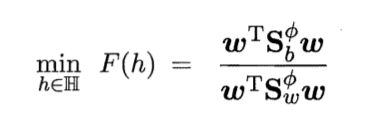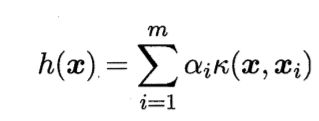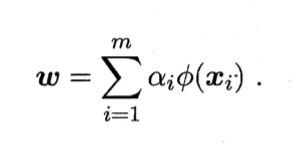机器学习-第六章 支持向量机(SVM)
机器学习-第六章 支持向量机(SVM)

D系鼎溜关注
2020.02.09 21:19:41字数 1,131阅读 458
6.1 间隔与支持向量
开倍速观看视频之后,对课本所说的会更加了解。
支持向量机讲解:https://www.bilibili.com/video/av77638697?p=6
给定一个数据集D={(x1,y1),(x2,y2),……,(xm,ym)},yi∈{-1,+1}。对于分类学习来说,最基本的想法就是找出一个超平面,能够把不同类别的样本分开。
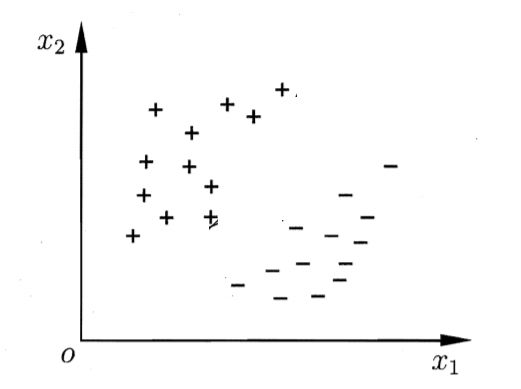
数据集
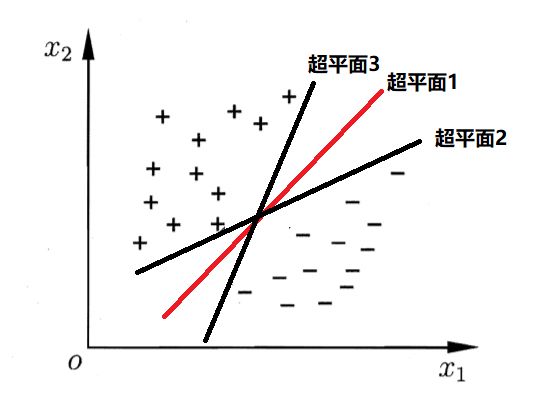
对于上图的分类,我们会想用一个超平面划分两类,
超平面划分两类
可以看出,划分两类的超平面有多种,那我们应该选择哪一种呢?
直觉上,我们会选择超平面1(红色线)。因为该超平面对训练样本局部扰动的"容忍性"好。如果选择超平面3,当有一个正例在超平面3的上方之外的话,那么就会分类错误,超平面3就不容忍这个正例,所以说超平面1的容忍性好。换句话说,就是超平面1所产生的分类结果是最鲁棒的,就是对新样例的泛化能力强。
在样本空间中,超平面的线性方程如下:
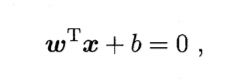
超平面线性方程
其中w = (w1,w2,……,wd)为法向量,决定了超平面的方向;b为位移项(截距),决定了超平面与原点之间的距离。划分超平面最终由w和b确定,记为(w,b)。
