CentOS7搭建Hadoop集群的详细操作流程
CentOS7搭建Hadoop集群的详细操作流程
一、准备工作
- 若还没安装虚拟机可参考:VMVMware14虚拟机安装程
- 没安装CentOS的可参考:Linux CentOS安装教程
- Haddop的下载可以到https://mirrors.cnnic.cn/apache/hadoop/common/这个网址下载,下载的时候版本是选择Hadoop2.x.版本。格式文件选择hadoop-2.x.y.tar.gz ,因为是已编译欧了的,而另一个包含 src 的则是 Hadoop 源代码,需要进行编译才可使用。
若有hadoop-2.x.y.tar.gz.mds 这个文件建议也可下载,因为该文件包含了检验值可用于检查hadoop-2.x.y.tar.gz 的完整性,否则若文件发生了损坏或下载不完整,Hadoop 将无法正常运行。想验证文件完整性,可在自行百度搜索,
PS:如果浏览器下载过慢,可复制下载链接到迅雷打开下载。
二、开始搭建虚拟机
前面准备工作完成后即可开始搭建虚拟机,进行hadoop集群操作。
- 下面为三台虚拟机的hostname和IP地址
| hostname | Ip地址 |
|---|---|
| Master | 192.168.100.10 |
| Slave1 | 192.168.100.11 |
| Slave2 | 192.168.100.12 |
以CentOS7为主机,命名为Master,复制两台虚拟机
找到虚拟机的目录,直接复制两台虚拟机,命名为Slave1,Slave2,并相应打开文件删除
下面的文件
![]()
接着打开虚拟机->我的计算机->扫描虚拟机->选择扫描位置浏览到刚才复制的文件->确定完成后对虚拟机重新命名开启即可。
网络配置
1.VMware 网络配置(使虚拟机上的各个节点能够互联,用同一个网段)
- VMnet8(NAT模式)----子网IP设置为:192.168.100.0----NAT设置:网关改为192.168.100.2—确定----去掉使用DHCP选项

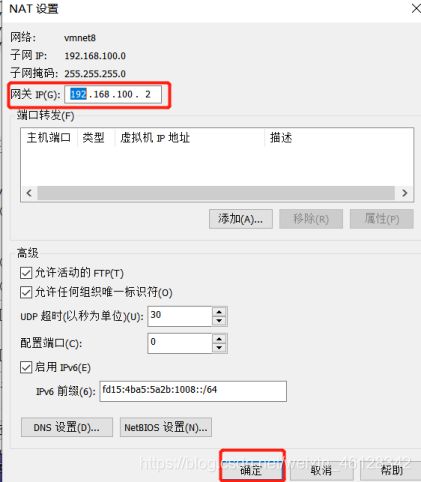
- 开始菜单->运行->services.msc或从控制面板中找到“服务”一项打开如下图所示,找到以vmware开头的服务,确保都启用

- 打开控制面板->系统和安全->网络和 Internet->网络和共享中心->更改适配器设置,启用VMnet8
 ,再查看属性,双击Intter协议版本4看IP地址与子网掩码是否配好,若没则进行相应配置。(注意IP地址与子网掩码是于上面虚拟机配置相对应的)
,再查看属性,双击Intter协议版本4看IP地址与子网掩码是否配好,若没则进行相应配置。(注意IP地址与子网掩码是于上面虚拟机配置相对应的)
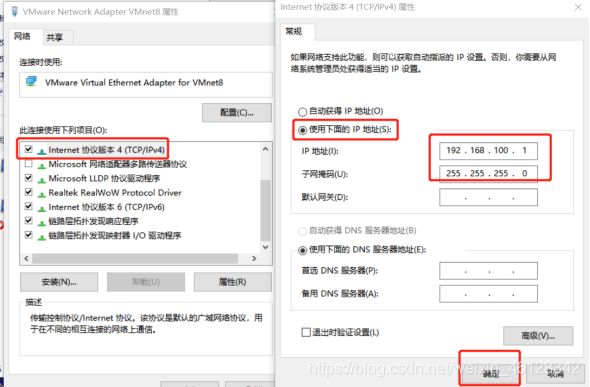
2.CentOS网络配置
Master节点上修改网卡配置
vi /etc/sysconfig/network-scripts/ifcfg-ens33
#ens33为自己本机上的网卡名
进入后先改
BOOTPROTO=static
ONBOOT=yes
后加
IPADDR=192.168.100.10 #IP地址
NETMASK=255.255.255.0 #子网掩码
GATEWAY=192.168.100.2 #网关地址
DNS1=8.8.8.8 #DNS服务器地址
Slave1、2节点上修改网卡配置,基本和Master上的配置一样,但Slaved1的IP地址改为192.168.100.11,Slaved2的IP地址改为192.168.100.12

