java面试 上传文件_字节跳动面试官,我也实现了大文件上传和断点续传
前言
前几天看到一个文章,感触很深
作者从0实现了大文件的切片上传,断点续传,秒传,暂停等功能,深入浅出的把这个面试题进行了全面的剖析
彩虹屁不多吹,我决定蹭蹭热点,录录视频,把作者完整写代码的过程加进去,并且接着这篇文章写,所以请看完上面的文章后再食用,我做了一些扩展如下
计算hash耗时的问题,不仅可以通过web-workder,还可以参考React的FFiber架构,通过requestIdleCallback来利用浏览器的空闲时间计算,也不会卡死主线程
文件hash的计算,是为了判断文件是否存在,进而实现秒传的功能,所以我们可以参考布隆过滤器的理念, 牺牲一点点的识别率来换取时间,比如我们可以抽样算hash
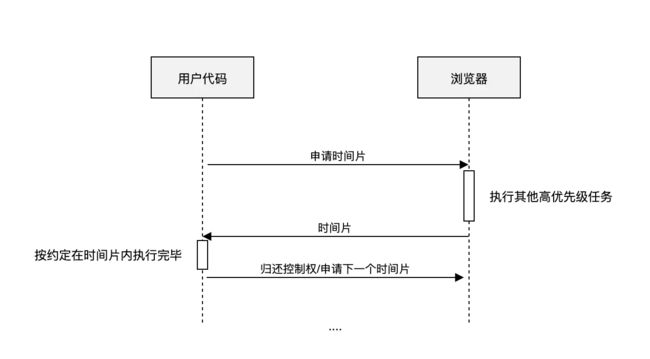
文中通过web-workder让hash计算不卡顿主线程,但是大文件由于切片过多,过多的HTTP链接过去,也会把浏览器打挂 (我试了4个G的,直接卡死了), 我们可以通过控制异步请求的并发数来解决,我记得这也是头条的一个面试题
每个切片的上传进度不需要用表格来显示,我们换成方块进度条更直管一些(如图)
并发上传中,报错如何重试,比如每个切片我们允许重试两次,三次再终止
由于文件大小不一,我们每个切片的大小设置成固定的也有点略显笨拙,我们可以参考TCP协议的慢启动策略, 设置一个初始大小,根据上传任务完成的时候,来动态调整下一个切片的大小, 确保文件切片的大小和当前网速匹配
小的体验优化,比如上传的时候
文件碎片清理
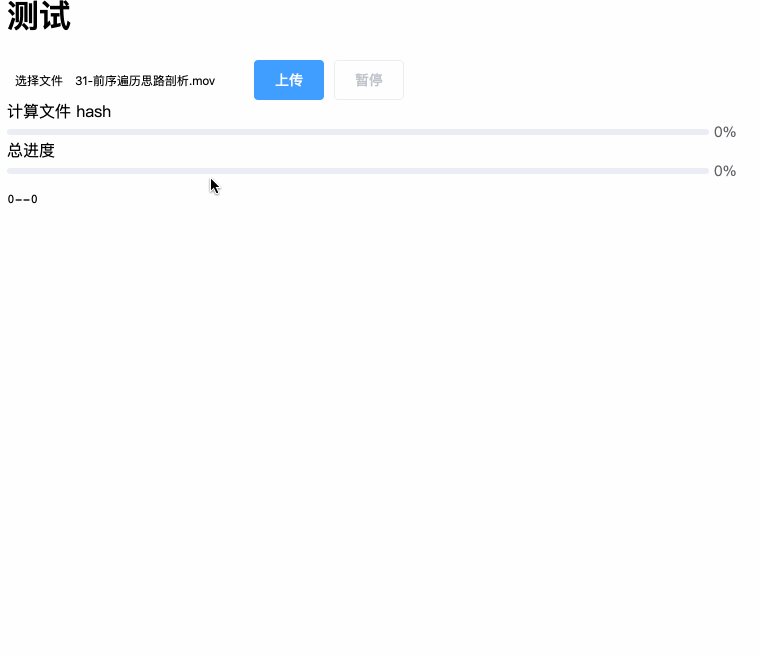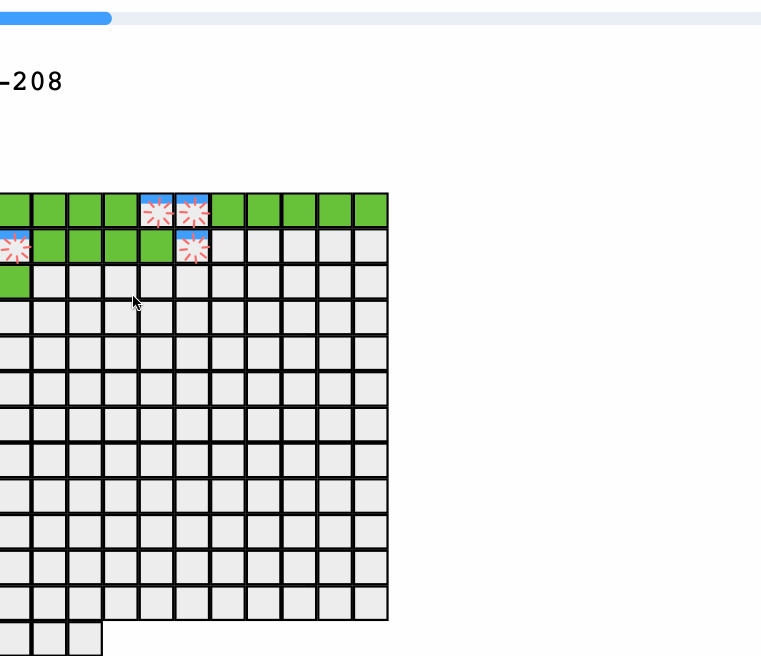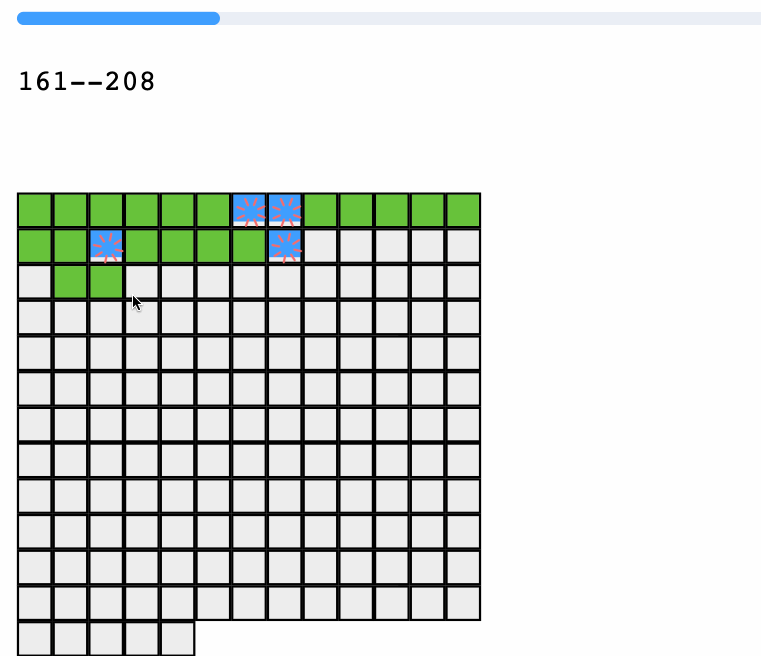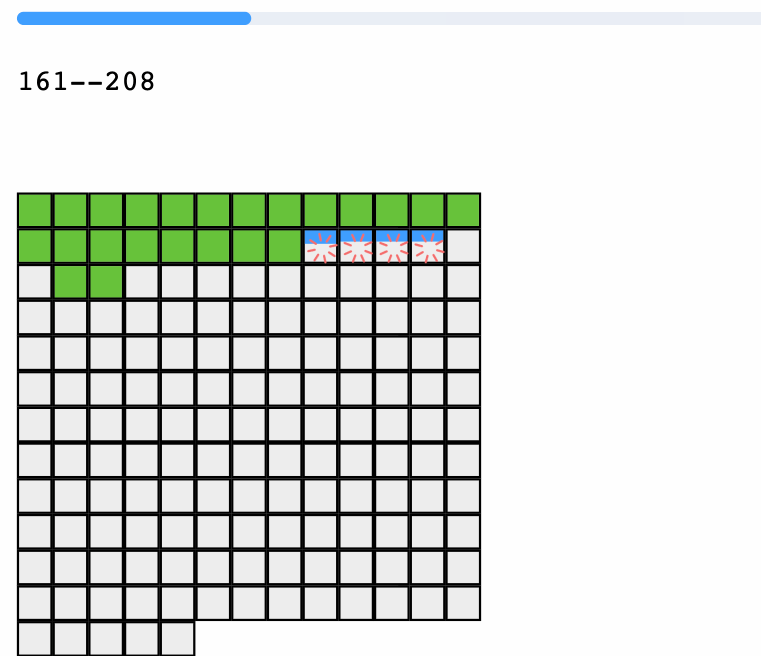
