基于Pytorch的YoLoV5 backbone 复现(上)
文章目录
- 前言
- 网络结构
- 参考设计图
-
- Focus模块
- Conv 卷积模块
- 残差模块
- C3 模块
- l x s m 的区别
前言
现在我们来做一个简单的总结,最近也是在复盘嘛,看看这个学期阶段的学习成果,巩固和增强,系列笔记还在整理,我给自己的复盘时间大概是1个月左右,这个礼拜当然是有关于深度学习的内容主要是YOLO,下周是自己课内的东西。
这篇博文也是准备了两天左右,仔细瞅了瞅V1~V3的论文,V4,V5 我还没看,因为从发展的角度来看V1到V3的改动是很大的,V4,V5更多是在神经网络的结构上优化。而我们今天的任务是如何复现出YOLOV5的backbone。
理论再好也要实践,这样可以加深理解和映像,接下来我们需要使用YOLO来做更加炫酷的事情,所以这一关是我无法逾越的关卡。
本博文基于YOLOV5.5版本进行探索~
考虑到篇幅问题,这里会拆成两篇博文进行复现。
网络结构
在开始之前我们先来看看整个yolov5的网络结构
这个是完整的神经网络结构,可以通过
https://netron.app/ 生成
不过我们不会直接使用这张图来看,因为你会发现这里面其实有很多重复的,我们采用这样图来实现
参考设计图
由于实际的图不好理解我们来参考知乎大佬:江大白 的图片
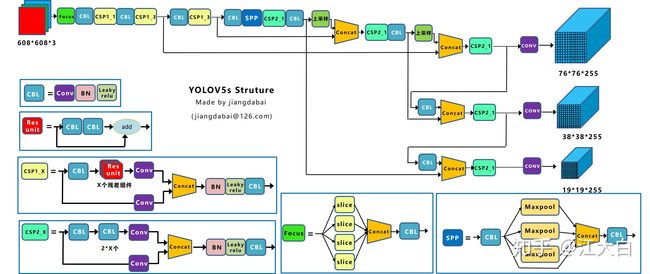
接下来我们就开始来对每一个模块进行说明。
(这里注意实际上我们当前版本是输入batch_size x 3 x 640 x 640 的图片)
并且我们实际的图和这个参考图纸是不太一样的,具体的其实还是以我们上面那张图为准,大概长啥样子,我都会贴出来。
Focus模块
在开始之前注意到有个玩意

这个玩意是干了这样的事情
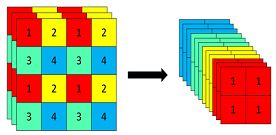
代码是这样的
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act) # 这里输入通道变成了4倍
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
原始的3 x 640 × 640 的图像输入Focus结构,采用切片操作,先变成12 x 320 × 320的特征图
这里代码里面是将一张图片切成4份,每一份有原来的3个通道,所以 这里是c1*4。并且你应该注意到了这个第一个CONV的W的大小是64 x 32 x3 x3
这个也很好解释,一张图片本来是 .3 x 640 x 640 卷积核大小 3 x 3 按道理如果输出一个通道的话 那么 就是 3 x 3 x 3 此时输出32个通道就是 32 x 3 x 3 x 3 但是你有4份就是12个所以就是 32 x 12 x 3 x 3。
具体的推导可以看这张图

接下来就是我们的其他模块
Conv 卷积模块
这个在YOLOV5里面为了放置各种训练问题,它做了不少优化,首先是一开始的训练的时候有数据增强的处理,然后就是在卷积的时候,有归一化的处理,防止参数差距很大带来的干扰。
class Conv(nn.Module):
def __init__(self,c1,c2,k=1,s=1,p=None,g=1,act=True):
super(Conv,self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
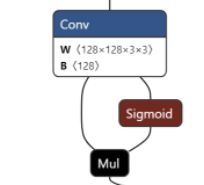
这里注意的是这个Sigmoid 是这个玩意和RULE其实很像,但是人家<0 有负值

这里的话多一嘴,其实这个卷积核和我们线性权重是类似的,只不过人家做到是矩阵微分,没那么神秘。
然后这里对应的图中应该是CBL模块,不过在咱们这里是Conv。
残差模块
这个对应的其实就是这个模块了CSP1_x 模块
在我们当前版本是这样的
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))

C3 模块
这个模块是这个样子的,和残差有点像,但是人家不是相加,而是扩充。
它是保留了一部分,然后进入残差,最后做一个融合。
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(C3, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
这个“砍”一半是通过卷积实现的,通过把通道砍到原来的0.5倍实现了留下一半,然后通过残差模块self.m(cv1)
实现卷积部分,然后在通过cat合并。

