自学springboot、开源框架、中间键笔记
SpringBoot
一.springboot的自动装配(大致原理)
springboot 所有自动配置都是在启动的时候扫描并加载:类路径下的META-INF/spirng.factoris所有的自动配置类都在这里面,但不一定生效,要判断条件是否成立,只要导入了对应的start,就有对应的启动器了,有了启动器,我们自动装配就会生效,然后配置成功。
精髓:
1.springboot启动会加载大量的自动配置类
2.我们看我们需要的功能有没有springboot默认写好的自动装配类;
3.我们再来这看这个自动配置类中到底配置了哪些组件;(只要我们要用的组件有,我们就不需要再来配置了)
4.给容器中自动配置类添加组件的时候,会从properties类中获取默写属性,我们就可以在配置文件中指定这些属性的值
xxxxAutoConfiguration:自动配置类
xxxxProperties:封装配置文件中相关属性
细节:
@Conditional派生注解(spring注解版原生的@Conditional作用)
作用:必须是@Conditional指定的条件成立,才给容器中添加组件,配置里面的所有内容才生效,在springboot衍生了很多@Conditional注解;
自动配置类必须在一定的条件下才能生效;
我们怎么知道那些自动配置类生效;
我们可以启用 debug=true属性,来让控制台打印自动配置报告,这样我们就可以很方便的知道哪些自动配置类生效;
注解:
@SpringBootApplication
作用:标注在某个类上说明这个类是SpringBoot的主配置类 , SpringBoot就应该运行这个类的main方法来启动SpringBoot应用;
@ComponentScan
这个注解在Spring中很重要 ,它对应XML配置中的元素。
作用:自动扫描并加载符合条件的组件或者bean , 将这个bean定义加载到IOC容器中
@SpringBootConfiguration
作用:SpringBoot的配置类 ,标注在某个类上 , 表示这是一个SpringBoot的配置类;
@Import({AutoConfigurationImportSelector.class}) :给容器导入组件 ;
@EnableAutoConfiguration :开启自动配置功能
以前我们需要自己配置的东西,而现在SpringBoot可以自动帮我们配置 ;@EnableAutoConfiguration告诉SpringBoot开启自动配置功能,这样自动配置才能生效;
@AutoConfigurationPackage :自动配置包
@Configuration
在spirngboot中使用@Configuration进行扩展配置,springboot自动配置和扩展配置都会起作用
@EnavleWebMvc
spingboot对springboot的自动配置不需要了,所有都是我们自己配
二.yaml
对空格的要求非常高!!
普通的key-value
name: hyh
对象
student:
name: hyh
age: 3
行内写法
student: {name: hyh,age: 3}
数组
pets:
- cat
- dog
- pig
pets: [cat,dog,pig]
JSR-303校验
验证依赖:
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-validationartifactId>
dependency>
数据验证注解:
@Validated