样本空间中样本点到超平面的距离如下:
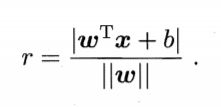
点到平面的距离公式
假设超平面(w,b)能将训练样本正确分类,则对于(xi,yi)∈D,
若yi=1,则wTxi+b>0;若yi= -1,则有wTxi+b < 0,令
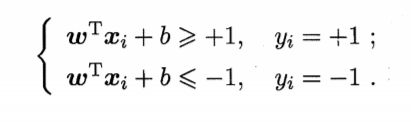
由于上面这个转换详解过于复杂,可以看视频详解,这里不作说明。对于距离超平面最近的样本点,我们称为"支持向量"。两个异类支持向量到超平面的距离之和称为间隔,如下
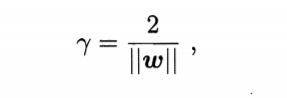
间隔
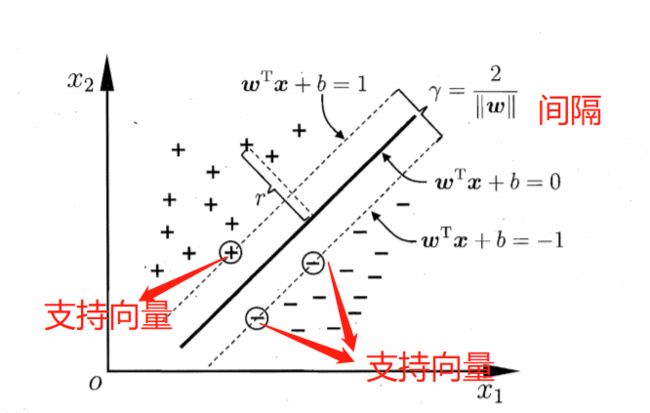
支持向量与间隔
为了尽可能划分类别正确,我们可以转化为找到具有"最大间隔"的超平面,即找到w和b,使得γ最大,即
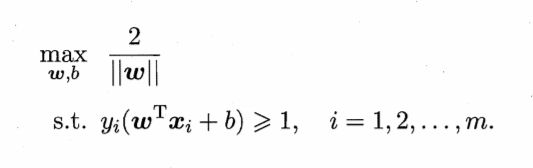
而最大化间隔,就需要最大化||w||-1,相当于最小化||w||2,则目标可以重写为
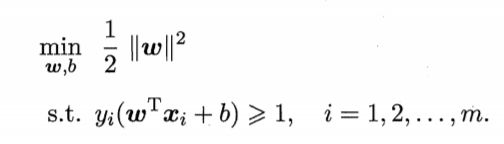
这就是支持向量机(SVM)的基本模型。
6.2 对偶问题
原始问题与对偶问题以及KKT条件的关系解释https://blog.csdn.net/fkyyly/article/details/86488582
原始问题与对偶问题的视频讲解:https://www.bilibili.com/video/av77638697?p=11
原始问题转化为对偶问题:https://www.bilibili.com/video/av77638697?p=12
上面这三个链接对于对偶问题有较好的解释。

