2019_KDD_KGAT_ Knowledge Graph Attention Network for Recommendation
2019_KDD_KGAT_ Knowledge Graph Attention Network for Recommendation
论文下载地址: https://doi.org/10.1145/3292500.3330989
发表期刊:KDD
Publish time: 2019
作者及单位:
- Xiang Wang National University of Singapore [email protected]
- Xiangnan He∗ University of Science and Technology of China [email protected]
- Yixin Cao National University of Singapore [email protected]
- Meng Liu Shandong University [email protected]
- Tat-Seng Chua National University of Singapore [email protected]
数据集:
- Amazon-book http://jmcauley.ucsd.edu/data/amazon
- Last-FM https://grouplens.org/datasets/hetrec-2011/
- Yelp2018 https://www.yelp.com/dataset/challenge
- 作者给的下载地址 https://github.
com/xiangwang1223/knowledge_graph_attention_network
代码:
- https://github.com/xiangwang1223/knowledge_graph_attention_network (论文给出的地址 tensorflow)
- https://github.com/LunaBlack/KGAT-pytorch (pytorch)
其他人写的文章
- 知识图注意力网络KGAT学习及代码讲解
- 【论文笔记】KGAT:融合知识图谱的 CKG 表示 + 图注意力机制的推荐系统
- KGAT_基于知识图谱+图注意力网络的推荐系统(KG+GAT)
- 论文笔记:《KGAT: Knowledge Graph Attention Network for Recommendation》
- 【论文笔记】KGAT:融合知识图谱的 CKG 表示 + 图注意力机制的推荐系统
- 复现KGAT: Knowledge Graph Attention Network for Recommendation(四)
- KGAT:代码阅读
- 知识图谱是如何增强推荐的,来通过pytorch深入理解KGAT模型
简要概括创新点:
- (1) In this work, we investigate the utility of knowledge graph (KG), which breaks down the independent interaction assumption by linking items with their attributes. (在这项工作中,我们研究了知识图谱(KG)的效用,它通过将项目与其属性联系起来,打破了独立交互的假设。)
- (2) In this work, we explore high-order connectivity with semantic relations in CKG for knowledge-aware recommendation. (在这项工作中,我们探索了CKG中语义关系的高阶连通性,以实现知识感知推荐。)
- (3) We propose a new method named Knowledge Graph Attention Network (KGAT) which explicitly models the high-order connectivities in KG in an end-to-end fashion. It recursively propagates the embeddings from a node’s neighbors (which can be users, items, or attributes) to refine the node’s embedding, and employs an attention mechanism to discriminate the importance of the neighbors. (我们提出了一种新的方法,称为知识图注意网络(KGAT),它以端到端的方式显式地建模KG中的高阶连通性。它递归地从节点的邻居(可以是用户、项目或属性)传播嵌入以细化节点的嵌入,并使用注意机制来区分邻居的重要性。)
- (4) KGAT is equipped with two designs to correspondingly address the challenges in high-order relation modeling: (该方法配备了两种设计,以相应地解决高阶关系建模中的挑战:)
- (1) recursive embedding propagation, which updates a node’s embedding based on the embeddings of its neighbors, and recursively performs such embedding propagation to capture high-order connectivities in a linear time complexity; and (递归嵌入传播,它基于节点邻居的嵌入更新节点的嵌入,并递归地执行这种嵌入传播以捕获线性时间复杂度中的高阶连通性)
- (2) attention-based aggregation, which employs the neural attention mechanism [6, 27] to learn the weight of each neighbor during a propagation, such that the attention weights of cascaded propagations can reveal the importance of a high-order connectivity. (基于注意的聚合,它利用神经注意机制[6,27]来学习传播过程中每个邻居的权重,这样级联传播的注意权重可以揭示高阶连接性的重要性。)
- (5) Figure 2 shows the model framework, which consists of three main components:
- (1) embedding layer, which parameterizes each node as a vector by preserving the structure of CKG; (嵌入层,通过保留CKG的结构将每个节点参数化为一个向量;)
- (2) attentive embedding propagation layers, which recursively propagate embeddings from a node’s neighbors to update its representation, and employ knowledge-aware attention mechanism to learn the weight of each neighbor during a propagation; (注意嵌入传播层,该层递归地传播来自节点邻居的嵌入以更新其表示,并且在传播过程中使用知识感知注意机制来学习每个邻居的权重;)
- and (3) prediction layer, which aggregates the representations of a user and an item from all propagation layers, and outputs the predicted matching score. (预测层,该层聚合来自所有传播层的用户和项目的表示,并输出预测的匹配分数)
- At it core is the attentive embedding propagation layer, which adaptively propagates the embeddings from a node’s neighbors to update the node’s epresentation. (其核心是注意力嵌入传播层,该层自适应地传播来自节点邻居的嵌入,以更新节点的epresentation。)
Abstract
- (1) To provide more accurate, diverse, and explainable recommendation, it is compulsory to go beyond modeling user-item interactions and take side information into account. Traditional methods like factorization machine (FM) cast it as a supervised learning problem, which assumes each interaction as an independent instance with side information encoded. Due to the overlook of the relations among instances or items (e.g., the director of a movie is also an actor of another movie), these methods are insufficient to distill the collaborative signal from the collective behaviors of users. (为了提供更准确、多样和可解释的建议,必须超越对用户项交互的建模,并考虑辅助信息。传统的方法如因子分解机(FM)将其视为一个有监督的学习问题,该问题假设每一次交互都是一个独立的实例,并对边信息进行编码。由于忽略了实例或项目之间的关系(例如,一部电影的导演也是另一部电影的演员),这些方法不足以从用户的集体行为中提取协作信号。)
- (2) In this work, we investigate the utility of knowledge graph (KG), which breaks down the independent interaction assumption by linking items with their attributes. (在这项工作中,我们研究了知识图谱(KG)的效用,它通过将项目与其属性联系起来,打破了独立交互的假设。)
- We argue that in such a hybrid structure of KG and user-item graph, high-order relations — which connect two items with one or multiple linked attributes — are an essential factor for successful recommendation. (我们认为,在KG和用户项目图的这种混合结构中,高阶关系——用一个或多个链接属性连接两个项目——是成功推荐的关键因素。)
- We propose a new method named Knowledge Graph Attention Network (KGAT) which explicitly models the high-order connectivities in KG in an end-to-end fashion. It recursively propagates the embeddings from a node’s neighbors (which can be users, items, or attributes) to refine the node’s embedding, and employs an attention mechanism to discriminate the importance of the neighbors. (我们提出了一种新的方法,称为知识图注意网络(KGAT),它以端到端的方式显式地建模KG中的高阶连通性。它递归地从节点的邻居(可以是用户、项目或属性)传播嵌入以细化节点的嵌入,并使用注意机制来区分邻居的重要性。)
- Our KGAT is conceptually advantageous to existing KG-based recommendation methods, which either exploit high-order relations by extracting paths or implicitly modeling them with regularization. (我们的KGAT在概念上优于现有的基于KG的推荐方法,这些方法要么通过提取路径来利用高阶关系,要么通过正则化隐式建模。)
- Empirical results on three public benchmarks show that KGAT significantly outperforms state-of-the-art methods like Neural FM [11] and RippleNet [29]. Further studies verify the efficacy of embedding propagation for high-order relation modeling and the interpretability benefits brought by the attention mechanism. (三个公共基准的实证结果表明,KGAT显著优于最先进的方法,如Neural FM[11]和RippleNet[29]。进一步的研究验证了嵌入传播对高阶关系建模的有效性,以及注意机制带来的可解释性好处。)
- We release the codes and datasets at https://github. com/xiangwang1223/knowledge_graph_attention_network.
CCS CONCEPTS
• Information systems → Recommender systems.
KEYWORDS
- Collaborative Filtering,
- Recommendation,
- Graph Neural Network,
- Higher-order Connectivity,
- Embedding Propagation,
- Knowledge Graph
1 INTRODUCTION
-
(1) The success of recommendation system makes it prevalent in Web applications, ranging from search engines, E-commerce, to social media sites and news portals — without exaggeration, almost every service that provides content to users is equipped with a recommendation system. To predict user preference from the key (and widely available) source of user behavior data, much research effort has been devoted to collaborative filtering (CF) [12, 13, 32]. (推荐系统的成功使其在从搜索引擎、电子商务到社交媒体网站和新闻门户网站的网络应用程序中普遍存在——毫不夸张地说,几乎所有向用户提供内容的服务都配备了推荐系统。为了从用户行为数据的关键(且广泛可用)来源预测用户偏好,协作过滤(CF)已经投入了大量研究工作[12,13,32]。)
- Despite its effectiveness and universality, CF methods suffer from the inability of modeling side information [30, 31], such as item attributes, user profiles, and contexts, thus perform poorly in sparse situations where users and items have few interactions. (尽管CF方法具有有效性和普遍性,但它无法对项目属性、用户配置文件和上下文等辅助信息进行建模[30,31],因此在用户和项目很少交互的稀疏情况下表现不佳。)
- To integrate such information, a common paradigm is to transform them into a generic feature vector, together with user ID and item ID, and feed them into a supervised learning (SL) model to predict the score. Such a SL paradigm for recommendation has been widely deployed in industry [7, 24, 40], and some representative models include factorization machine (FM) [23], NFM (neural FM) [11], Wide&Deep [7], and xDeepFM [18], etc. (为了整合这些信息,一个常见的范例是将它们与用户ID和项目ID一起转换为通用特征向量,并将它们输入到监督学习(SL)模型中以预测分数。这样的SL推荐范例已在行业中广泛应用[7,24,40],一些代表性模型包括因子分解机(FM)[23]、NFM(神经FM)[11]、Wide&Deep[7]和xDeepFM[18]等。)
-
(2) Although these methods have provided strong performance, a deficiency is that they model each interaction as an independent data instance and do not consider their relations. This makes them insufficient to distill attribute-based collaborative signal from the collective behaviors of users. (虽然这些方法提供了很强的性能,但缺点是它们将每个交互建模为独立的数据实例,而不考虑它们之间的关系。这使得它们不足以从用户的集体行为中提取基于属性的协作信号。)
- As shown in Figure 1, there is an interaction between user u 1 u_1 u1 and movie i 1 i_1 i1, which is directed by the person e 1 e_1 e1.

