初识HBase
1. HBase简介
Apache HBase™ is the Hadoop database, a distributed, scalable, big data store.
HBase is a type of "NoSQL" database.
HBase 是一个分布式、可伸缩的Hadoop 数据库,HBase是在HDFS(分布式文件系统)的基础之上构建的,所以HBase能存储海量的数据。
HBase是一个NoSQL数据库,一般用它来存储海量的数据;
HBase的一行记录由一个RowKey和一个或多个的列以及对应的值所组成。先有列族后有列,列可以随意添加;
HBase的增删改记录都有「版本」,默认以时间戳的方式实现;
RowKey的设计如果没有特殊的业务性,最好设计为散列的,这样避免热点数据分布在同一个HRegionServer中;
HBase的读写都经过Zookeeper去拉取meta数据,定位到对应的HRegion,然后找到HRegionServer。
2. 为什么要用HBase
2.1 一些常见组件的不足
1. MySQL
单机的,能存储多少数据取决于那台服务器的硬盘大小。
2. 缓存数据库 Redis
所有的读写都在内存中,速度贼快,AOF/RDB存储的数据都会加载到内存中,但不适合存大量的数据(内存太贵!)。
3. 分布式消息队列 Kafka
Kafka主要用来处理消息的(解耦异步削峰)。它将数据顺序写到磁盘,理论上可以存储很大的数据,但Kafka的数据我们不会单独取出来。
持久化了的数据,最常见的用法就是重新设置offset,做回溯操作。
4. 分布式搜索引擎 Elasticsearch
ES会把数据写到translog然后结合FileSystemCache将数据刷到磁盘中,理论上可以存储海量的数据。但ES主要用于检索(将数据用『索引』取出来),一般存储有经常「检索」需求的数据,(数据写入ES需要分词,会浪费资源)。
5. 分布式文件系统 HDFS
HDFS是可以存储海量数据,但有明显的缺点:不支持随机修改,查询效率低,对小文件支持不友好。
这些中间件(大数据组建2-5)基本都会有持久化的功能。
2.2 HBase的优势
HBase在HDFS之上提供了高并发的随机写和支持实时查询。
1. 以低成本来存储海量的数据并且支持高并发随机写和实时查询;
2. 存储数据的”结构“非常灵活,一个列族下可以任意添加列,不受任何限制。
3. HBase基础
HBase的列式存储和Key-Value结构:将数据列全部拆开,每行只存储有值的列(空缺列无需存储),存储空间利用率非常高。

3.1 HBase的数据模型
一行数据由一个行键(RowKey)和一个或多个相关的列以及它的值所组成。HBase的列(Column)都得归属到列族(Column Family)中,用列修饰符(Column Qualifier)来标识每一列。
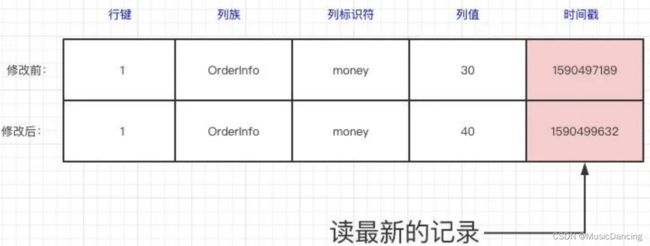
数据写到HBase的时候都会被记录一个时间戳,这个时间戳被当做一个版本。修改或删除某一条的时候,本质上是往里边新增一条数据,记录的版本加一了而已。比如现在要把这条记录的值改为40,实际上就是多添加一条记录,在读的时候按照时间戳读最新的记录。在外界「看起来」就是把这条记录改了。
3.2 HBase 的Key-Value
HBase本质上是Key-Value的数据库,Key由RowKey(行键) + ColumnFamily(列族) + Column Qualifier(列修饰符) + TimeStamp(时间戳--版本) + KeyType(类型)组成,而Value就是实际上的值。
修改一条数据实际是在原来的基础上增加一个版本,而准确定位一条数据,那就得使用“RowKey+Column+时间戳” 组合。
删除一条数据,实际上也是增加一条记录,在KeyType中设置为“Delete”就可以了。
3.3 HBase架构
整体流程:
Client发请求到Zookeeper,由Zookeeper返回HRegionServer地址给Client,Client根据返回的地址去请求HRegionServer,HRegionServer读写数据后返回给Client。

1. Client客户端:提供了访问HBase的接口,并且维护了对应的cache来加速HBase的访问。
2. Zookeeper: 存储HBase的元数据(meta表),无论是读还是写数据,都是去Zookeeper里边拿到meta元数据告诉给客户端去哪台机器读写数据。
3. HRegionServer: 处理客户端的读写请求,负责与HDFS底层交互,是真正干活的节点。
HBase的架构图:
3.4 HRegionServer内部结构

