kafka生产过程相关总结
1、生产者消息发送流程
Kafka的producer发送消息采用的是异步发送的方式。在消息发送的过程中,涉及到了两个线程——main线程和Sender线程,以及一个线程共享变量——RecordAccumulator。main线程将消息发送给RecordAccumulator,Sender线程不断地从RecordAccumulator中拉取消息发送到Kafka broker。
2、生产者的分区
2.1、分区的原因
(1)便于合理使用资源,Kafka中将一个主题分成多个分区,分别放在多台机器上,生产者将消息轮询的发送到多台机器上,提高了topic负载能力,也提高了kafka集群负载能力,同时也提高了并发,因为可以以Partition为单位读写了。
(2)可以提高并发,因为可以以 Partition 为单位发送数据。
2.2、分区的策略
(1)指明 partition 的情况下,直接将指明的值直接作为 partiton 值。
(2)没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition 数进行取余得到 partition 值。
(3)既没有给定分区号,也没有给定key值,直接轮循进行分区。Kafka采用Sticky Partition(黏性分区器),会随机选择一个分区,并尽可能一直使用该分区,待该batch已满或者已完成,Kafka再随机一个分区进行使用(和上一次的分区不同)。 例如:第一次随机选择0号分区,等0号分区当前批次满了(默认16k)或者linger.ms设置的时间到, Kafka再随机一个分区进行使用(如果还是0会继续随机)。
(4)自定义分区。根据业务需要制定以分区策略。
2.3、自定义分区
public class MyPartitioner implements Partitioner {
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
Integer partitionNum = cluster.partitionCountForTopic(topic);
return key.hashCode() % partitionNum;
}
public void close() {
}
public void configure(Map configs) {
}
} 3、数据的可靠性
3.1、ack应答级别
ack=0: producer 不等待 broker落盘便会应答 ,这一操作提供了一个最低的延迟,broker 一接收到还没有写入磁盘就已经返回,当 broker 故障时有可能丢失数据。
ack=1: producer 等待 broker 的 ack,partition 的 leader 落盘成功后返回 ack,如果在 follower同步成功之前 leader 故障,那么将会丢失数据。
ack=-1:producer 等待 broker 的 ack,partition 的 leader 和 ISR队列里的所有节点落盘成功后才返回 ack。但是如果在 follower 同步完成后,broker 发送 ack 之前,leader 发生故障,那么会造成数据重复。
3.2、ISR的概念
设想以下情景:leader 收到数据,所有 follower 都开始同步数据,但有一个 follower,因为某种故障,迟迟不能与 leader 进行同步,那 leader 就要一直等下去,直到它完成同步,才能发送 ack。这个问题怎么解决呢?
为了解决这个问题,Leader 维护了一个动态的 in-sync replica set (ISR),意为和 leader 保持同步的 follower 集合。当 ISR 中的 follower 完成数据的同步之后,leader 就会给 follower 发送 ack。如果 follower长时间未向 leader 同步数据 , 则该 follower 将被踢出 ISR , 该时间阈值由replica.lag.time.max.ms 参数设定。Leader 发生故障之后,就会从 ISR 中选举新的 leader。
3.3、数据完全可靠条件:(和钱相关的业务)
ASK级别设置为-1 + 分区副本大于等于2 +ISR队列里应答的最小副本数量大于等于2
3.4、Exactly Once 语义
Exactly Once为精确一次消费,将服务器的 ACK 级别设置为-1,可以保证数据不丢失,但无法保证数据不重复。
这时候引入了一项重大特性:幂等性(默认开启)
所谓的幂等性就是指 Producer 不论向 Server 发送多少次重复数据,Server 端都只会持久化一条。开启幂等性的 Producer 在初始化的时候会被分配一个 PID,发往同一 Partition 的消息会附带 Sequence Number。而Broker 端会对
Exactly Once=ASK级别设置为-1 + 幂等性
3.5、Producer 事务
由于PID 重启就会变化,同时不同的 Partition 也具有不同主键,所以幂等性无法保证跨分区跨会话的 Exactly Once。这时候就引出了Producer事务的概念。
为了实现跨分区跨会话的事务,需要引入一个全局唯一的 Transaction ID,并将 Producer 获得的PID 和Transaction ID 绑定。这样当Producer 重启后就可以通过正在进行的 Transaction ID 获得原来的 PID。
为了管理 Transaction,Kafka 引入了一个新的组件 Transaction Coordinator。Producer 就是通过和 Transaction Coordinator 交互获得 Transaction ID 对应的任务状态。Transaction Coordinator 还负责将事务所有写入 Kafka 的一个内部 Topic,这样即使整个服务重启,由于事务状态得到保存,进行中的事务状态可以得到恢复,从而继续进行。
4、数据的有序
4.1、分区内
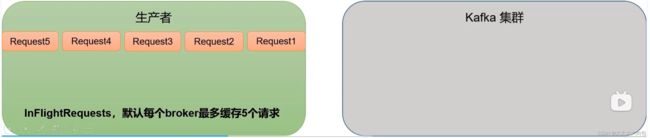
对于生产者缓冲的5个请求,如果第一个请求没问题,第二请求有问题,没有接收,第三个请求接着就来了,没问题,这时候第二个请求又没问题了,成功接收,最终的效果变是请求三会出现在请求二的前面,出现了无序的情况。
解决这个问题只需开启幂等性并且max.in.flight.requests.per.connection设置小于等于5。
原因说明:开启幂等性后,kafka服务端会缓存producer发来的最近5个request的元数据,会确保近5个request的数据是有序的。
4.2、全局中
根据业务的相关要求,编写自定义的分区,来实现全局的一个有序。
5、实现一个消费者Demo
public class demo {
public static final String brokerList = "master:9092,slave1:9092,slave2:9092";
public static final String topic = "test1";
public static Properties initConfig() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
//指定自定义分区器
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"cn.kafka.MyPartitioner");
//提高生产者的吞吐量
//设置缓冲区大小
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432);
//设置批次大小 默认16K
props.put(ProducerConfig.BATCH_SIZE_CONFIG,16384);
//设置等待时间 一般为5 - 100
props.put(ProducerConfig.LINGER_MS_CONFIG,5);
//设置压缩的格式
props.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"snappy");
// 设置 acks
props.put(ProducerConfig.ACKS_CONFIG, "-1");
// 重试次数 retries,默认是 int 最大值,2147483647
props.put(ProducerConfig.RETRIES_CONFIG, 3);
//指定事务id
props.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG,"transaction_id_test1");//必须唯一
return props;
}
public static void main(String[] args) {
Properties props = initConfig();
KafkaProducer producer = new KafkaProducer(props);
//初始化事务
producer.initTransactions();
//开始事务
producer.beginTransaction();
try {
ProducerRecord record = new ProducerRecord(topic, "hello world");
producer.send(record, new Callback() {
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null){
System.out.println(metadata.partition() + "-" + metadata.offset());
}
}
}).get(); //加get方法 就是异步传送
//提交事务
producer.commitTransaction();
}catch (Exception e){
//终止事务
producer.abortTransaction();
}finally {
//关闭资源
producer.close();
}
}
}