Figure 1: A toy example of collaborative knowledge graph. u 1 u_1 u1 is the target user to provide recommendation for. The yellow circle and grey circle denote the important users and items discovered by high-order relations but are overlooked by traditional methods. Best view in color. - CF methods focus on the histories of similar users who also watched i 1 i_1 i1, i.e., u 4 u_4 u4 and u 5 u_5 u5; (比如下图2中,用户 u 1 u_1 u1看了电影 i 1 i_1 i1,这个电影是 e 1 e_1 e1导演的,传统的CF方法会着重去找那些也看了电影 i 1 i_1 i1的用户,比如 u 4 u_4 u4跟 u 5 u_5 u5)
- while SL methods emphasize the similar items with the attribute e 1 e_1 e1,i.e., i 2 i_2 i2. (而监督学习方法会重点关注那些有相同属性 e 1 e_1 e1的电影,比如 i 2 i_2 i2)
- Obviously, these two types of information not only are complementary for recommendation, but also form a high-order relationship between a target user and item together. (显然,这两类信息不仅是推荐的补充,而且在目标用户和项目之间形成了一种高阶关系。)
- However, existing SL methods fail to unify them and cannot take into account the high-order connectivity, (然而,现有的SL方法不能统一它们,不能考虑高阶连通性)
- such as the users in the yellow circle who watched other movies directed by the same person e 1 e_1 e1, or the items in the grey circle that share other common relations with e 1 e_1 e1. (例如黄色圆圈中观看同一人导演的其他电影的用户 e 1 e_1 e1, 或灰色圆圈中与 e 1 e_1 e1有其他共同关系的项目 .)
- As shown in Figure 1, there is an interaction between user u 1 u_1 u1 and movie i 1 i_1 i1, which is directed by the person e 1 e_1 e1.
-
(3) To address the limitation of feature-based SL models, a solution is to take the graph of item side information, a k a aka aka. knowledge graph(A KG is typically described as a heterogeneous network consisting of entity-relation-entity triplets, where the entity can be an item or an attribute.)[3, 4], into account to construct the predictive model. We term the hybrid structure of knowledge graph and user-item graph as collaborative knowledge graph (CKG). As illustrated in Figure 1, the key to successful recommendation is to fully exploit the high-order relations in CKG, e.g., the long-range connectivities: (为了解决基于特征的SL模型的局限性,一个解决方案是采用项目辅助信息图 aka知识图谱(KG通常被描述为由实体-关系-实体三元组组成的异构网络,其中实体可以是项目或属性)[3,4],用于构建预测模型。我们将知识图谱和用户项目图的混合结构称为协作知识图(CKG)。如图1所示,成功推荐的关键是充分利用CKG中的高阶关系,例如远程连接性)

- which represent the way to the yellow and grey circle, respectively. Nevertheless, to exploit such high-order information the challenges are non-negligible: (分别代表通往黄色和灰色圆圈的道路。然而,要利用这种高阶信息,挑战是不容忽视的:)
- (1) the nodes that have high-order relations with the target user increase dramatically with the order size, which imposes computational overload to the model, and (与目标用户具有高阶关系的节点随着阶数的增加而急剧增加,这给模型带来了计算负担,并且)
- (2) the high-order relations contribute unequally to a prediction, which requires the model to carefully weight (or select) them. (高阶关系对预测的贡献是不平等的,这需要模型仔细地对它们进行加权(或选择)。)
- which represent the way to the yellow and grey circle, respectively. Nevertheless, to exploit such high-order information the challenges are non-negligible: (分别代表通往黄色和灰色圆圈的道路。然而,要利用这种高阶信息,挑战是不容忽视的:)
-
(4) Several recent efforts have attempted to leverage the CKG structure for recommendation, which can be roughly categorized
into two types, path-based [14, 25, 29, 33, 37, 39] and regularization-based [5, 15, 33, 38]: (最近几次尝试利用CKG结构进行推荐,推荐大致分为两种类型,基于路径的[14,25,29,33,37,39]和基于正则化的[5,15,33,38]:)- Path-based methods extract paths that carry the high-order information and feed them into predictive model. (基于路径的方法提取携带高阶信息的路径,并将其输入预测模型)
- To handle the large number of paths between two nodes, they have either applied path selection algorithm to select prominent paths [25, 33], or defined meta-path patterns to constrain the paths [14, 36]. (为了处理两个节点之间的大量路径,他们要么应用路径选择算法来选择突出的路径[25,33],要么定义元路径模式来约束路径[14,36]。)
- One issue with such two-stage methods is that the first stage of path selection has a large impact on the final performance, but it is not optimized for the recommendation objective. (这种两阶段方法的一个问题是,路径选择的第一阶段对最终性能有很大影响,但它没有针对推荐目标进行优化)
- Moreover, defining effective meta-paths requires domain knowledge, which can be rather labor-intensive for complicated KG with diverse types of relations and entities, since many meta-paths have to be defined to retain model fidelity. (此外,定义有效的元路径需要领域知识,这对于具有不同类型关系和实体的复杂KG来说可能是相当费力的,因为必须定义许多元路径以保持模型保真度。)
- Regularization-based methods devise additional loss terms that capture the KG structure to regularize the recommender model learning. (基于正则化的方法设计额外的损失项来捕获KG结构,以正则化推荐模型学习。)
- For example, KTUP [5] and CFKG [1] jointly train the two tasks of recommendation and KG completion with shared item embeddings. Instead of directly plugging high-order relations into the model optimized for recommendation, these methods only encode them in an implicit manner. Due to the lack of an explicit modeling, neither the long-range connectivities are guaranteed to be captured, nor the results of high-order modeling are interpretable. (例如,KTUP[5]和CFKG[1]通过共享项目嵌入,共同培训推荐和KG完成这两项任务。这些方法没有直接将高阶关系插入到为推荐而优化的模型中,而是以隐式方式对它们进行编码。由于缺乏明确的建模,既不能保证捕捉到长程连通性,也不能解释高阶建模的结果。)
- Path-based methods extract paths that carry the high-order information and feed them into predictive model. (基于路径的方法提取携带高阶信息的路径,并将其输入预测模型)
-
(5) Considering the limitations of existing solutions, we believe it is of critical importance to develop a model that can exploit high-orderinformation in KG in an efficient, explicit, and end-to-end manner. (考虑到现有解决方案的局限性,我们认为开发一个能够以高效、明确和端到端的方式利用KG中的高阶信息的模型至关重要。)
- Towards this end, we take inspiration from the recent developments of graph neural networks [9, 17, 28], which have the potential of achieving the goal but have not been explored much for KG-based recommendation. (为此,我们从图形神经网络[9,17,28]的最新发展中得到启发,这些网络具有实现目标的潜力,但对于基于KG的推荐还没有进行太多探索。)
- Specifically, we propose a new method named Knowledge Graph Attention Network (KGAT), which is equipped with two designs to correspondingly address the challenges in high-order relation modeling: (具体而言,我们提出了一种新方法,名为知识图注意网络(KGAT),该方法配备了两种设计,以相应地解决高阶关系建模中的挑战:)
- (1) recursive embedding propagation, which updates a node’s embedding based on the embeddings of its neighbors, and recursively performs such embedding propagation to capture high-order connectivities in a linear time complexity; and (递归嵌入传播,它基于节点邻居的嵌入更新节点的嵌入,并递归地执行这种嵌入传播以捕获线性时间复杂度中的高阶连通性)
- (2) attention-based aggregation, which employs the neural attention mechanism [6, 27] to learn the weight of each neighbor during a propagation, such that the attention weights of cascaded propagations can reveal the importance of a high-order connectivity. (基于注意的聚合,它利用神经注意机制[6,27]来学习传播过程中每个邻居的权重,这样级联传播的注意权重可以揭示高阶连接性的重要性。)
- Our KGAT is conceptually advantageous to existing methods in that: (我们的KGAT在概念上比这方面的现有方法更有利)
- (1) compared with path-based methods, it avoids the labor- intensive process of materializing paths, thus is more efficient and convenient to use, and (与基于路径的方法相比,它避免了物化路径的劳动密集型过程,因此更高效、更方便)
- (2) compared with regularization-based methods, it directly factors high-order relations into the predictive model, thus all related parameters are tailored for optimizing the recommendation objective. (与基于正则化的方法相比,它直接将高阶关系引入预测模型,因此所有相关参数都是为优化推荐目标而定制的)
-
(6) The contributions of this work are summarized as follows:
- We highlight the importance of explicitly modeling the high-order relations in collaborative knowledge graph to provide better recommendation with item side information. (我们强调了在协作知识图中显式建模高阶关系的重要性,以提供更好的项目侧信息推荐。)
- We develop a new method KGAT, which achieves high-order relation modeling in an explicit and end-to-end manner under the graph neural network framework. (我们开发了一种新的方法KGAT,它在图形神经网络框架下以显式和端到端的方式实现高阶关系建模。)
- We conduct extensive experiments on three public benchmarks, demonstrating the effectiveness of KGAT and its interpretability
in understanding the importance of high-order relations. (我们在三个公共基准上进行了广泛的实验,证明了KGAT的有效性及其在理解高阶关系重要性方面的可解释性。)
2 TASK FORMULATION
- We first introduce the concept of CKG and highlight the high-order connectivity among nodes, as well as the compositional relations. (我们首先介绍了CKG的概念,并强调了节点之间的高阶连通性,以及组成关系)
2.1 User-Item Bipartite Graph:
- (1) In a recommendation scenario, we typically have historical user-item interactions ( e . g . e.g. e.g., purchases and clicks).
