PairWise策略设计测试用例及PICT测试用例工具安装使用(实现测试用例的自动化)
一、我对于“好的”测试用例的理解和标准
个人认为,测试用例有点类似java语言的特点--也是需要面向对象操作的,并且还要考虑应用场景,才能保证用例具有针对性,高效性,全面性,合理性。例如针对一个项目,若存在用户端和运营端的话,从用户角度考虑,很多格式和长度是需要基本校验的,但也不是太死,例如对于一些非保存的操作就不需要校验长度值,例如查询条件的输入框就不需要做长度校验,用数据库的查询语句去想你就明白了,搜索不到默认就没有值;从运营人员的角度考虑,除了对应一些的格式要求规则需要做强制长度判断外,并不是所有都需要,例如密码的输入,有一套属于他的规则,就需要做长度判断了,但对于新增这种类保存操作,因为这种操作的规则是产品订的,后台又属于内部人员,就不需要那么严格对长度做校验了,不存在自己砸自己锅的行为吧,而且不是面向用户的操作内部也是可控的,再说,用户端的数据已经做了很好的把控和校验,到后台也基本不会存在这种问题,这样去写用例可以大大提高效率 。
针对测试用例的设计,我们有很多的方法和策略,目的都是为了使得测试用例更加丰富并且尽可能覆盖到更多的程序路径和场景。常见的测试用例设计方法有等价类划分法、边界值分析法、错误推断法等。常规思路都是希望测试用例越全面越完整越好,但在复杂的测试场景问题上,设计出完整全面的测试用例基本是不可能的,更何况还要保证在紧急项目的时候这就更不切实际了,另外巨大的测试用例相反也会降低测试效率,往往效果不尽人意。个人认为,最开始设计测试用例的时候希望做到“全面”,眼花缭乱的用例咋一看很是惊艳,但真正测试起来的时候便知道其效率有多低下,冗余有多繁杂,说这么多也是为了告诉大家,设计出全面完整的测试用例不是难事,难在如何将用例做减法。换句话说,如何用尽可能用较少的测试用例覆盖到更多的程序路径和功能场景,这才是算得上是一份“好的”测试用例。
测试用例的各种参数操作的排列组合,不经让人联想到数学,进而关于数学必将关联到算法问题,所以很多事其实并不需要埋头苦干,可以借鉴前人数学家的经验,将算法思想待入到编写测试用例中,做到灵活应用,而且还是经过大量数据验证和自己验证过的策略算法,还有现成的基于算法开发的工具,我觉得很有必要好好掌握,工具的使用基本是无脑的,只要你理解算法的意义和筛选用例的规则即可,然后就把你需要的数据交给工具去实现,可以大大的提高效率,不吹牛,信我往下看。
二、设计策略
常用的用例设计策略除了正交法外,还有pairwise算法,以及如下策略:
假设查询因子:A,B,C,D,E
1、单独查询:A;B;C;D;E
- 确保单独查询的正确性,这也是最基本的。
2、两个组合查询:AB;AC;AD;AE;BC;BD;BE;CD;CE;DE。
- 确保两个组合查询的正确性,这保证了两两之间不会相互影响。
3、三个组合查询:ABC;CDE
- 确保三个组合的正确性;因为我们已确保了单独及两个组合查询的正确性,所以不需要 测试三个组合的全部级组合。
4、五个组合查询:ABCDE
- 确保最大组合的正确性。
如果输入条件达到更多,可以考虑以下方法
1.单个条件遍历
2.默认条件查询
3.根据需求或者业务规则选取重点条件组合查询
4.全条件组合查询
5.根据查询所拼 SQL来修改查询条件进行查询
三、pairwise算法
1、背景介绍
Pairwise是L. L. Thurstone(29 May1887 – 30 September 1955)在1927年首先提出来的。他是美国的一位心理统计学家。Pairwise也正是基于数学统计和对传统的正交分析法进行优化后得到的产物。
Pairwise基于如下2个假设:
(1)每一个维度都是正交的,即每一个维度互相都没有交集。
(2)根据数学统计分析,73%的缺陷(单因子是35%,双因子是38%)是由单因子或2个因子相互作用产生的。19%的缺陷是由3个因子相互作用产生的。
因此,pairwise基于覆盖所有2因子的交互作用产生的用例集合性价比最高而产生的。
2、pairwise算法详解:
假设有3个维度,每个维度有几个因子。如下:
浏览器:M,O,P
操作平台:W(windows),L(linux),i(ios)
语言:C(chinese),E(english)
求解:
使用pairwise算法,有多少个测试case?具体是什么case?
