Python进阶(课程学习笔记)
1. import底层原理
假设先创建一个文件demonA.py,内容如下:
# encoding: utf-8
print("Test demon A")
def add(a, b):
"""
:param a:
:param b:
:return:
"""
return a + b
print("End test Demon B")
假设要在demonB.py文件中导入对应的demonA模块:
# encoding: utf-8
import demonA
在执行demonB.py文件的时候,结果如下:
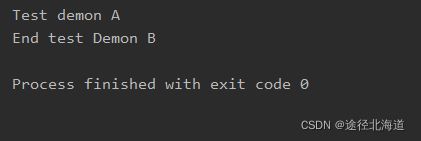
在import demonA模块的时候,python会做三件事情:
1. 执行demonA中的代码
2. 将demonA这个模块添加到sys.modules这个字典中(首先判断sys.modules中有没有demonA这 个模块,如果有,则不会去执行和导入,如果没有,则会执行导入模块)
3. 在当前文件中(demonB)中创建一个变量demonA,来指向demonA这个模块
4. from demonA import add() 所执行的流程与上述的流程类似。
2. 循环引用
A文件引用B文件,B文件引用A文件。
例子1:
A文件内容:
# encoding: utf-8
import demonB
print("Test demon A")
B文件内容:
# encoding: utf-8
import demonA
print("Test demon B")运行B文件,运行结果:

运行结果分析:
1. 运行B文件的时候,首先执行import A, 此时会判断A是否在字典sys.modules中,此时A还不在sys.modules中,所以会执行A中的代码。
2. 执行A中的代码,首先又会执行A中import B,此时B还不字典sys.modules中,因此会去执行B中的代码。
3. 此时又回到步骤1,执行B中的代码,但此时A已经在字典sys.modules中,因此不会再执行import A,而实直接打印Test DemonB
4. A文件中的import B执行完毕后,会继续执行print函数。
5.最后再回到B文件中,执行B文件中的print代码
含有自定义函数的文件的循环导入问题:
A文件内容:
# encoding: utf-8
# import demonB
# 换一种导入方法
from demonB import method_b
def method_a():
print("method in file A")
print("Test demon A")
B文件内容:
# encoding: utf-8
# import demonA
# 换一种导入方法
from demonA import method_a
def method_b():
print("method in file B")
print("Test demon B")此时运行B文件,会出下如下的错误:
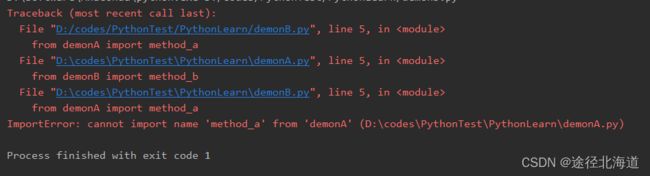
运行结果分析:
1. 执行B文件中的代码,首先执行from demonA import method_a,由于此时demonA不再sys.modules,因此回去先执行A文件中的代码。
2. 执行A文件中的代码,首先执行from demonB import method_b,此时demonB不再sys.modules中,因此回去执行B文件中的代码,此时执行from demonA import method_a,这个时候demonA已经在sys.modules中,但是此时A文件中还未执行到方法method_a()定义的位置,因此import method_a便会报错。
解决循环引用:
循环引用出现的原因: 代码设计不合理!将相互引用的内容按照下图进行调整:
/*
+---------------------+ +--------------------+
| | | |
| | | |
| --+--------> | |
| | | |
| method_a | | method_b |
| | | |
| <-+----------+- |
| | | |
+---------------------+ +--------------------+
A B
-------------------------------------------------------------------------------
+---------------------+
| |
| method_a |
| |
+---------> | method_b | <------+
| | | |
| | | |
| | | |
| +---------------------+ |
| |
| |
+--+------------------+ +-------------+------+
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
+---------------------+ +--------------------+
A B
*/3. 魔术变量
__name__变量,不需要的导入任何模块,它在任何一个python文件中都是存在的。可以通过print发放对其进行打印,查看其值:
print(__name__)输出值为:__main__