- Here we represent interaction data as a user-item bipartite graph G 1 \mathcal{G}_1 G1, which is defined as { ( u , y u i , i ) ∣ u ∈ U , i ∈ I ) } \{(u, y_{ui}, i) | u ∈ \mathcal{U}, i \in \mathcal{I})\} {(u,yui,i)∣u∈U,i∈I)},
- where U \mathcal{U} U and I \mathcal{I} I separately denote the user and item sets,
- and a link y u i = 1 y_{ui} = 1 yui=1 indicates that there is an observed interaction between user u u u and item i i i; otherwise y u i y_{ui} yui= 0.
- Here we represent interaction data as a user-item bipartite graph G 1 \mathcal{G}_1 G1, which is defined as { ( u , y u i , i ) ∣ u ∈ U , i ∈ I ) } \{(u, y_{ui}, i) | u ∈ \mathcal{U}, i \in \mathcal{I})\} {(u,yui,i)∣u∈U,i∈I)},
2.2 Knowledge Graph.
- (1) In addition to the interactions, we have side information for items (e.g., item attributes and external knowledge). Typically, such auxiliary data consists of real-world entities and relationships among them to profile an item. For example, a movie can be described by its director, cast, and genres.
- We organize the side information in the form of knowledge graph G 2 \mathcal{G}_2 G2, which is a directed graph composed of subject-property-object triple facts [5]. Formally, it is presented as { ( h , r , t ) ∣ h , t ∈ E , r ∈ R } \{(h, r, t) | h,t \in\mathcal{E}, r \in \mathcal{R}\} {(h,r,t)∣h,t∈E,r∈R}, where each triplet describes that there is a relationship r r r from head entity h h h to tail entity t t t.
- For example, (Hugh Jackman, ActorOf, Logan) states the fact that Hugh Jackman is an actor of the movie Logan. Note that R \mathcal{R} R contains relations in both canonical direction (e.g., ActorOf) and inverse direction (e.g., ActedBy).
- Moreover, we establish a set of item-entity alignments A = { ( i , e ) ∣ i ∈ I , e ∈ E } \mathcal{A} = \{(i,e)|i \in \mathcal{I},e \in \mathcal{E}\} A={(i,e)∣i∈I,e∈E}, where ( i , e ) (i,e) (i,e) indicates that item i i i can be aligned with an entity e e e in the KG.
2.3 Collaborative Knowledge Graph.
- (1) Here we define the concept of CKG, which encodes user behaviors and item knowledge as a unified relational graph.
- We first represent each user behavior as a triplet, ( u u u, Interact, i i i), where y u i = 1 y_{ui}= 1 yui=1 is represented as an additional relation Interact between user u u u and item i i i.
- Then based on the item-entity alignment set, the user-item graph can be seamlessly integrated with KG as a unified graph G = { ( h , r , t ) ∣ h , t ∈ E ′ , r ∈ R ′ } \mathcal{G} = \{(h,r,t)|h,t \in \mathcal{E}',r \in \mathcal{R}'\} G={(h,r,t)∣h,t∈E′,r∈R′}, where E ′ = E ∪ U \mathcal{E}'= \mathcal{E} \cup \mathcal{U} E′=E∪U and R ′ = R ∪ { I n t e r a c t } \mathcal{R}' = \mathcal{R} \cup \{Interact\} R′=R∪{Interact}
2.4 Task Description
We now formulate the recommendation task to be addressed in this paper:
- Input: collaborative knowledge graph G \mathcal{G} G that includes the user-item bipartite graph G 1 \mathcal{G}_1 G1 and knowledge graph G 2 \mathcal{G}_2 G2.
- Output: a prediction function that predicts the probability y ^ u i \hat{y}_{ui} y^ui that user u u u would adopt item i i i.
2.5 High-Order Connectivity.
- (1) Exploiting high-order connectivity is of importance to perform high-quality recommendation.
- Formally, we define the L L L-order connectivity between nodes as ==a multi-hop relation path: e 0 ⟶ r 1 e 1 ⟶ r 2 . . . ⟶ r L e L e_0 \stackrel{r_1}{\longrightarrow} e_1 \stackrel{r_2}{\longrightarrow} ... \stackrel{r_L}{\longrightarrow} e_L e0⟶r1e1⟶r2...⟶rLeL , where e l ∈ E ′ e_l \in \mathcal{E}' el∈E′ and r l ∈ R ′ r_l \in \mathcal{R}' rl∈R′; ( e l − 1 , r l , e l ) (e_{l−1} ,r_l, e_l) (el−1,rl,el) is the l l l-th triplet, and L L L is the length of the sequence.
- To infer user preference, CF methods build upon behavior similarity among users—more specifically similar users would exhibit similar preferences on items. Such intuition can be represented as behavior-based connectivity like u 1 ⟶ r 1 i 1 ⟶ − r 1 u 2 ⟶ r 1 i 2 u_1 \stackrel{r_1}{\longrightarrow} i_1 \stackrel{-r_1}{\longrightarrow} u_2 \stackrel{r1}{\longrightarrow} i_2 u1⟶r1i1⟶−r1u2⟶r1i2, which suggests that u 1 u_1 u1 would exhibit preference on i 2 i_2 i2, since her similar user u 2 u_2 u2 has adopted i 2 i_2 i2 before.
- Distinct from CF methods, SL models like FM and NFM focus on attributed-based connectivity, assuming that users tend to adopt items that share similar properties. For example, u 1 ⟶ r 1 i 1 ⟶ r 2 e 1 ⟶ − r 2 i 2 u_1 \stackrel{r_1}{\longrightarrow} i_1 \stackrel{r_2}{\longrightarrow} e_1 \stackrel{-r_2}{\longrightarrow} i_2 u1⟶r1i1⟶r2e1⟶−r2i2 suggests that u 1 u_1 u1 would adopt i 2 i_2 i2 since it has the same director e 1 e_1 e1 with i 1 i_1 i1 she liked before.
- However, FM and NFM treat entities as the values of individual feature fields, failing to reveal relatedness across fields and related instances. For instance, it is hard to model u 1 ⟶ r 1 i 1 ⟶ r 2 e 1 ⟶ − r 3 i 2 u_1 \stackrel{r_1}{\longrightarrow} i_1 \stackrel{r_2}{\longrightarrow} e1 \stackrel{-r_3}{\longrightarrow} i_2 u1⟶r1i1⟶r2e1⟶−r3i2, although e 1 e_1 e1 serves as the bridge connecting director and actor fields. We therefore argue that these methods do not fully explore the high-order connectivity and leave compositional high-order relations untouched. (将实体视为单个要素字段的值,无法显示字段和相关实例之间的关联性) (因此,我们认为这些方法没有充分探索高阶连接性,也没有触及成分的高阶关系)
3 METHODOLOGY
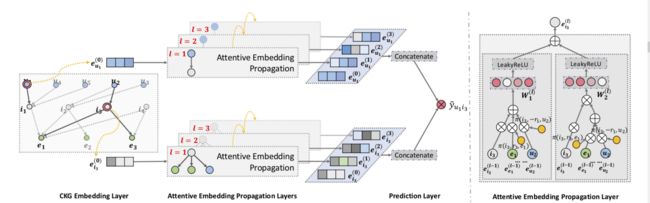
Figure 2: Illustration of the proposed KGAT model. The left subfigure shows model framework of KGAT, and the right subfigure presents the attentive embedding propagation layer of KGAT.
- We now present the proposed KGAT model, which exploits high-order relations in an end-to-end fashion. (我们现在提出了拟议的KGAT模型,该模型以端到端的方式利用高阶关系。)
- Figure 2 shows the model framework, which consists of three main components:
- (1) embedding layer, which parameterizes each node as a vector by preserving the structure of CKG; (嵌入层,通过保留CKG的结构将每个节点参数化为一个向量;)
- (2) attentive embedding propagation layers, which recursively propagate embeddings from a node’s neighbors to update its representation, and employ knowledge-aware attention mechanism to learn the weight of each neighbor during a propagation; (注意嵌入传播层,该层递归地传播来自节点邻居的嵌入以更新其表示,并且在传播过程中使用知识感知注意机制来学习每个邻居的权重;)
- and (3) prediction layer, which aggregates the representations of a user and an item from all propagation layers, and outputs the predicted matching score. (预测层,该层聚合来自所有传播层的用户和项目的表示,并输出预测的匹配分数)
3.1 Embedding Layer
-
(1) Knowledge graph embedding is an effective way to parameterize entities and relations as vector representations, while preserving the graph structure. (知识图谱嵌入是一种将实体和关系参数化为向量表示的有效方法,同时保留了图的结构。)
- Here we employ TransR [19], a widely used method, on CKG. To be more specific, it learns embeds each entity and relation by optimizing the translation principle e h r + e r ≈ e t r e^r_h + e_r \approx e^r_t ehr+er≈etr, if a triplet ( h , r , t ) (h,r,t) (h,r,t) exists in the graph.
