【Python】05 - Python组合数据类型(列表、集合、元组、字典)
目录
一、组合数据类型概述
二、列表
2.1 什么是列表
2.2 列表的基本操作
2.3 列表方法
2.4 操作列表的常用内置函数
2.5 列表推导式
三、元组(tuple)——不可变序列
3.1 什么是元组
3.2 元组的读取
3.3 元组的修改——可修改,但可以生产新的元组对象
3.4 元组的删除
3.5 元组的基本操作
3.6 用于元组的内置函数
3.7 元组的省略写法
3.8 元组存在的意义
四、集合
4.1 常用方法
4.2 集合操作
4.3 集合推导式
4.4 适用场合:
五、字典
5.1 什么是字典
5.2 字典创建 (有多种方法)
5.3 字典读取
5.4 copy():复制字典(浅拷贝)
5.5 update():用一个字典替换另一个字典
5.6 字典删除
5.7 字典推导式
六、应用
1、ds参数默认值判断
练习
一、组合数据类型概述
(1)适用场合
很多时候,计算机需要对一组数据进行批量处理, 例如:给定一组单词{python, data, function, list, loop},计算并输出每个单词的长度
(2) 什么是组合数据类型
将多个同类型或不同类型的数据组织起来,通过单一的表示使数据操作更有序更容易。 根据数据之间的关系,组合数据类型可以分为三类:
- 序列类型:是一个元素向量,元素之间存在先后关系,通过序号访问,元素之间不排他
- 集合类型:是一个元素集合,元素之间无序,不允许出现重复元素
- 映射类型:是“键-值” 数据项的组合,每个元素是一个键值对,表示为(key, value)
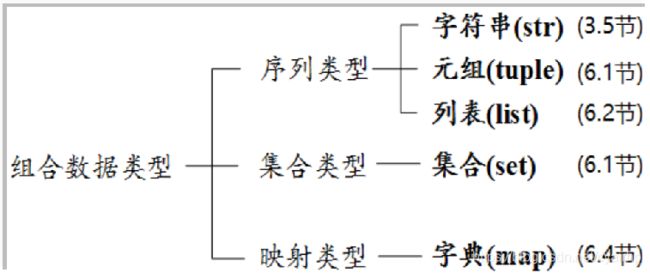
(3) 序列类型
Python语言中常用的序列类型包括:str(字符串)、 tuple(元组)和list(列表)
- 元组:包含0个或多个数据项的不可变序列类型,元组生成后是固定的,其中任何数据项不能替换或删除
- 列表:是一个可以修改数据项的序列类型,使用也最灵活
序列类型支持成员关系操作符(in)、 长度计算函数(len())、 分片([]),元素本身也可以是序列类型(即嵌套)

(4)集合类型
- 与数学中集合的概念一致,即包含0个或多个数据项的无序组合。
- 集合中元素不可重复,元素类型只能是固定数据类型,例如:整数、 浮点数、 字符串、 元组等,列表、 字典和集合类型本身都是可变数据类型,不能作为集合的元素出现。
- 由于集合是无序组合,它没有索引和位置的概念,不能分片,集合中元素可以动态增加或删除。 集合用花括号 {} 表示

(5)映射类型
映射类型是“键-值” 数据项的组合,每个元素是一个键值对,即元素是(key, value),元素之间是无序的。 键值对(key, value)是一种二元关系。 在Python中,映射类型主要以字典(dict)体现。
二、列表
2.1 什么是列表

- 使用方括号来定界,[ ] 表示空列表
- 逗号分隔元素,元素类型可以不同(比其它语言的”数组”功能更强大)
- 列表的元素也可以是一个列表(递归)
>>> list=['abc',30, [78, 60, 100]]
>>> list[2]
[78, 60, 100]
>>>- 也可以使用list()函数将元组、range对象、字符串或其他类型的可迭代对象类型的数据转换为列表

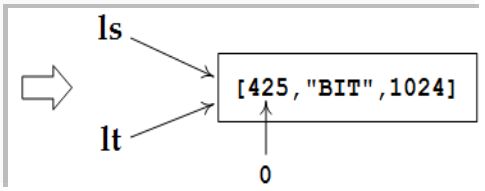
- 列表必须通过显式的数据赋值才能生成,简单将一个列表赋值给另一个列表不会生成新的列表对象