1. 如果一个python文件是作为被导入文件或者模块来运行的,那么就不是作为主运行文件来执行的。
2. 如果直接通过python文件来运行的,那么就是作为主运行文件来执行的。
例如:
A文件的内容:
# encoding: utf-8
from demonB import method_b
def method_a():
print("method in file A")
print("demonA: ", __name__)
B文件的内容:
# encoding: utf-8
print("demonB: ", __name__)
def method_b():
print("method in file B")
在A文件中导入了B文件,因此B是被导入执行,而A不是导入执行,因此AB文件的__main__变量值如下所示:
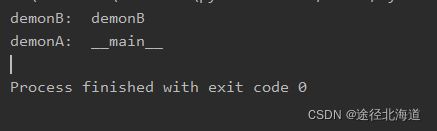
因此,不同的文件,变量__main__的值可能是不同的。
若需要一个文件需要作为主运行文件运行,则可以做 if __name__ = "__main__"判断。
4. PIP简要介绍
如果在本地环境下开发完成,需要将项目部署到服务器。此时需要将当前本地开发环境下安装的包在服务器端安装一遍,可以采用如下命令,将当前环境下安装的包全部列出来放在指定文件中。
pip freeze > requirements.txt将requirements问价放到服务器端,然后通过如下的命令,可以使python按照文件中的包的版本自动安装所有的包:
pip install -r requirements.txt有的包的网站服务器在国外,导致安装的速度过慢,甚至导致超时报错,此时可以更换安装源,将安装源更换为国内镜像,此时的安装速度就会很快,例如,可指定豆瓣的安装源,此外还有好多其他的国内安装镜像源,可自行百度。
pip install packageName -i https://pypi/douban.com/simple永久修改安装源:、
windows操作系统下,在当前用户的目录下新建pip/pip.ini,然后在文件中添加如下的代码:
[global]
timeout = 6000
index-url = https://pypi.douban.com/simpleLinux操作系统下,在用户目录下,新建.pip/pip.conf,然后在文件中添加:
[global]
timeout = 5000
index-url = https://pypi.douban.com/simple5. 列表生成式(列表推导式)
x = [x for x in range(100)]
print(x)x = [1 for _ in range(100)]
print(x)values = [x for x in range(100) if x % 2 == 0]
print(values)
6.Python虚拟环境
在使用pip安装的第三方包,会安装到系统级的python环境中,但是有时,需要维护的项目所需的第三方包,与现有的安装版本不同,或者是同时需要维护多个不同版本的项目,需要同时安装多个不同版本的第三方包,此时就可以通过python虚拟环境来解决这个问题。
python中的一个虚拟环境相当于一个抽屉,安装在这个抽屉中的软件包,不会影响其他抽屉中的软件包。并且在项目中,可以指定项目的虚拟环境来配合项目,针对不同的项目可以创建不同的虚拟环境。
virtualevnwrapper是一个用于简化管理python虚拟环境的包:(相比于直接使用virtualenv的优点)
1. 可以预先设置python虚拟环境的创建路径,设置好路径之后,每次创建的虚拟环境都会放在已经指定号的路径下。
2.每次需要激活或者关闭虚拟环境的时候,无需再次切换到虚拟环境所在的路径下。
3. 无需通过切换到特定目录下去查看安装了哪些虚拟环境,可通过命令行直接进行查看。
安装:
windows下:pip install virtualenvwrapper-win
Linux下:pip install virtualenvwrapper
创建虚拟环境:mkvirtualenv envname
激活/切换到某个虚拟环境:workon envname
退出虚拟环境:deactivate
删除虚拟环境:rmvirtualenv envname
列出所有虚拟环境:lsvirtualenv
进入到虚拟环境所在的目录:cdvirtualenv
安装好virtualevnwrapper之后,如果需要指定虚拟环境的创建位置,需要设置一下环境变量,设置方式如下所示(推荐操作):
windows下在 高级系统设置 > 环境变量 > 系统变量 中 添加一个参数WORKON_HOME,将这个 参数的值设置为需要的路径即可。
此外,还可以在创建虚拟环境的时候指定python的版本:
mkvirtualenv --python==c:\python36\python.exe envname7. Python迭代器和for循环底层原理
什么是迭代器:
迭代器可以使我们在访问集合的时候变得非常方便,python中的for ... in ...的访问集合的方式,就是通过迭代器进行的。如果没有迭代器,只能通过在循环中利用下标及逆行访问。如果某个类实现了__next__方法和__iter__方法,并且这个方法返回了值的对象,称为迭代器对象,如果迭代器没有返回值了,那应该在next方法中抛出一个StopIteration异常。(根本没有描述清楚!)