- Herein, e h , e t ∈ R d e_h, e_t∈ R^d eh,et∈Rd and e r ∈ R k e_r∈ R^k er∈Rk are the embedding for h h h, t t t, and r r r, respectively;
- and e h r e^r_h ehr, e t r e^r_t etr are the projected representations of e h e_h eh and e t e_t et in the relation r ’ s r’s r’s space.
- Hence, for a given triplet ( h , r , t ) (h,r,t) (h,r,t), its plausibility score (or energy score) is formulated as follows: (其合理性评分(或能量评分)公式如下)

- where W r ∈ R k × d W_r \in R^{k\times d} Wr∈Rk×d is the transformation matrix of relation r r r, which projects entities from the d d d-dimension entity space into the k k k-dimension relation space. A lower score of g ( h , r , t ) g(h,r,t) g(h,r,t) suggests that the triplet is more likely to be true true, and vice versa. (这表明三元组更可能是真的,反之亦然)
- Here we employ TransR [19], a widely used method, on CKG. To be more specific, it learns embeds each entity and relation by optimizing the translation principle e h r + e r ≈ e t r e^r_h + e_r \approx e^r_t ehr+er≈etr, if a triplet ( h , r , t ) (h,r,t) (h,r,t) exists in the graph.
-
(2) The training of TransR considers the relative order between valid triplets and broken ones, and encourages their discrimination through a pairwise ranking loss: (TransR的训练考虑了有效三胞胎和破碎三胞胎之间的相对顺序,并通过两两排序损失鼓励它们的区分)

- where τ = ( h , r , t , t ′ ) ∣ ( h , r , t ) ∈ G , ( h , r , t ′ ) ∉ G \tau = {(h,r,t,t')|(h,r,t) \in \mathcal{G}, (h,r,t') \notin \mathcal{G}} τ=(h,r,t,t′)∣(h,r,t)∈G,(h,r,t′)∈/G , and ( h , r , t ′ ) (h,r,t') (h,r,t′) is a broken triplet constructed by replacing one entity in a valid triplet randomly;
- σ ( ⋅ ) \sigma(\cdot) σ(⋅) is the sigmoid function.
- This layer models the entities and relations on the granularity of triples, working as a regularizer and injecting the direct connections into representations, and thus increases the model representation ability (evidences in Section 4.4.3.) (该层在三元组的粒度上对实体和关系进行建模,充当正则化器,并将直接连接注入表示中,从而提高模型表示能力(见第4.4.3节))
3.2 Attentive Embedding Propagation Layers
- (1) Next we build upon the architecture of graph convolution network [17] to recursively propagate embeddings along high-order connectivity; (接下来,我们基于图卷积网络[17]的体系结构,沿着高阶连通性递归传播嵌入;)
- moreover, by exploiting the idea of graph attention network [28], we generate attentive weights of cascaded propagations to reveal the importance of such connectivity. (此外,通过利用图注意网络[28]的思想,我们生成级联传播的注意权重,以揭示这种连通性的重要性。)
- Here we start by describing a single layer, which consists of three components:
- information propagation, (信息传播)
- knowledge-aware attention, (知识意识注意力)
- and information aggregation, (信息聚合)
- and then discuss how to generalize it to multiple layers. (然后讨论如何将其推广到多个层次)
3.2.1 Information Propagation:
- (1) One entity can be involved in multiple triplets, serving as the bridge connecting two triplets and propagating information. Taking e 1 ⟶ r 2 i 2 ⟶ − r 1 u 2 e_1 \stackrel{r_2}{\longrightarrow} i_2 \stackrel{-r_1}{\longrightarrow} u_2 e1⟶r2i2⟶−r1u2 and e 2 ⟶ r 3 i 2 ⟶ − r 1 u 2 e_2 \stackrel{r_3}{\longrightarrow} i_2 \stackrel{-r_1}{\longrightarrow}u_2 e2⟶r3i2⟶−r1u2 as an example, item i 2 i_2 i2 takes attributes e 1 e_1 e1 and e 2 e_2 e2 as inputs to enrich its own features, and then contributes user u 2 u_2 u2’s preferences, which can be simulated by propagating information from e 1 e_1 e1 to u 2 u_2 u2. We build upon this intuition to perform information propagation between an entity and its neighbors. (项目 i 2 i_2 i2获取属性 e 1 e_1 e1和 e 2 e_2 e2作为输入来丰富自己的功能,然后贡献给用户 u 2 u_2 u2’s偏好,可以通过传播来自 e 1 e_1 e1的信息给 u 2 u_2 u2来模拟 . 我们基于这种直觉来执行实体与其邻居之间的信息传播)
- (2) Considering an entity h h h, we use N h = { ( h , r , t ) ∣ ( h , r , t ) ∈ G } N_h= \{(h,r,t)|(h,r,t) \in \mathcal{G}\} Nh={(h,r,t)∣(h,r,t)∈G} to denote the set of triplets where h h h is the head entity, termed ego-network [21]. To characterize the first-order connectivity structure of entity h h h, we compute the linear combination of h’s ego-network:
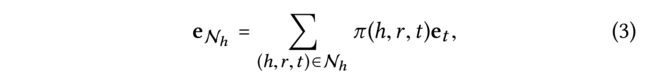
- where π ( h , r , t ) \pi (h,r,t) π(h,r,t) controls the decay factor on each propagation on edge ( h , r , t ) (h,r,t) (h,r,t), indicating how much information being propagated from t t t to h h h conditioned to relation r r r.
3.2.2 Knowledge-aware Attention:
- We implement π ( h , r , t ) \pi (h,r,t) π(h,r,t) via relational attention mechanism, which is formulated as follows:

- where we select tanh [28] as the nonlinear activation function. This makes the attention score dependent on the distance between e h e_h eh and e t e_t et in the relation r r r’s space, e.g., propagating more information for closer entities. Note that, we employ only inner product on these representations for simplicity, and leave the further exploration of the attention module as the future work.
- (2) Hereafter, we normalize the coefficients across all triplets connected with h h h by adopting the softmax function:

- (3) As a result, the final attention score is capable of suggesting which neighbor nodes should be given more attention to capture
collaborative signals. When performing propagation forward, the attention flow suggests parts of the data to focus on, which can be treated as explanations behind the recommendation. (因此,最终的注意力分数能够建议应该给予哪些邻居节点更多的注意力来捕获协作信号。当执行向前传播时,注意力流建议关注部分数据,这可以被视为建议背后的解释。) - (4) Distinct from the information propagation in GCN [17] and GraphSage [9] which set the discount factor between two nodes as 1 / ∣ N h ∣ ∣ N t ∣ 1/\sqrt{|N_h||N_t|} 1/∣Nh∣∣Nt∣ or 1 / ∣ N t ∣ 1/|N_t| 1/∣Nt∣, our model not only exploits the proximity structure of graph, but also specify varying importance of neighbors. Moreover, distinct from graph attention network [28] which only takes node representations as inputs, we model the relation e r e_r er between e h e_h eh and e t e_t et, encoding more information during propagation. We perform experiments to verify the effectiveness of the attention mechanism and visualize the attention flow in Section 4.4.3 and Section 4.5, respectively. (我们的模型不仅利用了图的邻近结构,还指定了邻居的不同重要性。此外,与仅将节点表示作为输入的图注意网络[28]不同,我们对 e h e_h eh和 e h e_h eh之间的关系 e r e_r er进行了建模 , 在传播过程中编码更多信息。我们分别在第4.4.3节和第4.5节中进行实验,以验证注意机制的有效性,并可视化注意流。)
3.2.3 Information Aggregation:
-
(1) The final phase is to aggregate the entity representation e h e_h eh and its ego-network representations e N h e_{N_h} eNh as the new representation of entity h h h — more formally, e h ( 1 ) = f ( e h , e N h ) e^{(1)}_h = f (e_h, e_{N_h}) eh(1)=f(eh,eNh). We implement f ( ⋅ ) f(\cdot) f(⋅) using the following three types of aggregators:
-
(2)GCN Aggregator [17] sums two representations up and applies a nonlinear transformation, as follows: (GCN聚合器[17]将两种表示相加,并应用非线性变换,如下所示)

- where we set the activation function set as LeakyReLU [20];
- W ∈ R d ′ × d W \in R^{d'×d} W∈Rd′×d are the trainable weight matrices to distill useful information for propagation, (是可训练的权重矩阵,用于提取传播的有用信息,)
- and d ′ d' d′ is the transformation size.
-
(3) GraphSage Aggregator [9] concatenates two representations, followed by a nonlinear transformation: (GraphSage聚合器[9]连接两种表示,然后进行非线性变换)
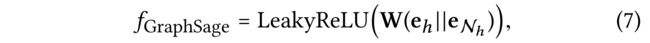
- where ∥ \parallel ∥ is the concatenation operation.
