FSA-Net学习笔记
头部姿态论文阅读笔记1:FSA-Net
-
- (一) 术语:
- (二) FSA-Net 论文理解:
-
-
- 1. 头部姿态检测:
- 2. SSR-Net-MD:
- 3. FSA-Net:
- 4. scoring function:
- 5. 结果:
-
- (三) 代码:
-
- 1. 预处理模块:
- 2. 训练测试模块:
- 3. Demo:
- (四) 总结:
- (五) 参考博客:
(一) 术语:
1. SOTA model: state-of-the-art model:目前最好的模型,达到SOTA指的是该模型在该领域中表现最好。
2. SOTA result: state-of-the-art result,指的是在该项研究任务中,目前最好的模型的结果。
3.SSR-Net: 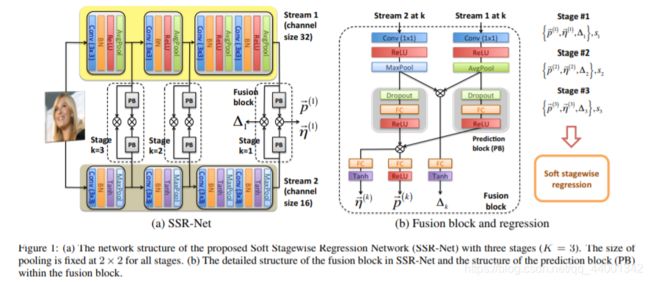
SSR-Net的全称是:Soft Stagewise Regression Network,意为软阶段回归网络,采用CNN为主框架,最早提出时是为了完成年龄预测任务,SSR-Net的网络模型如上图所示。
SSR-Net的主要思想是分类思想,在原文中将年龄按照跨度进行细分,例如0~90岁的年龄跨度为V=90, 再根据 Stage k 将年龄划分为一个个阶段,完成一个大的分类;在大的分类之下,再进行细分,例如 s1 = s2 = 3,表示将每个年龄段再细分为3类。举例: K = 2,那么在第一阶段 K=1时,根据 s1 = 3,将(0,90)划分为(0,30)(30,60)(60,90)三个层次;在第二个阶段 K = 2时,根据 s2 = 3, 再将 s1 阶段划分好的bin细分为(0,10)(10,20)(20,30)…等等。
最后用两个异构流,即 stream 1与 stream 2 融合互补。这两种stream的基本结构为:3×3卷积层、归一化批处理、非线性激活层 和 2×2 的池化层组成,每个流都采用不同类型的激活函数使它们异构。不同阶段 K 采用不同层次的特征,对于每个阶段,来自两个 stream 的特性被输入到一个融合块中用于信息互补与提升性能。
SSR-Net原文
(二) FSA-Net 论文理解:
论文名: FSA-Net: Learning Fine-Grained Structure Aggregation for Head Pose Estimation from a Single Image
FSA-Net 原文
(昨天追剧去了,geigeigeigeigei)
FSA-Net 是2019年CVPR中的一篇文章,中文译作:‘学习从单个图像进行头部姿态估计的细粒度聚合结构’,文章的大体是对前面提到的方法SSR-Net的改进,并将其应用到了头部姿态估计领域。
文章的整体架构:首先介绍了头部姿态的估计的方法,采用MEA(平均绝对误差)来评估预测函数F和真实值之间的差异,MEA越小,代表结果越理想。其次,介绍了基于SSR-Net的改进版本SSR-Net-MD,内容大体和SSR-Net差不多,应用在头部姿态估计方面。最后,介绍了 FSA-Net,在FSA-Net模块中,采用了一个评分模块score,将前面得到的特征图Uk转换为注意力图谱AK;再通过细粒度结构映射将结果输入到SSR-Net-MD网络中。