可迭代对象:可以直接使用python的for循环遍历的对象称为可迭代对象。常见的List,tuple, set等。
判断一个对象是否可迭代的依据是,这个对象是否实现了__iter__方法,且这个方法需要返回一个迭代器对象。
采用如下方法判断一个对象是否为可迭代对象:
from collections import Iterable
a = [1, 2, 3, 4]
ret = isinstance(a, Iterable)
print(ret)如下所示,可自定义一个可迭代对象:
# 自定义一个迭代器,迭代器中需要实现两个方法
class MyRangeIterator:
def __init__(self, start, end):
"""
构造函数
:param start: 起始位置
:param end: 迭代位置
"""
self.start = start
self.end = end
def __iter__(self):
"""
iter方法返回自己
:return:
"""
return self
def __next__(self):
"""
在每一次进行for循环遍历的时候,就会去调用这个方法
:return:
"""
if self.start < self.end:
temp = self.start
self.start += 1
return temp
else:
"""
如果已经超过限制,此时应该抛出StopIteration异常,此时for循环捕获到这个异常,会停止循环
"""
raise StopIteration()
# 定义一个可迭代的对象
class MyRange:
def __init__(self, start, end):
"""
构造函数
:param start: 起始
:param end: 结束
"""
self.start = start
self.end = end
def __iter__(self):
"""
实现iter方法,在此方法中需要返回一个迭代器对象
:return:
"""
return MyRangeIterator(self.start, self.end)
r = MyRange(1, 10)
for x in r:
print(x)
输出结果: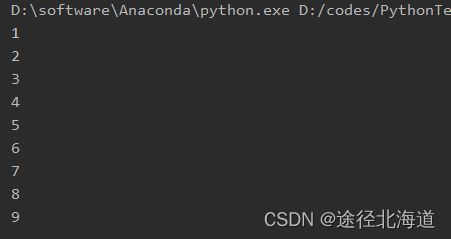
for循环的运行原理:for循环首先会通过可迭代对象中的__iter__方法获取可迭代对象的迭代器,然后会调用迭代器的__next__方法,每循环一次,都会去调用这个__next__方法返回相应的值。
获取迭代器以及遍历其中的内容:
对于一个可迭代对象,可以通过iter()方法获取其迭代器:
r = MyRange(1, 10)
my_iterator = iter(r) # 获取可迭代对象的迭代器
# 遍历迭代器中的内容
while True:
try:
x = my_iterator.__next__()
print(x)
except StopIteration:
"""
这里需要自行捕0获迭代器抛出的StopIteration异常,结束循环
在for ...in ...循环的底层,python已经提前封装好了这些东西,因此不用
再手动去捕获
"""
break
输出结果:
另一种写法
还可以将上述的可迭代对象以及迭代器合并,写到一个类中:
# 定义一个可迭代的对象
class MyRange:
"""
可迭代对象需要实现__iter__()方法,迭代器需要实现__iter__()以及__next__()
此设在同一个类中实现这两个方法,这个类相当于一个可迭代对象和迭代器
"""
def __init__(self, start, end):
"""
构造函数
:param start: 起始
:param end: 结束
"""
self.start = start
self.end = end
self.index = start
def __iter__(self):
"""
实现iter方法,在此方法中需要返回一个迭代器对象
:return:
"""
# return MyRangeIterator(self.start, self.end)、
return self # 此时返回self即可,因此此时这个类本身实现了__next__(),相当于迭代器了
def __next__(self):
"""
在每一次进行for循环遍历的时候,就会去调用这个方法
:return:
"""
if self.index < self.end:
temp = self.index
self.index += 1
return temp
else:
"""
如果已经超过限制,此时应该抛出StopIteration异常,此时for循环捕获到这个异常,会停止循环
"""
raise StopIteration()
r = MyRange(1, 10)
for x in r:
print(x)
print("="*25)
for y in r:
print(y)但是出现的新问题是,此时如果遍历两次,第二次会遍历不到任何值(第一种写法则不存在这种问题):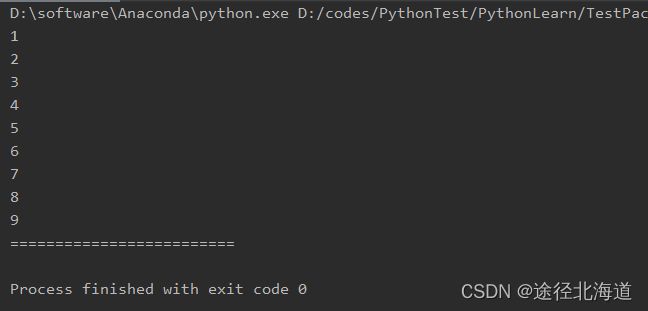