-
(4) Bi-Interaction Aggregator is carefully designed by us to consider two kinds of feature interactions between e h e_h eh and e N h e_{N_h} eNh, as follows:

- where W 1 , W 2 ∈ R d ′ × d W_1, W_2 \in R^{d' \times d} W1,W2∈Rd′×d are the trainable weight matrices,
- and ⊙ \odot ⊙ denotes the element-wise product.
- Distinct from GCN and GraphSage aggregators, we additionally encode the feature interaction between e h e_h eh and e N h e_{N_h} eNh. This term makes the information being propagated sensitive to the affinity between e h e_h eh and e N h e_{N_h} eNh, e.g., passing more messages from similar entities.
-
(5) To summarize, the advantage of the embedding propagation layer lies in explicitly exploiting the first-order connectivity information to relate user, item, and knowledge entity representations. We empirically compare the three aggregators in Section 4.4.2. (总之,嵌入传播层的优势在于显式地利用一阶连接性信息来关联用户、项目和知识实体表示。我们在第4.4.2节中对三个聚合器进行了经验比较。)
3.2.4 High-order Propagation:
- We can further stack more propagation layers to explore the high-order connectivity information, gathering the information propagated from the higher-hop neighbors. More formally, in the l l l-th steps, we recursively formulate the representation of an entity as: (我们可以进一步堆叠更多传播层来探索高阶连接性信息,收集从高跳邻居传播的信息。更正式地说,在第11步中,我们递归地将实体的表示形式表述为:)
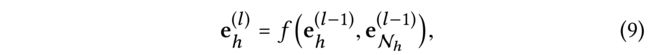
- wherein the information propagated within l l l-ego network for the entity h h h is defined as follows,
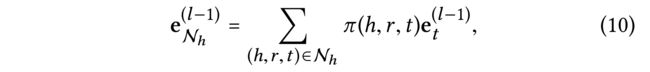
- e t ( l − 1 ) e^{(l−1)}_t et(l−1) is the representation of entity t t t generated from the previous information propagation steps, memorizing the information from its ( l − 1 ) (l − 1) (l−1)-hop neighbors;
- e h ( 0 ) e^{(0)}_h eh(0) is set as e h e_h eh at the initial information-propagation iteration. It further contributes to the representation of entity h h h at layer l l l.
- As a result, high-order connectivity like u 2 ⟶ r 1 i 2 ⟶ − r 2 e 1 ⟶ r 2 i 1 ⟶ − r 1 u 1 u_2 \stackrel{r_1}{\longrightarrow} i_2 \stackrel{-r_2}{\longrightarrow} e_1 \stackrel{r_2}{\longrightarrow} i_1 \stackrel{-r_1}{\longrightarrow} u_1 u2⟶r1i2⟶−r2e1⟶r2i1⟶−r1u1 can be captured in the embedding propagation process. Furthermore, the information from u 2 u_2 u2 is explicitly encoded in e u 1 ( 3 ) e^{(3)}_{u1} eu1(3). Clearly, the high-order embedding propagation seamlessly injects the attribute-based collaborative signal into the representation learning process. (显然,高阶嵌入传播将基于属性的协作信号无缝地注入到表示学习过程中。)
3.3 Model Prediction
- (1) After performing L L L layers, we obtain multiple representations for user node u u u, namely { e u ( 1 ) , ⋅ ⋅ ⋅ , e u ( L ) } \{e^{(1)}_u,· · ·,e^{(L)}_u\} {eu(1),⋅⋅⋅,eu(L)}; analogous to item node i i i, e i ( 1 ) , ⋅ ⋅ ⋅ , e i ( L ) {e^{(1)}_i,· · ·,e^{(L)}_i} ei(1),⋅⋅⋅,ei(L) are obtained. As the output of the l l l-th layer is the message aggregation of the tree structure depth of l l l rooted at u u u (or i i i) as shown in Figure 1, the outputs in different layers emphasize the connectivity information of different orders. We hence adopt the layer-aggregation mechanism [34] to concatenate the representations at each step into a single vector, as follows: (如图1所示,由于第 l l l层的输出是以 u u u(或 i i i)为根的l树结构深度的消息聚合,因此不同层的输出强调不同阶的连接信息。因此,我们采用层聚合机制[34]将每一步的表示连接成一个向量,如下所示)
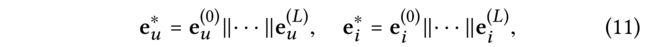
- where ∥ is the concatenation operation. By doing so, we not only enrich the initial embeddings by performing the embedding
propagation operations, but also allow controlling the strength of propagation by adjusting L L L. (通过这样做,我们不仅可以通过执行嵌入传播操作来丰富初始嵌入,还可以通过调整 L L L来控制传播的强度。)
- where ∥ is the concatenation operation. By doing so, we not only enrich the initial embeddings by performing the embedding
- (2) Finally, we conduct inner product of user and item representations, so as to predict their matching score:
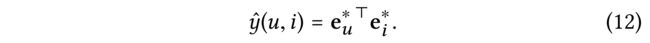
3.4 Optimization
-
(1) To optimize the recommendation model, we opt for the BPR loss [22]. Specifically, it assumes that the observed interactions, which indicate more user preferences, should be assigned higher prediction values than unobserved ones:

- where O = { ( u , i , j ) ∣ ( u , i ) ∈ R + , ( u , j ) ∈ R − } \mathcal{O} = \{(u, i, j) | (u, i) \in \mathcal{R}^+, (u,j) \in R^−\} O={(u,i,j)∣(u,i)∈R+,(u,j)∈R−} denotes the training set,
- R + \mathcal{R}^+ R+ indicates the observed (positive) interactions between user u u u and item j j j
- while R − \mathcal{R}^- R− is the sampled unobserved (negative) interaction set;
- σ ( ⋅ ) \sigma(\cdot) σ(⋅) is the sigmoid function.
-
(2) Finally, we have the objective function to learn Equations (2) and (13) jointly, as follows:

- where Θ = { E , W r , ∀ l ∈ R , W 1 ( l ) , W 2 ( l ) , ∀ l ∈ { 1 , ⋅ ⋅ ⋅ , L } } \Theta = \{E,W_r, \forall l \in \mathcal{R},W^{(l)}_1, W^{(l)}_2, \forall l \in \{1,· · ·,L\}\} Θ={E,Wr,∀l∈R,W1(l),W2(l),∀l∈{1,⋅⋅⋅,L}} is the model parameter set,
- and E E E is the embedding table for all entities and relations;
- L2 regularization parameterized by λ \lambda λ on Θ \Theta Θ is conducted to prevent overfitting.
- It is worth pointing out that in terms of model size, the majority of model parameters comes from the entity embeddings (e.g., 6.5 million on experimented Amazon dataset), which is almost identical to that of FM; the propagation layer weights are lightweight (e.g., 5.4 thousand for the tower structure of three layers, i.e., 64 − 32 − 16 − 8, on the Amazon dataset).
3.4.1 Training:
- We optimize L K G L_{KG} LKG and L C F L_{CF} LCF alternatively, where mini-batch Adam [16] is adopted to optimize the embedding loss and the prediction loss.
- Adam is a widely used optimizer, which is able to adaptively control the learning rate w.r.t. the absolute value of gradient.
- In particular, for a batch of randomly sampled ( h , r , t , t ′ ) (h,r,t,t′) (h,r,t,t′), we update the embeddings for all nodes; hereafter, we sample a batch of ( u , i , j ) (u,i,j) (u,i,j) randomly, retrieve their representations after L L L steps of propagation, and then update model parameters by using the gradients of the prediction loss. (在传播的所有步骤后检索它们的表示,然后使用预测损失的梯度更新模型参数)
3.4.2 Time Complexity Analysis:
- (1) As we adopt the alternative optimization strategy, the time cost mainly comes from two parts.
- For the knowledge graph embedding (cf. Equation (2)), the translation principle has computational complexity O ( ∣ G 2 ∣ d 2 ) O(|\mathcal{G}_2|d^2) O(∣G2∣d2).
- For the attention embedding propagation part, the matrix multiplication of the l l l-th layer has computational complexity O ( ∣ G ∣ d l d l − 1 ) O(|\mathcal{G}|d_l d_{l−1}) O(∣G∣dldl−1); and d l d_l dl and d l − 1 d_{l−1} dl−1 are the current and previous transformation size.
- For the final prediction layer, only the inner product is conducted, for which the time cost of the whole training epoch is O ( P L l = 1 ∣ G ∣ d l ) O(PL l=1|G|dl) O(PLl=1∣G∣dl). Finally, the overall training complexity of KGAT is O ( ∣ G 2 ∣ d 2 + P L l = 1 ∣ G ∣ d l d l − 1 + ∣ G ∣ d l ) O(|G2|d2+ PL l=1|G|dldl−1+ |G|dl) O(∣G2∣d2+PLl=1∣G∣dldl−1+∣G∣dl).
- (2) As online services usually require real-time recommendation, the computational cost during inference is more important that
that of training phase.- Empirically, FM, NFM, CFKG, CKE, GCMC, KGAT, MCRec, and RippleNet cost around 700s, 780s, 800s, 420s, 500s, 560s, 20 hours, and 2 hours for all testing instances on Amazon-Book dataset, respectively. As we can see, KGAT achieves comparable computation complexity to SL models (FM and NFM) and regularization-based methods (CFKG and CKE), being much efficient that path-based methods (MCRec and RippleNet).