原始问题
对于上式,是一个凸函数二次规划的问题。我们可以对上式使用拉格朗日乘子法得到原始问题的对偶问题。
对每个约束条件添加拉格朗日乘子αi,且αi≥0,则该问题的优化函数为
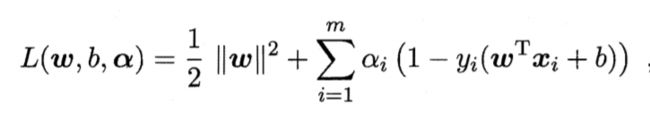
先求优化函数对于w和b的极小值即,对w和b求偏导,令偏导为0,有
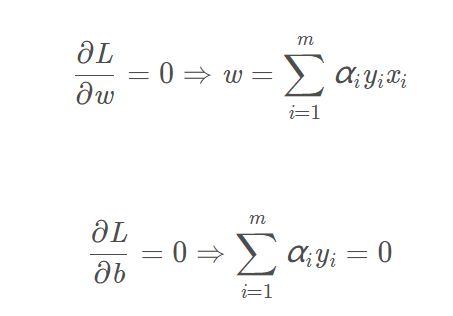
对w和b求偏导
接着将w代入优化函数得到
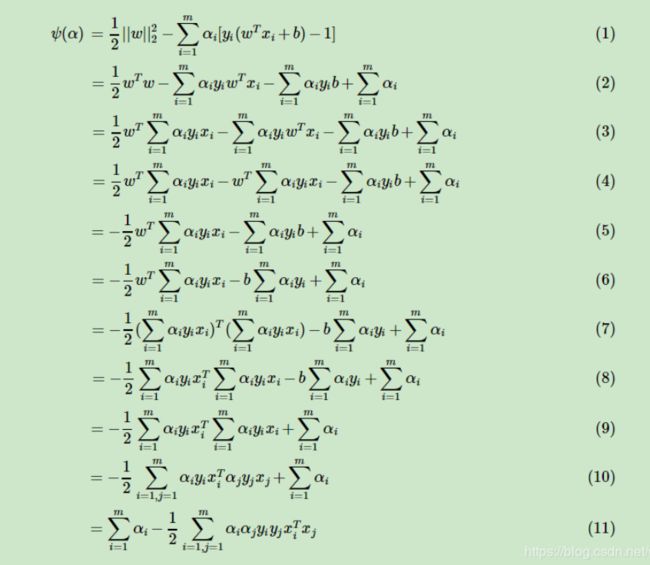
可以看出,对w和b求偏导之后代入,再考虑对b求偏导得到的约束,就得到了对偶问题
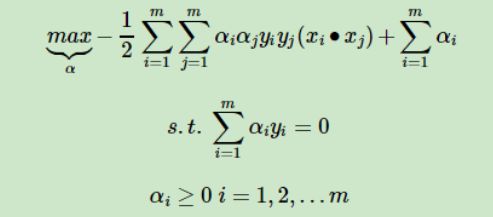
得到对偶问题
得到优化函数只剩下α作为参数,只要求优化函数的极大值,就可以求出α,进而求出w和b,再代入我们的模型,就可以了,假设我们的模型是f(x) = wTx + b,则