我们沿用数学做题的格式。
解:
如果不用pairwise算法,我们需要 3*3*2=18个测试case。下面是具体的case:
1,M W C
2,MW E
3,M L C
4,M L E
5,M I C
6,M I E
7,O W C
8,O W E
9,O L C
10,O L E
11,O I C
12,O I E
13,P W C
14,P W E
15,P L C
16,P L E
17,P I C
18,P I E
一共有18个,很繁琐。但是这是100%的测试覆盖率,缺陷率也是100%。
现在我们使用pairwise,看看结果如何?
首先咱们从最下方一个18号开始,它是 P I E,两两组合是 PI ,PE ,IE。看这3个组合在以上的相同位置出现过没有,PI在17号,PE在16号,IE在12号出现过。所以18这个case就可以舍去。
最终剩下的如下:
1,MWC
4,MLE
6, MIE
7, OWE
9, OLC
11, OIC
14, PWE
15, PLC
17,PIC
共计9个测试case,节省了50%的测试case。
现在我们从上面开始重新做一次。1号是MWC,两两组合是MW MC WC 都出现过,去掉。
最终剩下的是:
2,MWE
4, MLE
5, MIC
8, OWE
10, OLE
11, OIC
13 PWC
15 PLC
18 PIE
这样也是剩下9个测试case,但是具体的case内容不一样。经过L. L. Thurstone证明,pairwise算法最终剩下的测试case个数肯定相同,但是可以有不同的case组合。
3、pairwise算法效率
Pairwise算法和正交分析法进行比较,当有3个维度,每个维度有4个因子的时候:
(1)正交分析法的case数量:4*4*4=64个
(2)Pairwise算法的case数量:20个
Pairwise的case数量是正交设计法的三分之一。当维度越多的时候,效果越明显。当有10个维度的时候 4*4*4*4*3*3*3*2*2*2=55296个测试case,pairwise为24个。是原始测试用例规模的0.04%。
再说大点,如果你想测试10个参数且每个参数都有26个值的功能,所有组合情况将导致141167095653376个测试用例。而pairWise设计测试用例只需要1094个测试用例既可以尽可以的覆盖到全的测试路径。
3、pairwise设计方法思维:
(1)获取维度和因子进行全排列。
(2)得到具体的case的两两因子组合(带位置)。
(3)判断这个case中两两因子组合是否在上面出现过,如果出现一个就删除掉。全部都没出现过,就保留这个case。
(4)按照不同的顺序使用pairwise算法再过滤一遍。
(5)得到2组数据,找出相同的case。
(6)按照维度的顺序增加case。
四、PICT测试用例设计工具的安装和使用
1、安装
PICT是微软的一个免费测试工具,可以生成成对的组合。pairwise是知当输入条件过多,覆盖样例太大时,为了有效的、合理的减少输入条件的组合数,pairwise能够简化问题大大减少组合数这里要是针对一个全新的系统,可以针对这些给出的组合造数据,突然想到是造数据神器。
windows版本下载链接:http://download.microsoft.com/download/f/5/5/f55484df-8494-48fa-8dbd-8c6f76cc014b/pict33.msi
mac版本下载链接:https://github.com/microsoft/pict