4 EXPERIMENTS
We evaluate our proposed method, especially the embedding propagation layer, on three real-world datasets. We aim to answer the following research questions:
- RQ1: How does KGAT perform compared with state-of-the-art knowledge-aware recommendation methods?
- RQ2: How do different components (i.e., knowledge graph embedding, attention mechanism, and aggregator selection) affect KGAT?
- RQ3: Can KGAT provide reasonable explanations about user preferences towards items?
4.1 Dataset Description
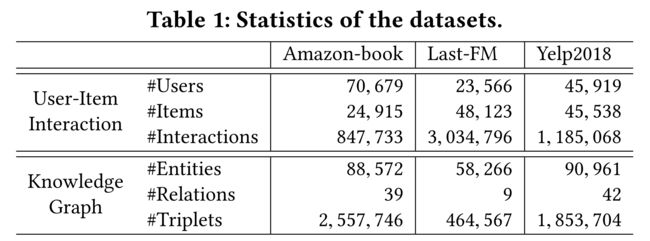
- (1) To evaluate the effectiveness of KGAT, we utilize three benchmark datasets: Amazon-book, Last-FM, and Yelp2018, which are publicly accessible and vary in terms of domain, size, and sparsity
Amazon-book:
Amazon-review is a widely used dataset for product recommendation [10]. We select Amazon-book from this collection. To ensure the quality of the dataset, we use the 10-core setting, i.e., retaining users and items with at least ten interactions. (Amazon review是一个广泛使用的产品推荐数据集[10]。我们从这个系列中选择亚马逊图书。为了确保数据集的质量,我们使用了10个核心设置,即保留至少10个交互的用户和项目。)
Last-FM:
This is the music listening dataset collected from Last.fm online music systems. Wherein, the tracks are viewed as the items. In particular, we take the subset of the dataset where the timestamp is from Jan, 2015 to June, 2015. We use the same 10-core setting in
order to ensure data quality. (这是从去年收集的音乐收听数据集。调频在线音乐系统。其中,轨迹被视为项目。特别是,我们选取时间戳为2015年1月至2015年6月的数据集子集。我们使用相同的10核设置,以确保数据质量。)
Yelp2018
This dataset is adopted from the 2018 edition of the Yelp challenge. Here we view the local businesses like restaurants and bars as the items. Similarly, we use the 10-core setting to ensure that each user and item have at least ten interactions. (该数据集取自2018年版的Yelp挑战赛。在这里,我们将餐馆和酒吧等当地企业视为商品。类似地,我们使用10个核心设置来确保每个用户和项目至少有10个交互。)
- (2) Besides the user-item interactions, we need to construct item knowledge for each dataset.
- For Amazon-book and Last-FM, we map items into Freebase entities via title matching if there is a mapping available. In particular, we consider the triplets that are directly related to the entities aligned with items, no matter which role (i.e., subject or object) it serves as.
- Distinct from existing knowledge-aware datasets that provide only one-hop entities of items, we also take the triplets that involve two-hop neighbor entities of items into consideration.
- For Yelp2018, we extract item knowledge from the local business information network (e.g., category, location, and attribute) as KG data. To ensure the KG quality, we then preprocess the three KG parts by filtering out infrequent entities (i.e., lowever than 10 in both datasets) and retaining the relations appearing in at least 50 triplets.
- We summarize the statistics of three datasets in Table 1 and publish our datasets at https://github. com/xiangwang1223/knowledge_graph_attention_network.
- (除了用户项交互之外,我们还需要为每个数据集构建项知识。对于Amazon book和Last FM,如果有可用的映射,我们会通过标题匹配将项目映射到Freebase实体。特别地,我们考虑与对象对齐的实体直接相关的三元组,而不管它充当哪个角色(即主题或对象)。与现有的只提供一跳实体的知识感知数据集不同,我们还考虑了包含两跳相邻实体的三元组。对于Yelp2018,我们从本地业务信息网络(例如,类别、位置和属性)中提取项目知识作为KG数据。为了确保KG质量,我们通过过滤掉不常见的实体(即,两个数据集中的实体数均低于10个)并保留至少50个三元组中出现的关系,对三个KG部分进行预处理。我们总结了表1中三个数据集的统计数据,并在https://github.com/xiangwang1223/knowledge\u graph\u attention\u network。)
- For Amazon-book and Last-FM, we map items into Freebase entities via title matching if there is a mapping available. In particular, we consider the triplets that are directly related to the entities aligned with items, no matter which role (i.e., subject or object) it serves as.
- (3) For each dataset, we randomly select 80% of interaction history of each user to constitute the training set, and treat the remaining as the test set. From the training set, we randomly select 10% of interactions as validation set to tune hyper-parameters. For each observed user-item interaction, we treat it as a positive instance, and then conduct the negative sampling strategy to pair it with one negative item that the user did not consume before. (对于每个数据集,我们随机选择每个用户80%的交互历史来构成训练集,并将剩余的作为测试集。从训练集中,我们随机选择10%的交互作为验证集来调整超参数。对于每个观察到的用户项目交互,我们将其视为一个正实例,然后执行负采样策略,将其与用户以前没有消费过的一个负项目配对。)
4.2 Experimental Settings
4.2.1 Evaluation Metrics.
- For each user in the test set, we treat all the items that the user has not interacted with as the negative items. Then each method outputs the user’s preference scores over all the items, except the positive ones in the training set. To evaluate the effectiveness of top-K recommendation and preference ranking, we adopt two widely-used evaluation protocols [13, 35]: recall@K and ndcg@K. By default, we set K = 20 K= 20 K=20. We report the average metrics for all users in the test set.
4.2.2 Baselines.
- To demonstrate the effectiveness, we compare our proposed KGAT with SL (FM and NFM), regularization-based (CFKG and CKE), path-based (MCRec and RippleNet), and graph neural network-based (GC-MC) methods, as follows:
- FM[23]: This is a bechmark factorization model, where considers the second-order feature interactions between inputs. Here we
treat IDs of a user, an item, and its knowledge (i.e., entities connected to it) as input features. (这是一个bechmark分解模型,其中考虑了输入之间的二阶特征交互。在这里,我们将用户、项目及其知识(即连接到它的实体)的ID视为输入特征。) - NFM [11]: The method is a state-of-the-art factorization model, which subsumes FM under neural network. Specially, we employed one hidden layer on input features as suggested in [11]. (该方法是一种最先进的因式分解模型,将FM纳入神经网络。特别是,我们在[11]中建议的输入特征上使用了一个隐藏层。)
- CKE [38]: This is a representative regularization-based method, which exploits semantic embeddings derived from TransR [19] to enhance matrix factorization [22]. (这是一种典型的基于正则化的方法,它利用TransR[19]中的语义嵌入来增强矩阵分解[22]。)
- CFKG [1]: The model applies TransE [2] on the unified graph including users, items, entities, and relations, casting the recommendation task as the plausibility prediction of (u,Interact,i) triplets. (该模型在包括用户、项目、实体和关系的统一图上应用TransE[2],将推荐任务转化为(u,Interact,i)三元组的合理性预测。)
- MCRec[14]: This is a path-based model, which extracts qualified meta-paths as connectivity between a user and an item. (这是一个基于路径的模型,它提取合格的元路径作为用户和项目之间的连接。)
- RippleNet [29]: Such model combines regularization- and path-based methods, which enrich user representations by adding that of items within paths rooted at each user. (这种模型结合了正则化和基于路径的方法,通过在每个用户的根路径中添加项目来丰富用户表示。)
- GC-MC [26]: Such model is designed to employ GCN [17] encoder on graph-structured data, especially for the user-item bipartite graph. Here we apply it on the user-item knowledge graph. Especially, we employ one graph convolution layers as suggested in [26], where the hidden dimension is set equal to the embedding size. (该模型设计用于在图结构数据上使用GCN[17]编码器,尤其是对于用户项二部图。在这里,我们将其应用于用户项知识图。特别是,我们使用了[26]中建议的一个图卷积层,其中隐藏维度设置为嵌入大小。)
- FM[23]: This is a bechmark factorization model, where considers the second-order feature interactions between inputs. Here we
4.2.3 Parameter Settings.
- We implement our KGAT model in Tensorflow.
- The embedding size is fixed to 64 for all models, except RippleNet 16 due to its high computational cost.
- We optimize all models with Adam optimizer, where the batch size is fixed at 1024. The default Xavier initializer [8] to initialize the model parameters.
- We apply a grid search for hyper-parameters: the learning rate is tuned amongst {0.05,0.01,0.005,0.001}, the coefficient of L2 normalization is searched in {10−5,10−4,· · ·,101,102}, and the dropout ratio is tuned in {0.0,0.1,· · ·,0.8} for NFM, GC-MC, and KGAT.
- Besides, we employ the node dropout technique for GC-MC and KGAT, where the ratio is searched in {0.0,0.1,· · ·,0.8}.
- For MCRec, we manually define several types of user-item-attribute-item meta-paths, such as user-book-author-user and user-book-genre-user for Amazon-book dataset;
- we set the hidden layers as suggested in [14], which is a tower structure with 512, 256, 128, 64 dimensions.
- For RippleNet, we set the number of hops and the memory size as 2 and 8, respectively.
- Moreover, early stopping strategy is performed, i.e., premature stopping if recall@20 on the validation set does not increase for 50 successive epochs.
- To model the third-order connectivity, we set the depth of KGAT L L L as three with hidden dimension 64, 32, and 16, respectively;
- we also report the effect of layer depth in Section 4.4.1. For each layer, we conduct the Bi-Interaction aggregator.
