【迎战蓝桥】 算法·每日一题(详解+多解)-- day9
目录
1. 两个链表的第一个公共结点
2. 二叉树的深度
3. 数组中只出现一次的数字
【大家好,我是爱干饭的猿,如果喜欢这篇文章,点个赞,关注一下吧,后续会一直分享题目与算法思路】
1. 两个链表的第一个公共结点
描述
输入两个无环的单向链表,找出它们的第一个公共结点,如果没有公共节点则返回空。(注意因为传入数据是链表,所以错误测试数据的提示是用其他方式显示的,保证传入数据是正确的)
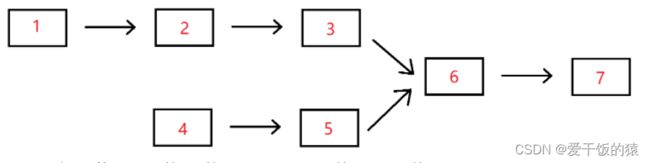
例如,输入{1,2,3},{4,5},{6,7}时,两个无环的单向链表的结构如下图所示:
可以看到它们的第一个公共结点的结点值为6,所以返回结点值为6的结点。
输入描述:
输入分为是3段,第一段是第一个链表的非公共部分,第二段是第二个链表的非公共部分,第三段是第一个链表和第二个链表的公共部分。 后台会将这3个参数组装为两个链表,并将这两个链表对应的头节点传入到函数FindFirstCommonNode里面,用户得到的输入只有pHead1和pHead2。
返回值描述:
返回传入的pHead1和pHead2的第一个公共结点,后台会打印以该节点为头节点的链表。
解题思路:
1. 思路一:题目要求是单链表,所以如果有交点,则最后一个链表的节点地址一定是相同的,求第一公共节点,而且两条链表相同的节点长度相同
1. 我们可以让较长的链表先往后走Math.abs(length1-length2)步,
2. 然后往后找第一个地址相同的节点(并且要保证两条链中该节点之后的所有节点值相同),就是题目要求的节点。
2. 思路二:我们可以使用Map
1. 先将第一个单链表节点值全部加入到map集合
2. 然后遍历第二个单链表,将节点加入map中时,如果当前节点值已存在在map集合
3. 并且在此节点之后的节点值也都在map集合之中,也就是说该节点有极大可能性就是pHead1和pHead2的第一个公共结点。
思路一:代码如下:
// 方法一
// 让较长的链先走k步,使得两条链长度相同,然会两条链同时向后走
// 当遇到第一个相同节点时,该节点就是两个链表的第一个公共结点
public ListNode FindFirstCommonNode(ListNode pHead1, ListNode pHead2) {
if(pHead1 == null || pHead2 == null){
return null;
}
int length1 = getLength(pHead1);
int length2 = getLength(pHead2);
int step = Math.abs(length1 - length2);
// 1. 使得较长的链先走step步
if(length2 < length1){
for (int i = 0; i < step; i++) {
pHead1 = pHead1.next;
}
}else {
for (int i = 0; i < step; i++) {
pHead2 = pHead2.next;
}
}
// 2. 找第一个地址相同的节点
while (pHead1 != null && pHead2 != null){
// 并且要保证两条链中该节点之后的所有节点值相同
if(pHead1.val == pHead2.val && allContains(pHead1.next,pHead1.next)){
return pHead1;
}
pHead1 = pHead1.next;
pHead2 = pHead2.next;
}
return null;
}
// 保证两条链中该节点之后的所有节点值相同
private boolean allContains(ListNode l1, ListNode l2) {
while (l1 != null && l2 != null){
if(l1.val != l2.val){
return false;
}
l1 = l1.next;
l2 = l2.next;
}
return true;
}思路二:代码如下:
// 方法二
// 用例8/9
public ListNode FindFirstCommonNode2(ListNode pHead1, ListNode pHead2) {
Map map = new LinkedHashMap();
// 1. 使用Map,先将第一个单链表节点值全部加入到map集合
for(ListNode x = pHead1;x != null;x = x.next){
map.put(x.val,1);
}
// 2. 然后遍历第二个单链表
for(ListNode x = pHead2;x != null;x = x.next){
// 将节点加入map中时,如果当前节点值已存在在map集合
if(map.containsKey(x.val)){
if(x.next != null){
// 3. 并且在此节点之后的节点值也都在map集合之中
if(allContainKey(map,x.next)){
// 该节点有极大可能性就是pHead1和pHead2的第一个公共结点
return x;
}
}else {
return x;
}
}
}
return null;
}
// 判断此节点之后的节点值也都在map集合之中
private boolean allContainKey(Map map, ListNode x) {
while (x != null){
if(!map.containsKey(x.val)){
return false;
}
x = x.next;
}
return true;