2.2 列表的基本操作
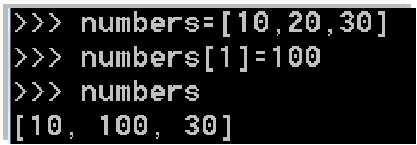
- 改变列表:通过索引值给特定元素赋值。不允许为位置不存在的元素赋值

- 删除元素或列表
- 删除列表中的元素:对象的 remove 方法
- 删除整个列表:
- del 命令 删除部分元素:


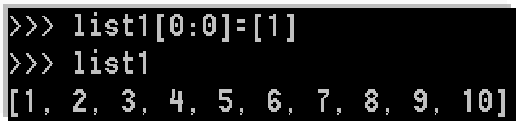
- 分片赋值(功能强大)
- 一次为多个元素赋值

- 实现“插入”功能
- 实现“删除”功能

请注意: 变量名不能使用关键字命名,例如:list、tuple、map等
2.3 列表方法
格式: 对象.方法(参数)
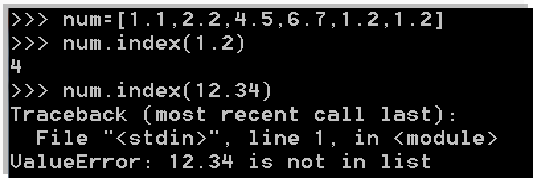
- index(值): 查找某值的第一个匹配项,返回索引值。无匹配项时,抛出异常
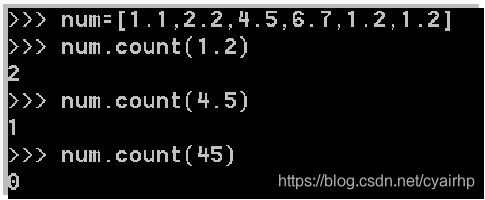
- count(值): 查找统计某元素在列表中出现次数
- append(元素): 在列表尾部增加新的元素

- extend(列表): 在列表的尾部一次性追加另一列表的多个值

比较: extend与append的不同点
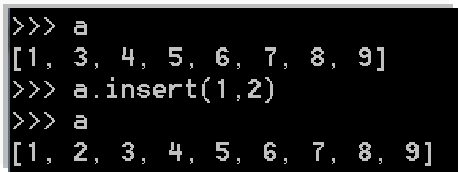
- insert(索引位置,元素): 在列表指定位置插入元素。但由于列表的自动内存管理功能,insert()方法会涉及到插入位置之后所有元素的移动,这会影响处理速度
- pop([索引位置]):删除并返回指定(默认为最后一个)位置上的元素,如果给定的索引超出了列表的范围则抛出异常。

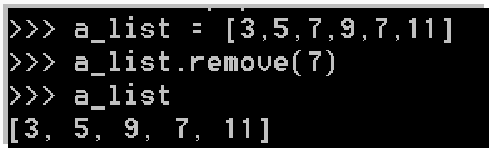
- remove(值): 在列表删除首次出现的指定元素,如果列表中不存在要删除的元素,则抛出异常
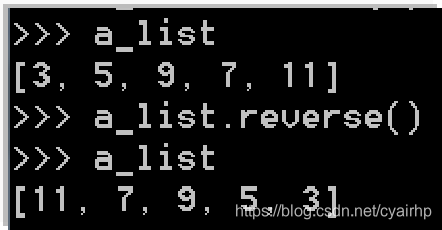
- reverse():将列表中的元素反向存放
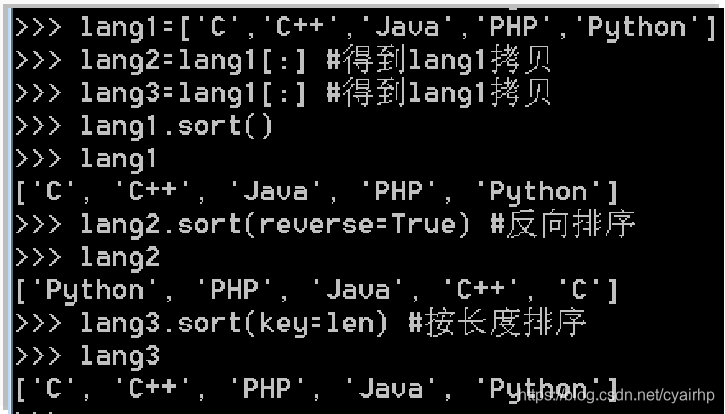
- sort(): 对列表元素进行排序,可加入一些选项
2.4 操作列表的常用内置函数
说明: 即参数为列表
- sum(列表):对数值型列表的元素进行求和运算,对非数值型列表运算则出错,同样适用于元组、range