4.3 Performance Comparison (RQ1)
- We first report the performance of all the methods, and then investigate how the modeling of high-order connectivity alleviate the sparsity issues.
4.3.1 Overall Comparison.
- The performance comparison results are presented in Table 2. We have the following observations:

- (1) KGAT consistently yields the best performance on all the datasets. In particular, KGAT improves over the strongest baselines w.r.t. recall@20 by 8.95%, 4.93%, and 7.18% in Amazon-book, Last-FM, and Yelp2018, respectively. By stacking multiple attentive embedding propagation layers, KGAT is capable of exploring the high-order connectivity in an explicit way, so as to capture collaborative signal effectively. This verifies the significance of capturing collaborative signal to transfer knowledge. Moreover, compared with GC-MC, KGAT justifies the effectiveness of the attention mechanism, specifying the attentive weights w.r.t. compositional semantic relations, rather than the fixed weights used in GC-MC. (KGAT在所有数据集上都能产生最佳性能。特别是,KGAT比w.r.t.的最强基线有所改善。recall@20在亚马逊图书、Last FM和Yelp2018中分别下降了8.95%、4.93%和7.18%。通过叠加多个专注的嵌入传播层,KGAT能够以明确的方式探索高阶连通性,从而有效捕获协作信号。这验证了捕获协作信号以转移知识的重要性。此外,与GC-MC相比,KGAT证明了注意机制的有效性,规定了注意权重w.r.t.成分语义关系,而不是GC-MC中使用的固定权重。)
- (2) SL methods (i.e., FM and NFM) achieve better performance than the CFKG and CKE in most cases, indicating that regularization-based methods might not make full use of item knowledge. In particular, to enrich the representation of an item, FM and NFM exploit the embeddings of its connected entities, while CFKG and CKE only use that of its aligned entities. Furthermore, the cross features in FM and NFM actually serve as the second-order connectivity between users and entities, whereas CFKG and CKE model connectivity on the granularity of triples, leaving high-order connectivity untouched. (SL方法(即FM和NFM)在大多数情况下比CFKG和CKE取得更好的性能,这表明基于正则化的方法可能无法充分利用项目知识。特别是,为了丰富项目的表示,FM和NFM利用其关联实体的嵌入,而CFKG和CKE仅使用其对齐实体的嵌入。此外,FM和NFM中的交叉功能实际上是用户和实体之间的二阶连接,而CFKG和CKE在三元组的粒度上建模连接,保持高阶连接不变。)
- (3) Compared to FM, the performance of RippleNet verifies that incorporating two-hop neighboring items is of importance to enrich user representations. It therefore points to the positive effect of modeling the high-order connectivity or neighbors. However, RippleNet slightly underperforms NFM in Amazon-book and Last-FM, while performing better in Yelp2018. One possible reason is that NFM has stronger expressiveness, since the hidden layer allows NFM to capture the nonlinear and complex feature interactions between user, item, and entity embeddings. (与FM相比,RippleNet的性能验证了合并两跳相邻项对于丰富用户表示的重要性。因此,它指出了对高阶连通性或邻居建模的积极影响。然而,RippleNet在Amazon book和Last FM中的表现略逊于NFM,而在Yelp2018中表现更好。一个可能的原因是NFM具有更强的表达能力,因为隐藏层允许NFM捕获用户、项目和实体嵌入之间的非线性和复杂的特征交互。)
- (4) RippleNet outperforms MCRec by a large margin in Amazon-book. One possible reason is that MCRec depends heavily on the quality of meta-paths, which require extensive domain knowledge to define. The observation is consist with [29]. (RippleNet在亚马逊图书中的表现大大超过了MCRec。一个可能的原因是MCRec严重依赖于元路径的质量,这需要大量的领域知识来定义。观察结果与[29]一致。)
- (5) GC-MC achieves comparable performance to RippleNet in Last-FM and Yelp2018 datasets. While introducing the high-order
connectivity into user and item representations, GC-MC forgoes the semantic relations between nodes; whereas RippleNet utilizes
relations to guide the exploration of user preferences. (GC-MC在上一个FM和Yelp2018数据集的性能与RippleNet相当。在用户和项目表示中引入高阶连通性的同时,GC-MC放弃了节点之间的语义关系;而RippleNet则利用关系来指导用户偏好的探索。)
4.3.2 Performance Comparison w.r.t. Interaction Sparsity Levels.
- (1) One motivation to exploiting KG is to alleviate the sparsity issue, which usually limits the expressiveness of recommender systems. It is hard to establish optimal representations for inactive users with few interactions. Here we investigate whether exploiting connectivity information helps alleviate this issue.
- (2) Towards this end, we perform experiments over user groups of different sparsity levels. In particular, we divide the test set into four groups based on interaction number per user, meanwhile try to keep different groups have the same total interactions. Taking Amazon-book dataset as an example, the interaction numbers per user are less than 7, 15, 48, and 4475 respectively. Figure 3 illustrates the results w.r.t. ndcg@20 on different user groups in Amazon-book, Last-FM, and Yelp2018. We can see that: (为此,我们对不同稀疏级别的用户组进行了实验。特别是,我们根据每个用户的交互次数将测试集划分为四个组,同时尝试保持不同组的总交互次数相同。以亚马逊图书数据集为例,每个用户的交互次数分别小于7、15、48和4475。图3显示了w.r.t.的结果。ndcg@20在Amazon book、Last FM和Yelp2018中的不同用户组上。我们可以看到:)
- KGAT outperforms the other models in most cases, especially on the two sparsest user groups in Amazon-Book and Yelp2018.
It again verifies the significance of high-order connectivity modeling, which (KGAT在大多数情况下都优于其他模型,尤其是在Amazon Book和Yelp2018中最稀疏的两个用户群上。它再次验证了高阶连接性建模的重要性)- (1) contains the lower-order connectivity used in baselines, (包含基线中使用的低阶连接性)and
- (2) enriches the representations of inactive users via recursive embedding propagation. (通过递归嵌入传播丰富非活动用户的表示。)
- It is worthwhile pointing out that KGAT slightly outperforms some baselines in the densest user group (e.g., the < 2057 group of Yelp2018). One possible reason is that the preferences of users with too many interactions are too general to capture. High-order connectivity could introduce more noise into the user preferences, thus leading to the negative effect. (值得指出的是,KGAT在最密集的用户组(例如,Yelp2018的<2057组)中略优于一些基线。一个可能的原因是,交互次数过多的用户的偏好过于笼统,难以捕捉。高阶连接性可能会在用户偏好中引入更多噪声,从而导致负面影响。)
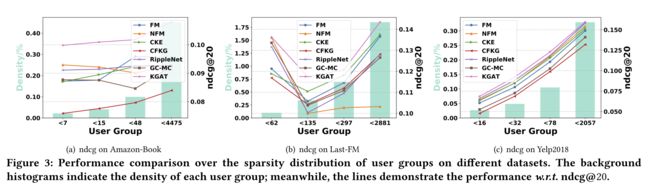
- KGAT outperforms the other models in most cases, especially on the two sparsest user groups in Amazon-Book and Yelp2018.
4.4 Study of KGAT (RQ2)
To get deep insights on the attentive embedding propagation layer of KGAT, we investigate its impact. We first study the influence of layer numbers. In what follows, we explore how different aggregators affect the performance. We then examine the influence of knowledge graph embedding and attention mechanism. (为了深入了解KGAT的专注嵌入传播层,我们研究了它的影响。我们首先研究层数的影响。接下来,我们将探讨不同的聚合器如何影响性能。然后,我们研究了知识图嵌入和注意机制的影响。)
4.4.1 Effect of Model Depth.
- We vary the depth of KGAT (e.g., L) to investigate the efficiency of usage of multiple embedding propagation layers. In particular, the layer number is searched in the range of {1,2,3,4}; we use KGAT-1 to indicate the model with one layer, and similar notations for others. We summarize the results in Table 3, and have the following observations: (我们改变KGAT的深度(例如,L),以研究使用多个嵌入传播层的效率。具体地,在{1,2,3,4}范围内搜索层号;我们使用KGAT-1来表示一层模型,其他层用类似的符号表示。我们总结了表3中的结果,并得出以下观察结果:)
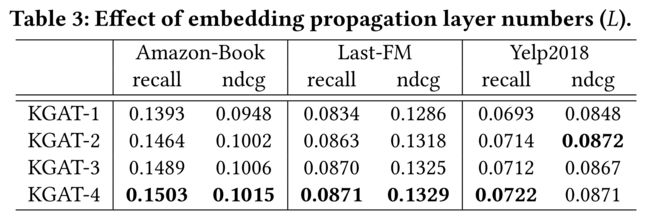
- (1) Increasing the depth of KGAT is capable of boosting the performance substantially. Clearly, KGAT-2 and KGAT-3 achieve
consistent improvement over KGAT-1 across all the board. We attribute the improvements to the effective modeling of high-order relation between users, items, and entities, which is carried by the second- and third-order connectivities, respectively. (增加KGAT的深度能够显著提高性能。显然,KGAT-2和KGAT-3在所有方面都比KGAT-1取得了一致的改进。我们将这些改进归因于对用户、项目和实体之间的高阶关系的有效建模,这分别由二阶和三阶连接性进行。) - (2) Further stacking one more layer over KGAT-3, we observe that KGAT-4 only achieve marginal improvements. It suggests
that considering third-order relations among entities could be sufficient to capture the collaborative signal, which is consistent to the findings in [14, 33]. (在KGAT-3上再叠加一层,我们观察到KGAT-4只能获得微小的改善。这表明,考虑实体之间的三阶关系可能足以捕捉协作信号,这与[14,33]中的研究结果一致。) - Jointly analyzing Tables 2 and 3, KGAT-1 consistently outperforms other baselines in most cases. It again verifies the effectiveness of that attentive embedding propagation, empirically showing that it models the first-order relation better. (综合分析表2和表3,在大多数情况下,KGAT-1始终优于其他基线。它再次验证了这种专注的嵌入传播的有效性,从经验上表明它能更好地模拟一阶关系。)
- (1) Increasing the depth of KGAT is capable of boosting the performance substantially. Clearly, KGAT-2 and KGAT-3 achieve
