python网页爬虫漫画案例_Python爬虫 JS 案例讲解:爬取漫画
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
以下文章来源于Python爬虫案例,作者麦自香
转载地址
https://blog.csdn.net/fei347795790?t=1

由于今天涉及的内容颇多,还请各位看官搬上小板凳,带上香瓜子,慢慢细品,话不多说,第一步还是上链接,作为我们的目标网站,首先把链接贴出来,如下:
https://ac.qq.com/
由于最终的目的是为了爬取漫画的内容页,所以开门见山直接找一个漫画进行页面分析,(该文章主要用于爬取免费的漫画,收费请看代码注释),我们以《尸兄》第一话为例:
https://ac.qq.com/ComicView/index/id/17114/cid/3
按F12进行元素审查,通过往下滑动可以看到图片不断的加载出来,所以内容可能是动态加载出来的。
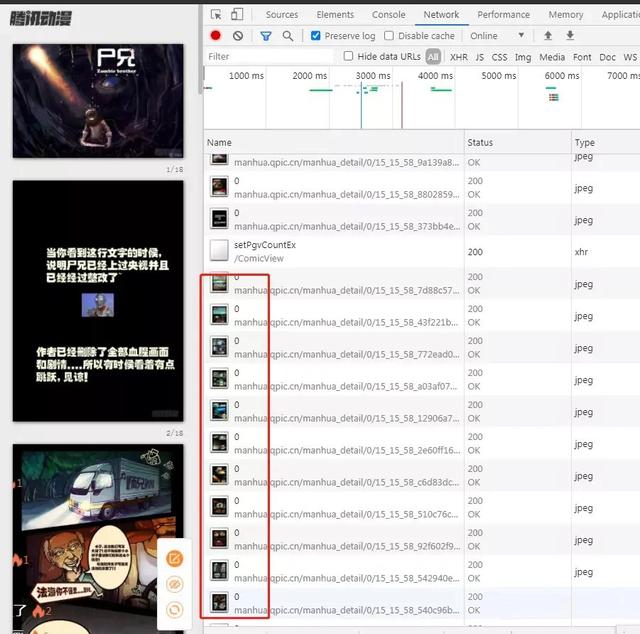
页面动态加载内容的话,此时让我们切换到XHR标签,如图:
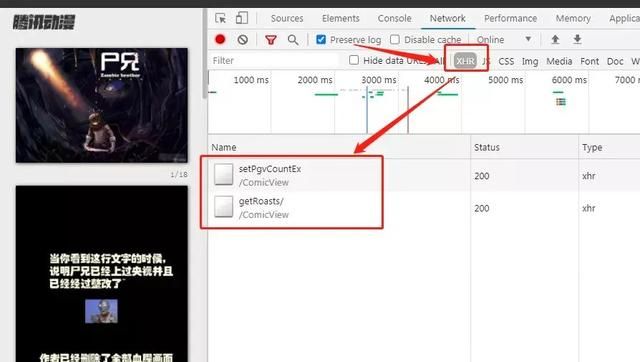
通过分析过后,我们发现这两个接口,除了返回的有弹幕外,其他的什么数据都没有返回,所以数据并不是通过此处返回的。
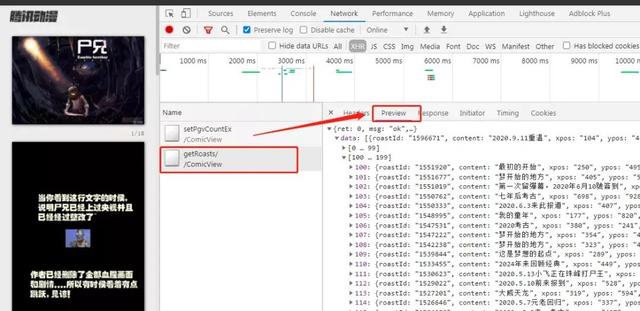