HBase通过RowKey横向切割表,实现将一张表的数据分到多台机器上。
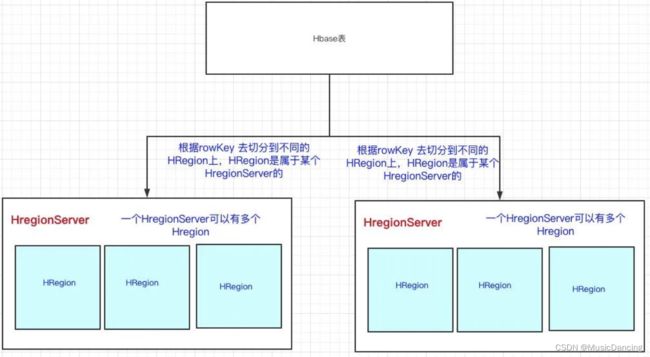
3.4.1 HRegion
在一个HRegion上,存储HBase表的一部分数据。HRegion里边会有多个Store,每个Store存储一个列族的数据(HBase是基于列族存储的)。

Store里有:Mem Store、Store File(HFile)。在写数据的时候,会先写到Mem Store,当Mem Store超过一定阈值,就会将内存中的数据刷写到硬盘上,形成Store File,而Store File底层是以HFile的格式保存,HFile是HBase中KeyValue数据的存储格式。
Mem Store可以理解为内存 buffer,HFile是HBase实际存储的数据格式,而Store File只是HBase里的一个名字。其实就是先走一层内存,然后再刷到磁盘的结构。
3.4.2 HLog
写数据时先写到内存(Mem store),为了防止机器宕机,内存的数据没刷到磁盘中就挂了,还会写一份到HLog,这个HLog是顺序写到磁盘的,所以速度还是挺快的。
3.5 HMaster
Hamster会处理 HRegion 的分配或转移(但读写请求都没经过HMaster)。如果HRegion的数据量太大,HMaster会对拆分后的Region重新分配RegionServer;如果发现失效的HRegion,也会将失效的HRegion分配到正常的HRegionServer中。
HMaster会处理元数据的变更和监控RegionServer的状态。
4. RowKey的设计
RowKey行键要保证是唯一的,在HBase里边提供了三种的查询方式:
全局扫描;
根据一个RowKey进行查询;
根据RowKey过滤的范围查询。
4.1 根据一个RowKey查询
RowKey是按字典序排序的,HBase用RowKey来横向切分表。无论读写都是用RowKey去定位到HRegion,然后找到HRegionServer。
1. 怎么知道这个RowKey是在这个HRegion上的?
HRegion上有两个很重要的属性:
start-key和end-key。在定位HRegionServer的时候,实际上就是定位这个RowKey在不在这个HRegion的start-key和end-key范围之内,如果在,说明就找到了。
2. 热点数据问题:
由于RowKey是以字典序排序的,如果没有做任何处理,那就有可能存在热点数据的问题。
一个例子,RowKey如下:
zz111
zz222
zz333
aaa
bbb
zz444
zz555...
zz开头的RowKey很多,而其他的RowKey很少。如果我们有多个HRegion的话,那么存储zz的HRegion的数据量是最大的,而分配给其他的HRegion数量是很少的。关键是我们的查询也几乎都是以zz的数据去查,这会导致某部分数据会集中在某台HRegionServer上存储以及查询,而其他的HRegionServer却很空闲。
解决方案:
对RowKey散列,分配到HRegion时就比较均匀,少了热点的问题。
3. HBase优化手册
建表申请时(HBase管理平台里申请HBase表)的预分区设置。
(1) 自己指定RowKey的分割点来划分region个数
如果对于RowKey的组成及数据分布非常清楚的话,可以使用这种方式精确预分区。比如有一组数据RowKey为[1,2,3,4,5,6,7],此时给定split RowKey是3,6;那么就会划分为[1,3), [3,6), [6,7)的三个初始region了。
(2) 指定始末的RowKey和大致的region数
startKey=00000000,
endKey=xxxxxxxx,
regionsNum=x
如果只知道RowKey的组成大致的范围,可以选用这种方式让集群来均衡预分区,一般region数最多不要超过集群的rs节点数,过多region数不但不能增加表访问性能,反而会增加master节点压力。如果给定始末RowKey范围与实际偏差较大的话,还是比较容易产生数据热点问题。
(3)生成RowKey时,尽量进行加盐或者哈希处理,很大程度上可以缓解数据热点问题。
4.2 根据RowKey范围查询
HBase将RowKey设计为字典序排序,如果不做限制,那很可能类似的RowKey存储在同一个HRegion中。如果正好有这个场景上的业务,那我在同一个HRegion就可以拿到想要的数据了。
一个例子:
我们会间隔几秒就采集直播间热度,将这份数据写到HBase中,然后业务方经常要把主播的一段时间内的热度给查询出来。
计好的RowKey,将该主播的一段时间内的热度都写到同一个HRegion上,拉取的时候只要访问一个HRegionServer就可以得到全部我想要的数据了,那查询的速度就快很多。