对于python 的正则表达式,你学废了吗
python 正则表达式保姆式教学,带你领略正则的魅力
- 一、什么是正则
- 二、re 模块基本用法
- 三.基本正则匹配
- 四.正则重复
- 五.正则分组
- 六.正则标记
- 七.正则标记
- 总结

提示:以下是本篇文章正文内容,下面案例可供参考
一、什么是正则
1. 引 入
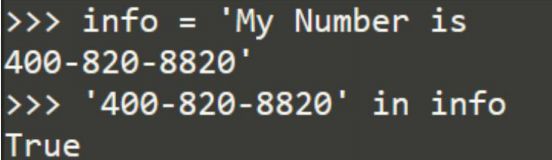
查找字符串中是否含有电话号码400-820-8820?
字符串内容:‘MyNumberis400-820-8820’
in,find可以检查字符串中是否含有某个子串。
2. 正则的目的
“数据挖掘”
从一大堆文本中找到一小堆文本时。如,从文本是寻找email,ip,telephone等
验证
使用正则确认获得的数据是否是期望值。如,email、用户名是否合法等
非必要时慎用正则,如果有更简单的方法匹配,可以不使用正则
指定一个匹配规则,从而识别该规则是否在一个更大的文本字符串中。
正则表达式可以识别匹配规则的文本是否存在
还能将一个规则分解为一个或多个子规则,并展示每个子规则匹配的文本
3. 正则表达式的优缺点
优点:提高工作效率、节省代码
缺点:复杂,难于理解
二、re 模块基本用法
1.什么是 re模块
从文本中匹配某些子串。
官方文档:re 的官方文档
安装:python标准库,无需要安装
2.re模块基本用法-search
match与search:查找第一个匹配
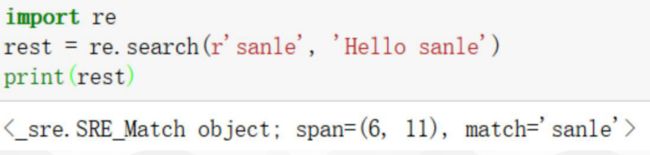
re.search
查找匹配项
接受一个正则表达式和字符串,并返回发现的第一个匹配。
如果完全没有找到匹配,re.search返回None
3.re模块基本用法-match
match与search:查找第一个匹配
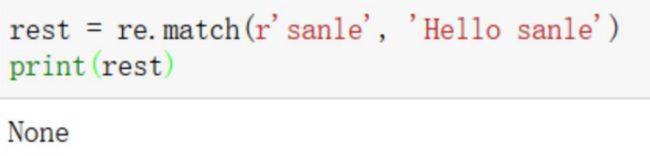
re.match
从字符串头查找匹配项
接受一个正则表达式和字符串,从主串第一个字符开始匹配,并返回发现的第一个匹配。
如果字符串开始不符合正则表达式,则匹配失败,re.match返回None
4.re模块基本用法-raw
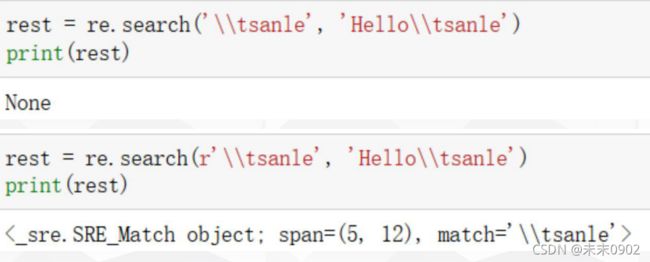
r’sanle’中的r代表的是raw(原始字符串)
原始字符串与正常字符串的区别是原始字符串不会将\字符解释成一个转义字符正则表达式使用原始字符很常见且有用
参考资料:51 的文章
5.re模块基本用法-match对象
match.group(default=0):返回匹配的字符串。
group是由于正则表达式可以分拆为多个只调出匹配子集的子组。
0是默认参数,表示匹配的整个串,n表示第n个分组