上述过程要满足KKT条件
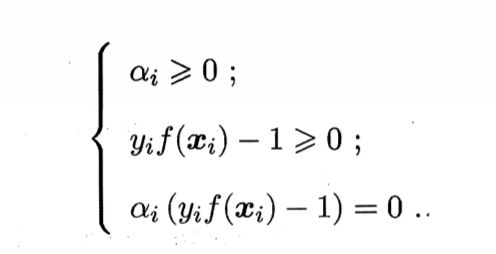
KKT条件
对于对偶问题,我们该如何求解α呢?我们用的就是SMO算法
SMO基本思路:先固定αi之外的所有参数,然后求αi上的极值。
SMO步骤:每次选择两个变量αi和αj,并固定其他参数,分别对αi和αj求偏导为0,得到αi和αj,若符合约束条件就不用算,若不符合约束条件,再更新αi和αj,代入对偶问题的目标函数,直到符合条件。

SMO步骤
可以看出,SMO固定了其他的参数,仅仅考虑αi和αj,因此对偶问题中的约束条件可以重写为
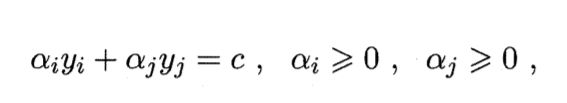
约束条件重写
其中的c
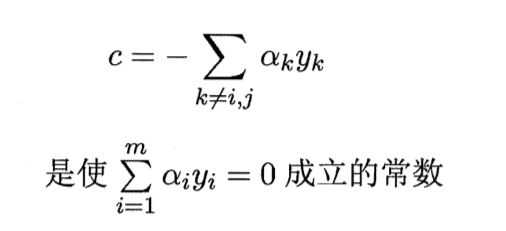
c的含义
通过重写之后的约束条件,我们可以将对偶问题中的目标函数的αj消去,只剩下αi一个变量,这时我们的约束只有KKT里面的αi≥0,对αi求导为0,得到αi,再求出aj,通过这样子我们可以更高效的求出ai和aj。求出α之后,代入
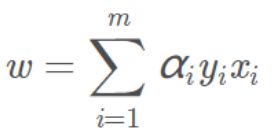
就可以计算出w了。
那么b该如何计算呢?
使用所有支持向量求解的平均值
设支持向量表示为(xs,ys)
设S= { i | αi>0,i = 1,2,3……,m}为所有支持向量的下标集。
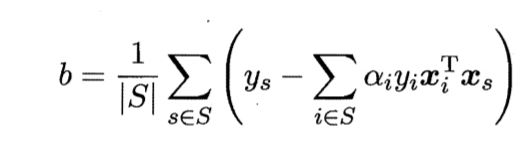
b的求解公式
支持向量机的代码实现:
https://blog.csdn.net/qq_43608884/article/details/88658216
6.3 核函数
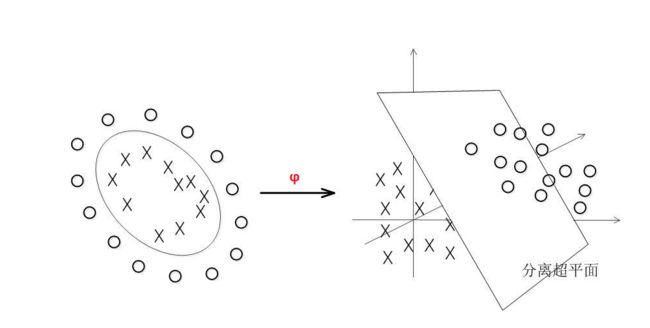
在前面的讨论中,我们假设训练样本都是线性可分的,上述SVM也只是在处理线性可分的数据。事实上,我们很多数据都是非线性可分的。
对于非线性的情况,SVM 的处理方法是选择一个核函数 κ(⋅,⋅) ,通过将数据映射φ到高维空间,来解决在原始空间中线性不可分的问题。
具体来说,在线性不可分的情况下,支持向量机首先在低维空间中完成计算,然后通过核函数将输入空间映射到高维特征空间,最终在高维特征空间中构造出最优分离超平面,从而把平面上本身不好分的非线性数据分开。
如图所示,一堆数据在二维空间无法划分,从而映射到三维空间里划分:

类似,原始问题为

原始问题
对偶问题为
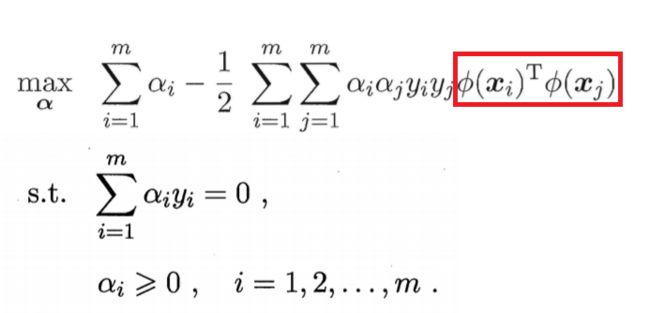
对偶问题
其中,红色方框里面的式子,表示的是样本xi和xj映射到特征空间之后的内积,当属性空间的维数很大时,直接计算内积是很困难的,因此,有
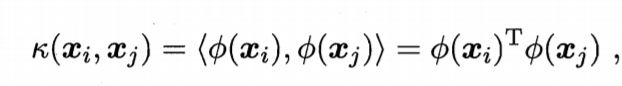
即xi和xj在属性空间中的内积等于在原始样本空间中通过函数K(·,·)计算的结果。
这里的函数K(·,·),就是核函数。
于是,对偶问题可以重写为