4.4.2 Effect of Aggregators.
- To explore the impact of aggregators, we consider the variants of KGAT-1 that uses different settings — more specifically GCN, GraphSage, and Bi-Interaction (cf. Section 3.1), termed KGAT-1GCN, KGAT-1GraphSage, and KGAT-1Bi, respectively. Table 4 summarizes the experimental results. We have the following findings: (为了探索聚合器的影响,我们考虑使用不同设置的KGAT-1的变体——更具体地,GCN、GraceSaGE和Bi相互作用(参见第3.1节),分别命名为KGAT-1GCN、KGAT-1GraseAGE和KGAT-1BI。表4总结了实验结果。我们有以下发现:)
- KGAT-1GCNis consistently superior to KGAT-1GraphSage. One possible reason is that GraphSage forgoes the interaction between the entity representation e h e_h eh and its ego-network representation e N h e_{N_h} eNh. It hence illustrates the importance of feature interaction when performing information aggregation and propagation. (KGAT-1GcNs始终优于KGAT-1GcNs。一个可能的原因是GraphSage放弃了实体表示 e h e_h eh 与自我网络表示 e N h e_{N_h} eNh之间的交互. 因此,它说明了在执行信息聚合和传播时特征交互的重要性。)
- Compared to KGAT-1GCN, the performance of KGAT-1Biverifies that incorporating additional feature interaction can improve the representation learning. It again illustrates the rationality and effectiveness of Bi-Interaction aggregator. (与KGAT-1GCN相比,KGAT-1的性能表明,加入额外的特征交互可以改善表征学习。再次说明了Bi交互聚合器的合理性和有效性。)
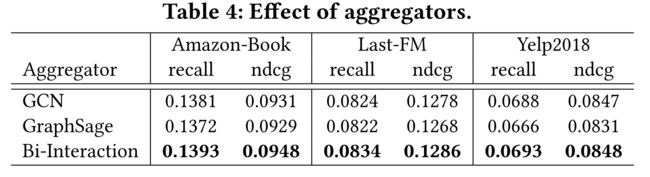
4.4.3 Effect of Knowledge Graph Embedding and Attention Mechanism.
- To verify the impact of knowledge graph embedding and attention mechanism, we do ablation study by considering three variants of KGAT-1. In particular, we disable the TransR embedding component (cf. Equation (2)) of KGAT, termed KGAT-1w/o KGE; we disable the attention mechanism (cf. Equation (4)) and set π ( h , r , t ) \pi (h,r,t) π(h,r,t) as 1 / ∣ N h ∣ 1/|N_h| 1/∣Nh∣, termed KGAT- 1 w / o A t t 1_{w/o Att} 1w/oAtt. Moreover, we obtain another variant by removing both components, named KGAT- 1 w / o K & A 1_{w/o K\&A} 1w/oK&A. We summarize the experimental results in Table 5 and have the following findings:

- Removing knowledge graph embedding and attention components degrades the model’s performance. KGAT- 1 w / o K & A 1_{w/o K\&A} 1w/oK&A consistently underperforms KGAT- 1 w / o K G E 1_{w/o KGE} 1w/oKGE and KGAT- 1 w / o A t t 1_{w/o Att} 1w/oAtt. It makes sense since KGATw/o K&A fails to explicitly model the representation relatedness on the granularity of triplets.
- Compared with KGAT- 1 w / o A t t 1_{w/o Att} 1w/oAtt, KGAT- 1 w / o K G E 1_{w/o KGE} 1w/oKGE performs better in most cases. One possible reason is that treating all neighbors equally (i.e., KGAT- 1 w / o A t t 1_{w/o Att} 1w/oAtt) might introduce noises and mislead the embedding propagation process. It verifies the substantial influence of graph attention mechanism.
4.5 Case Study (RQ3)
- Benefiting from the attention mechanism, we can reason on high-order connectivity to infer the user preferences on the target item,
offering explanations. Towards this end, we randomly selected one user u u u 208 from Amazon-Book, and one relevant item i i i 4293 (from the test, unseen in the training phase). We extract behavior-based and attribute-based high-order connectivity connecting the user-item pair, based on the attention scores. Figure 4 shows the visualization of high-order connectivity. There are two key observations: (得益于注意机制,我们可以基于高阶连接性推理来推断用户对目标项目的偏好,并提供解释。为此,我们从Amazon Book中随机选择了一个用户 u u u 208,以及一个相关的条目 i i i 4293(来自测试,在培训阶段没有看到)。我们根据注意力得分提取连接用户项对的基于行为和基于属性的高阶连通性。图4显示了高阶连接性的可视化。有两个关键观察结果:)
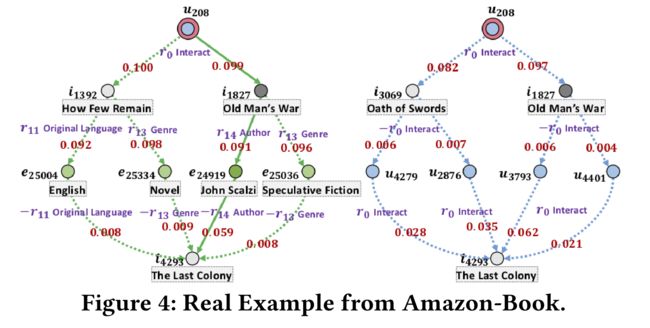
- (1) KGAT captures the behavior-based and attribute-based high-order connectivity, which play a key role to infer user preferences.
- The retrieved paths can be viewed as the evidence why the item meets the user’s preference.
- As we can see, the connectivity u 208 ⟶ r 0 O l d M a n ’ s W a r ⟶ r 14 J o h n S c a l z i ⟶ − r 14 i 4293 u208 \stackrel{r0}{\longrightarrow} Old Man’s War \stackrel{r_{14}}{\longrightarrow} John Scalzi \stackrel{-r_{14}}{\longrightarrow} i_{4293} u208⟶r0OldMan’sWar⟶r14JohnScalzi⟶−r14i4293 has the highest attention score, labeled with the solid line in the left subfigure. Hence, we can generate the explanation as The Last Colony is recommended since you have watched Old Man’s War written by the same author John Scalzi.
- (2) The quality of item knowledge is of crucial importance. As we can see, entity English with relation O r i g i n a l L a n g u a g e Original Language OriginalLanguage is involved in one path, which is too general to provide high-quality explanations. This inspires us to perform hard attention to filter less informative entities out in future work. (项目知识的质量至关重要。正如我们所见,实体英语与关系原语originallanguage涉及一条路径,这条路径过于笼统,无法提供高质量的解释。这激励我们在未来的工作中努力过滤信息量较小的实体。)
- (1) KGAT captures the behavior-based and attribute-based high-order connectivity, which play a key role to infer user preferences.
5 CONCLUSION AND FUTURE WORK
- (1) In this work, we explore high-order connectivity with semantic relations in CKG for knowledge-aware recommendation. (在这项工作中,我们探索了CKG中语义关系的高阶连通性,以实现知识感知推荐。)
- (2) We devised a new framework KGAT, which explicitly models the high-order connectivities in CKG in an end-to-end fashion. ( (我们设计了一个新的框架KGAT,它以端到端的方式显式地对CKG中的高阶连接性进行建模。))
- At it core is the attentive embedding propagation layer, which adaptively propagates the embeddings from a node’s neighbors to update the node’s epresentation. (其核心是注意力嵌入传播层,该层自适应地传播来自节点邻居的嵌入,以更新节点的epresentation。)
- Extensive experiments on three real-world datasets demonstrate the rationality and effectiveness of KGAT.
- (3) This work explores the potential of graph neural networks in recommendation, and represents an initial attempt to exploit structural knowledge with information propagation mechanism. (这项工作探索了图形神经网络在推荐中的潜力,并代表了利用信息传播机制开发结构知识的初步尝试。)
- Besides knowledge graph, many other structural information indeed exists in real-world scenarios, such as social networks and item contexts. For example, by integrating social network with CKG, we can investigate how social influence affects the recommendation. Another exciting direction is the integration of information propagation and decision process, which opens up research possibilities of explainable recommendation. (除了知识图之外,许多其他结构信息确实存在于现实世界场景中,例如社交网络和项目上下文。例如,通过将社交网络与CKG相结合,我们可以调查社会影响如何影响推荐。另一个令人兴奋的方向是信息传播和决策过程的集成,这为解释性推荐的研究开辟了可能性。)
Acknowledgement:
This research is part of NExT++ research and also supported by the Thousand Youth Talents Program 2018. NExT++ is supported by the National Research Foundation, Prime Minister’s Office, Singapore under its IRC@SG Funding Initiative.