match.start()
start方法提供了原始字符串中匹配开始的索引

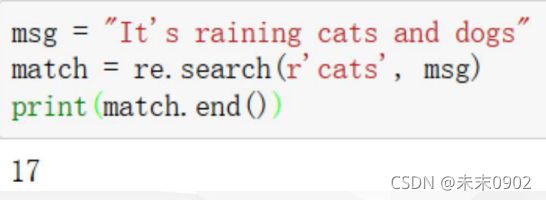
match.end()
end方法提供了原始字符串中匹配开始的索引
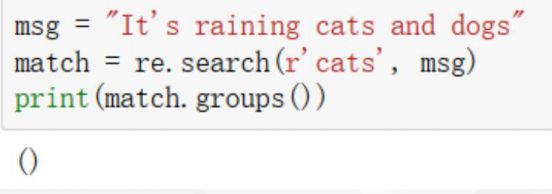
match.groups()
groups返回一个包含所有小组字符串的元组,从1到所含的小组号。
6.re模块基本用法-findall
findall和finditer:找到多个匹配
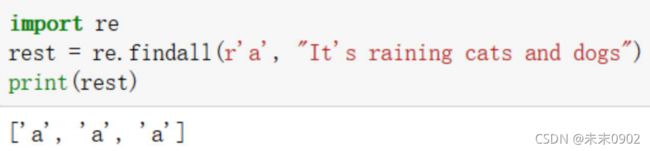
re.findall
查找并返回匹配的字符串,返回一个列表
findall和finditer:找到多个匹配
re.finditer
查找并返回匹配的字符串,返回一个迭代器

7.re模块基本用法-sub
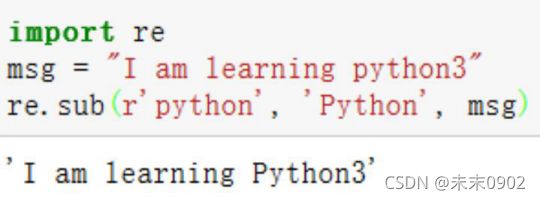
re.sub(‘匹配正则’,‘替换内容’,‘string’)
将string中匹配的内容替换为新内容
8.re模块基本用法-compile
编译正则:re.compile(‘匹配正则’)
reg=re.compile(r’l+’)
result=reg.search(Zen)print(result,type(result))
编译正则的特点:
复杂的正则可复用
使用编译正则更方便,省略了参数
re模块缓存它即席编译的正则表达式,因此在大多数情况下,使用compile并没有很大的性能优势
三.基本正则匹配
1.基本正则匹配-区间
最简单的正则表达式是那些仅包含简单的字母数字字符的表达式,复杂的正则可以实现强大的匹配
区间:[]
•正则匹配区分大小写
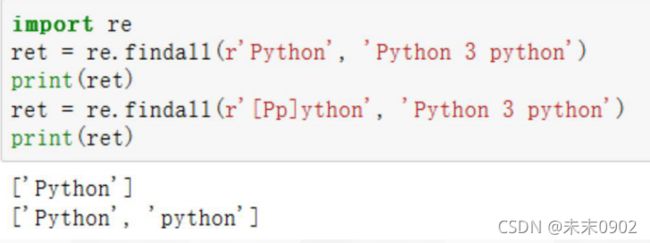
•匹配所有字母:[a-zA-Z]
•匹配所有字母及-:[a-zA-Z-]
2.基本正则匹配-或匹配
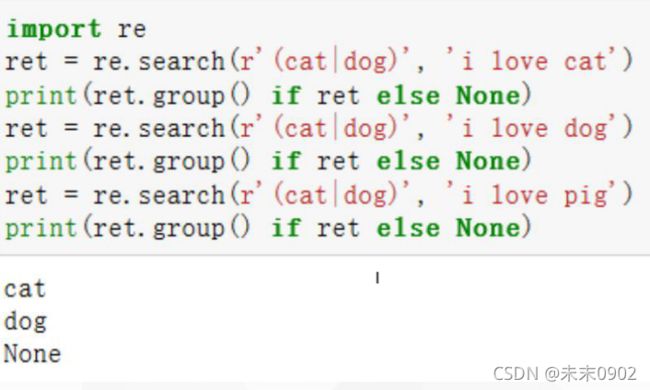
匹配a或b:a|b
•匹配cat或dog
3.基本正则匹配-取反
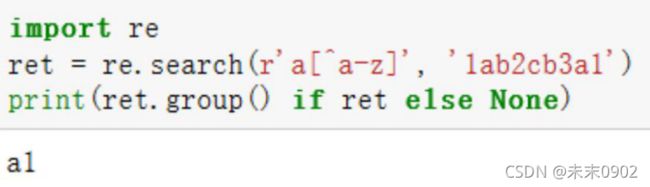
取反:[^abc]
•匹配a+非小写字母
4.基本正则匹配-任意字符(占位符)
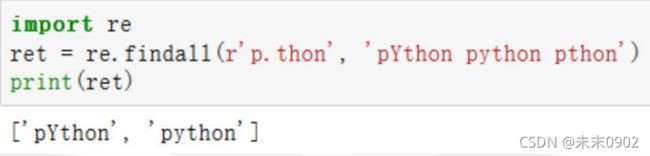
任意字符:“.”占位符
•匹配任何(除\n外)的单个字符,它仅仅只以出现在方括号字符组以外
5.基本正则匹配-快捷方式
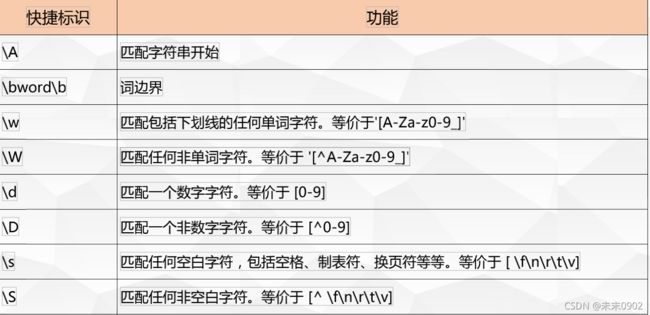

