PyTorch 全连接层权值共享的手势识别网络
机器人学实验课的考核是,利用机械臂做一下拓展应用,所以花了很多时间来设计了这个神经网络
因为这个神经网络的思路比较新颖,而且尝试了一些防止过拟合、性能优化的手段,所以决定记录一下
模型性能
| time | FPS | FLOTs | Params (float16) |
| 4.195 ms | 238 | 9,186,336 | 19.336 KB |
训练过程截图:展示平均损失、分类精度、分类准确率

卷积层
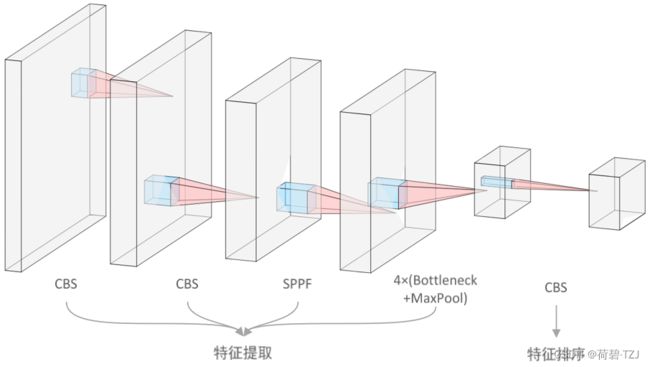
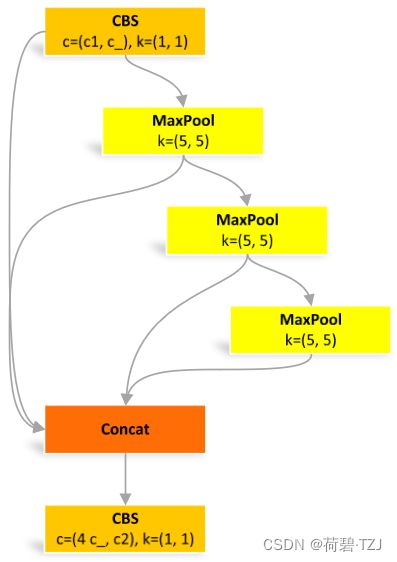
引入空间金字塔池化 SPPF,增强了神经网络对多尺度信息的感知能力
对 YOLOv5 中的 Bottleneck 进行修改:参数量减少到原来的 55%

末端的 1×1 卷积用于将特征进行排序,使其对左右手手势的增益信息在通道维度上对称

全连接层
为了防止左右手势识别结果的互相干扰,在使用卷积层提取出图像特征之后,在水平方向上进行分离:左半图特征、右半图特征
欲将两者利用同一个全连接层进行处理,需保证两者的特征分布有相同的形式:
- 左半图特征在翻转通道后,在通道上与右半图特征有相同的分布形式
- 右半图特征在水平翻转后,在水平上与左半图特征有相同的分布形式
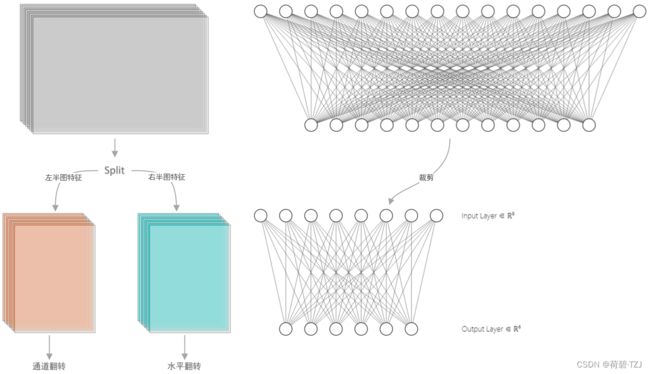
全连接层的权值共享,使得全连接层的训练量翻倍,也减少了网络模型参数量
左右手的手势分别有:none(无)、close(闭合)、in(向中间)、out(向两侧)、rise(向上)、drop(向下)
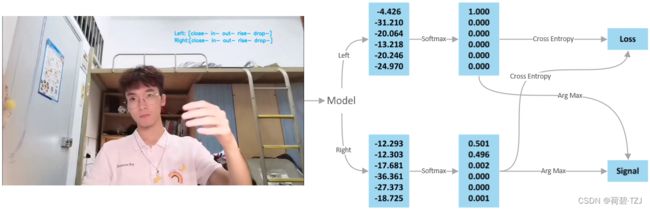
神经网络的声明如下,涉及到的网络单元见这篇文章:YOLOv5-6.0 源码解析 —— 卷积神经单元
class Model(nn.Module):
def __init__(self, shrink=6, e=0.75, hidden=[36, 18]):
super(Model, self).__init__()
# head: CBS, CBS, SPPF
c1, c2, c_ = 3, 6, 8
self.head = nn.Sequential(
Conv(c1, c2, k=3, s=2),
Conv(c2, c_, k=3, s=2),
SPPF(c_, c2)
)
c1 = c2
# bone: 4×(Bottleneck + MaxPool), CBS
self.bone = []
for _ in range(shrink - 2):
conv = Bottleneck(c1, c2, e=e)
step = nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
self.bone += [conv, step]
self.bone.append(Conv(c1, c2, k=1, s=1))
self.bone = nn.Sequential(*self.bone)
# mlp: [72, 36, 18, 6]
size = self.bone(self.head(torch.zeros([1, 3, *IMG_SHAPE]))).numel() // 2
self.mlp = MLP([size, *hidden, 6])
def forward(self, x):
batch_size = x.shape[0]
# 使用卷积层进行推导
x = self.head(x)
x = self.bone(x)
# 在水平轴上分割: 左半图信息、右半图信息
wu = x.shape[3] // 2
# 左半图在通道维度上翻转
x_l = x[..., :wu].flip(1).contiguous().view(batch_size, -1)
# 右半图在水平轴上翻转
x_r = x[..., wu:].flip(3).contiguous().view(batch_size, -1)
# 在新维度上拼接左半图、右半图
x = torch.stack([x_l, x_r], dim=1)
x = self.mlp(x, reshape=False)
return x损失计算
使用半精度训练方法,训练时 FPS 从原来的 482 提升到 675(提升40%)
- 在加载数据集时,对图像张量使用 .half(),将数据类型从 float32 转为 float16,节约了大量 CPU 资源
- 初始化 Model 后,使用 .half() 方法使使模型支持半精度训练,设置 Adam 优化器的 eps 为 1e-4,避免计算交叉熵时出现 nan
训练集损失收敛到 0.15 附近时,准确率也将近 99%;但测试集损失却越来越大,振荡范围在 [0.70, 0.90],准确率渐渐跌下 90%

