Go语言出现后,Java还是最佳选择吗?

阿里妹导读:随着大量新生的异步框架和支持协程的语言(如Go)的出现,在很多场景下操作系统的线程调度成为了性能的瓶颈,Java也因此被质疑是否不再适应最新的云场景了。4年前,阿里JVM团队开始自研Wisp2,将Go语言的协程能力带入到Java世界。既享受Java的丰富生态,又获得异步程序的性能,Wisp2让Java平台历久弥新。
Java平台一直以生态的繁荣著称,大量的类库、框架帮助开发者们快速搭建应用。 而其中大部分Java框架类库都是基于线程池以及阻塞机制来服务并发的,主要原因包括:
2. Java EE的一些标准都是线程级阻塞的(比如JDBC);
3. 基于阻塞模式可以快速地开发应用。
但如今,大量新生的异步框架和支持协程的语言(如Go)的出现,在很多场景下操作系统的线程调度成为了性能的瓶颈。 Java也因此被质疑是否不再适应最新的云场景了。
4年前,阿里开始自研Wisp2。 它主要是用在IO密集的服务器场景,大部分公司的在线服务都是这样的场景 (离线应用都是偏向于计算,则不适用)。 它在功能属性上对标Goroutine的Java协程,在产品形态、性能、稳定性上都达到了一个比较理想的情况。 到现在 ,已经有上百个应用,数万个容器上线了Wisp1/2。 Wisp协程完全兼容多线程阻塞的代码写法,仅需增加JVM参数来开启协程,阿里巴巴的核心电商应用已经在协程模型上经过两个双十一的考验,既享受到了Java的丰富生态,又获得了异步程序的性能。
Wisp2主打的是性能和对现有代码的兼容性,简而言之,现有的基于多线程的IO密集的Java应用只需要加上Wisp2的JVM参数就可以获得异步的性能提升。
作为例子,以下是消息中间件代理(简称mq)和drds只添加参数不改代码的压测比较:
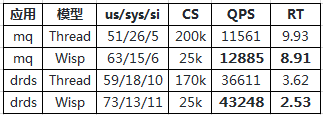
可以看到上下文切换以及sys CPU显著降低,RT减少、QPS分别提升11.45%,18.13%。
Quick Start
由于Wisp2完全兼容现有的Java代码,因此使用起来十分简单,有多简单?
如果你的应用是“标准”的在线应用(使用/home/admin/$APP_NAME/setenv.sh配置参数),那么在admin用户下输入如下命令就可以开启Wisp2了:
curl https://gosling.alibaba-inc.com/sh/enable-wisp2.sh | sh
否则需要手动升级JDK和Java参数:
ajdk 8.7.12_fp2 rpm
sudo yum install ajdk -b current # 也可以通过yum安装最新jdk
java -XX:+UseWisp2 .... # 使用Wisp参数启动Java应用
java -XX:+UseWisp2 .... # 使用Wisp参数启动Java应用
然后就可以通过jstack验证协程确实被开启了。
Carrier线程是调度协程的线程,下方的- Coroutine [...]表示一个协程,active表示协程被调度的次数,steal表示被work stealing的次数,preempt表示时间片抢占次数。

下图是DRDS在ecs上压测时的top -H,可以看出来应用的数百个线程被8个Carrier线程托管,均匀地跑在CPU核数个线程上面。下方一些名为java的线程是gc线程。

过多线程的开销
误区1: 进内核引发上下文切换
我们看一段测试程序:
pipe(a);while (1) {write(a[1], a, 1);read(a[0], a, 1);n += 2;}

执行这段程序时上下文切换非常低,实际上上面的IO系统调用都是不会阻塞的,因此内核不需要挂起线程,也不需要切换上下文,实际发生的是用户/内核态的模式切换。
上面的程序在神龙服务器测得每个pipe操作耗时约334ns,速度很快。
误区2: 上下文切换的开销很大
本质上来说无论是用户态还是内核态的上下文切换都是很轻量的,甚至有一些硬件指令来支持,比如pusha可以帮助我们保存通用寄存器。同一个进程的线程共享页表,因此上下文切换的开销一般只有:
-
保存各种寄存器
-
切换sp(call指令会自动将pc压栈)
可以在数十条指令内完成。
开销
既然近内核以及上下文切换都不慢,那么多线程的开销究竟在哪?