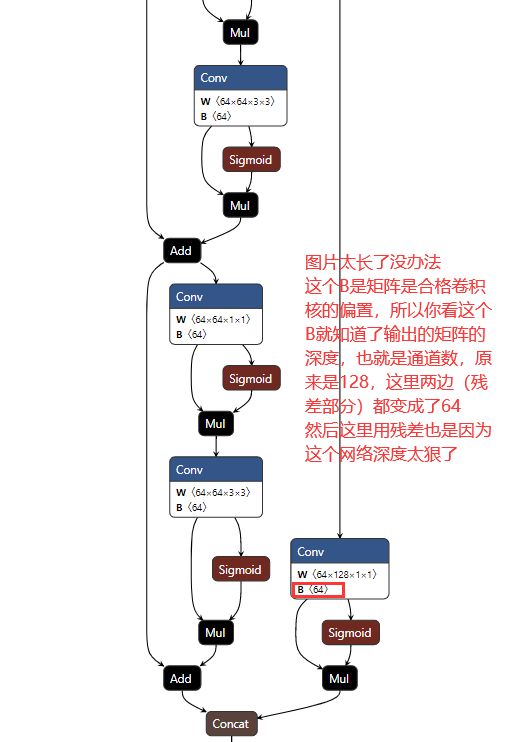
基本上我们实际的网络架构图里面有的东西就有了,当然这里面其实还有很多门道,你仔细看common文件里面就知道,这些东西的话需要结合论文来说,我这里不好说,为了这个玩意儿我至少看了5,6篇论文,还要整理。
之后在V3这个版本提出来的这个7x7 13x13 26x26的grad cell 在咱们这里就是(当然在这里已经不是那么小的grad cell了)

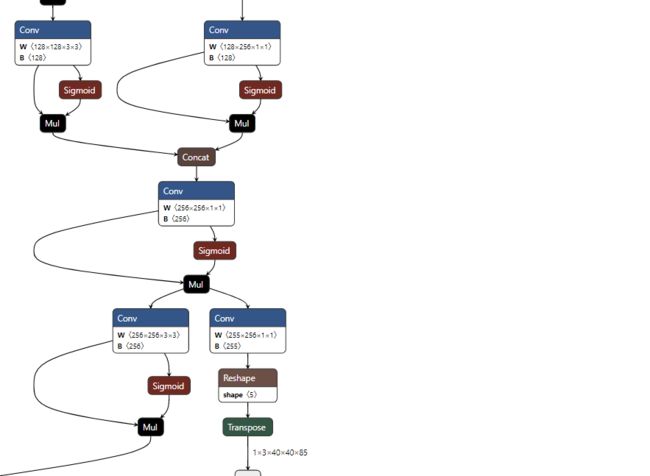
这个就是和江大白老师的那个图类似了。
后面就是不断重复。
l x s m 的区别
到这里了我们再来聊聊咱们这个yolov5后面的这些后缀表示了啥吧。

其实这个你打开这个yolov5xx.yaml 你就知道了。
你会发现除了这个
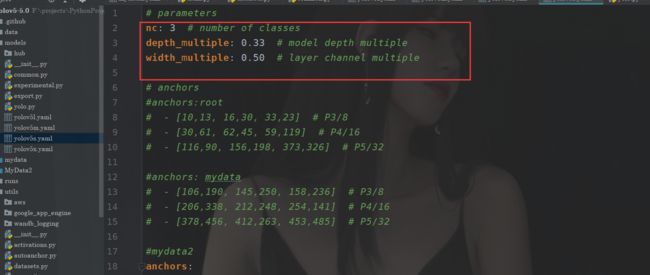
不同,其他的都类似。
其实这两个参数表示了你的网络的深度和宽度,例如width_multiple 这里是0.5
如何控制你的输出咧?很简单。
你的卷积输出的通道数的大小乘上width_mulitple其实就是控制了深度,例如我这了输出128个通道,原来设置的,但是我这里乘上0.5 这样输出的就是64个,这样一来宽度小了。那么深度呢,也很简单。还记得CSP1_X 嘛
那个再江大白老师里面的图里面表示的就是你有几个残差重复的,我假设标准的设定是CSP1_3(假设有一个模块)现在3x0.3取整数为1 那么我这个CSP1_3 实际上就是只有一个残差,以此类推于是我们的这个深度就下来了。最标准的是yolov5l.pt 因为设置都是1.0。