图像检测:图像生成
判别式与生成式模型
判别式模型 :已知观察变量X和隐含变量z,它对p(z|X)进行建模,它根据输入的观察变量x得到隐含变量z出现的可能性。根据原始图形推测图形具备的一些性质,例如根据数字图像推测数字的名称等。
生成式模型 :它对p(X|z)进行建模,输入是隐含变量,输出是观察变量的概率。通常给出的驶入是图像具备的性质,而输出是性质对应的图像。
生成模型
模型目标:
- 训练数据集的模型:x~Ptrain(x)
- 生成样本的模型:x~Pmodel(x)
- 令Pmodel(x) = Pdata(x)
解决问题:构建高维,复杂概率分布,数据缺失,多模态输出,真实输出任务,未来数据预测。

MLE
样本集中的样本都是独立同分布,可以只考虑一类样本集D,来估计参数向量θ。记已知的样本集为:

似然函数(likelihood function):联合概率密度函数p(D|θ)称为相对于θ的似然函数。

如果 θ^ 是参数空间中能使似然函数L(θ)最大的 θ^ 值,则 θ^ 应该是最可能的参数值,那么 θ^ 就是θ的极大似然估计量。
求使得出现改组样本的概率的最大θ值。

实际中为了便于分析,定义了对数似然函数。

VAE
经典的自编码机:左侧把原始图形编码卷积(编码)成向量;解卷积层则能把这些向量解码回原始图像。可以用尽可能多的图像来训练网络,如果保存了某张图片的向量,我们随是就能用解码组件来重建该图像。

问题:潜在向量除了从已有图像中编码得到,能否凭空创造出这些潜在向量来?
简单的办法:给编码网络增加一个约束,使它所生成的潜在向量大体上服从单位高斯分布。
生成新的图像就变得容易了:只需从单位高斯分布中采样出一个潜在向量,并将其传到解码器。

假定认为输入数据的数据集D(显变量)的分布完全有一组隐变量z操控,而这组隐变量之间相互独立而且服从高斯分布。VAE让encoder学习输入数据的隐变量模型,也就是去学习这组隐变量的高斯概率分布的参数:隐变量高斯分布的均值(μ)和方差(σ)的log值。而隐变量z就可以从这组分布参数的正态分布中采样得到:z~N(μ,σ),再通过decoder对z隐变量进行解码来重构输入。

**误差项精确度与潜在变量在到单位高斯分布上的契合程度,包括两部分内容: **
- 生成误差:用以衡量网络重构图像精确度的均方误差。
- 潜在误差:用以衡量潜在变量在单位高斯分布上的契合程度的KL散度。
总的目标函数:

假设现在有一个样本集中两个概率分布p、q,其中p为真实分布,q为非真实分布。
则按照真实分布p来衡量识别一个样本所需要的编码长度的期望为:
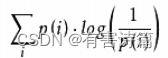
如果采用错误的分布q来表示来自真实分布p的平均编码长度,则应该是:

此时就将H(p,q)称之为交叉熵。
KL散度又称为相对嫡,是是两个概率分布P和Q差别的非对称性的度量。典型情况下,P表示数据的真实分布,〇表示数据的理论分布(模型分布或P的近似分布)。

KL散度不是对称的,并不满足距离的性质;
![]()
JS散度度量了两个概率分布的相似度,基于KL散度的变体,解决了KL散度非对称的问题。一般地,JS散度是对称的,其取值是0到1之间。

*Reparameterization: ** VAE模型并没有真正的用z~N(μ,σ) 来采样得到z变量,因为这样采样之后,没有办法对N(μ,σ)进行求导。先采样一个标准高斯分布: ε ~ N(0,1),然后z=μ+σ ε,这样得到的z就是服从z ~N(μ,σ),同时也可以正常对(μ,σ)进行求导。

VAE全过程

优点: 遵循编码-解码模式,能直接把生成的图像同原始图形进行对比。
不足: 由于它是直接采用均方误差,其神经网络倾向于生成较为模糊的对象。

VAE与GAN

生成式对抗网络(GAN)
结构: 生成器(Generator)和判别器(Discriminator)
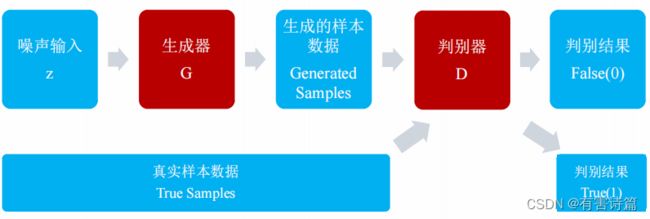
生成器网络:
负责生成样本数据,输入为高斯白噪声向量z,输出为样本数据向量x。必须可微分。
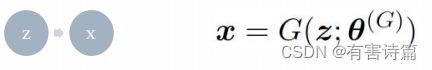
判别器网络:
负责检测样本数据真假,输入为真实或生成的样本数据,输出为标签。必须可微分。



让第一代G产生一些图片,然后把这些图片和一些真实的图片丢到第一代的D里面去学习,让第一代的D能够分辨生成的图片和真实的图片。然后训练第二代的G,第二代的G产生的图片,能够骗过第一代的D,再训练第二代的D,依此迭代。

如何训练新一代的G来骗过上一代的D?
很简单,可以把新一代的G和上一代的D连起来形成一个新的NN,我们希望最终的输出接近1,训练之…
然后我们就可以拿中间的结果当作我们的新的图片的输出。