我们不妨看一个阻塞的系统调用futex的热点分布:

可以看到上面的热点中有大量涉及调度的开销。我们来看过程:
-
调用系统调用(可能需要阻塞);
-
系统调用确实需要阻塞,kernel需要决定下一个被执行的线程(调度);
-
执行上下切换。
因此,上面2个误区与多线程的开销都有一定因果关系,但是真正的开销来源于线程阻塞唤醒调度。
综上,希望通过线程模型来提升web server性能的原则是:
-
活跃线程数约等于CPU个数
-
每个线程不太需要阻塞
文章后续将紧紧围绕这两个主题。
为了满足上述两个条件,使用eventloop+异步callback的方式是一个极佳的选择。
异步与协程的关系
为了保持简洁,我们以一个异步服务器上的Netty写操作为例子(写操作也存在阻塞的可能):
private void writeQuery(Channel ch) {ch.write(Unpooled.wrappedBuffer("query".getBytes())).sync();logger.info("write finish");}
这里的sync()会阻塞线程。不满足期望。由于netty本身是一个异步框架,我们引入回调:
private void writeQuery(Channel ch) {ch.write(Unpooled.wrappedBuffer("query".getBytes())).addListener(f -> {logger.info("write finish");});}
注意这里异步的write调用后,writeQuery会返回。因此假如逻辑上要求在write后执行的代码,必须出现在回调里,write是函数的最后一行。这里是最简单的情形,如果函数有其他调用者,那么就需要用CPS变换。
需要不断的提取程序的"下半部分",即continuation,似乎对我们造成一些心智负担了。这里我们引入kotlin协程帮助我们简化程序:
suspend fun Channel.aWrite(msg: Any): Int =suspendCoroutine { cont ->write(msg).addListener { cont.resume(0) }}suspend fun writeQuery(ch: Channel) {ch.aWrite(Unpooled.wrappedBuffer("query".toByteArray()))logger.info("write finish")}
这里引入了一个魔法suspendCoroutine,我们可以获得当前Continuation的引用,并执行一段代码,最后挂起当前协程。Continuation代表了当前计算的延续,通过Continuation.resume()我们可以恢复执行上下文。因此只需在写操作完成时回调cont.resume(0),我们又回到了suspendCoroutine处的执行状态(包括caller writeQuery),程序继续执行,代码返回,执行log。从writeQuery看我们用同步的写法完成了异步操作。当协程被suspendCoroutine切换走后,线程可以继续调度其他可以执行的协程来执行,因此不会真正阻塞,我们因此获得了性能提升。
从这里看,只需要我们有一个机制来保存/恢复执行上下文,并且在阻塞库函数里采用非阻塞+回调的方式让出/恢复协程,就可以使得以同步形式编写的程序达到和异步同样的效果了。
理论上只要有一个库包装了所有JDK阻塞方法,我们就可以畅快地编写异步程序了。改写的阻塞库函数本身需要足够地通用流行,才能被大部分程序使用起来。据我所知,vert.x的kotlin支持已经做了这样的封装。
虽然vert.x很流行,但是无法兼顾遗留代码以及代码中的锁阻塞等逻辑。因此不能算是最通用的选择。实际上Java程序有一个绕不过的库——JDK。Wisp就是在JDK里所有的阻塞调用出进行了非阻塞+事件恢复协程的方式支持了协程调度,在为用户带来最大便利的同时,兼顾了现有代码的兼容性。
