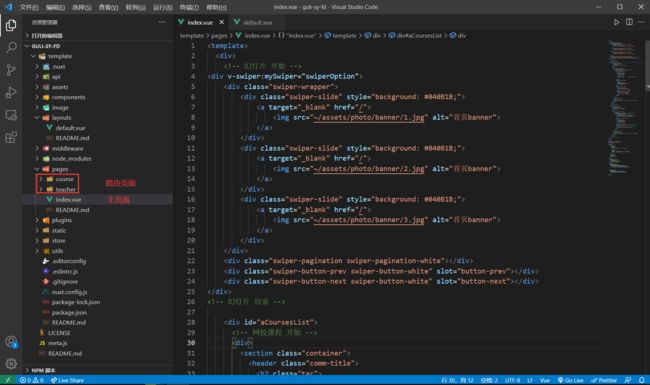
路由
1、固定路由
点击,跳转。跳转的路径是固定的
2、动态路由
如果我们需要根据id查询一条记录,就需要使用动态路由。NUXT的动态路由是以下划线开头的vue文件,参数名为下划线后边的文件名
在pages下的course目录下创建_id.vue
封装axios
为了更好的操作ajax,我们用axios来操作
我们参考guli-admin将axios操作封装起来
下载axios ,使用命令 npm install axios
创建utils文件夹,utils下创建request.js
import axios from 'axios'
// 创建axios实例
const service = axios.create({
baseURL: 'http://localhost:8201', // api的base_url
timeout: 20000 // 请求超时时间
})
export default service
整合教师页面和课程页面
就是复制两个vue页面
然后分别定义两个动态路由页面
整合Redis
这里整合的redis实例是尚荣宝项目的,给树状图做缓存
下面在整合一个前端的banner轮播图
树状图整合
1、centos上运行redis服务器

2、目前数据库是空的
127.0.0.1:6379> keys *
(empty array)
127.0.0.1:6379>
3、在查询接口实现类中通过redistemplate加上redis缓存

4、访问前端项目,看redis中是否会加上key和value

5、测试

banner整合
第二种整合方式采用注解形式,注解形式的整合需要redis的配置文件
配置文件的写法是固定的,如下:
一、配置类
@Configuration
@EnableCaching //开启缓存
public class RedisConfig extends CachingConfigurationSelector {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.activateDefaultTyping(LaissezFaireSubTypeValidator.instance,ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
template.setConnectionFactory(factory);
//key序列化方式
template.setKeySerializer(redisSerializer);
//value序列化
template.setValueSerializer(jackson2JsonRedisSerializer);
//value hashmap序列化
template.setHashValueSerializer(jackson2JsonRedisSerializer);
return template;
}
@Bean
public CacheManager cacheManager(RedisConnectionFactory factory) {
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
//解决查询缓存转换异常的问题
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.activateDefaultTyping(LaissezFaireSubTypeValidator.instance,ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
// 配置序列化(解决乱码的问题),过期时间600秒
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofSeconds(600))
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(redisSerializer))
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(jackson2JsonRedisSerializer))
.disableCachingNullValues();
RedisCacheManager cacheManager = RedisCacheManager.builder(factory)
.cacheDefaults(config)
.build();
return cacheManager;
}
}
二、配置文件
# 服务端口
server.port=8004
# 服务名
spring.application.name=service-cms
spring.cloud.nacos.discovery.server-addr=127.0.0.1:8848
# mysql数据库连接
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/guli?serverTimezone=GMT%2B8
spring.datasource.username=root
spring.datasource.password=root
#返回json的全局时间格式
spring.jackson.date-format=yyyy-MM-dd HH:mm:ss
spring.jackson.time-zone=GMT+8
#配置mapper xml文件的路径
mybatis-plus.mapper-locations=classpath:com/caq/educms/mapper/xml/*.xml
spring.redis.host=172.20.10.9
spring.redis.port=6379
spring.redis.database= 0
spring.redis.timeout=1800000
spring.redis.lettuce.pool.max-active=20
spring.redis.lettuce.pool.max-wait=-1
#最大阻塞等待时间(负数表示没限制)
spring.redis.lettuce.pool.max-idle=5
spring.redis.lettuce.pool.min-idle=0
#mybatis日志
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
三、修改实现类
@Service
public class CrmBannerServiceImpl extends ServiceImpl<CrmBannerMapper, CrmBanner> implements CrmBannerService {
@Cacheable(value = "banner",key = "'selectIndexList'")
@Override
public List<CrmBanner> selectAllBanner() {
//根据id进行降序排序,显示排列之后的前两条记录
QueryWrapper<CrmBanner> queryWrapper = new QueryWrapper<>();
queryWrapper.orderByDesc("id");
//拼接sql语句
queryWrapper.last("limit 2");
List<CrmBanner> list = baseMapper.selectList(null);
return list;
}
}
四、测试

注意点
redis主要是配置文件,对配置文件的详解可看如下文章
Redis配置文件详解 - 云+社区 - 腾讯云 (tencent.com)
(1)关闭liunx防火墙
(2)找到redis配置文件, 注释一行配置
默认情况这个bind不改的话只能接受本机的访问请求

修改 protected-mode yes
改为protected-mode no
关掉redis的bind项和没设置redis密码的时候,能让redis接受其他主机的响应