针对严重的过拟合现象,采用了以下防过拟合的措施:
- 数据集刷新:每训练 10 轮,改变图像的饱和度、亮度、对比度
- 隐式数据增强:在训练中读取 batch 后,才对图像进行水平翻转,交换左右手势识别结果,使 batchsize 翻倍。几乎不增加 CPU 存储量,使数据集翻倍
- 低精度弥补:修改交叉熵损失的正例权值,使得网络可以偏向于提高某一类别的精度
- L2 范数正则化:

使用 Softmax 将全连接层的输出值转化为概率,只在交叉熵损失的作用下,可观察到概率越来越趋向于 Hard Pred
但很明显 Soft Pred 的信息更丰富,有助于网络泛化能力的提升,记概率向量为 w,正则项构造为:
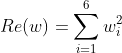
在训练过程中,与交叉熵损失加权;在测试过程中则不参与计算
BATCH_SIZE = 20
LEARN_RATE = 2e-3
REGULAR_WEIGHT = 2
class Classifier(Trainer):
''' 分类器
net: 网络模型
net_file: 网络模型保存路径 (.pt)'''
def __init__(self, net, net_file: str, lr: float, classes=10):...
def _forward(self, data_set, train: bool, prefix: str):
# 批信息
batch_num = len(data_set)
# 初始化分类精度计算器
counter = Pr_Counter(batch_num, prefix)
for idx, batch in enumerate(data_set):
loss, logits, target = self.loss(batch)
if train:
# 叠加正则项
regular = (logits.softmax(dim=2) ** 2).mean()
loss += REGULAR_WEIGHT * regular
# loss 反向传播梯度,并迭代
loss.backward()
self._optimizer.step()
self._optimizer.zero_grad()
# 更新分类精度计算器
avg_loss = counter.update(idx, logits, target, loss)
# 关闭进度条
counter.pbar.close()
return avg_loss
def loss(self, batch):
# 交叉熵正例权值
ce_weight = torch.tensor([.9, 1.2, 1.1, 1.0, 1.1, 1.2]).half().cuda()
# 水平翻转图像、改变标签, 拼接到原图像上完成数据增强
image, target = batch
image = torch.cat([image, image.flip(3)], dim=0).cuda()
target = torch.cat([target, target.flip(1)], dim=0).cuda()
# 调用神经网络
logits = self.net(image)
# 使用交叉熵损失
loss = F.cross_entropy(logits[:, 0], target[:, 0], weight=ce_weight) + \
F.cross_entropy(logits[:, 1], target[:, 1], weight=ce_weight)
return loss, logits, target随着训练轮次的增加,训练集的损失逐渐减小
没有正则项的作用时,测试集的损失越来越大,过拟合现象越来越严重
有正则项的作用时,测试集的损失相对更加平稳,没有明显的上升趋势
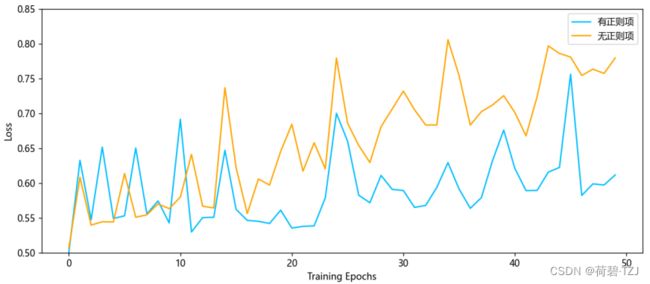
取得成效:AP 提升 4.01% (最终 86.66%),Acc 提升 2.00% (最终 92.84%)