- zip(列表1,列表2,…):将多个列表对应位置元素组合为元组,并返回包含这些元组的列表

- 其它函数: min()、max()、len()、sorted()等
2.5 列表推导式
- 什么是列表推导式?
Python程序开发时应用最多的技术之一,它以非常简洁的方式来快速生成满足特定需求的列表,代码具有非常强的可读性。例如:

相当于
aList = []
for x in range(10):
aList.append(x**2)
- 应用举例
1)使用列表推导式实现嵌套列表的平铺

2)过滤不符合条件的元素

3)使用多个循环,实现多序列元素的任意组合,并且可以结合条件语句过滤特定元素

三、元组(tuple)——不可变序列
3.1 什么是元组

- 用圆括号表示,( ) 表示空元组
- 元组与列表的区别在于:列表元素可变,而元组不可变。
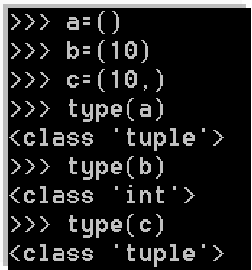
问题: ( )、(10)、(10,)的数据类型分别是什么?
3.2 元组的读取
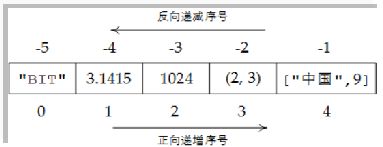
与列表相同(左边从0开始,右边从-1开始)
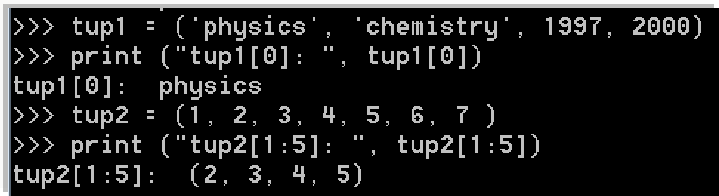
3.3 元组的修改——可修改,但可以生产新的元组对象

3.4 元组的删除
不可删除元组中的元素,但可以删除整个元组对象

3.5 元组的基本操作

3.6 用于元组的内置函数

3.7 元组的省略写法
- 在不引起混绕的情况下,元组的圆括号可以省略

- 用于赋值

3.8 元组存在的意义
表达固定数据项(如字典的key值)、 函数多返回值、多变量同步赋值、 循环遍历、函数可变参数等情况

四、集合
- 集合是无序可变序列,使用一对大括号{ }界定;
- 元素不可重复,同一个集合中每个元素都是唯一的;
- 集合中只能包含数字、字符串、元组等不可变类型(或者说可哈希)的数据,而不能包含列表、字典、集合等可变类型的数据;
- 可以通过 set 函数从其它序列对象生成集合,例如 set( range(1,10) )