yml多文档块
spring:
profiles:
active: dev
---
server:
port: 8082
spring:
profiles: dev
---
server:
port: 8083
spring:
profiles: test
@ConfigurationProperties和@value的区别
| @ConfigurationProperties | @value | |
|---|---|---|
| 功能 | 批量注入属性文件中的属性 | 一个个指定 |
| 松散绑定(松散语法) | 支持 | 不支持 |
| SpEL | 不支持 | 支持 |
| JSR303数据校验 | 支持 | 不支持 |
| 复杂类型封装 | 支持 | 不支持 |
@ConfigurationProperties默认从全局配置中获取值
@PropertySource(value = “classpath:person.properties”) 加载指定的配置文件
**@ImportResource(locations = {“classpath:beans.xml”}) **导入spring的配置文件,让其生效
三.日志
日志级别:
private static final Logger log = LoggerFactory.getLogger(GlobalException.class);
Logger logger = LoggerFactory.getLogger(getClass());
//由低到高 trace
//可以调整输出日志的级别;日志就会在这个级别以后的高级别生效
logger.trace("这是trace日志....");
logger.debug("这是trace日志....");
//springboot默认给我们使用的是info级别的
logger.info("这是trace日志....");
logger.warn("这是trace日志....");
logger.error("这是trace日志....");
#输出debug级别
logging:
level:
com.hyh.server.mapper: debug
#日志保存
file:
name: spring.log
日志配置——logging.file.name与logging.file.path的使用
1.logging.file.name可以指定日志文件的路径与名字;
例如:logging.file.name:D://logs/ex.log,则该日志文件的路径为D://logs 日志文件的名字是ex.log
2.logging.file.path可以指定日志文件的路径,而不能指定名字
例如:logging.file.path:D://logs,则该日志文件的路径为D://logs 日志文件的名字是默认的spring.log
3.logging.file.name和logging.file.path不能同时生效,在配置了两者的情况下,以logging.file.name为准。
默认情况下,spring boot按照下表查找log的配置文件。
| 日志 | 命名 |
|---|---|
| Logback | logback-spring.xml, logback-spring.groovy, logback.xml, or logback.groovy |
| Log4j2 | log4j2-spring.xml or log4j2.xml |
| JDK (Java Util Logging) | logging.properties |
在某些情况下,希望使用其它的配置文件,比如:名为logback-spring-dev.xml的配置文件。此时,需要在application.properties文件中使用属性logging.config指定配置文件。如下:
logging.config=classpath:logback-spring-dev.xml
mybatis配置日志在控制台输出
mybatis-plus:
#mapper映射文件
mapper-locations: classpath*:/mapper/**Mapper.xml
#配置MyBatis数据返回类型别名
type-aliases-package: com.hyh.pojo
configuration:
#自动驼峰命名
map-underscore-to-camel-case: false
#控制台输出日志
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
四.springboot web 开发
静态资源
1.在springboot,可以使用以下方式处理静态资源
- webjars localhost:8080/webjars/
- public ,static,/**,resources localhost:8080/
2.优先级:resources>static(默认)>public
Thymeleaf模板引擎
依赖:
<dependency>
<groupId>org.thymeleafgroupId>
<artifactId>thymeleaf-spring5artifactId>
dependency>
<dependency>
<groupId>org.thymeleaf.extrasgroupId>
<artifactId>thymeleaf-extras-java8timeartifactId>
dependency>
HTML头文件:
<html lang="en" xmlns:th="http://www.thymeleaf.org">
public static final String DEFAULT_PREFIX = "classpath:/templates/";
public static final String DEFAULT_SUFFIX = ".html";
//springboot默认会找templates下的.html文件
国际化
1.springboot自动配置好了国际化资源文件组件。
2.配置文件可以直接放到类路径下叫message.properties
#更改默认路径
spring:
messages:
basename: i18n.login
Druid
依赖:
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druid-spring-boot-starterartifactId>
<version>1.2.6version>
dependency>
属性配置:
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
druid:
driverClassName: com.mysql.cj.jdbc.Driver
username: root
url: jdbc:mysql://localhost:3306/vue?serverTimezone = GMT
password: 123456
#druid数据源专有配置
initialSize: 5
minIdle: 5
maxActive: 20
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
#配置监控统计拦截的filters,stat:监控统计、log4j:日志记录、wall:防御sql注入
#如果允许报错,java.lang.ClassNotFoundException: org.apache.Log4j.Properity
#则导入log4j 依赖就行
filters: stat,wall,log4j
maxPoolPreparedStatementPerConnectionSize: 20
useGlobalDataSourceStat: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
DruidConfig:
@Configuration
public class DruidConfig {
@ConfigurationProperties(prefix = "spring.datasource.druid")
@Bean
public DataSource druidDataSource(){
return new DruidDataSource();
}
//后台监控: web.xml ServletRegistrationBean
//因为SpringBoot 内置了servlet容器,所以没有web.xml ,替代方法;ServletRegistrationBean
@Bean
public ServletRegistrationBean statViewServlet(){
ServletRegistrationBean<StatViewServlet> bean = new ServletRegistrationBean<>(new StatViewServlet(),"/druid/*");
//后台需要有人登录,账号密码配置
HashMap<String,String> initParameters = new HashMap<>();
//增加配置
initParameters.put("loginUsername","admin");//key 是固定的
initParameters.put("loginPassword","123456");
//允许谁可以访问
initParameters.put("allow","");
//禁止谁可以访问 initParameters.put("hyh","192.168.1.1");
//设置初始化参数
bean.setInitParameters(initParameters);
return bean;
}
//filter 过滤器
@Bean
public FilterRegistrationBean webStatFilter(){
FilterRegistrationBean bean = new FilterRegistrationBean();
bean.setFilter(new WebStatFilter());
Map<String,String> initParameters = new HashMap<>();
//这些东西不进行统计
initParameters.put("exclusions","*.js,*.css,/druid/*");
bean.setInitParameters(initParameters);
return bean;
}
}
Mybatis
依赖:
<dependency>
<groupId>org.mybatis.spring.bootgroupId>
<artifactId>mybatis-spring-boot-starterartifactId>
<version>2.2.0version>
dependency>
属性配置:
mybatis:
type-aliases-package: com.hyh.pojo
mapper-locations: classpath*:/mapper/**Mapper.xml
spring事务注解
@Transactional
SpringSecurity(安全)
依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-securityartifactId>
dependency>
获取当前登录用户
方法一: SecurityContextHolder.getContext().getAuthentication().getPrincipal()
Integer adminId = ((Admin) SecurityContextHolder.getContext().getAuthentication().getPrincipal()).getId();
方法二:加@AuthenticationPrincipal注解
@ApiOperation(value = "获取当前登录用户的信息")
@GetMapping("/admin/info")
public Admin getAdminInfo(@AuthenticationPrincipal Admin admin) {
admin.setPassword(null);
return admin;
}
方法三:Authentication
@MessageMapping("/ws/chat")
public void handleMsg(Authentication authentication, ChatMsg chatMsg){
Admin admin = (Admin) authentication.getPrincipal();
chatMsg.setFrom(admin.getUsername());
chatMsg.setFromNickName(admin.getName());
chatMsg.setDate(LocalDateTime.now());
/**
* 发送消息
* 1.消息接收者
* 2.消息队列
* 3.消息对象
*/
simpMessagingTemplate.convertAndSendToUser(chatMsg.getTo(),"/queue/chat",chatMsg);
}
配置:
@Configuration
public class SecurityConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure(HttpSecurity http) throws Exception {
http.authorizeRequests()
//所有请求都可以访问
.antMatchers("/**").permitAll()
//指定请求方法,才能访问
.antMatchers(HttpMethod.POST,"/demo").permitAll()
//放行后缀.png
.antMatchers("/**/*.png").permitAll()
//根据权限控制访问
.antMatchers("/level1/**").hasAuthority("vip1")
.antMatchers("/level2/**").hasAuthority("vip2")
.antMatchers("/level3/**").hasAuthority("vip3")
//多个权限
.antMatchers("/level1/**").hasAnyAuthority("vip1","vip2","vip3")
//根据角色控制访问
.antMatchers("/main.html").hasRole("abc")
//根据ip地址角色控制访问
.antMatchers("/").hasIpAddress("127.0.0.1")
//所有请求必须认证才能访问
.anyRequest().authenticated();
//没有权限默认到登录页,需要开启登录页面
http.formLogin();
//注销
http.logout();
}
//认证
//密码编码: PasswordEncoder
@Bean
@Override
protected void configure(AuthenticationManagerBuilder auth) throws Exception {
auth.inMemoryAuthentication().passwordEncoder(new BCryptPasswordEncoder())
.withUser("hyh").password(new BCryptPasswordEncoder().encode("123456")).roles("vip1","vip2")
.and()
.withUser("root").password(new BCryptPasswordEncoder().encode("123456")).roles("vip1","vip2","vip3")
.and()
.withUser("admin").password(new BCryptPasswordEncoder().encode("123456")).roles("vip1");
}
}
获取当前登录用户信息
public RespBean getShop(@AuthenticationPrincipal Admin admin){}
shiro
依赖:
<dependency>
<groupId>org.apache.shirogroupId>
<artifactId>shiro-coreartifactId>
<version>1.7.1version>
dependency>
自定义shiro:
UserRealm
//自定义realm实现,将认证/授权的来源转为数据库的来源
public class UserRealm extends AuthorizingRealm {
//授权
@Override
protected AuthorizationInfo doGetAuthorizationInfo(PrincipalCollection principalCollection) {
return null;
}
//认证
@Override
protected AuthenticationInfo doGetAuthenticationInfo(AuthenticationToken authenticationToken) throws AuthenticationException {
String account = (String) authenticationToken.getPrincipal();
if ("root".equals(account)){
//参数1: 账号 参数2 :密码 参数3:当前realm的名字
return new SimpleAuthenticationInfo(account,"12345",this.getName());
}
return null;
}
}
TestUserRealmAuthenticator
public class TestUserRealmAuthenticator {
public static void main(String[] args) {
//创建 securityManager
DefaultSecurityManager defaultSecurityManager = new DefaultSecurityManager();
//设置自定义realm
defaultSecurityManager.setRealm(new UserRealm());
//设置安全工具类
SecurityUtils.setSecurityManager(defaultSecurityManager);
//通过安全工具类获取subject
Subject subject = SecurityUtils.getSubject();
//创建token
UsernamePasswordToken usernamePasswordToken = new UsernamePasswordToken("root","123456");
//6.用户认证
try {
subject.login(usernamePasswordToken);
System.out.println("登录成功");
}catch (UnknownAccountException e){
System.out.println("用户名错误");
}catch (IncorrectCredentialsException e){
System.out.println("密码错误");
}
}
}
MD5
作用:一般用来加密 或者 签名
特点:MD5算法不可逆 无论执行多少次md5生成结果始终一致
生成结果:始终都是一个16进制32位长度字符串
一般md5会和随机盐(salt)一起使用实现加密
//使用MD5+salt+hash散列处理
Md5Hash md5Hash = new Md5Hash("123", "zxc",1024);
权限字符串
权限字符串的规则是:“资源标识符:操作:资源实例标识符”,意思是对哪个资源的哪个实例具有什么操作,”:“是资源/操作/实例的分隔符,权限字符串也可以使用*通配符
shiro+springboot
shiro 三大要素:
1.Subject 用户
2.SecurityManager 管理所有用户
3.Realm 连接数据
依赖:
<dependency>
<groupId>org.apache.shirogroupId>
<artifactId>shiro-coreartifactId>
<version>1.7.1version>
dependency>
<dependency>
<groupId>org.apache.shirogroupId>
<artifactId>shiro-springartifactId>
<version>1.3.2version>
dependency>
shiro+thymeleaf
依赖:
<dependency>
<groupId>com.github.theborakompanionigroupId>
<artifactId>thymeleaf-extras-shiroartifactId>
<version>2.0.0version>
dependency>
头文件:
<html lang="en" xmlns:th="http://www.thymeleaf.org"
xmlns:shiro=http://www.thymeleaf.org/thymeleaf-extras-shiro>
shiro+ehcache
依赖:
<dependency>
<groupId>org.apache.shirogroupId>
<artifactId>shiro-ehcacheartifactId>
<version>1.5.3version>
dependency>
ehcache
@Bean
public Realm getRealm(){
UserRealm userRealm = new UserRealm();
//修改凭证效验匹配器
HashedCredentialsMatcher credentialsMatcher = new HashedCredentialsMatcher();
credentialsMatcher.setHashAlgorithmName("md5");
credentialsMatcher.setHashIterations(1024);
userRealm.setCredentialsMatcher(credentialsMatcher);
//开启缓存
userRealm.setCacheManager(new EhCacheManager());
userRealm.setCachingEnabled(true);//开启全局缓存
userRealm.setAuthorizationCachingEnabled(true);//开启授权缓存
userRealm.setAuthorizationCacheName("authorizationCache");
userRealm.setAuthenticationCachingEnabled(true);//开启认证缓存
userRealm.setAuthenticationCacheName("authenticationCache");
return userRealm;
}
邮箱
配置:
spring:
mail:
username: [email protected]
password: LNYOEMBFJJVEIRAQ
host: smtp.163.com
#开启加密验证
properties:
mail:
smtp:
ssl:
enable: true
依赖:
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-mailartifactId>
dependency>
异步
在方法上加@Async注解,并在springboot启动类上加上@EnableAsync开启异步注解功能即可.
定时任务
0 * * * * MON-SAT
Seconds (秒) :可以用数字0-59 表示,
Minutes(分) :可以用数字0-59 表示,
Hours(时) :可以用数字0-23表示,
Day-of-Month(天) :可以用数字1-31 中的任一一个值,但要注意一些特别的月份
Month(月) :可以用0-11 或用字符串 “JAN, FEB, MAR, APR, MAY, JUN, JUL, AUG, SEP, OCT, NOV and DEC” 表示
Day-of-Week(每周):可以用数字1-7表示(1 = 星期日)或用字符口串“SUN, MON, TUE, WED, THU, FRI and SAT”表示
“/”:为特别单位,表示为“每”如“0/15”表示每隔15分钟执行一次,“0”表示为从“0”分开始, “3/20”表示表示每隔20分钟执行一次,“3”表示从第3分钟开始执行
“?”:表示每月的某一天,或第周的某一天
“L”:用于每月,或每周,表示为每月的最后一天,或每个月的最后星期几如“6L”表示“每月的最后一个星期五”
“W”:表示为最近工作日,如“15W”放在每月(day-of-month)字段上表示为“到本月15日最近的工作日”
““#”:是用来指定“的”每月第n个工作日,例 在每周(day-of-week)这个字段中内容为"6#3" or "FRI#3" 则表示“每月第三个星期五”
在启动类开启@EnableScheduling定时注解,在类上加@Scheduled(cron = “0/10 * * * * ?”)实现定时。
五.Redis
Redis(Remote Dictionary Server ),即远程字典服务
默认端口6379
依赖:
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-pool2artifactId>
dependency>
配置:
spring:
redis:
#超时时间
connect-timeout: 10000ms
#服务器地址
host: localhost
#数据库
database: 0
#服务器端口
port: 6379
lettuce:
pool:
#最大连接数,默认8
max-active: 1024
#最大连接阻塞等待时间,默认-1
max-wait: 10000ms
#最大空闲连接
max-idle: 200
#最小空闲连接
min-idle: 5
config:
/**
* Redis配置类
*/
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate redisTemplate(RedisConnectionFactory redisConnectionFactory){
RedisTemplate redisTemplate = new RedisTemplate<>();
//string类型序列key
redisTemplate.setKeySerializer(new StringRedisSerializer());
//string类型序列value
redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());
//hash类型key序列化
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
//hash类型value序列器
redisTemplate.setHashValueSerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.setConnectionFactory(redisConnectionFactory);
return redisTemplate;
}
}
启动服务:
cd /usr/local/bin
redis-server hyhconfig/redis.conf
[root@hadoop128 bin] redis-cli -p 6379
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> set name hyh
OK
127.0.0.1:6379> get name
"hyh"
127.0.0.1:6379> keys *
1) "name"
查看进程是否开启:
ps -ef|grep redis
关闭Redis:
127.0.0.1:6379> shutdown
not connected> exit
性能测试
redis-benchmark
| 序号 | 选项 | 描述 | 默认值 |
|---|---|---|---|
| 1 | -h | 指定服务器主机名 | 127.0.0.1 |
| 2 | -p | 指定服务器端口 | 6379 |
| 3 | -s | 指定服务器 socket | |
| 4 | -c | 指定并发连接数 | 50 |
| 5 | -n | 指定请求数 | 10000 |
| 6 | -d | 以字节的形式指定 SET/GET 值的数据大小 | 2 |
| 7 | -k | 1=keep alive 0=reconnect | 1 |
| 8 | -r | SET/GET/INCR 使用随机 key, SADD 使用随机值 | |
| 9 | -P | 通过管道传输 请求 | 1 |
| 10 | -q | 强制退出 redis。仅显示 query/sec 值 | |
| 11 | –csv | 以 CSV 格式输出 | |
| 12 | *-l*(L 的小写字母) | 生成循环,永久执行测试 | |
| 13 | -t | 仅运行以逗号分隔的测试命令列表。 | |
| 14 | *-I*(i 的大写字母) | Idle 模式。仅打开 N 个 idle 连接并等待。 |
简单测试
#测试100并发连接 100000请求
redis-benchmark -h localhost -p 6379 -c 100 -n 100000
基础知识
redis默认有16个数据库,默认使用第0个可以使用select进行切换
[root@hadoop128 bin]redis-cli -p 6379
127.0.0.1:6379> select 3
OK
127.0.0.1:6379[3]> dbsize
(integer) 0
127.0.0.1:6379[3]> keys * #查看所有的key
1) "name"
127.0.0.1:6379[3]> get name
"hyh"
清空当前数据库 flushdb
清空所有数据库内容 flushall
Redis是单线程的!
Redis 是基于内存操作的,cpu不是Redis内存瓶颈,Redis的瓶颈是根据机器的内存和网络带宽,既然可以使用单线程事项,就使用单线程。
Redis是c语言写的,官方提供的数据为100000+的Qps,完全不比同样是使用key-value的Memecache差!
Redis为什么单线程还那么快?
1.误区1:高性能的服务器一定是多线程?
2.误区2:多线程(cpu 上下文会切换 )一定比单线程效率高!
核心:reids是讲所有的数据全部放到内存中的,所以单线程去操作效率是最高的,多线程(cpu上下文切换:耗时操作),对于内存系统来说,如果没有上下文切换效率就是最高的。多次读写都是在一个cpu上的,在内存情况下,这就是最佳的方案!
五大基本数据类型
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
- string 字符串(可以为整形、浮点型和字符串,统称为元素)
- list 列表(实现队列,元素不唯一,先入先出原则)
- set 集合(各不相同的元素)
- hash hash散列值(hash的key必须是唯一的)
- sort set 有序集合
Redis-key
127.0.0.1:6379> keys *
(empty array)
127.0.0.1:6379> set name hyh
OK
127.0.0.1:6379> exists name #判断是否存在
(integer) 1
127.0.0.1:6379> exists age
(integer) 0
127.0.0.1:6379> move name 1 #删除
(integer) 1
127.0.0.1:6379> set name hyh
OK
127.0.0.1:6379> expire name 10 #设置10秒后过期 单位是秒
(integer) 1
127.0.0.1:6379> ttl naem #查看多少秒后过期
(integer) -2
127.0.0.1:6379> ttl name
(integer) 2
127.0.0.1:6379> type name #查看key类型
string
String(字符串)
127.0.0.1:6379> set key1 hello
OK
127.0.0.1:6379> append key1 word #追加,如果当前字符串不存在就相当于set key
(integer) 9
127.0.0.1:6379> get key1
"helloword"
127.0.0.1:6379> strlen key1 #获取字符串长度
(integer) 9
127.0.0.1:6379> set view 0
OK
#i++ 步长
127.0.0.1:6379> incr view #增加1
(integer) 1
127.0.0.1:6379> incr view
(integer) 2
127.0.0.1:6379> decr view #减少1
(integer) 1
127.0.0.1:6379> decr view
(integer) 0
127.0.0.1:6379> incrby view 10 #设置步长,指定增量
(integer) 10
127.0.0.1:6379> decrby view 5 #设置步长,指定减量
(integer) 5
#字符串范围range
127.0.0.1:6379> get key1
"helloword"
127.0.0.1:6379> getrange key1 0 2 #截取字符串[0,2]
"hel"
127.0.0.1:6379> getrange key1 0 -2 #从末尾截取1个
"hellowor"
127.0.0.1:6379> getrange key1 0 -1 #和get key一样
"helloword"
127.0.0.1:6379> setrange key2 1 xx #从1开始替换为xx
(integer) 7
127.0.0.1:6379> get key2
"axxdefg"
#setex(set with expire) #设置过期时间
#setnx(set if not exist) #不存在设置(在分布式锁中会常常使用)
127.0.0.1:6379> setex key3 30 "hello" #30秒后过期
OK
127.0.0.1:6379> ttl key3
(integer) -2
127.0.0.1:6379> setnx mykey "mo" #不存在则创建
(integer) 1
127.0.0.1:6379> setnx mykey "hi" #存在则创建失败
(integer) 0
127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3 #同时设置多个值
OK
127.0.0.1:6379> mget k1 k2 k3 #同时获取多个值
1) "v1"
2) "v2"
3) "v3"
127.0.0.1:6379> msetnx k1 v1 k4 v4 #msetnx 是一个原子性的操作,要么一起成功,要么一起失败
(integer) 0
127.0.0.1:6379> get k4
(nil)
#对象
set user:1 {name:zhangsan,age:3} #设置一个user:对象,值为json字符串来保存一个对象
#这里的key是一个巧妙的设计:user:{id}:{filed},如此设计在Reids中完全ok
127.0.0.1:6379> mset user:1:name zhangsan user:1:age 3
OK
127.0.0.1:6379> mget user:1:name user:1:age
1) "zhangsan"
2) "3"
#组合命令
127.0.0.1:6379> getset db reids
(nil)
127.0.0.1:6379> get db
"reids"
List(列表)
127.0.0.1:6379> LPUSH list one #将一个或多个值插入列表的头部
(integer) 1
127.0.0.1:6379> lpush list two
(integer) 2
127.0.0.1:6379> lpush list three
(integer) 3
127.0.0.1:6379> lrange list 0 -1
1) "three"
2) "two"
3) "one"
127.0.0.1:6379> rpush list one #将一个或多个值插入到列表的尾部
(integer) 4
127.0.0.1:6379> rpop list #移除列表的最后一个元素
"-1"
127.0.0.1:6379> lpop list #移除列表的第一个元素
"three"
127.0.0.1:6379> lindex list 1 #获取下标的第一个值
"one"
127.0.0.1:6379> lindex list 0
"two"
127.0.0.1:6379> llen list #返回列表的长度
(integer) 3
127.0.0.1:6379> lrem list 1 one #移除list中指定个数的value
(integer) 1
127.0.0.1:6379> ltrim list 1 2 #通过下标截取指定长度
OK
#rpoplush 移除列表的最后一个元素,并填加到另一个元素中
127.0.0.1:6379> rpoplpush list myothlist
"two"
127.0.0.1:6379> lrange myothlist 0 -1
1) "two"
127.0.0.1:6379> lset list 0 item #从指定下标赋值
小结
- 他实际上是一个链表,before Node after ,left right 都可以插入值
- 如果key不存在,创建新的链表
- 如果key存在,新增内容
- 如果移除了所有值,空链表,也代表不存在
- 在两边插入或者改动值,效率最高!中间元素,相对来说效率会更底一点~
消息队列(Lpush Rpop),栈(Lpush Lpop)
Set(集合)
无序不重复集合
127.0.0.1:6379> sadd myset hello #set中添加值
(integer) 1
127.0.0.1:6379> smembers myset #查看set中的值
1) "helloword"
2) "hello"
127.0.0.1:6379> sismember myset hello #判断这个值是否存在
(integer) 1
127.0.0.1:6379> smembers myset
1) "helloword"
2) "hello"
127.0.0.1:6379> scard myset #查看set中元素的个数
(integer) 2
127.0.0.1:6379> srem myset hello #移除set中的指定元素
(integer) 1
127.0.0.1:6379> scard myset
(integer) 1
127.0.0.1:6379> srandmember myset #随机抽取一个元素
"helloword"
127.0.0.1:6379> srandmember myset 2 #随机抽取指定个数的元素
1) "helo"
2) "hello"
127.0.0.1:6379> spop myset # 从集合的右侧(尾部)移除一个成员,并将其返回
"hello"
127.0.0.1:6379> smembers myset
1) "helloword"
2) "helo"
127.0.0.1:6379> srem myset helo #从集合中删除指定的值
(integer) 1
127.0.0.1:6379> smove myset myset2 helloword #把集合中指定的一个元素移动到另一个集合中
(integer) 1
127.0.0.1:6379> smembers myset2
1) "helloword"
127.0.0.1:6379> sadd set1 a
(integer) 1
127.0.0.1:6379> sadd set1 b
(integer) 1
127.0.0.1:6379> sadd set1 c
(integer) 1
127.0.0.1:6379> sadd set2 b
(integer) 1
127.0.0.1:6379> sadd set2 c
(integer) 1
127.0.0.1:6379> sadd set2 d
(integer) 1
127.0.0.1:6379> sdiff set1 set2 # 差集
1) "a"
127.0.0.1:6379> sdiff set2 set1
1) "d"
127.0.0.1:6379> sinter set1 set2 #交集
1) "c"
2) "b"
127.0.0.1:6379> sunion set1 set2 #并集
1) "b"
2) "c"
3) "a"
4) "d"
Hash(哈希)
Map集合,key-map!这时候值是一个map集合
127.0.0.1:6379> hset myhash name hyh #修改k-v
(integer) 1
127.0.0.1:6379> hset myset age 21
(integer) 1
127.0.0.1:6379> hget myhash name #获取键对应的值
"hyh"
127.0.0.1:6379> hmset myhash name zhangsan age 15 #同时修改 k-v
OK
127.0.0.1:6379> hmget myhash name age #获取多个键对应的值
1) "zhangsan"
2) "15"
127.0.0.1:6379> hgetall myhash #获取所有的键和值
1) "name"
2) "zhangsan"
3) "age"
4) "15"
127.0.0.1:6379> hlen myhash #获取hash中字段的长度
(integer) 2
127.0.0.1:6379> hexists myhash name #判断hash中key是否存在
(integer) 1
127.0.0.1:6379> hkeys myhash #获取hash中所有的key
1) "name"
2) "age"
127.0.0.1:6379> hvals myhash#获取hash中所有的value
1) "zhangsan"
2) "15"
127.0.0.1:6379> hset myhash2 age 10
(integer) 1
127.0.0.1:6379> hincrby myhash2 age -1 #自减
(integer) 9
127.0.0.1:6379> hincrby myhash2 age 1 #自加
(integer) 10
127.0.0.1:6379> hsetnx myhash name hyh
(integer) 0
127.0.0.1:6379> hsetnx myhash2 name hyh #存在则创建失败,不存在创建成功
(integer) 1
Zset(有序集合)
在set的基础上,增加了一个值
127.0.0.1:6379> zadd myset 1 one #添加一个值
(integer) 1
127.0.0.1:6379> zadd myset 2 two 3 three #添加多个值
(integer) 2
127.0.0.1:6379> zrange myset 0 -1
1) "one"
2) "two"
3) "three"
127.0.0.1:6379> zrangebyscore myset -inf +inf #从小到大排序(负无穷到正无穷)
1) "one"
2) "two"
3) "three"
127.0.0.1:6379> zrevrange myset 0 -1 #从大到小排序
1) "three"
2) "two"
127.0.0.1:6379> zrangebyscore myset -inf +inf withscores #从小到大排序并并显示分数
1) "one"
2) "1"
3) "two"
4) "2"
5) "three"
6) "3"
127.0.0.1:6379> zrem myset one #删除元素
(integer) 1
127.0.0.1:6379> zrange myset 0 -1
1) "two"
2) "three"
127.0.0.1:6379> zcard myset #获取有序集合中的个数
(integer) 2
127.0.0.1:6379> zcount myset 1 3 #获取指定区间的成员数量
(integer) 3
思路:用于排行榜
三种特殊数据类型
geospatial
有效经度从-180度到180度
有效的纬度从-85.05112878度到85.05112878度
getadd
#getadd 添加地理位置
#参数: 纬度 经度 名称
127.0.0.1:6379> geoadd china:city 121.47 31.23 shanghai
(integer) 1
127.0.0.1:6379> geoadd china:city 106.50 29.53 chongqin 114.05 22.52 shengzheng 120.16 30.24 hangzhou 108.96 34.26 xian
(integer) 4
127.0.0.1:6379> geopos china:city shanghai #获取城市的经度和纬度
1) 1) "121.47000163793563843"
2) "31.22999903975783553"
127.0.0.1:6379> geopos china:city chongqin shengzheng
1) 1) "106.49999767541885376"
2) "29.52999957900659211"
2) 1) "114.04999762773513794"
2) "22.5200000879503861"
geodist
127.0.0.1:6379> geodist china:city shanghai chongqin km #重庆到上海的距离
"1447.6737"
georadius
127.0.0.1:6379> georadius china:city 110 30 1000 km #查询指定位置半径内的城市
1) "chongqin"
2) "xian"
3) "shengzheng"
4) "hangzhou"
127.0.0.1:6379> georadius china:city 110 30 500 km
1) "chongqin"
2) "xian"
127.0.0.1:6379> georadius china:city 110 30 500 km withcoord
1) 1) "chongqin"
2) 1) "106.49999767541885376"
2) "29.52999957900659211"
2) 1) "xian"
2) 1) "108.96000176668167114"
2) "34.25999964418929977"
127.0.0.1:6379> georadius china:city 110 30 500 km count 1 #count 1 只查询一个
1) "chongqin"
georadiusbymember
127.0.0.1:6379> georadiusbymember china:city shanghai 1000 km #查找指定城市周围的城市
1) "hangzhou"
2) "shanghai"
geohash
#将二维的经度纬度转换成一维的hash
127.0.0.1:6379> geohash china:city shanghai
1) "wtw3sj5zbj0"
geospatial底层就是zset,可以通过zset修改geospatial
127.0.0.1:6379> zrange china:city 0 -1
1) "chongqin"
2) "xian"
3) "shengzheng"
4) "hangzhou"
5) "shanghai"
hyperloglog
基数统计算法(允许容错)
优点:占用的内存是固定的,2^64不同元素的技术,只需要12kb内存
127.0.0.1:6379> pfadd mykey a b c d e f g h i j #添加
(integer) 1
127.0.0.1:6379> pfcount mykey
(integer) 10
127.0.0.1:6379> pfadd mykey2 h i j z b g
(integer) 1
127.0.0.1:6379> pfcount mykey2
(integer) 6
127.0.0.1:6379> pfmerge mykey3 mykey mykey2 #并集
OK
127.0.0.1:6379> pfcount mykey3 #并集数
(integer) 11
bitmaps
位存储
统计打卡情况,两个状态的,都可以使用bitmaps
bitmaps位图,都是操作二进制位来进行记录,就只有0和1两个状态
127.0.0.1:6379> setbit sign 0 1 #存
(integer) 0
127.0.0.1:6379> setbit sign 1 1
(integer) 0
127.0.0.1:6379> setbit sign 2 0
(integer) 0
127.0.0.1:6379> setbit sign 3 1
(integer) 0
127.0.0.1:6379> getbit sign 3 #取
(integer) 1
127.0.0.1:6379> getbit sign 2
(integer) 0
127.0.0.1:6379> bitcount #统计打卡天数
(integer) 3
事务
Redis事务本质:一组命令的集合!一个事务中的所有命令都会被序列化,在事务执行过程中,会按照顺序执行.
一次性.顺序性.排他性
Redis单条命令是保证原子性的,但是事务不保证原子性.
--------队列 set set set 执行--------
所有的命令在事务中,并没有直接被执行,只有发起执行命令的时候才会执行!
redis的事务:
- 开启事务(multi)
- 命令入队(…)
- 执行事务(exec) /放弃事务(discard)
正常执行事务
127.0.0.1:6379> multi #开启事务
OK
127.0.0.1:6379(TX)> set key1 hello
QUEUED
127.0.0.1:6379(TX)> set key2 hello
QUEUED
127.0.0.1:6379(TX)> set key3 hello
QUEUED
127.0.0.1:6379(TX)> get key3
QUEUED
127.0.0.1:6379(TX)> exec #提交事务
1) OK
2) OK
3) OK
4) "hello"
放弃事务
127.0.0.1:6379> multi #开启事务
OK
QUEUED
127.0.0.1:6379(TX)> set key3 v3
QUEUED
127.0.0.1:6379(TX)> discard #取消事务
OK
127.0.0.1:6379> get k4
(nil)
编译时异常(命令有错),事务中的所有命令都不会执行
127.0.0.1:6379(TX)> set key1 v1
QUEUED
127.0.0.1:6379(TX)> getset vk
(error) ERR wrong number of arguments for 'getset' command
127.0.0.1:6379(TX)> exec
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6379> get key1
(nil)
运行时异常,事务队列中一个命令存在错误,其他命令可以正常执行,错误命令抛出异常
127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> set k1 "v1"
QUEUED
127.0.0.1:6379(TX)> incr k1
QUEUED
127.0.0.1:6379(TX)> set ke3 v3
QUEUED
127.0.0.1:6379(TX)> get ke3
QUEUED
127.0.0.1:6379(TX)> exec
1) OK
2) (error) ERR value is not an integer or out of range
3) OK
4) "v3"
多进程修改值,使用watch可以当做redis的乐观锁
127.0.0.1:6379> set money 100
OK
127.0.0.1:6379> set out 0
OK
127.0.0.1:6379> watch money #监视 money