PICT 可以有效地按照两两测试的原理,进行测试用例设计。在使用PICT时,需要输入与测试用例相关的所有参数,以达到全面覆盖的效果。对了这个在jmeter的接口测试时也使用到了,可以查看我的文章:jmeter接口测试基本操作全解_LYX_WIN-CSDN博客
2、使用
(1)mac版本下载源码后解压直接进入源码路径下执行make命令
(2)前期需要准备一个生成测试用例的txt文件,而且这个txt文件必须放在安装目录同一文件夹下,否则没有作用
先来个实战案例背景:
Record:5年没有违规,3年没有违规,3年内违规小于3次,过去3年违规3次或3次以上,过去1年内违规3次或3次以上
Type:国产车,高档国产车,进口车,高档进口车
Method:出租车,商务车,私家车
Place:城市中心地带,市区,郊区,农村
Item:全保,自由组合,最基本保险
Years:小于1年,小于3年,小于5年,小于10年,大于10年
Insurance:首次保险,第二次参保,连续受保
if[Years]="小于1年" then [Record] in {"3年没有违规","3年内违规小于3次","过去1年内违规3次或3次以上"};
if[Years]="小于3年" then [Record] in {"3年没有违规","3年内违规小于3次","过去3年违规3次或3次以上","过去1年内违规3次或3次以上"};

注意:txt文档中的所有符号、冒号、逗号都是英文字符,中文字符无法识别;格式需要使用ANSI格式,试过UTF8无BOM格式,结果显示乱码(如何改变字体的编码格式,可以使用vi或vim命令编辑,也可以使用Notepad++或者sublime Text,个人觉得比较方便。
规则都写好了,后面都不用管了,你直管往txt文件里扔就是了,后面得都不需要你思考,大胆得交给PICT去解决吧。
(3)万事俱备,切换到安装目录下执行如下命令:
leiyuxingdeMacBook-Pro-2:pict leiyuxing$ ./pict Demo.txt结果:(是不是很6,你要的测试用例情况都有)
(4)都进行到这了,再附送一个操作,将你写的测试用例写到.xls文件里
leiyuxingdeMacBook-Pro-2:pict leiyuxing$ ./pict Demo.txt >Demo.xlsx此时会发现可能存在乱码问题,结果如下不尽人意:
这是vim的编码问题,Excel支持Windows上默认使用的简体中文编码GB2312。
解决:
1)首先先查看当前文件的编码格式,好进行编码转换:
vim打开文件,然后使用命令
:set fileencoding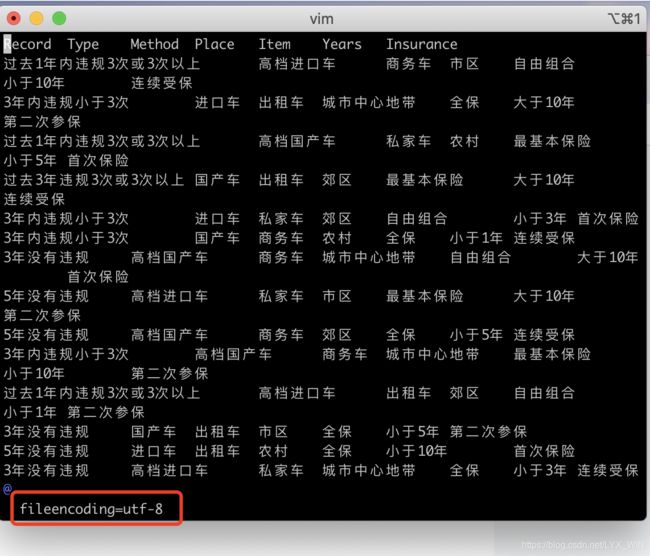
2)修改编码格式
命令格式:iconv -f UTF8 -t GB18030 源文件.csv >新文件.csv
实际执行例:iconv -f UTF8 -t GB18030 Demo.xls >Demo1.xls3)打开文件看下效果吧
完美解决,over!
为了方便懒人操作,写个脚本:新建一个文件名vim exit.sh
#!/bin/bash
./pict $1.txt >1$1.xls
iconv -f UTF8 -t GB18030 1$1.xls >$1.xls给脚本赋个权限:chmod 777 exit.sh
执行脚本:./exit.sh 文件名
参考链接:
1)多条件查询测试用例设计方法(1)—Pairwise(转) - 束河的阳光 - 博客园
2)深入浅出 pairwise 算法_aassddff261的专栏-CSDN博客_pairwise算法