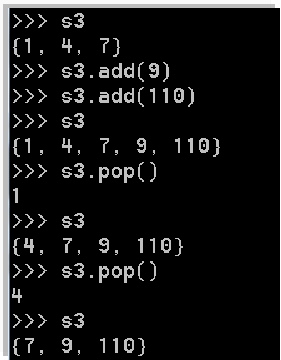
4.1 常用方法
- add( e ) 添加元素 e
- pop( ) 弹出(删除并返回)一个元素
- remove( e ) 删除指定元素 e
- clear()清空集合
- del删除整个集合
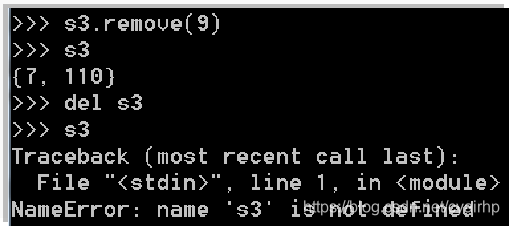
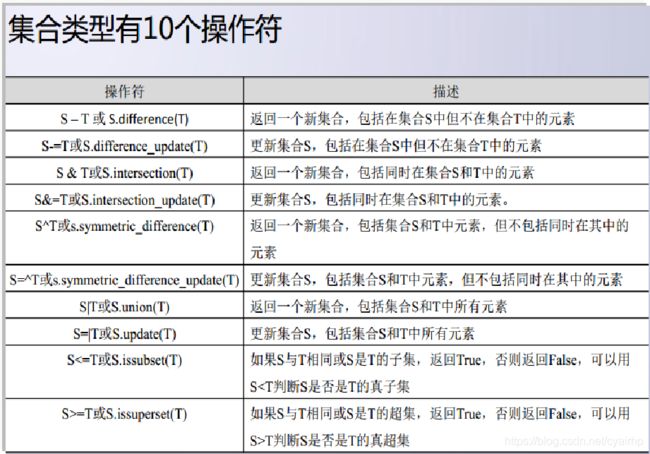
4.2 集合操作
- Python集合支持交集、并集、差集等运算


- 测试是否为子集、交集是否为空、比较大小

4.3 集合推导式

4.4 适用场合:
成员关系测试、 元素去重和删除数据项

五、字典
5.1 什么是字典
- 字典是无序可变序列;
- 定义字典时,每个元素(item)由键(key)和值(value)两部分组成,它们间用冒号分隔,元素之间用逗号分隔,所有的元素放在一对花括号{}中。{ }是空字典;
- 字典中的键可以为任意不可变数据,比如整数、实数、复数、字符串、元组等(不能是列表,why?);值可以是任何类型的数据,也可以是另一个字典对象。

5.2 字典创建 (有多种方法)
- 使用dict根据已有序列或迭代器创建(只带一个参数)
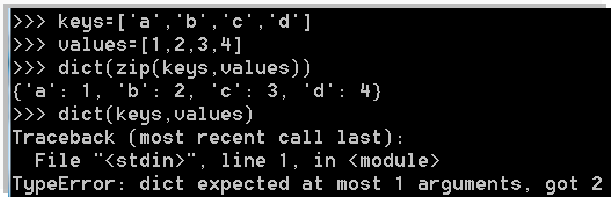