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> decrby money 20
QUEUED
127.0.0.1:6379(TX)> incrby out 20
QUEUED
127.0.0.1:6379(TX)> exec #执行之前,另一个线程修改了我们的值,这个时候,就会导致事务执行失败
(nil)
Jedis
测试
1.导入依赖
<dependencies>
<dependency>
<groupId>redis.clientsgroupId>
<artifactId>jedisartifactId>
<version>3.6.0version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.70version>
dependency>
dependencies>
2.编码测试
- 连接数据库
- 操作命令
- 断开连接
Jedis API 参考
测试连接:
public class TestPing {
public static void main(String[] args) {
//1. new Jedis 对象
Jedis jedis = new Jedis("127.0.0.1",6379);
//jedis 的所有命令就是我们之前学习的所有命令
System.out.println(jedis.ping());
}
}
事务操作:
public class TestTx {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1",6379);
jedis.flushDB();
JSONObject jsonObject = new JSONObject();
jsonObject.put("name","张三");
jsonObject.put("sex","男");
//开启事务
Transaction multi = jedis.multi();
try {
multi.set("user1",jsonObject.toJSONString());
//代码抛出异常 ,执行失败
// int i = 1/0;
multi.set("user2",jsonObject.toJSONString());
multi.exec();
} catch (Exception e) {
multi.discard();//放弃事务
e.printStackTrace();
} finally {
System.out.println(jedis.get("user1"));
System.out.println(jedis.get("user2"));
jedis.close();//关闭链接
}
}
}
Redis持久化
在指定的时间间隔内将内存中的数据快照写入磁盘,也就是Snapshot快照,他恢复时是将快照文件读到内存中.
Redis会单独创建(fork)一个字进程来进行持久化,会将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件,整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能,如果需要进行大规模的数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的有效,RDB的缺点是最后一次持久化后端数据可能丢失,我们默认的就是RDB,一般情况下不需要修改这个配置.
RDB
rdb保存的文件是dump.rdb 在我们的配置文件的快照中进行配置
reb保存文件触发机制
- save的规则满足的情况下,会自动触发rdb规则
- 执行flushall命令,也会触发我们的rdb规则
- 退出redis,也会产生reb文件
如何恢复rdb文件
-
只需要将rdb文件放在我们reids启动目录就可以,reids启动的时候会自动检查dump.rdb恢复其中的数据
-
查看需要存放的位置
127.0.0.1:6379> config get dir 1) "dir" 2) "/data" #如果在目录下存在dump.rdb文件,启动就会自动恢复其中的数据
优点:
- 适合发规模的数据恢复
- 对数据的完整性要求不高
缺点:
- 需要一定的时间间隔进程操作,如果reids意外宕机了,这个最后一次修改数据就没有了
- fork进程的时候,会占用一定的内存空间
AOF
以日志的的形式来记录每个写操作,将reids执行过的所有命令记录下来(读取操作不记录),只许追加文件但不可以改写文件,redis启动之初会读取文件重新构建数据,换言之,redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复操作.
aof保存的是appendonly.aof文件
aof默认是不开启的,我们只需要将appendonly 改为yes 就开启了
如果这个aof文件有错误,这时候redis是启动不起来的,我们需要修复这个aof文件
reids给我们提供了一个工具redis-check-aof --fix 来修复文件
root@64b259e0ddb7:/data# redis-check-aof --fix appendonly.aof
AOF analyzed: size=110, ok_up_to=110, ok_up_to_line=27, diff=0
AOF is valid
如果aof文件大于64m,太大了,fork一个新的进程来将我们的文件进行重写
优点:
- 每一次修改都同步,文件的完整性更加好
- 每秒同步一次,可能会丢失一秒的数据
- 从不同步,效率最高
缺点:
- 相对数据文件来说,aof远远大于rdb,修复的速度也比rdb慢
- aof运行效率也要比rdb慢,所以我们reids默认的配置就是rdb持久化
Redis发布订阅
订阅端:
127.0.0.1:6379> subscribe hyh #订阅一个频道
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "hyh"
3) (integer) 1
#等待读取推送的信息
1) "message" #消息
2) "hyh" #哪个频道的消息
3) "hello,hyh" #消息具体内容
1) "message"
2) "hyh"
3) "helloword"
发布端:
127.0.0.1:6379> publish hyh "hello,hyh" #发布者发布消息到频道
(integer) 1
127.0.0.1:6379> publish hyh "helloword"
(integer) 1
Redis主从复制
概念
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(Master/Leader),后者称为从节点(Slave/Follower), 数据的复制是单向的!只能由主节点复制到从节点(主节点以写为主、从节点以读为主)。
默认情况下,每台Redis服务器都是主节点,一个主节点可以有0个或者多个从节点,但每个从节点只能由一个主节点。
作用
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余的方式。
- 故障恢复:当主节点故障时,从节点可以暂时替代主节点提供服务,是一种服务冗余的方式
- 负载均衡:在主从复制的基础上,配合读写分离,由主节点进行写操作,从节点进行读操作,分担服务器的负载;尤其是在多读少写的场景下,通过多个从节点分担负载,提高并发量。
- 高可用基石:主从复制还是哨兵和集群能够实施的基础。
为什么使用集群
- 单台服务器难以负载大量的请求
- 单台服务器故障率高,系统崩坏概率大
- 单台服务器内存容量有限。
环境配置
只配置从库,不用配置主库
127.0.0.1:6379> info replication #查看当前库的信息
# Replication
role:master #角色 master
connected_slaves:0 # 没有从机
master_failover_state:no-failover
master_replid:b5661e8f1f230f541b11fdb02bfeafd593a5e104
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
使用命令将reids设置为从机,如果重启就会变回主机.
127.0.0.1:6380> slaveof 127.0.0.1 6379
OK
只要变为从机,立马就会从主机中获取值
复制原理
Slave启动成功连接到master后会发送一个sync同步命令,Master接到命令后,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕后,master将传送整个数据文件到slave,并完成一次完全同步.
- 全量复制:slave服务在接收到数据库文件数据后,将其存盘并加载到内存中
- 增量复制:Master继续将新的所有收集到的修改命令一次传给slave,完成同步,但是只要是重新来凝结master,一次完全同步(全量复制)将被自动执行
层层链路
上一个M连接下一个S!
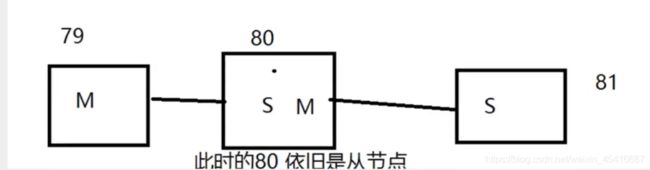
如果主节点断开
谋朝篡位(手动版)
如果主节点断开连接,我们可以使用slaveof no one让自己变成主机,其他的节点就可以手动连接到当前节点
哨兵模式
谋朝篡位(自动版)
概述
主从切换计数的方法是:当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费时费力,还会造成一段时间内服务不可用。这不是一种推荐的方式,更多时候,我们优先考虑哨兵模式。Redis从2.8开始正式提供了Sentinel(哨兵)架构来解决这个问题
谋朝篡位的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例
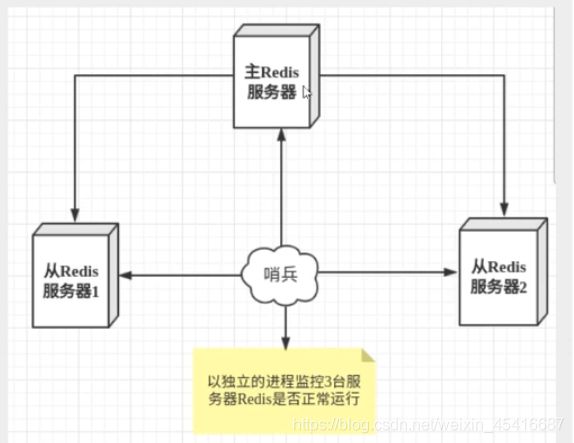
这里的哨兵有两个作用
- 通过发送命令,让Redis服务器的返回监控其运行状态,包括主服务器和从服务器
- 当哨兵监测到master宕机,会自动将slave切换程master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它么切换主机
然而一个哨兵进行对Redis服务器进行监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式
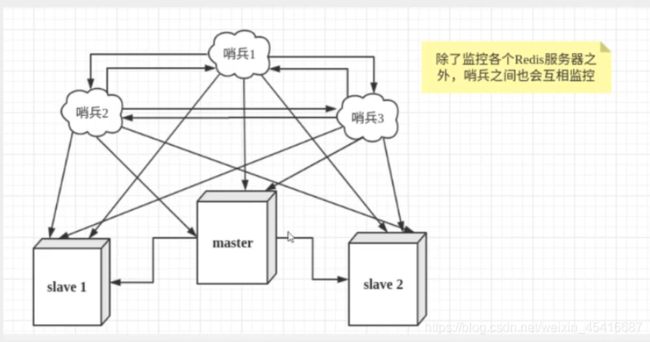
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象称为主观下线,当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover【故障转移】操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线
测试:
我们目前的状态是一主二从
1、配置哨兵配置文件 sentinel.conf
vim sentinel.conf
#sentinel monitor 被监控的主机名称 host port 1
sentinel monitor myredis 192.168.137.140 6379 1
#后面这个数字1,代表主机挂了,slave投票让谁接替成为主机,票数最多的,就会成为主机
#有密码的需要在配置文件中增加
sentinel auth-pass <master-name> <password>
2.通过redis-sentinel kconfig/sentinel.conf命令启动哨兵
如果Master节点断开了,这个时候就会从从节点中投票选择一个服务器.
如果主机回来了,自动归并到新的主机下,当做从机.
哨兵模式
优点:
- 哨兵集群,基于主从复制模式,所有的主从配置优点,他全有
- 主从可以切换,故障转移,系统的可用性就会更好
- 哨兵模式就是主从模式下的升级,手动到自动
缺点:
- Redis不好在线扩容,如果集群容量满了,在线扩容就十分麻烦
- 实现哨兵模式的配置,很麻烦,里面有很多选择
哨兵模式的全部配置
# Example sentinel.conf
# 哨兵sentinel实例运行的端口 默认26379
port 26379
# 哨兵sentinel的工作目录
dir /tmp
# 哨兵sentinel监控的redis主节点的 ip port
# master-name 可以自己命名的主节点名字 只能由字母A-z、数字0-9 、这三个字符".-_"组成。
# quorum 当这些quorum个数sentinel哨兵认为master主节点失联 那么这时 客观上认为主节点失联了
# sentinel monitor
sentinel monitor mymaster 127.0.0.1 6379 1
# 当在Redis实例中开启了requirepass foobared 授权密码 这样所有连接Redis实例的客户端都要提供密码
# 设置哨兵sentinel 连接主从的密码 注意必须为主从设置一样的验证密码
# sentinel auth-pass
sentinel auth-pass mymaster 123
# 指定多少毫秒之后 主节点没有应答哨兵sentinel 此时 哨兵主观上认为主节点下线 默认30秒
# sentinel down-after-milliseconds
sentinel down-after-milliseconds mymaster 30000
# 这个配置项指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行 同步,这个数字越小,完成failover所需的时间就越长,但是如果这个数字越大,就意味着越 多的slave因为replication而不可用。可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。
# sentinel parallel-syncs
sentinel parallel-syncs mymaster 1
# 故障转移的超时时间 failover-timeout 可以用在以下这些方面:
#1. 同一个sentinel对同一个master两次failover之间的间隔时间。
#2. 当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那里同步数据时。
#3.当想要取消一个正在进行的failover所需要的时间。
#4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了
# 默认三分钟
# sentinel failover-timeout
sentinel failover-timeout mymaster 180000
# SCRIPTS EXECUTION
#配置当某一事件发生时所需要执行的脚本,可以通过脚本来通知管理员,例如当系统运行不正常时发邮件通知相关人员。
#对于脚本的运行结果有以下规则:
#若脚本执行后返回1,那么该脚本稍后将会被再次执行,重复次数目前默认为10
#若脚本执行后返回2,或者比2更高的一个返回值,脚本将不会重复执行。
#如果脚本在执行过程中由于收到系统中断信号被终止了,则同返回值为1时的行为相同。
#一个脚本的最大执行时间为60s,如果超过这个时间,脚本将会被一个SIGKILL信号终止,之后重新执行。
#通知型脚本:当sentinel有任何警告级别的事件发生时(比如说redis实例的主观失效和客观失效等等),将会去调用这个脚本,
#这时这个脚本应该通过邮件,SMS等方式去通知系统管理员关于系统不正常运行的信息。调用该脚本时,将传给脚本两个参数,
#一个是事件的类型,
#一个是事件的描述。
#如果sentinel.conf配置文件中配置了这个脚本路径,那么必须保证这个脚本存在于这个路径,并且是可执行的,否则sentinel无法正常启动成功。
#通知脚本
# sentinel notification-script
sentinel notification-script mymaster /var/redis/notify.sh
# 客户端重新配置主节点参数脚本
# 当一个master由于failover而发生改变时,这个脚本将会被调用,通知相关的客户端关于master地址已经发生改变的信息。
# 以下参数将会在调用脚本时传给脚本:
#
# 目前总是“failover”,
# 是“leader”或者“observer”中的一个。
# 参数 from-ip, from-port, to-ip, to-port是用来和旧的master和新的master(即旧的slave)通信的
# 这个脚本应该是通用的,能被多次调用,不是针对性的。
# sentinel client-reconfig-script
六.jwt
依赖:
<dependency>
<groupId>io.jsonwebtokengroupId>
<artifactId>jjwtartifactId>
<version>0.9.1version>
dependency>
令牌组成
-标头
-有效负载
-签名
因此,jwt通常如下所示:xxxxx.yyyyy.zzzzz
JWTUtil
import io.jsonwebtoken.Claims;
import io.jsonwebtoken.Jwts;
import io.jsonwebtoken.SignatureAlgorithm;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.security.core.userdetails.UserDetails;
import org.springframework.stereotype.Component;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
/**
* jwt 工具类
*/
@Component
public class JwtTokenUtil {
private static final String CLAIM_KEY_USERNAME = "sub";
private static final String CLAIM_KEY_CREATED = "created";
@Value("${jwt.secret}")
private String secret;
@Value("${jwt.expiration}")
private Long expiration;
/**
* 根据用户信息生成token
*
* @param userDetails
* @return
*/
public String generateToken(UserDetails userDetails) {
Map<String, Object> map = new HashMap<>();
map.put(CLAIM_KEY_USERNAME, userDetails.getUsername());
map.put(CLAIM_KEY_CREATED, new Date());
return generateToken(map);
}
/**
* 从token中获取登录用户名
*
* @param token
* @return
*/
public String getUserNameFormToken(String token) {
String username;
try {
Claims claims = getClaimsFormToken(token);
username = claims.getSubject();
} catch (Exception e) {
username = null;
}
return username;
}
/**
* 从token中获取荷载
*
* @param token
* @return
*/
private Claims getClaimsFormToken(String token) {
Claims claims = null;
try {
claims = Jwts.parser()
.setSigningKey(secret)
.parseClaimsJws(token)
.getBody();
} catch (Exception e) {
e.printStackTrace();
}
return claims;
}
/**
* 判断token是否可以被刷新
*
* @param token
* @return
*/
public boolean canRefresh(String token) {
return !isTokenExpired(token);
}
public String refreshToken(String token) {
Claims claims = getClaimsFormToken(token);
claims.put(CLAIM_KEY_CREATED, new Date());
return generateToken(claims);
}
/**
* 验证是否有效
*
* @param token
* @param userDetails
* @return
*/
public boolean validateToken(String token, UserDetails userDetails) {
String username = getUserNameFormToken(token);
return username.equals(userDetails.getUsername()) && !isTokenExpired(token);
}
/**
* 判断token 是否失效
*
* @return
*/
private boolean isTokenExpired(String token) {
Date expireDate = getExpiredDateFromToken(token);
return expireDate.before(new Date());
}
/**
* 从token 中获取过期时间
*
* @param token
* @return
*/
private Date getExpiredDateFromToken(String token) {
Claims claims = getClaimsFormToken(token);
return claims.getExpiration();
}
/**
* 根据荷载生成JWT Token
*
* @param map
* @return
*/
public String generateToken(Map<String, Object> map) {
return Jwts.builder()
.setClaims(map)
.setExpiration(generateExpirationDate())
.signWith(SignatureAlgorithm.HS512, secret)
.compact();
}
/**
* 生成Token 失效时间
*
* @return
*/
private Date generateExpirationDate() {
return new Date(System.currentTimeMillis() + expiration * 1000);
}
}
public class JWTUtil {
private static final String SING = "1323!#@#!#!#dxcvas";
/**
*
* @param map
* @return token
*/
public static String getToken(Map<String,Object> map){
Calendar instance = Calendar.getInstance();
instance.add(Calendar.DATE,7);//默认7天过期
JWTCreator.Builder builder = JWT.create();
map.forEach((k,v)->{
builder.withClaim(k, (String) v);
});
String token = builder.withExpiresAt(instance.getTime())//过期时间
.sign(Algorithm.HMAC256(SING));
return token;
}
/**
*验证token合法性
* @param token
*/
public static DecodedJWT verify(String token){
return JWT.require(Algorithm.HMAC256(SING)).build().verify(token);
}
}
七.Mybatis-Plus
依赖:
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-freemarkerartifactId>
dependency>
<dependency>
<groupId>com.baomidougroupId>
<artifactId>mybatis-plus-boot-starterartifactId>
<version>3.4.0version>
dependency>
<dependency>
<groupId>com.baomidougroupId>
<artifactId>mybatis-plus-generatorartifactId>
<version>3.4.1version>
dependency>
配置:
mybatis-plus:
#mapper映射文件
mapper-locations: classpath*:/mapper/**Mapper.xml
#配置MyBatis数据返回类型别名
type-aliases-package: com.hyh.server.pojo
configuration:
#自动驼峰命名
map-underscore-to-camel-case: false
SQL查询时不加入属性
@TableField(exist = false)
CRUD
查询:
// 测试批量查询!
@Test
public void testSelectByBatchId(){
List<User> users = userMapper.selectBatchIds(Arrays.asList(1, 2, 3));
for (User user : users) {
System.out.println(user);
}
}
// 按条件查询之一使用map操作
@Test
public void testSelectByBathIds(){
HashMap<String, Object> map = new HashMap<>();
//自定义查询条件
map.put("name","狂神说Java");
map.put("age",3);
List<User> users = userMapper.selectByMap(map);
users.forEach(System.out::println);
}
删除:
// 通过id批量删除
@Test
public void testDeleteBatchId(){
userMapper.deleteBatchIds(Arrays.asList(1240620674645544961L,1240620674645544962L));
}
// 通过map删除
@Test
public void testDeleteMap(){
HashMap<String, Object> map = new HashMap<>();
map.put("name","狂神说Java");
userMapper.deleteByMap(map);
}
逻辑删除:
物理删除 :从数据库中直接移除
逻辑删除 :再数据库中没有被移除,而是通过一个变量来让他失效! deleted = 0 ==>> deleted = 1
管理员可以查看被删除的记录!防止数据的丢失,类似于回收站!
测试一下:
1、在数据表中增加一个 deleted 字段
2、实体类中增加属性
@TableLogic //逻辑删除
private Integer deleted;
3、配置!
// 逻辑删除组件!
@Bean
public ISqlInjector sqlInjector() {
return new LogicSqlInjector();
}
配置逻辑删除
mybatis-plus:
global-config:
db-config:
logic-delete-value: 1 # 逻辑已删除值(默认为 1)
logic-not-delete-value: 0 # 逻辑未删除值(默认为 0)
主键生成策略:
数据库默认插入的ID为全局唯一ID
数据库中的主键生成[uuid,自增id,雪花算法(推特的snowflake),reids,zookeeper]
雪花算法:
SnowFlake 算法,是 Twitter 开源的分布式 id 生成算法。其核心思想就是:使用一个 64 bit 的 long 型的数字作为全局唯一 id。在分布式系统中的应用十分广泛,且ID 引入了时间戳,基本上保持自增的,后面的代码中有详细的注解。
@TableId(value = "id", type = IdType.AUTO)
//AUTO(0) 主键自增
//NONE(1) 未设置主键
//INPUT(2) 手动输入
//ASSIGN_ID(3) 默认全局id
//ASSIGN_UUID(4) 全局唯一UUID
自动填充
创建时间,修改时间,这些操作自动完成,不手动更新!
阿里巴巴开发手册:所有的数据库表:gmt_creat,gmt_modlified几乎所有的表都要配置上,而且需要自动化!
方式一:数据库级别(在工作中不允许修改数据库)
方式二:代码级别
1.删除数据库的默认值
2.实体类字段属性上需要增加注解
@TableField(fill = FieldFill.INSERT)
//DEFAULT
//INSERT
//UPDATE
//INSERT_UPDATE
3.编写处理器来处理这个注解即可
@Slf4j
@Component
public class MyMetaObjectHandler implements MetaObjectHandler {
@Override
public void insertFill(MetaObject metaObject) {
log.info("start insert fill ....");
this.strictInsertFill(metaObject, "createTime", LocalDateTime.class, LocalDateTime.now()); // 起始版本 3.3.0(推荐使用)
// 或者
this.strictInsertFill(metaObject, "createTime", () -> LocalDateTime.now(), LocalDateTime.class); // 起始版本 3.3.3(推荐)
// 或者
this.fillStrategy(metaObject, "createTime", LocalDateTime.now()); // 也可以使用(3.3.0 该方法有bug)
}
@Override
public void updateFill(MetaObject metaObject) {
log.info("start update fill ....");
this.strictUpdateFill(metaObject, "updateTime", LocalDateTime.class, LocalDateTime.now()); // 起始版本 3.3.0(推荐)
// 或者
this.strictUpdateFill(metaObject, "updateTime", () -> LocalDateTime.now(), LocalDateTime.class); // 起始版本 3.3.3(推荐)
// 或者
this.fillStrategy(metaObject, "updateTime", LocalDateTime.now()); // 也可以使用(3.3.0 该方法有bug)
}
}
乐观锁
乐观锁:顾名思义十分乐观,他总是认为不会出现问题,无论干什么不去上锁!如果出现了问题,再次更新测试
悲观锁:顾名思义十分悲观,他总是认为会出现问题,无论干什么都会上锁!再操作
乐观锁实现方式
- 取出记录,获取当前version
- 更新是,带上这个version
- 执行更新是,set varsion = newVersion where version = oldVersion
- 如果version不对,就更新失败
乐观锁:1.先查询,获得版本号 version = 1
--A
update user set name = "hyh" ,version = version + 1
where id = 2 and version = 1
--B 线程抢险完成,这个时候version=2,会导致A修改失败
update user set name = "hyh" ,version = version + 1
where id = 2 and version = 1
MP的乐观锁插件
1.给数据库中增加version字段
2.给实体类对应的字段上加上@Version注解
3.注册组件
// Spring Boot 方式
@Configuration
@MapperScan("按需修改")
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor mybatisPlusInterceptor = new MybatisPlusInterceptor();
mybatisPlusInterceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor());
return mybatisPlusInterceptor;
}
}
测试:
@Test
public void testOptimisticLocker2(){
// 线程 1
User user = userMapper.selectById(1L);
user.setName("kuangshen111");
user.setEmail("[email protected]");
// 模拟另外一个线程执行了插队操作
User user2 = userMapper.selectById(1L);
user2.setName("kuangshen222");
user2.setEmail("[email protected]");
userMapper.updateById(user2);
// 自旋锁来多次尝试提交!
userMapper.updateById(user); // 如果没有乐观锁就会覆盖插队线程的值!
}
分页插件
配置:
//Spring boot方式
@Configuration
@MapperScan("com.hyh.mapper")
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.H2));
interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor());
return interceptor;
}
}
使用:
@Override
public RestPageBean getGoodByType(Integer currentPage,Integer size,Integer id) {
Page<Goods> page = new Page<>(currentPage,size);
IPage<Goods> goodsIPage = goodsMapper.getGoodByType(page,id);
RestPageBean restPageBean = new RestPageBean(goodsIPage.getTotal(), goodsIPage.getRecords());
return restPageBean;
}
IPage<Goods> getGoodByType(Page page,@Param("id") Integer id);
代码生成器
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
import com.baomidou.mybatisplus.core.exceptions.MybatisPlusException;
import com.baomidou.mybatisplus.core.toolkit.StringPool;
import com.baomidou.mybatisplus.core.toolkit.StringUtils;
import com.baomidou.mybatisplus.generator.InjectionConfig;
import com.baomidou.mybatisplus.generator.config.*;
import com.baomidou.mybatisplus.generator.config.po.TableInfo;
import com.baomidou.mybatisplus.generator.engine.FreemarkerTemplateEngine;
public class CodeGenerator {
/**
*
* 读取控制台内容
*
*/
public static String scanner(String tip) {
Scanner scanner = new Scanner(System.in);
StringBuilder help = new StringBuilder();
help.append("请输入" + tip + ":");
System.out.println(help.toString());
if (scanner.hasNext()) {
String ipt = scanner.next();
if (StringUtils.isNotBlank(ipt)) {
return ipt;
}
}
throw new MybatisPlusException("请输入正确的" + tip + "!");
}
public static void main(String[] args) {
// 代码生成器
AutoGenerator mpg = new AutoGenerator();
// 全局配置
GlobalConfig gc = new GlobalConfig();
String projectPath = System.getProperty("user.dir");
gc.setOutputDir(projectPath + "/src/main/java");
gc.setAuthor("jobob");
gc.setOpen(false);
// gc.setSwagger2(true); 实体属性 Swagger2 注解
mpg.setGlobalConfig(gc);
// 数据源配置
DataSourceConfig dsc = new DataSourceConfig();
dsc.setUrl("jdbc:mysql://localhost:3306/vueblog?serverTimezone = GMT");
// dsc.setSchemaName("public");
dsc.setDriverName("com.mysql.cj.jdbc.Driver");
dsc.setUsername("root");
dsc.setPassword("123456");
mpg.setDataSource(dsc);
// 包配置
PackageConfig pc = new PackageConfig();
pc.setModuleName(null);
pc.setParent("com.hyh");
mpg.setPackageInfo(pc);
// 自定义配置
InjectionConfig cfg = new InjectionConfig() {
@Override
public void initMap() {
// to do nothing
}
};
// 如果模板引擎是 freemarker
String templatePath = "/templates/mapper.xml.ftl";
// 如果模板引擎是 velocity
// String templatePath = "/templates/mapper.xml.vm";
// 自定义输出配置
List<FileOutConfig> focList = new ArrayList<>();
// 自定义配置会被优先输出
focList.add(new FileOutConfig(templatePath) {
@Override
public String outputFile(TableInfo tableInfo) {
// 自定义输出文件名 , 如果你 Entity 设置了前后缀、此处注意 xml 的名称会跟着发生变化!!
return projectPath + "/src/main/resources/mapper/"
+ "/" + tableInfo.getEntityName() + "Mapper" + StringPool.DOT_XML;
}
});
/*
cfg.setFileCreate(new IFileCreate() {
@Override
public boolean isCreate(ConfigBuilder configBuilder, FileType fileType, String filePath) {
// 判断自定义文件夹是否需要创建
checkDir("调用默认方法创建的目录,自定义目录用");
if (fileType == FileType.MAPPER) {
// 已经生成 mapper 文件判断存在,不想重新生成返回 false
return !new File(filePath).exists();
}
// 允许生成模板文件
return true;
}
});
*/
cfg.setFileOutConfigList(focList);
mpg.setCfg(cfg);
// 配置模板
TemplateConfig templateConfig = new TemplateConfig();
// 配置自定义输出模板
//指定自定义模板路径,注意不要带上.ftl/.vm, 会根据使用的模板引擎自动识别
// templateConfig.setEntity("templates/entity2.java");
// templateConfig.setService();
// templateConfig.setController();
templateConfig.setXml(null);
mpg.setTemplate(templateConfig);
// 策略配置
StrategyConfig strategy = new StrategyConfig();
strategy.setNaming(NamingStrategy.underline_to_camel);
strategy.setColumnNaming(NamingStrategy.underline_to_camel);
// strategy.setSuperEntityClass("你自己的父类实体,没有就不用设置!");
strategy.setEntityLombokModel(true);
strategy.setRestControllerStyle(true);
// 公共父类
//strategy.setSuperControllerClass("你自己的父类控制器,没有就不用设置!");
// 写于父类中的公共字段
//strategy.setSuperEntityColumns("id");
strategy.setInclude(scanner("表名,多个英文逗号分割").split(","));
strategy.setControllerMappingHyphenStyle(true);
strategy.setTablePrefix("m_");
mpg.setStrategy(strategy);
mpg.setTemplateEngine(new FreemarkerTemplateEngine());
mpg.execute();
}
}
分页:
import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.autoconfigure.ConfigurationCustomizer;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MybatisPlusConfig {
/* 旧版本配置
@Bean
public PaginationInterceptor paginationInterceptor(){
return new PaginationInterceptor();
}*/
/**
* 新的分页插件,一缓和二缓遵循mybatis的规则,需要设置 MybatisConfiguration#useDeprecatedExecutor = false 避免缓存出现问题
*/
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
@Bean
public ConfigurationCustomizer configurationCustomizer() {
return configuration -> configuration.setUseDeprecatedExecutor(false);
}
}
八.EasyPoi
依赖:
<dependency>
<groupId>cn.afterturngroupId>
<artifactId>easypoi-spring-boot-starterartifactId>
<version>4.3.0version>
dependency>
<dependency>
<groupId>cn.afterturngroupId>
<artifactId>easypoi-baseartifactId>
<version>4.3.0version>
dependency>
<dependency>
<groupId>cn.afterturngroupId>
<artifactId>easypoi-webartifactId>
<version>4.3.0version>
dependency>
<dependency>
<groupId>cn.afterturngroupId>
<artifactId>easypoi-annotationartifactId>
<version>4.3.0version>
dependency>
导出:
@ApiOperation(value = "导出员工数据")
@GetMapping(value = "/export",produces = "application/octet-stream")
public void exportEmployee(HttpServletResponse response){
List<Employee> list = employeeService.getEmployee(null);
ExportParams params = new ExportParams("员工表","员工表", ExcelType.HSSF);
Workbook workbook = ExcelExportUtil.exportExcel(params,Employee.class,list);
ServletOutputStream outputStream = null;
try {
//流形式
response.setHeader("content-type","application/octet-stream");
//中文乱码
response.setHeader("content-disposition","attachment;filename="+ URLEncoder.encode("员工表.xls","UTF-8"));
outputStream = response.getOutputStream();
workbook.write(outputStream);
} catch (Exception e) {
e.printStackTrace();
}finally {
if (null != outputStream){
try {
outputStream.flush();
outputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
导入:
@ApiOperation(value = "导入员工数据")
@PostMapping("/import")
public RespBean importEmployee(MultipartFile file){
ImportParams params = new ImportParams();
//去掉标题行
params.setTitleRows(1);
List<Nation> nations = nationService.list();
List<PoliticsStatus> politicsStatuses = politicsStatusService.list();
List<Position> positions = positionService.list();
List<Department> departments = departmentService.list();
List<Joblevel> joblevels = joblevelService.list();
try {
List<Employee> list = ExcelImportUtil.importExcel(file.getInputStream(), Employee.class, params);
list.forEach(employee ->{
//民族id
employee.setNationId(nations.get(nations.indexOf(new Nation(employee.getNation().getName()))).getId());
//政治面貌id
employee.setPoliticId(politicsStatuses.get(politicsStatuses.indexOf(new PoliticsStatus(employee.getPoliticsStatus().getName()))).getId());
//部门id
employee.setDepartmentId(departments.get(departments.indexOf(new Department(employee.getDepartment().getName()))).getId());
//职称id
employee.setJobLevelId(joblevels.get(joblevels.indexOf(new Joblevel(employee.getJoblevel().getName()))).getId());
//职位id
employee.setPosId(positions.get(positions.indexOf(new Position(employee.getPosition().getName()))).getId());
});
if (employeeService.saveBatch(list)){
return RespBean.success("导入成功");
}
return RespBean.error("导入失败");
} catch (Exception e) {
e.printStackTrace();
}
return RespBean.error("导入失败");
}
九.RabbitMQ
消息的高可用和高可靠
保证消息服务器不会挂掉,出现了故障依然可以抱着消息服务继续使用的方式:
1.消息共享
2.消息同步
3.元数据共享
URL: http://localhost:15672/#/
RabbitMQ的几种工作模式
1.simple简单模式
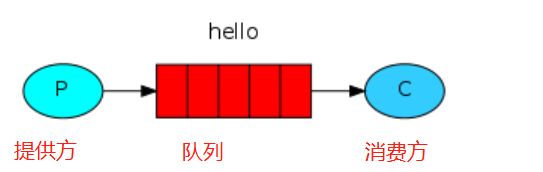
1)消息产生后将消息放入队列
2)消息的消费者(consumer) 监听(while) 消息队列,如果队列中有消息,就消费掉,消息被拿走后,自动从队列中删除(隐患 消息可能没有被消费者正确处理,已经从队列中消失了,造成消息的丢失)应用场景:聊天(中间有一个过度的服务器;p端,c端
2.work工作模式(资源的竞争)
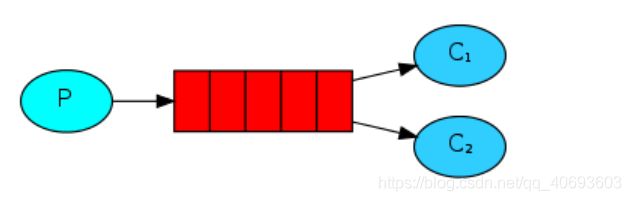
功能:一个生产者,多个消费者,每个消费者获取到的消息唯一,多个消费者只有一个队列
1)消息产生者将消息放入队列消费者可以有多个,消费者1,消费者2,同时监听同一个队列,消息被消费?C1 C2共同争抢当前的消息队列内容,谁先拿到谁负责消费消息(隐患,高并发情况下,默认会产生某一个消息被多个消费者共同使用,可以设置一个开关(syncronize,与同步锁的性能不一样。保证一条消息只能被一个消费者使用)
2)应用场景:红包;大项目中的资源调度(任务分配系统不需知道哪一个任务执行系统在空闲,直接将任务扔到消息队列中,空闲的系统自动争抢)
3、publish/subscribe发布订阅(共享资源)