对偶问题重写
最终可以得到
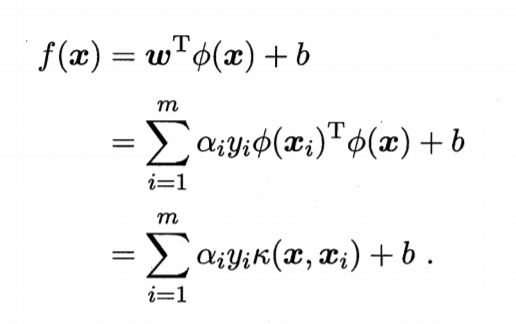
常用的核函数K(·,·)有以下几种

常用核函数
关于核函数,有下面三个关系:
- 若k1和k2为核函数,则对于任意正数γ1和γ2,其线性组合γ1k1+γ2k2也为核函数
- 若k1和k2为核函数,则核函数的直积也为核函数
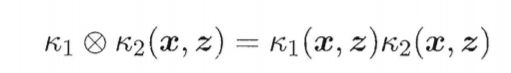
核函数的直积
- 若k1和k2为核函数,则对于任意函数g(x)
也是核函数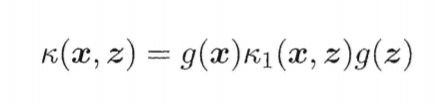
对文本数据通常采用线性核,情况不明时可先尝试高斯核。
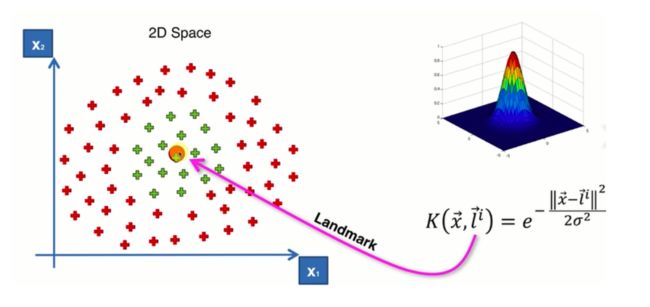
高斯核函数
支持向量机的非线性代码实现
https://blog.csdn.net/kt513226724/article/details/80413018
6.4 软间隔与正则化
在上述中的支持向量机中,我们要求所有样本都要满足约束,即都被划分正确,这叫做"硬间隔"。可实际上,很难确定合适的核函数使得样本在特种空间中线性可分,不允许分类错误的样本。
缓解这一个问题的办法就是允许支持向量机在一些样本上出错,
为此,引入"软间隔"。
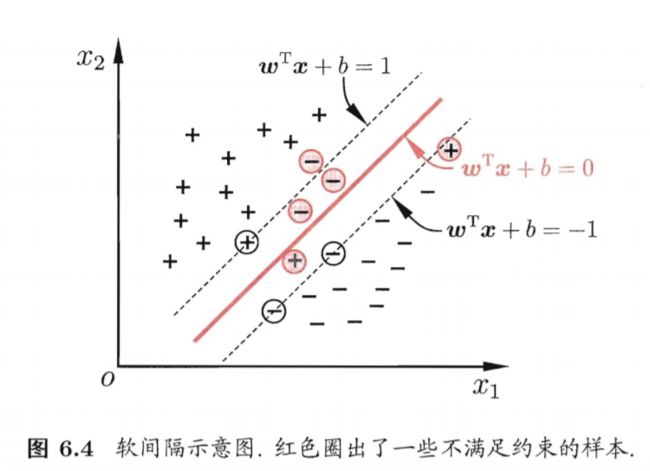
软间隔
软间隔允许某些样本不满足约束条件,也要让这些样本很少。则优化目标可以写为

其中C是一个常数,可以理解为问题正则化时加入的参数。当C趋于无穷大时,所有样本均满足原来硬间隔的约束条件;当C取有限值时,允许一些样本不满足约束。
而式子中的

损失函数
然而"0/1损失函数"的不可微、不连续,数学性质较差,于是我们可以用其他函数替代损失函数,称为"替代损失函数",通常数学性质较好,通常有以下三种替代损失函数:
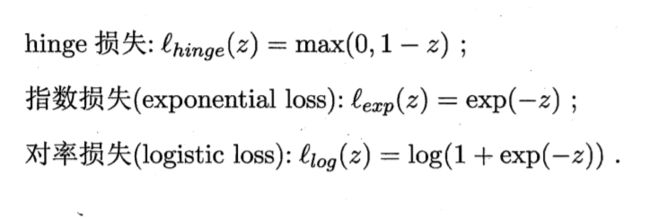
替代损失函数

下面我们使用hinge损失函数来优化目标。
首先对训练集的每个样本(xi,yi)引入一个松弛变量ξi≥0,使函数间隔加上松弛变量大于等于1,也就是说,约束条件变为
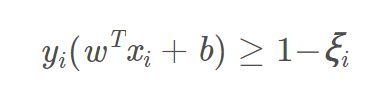
加入松弛变量之后的约束条件
对比硬间隔最大化,可以看到我们对样本到超平面的函数距离的要求放松了,之前是一定要大于等于1,现在只需要加上一个大于等于0的松弛变量能大于等于1就可以了。当引入了ξ之后,也是需要成本的,所以硬间隔到软间隔的优化目标变为

