Thinking in Frequency: Face Forgery Detection by Mining Frequency-aware Clues
F3-Net 商汤Deepfake检测模型 - 知乎前言这篇论文是商汤团队在ECCV2020的一个工作: Thinking in Frequency: Face Forgery Detection by Mining Frequency-aware Clues,通过引入两种提取频域特征的方法FAD (Frequency-Aware Decomposition) 和LFS (L… https://zhuanlan.zhihu.com/p/260998460
https://zhuanlan.zhihu.com/p/260998460
本文还是很值得读的,在篡改检测上应用频率信息进行分类,同时间段还有一篇达摩院的文章,频域信息在压缩领域是比较敏感的,jepg图像在传递过程中可能经过多次压缩,这使得光用空域的特征检测细微的变换变得很困难。本文很有意思,通常对频域的利用就是在输入时直接将图像用dct转成频域图,在频域图上用cnn去提取特征,让cnn自己学,但是这比较难的,当然也可以,小视科技的活体检测就是这个思路,另外就是频域和空域在特征提取中的相互转换,空域图经过逆dct是可以转成频域图的,原始的频域图提完特征之后重组,再让cnn去学习,有两个点,或者说利用了两个频率特征,FAD和LFS,频率特征如何嵌入到cnn中。
挖掘篡改检测模式中的awareness of frequency.频域可以很好的描述subtle forgert artifacts or compression errors.细微的伪造伪影和压缩错误。F3net提了两个点。1.frequency-aware decomposed image components,频率感知分解图像分量 2.local frequency statistics, 局部频率统计,应用dct做频率转换。DCT变换较DFT变换具有更好的频域能量聚集度。
1.introduction
一系列早期的工作依赖于手工制作的特征,例如局部模式分析 、噪声方差评估 和隐写分析特征来发现伪造模式并放大真实和伪造图像之间的微弱差异。 如果伪造人脸的视觉质量大幅下降,例如压缩比大的JPEG或H.264压缩,伪造伪影会被压缩错误污染,有时无法在RGB域中捕获 . 但这些伪影可以在频域中被捕获。 与真实面孔相比,它们以不寻常的频率分布的形式出现。但是,如何将频率感知线索纳入深度学习的 CNN 模型中? 传统的频域,例如 FFT 和 DCT,与自然图像所拥有的移位不变性和局部一致性不匹配,因此普通的 CNN 结构可能不可行。 因此,如果我们想利用可学习 CNN 的判别表示能力进行频率感知人脸伪造检测,那么与 CNN 兼容的频率表示就变得至关重要。

如上图,在低质量(Low Quality)图片中,两种图片都很真实,但是在局部的频率统计量(LFS)中,呈现出明显的差异,这也就很自然能被检测出来。
2.related work
spatial-based forgery detection.利用空域信息。大部分是基于RGB和HSV等空域,提取色彩空间特征来分类,例如ela使用像素级错误来检测伪造,包括一些浅层网络或者GAN等,绝大多数使用空域信息,因此难以在色彩空间中检测细微操作变化。
Frequency-based forgery detection.小波变换,傅里叶变换将图片转换为频域并挖掘潜在的伪影。 此外,过滤是一种经典的图像信号处理方法,可利用现有的关于假图像特征的知识,对伪造检测中的潜在细微信息进行细化和挖掘。 一些研究使用高通滤波器、Gabor 滤波器等基于与高频分量有关的特征来提取感兴趣的特征(例如边缘和纹理信息)。使用手工制作的 Gabor 和高通滤波器来增强边缘和纹理特征。 经过高通滤波后,可以在真实图像和虚假图像之间的光谱中获得显着差异。不过这些过滤器通常是固定,SRM类似的噪声流,噪声流相当于在空域的方法,上了一层滤波器,无法自适应的捕获伪造模式。转频域用的dct或者dft,和一般滤波器有区别,本文中还涉及的到dct的梯度回传,如果一开始直接提特征确实就没有提取回传的问题,输入经过dct'处理的图就可以了,后面和空域的处理方法一致。