1)X代表交换机rabbitMQ内部组件,erlang 消息产生者是代码完成,代码的执行效率不高,消息产生者将消息放入交换机,交换机发布订阅把消息发送到所有消息队列中,对应消息队列的消费者拿到消息进行消费
2)相关场景:邮件群发,群聊天,广播(广告)
4、routing路由模式

1)消息生产者将消息发送给交换机按照路由判断,路由是字符串(info) 当前产生的消息携带路由字符(对象的方法),交换机根据路由的key,只能匹配上路由key对应的消息队列,对应的消费者才能消费消息
2)根据业务功能定义路由字符串
3)从系统的代码逻辑中获取对应的功能字符串,将消息任务扔到对应的队列中业务场景:error 通知;EXCEPTION;错误通知的功能;传统意义的错误通知;客户通知;利用key路由,可以将程序中的错误封装成消息传入到消息队列中,开发者可以自定义消费者,实时接收错误
5、 topic 主题模式(路由模式的一种)
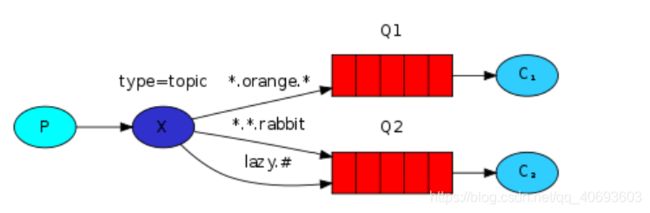
1)星号井号代表通配符
2)星号代表多个单词,井号代表一个单词
3)路由功能添加模糊匹配
4)消息产生者产生消息,把消息交给交换机
5)交换机根据key的规则模糊匹配到对应的队列,由队列的监听消费者接收消息消费
5、RPC模式
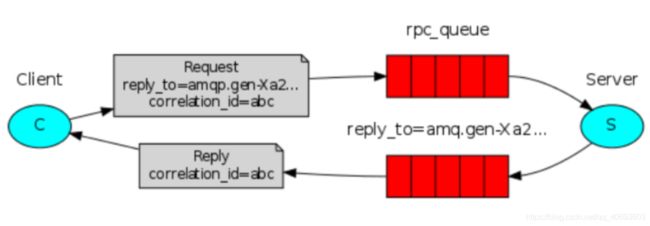
RPC即客户端远程调用服务端的方法 ,使用MQ可以实现RPC的异步调用,基于Direct交换机实现,流程如下:
1)客户端即是生产者也是消费者,向RPC请求队列发送RPC调用消息,同时监听RPC响应队列。
2)服务端监听RPC请求队列的消息,收到消息后执行服务端的方法,得到方法返回的结果。
3)服务端将RPC方法 的结果发送到RPC响应队列。
4)客户端(RPC调用方)监听RPC响应队列,接收到RPC调用结果。
更多参考
Exchange交换机类型
- Direct exchange(直连交换机) 定向,点对点
- Fanout exchang(扇型交换机) 广播,发送消息到每一个与之绑定队列
- Topic exchange(主体交换机) 通配符的方式
- Headers exchange(头交换机) 参数匹配
依赖:
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-amqpartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-mailartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-thymeleafartifactId>
dependency>
spring:
rabbitmq:
username: guest
password: guest
host: localhost
port: 5672
自动配置:
1.RabbitProperties封装了RabbitMQ配置
2.RabbitTemplate:给Rabbitmq发送和接受消息
3.AmqpAdmin:RabbitMQ系统管理功能组件
//message需要自己构造应该,定义消息体内容和消息头
rabbitTemplate.send(exchange,routeKey,message);
//只需要传入要发送的对象,自动序列化发送给rabbitmq
rabbitTemplate.convertAndSend(exchange,routeKey,object);
RabbitMQ接收消息:
rabbitTemplate.receiveAndConvert(QueuesName);
@EnableRabbit + @RabbitListener(queues = MailConstants.MAIL_QUEUE_NAME) 实现监听消息队列的内容
高级
过期时间
两种方式都开启时以时间最短的为准
方式1(通过TTL队列来设置,过期后写入死信队列):
//2.Queue队列
@Bean
public Queue ttlQueue(){
//设置队列的过期时间
Map<String,Object> args = new HashMap<>();
args.put("x-message-ttl",5000);//这里一定是int类型
return new Queue(QUEUE_NAME,true,false,false,args);
}
方式2(消息中设置,过期直接移除):
@Test
void contextLoad3() {
//给消息设置过期时间
MessagePostProcessor messagePostProcessor = message -> {
message.getMessageProperties().setExpiration("5000");
message.getMessageProperties().setContentEncoding("UTF-8");
return message;
};
rabbitTemplate.convertAndSend(RabbitMQConfig.EXCHANGE_NAME,"boot.hyh","boot mq hello",messagePostProcessor);
}
死信队列
1.创建一个普通队列
@Configuration
public class DeadRabbitMQConfig {
public static final String EXCHANGE_NAME = "dead_direct_exchange";
public static final String QUEUE_NAME = "dead_direct_queue";
//1.交换机
@Bean
public DirectExchange deadExchange(){
return new DirectExchange(EXCHANGE_NAME,true,false);
}
//2.Queue队列
@Bean
public Queue deadQueue(){
return new Queue(QUEUE_NAME,true);
}
//3.队列和交换机绑定关系
@Bean
public Binding deadBindQueueExchange(){
return BindingBuilder.bind(deadQueue()).to(deadExchange()).with("dead");
}
}
2.将ttl队列绑定死信队列
@Configuration
public class TTLRabbitMQConfig {
public static final String EXCHANGE_NAME = "ttl_direct_exchange";
public static final String QUEUE_NAME = "ttl_direct_queue";
//1.交换机
@Bean
public DirectExchange ttlExchange(){
return new DirectExchange(EXCHANGE_NAME,true,false);
}
//2.Queue队列
@Bean
public Queue ttlQueue(){
//设置队列的过期时间
Map<String,Object> args = new HashMap<>();
args.put("x-message-ttl",5000);//这里一定是int类型
args.put("x-dead-letter-exchange","dead_direct_exchange");
args.put("x-dead-letter-routing-key","dead");//fanout不需要配置
return new Queue(QUEUE_NAME,true,false,false,args);
}
//3.队列和交换机绑定关系
@Bean
public Binding ttlBindQueueExchange(){
return BindingBuilder.bind(ttlQueue()).to(ttlExchange()).with("ttl");
}
}
RabbitMQ运维-内存磁盘的监控
RabbitMQ的内存警告
参考帮助文档:https://www.rabbitmq.com/configure.html
当内存使用超过配置的阈值或者磁盘空间剩余空间对于配置的阈值时,RabbitMQ会暂时阻塞客户端的连接,并且停止接收从客户端发来的消息,以此避免服务器的崩溃,客户端与服务端的心态检测机制也会失效。
如下图:

当出现blocking或blocked话说明到达了阈值和以及高负荷运行了。
命令的方式
rabbitmqctl set_vm_memory_high_watermark <fraction>
rabbitmqctl set_vm_memory_high_watermark absolute 50MB
fraction/value 为内存阈值。默认情况是:0.4/2GB,代表的含义是:当RabbitMQ的内存超过40%时,就会产生警告并且阻塞所有生产者的连接。通过此命令修改阈值在Broker重启以后将会失效,通过修改配置文件方式设置的阈值则不会随着重启而消失,但修改了配置文件一样要重启broker才会生效。
配置文件方式 rabbitmq.conf
当前配置文件:/etc/rabbitmq/rabbitmq.conf
#默认
#vm_memory_high_watermark.relative = 0.4
# 使用relative相对值进行设置fraction,建议取值在04~0.7之间,不建议超过0.7.vm_memory_high_watermark.relative = 0.6
# 使用absolute的绝对值的方式,但是是KB,MB,GB对应的命令如下
vm_memory_high_watermark.absolute = 2GB
RabbitMQ的内存换页
在某个Broker节点及内存阻塞生产者之前,它会尝试将队列中的消息换页到磁盘以释放内存空间,持久化和非持久化的消息都会写入磁盘中,其中持久化的消息本身就在磁盘中有一个副本,所以在转移的过程中持久化的消息会先从内存中清除掉。默认情况下,内存到达的阈值是50%时就会换页处理。也就是说,在默认情况下该内存的阈值是0.4的情况下,当内存超过0.4*0.5=0.2时,会进行换页动作。比如有1000MB内存,当内存的使用率达到了400MB,已经达到了极限,但是因为配置的换页内存0.5,这个时候会在达到极限400mb之前,会把内存中的200MB进行转移到磁盘中。从而达到稳健的运行。
可以通过设置 vm_memory_high_watermark_paging_ratio 来进行调整
vm_memory_high_watermark.relative = 0.4
vm_memory_high_watermark_paging_ratio = 0.7(设置小于1的值)
为什么设置小于1,以为你如果你设置为1的阈值。内存都已经达到了极限了。你在去换页意义不是很大了。
RabbitMQ的磁盘预警
当磁盘的剩余空间低于确定的阈值时,RabbitMQ同样会阻塞生产者,这样可以避免因非持久化的消息持续换页而耗尽磁盘空间导致服务器崩溃。
默认情况下:磁盘预警为50MB的时候会进行预警。表示当前磁盘空间第50MB的时候会阻塞生产者并且停止内存消息换页到磁盘的过程。
这个阈值可以减小,但是不能完全的消除因磁盘耗尽而导致崩溃的可能性。比如在两次磁盘空间的检查空隙内,第一次检查是:60MB ,第二检查可能就是1MB,就会出现警告。
通过命令方式修改如下:
rabbitmqctl set_disk_free_limit <disk_limit>
rabbitmqctl set_disk_free_limit memory_limit <fraction>
disk_limit:固定单位 KB MB GB
fraction :是相对阈值,建议范围在:1.0~2.0之间。(相对于内存)
通过配置文件配置如下:
disk_free_limit.relative = 3.0
disk_free_limit.absolute = 50mb
十.ElasticSearch
配置跨域
#vim /config/elasticsearch.yml
http.cors.enabled: true
http.cors.allow-origin: "*"
ES核心概念
集群,节点,索引,类型,文档,分片,映射是什么?
elasticsearch是面向文档,关系型数据库和elasticsearch客观的对比!一切都是json
| Relational DB | Elasticsearch |
|---|---|
| 数据库(database) | 索引(index) |
| 表(tables) | 类型(types) |
| 行(rows) | 文档(documents) |
| 字段(columns) | fields |
物理设计:
elasticsearch在后台把每个索引划分成多个分片。每个分片可以在集群中的不同服务器间迁移
逻辑设计:
一个索引类型中,包含多个文档,当我们索引一篇文档时,可以通过这样的一个顺序找到它:索引=>类型=>文档id,通过这个组合我们就能索引到某个具体的文档。注意:ID不是整数,实际上它是一个字符串.
文档
就是我们的一条条的记录,之前说elasticsearch是面向文档的,那么就意味着索弓和搜索数据的最小单位是文档, elasticsearch中,文档有几个重要属性:
-
自我包含, - -篇文档同时包含字段和对应的值,也就是同时包含key:value !
-
可以是层次型的,-一个文档中包含自文档,复杂的逻辑实体就是这么来的! {就是一 个json对象! fastjson进行自动转换!}
-
灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在elasticsearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
尽管我们可以随意的新增或者忽略某个字段,但是,每个字段的类型非常重要,比如一一个年龄字段类型,可以是字符串也可以是整型。因为elasticsearch会保存字段和类型之间的映射及其他的设置。这种映射具体到每个映射的每种类型,这也是为什么在elasticsearch中,类型有时候也称为映射类型。
类型
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。类型中对于字段的定 义称为映射,比如name映射为字符串类型。我们说文档是无模式的 ,它们不需要拥有映射中所定义的所有字段,比如新增一个字段,那么elasticsearch是怎么做的呢?elasticsearch会自动的将新字段加入映射,但是这个字段的不确定它是什么类型, elasticsearch就开始猜,如果这个值是18 ,那么elasticsearch会认为它是整形。但是elasticsearch也可能猜不对 ,所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后再使用,别整什么幺蛾子。
索引
就是数据库!
索引是映射类型的容器, elasticsearch中的索引是一个非常大的文档集合。索|存储了映射类型的字段和其他设置。然后它们被存储到了各个分片上了。我们来研究下分片是如何工作的。
物理设计:节点和分片如何工作
一个集群至少有一 个节点,而一个节点就是一-个elasricsearch进程 ,节点可以有多个索引默认的,如果你创建索引,那么索引将会有个5个分片( primary shard ,又称主分片)构成的,每一个主分片会有-一个副本( replica shard ,又称复制分片)