硬间隔到软间隔
接着我们对软间隔支持向量机进行目标函数的优化。通过拉格朗日乘子法得到

软间隔的拉格朗日函数
对w、b和ξ求偏导为0,得到
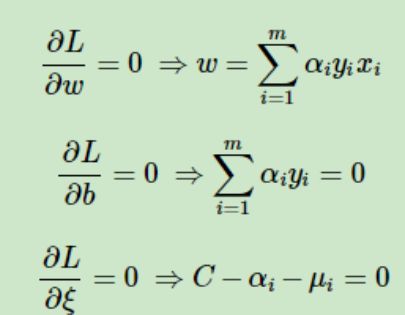
将他们代入拉格朗日函数

代入过程
此时我们就得到了,原始问题的对偶问题,
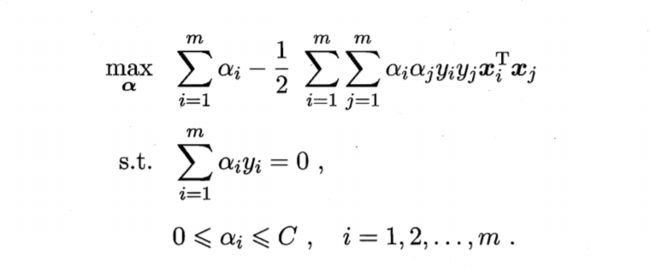
对偶问题
接着用SMO算法算出α,就可以得到w,然后再计算b,与硬间隔类似。
对于上述过程,也需要满足KKT条件

软间隔支持向量机的KKT条件
对于训练样本(xi,yi),有
1)若α=0,那么yi(wTxi+b)-1≥0,即样本在间隔边界之外,即被正确分类。
2)若0<α
① 如果0≤ξi≤1,那么样本点在超平面和间隔边界之间,但是被正确分类。
② 如果ξi=1,那么样本点在超平面上,无法被正确分类。
③ 如果ξi>1,样本点被分类错误。
对于,允许误差的优化目标函数,我们可以写为更加一般的形式
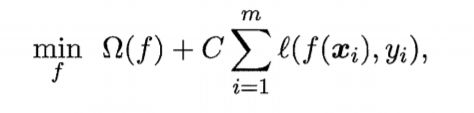
Ω(f)称为"结构风险",用于描述模型f的某些性质;
第二项的Σml(f(xi),yi)称为"经验风险",用于描述模型与训练数据的契合度。
C称为正则化常数,用于对结构风险和经验风险进行折中。
上式被称为"正则化问题",Ω(f)称为正则化项,C为正则化常数。
6.5 支持向量回归(SVR)
上面讲到的SVM是用于分类任务的,而对于回归任务,我们使用SVR。
SVM分类,就是找到一个平面,让两个分类集合的支持向量或者所有的数据离分类平面最远;
SVR回归,就是找到一个回归平面,让一个集合的所有数据到该平面的距离最近。
SVR假设f(x)与y之间最多有ε的偏差,即以f(x)为中心,允许f(x)+ε和f(x)-ε的误差,构建一个2ε的间隔。