} 2. 二叉树的深度
描述
输入一棵二叉树,求该树的深度。从根结点到叶结点依次经过的结点(含根、叶结点)形成树的一条路径,最长路径的长度为树的深度,根节点的深度视为 1 。
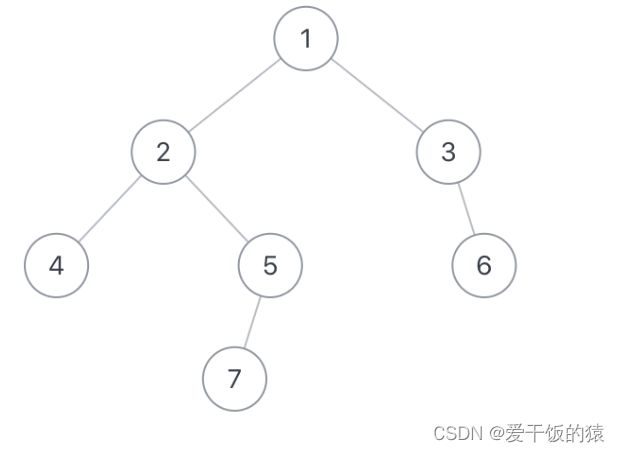
假如输入的用例为{1,2,3,4,5,#,6,#,#,7},那么如下图:

解题思路:
1. 思路一:可以使用递归方式,当每次递时 + 1,递到叶子节点时归,取左右孩子归的最大值。
2. 思路二: 可以层序遍历,统计层数,也就是深度or 高度1. 设置一个队列,并将根节点入队2. 如果队列不为空,就 将当前队列中所有节点出队(将一层节点出队depth += 1)3. 出队时将该节点的左右孩子入队4. 当队列为空时,说明每层节点都进行了入队出队操作,depth 值就是树的深度
思路一:代码如下:
// 方法一 递归
public int TreeDepth(TreeNode root) {
// 递到叶子节点时归,
if(root == null){
return 0;
}
// 当每次递时 + 1,取左右孩子归的最大值
return 1 + Math.max(TreeDepth(root.left),TreeDepth(root.right));
}思路二:代码如下:
// 方法二 迭代
public int TreeDepth2(TreeNode root) {
if (root == null) {
return 0;
}
// 1.设置一个队列,并将根节点入队
Queue queue = new LinkedList<>();
queue.offer(root);
int depth = 0;
// 2. 如果队列不为空,当前队列中所有节点出队
while (!queue.isEmpty()) {
// (将一层节点出队depth+= 1)
depth++;
int size = queue.size();
// 就将当前队列中所有节点出队
for (int i = 0; i < size; i++) {
TreeNode node = queue.poll();
// 3. 出队时将该节点的左右孩子入队
if(node.left != null) queue.offer(node.left);
if(node.right != null) queue.offer(node.right);
}
}
// 4. 走到这,说明当队列为空,每层节点都进行了入队出队操作,depth 值就是树的深度
return depth;
} 3. 数组中只出现一次的数字
描述
一个整型数组里除了两个数字之外,其他的数字都出现了两次。请写程序找出这两个只出现一次的数字。
解题思路:
1. 思路一:如果只有一个数据单独出现,直接整体异或得到结果,但是这道题是两个不重复的数据。
1. 我们可以采取先整体异或,异或结果一定不为0,而其中为1的比特位,不同的两个数据该 位置上的数据一定不同
2. 找到整体异或结果其中为1的比特位(只有两个单身数字异或结果有1的比特位)
3. 所以我们可以用该比特位进行分组,分组的结果一定是,相同数据被分到了同一组,不同数据一定被分到了不同的组,问题就转化成了两个问题一
2. 思路二:使用map key-value键值对
1. 先设置一个map集合,并将所有元素加入map集合中,如果map中已存在该元素,使该value+1
2. 遍历map集合,其中value值为1 的元素就是单身元素
思路一:代码如下:
// 方法一 异或^
public void FindNumsAppearOnce(int [] array,int num1[] , int num2[]) {
int result = 0;
// 1.将所有元素全部异或一遍
// 得到的result就是两个只出现一次的异或结果
for(int i = 0;i < array.length;i++){
result ^= array[i];
}
// 2. 找到整体异或结果其中为1的比特位(只有两个单身数字异或结果有1的比特位)
int flag = 1;
while (true){
if((flag & result) != 0){
break;
}
flag <<= 1;
}
// 3. 所以我们可以用该比特位进行分组,分组的结果一定是,
// 相同数据被分到了同一组,不同数据一定被分到了不同的组,问题就转化成了两个问题一
for (int i = 0; i < array.length; i++) {
if((flag & array[i]) == 1){
num1[0] ^= array[i];
}else {
num2[0] ^= array[i];
}
}
}思路二:代码如下:
// 方法二 map
public void FindNumsAppearOnce1(int [] array,int num1[] , int num2[]) {
// 1. 先设置一个map集合,并将所有元素加入map集合中
Map map = new HashMap<>();
for(int i : array){
if(map.containsKey(i)){
// 如果map中已存在该元素,使该value+1
map.replace(i,map.get(i)+1);
}else {
map.put(i,1);
}
}
// 2. 遍历map集合,其中value值为1 的元素就是单身元素
int count = 0;
for(int i : array){
if(map.get(i) == 1){
if(count == 0){
num1[0] = i;
count ++;
}else {
num2[0] = i;
}
}
}
}
}