上图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同-个节点内,这样有利于某个节点挂掉了,数据也不至于丢失。实际上, 一个分片是- -个Lucene索引, -一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。不过,等等,倒排索引是什么鬼?
倒排索引
elasticsearch使用的是一种称为倒排索引的结构,采用Lucene倒排索作为底层。这种结构适用于快速的全文搜索,一个索引由文
档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。 例如,现在有两个文档,每个文档包含如下内容:
Study every day, good good up to forever # 文 档1包含的内容
To forever, study every day,good good up # 文档2包含的内容
为创建倒排索引,我们首先要将每个文档拆分成独立的词(或称为词条或者tokens) ,然后创建一一个包含所有不重 复的词条的排序列表,然后列出每个词条出现在哪个文档.
例如:我们通过博客标签来搜索博客文章。那么倒排索引列表就是这样的一个结构:
| 博客文章(原始数据) | 博客文章(原始数据) | 索引列表(倒排索引) | 索引列表(倒排索引) |
|---|---|---|---|
| 博客文章ID | 标签 | 标签 | 博客文章ID |
| 1 | python | python | 1,2,3 |
| 2 | python | linux | 3,4 |
| 3 | linux,python | ||
| 4 | linux |
如果要搜索含有python标签的文章,那相对于查找所有原始数据而言,查找倒排索引后的数据将会快的多。只需要查看标签这一栏,然后获取相关的文章ID即可。完全过滤掉无关的所有数据,提高效率!
elasticsearch的索引和Lucene的索引对比
在elasticsearch中,索引(库)这个词被频繁使用,这就是术语的使用。在elasticsearch中 ,索引被分为多个分片,每份分片是-个Lucene的索引。所以一个elasticsearch索引是由多 个Lucene索引组成的。
Ik分词器
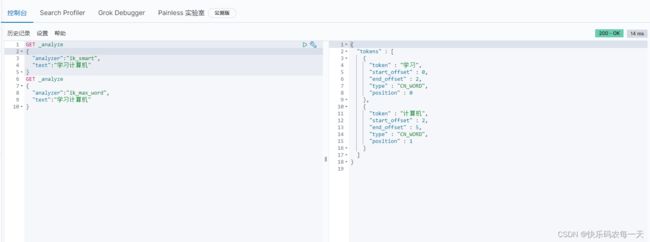
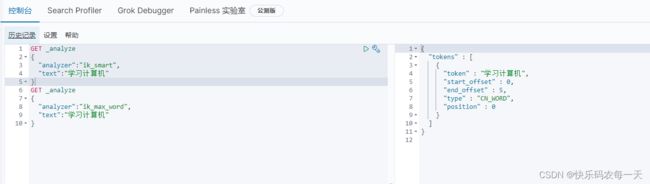
IK提供两种分词模式:最少切分和细粒度模式(最少切分:对应es的IK插件的ik_smart,细粒度:对应es的IK插件的ik_max_word)。
查看不同分词器效果
ik_smart
ik_max_word
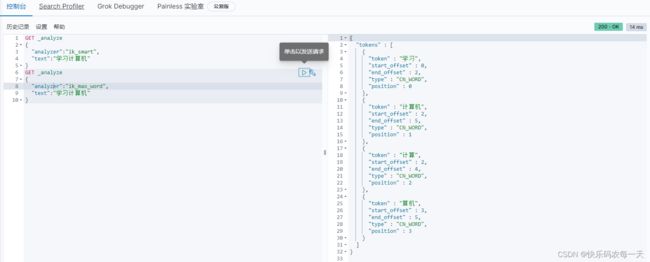
ik分词器字典配置
在ik\config\IKAnalyzer.cfg.xml中可以使用自定义的字典
学习计算机