优化目标
价值函数(Value Function):
![]()
生成器固定之后,使用maxV(D,G)来评价Pdata和Pz之间的差异。
优化方式:
- 生成器优化方向:最小化价值函数
- 判别器优化方向:最大化价值函数
- 交替优化,直到达到纳什均衡点。
Minimax Game
**D-step: **

**G-step: **
![]()
生成器最小化目标,判别器将生成数据识别为假的概率的log值。
均衡点是判别器代价函数的鞍点。

变换成这个样子是为了引入KL散度和JS散度。

在最优判别器下,GAN定义的生成器loss可等价变换为最小化真实分布于生成分布之间的JS散度。

绿线:生成器的数据分布
黑线:真实数据分布
蓝线:判别器的结果分布
随着绿色的线与黑色的线的偏移,蓝色的线下降了,也就是判别器的准确率下降了。

问题及挑战
训练困难: 很难收敛到纳什均衡点,无法有效监控收敛状态。
**模型崩溃: ** 判别器快速达到最优,能力明显强于生成器,生成器将数据集中生成在判别器最认可的空间电上,即输出多样性低。
**不使用与离散输出: ** 文本生成。
DCGAN
为GAN的训练提供了一个适合的网络结构,表明生成的特征具有向量的计算特性。特征可以进行加减运算。

模型稳定训练的技巧:
- 全连接层->卷积层
- 池化层,上采样层->卷积层
- 使用批量归一化
- 生成器中使用ReLU激活函数,输出使用Tanh
- 判别器中使用Leaky ReLU激活函数。
- 使用Adam优化器训练,学习率最好是0.0002
生成效果: 仅支持低分辨率图片,无法捕捉物体结构特性。

Z向量的计算特性

Z向量的插值特性

CGAN
GAN中输入是随机的数据,那么很自然就会想到能否用输入改成一个有意义的数据?
最简单的就是数字字体生成,能否输入一个数字,然后输出对应的字体。
这就是CGAN思路。
**实现方式: **
在G网络上的输入在z的基础上连接一个y;然后在D网络的输入在X的基础上也连接一个y。

目标函数:
![]()
Wasserstein GAN
WGAN相比原始GAN的算法只改了四点:
- 判别器最后一层去掉sigmoid
- 生成器和判别器的loss不去log
- 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
- 不要用基于动量的优化算法(momentum,Adam),可以使用RMSProp,SGD也行。
WGAN实现了以下关键点:
- 彻底解决GAN训练不稳定的问题,不再需要小心平衡生成器和判别器的训练程度;
- 基本解决了collapse mode的问题,确保了生成样本的多样性;
- 训练过程中终于有一个像交叉嫡、准确率这样的数值来指示训练的进程,这个数值越小代表GAN训练得越好,代表生成器产生的图像质量越高;
- 以上一切好处不需要精心设计的网络架构,最简单的多层全连接网络就可以做到。
只要Pr,和Pg没有一点重叠或者重叠部分可忽略,JS散度就固定是常数,而这对于梯度下降方法意味着梯度为0。
Pr,和Pg不重叠或重叠部分可忽略的可能性有多大?不严谨的说是:非常大。
在(近似)最优判别器下,最小化生成器的loss等价于最小化Pr,和Pg之间的JS散度,而由于Pr和Pg几乎肯定有可忽略的重叠,所以无论它们相距多远JS散度都是常数,最终导致生成器的梯度(近似)为0,梯度消失。
Wasserstein距离又叫Earth-Mover距离:

可理解为在这个"路径规划”下把Pr这堆”土”挪到Pg“位置"所需的"消耗”,而W(Pr ,Pg)就是"最优路径规划”下的”最小消耗”。
Wasserstein距离相比KL散度、JS散度的优越性在于,即便两个分布没有重叠,
Wasserstein距离仍然能够反映它们的远近。
原GAN的目标函数中的log(x)不能用,因为它的导数没有上界,就不是Lipschitz连续。Lipschitz连续——其实就是在一个连续函数上面额外施加了一个限制。
原GAN的判别器做的是二分类任务,所以最后一层是sigmoid;现在判别器做的是近似拟合Wasserstein距离,属于回归任务,所以要把最后一层的sigmoid拿掉。
这样得到了WGAN的两个loss:
WGAN生成器loss函数:
![]()
WGAN判别器loss函数:
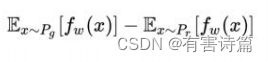
判别器所近似的Wasserstein距离与生成器的生成图片质量高度相关。

WGAN如果用类似DCGAN架构,生成图片的效果与DCGAN差不多。
但是厉害的地方在于:WGAN不用DCGAN各种特殊的架构设计也能做到不错的效果。

Super-ResolutionGAN
ILR是高分辨率图像HR的低分辨率副本。高分辨率图像全部来自于数据库。ILR是对IHR进行高斯滤波然后进行下采样得到的。
SRGAN的博弈公式:

参数θG通过优化一个特殊的损失函数ISR得到的,即:
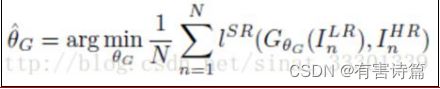
生成网络:应用了分布相同的B残差块,每个残差块都有两个卷积层。
卷积层后面加上batch-normalization,并用PReLU作为激活函数。
卷积层的卷积核都是3×3,并有64个特征图。还有跃层连接。

判别网络:由连续的卷积块构成,卷积块包括卷积层、Leaky ReLU层和BN层。
卷积层的卷积核都是3×3。
最后是两个dense层,并通过sigmoid进行鉴别判断。


效果展示:捕捉人类视觉感知代价