6.基本正则匹配-开始与结束
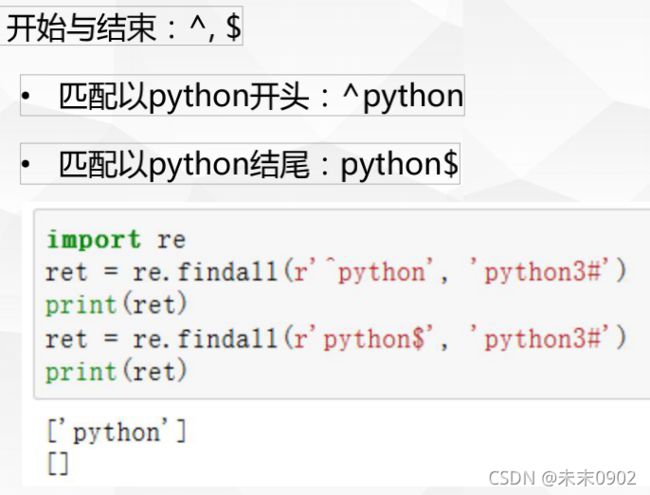
四.正则重复
1.正则重复-通配符
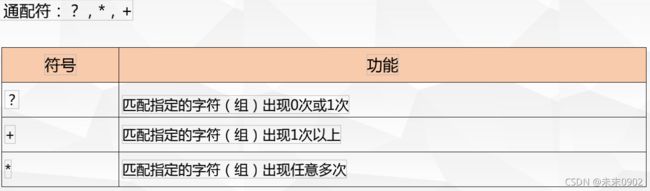


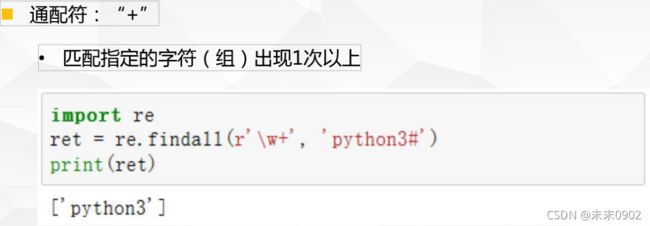

2.基本正则匹配-贪婪与非贪婪模式
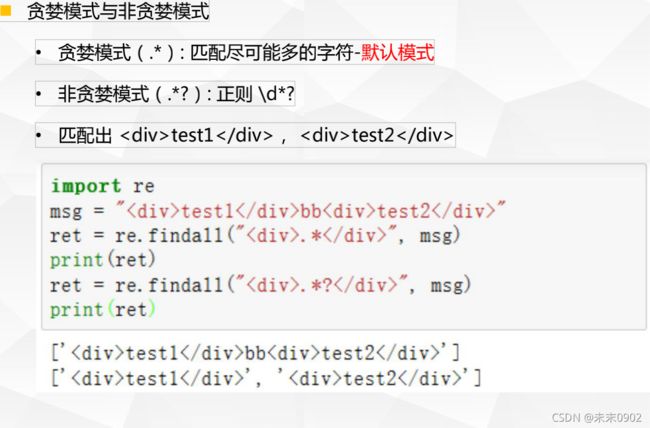
五.正则分组
当使用分组时,除了可以获得整个匹配,还能够获得选择每一个单独组,使用()进行分组
1. 正则分组-简单分组