加入字典后ik_smart测试结果:
命令模式的使用
ES数据类型

指定字段类型properties

未指定数据类型时,会有默认的数据类型

GET _cat/ 命令可以查看很多信息

Rest风格
一种软件架构风格,而不是标准。更易于实现缓存等机制
| method | url地址 | 描述 |
|---|---|---|
| PUT | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id),已存在会覆盖 |
| POST | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id),已存在会覆盖 |
| POST | localhost:9200/索引名称/_update/文档id | 修改文档 |
| DELETE | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET | localhost:9200/索引名称/类型名称/文档id | 通过文档id查询文档 |
| GET | localhost:9200/索引名称/_search | 查询所有的数据 |
添加
PUT /索引名/`类型名`(默认_doc)/文档id
{请求体}
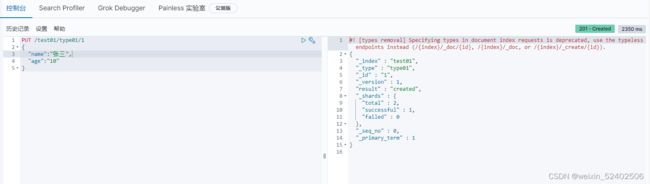 创建结果
创建结果
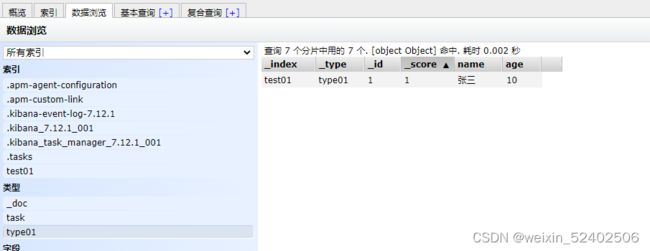
修改
方式一:PUT.POST (添加方式,覆盖)
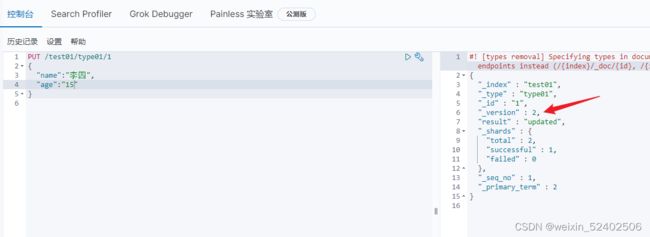
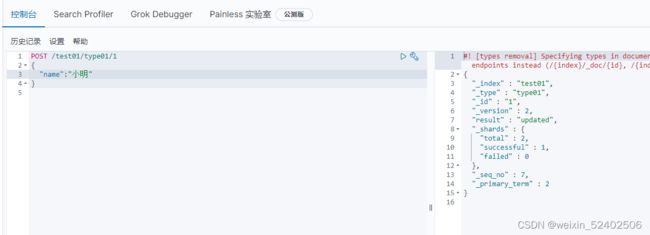
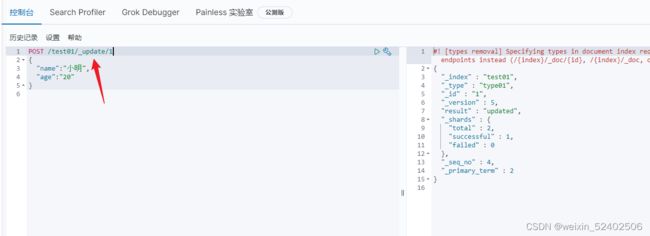
方式二:POST(空值不会覆盖)
删除