上述方式支持了,每个线程不太需要阻塞,Wisp在Thread.start()处,将线程转成成了协程,来达到了另一目的: 活跃线程数约等于CPU个数。因此只需要使用Wisp协程,所有现有的Java多线程代码都可以获得异步的性能。
手工异步/Wisp性能比较
对于基于传统的编程模型的应用,考虑到逻辑清晰性、异常处理的便利性、现有库的兼容性,改造成异步成本巨大。使用Wisp相较于异步编程优势明显。
下面我们在只考虑性能的新应用的前提下分析技术的选择。
基于现有组件写新应用
如果要新写一个应用我们通常会依赖JDBC、Dubbo、Jedis这样的常用协议/组件,假如库的内部使用了阻塞形式,并且没有暴露回调接口,那么我们就没法基于这些库来写异步应用了(除非包装线程池,但是本末倒置了)。下面假设我们依赖的所有库都有回调支持,比如dubbo。
1)假设我们使用Netty接受请求,我们称之为入口eventLoop,收到请求可以在Netty的handler里处理,也可以为了io的实时性使用业务线程池。
2)假设请求处理期间需要调用dubbo,因为dubbo不是我们写的,因此内部有自己的Netty Eventloop,于是我们向dubbo内部的Netty eventLoop处理IO,等待后端响应后回调。
3)dubbo eventLoop收到响应后在eventloop或者callback线程池调用callback。
4)后续逻辑可以在callback线程池或者原业务线程池继续处理。
5)为了完成对客户端的响应最终总是要由入口的eventloop来写回响应。
我们可以看到由于这种封装导致的eventLoop的割裂,即便完全使用回调的形式,我们处理请求时多多少少要在多个eventLoop/线程池之间传递,而每个线程又都没法跑到一个较满的程度,导致频繁地进入os调度。与上述的每个线程不太需要阻塞原则相违背。因此虽然减少了线程数,节约了内存,但是我们得到的性能收益变得很有限。
完全从零开始开发
对于一个功能有限的新应用(比如nginx只支持http和mail协议)来说我们可以不依赖现有的组件来重新写应用。比如我们可以基于Netty写一个数据库代理服务器,与客户端的连接以及与真正后端数据库的连接共享同一个eventloop。
这样精确控制线程模型的应用通常可以获得很好的性能,通常性能是可以高于通过非异步程序转协程的,原因如下:
-
线程控制更加精确:举个例子,比如我们可以控制代理的客户端和后端连接都绑定在同一个netty线程,所有的操作都可以threadLocal化
-
没有协程的runtime和调度开销(1%左右)
但是使用协程依旧有一个优势:对于jdk中无处不在的synchronized块,wisp可以正确地切换调度。
适应的Workload
基于上述的背景,我们已经知道Wisp或者其他各种协程是适用于IO密集Java程序设计的。否则线程没有任何切换,只需要尽情地在CPU上跑,OS也不需要过多的干预,这是比较偏向于离线或者科学计算的场景。
在线应用通常需要访问RPC、DB、cache、消息,并且是阻塞的,十分适合使用Wisp来提升性能。
最早的Wisp1也是对这些场景进行了深度定制,比如hsf接受的请求处理是会自动用协程取代线程池,将IO线程数量设置成1个后使用epoll_wait(1ms)来代替selector.wakeup(),等等。因此我们经常受到的一个挑战是Wisp是否只适合阿里内部的workload?
-
对于Wisp1是这样的,接入的应用的参数以及Wisp的实现做了深度的适配。
-
对于Wisp2,会将所有线程转换成协程,已经无需任何适配了。
为了证明这一点,我们使用了web领域最权威的techempower benchmak集来验证,我们选择了com.sun.net.httpserver、Servlet等常见的阻塞型的测试(性能不是最好,但是最贴近普通用户,同时具备一定的提升空间)来验证Wisp2在常见开源组件下的性能,可以看到在高压力下qps/RT会有10%~20%的优化。
Project Loom
Project Loom作为OpenJDK上的标准协程实现很值得关注,作为java开发者我们是否应该拥抱Loom呢?
