kafka入门使用
略过下载及安装,值得注意的是,启动kafka之前需要先启动zookeeper,kafka依赖于zookeeper。kafka跟我们所认知的传统消息队列有所不同,它衍生的一些概念比如消费者组,topic,partition等,如果没有kafka的使用经验似乎有点难以理解。
配置server.properties
broker.id=0:集群唯一id
log.dirs=/usr/local/data/kafka-logs:kafka消息存放文件
log.retention.hours=168:kafka消息保留时间,默认7天
zookeeper.connect=node01:2181:zookeeper地址
启动
bin/kafka-server-start.sh -daemon config/server.properties
或者
bin/kafka-server-start.sh config/server.properties &创建topic:test
bin/kafka-topics.sh --create --zookeeper 192.168.43.11:2181 --replication-factor 1 --partitions 1 --topic test查看topic
bin/kafka-topics.sh --list --zookeeper node01:2181生产者向kafka发送消息
bin/kafka-console-producer.sh --broker-list node01:9092 --topic test
开启消费者消费消息
在生产者发送第一个消息“rick1”之后执行以下命令, 生产者继续向kafka发送消息,消费者只会从当前发送的消息开始消费。
bin/kafka-console-consumer.sh --bootstrap-server node01:9092 --topic test
当然也可以通过以下命令从头开始消费topic里的消息
bin/kafka-console-consumer.sh --bootstrap-server 192.168.43.11:9092 --from-beginning --topic test
单播消息
在同一个消费者组里,生产者向同一个topic中发送消息,消费者组里永远只有一个消费者可以消费消息。现在同时开启两个消费者,并声明消费者组为testGroup:
bin/kafka-console-consumer.sh --bootstrap-server node01:9092 --consumer-property group.id=testGroup --topic test生产者继续向kafka发送消息,最终只有一个消费者会消费消息如下图:

![]()
多播消息
要实现多播消息,只能将这些消费者在不同的消费者组里,只需在增加一个消费者,而这个消费者属于testGroup-2这个消费者组。
bin/kafka-console-consumer.sh --bootstrap-server node01:9092 --consumer-property group.id=testGroup-2 --topic test查看消费者组
bin/kafka-consumer-groups.sh --bootstrap-server 192.168.43.11:9092 --list查看消费者组的偏移量
bin/kafka-cumer-groups.sh --bootstrap-server node01:9092 --describe --group testGroup
CURRENT-OFFSET:当前消费者组在partition中已消费消息的偏移量
LOG-END-OFFSET:topic对应当前partition的结束偏移量
LAG :当前消费者组未消费消息的数量
topic和group(消费者组)的理解
到这里,重新理解下topic和group这两个概念,消费者按组进行划分,group包含了很多具体的消费者,kafka中消费消息时按group为单位进行消费的,同一个队列的消息只能被消费者组中某一个消费者消费一次。而这个队列我们可以抽象的理解为topic,topic也可以理解为某一类消息,比如在电商系统中,按照消息的类型划分为日志、订单等,而日志,订单在kafka中就可以被分类为topic。真正存储消息的是partition
partition
partition是承载消息的物理存储。Partition是一个有序的message序列,这些message按顺序添加到一个叫做commit log的文件中。每个partition中的消息都有一个唯一的编号,称之为offset,用来唯一标示某个分区中的message。 每个consumer是基于自己在commit log中的消费进度(offset)来进行工作的。在kafka中,消费offset由consumer自己来维护;
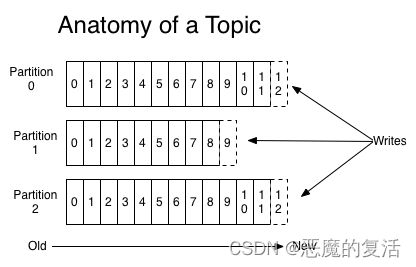
创建两个partition的topic
bin/kafka-topics.sh --create --zookeeper node01:2181 --replication-factor 1 --partitions 2 --topic test1
bin/kafka-topics.sh --describe --zookeeper node01:2181 --topic test1
可以看到,topic为test1的共有两个partition:0和1,而他们的leader都是0(集群中唯一id),由于创建test1的topic时只指定了一个副本,所以只包含一个Replicas(副本)还是0。Isr 是replicas的一个子集,它只列出当前还存活着的,并且已同步备份了该partition的节点。
新增partition
bin/kafka-topics.sh -alter --partitions 3 --zookeeper node01:2181 --topic test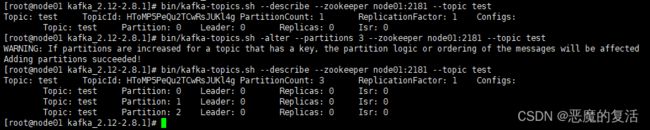
为什么要对Topic下数据进行分区存储?