已经存在的秒传的切片就是绿的,正在上传的是蓝色的,并发量是4,废话不多说,我们一起代码开花
时间切片计算文件hash
其实就是time-slice概念,React中Fiber架构的核心理念,利用浏览器的空闲时间,计算大的diff过程,中途又任何的高优先级任务,比如动画和输入,都会中断diff任务, 虽然整个计算量没有减小,但是大大提高了用户的交互体验
requestIdleCallback
window.requestIdleCallback()方法将在浏览器的空闲时段内调用的函数排队。这使开发者能够在主事件循环上执行后台和低优先级工作
requestIdelCallback执行的方法,会传递一个deadline参数,能够知道当前帧的剩余时间,用法如下
requestIdelCallback(myNonEssentialWork);
function myNonEssentialWork (deadline) {
// deadline.timeRemaining()可以获取到当前帧剩余时间
// 当前帧还有时间 并且任务队列不为空
while (deadline.timeRemaining() > 0 && tasks.length > 0) {
doWorkIfNeeded();
}
if (tasks.length > 0){
requestIdleCallback(myNonEssentialWork);
}
}
复制代码
deadline的结构如下
interface Dealine {
didTimeout: boolean // 表示任务执行是否超过约定时间
timeRemaining(): DOMHighResTimeStamp // 任务可供执行的剩余时间
}
复制代码

该图中的两个帧,在每一帧内部,TASK和redering只花费了一部分时间,并没有占据整个帧,那么这个时候,如图中idle period的部分就是空闲时间,而每一帧中的空闲时间,根据该帧中处理事情的多少,复杂度等,消耗不等,所以空闲时间也不等。
而对于每一个deadline.timeRemaining()的返回值,就是如图中,Idle Callback到所在帧结尾的时间(ms级)
时间切片计算
我们接着之前文章的代码,改造一下calculateHash
async calculateHashIdle(chunks) {
return new Promise(resolve => {
const spark = new SparkMD5.ArrayBuffer();
let count = 0;
// 根据文件内容追加计算
const appendToSpark = async file => {
return new Promise(resolve => {
const reader = new FileReader();
reader.readAsArrayBuffer(file);
reader.onload = e => {
spark.append(e.target.result);
resolve();
};
});
};
const workLoop = async deadline => {
// 有任务,并且当前帧还没结束
while (count < chunks.length && deadline.timeRemaining() > 1) {
await appendToSpark(chunks[count].file);
count++;
// 没有了 计算完毕
if (count < chunks.length) {

关于找一找教程网
本站文章仅代表作者观点,不代表本站立场,所有文章非营利性免费分享。
本站提供了软件编程、网站开发技术、服务器运维、人工智能等等IT技术文章,希望广大程序员努力学习,让我们用科技改变世界。
[字节跳动面试官,我也实现了大文件上传和断点续传]http://www.zyiz.net/tech/detail-109137.html