SVR
SVR的形式如下

SVR原始问题

不敏感损失函数
由于间隔带的两侧松弛程度有所不同,所有引入松弛变量ξi和ξ^i,则原始问题重写为

接着我们要求对偶问题。首先引入拉格朗日乘子,可以得到拉格朗日函数
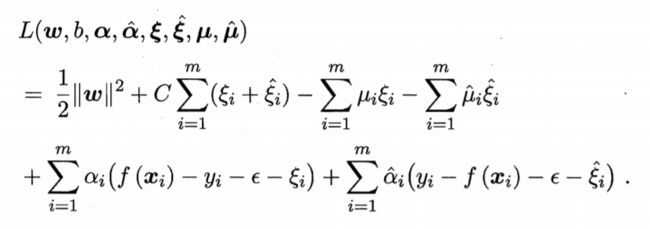
令L对w、b、ξi、ξ^i的偏导为0,可得到
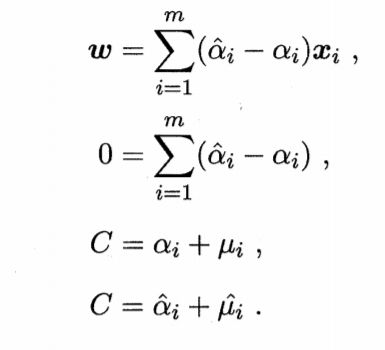
将它们代入L,可以得到对偶问题

SVR的对偶问题
上述过程中,要满足KKT条件
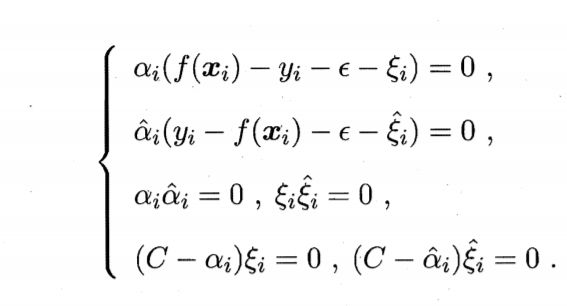
KKT条件
将上面求得的w代入我们原来的模型f(x) = wTx + b,得到SVR的解
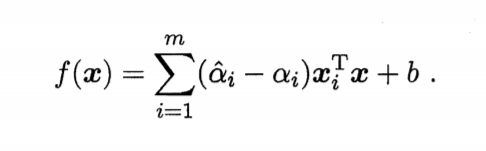
b 实际上,我们更常用的是:选取所有满足0 < ai < C的样本求解b之后取平均值。 若考虑映射到高维空间则有 最终通过上述类似的求解过程,我们得到SVR可以表示为 SVR映射形式 对于SVM和SVR,它们的优化问题都是类似下面的式子 而SVR和SVM学得的模型总能表示为核函数K(x,xi)的线性组合,所以上式的模型也可以写成为核函数的线性组合 上式模型的解 对于上面这个结论,就是"表示定理" 表示定理 我们难以直到映射φ的具体形式,因此使用核函数K(x,xi) = φ(xi)Tφ(x)来表达映射和特征空间F。 由表示定理得, 再由式6.59得 2人点赞 机器学习
由KKT可以看出,对每个样本(xi,yi)有:
1)(C - αi)ξi=0 ,2)αi(f(xi) - yi - ε - ξi)=0。
于是通过SMO算法得到αi之后,若0<αi
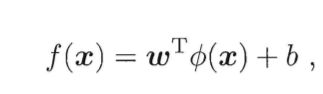
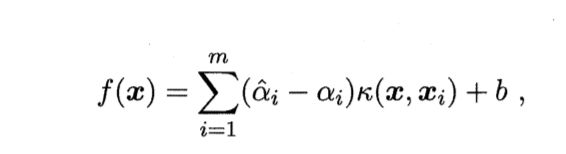
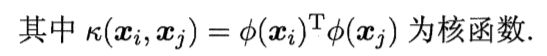
6.6 核方法
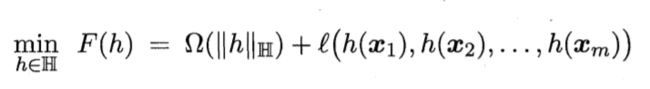
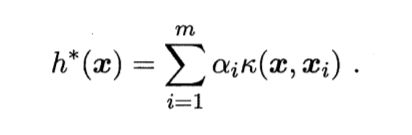

人们基于核函数的学习方法,称为"核方法"。最常见的,是通过引入核函数来将线性学习扩展为非线性。
下面以"核线性判别分析"(KLDA)为例,演示如何引入核函数进行非线性扩展。

把J(w)作为式子6.57中的损失函数,令Ω=0,有