1. 头部姿态检测:
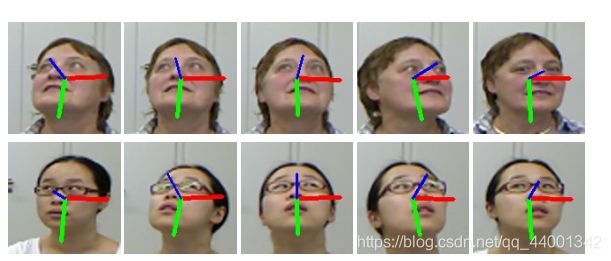
头部姿态是3D矢量,头部姿态的矢量分量包含偏航角(yaw),俯仰角(pitch)和滚转角(roll),说的通俗点也就是抬头,摇头和转头的角度问题。如上图所示,蓝色的代表偏航角,绿色的代表俯仰角,红色的代表滚转角。由于图片是二维的,缺失了头部姿态所需的关键三维信息,传统方法通常采用人脸特征点检测或者用深度信息来补全三维信息。
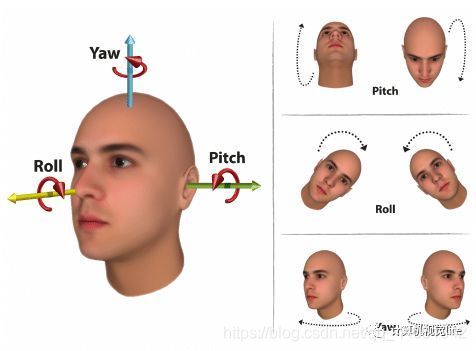
头部姿态的检测可以通过检测关键特征来实现,例如计算鼻子,脸颊的偏转等。一些优秀的方法可以将头部的各个特征聚合起来,通俗的说就是利用多个头部的特征信息来计算头部偏转。优秀的方法有:胶囊网络(capsule), NetVLAD等,但是传统方法大多将头部的整体作为特征计算的输入,忽略了特征之间的空间信息,例如:计算了鼻子和嘴巴的特征信息后整合在一起,但是没有利用鼻子在嘴巴上面这一空间特性。作者就提出了一个细粒度聚合结构:将特征细化为区域特征,利用空间编码表示区域特征之间的空间位置关系。
头部姿态检测的方法如下:
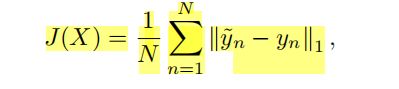
给定n个图像序列X={x1,x2,x3…xn},以及每个图像的姿态向量 y,姿态向量 y 包含了三个矢量分量,分别对应yaw,pitch,roll,方法是通过最小化面部预测值和真实值之间的误差的平均绝对值,来找到目标函数 F, 使得其尽可能拟合真实人脸。y˜n 为预测值,yn为真实值。
2. SSR-Net-MD:
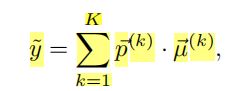
SSR-Net-MD是SSR-Net的变体,SSR-Net将年龄划分为一个个bin,通过神经网络计算年龄的概率分布,再由概率分布的期望值反过来估计图片中人物的年龄;结合前面对SSR的介绍,若有阶数K,在每一阶段只对年龄进行中间分类(大了,刚好,小了),而下一阶段中再对前一阶段进行细分,最后利用一个软分期回归来估计年龄。
如上图所示,y˜代表年龄的预估值,K为阶数,p(k)为第k阶段的年龄的概率分布,μ(k)为第k阶段年龄的代表值所组成的向量;为了增加容错率,加入位移因子η(k):使得每类年龄的中心有所偏移;加入缩放因子Δk:用于缩放年龄组的容量;最终得到的结果是:输入一幅图像,SSR-Net输出第K阶段年龄组的参数:{p(k), η(k), Δk},再将这些参数代入上图公式,得到年龄的预估值。
头部姿态是三维估计,而年龄是二维估计,作者将其改为SSR-Net-MD,以应用到头部姿态估计中,具体的改进在下节中介绍。
3. FSA-Net:
FSA-Net的整体结构如下:
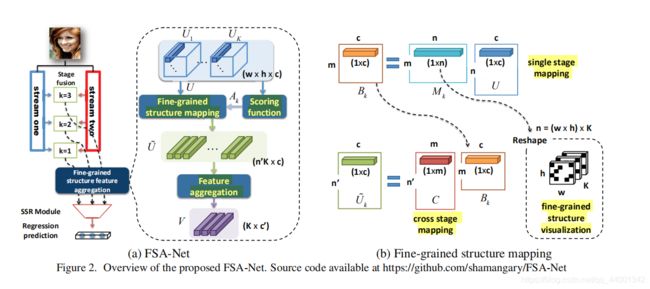
首先,采用一个双异构流即 stream one 和 stream two,采用双 stream 的目的是两个stream之间可以互相补充有效信息,每个stream所采用的结构都不相同:
stream 1的结构为:{ BR(16) - AvgPool(2×2) - BR(32) - BR(32) - AvgPool(2×2)} - {BR(64)-BR(64) - AvgPool(2×2)} - {BR(128) - BR(128)}。
stream2的结构为:{ BT(16) - MaxPool(2×2) - BT(32) - BT(32) - MaxPool(2×2)} - {BT(64) - BT(64) - MaxPool(2×2)} - {BT(128) - BT(128)}。
是不是晕了? 拆开来看:BR(c) = { SepConv2D (3×3, c) - BN - ReLU}, BT(c)= { SepConv2D(3×3, c) - BN - Tanh};其中,SepConv2D 是可分离 2D 卷积;BN为批处理标准化操作,c 为参数。AvgPool 代表的是平均池化层,MaxPool 代表的是最大池化层。因此 stream1 的结构就可以分解为由BR+平均池化+BR+BR+平均池化组成的一层网络和BR+BR+平均池化+BR+BR组成层的二层网络。
在双异构流中,每个stream在每一阶段的K中都提取一个特征映射;利用阶段融合模块,通过元素相乘的方式在每一阶段将两个stream提取的特征进行融合(中间的绿色方框),而不是等到最后再融合;利用阶段融合模块,通过元素相乘的方式在每一阶段将两个stream提取的特征进行融合,而不是等到最后再融合;将融合后的特征利用1x1的卷积转换到卷积通道c中,这一部分为细粒度结构映射模块。如(b)所示;
之后得到大小为W x H x C大小的特征图:Uk,Uk分为一个个单元,每个单元格都存放了相应的特征空间信息;将特征图Uk输入到SSR-Net中来获得参数:{p(k), η(k), Δk}。这样做的好处是,利用全局空间信息编码取代像素编码作为特征聚合模块的输入,即考虑到了特征之间的空间相关性。
在细粒度结构映射中(Fine-grained structure mapping),首先将特征Uk平铺到二维矩阵中,矩阵中包含了所有阶中所有的特征映射的c-d空间特征,再利用n个像素级特征的线性组合对细粒度聚合结构提取出的n个代表性特征进行表示,达到降维的目的;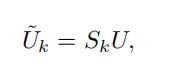
如上图所示,在第K阶段,通过映射结构找到一个该阶段的映射Sk,选择特征U中的n个具有代表性的特征放在Uk中。而特征映射Sk又可以分解为:
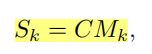
C为所有阶段共享的特征图谱,Mk为第k阶段的特征图谱,二者组成如下:
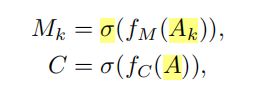
其中σ是sigmoid函数;fM和fC是由全连通层定义的两个不同的功能;而 A = [A1, A2,…] 是所有注意力图的连接。fM 和 fC 都是端到端可训练的 FSANet 的一部分,通过对训练数据的学习得到。特征图谱Mk的每一行可以折叠成大小为w × h的 K 个地图,每个地图代表像素级特征在空间上对特定行对应的代表特征的贡献。因此,每一行Mk可以看作是一种对姿态估计具有显著性的细粒度结构(细粒度结构名称的由来?)
