算法刷题记录(Day 62)
权限查询(csp-201606-3)
原题链接
解题思路:以权限为主体,建立不同权限或者不同等级的权限的访问角色表。若角色role有privilege:level的权限,则role应该被添加到privilege的0到level的数组中。同时,为了方便,需要维护一个数组,记录每一个角色对于每一个权限所拥有的最大的等级。
在进行判断中,对于是否具有权限的判断,仅需判断权限的访问角色表中的角色是否和用户的角色有交集;对于最高权限的判断,遍历用户的所有角色,利用角色-最大权限等级矩阵进行获取。
问题是:
如何去返回具有的最高等级呢?->从本身的最高等级查起
如何去标识->查询0等级和查询最高等级之间的区别->使用p来进行
map和vector的无法嵌套使用->string的find来进行代替
#includetip:
1.运行错误代表的是出现了诸如溢出之类的问题2.调试过程中的输出不要忘记注释掉。
3.vector里面嵌套map等stl容器可能会存在错误
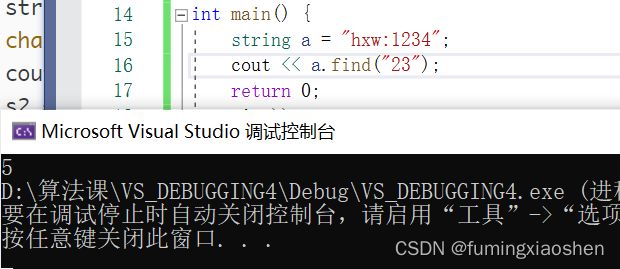
4.string的find返回的是子串开始的位置
5.map当不存在时返回的是0
6.注意看清楚题目的条件!!!
7.使用string.h而不是string,否则会报编译错误


参考链接:
string find使用
csp编译错误
赤壁之战
原题链接
若 使用dp[i][j]代表到i为止长度为j的子串的个数,则时间复杂度O(MNN),肯定会超时
那么能否仅仅计算最长的严格升序列,然后再利用组合数求得最终的结果,但是除了由最长增序列求解长度为M的个数,长度为M的也可能位于非最长增序列中
使用离散化+树状数组的方式,来将对于特定的长度、特定的位置,需要遍历前面所有的数字以求和转化为树状数组的求和过程。
在计算长度为i的过程中,B中维护的是特定位置以前的长度为i-1的前缀和,鉴于在A中,可能存在相同的,因此在遍历过程中逐步在B中加上i-1的值。
#include#includetip:
1.在debug过程中发现关于%mod很奇怪,起初是下面的代码WA,后来又好了
2.对于求和的内容,离散化的思想很重要。同时,对于大小的比较,也可以考虑到离散化的角度。
3.对于add的时机,由于处理到A[i+1]及其后面的数据时,才会使用到A[i]对于B的影响,因此,需要在计算完A[i]后再在B上加上A[i]的影响。