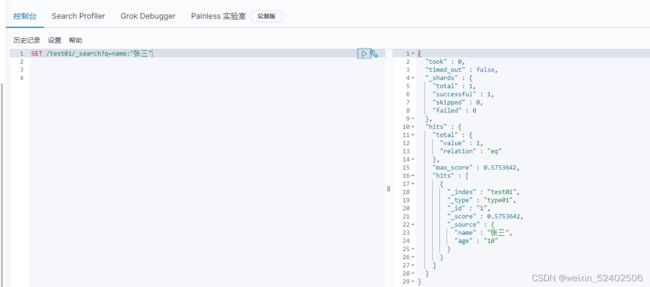
查询
复杂查询
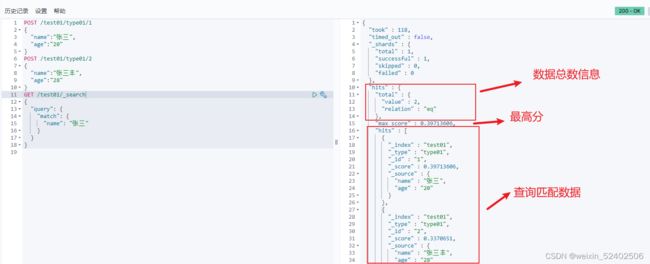
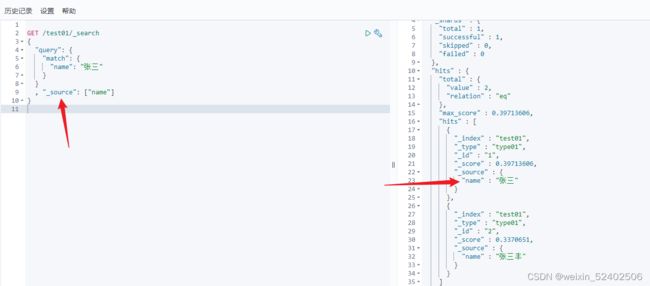
使用_source设置只查询哪些字段
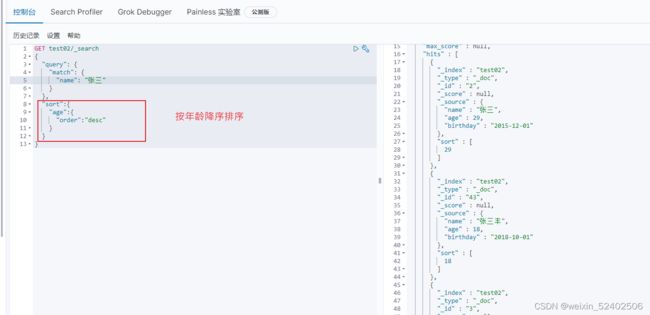
排序
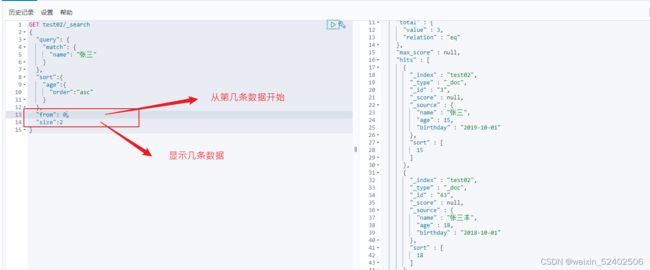
分页
bool查询
bool.must 相当于mysql中 where name="张三" and age=15
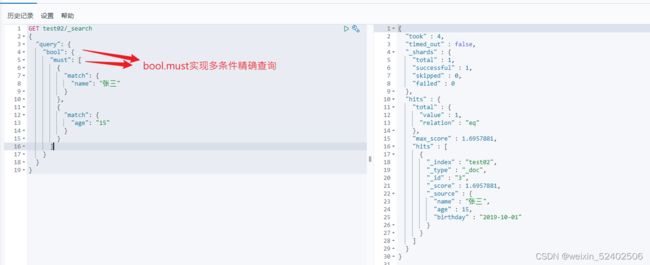
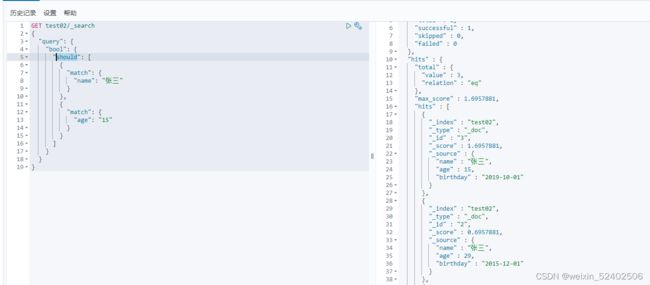
bool.should 相当于mysql中where name="张三" or age=15
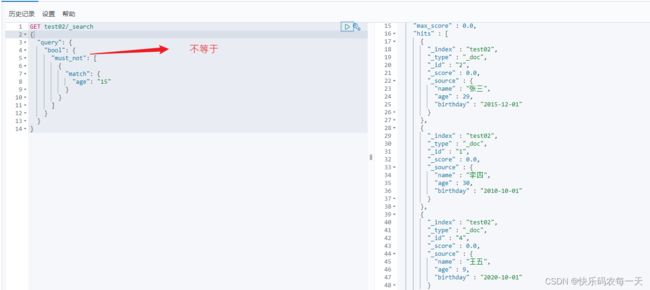
bool.must_not相当于mysql中where age!=15
bool.filter相当于mysql中where age between 10 and 20
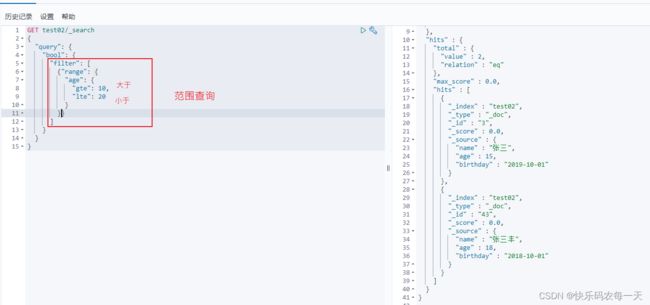
- gt 大于
- gte 大于等于
- lt 小于
- lte 小于等于
匹配多个条件(数组)

精确查询
term和match区别
- term ,直接精确查询(倒排索引)
- match,会使用分词器解析!(先分析文档,然后通过分析的文档进行查询)
使用term
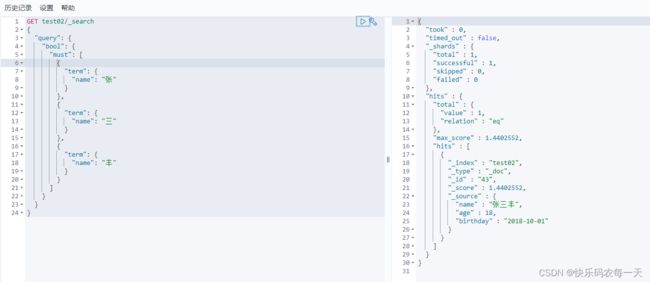
使用match

keyword 和 text 类型区别:
- keyword类型不会被分词器解析(查询时全文匹配)
- text类型会被分词器解析(查询时英文是一个单词进行匹配,中文是一个字进行匹配)
高亮
highlight实现搜索内容高亮
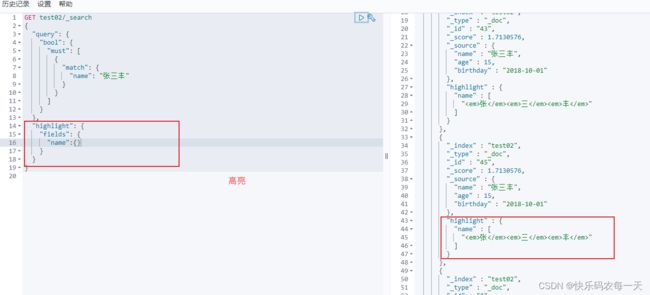
样式设置

SpringBoot集成Es
依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-elasticsearchartifactId>
dependency>
springboot版本低缺包
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-high-level-clientartifactId>
dependency>
设置es版本

config配置
@Configuration
public class ElasticSearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));
return client;
}
}
具体Api测试
@SpringBootTest
class HyhEsApiApplicationTests {
@Autowired
private RestHighLevelClient client;
//测试创建索引
@Test
void contextLoads() throws IOException {
//1.创建索引请求
CreateIndexRequest request = new CreateIndexRequest("hyh_index");
//2.客户端执行请求 IndicesClient,请求后获得响应
CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);
System.out.println(createIndexResponse);
}
//测试获取索引
@Test
void testExistIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("hyh_index");
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
//测试删除索引
@Test
void testDeleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("hyh_index");
AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);
System.out.println(delete.isAcknowledged());
}
//添加文档
@Test
void testAddDocument() throws IOException {
//创建对象
User user = new User("张三", 15);
//创建请求
IndexRequest request = new IndexRequest("hyh_index");
//规则
request.id("1")
//设置超时
.timeout(TimeValue.timeValueSeconds(1))
//.timeout("1s");
//将我们数据放入请求
.source(JSON.toJSONString(user), XContentType.JSON);
//客户端发送请求,获取响应结果
IndexResponse index = client.index(request, RequestOptions.DEFAULT);
System.out.println(index.toString()
+"\t"+index.status());//返回状态 CREATED
}
//获取文档,判断是否存在
@Test
void testIsExists() throws IOException {
GetRequest request = new GetRequest("hyh_index","1");
//不获取返回的_source的上下文
request.storedFields("_none_");
request.fetchSourceContext(new FetchSourceContext(false));
boolean exists = client.exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
//获得文档的信息
@Test
void testGetDocument() throws IOException {
GetRequest request = new GetRequest("hyh_index","1");
GetResponse getResponse = client.get(request, RequestOptions.DEFAULT);
System.out.println(getResponse.getSourceAsString());//打印文档的内容
System.out.println(getResponse);
}
//更新文档的信息
@Test
void testUpdateDocument() throws IOException {
UpdateRequest updateRequest = new UpdateRequest("hyh_index","1");
User user = new User("李四", 15);
updateRequest.doc(JSON.toJSONString(user),XContentType.JSON);
UpdateResponse update = client.update(updateRequest,RequestOptions.DEFAULT);
System.out.println(update.status());
}
//删除文档
@Test
void testDeleteDocument() throws IOException {
DeleteRequest request = new DeleteRequest("hyh_index","1");
DeleteResponse deleteResponse = client.delete(request, RequestOptions.DEFAULT);
System.out.println(deleteResponse.status());
}
//大批量插入
@Test
void testBulkRequest() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("10s");
ArrayList<User> users = new ArrayList<>();
users.add(new User("张三",10));
users.add(new User("李四",12));
users.add(new User("王五",45));
users.add(new User("梁志超",10));
users.add(new User("李强",56));
for (int i = 0; i <users.size() ; i++) {
bulkRequest.add(new IndexRequest("hyh_index")
.id(""+(i+1))
.source(JSON.toJSONString(users.get(i)),XContentType.JSON));
};
BulkResponse bulk = client.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println(bulk.hasFailures());//是否失败,false
}
//查询
@Test
void testSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest("hyh_index");
//构建搜索条件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//查询条件,我们可以使用 QueryBuilders 工具类来实现
//QueryBuilders.termQuery() 精确查询
//QueryBuilders.matchAllQuery() 匹配所有
//QueryBuilders.matchQuery() 使用match分词器查询
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", "张");
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("name", "张");
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
sourceBuilder.query(matchAllQueryBuilder)
//设置超时
.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(JSON.toJSONString(searchResponse.getHits()));
System.out.println("============================");
for (SearchHit hit : searchResponse.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}
}
十一.Dubbo
依赖
<dependency>
<groupId>org.apache.dubbogroupId>
<artifactId>dubbo-spring-boot-starterartifactId>
<version>2.7.3version>
dependency>
<dependency>
<groupId>com.github.sgroschupfgroupId>
<artifactId>zkclientartifactId>
<version>0.1version>
dependency>
<dependency>
<groupId>org.apache.curatorgroupId>
<artifactId>curator-frameworkartifactId>
<version>2.12.0version>
dependency>
<dependency>
<groupId>org.apache.curatorgroupId>
<artifactId>curator-recipesartifactId>
<version>2.12.0version>
dependency>
<dependency>
<groupId>org.apache.zookeepergroupId>
<artifactId>zookeeperartifactId>
<version>3.4.14version>
<exclusions>
<exclusion>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
exclusion>
exclusions>
dependency>
生产者配置
#注册中心应用名
dubbo.application.name=provider-server
#注册中心地址
dubbo.registry.address=zookeeper://127.0.0.1:2181
#那些服务被注册
dubbo.scan.base-packages=com.hyh.service
消费者配置
#消费者拿服务,需要暴露自己的名字
dubbo.application.name=consumer-server
#注册中心地址
dubbo.registry.address=zookeeper://127.0.0.1:2181
步骤
- 生产者提供服务
- 导入依赖
- 配置注册中心的地址,以及服务发现名,和要扫描的包
- 在想要被注册的服务上面,增加@Service注解
- 消费者进行消费
- 导入依赖
- 配置注册中心地址,配置自己的服务名
- 从远程注入服务@Reference
生产者接口
package com.hyh.service;
public interface TicketService {
public String getTicket();
}
生产者实现
package com.hyh.service.impl;
import com.hyh.service.TicketService;
import org.apache.dubbo.config.annotation.Service;
import org.springframework.stereotype.Component;
@Service //可以被扫描到,在项目一启动就自动注册到注册中心
@Component //使用了dubbo尽量不要用service
public class TicketServiceImpl implements TicketService {
@Override
public String getTicket() {
return "hello Dubbo";
}
}
消费者接口
package com.hyh.service;
public interface TicketService {
public String getTicket();
}
消费者实现
package com.hyh.service.impl;
import com.hyh.service.TicketService;
import org.apache.dubbo.config.annotation.Reference;
import org.springframework.stereotype.Service;
@Service //放到容器中
public class UserService {
//去注册中心拿到服务
@Reference//引用, pom 坐标,可以定义路径相同的接口名
TicketService ticketService;
public void buyTicket(){
String ticket = ticketService.getTicket();
System.out.println("在注册中心拿到了服务====>"+ticket);
}
}
测试
@SpringBootTest
class ConsumerServerApplicationTests {
@Autowired
UserService userService;
@Test
void contextLoads() {
userService.buyTicket(); //结果: 在注册中心拿到了服务====>hello Dubbo
}
}
十二.Hutool
导出Excel