4. scoring function:
评分模块的主要作用是为了证明前面利用空间信息编码的有效性。在评分模块中,通过评分机制将特征图 Uk 转换为注意力图 Ak。文章中采用了三种评估函数:(1)1X1的卷积(2)方差(3)均值。
(1)卷积评分函数 :Φ(u) = σ(w · u), 其中σ为sigmod函数,w为可学习的卷积核。用该方法时,如果训练数据与测试数据差距过大时,可能出现过拟合问题;(2)方差公式:
![]()
![]()
方差虽然可微,但该方法不具有学习性。最后是(3)均值函数:Φ(u)=1。三种情况分别对应:可学习,不可学习,以及不变特征。三种方法的侧重点不同,文章中将三种方法得到的数据加权取均值,整体性能最优,即文章中提到的:FSA-Fusion。得到转准换后的注意力图Ak效果如下:

第一列显示了估计的头部姿势。另外四列通过热图展示了四种空间结构,这些热图将模型发现的Mk某些行的折叠版本可视化。热图中的红色部分代表重点关注的区域。b,c,d,e四种不同的热图是由于采用了四种不同的评估函数导致的,即:1x1卷积,方差,均值,以及三种的结合fusion。
5. 结果:
文章中介绍了两种准则下的评估,这里就放一个测评结果意思一下,结果显示该方法在多个方面达到了sota。
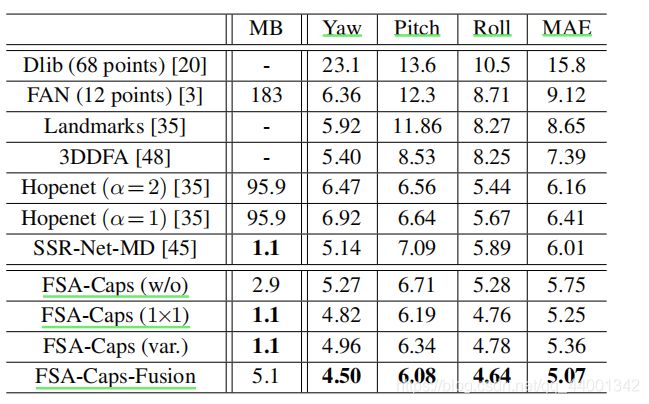
MB代表了模型的大小,第一列为各种方法的比较,FSA-CAP代表采用了胶囊模型,后缀 ()的代表评分中采用的函数,yaw,pitch,roll为三种偏转角度,MAE为前面提到的平均绝对误差,MAE越小,代表模型预测越准确。可以看出,采用胶囊网络和混合score函数的FSA-Caps-Fusion的效果最好,在任何情况下都能达到最优。
对于图像中人物的预测结果如下:
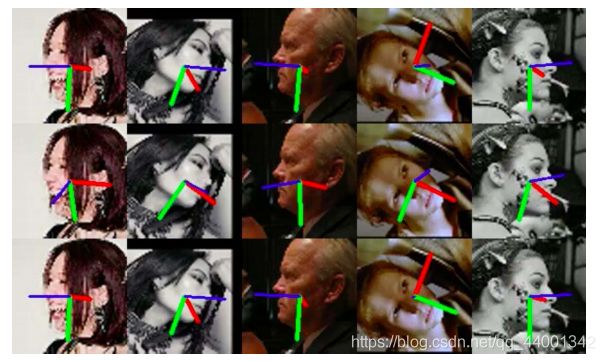
第一行为真实的偏转,第二行为其他方法(Hopenet)的预测结果,第三行为文章中的方法FSA-Net预测结果。可以看出,FSA-Net相当接近真实值。
最后的最后,作者做了一个消融实验探究各个因素在模型中的影响(很严谨的思路,学习到了),细节可以看论文原文,这里放一个探究的结果图:
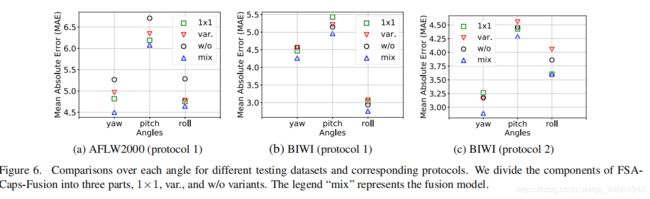
图中探究了三种评分函数与混合函数各自的精确度,再次证明了混合模型在任何情况下都能得到很好的结果。文章整体则证明了通过学习有意义的中间特征来改进回归结果是可能的。
(三) 代码:
代码连接
提取码:nuzz
环境配置:
- Keras
- Tensorflow
- GTX-1080Ti
- Ubuntu
python 3.5.6 hc3d631a_0
keras-applications 1.0.4 py35_1 anaconda
keras-base 2.1.0 py35_0 anaconda
keras-gpu 2.1.0 0 anaconda
keras-preprocessing 1.0.2 py35_1 anaconda
tensorflow 1.10.0 mkl_py35heddcb22_0
tensorflow-base 1.10.0 mkl_py35h3c3e929_0
tensorflow-gpu 1.10.0 hf154084_0 anaconda
cudnn 7.1.3 cuda8.0_0
cuda80 1.0 0 soumith