目前见到的滤波器之前的工作基本用的还是滑窗conv的结构,更换weight即可,srm,constrained cnn都是这么操作的
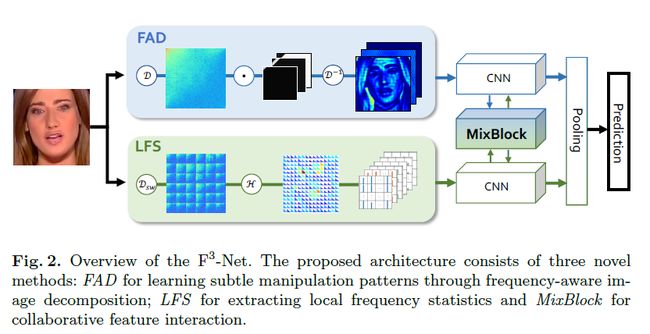
3.our approach
3.1 FAD: frequency-aware decomposition
对于频率感知图像分解,以前的研究通常在空间域中应用手工制作的滤波器组 ,因此无法覆盖完整的频域。 同时,固定的过滤配置使得自适应地捕捉伪造模式变得困难。我们提出了一种新颖的频率感知分解(FAD),根据一组可学习的频率滤波器在频域中自适应地划分输入图像。分解后的频率分量可以逆变换到空间域,从而产生一系列频率感知图像分量。 这些组件沿着通道轴堆叠,然后输入到卷积神经网络(在我们的实现中,我们使用 Xception [12] 作为主干)来全面挖掘伪造模式。
这里的步骤是:先定义了dct的参数,这里的size其实就是频率的数目,3通道为一组计算dct。得到二维频谱图后生成一个同样二维的滤波器,然后滤波器直接与原频谱图点乘,得到的滤波结果在做逆dct变换,全程都在二维频谱上进行变换的。generate_filter是生成base_filter的函数,对于size为256的二维频谱,生成低频的滤波器的调用方式为genate_filter(0,64,256),效果为生成一个左上角为1其余部分为0的mask,即认为选取了频谱中低频的部分,低频响应应位于左上角,而高频相应位于右下角。观察自然图像频谱,我们发现频谱分布不均匀,大部分幅度集中在低频区域。
对于确定块大小的DCT和IDCT本质上就是参数固定的卷积核反卷积过程,系数可以算出来。
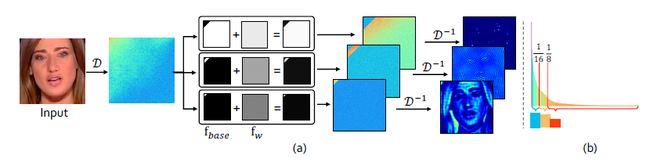
输入图经过Dct转变变成频域图,在经过一个base和w的滤波器变成三个频谱图,这三个频谱对应了三个频段,高中低,在逆DCT回去重组成原图。base相当于一个二进制的mask,是用来制作频带的,有了频带之后再有一个可学习的滤波器来进行特征提取,相当于在频域做了特征提取在转回空域。
3.2 LFS
FAD提供了与cnn兼容的频率感知表示,但它必须将频率表示回空域,因此无法直接利用频率信息,通过直接从光谱表示中使用cnn开挖掘伪造伪影通常是不可行的,这个观点还挺重要,也就是说直接利用频域特征去找伪造特征不可行,也确实如此,经过dct之后的频域图还不如ela之后的像素图靠谱,FAD尽管利用到了频域信息,但它最后通过反dct变换重新转到rgb空域上进而输入到cnn上,这些信息并不是直接利用频域信息的。
在local frequecncy statistics上,1.对输入的图片采用滑窗dctsilde windows dct,其实这种写法很常见,之前见到的srm等等算子也是直接更改weights,使用conv2d的方式,这里用unfold一样,这个操作和卷积一样,只是不使用weights做计算,再添加dct计算的weights即可,就是unfold拿到一块块,然后这一块块用dct算,算完把权重填上去。2.计算一些列可学习频带的频率响应值,其实就是计算weights。3.将频率统计信息重新组合为与输入图像一样的大小。这里的局部频率统计其实就是对FAD的一个简化版,相当于在一块一块的windows上计算FAD,完了之后补充idct回去,而是直接把这个频率信息送到后面的cnn进行学习,看着挺玄乎,其实就相当于在cnn中使用一层自设计的weight的cnn做了特征提取。
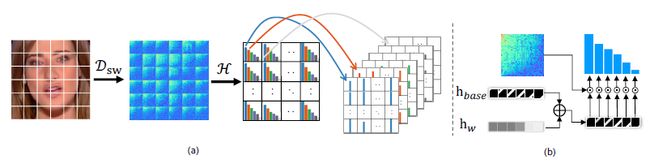
窗口大小采用10,步长为2,波段长为6,就是输出6个通道数目。
3.3 mixblock融合模块