当使用分组时,除了可以获得整个匹配,还能够获得选择每一个单独组,使用()进行分组
分组不匹配(?:规则)
•表示将()仅用于组合字符串,不识别为分组
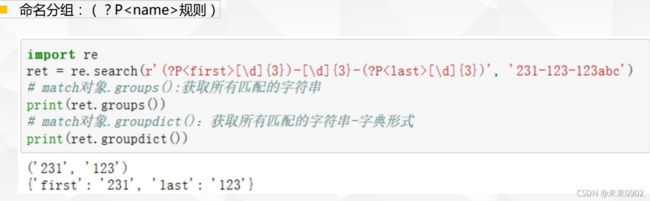
2.正则分组-命名分组
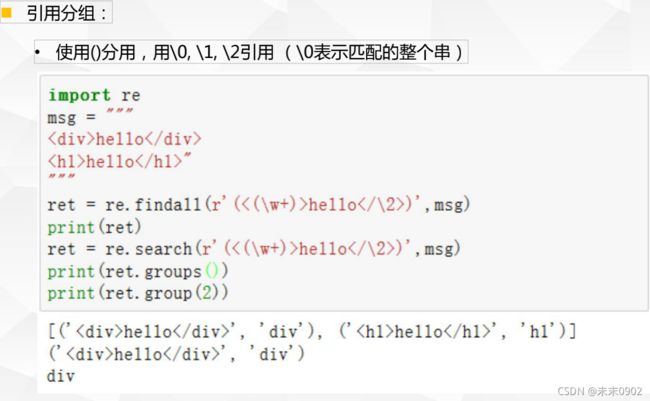
3.正则分组-引用分组
六.正则标记
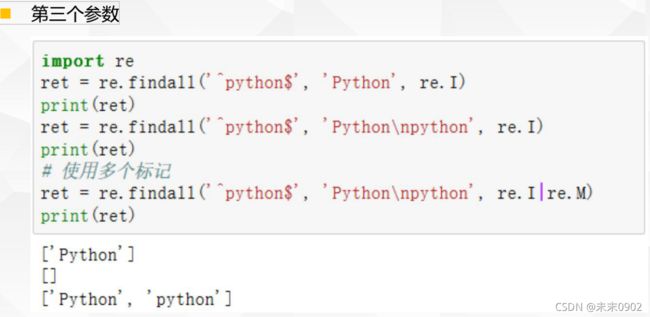
1.正则标记-第三个参数

2.基本正则匹配-内联标记

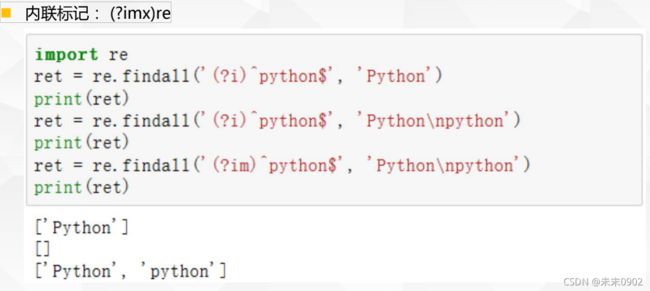
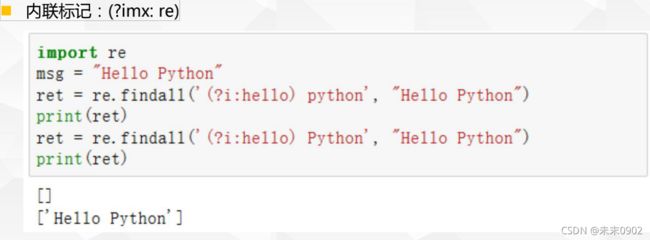
七.正则标记
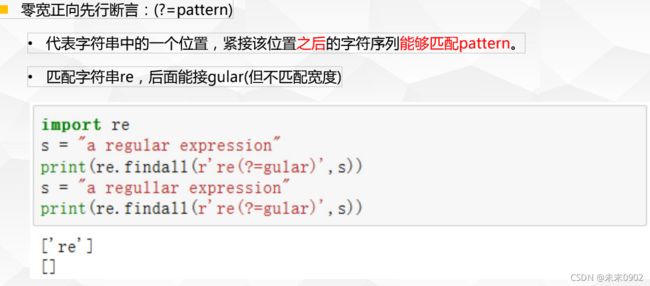
1.正则表达式断言





总结
1.正则表达式是可以提高效率,但是首先要掌握正则的规则,然后要会写才可以提高效率。如果你为了一个正则表达式,而去想了很久,还不如老老实实地按照传统方法去敲代码。。。。
2.大佬都直接用正则去写,怪不得代码那么优雅。
优雅永不过时!!!