我们首先对Wisp和Loom这里进行一些比较:
1)Loom使用序列化的方式保存上下文,更省内存,但是切换效率低。
2)Wisp采用独立栈的方式,这点和go类似。协程切换只需切换寄存器,效率高但是耗内存。
3)Loom不支持ObectMonitor,Wisp支持。
synchronized/Object.wait()将占用线程,无法充分利用CPU。
还可能产生死锁,以Wisp的经验来说是一定会产生死锁(Wisp也是后来陆续支持ObectMonitor的)。
4)Wisp支持在栈上有native函数时切换(反射等等),Loom不支持。
对dubbo这样的框架不友好,栈底下几乎都带有反射。
总根据我们的判断,Loom至少还要2年时间才能到达一个稳定并且功能完善的状态。Wisp的性能优秀,功能要完整很多,产品本身也要成熟很多。Loom作为Oracle项目很有机会进入Java标准,我们也在积极地参与社区,希望能将Wisp的一些功能实现贡献进社区。
同时Wisp目前完全兼容Loom的Fiber API,假如我们的用户基于Fiber API来编程,我们可以保证代码的行为在Loom和Wisp上表现完全一致。
FAQ
协程也有调度,为什么开销小?
我们一直强调了协程适用于IO密集的场景,这就意味了通常任务执行一小段时间就会阻塞等待IO,随后进行调度。这种情况下只要系统的CPU没有完全打满,使用简单的先进先出调度策略基本都能保证一个比较公平的调度。同时,我们使用了完全无锁的调度实现,使得调度开销相对内核大大减少。
Wisp2为什么不使用ForkJoinPool来调度协程?
ForkJoinPool本身十分优秀,但是不太适合Wisp2的场景。
为了便于理解,我们可以将一次协程唤醒看到做一个Executor.execute()操作,ForkJoinPool虽然支持任务窃取,但是execute()操作是随机或者本线程队列操作(取决于是否异步模式)的,这将导致协程在哪个线程被唤醒的行为也很随机。
在Wisp底层,一次steal的代价是有点大的,因此我们需要一个affinity,让协程尽量保持绑定在固定线程,只有线程忙的情况下才发生workstealing。我们实现了自己的workStealingPool来支持这个特性。从调度开销/延迟等各项指标来看,基本能和ForkJoinPool打平。
还有一个方面是为了支持类似go的M和P机制,我们需要将被协程阻塞的线程踢出调度器,这些功能都不适宜改在ForkJoinPool里。
如何看待Reactive编程?
Reactive编程模型已经被业界广泛接受,是一种重要的技术方向;同时Java代码里的阻塞也很难完全避免。我们认为协程可以作为一种底层worker机制来支持Reactive编程,即保留了Reactive编程模型,也不用太担心用户代码的阻塞导致了整个系统阻塞。
这里是Ron Pressler最近的一次演讲,作为Quasar和Loom的作者,他的观点鲜明地指出了回调模型会给目前的编程带来很多挑战 。
Wisp经历了4年的研发,我将其分为几个阶段:
1)Wisp1,不支持objectMonitor、并行类加载,可以跑一些简单应用;
2)Wisp1,支持了objectMonitor,上线电商核心,不支持workStealing,导致只能将一些短任务转为协程(否则workload不均匀),netty线程依旧是线程,需要一些复杂且trick的配置;
3)Wisp2,支持了workStealing,因此可以将所有线程转成协程,上述netty问题也不再存在了。
目前主要的限制是什么?
目前主要的限制是不能有阻塞的JNI调用,wisp是通过在JDK中插入hook来实现阻塞前调度的,如果是用户自定义的JNI则没有机会hook。
最常见的场景就是使用了Netty的EpollEventLoop:
1)蚂蚁的bolt组件默认开启了这个特点,可以通过-Dbolt.netty.epoll.switch=false 来关闭,对性能的影响不大。
2)也可以使用-Dio.netty.noUnsafe=true , 其他unsafe功能可能会受影响。
3)(推荐) 对于netty 4.1.25以上,支持了通过-Dio.netty.transport.noNative=true 来仅关闭jni epoll,参见358249e5
![]()
你可能还喜欢
点击下方图片即可阅读