点i进入编辑
退出编辑-> esc键 :x
重启网卡
在Master节点和Slave1、2节点上重启网卡
systemctl restart network
关闭掉Master和Slave1、2上的防火墙
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
修改主机名
CentOS7修改主机名:
hostnamectl set-hostname +主机名
hostnamectl set-hostname Master
hostname #查看一下
ls
如果是CentOS6修改主机名则用
vi /etc/sysconfig/network
Master上改主机名
vi /etc/sysconfig/network
修改HOSTNAME=Master
Slave1改主机名
vi /etc/sysconfig/network
添加HOSTNAME=Slave1
Slave2改主机名
vi /etc/sysconfig/network
添加HOSTNAME=Slave2
hosts修改域名:(三个节点上都配一遍)
vi /etc/hosts
修改内容为
192.168.100.10 Master Master.cn
192.168.100.11 Slave1 Slave1.cn
192.168.100.12 Slave2 Slave2.cn
#ip地址 hostname 域名 ,设置完之后可以用域名进行访问
重新启动一下
reboot
测试能不能跑通,实现节点间互联
查看网络配置是否成功
ifconfig #显示的网络信息是否和我们配置的契合
Master上
ping baidu.com
ping 192.168.100.10
ping Slave1
ping Slave2
Slave1上
ping baidu.com
ping 192.168.100.11
ping Master
ping Slave2
Slave2同上进行相互ping
以上如果ping不通则说明你还有bug要修
yum 源配置
1.安装wget
yum install -y wget
2.备份/etc/yum.repos.d/CentOS-Base.repo文件
cd /etc/yum.repos.d/
mv CentOS-Base.repo CentOS-Base.repo.back
3.下载阿里云的Centos-7.repo文件
wget -O CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
4.重新加载yum
yum clean all
yum makecache
若已经有默认的yum源可进行更换为国内的阿里云yum源,让下载安装及更新速度更快一些,替换很简单,简单记录一下步骤。
1、备份
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
或
mv /etc/yum/repos.d/CentOS-Base.repo{,.date -I}
2.下载新的CentOS-Base.repo 到/etc/yum.repos.d/
wget -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
或
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
3、添加EPEL
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
4、清理缓存并生成新的缓存
yum clean all
yum makecache
CentOS6上更换yum源,可点击此次
jdk的安装
Master上首先可用rz命令进行上传jdk文件,若rz没有,用 yum install lrzsz 进行下载,下载成功后在home目录下rz进行上传jdk文件,再ls查看一下文件即可查看jdk上传成功