- 使用dict根据已有键、值创建

- 直接给字典的键值,如该键已存在,则修改其对应的值;否则,新增一个新键,并赋值

- 以给定内容为键,创建值为空(或指定值)的字典


5.3 字典读取
- 以 key 作为下标直接读取对应值
>>> d1 = {'id':2021, 'name':'xu'}
>>> d1['id']
2021
- 当找不到对应的键时,会报错
>>> d1['grade']
Traceback (most recent call last):
File "", line 1, in
KeyError: 'grade'
- get()获取指定键对应的值。即使指定键不存在时,也不会报错,返回None,当然也可以指定相应值
>>> d1
{'id': 2021, 'name': 'xu'}
>>> d1.get('name')
'xu'
>>> print(d1.get('grade'))
None
>>> d1.get('grade', '对应键不存在')
'对应键不存在'
- 内置方法
- keys():返回字典中的键
>>> d2 = {'id':2021, 'name':'xu', 'grade':2}
>>> d2.keys()
dict_keys(['id', 'name', 'grade'])
>>> for key in d2.keys():
... print(key,end=' ')
...
id name grade >>>-
- values():返回字典中的值
>>> d2.values()
dict_values([2021, 'xu', 2])
>>> for value in d2.values():
... print(value, end=' ')
...
2021 xu 2 >>>-
- items()返回字典中的键值对
>>> d2.items()
dict_items([('id', 2021), ('name', 'xu'), ('grade', 2)])
>>> for k,v in d2.items():
... print(k,':',v,end=' ')
...
id : 2021 name : xu grade : 2 >>>5.4 copy():复制字典(浅拷贝)
>>> d1 = {'name':'zhang','books':['book1','book2','book3']}
>>> id(d1)
2279721142536
>>> d2=d1.copy()
>>> id(d2)
2279719966744
>>> d2['name'] = 'li'
>>> d2
{'name': 'li', 'books': ['book1', 'book2', 'book3']}
>>> d2['books'].remove('book2')
>>> d2
{'name': 'li', 'books': ['book1', 'book3']}
>>> d1
{'name': 'zhang', 'books': ['book1', 'book3']}说明: 当在副本中修替换了值时,原字典不受影响;当在修改了某个值(原地修改,不是替换),则原字典会改变。
5.5 update():用一个字典替换另一个字典
>>> old={'one':1, 'two':2, 'three':3}
>>> x={'one':11}
>>> old.update(x)
>>> old
{'one': 11, 'two': 2, 'three': 3}
>>> y={'four':4}
>>> old.update(y)
>>> old
{'one': 11, 'two': 2, 'three': 3, 'four': 4}说明: 提供字典的项会被添加到原字典中去,若值相同,则被覆盖。
5.6 字典删除
- del删除字典中指定键的元素或整个字典;
- clear(): 删除字典中所有元素
- pop():删除并返回指定键的元素
- popitem():删除并返回字典中的一个元素
>>> d={'one':1, 'two':2, 'three':3, 'four':4}
>>> del d['one']
>>> d
{'two': 2, 'three': 3, 'four': 4}
>>> d.pop('three')
3
>>> d
{'two': 2, 'four': 4}
>>> d.popitem()
('four', 4)
>>> d
{'two': 2}
>>> d.clear()
>>> d
{}
>>> del d
>>> d
Traceback (most recent call last):
File "", line 1, in
NameError: name 'd' is not defined 请注意: 判断成员资格时,表达式 k in d(d为字典),查找的是键,而不是值
5.7 字典推导式
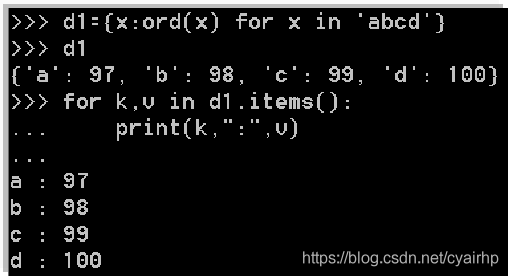
>>> d1={x:str(x) for x in range(1,6)}
>>> d1
{1: '1', 2: '2', 3: '3', 4: '4', 5: '5'}
>>> d2={x:x.lower() for x in 'AEIOU'}
>>> d2
{'A': 'a', 'E': 'e', 'I': 'i', 'O': 'o', 'U': 'u'}六、应用
1、ds参数默认值判断
para_list = []
if判断——>二元特征
if sum() = =0:
ok
else:
error
2、批量安装包
练习
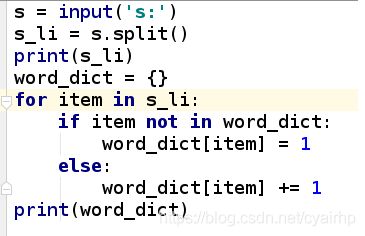
1、编写函数,用列表为参数,判断有无重复元素,并调用函数来验证;(字段重复)

2、将slist = ['a', 'b', 'cd', 'e', 'f', 'cd', 'g', 'h', 'i'] 转换为 [['a', 'b', 'cd', 'e', 'f'], ['a', 'b', 'cd', 'g', 'h', 'i']]
slist = ['a', 'b', 'cd', 'e', 'f', 'cd', 'g', 'h', 'i']
z = [] # 主支
dot_index = [] # 支点的所有位置及最后一个位置
# 输出主支
for i, j in enumerate(slist):
if j == 'cd':
dot_index.append(i)
if i < slist.index('cd'):
z.append(j)
# 添加最后一个位置
dot_index.append(len(slist))
final_list = []
for i in range(len(dot_index) - 1):
final_list.append(z + slist[dot_index[i]:dot_index[i+1]])
print(final_list)3、查看下面2张图片,看看如何将表格数据用字典表示?