分析可知,使用for循环每次遍历可迭代对象的时候,第一种写法总是会返回一个重新初始化的迭代器,所以可以返回正常的值。对于第二种写法,当使用for循环第二次遍历的时候,此时self.index已经达到最大值,此时再调用__next__(),只会抛出异常,导致循环立即终止。
此时需要做如下修改:
def __next__(self):
"""
在每一次进行for循环遍历的时候,就会去调用这个方法
:return:
"""
if self.index < self.end:
temp = self.index
self.index += 1
return temp
else:
"""
如果已经超过限制,此时应该抛出StopIteration异常,此时for循环捕获到这个异常,会停止循环
"""
self.index = self.start # 将self.index置为初始值
raise StopIteration()8. 生成器
什么场景下需要生成器:例如需要打印1~1亿的整型数字,直接调用range()函数,大概率会导致程序崩溃,因为range()函数会直接产生一个1-1亿的列表,且将列表中的所有数据存放到内存中,导致内存爆满。此时就需要使用生成器来解决这个问题,生成器的工作原理是,不会一次把所有数据都加载到内存中,而是在循环的时候临时生成数据,循环一次生成一个,所以在程序运行期间永远只会生成一个数据,极大的节省了内存。
1. 用rangge配合圆括号可产生一个生成器
numbers = (x for x in range(1, 10000000))
print(type(numbers)) # 输出
for xx in numbers:
print(xx) 2. 自定义一个生成器:
生成器可以通过函数产生,如果在一个函数中出现了yield关键字,那么这个函数将不再是一个普通的函数,而是一个生成器函数。yield一次会返回一个结果,并且会冻结当前函数的状态,如下例子所示:
def my_gen():
"""
定义生成器函数,每次通过next获取生成器中的值的时候,
会执行一条yield语句,且函数的状态能够保持,例如函数
中的临时变量的值会保存下来
:return: 返回的不是yield后面的值,而是一个生成器
"""
yield 1
yield 2
yield 3
# 获取生成器中的值
ret = my_gen() # 此时不执行函数my_gen()中的代码,而是返回一个生成器,调用next的时候才会去执行 ,也就是说,next会触发下一条yield语句
print(next(ret)) # 1
print(next(ret)) # 2
print(next(ret)) # 2
print(next(ret)) # 抛出异常 StopIteration生成器的基本原理如上,而且可以用for循环遍历生成器,因此生成器也是一个可迭代对象,也是一个迭代器,因此他只能被遍历一次(第二次遍历不到任何值,如前面可迭代对象的例子所示)。
例如自定义一个1~1亿的生成器:
def gen(start, end):
"""
自定义一个生成器
:param start: 起始位置
:param end: 结束位置
:return:
"""
index = start
while index < end:
yield index
index += 1 # index的状态会被保存下来,在重复调用next的时候会触发yield语句,产生对应的值
ret = gen(1, 100000)
for x in ret:
print(x)注: 在调用生成器函数的时候,确实不会执行函数中的任何语句,只有调用next触发yield语句的时候,才会第一次执行响应的语句,之后每次再去根据next触发去执行yield语句。
def gen(start, end):
"""
自定义一个生成器
:param start: 起始位置
:param end: 结束位置
:return:
"""
print("Hello")
index = start
while index < end:
yield index
index += 1 # index的状态会被保存下来,在重复调用next的时候会触发yield语句,产生对应的值
ret = gen(1, 10)
for x in ret:
print(x)输出结果: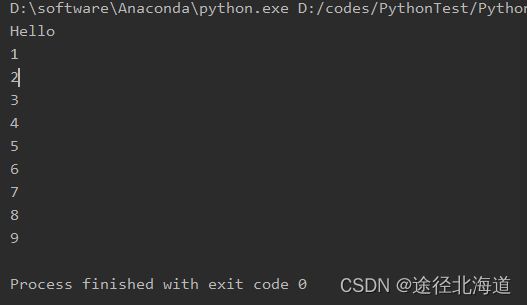
send方法:与next方法类似,send方法也可以触发生成器的下一个yield,与next不同的是,send函数还可以发送数据过去,作为yield表达式的值。
注:生成器中如果写了return语句,就会触发StopIteration异常
def my_gen():
print("hello")
yield 1
return
yield 2
ret = my_gen()
next(ret)
next(ret)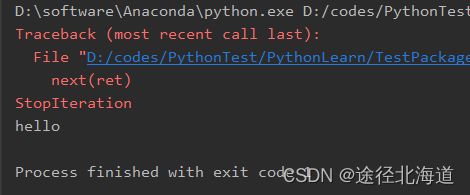
生成器案例:
1. 生成器打印斐波那契额数列:
def fab(n):
"""
斐波那契数列
:param n: 数列的个数
:return:
"""
count = 0
first = 0
second = 1
while count < n:
temp = first + second
first = second
second = temp
count += 1
yield temp
ret = fab(10)
for x in ret:
print(x)