信号管理器
读取视频并对每一帧图像进行识别后,将识别结果传进信号管理器,并记录“连续消失次数”、“连续出现次数”
- Tentative:当手势第 1 次出现时,记为不确定态,不对外展示
- Confirmd:当手势连续出现 3 次时,记为确信态,对外展示
- Deleted:当手势连续消失 3 次 / 未连续出现 3 次时,记为删除态,取消对外展示

信号管理器通过对三种状态的转换,实现了视频前后帧识别结果的关联,进一步提高了手势识别结果的连续性、平稳性
在使用网络对图像进行手势识别时,同时识别原图、水平翻转图像
- 左手识别结果: 原图左手识别结果 + 水平翻转后右手识别结果
- 右手识别结果: 原图右手识别结果 + 水平翻转后左手识别结果
不同图像识别结果的叠加,进一步提升了手势识别结果的可信度
def parse_signal(image, augment=True):
''' 图像 -> 手势识别结果'''
# 读取并对图像执行变换
image = Image.fromarray(image)
image = TRAN(image)
start = time.time()
if augment:
# 拼接上水平翻转图像
image = torch.stack([image, image.flip(2)], dim=0)
# 使用神经网络进行预测
logits = model(image).view(4, -1)
# 左手识别结果: 原图左手识别结果 + 水平翻转后右手识别结果
left_logits = logits[0] + logits[3]
# 右手识别结果: 原图右手识别结果 + 水平翻转后左手识别结果
right_logits = logits[1] + logits[2]
else:
left_logits, right_logits = model(image.unsqueeze(0))[0]
left_command = left_logits.argmax().item()
right_command = right_logits.argmax().item()
# 计算 FPS
cost = time.time() - start
fps = round(1 / cost)
return [left_command, right_command], f'FPS: {fps}'
class Signal_Manager:
state_dict = ['close', 'in', 'out', 'rise', 'drop']
def __init__(self, comfirm_time=3, loss_time=3):
# 系统参数
self.comfirm_time = comfirm_time
self.loss_time = loss_time
# 初始化状态记录器
self.state = torch.zeros([2, 5], dtype=torch.bool)
# 初始化消失、出现计数器
self.loss_count = torch.zeros_like(self.state, dtype=torch.uint8)
self.appear_count = torch.zeros_like(self.state, dtype=torch.uint8)
def receive(self, result):
# 生成命令掩膜
left_command, right_command = result
command = torch.zeros_like(self.state, dtype=torch.bool)
if left_command:
command[0][left_command - 1] = True
if right_command:
command[1][right_command - 1] = True
# 记录出现次数
self.appear_count += command
# 当出现次数达到 3 时, 才确信已经出现
self.state |= self.appear_count >= self.comfirm_time
# 如果出现则重新计算消失次数
self.loss_count *= ~ command
# 记录消失次数
self.loss_count += ~ command
# 判断动作是否已消失
keep_state = self.loss_count < self.loss_time
# 消失则从状态中抹除
self.state *= keep_state
# 未被抹除的继续计数
self.appear_count *= keep_state
# 数据剪枝
self.appear_count = torch.clip(self.appear_count, 0, self.comfirm_time)
self.loss_count = torch.clip(self.loss_count, 0, self.loss_time)
# 状态后处理
self.output_file()
return self.output_state()
def output_state(self, true='@', false='-'):
# 生成手势识别信息
message = ['Left: [', 'Right:[']
for i in range(2):
for action, state in zip(self.state_dict, self.state[i]):
state = true if state else false
message[i] += f'{action}{state} '
message[i] = message[i].rstrip() + ']'
# 输出识别信息
print(f'\r{message[0]} —— {message[1]}', end='')
return message
def output_file(self):
state = self.state.int()
tran = lambda item: str(item.item())
# 等待状态文件被读取
if CONTROL:
while os.path.isfile(STATE_FILE):
pass
# 写入状态文件
with open(STATE_FILE, 'w') as f:
f.write(' '.join(map(tran, state[0])))
f.write('\n')
f.write(' '.join(map(tran, state[1])))