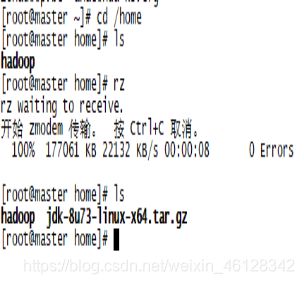
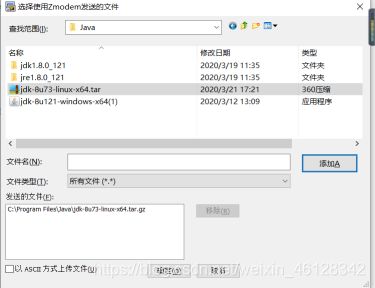
接着用
scp jdk-8u73-linux-x64.tar.gz Slave1.cn:/home
上传到Slave1
Slave1上
ls #一下即可看到文件已上传成功
mkdir -p /export/servers #在home目录下创建一个目录
tar -zxvf jdk-8u73-linux-x64.tar.gz -C /export/servers/ #解压到对应目录
cd /export/servers #进入目录ls查看到文件已解压安装成功
ln -s jdk1.8.0_73 jdk #对jdk1.8.0_73 创建快捷方式为jdk
ls
pwd #看一下当前目录
cd jdk
vi /etc/profile #在jdk目录下配置一下java的环境变量
添加
#java path configuration
export JAVA_HOME=/export/servers/jdk
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
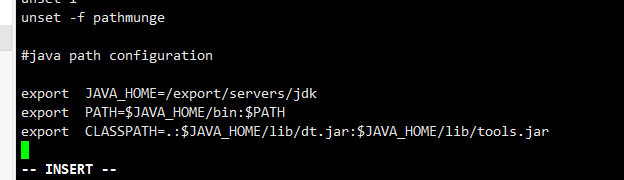
#注意中间的空格为tab键
:wq 保存退出
source /etc/profile #让配置生效
java -version #看java是否安装配置成功
chkconfig iptables off #如果之前忘记关防火墙,可用此命令进行防火墙永久关闭
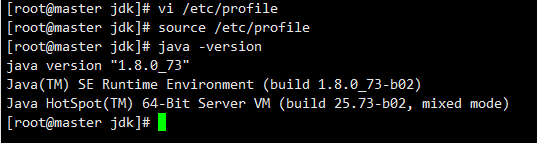
(Master、Slave2的jdk配置同上)
配置免密码登录
在Master上
cd ~
ssh-keygen -t rsa #一直按回车
ssh localhost t#这时候连接到本机是不需要密码了
ssh-copy-id Slave1.cn
ssh-copy-id Slave2.cn #拷贝到Slave1、2上
在Master上测试是否能无密码ssh登录到Slave1、2
ssh Slave1
ssh Slave2
这时已经不需要密码登录了
![]()
Hadoop的安装
Mater上
cd /home
cd /export
mkdir software #进入export下创建一个目录放hadoop,然后ls可查看一下
cd software/
rz #上传hadoop文件到software目录下
ls #查看hadopp是否上传成功
scp hadoop-2.6.1.tar.gz Slave1.cn:/export/software/ #先在Slave1创建好software再执行此命令,将hadoop包传到Slave1
Slave1上
cd /export
mkdir software #创建一个目录放hadoop
cd software/
ls
tar -zxvf hadoop-2.6.1.tar.gz -C /export/servers #解压到servers目录
cd /export
cd servers/
ls #进入servers目录查看解压是否成功
ln -s hadoop-2.6.1 hadoop #对hadoop-2.6.1 创建快捷方式为hadoop
ls
vim /etc/profile #配置hadoop的环境变量
添加
#hadoop configuration
export HADOOP_HOME=/export/servers/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
#注意中间的空格为tab键