numpy 1.15.2 py35_blas_openblashd3ea46f_0 [blas_openblas] conda-forge
numpy-base 1.14.3 py35h2b20989_0
依赖环境:
- A guide for most dependencies. (in Chinese)
地址 - Anaconda
- OpenCV
- MTCNN
pip3 install mtcnn
- Capsule: 地址
- Loupe_Keras:地址
运行所需的三个模块为:
- Data pre-processing(预训练模块)
- Training and testing(测试模块)
- Demo
1. 预处理模块:
Data pre-processing(预处理模块)
里面存放了作者已经处理过的数据文件,毕竟自己训练的话对电脑啥的要求较高,还费时间。可以直接下载 data.zip 替换数据文件夹。
下载地址:地址
2. 训练测试模块:
数据集:
- 300W-LP, AFLW2000
- BIWI
把下载好的300W-LP,AFLW2000数据集放在文件夹:data/type1 下,把BIWI放在文件夹:data/ 下。
3. Demo:
- 需要开启摄像头权限;
- demo相当于一个实时检测程序,可以利用摄像头捕捉人脸,进而判断人脸的偏转情况。
# LBP face detector (fast but often miss detecting faces)
cd demo
sh run_demo_FSANET.sh
# MTCNN face detector (slow but accurate)
cd demo
sh run_demo_FSANET_mtcnn.sh
# SSD face detector (fast and accurate)
cd demo
sh run_demo_FSANET_ssd.sh
从视频中提取头像:
cd training_and_testing
python keras_to_tf.py --trained-model-dir-path ../pre-trained/300W_LP_models/fsanet_var_capsule_3_16_2_21_5 --output-dir-path <your_output_dir>
模块说明:
-
ssr_G_model:
双异构流结构 -
ssr_feat_S_model:
细粒度结构映射 -
ssr_aggregation_model:
评分模块 -
ssr_F_model:
SSR-Net接收输入 -
SSRLayer:
输出yaw, pitch, roll三种偏转角
其它问题可以自己看READE ME文件哈
(四) 总结:
总体上,为我在与表情识别与教育的结合上提供了许多新的思路。文章中也提到,多任务并行的检测精度是高于单任务的,因为各任务之间相互关联。头部姿态检测的信息可以用做表情识别,人脸识别的补充信息。其次是各个特征之间的空间信息利用,以及采用特征聚合,评估函数融合的思路。文章来自CVPR,思路非常严谨,以后自己写论文也可以学习。感觉头部姿态评估在判断学生的上课注意力情况上确实优于表情识别,具体的结合方法等再看几篇论文再想。
(五) 参考博客:
1. https://blog.csdn.net/weixin_30664615/article/details/101749135
2. https://blog.csdn.net/iteapoy/article/details/104435384/
3. …剩下的忘了…