1、分布式存储,使kafka能存储海量数据。
2、提高消费者消费消息的并行度。
kafka集群
对于kafka来说,一个单独的broker意味着kafka集群中只有一个节点。要想增加kafka集群中的节点数量,只需要多启动几个broker实例即可。我启动了三个节点
创建副本为3个,分区为2个的topic
bin/kafka-topics.sh --create --zookeeper node01:2181 --replication-factor 3 --partitions 2 --topic my-topic查看my-topic的描述:0号分区Leader所在的节点为broker.id=2,两个副本是0和1,Isr表示当前活着并且已同步数据的副本。

java生产者
Properties props = new Properties();
//声明连接kafka的集群,也可以只填一个地址,但是建议写全,防止单一服务不可用导致连不上
props.put("bootstrap.servers", "node01:9092, node02:9092, node03:9092");
//发出消息持久化参数:
//acks=0:表示消息发送以后,直接返回,无需等待kafka集群中Leader写磁盘
//acks=1:消息发送以后,线程等待partition的Leader副本写入磁盘成功后返回
//acks=-1或all:消息发送以后,线程等待min.insync.replicas(默认为1,推荐配置大于等于2) 这个参
//数配置的副本个数都成功写入日志.安全级别最高
props.put("acks", "all");
//消息发送失败,重发次数,保证不丢失消息,但也有可能造成消息重复消费,需要在接受者中做幂等处理。
//消息重发时间间隔参数:retry.backoff.ms,默认100ms
props.put("retries", 0);
//IO线程每次会从缓冲区中取batchSize大小的消息发送出去
props.put("batch.size", 16384);
//如果有消息则每隔1ms发送一次
props.put("linger.ms", 1);
//设置本地消息缓冲区大小,默认32M
props.put("buffer.memory", 33554432);
//指定key的序列化方式
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//指定value的序列化方式
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer producer = new KafkaProducer<>(props);
for(int i = 0; i < 100; i++)
//send()是异步发送的,一旦消息发送到等待发送的缓冲区(buffer.memory)就返回,当消息发送到kafka集群后并返回IO线程会调用callback
producer.send(new ProducerRecord("my-topic", Integer.toString(i), Integer.toString(i)), callback);
producer.close(); java消费者
Properties props = new Properties();
props.setProperty("bootstrap.servers", "node01:9092, node02:9092, node03:9092");
//设置消费组,
props.setProperty("group.id", "test");
//是否自动提交offset:消费者向kafka集群提交自己消费partition的offset,
//默认是true,但是建议设置false,手动提交消息消费完成后调用consumer.commitSync();
props.setProperty("enable.auto.commit", "true");
//自动提交offset的间隔时间
props.setProperty("auto.commit.interval.ms", "1000");
//设置key和value的反序列化方式
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
while (true) {
//如果拉取到消息会立刻返回消息,否则poll将持续拉取消息100ms并返回null。
ConsumerRecords records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
} 手动提交offset
props.setProperty("enable.auto.commit", "false");
final int minBatchSize = 200;
List> buffer = new ArrayList<>();
while (true) {
ConsumerRecords records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord record : records) {
buffer.add(record);
}
if (buffer.size() >= minBatchSize) {
insertIntoDb(buffer);
consumer.commitSync();
buffer.clear();
}
} kafka同时支持以下的操作:从头开始消费,指定分区号消费,指定offset消费消息以及指定时间点开始消费等功能
//表示当指定offset消费或者新的消费组加入消费时
//配置earlist表示从头开始消费或者从指定offset的位置开始消费
//配置latest(默认)表示消费者启动后开始消费生产者以后发送的消息
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 消费者指定分区消费
consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));
//无论当前是否消费过消息,都从头开始消费topic指定分区的所有消息
consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));
consumer.seekToBeginning(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));
//指定offset消费
consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));
consumer.seek(new TopicPartition(TOPIC_NAME, 0), 3);