退出
source /etc/profile #让其配置生效
hadoop version #查看是否成功
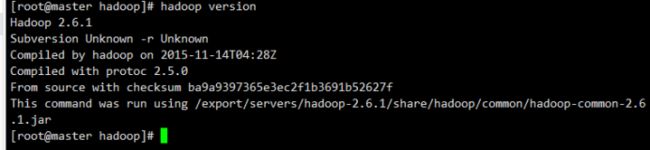
(Master、Slave2的hadoop配置同上)
Master上修改配置文件进行集群
mkdir data #进入export新建一个目录放data,然后ls一下
cd data
mkdir -p hadoop/tmp #在data下新建一个放hadoop数据,然后ls一下
进入servers目录下的hadoop
cd etc
cd hadoop/ #进入到etc的hadoop的配置文件
vim hadoop-env.sh #进入修改一下JAVA_HOME的安装目录

vim mapred-env.sh #同样进入修改一下JAVA_HOME的安装目录
![]()
vim core-site.xml #配置 core-site.xml
#在和 中间添加
hadoop.tmp.dir</name>
/export/data/hadoop/tmp</value>
</property>
fs.defaultFS</name>
hdfs://192.168.100.10:9000</value>
</property>
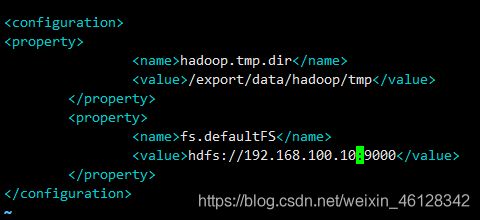
#其中/export/data/hadoop/tmp是之前是建的放hadoop数据的地方
hdfs://192.168.100.10:9000 前面为主机Master的IP地址,后面为端口号,可以默认为9000
vim yarn-site.xml #配置yarn-sit.xml
#在和 中间添加
yarn.resourcemanager.hostname</name>
192.168.100.10</value>
</property>
yarn.nodemanager.aux-services</name>
mapreduce_shuffle</value>
</property>
#其中192.168.100.10是为主机Master的IP地址

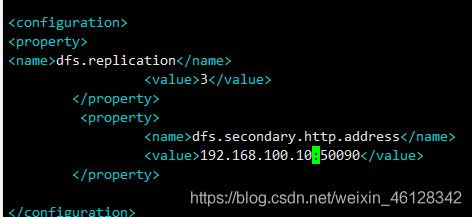
vim hdfs-site.xml #配置hdfs-site.xml
#在和 中间添加
dfs.replication</name>
3</value>
</property>
dfs.secondary.http.address</name>
192.168.100.10:50090</value>
</property>
#其中192.168.100.10是为主机的IP地址,3为机器的节点数
cp mapred-site.xml.template mapred-site.xml #复制一份 mapred-site.xml
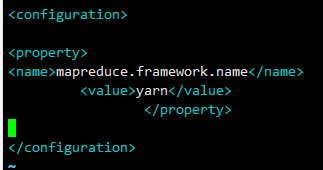
vim mapred-site.xml #配置mapred-site.xml
#在和 中间添加
mapreduce.framework.name</name>
yarn</value>
</property>
vim slaves #配置slaves
修改
localhost—>Slave1.cn Slave2.cn
#lave1.cn Slave2.cn为你要集群的机器

master配置完分发到其他机器上,可以把master上的hadoop配置文件进行打包压缩复制到slaves节点上,或者直接在slaves节点上各配置一遍,其中配置内容跟master的配置一模一样(包括IP地址和端口号)
#以上配置文件已完成
hdfs namenode -format #启动前先格式化文件系统,之后无须格式化
开启集群
start-dfs.sh #启动dfs
start-yarn.sh #启动yarn
mr-jobhistory-daemon.sh start historyserver #启动脚本
jps #可以查看各个节点所启动的进程
正确的话,在 Master 节点上可以看到 NameNode、ResourceManager、SecondrryNameNode、JobHistoryServer 进程;
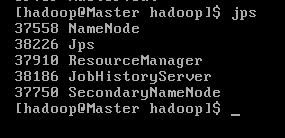
在Slave1、2节点上可以看到DataNode 和 NodeManager进程;


以上集群已搭建成功
关闭集群也是在Master上关闭,按顺序执行命令
stop-yarn.sh
stop-dfs.sh
mr-jobhistory-daemon.sh stop historyserver
注意:CentOS系统默认开启了防火墙,在开启 Hadoop 集群之前,需要关闭集群中每个节点的防火墙。有防火墙会导致 ping 得通但 telnet 端口不通,从而导致 DataNode 启动了,但 Live datanodes 为 0的情况。我们前面的操作中已经关闭防火墙了,如果防火墙没关闭的请关闭再开启集群。
同时有事没事不要随便初始化NameNode,初始过一遍就欧了。
Ubuntu上搭建hadoop伪分布式配置可看一下这里
CentOS上搭建hadoop伪分布式配置可看一下这里