没办法,看来不是从这请求的数据,接下来让我们找一个图片的名称进行全局搜索,看看哪些文件夹里面包含了这些名称。以便确定数据到底存放在了哪里。
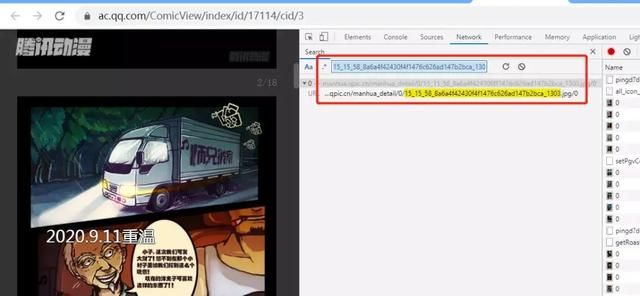
通过进行的全局搜索,我们发现除了只能搜到这个图片,也没发现其他的文件内有存储该图片的位置,说明这个方法也是行不通的。图片的地址既没有动态加载,也没有在其他的源代码中,那么只能说明地址是被加密放到了某一个地方。除去图片,js,css这些,剩下有可能的就只有主页了,所以直接看主页的源代码,并且主要关注script标签下的内容,整个主页的源代码中,有可能存放加密数据的就只有倒数后面的一个script标签。
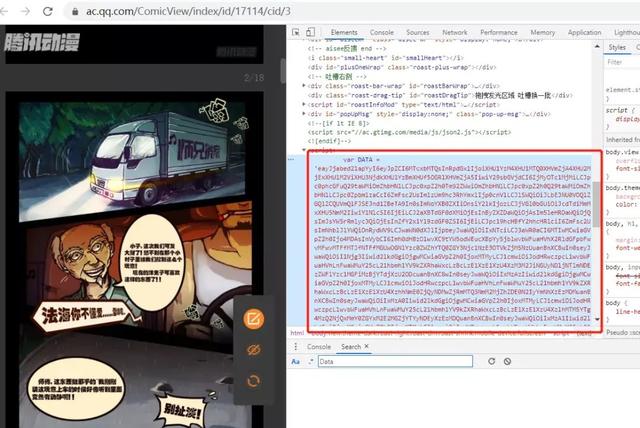
从页面的内容来看,DATA变量很有可能就是加密的数据,此时需要查找如何解密这段数据,继续在全局中搜索DATA,并且区分大小写。
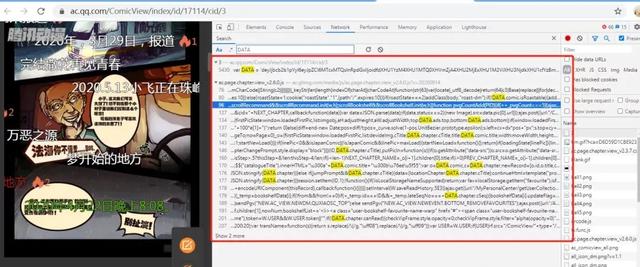
由此可以看到除了自身以外,就剩下一个js文件内有出现过DATA变量,那么进入到这个js文件里面继续搜索DATA,并且同样需要区分大小写。
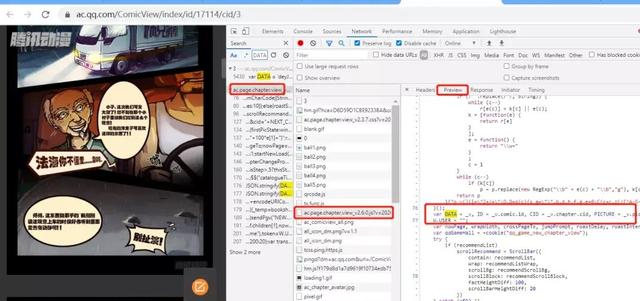
搜索后发现“那个村的王富贵”还是蛮多的,浏览一遍发现,除了第一个以外,其他都是取DATA变量的值,说明关键在第一个DATA变量,因为还没有解密又怎么取值呢。直接在第一次出现DATA变量的那一行打上断点,然后刷新。
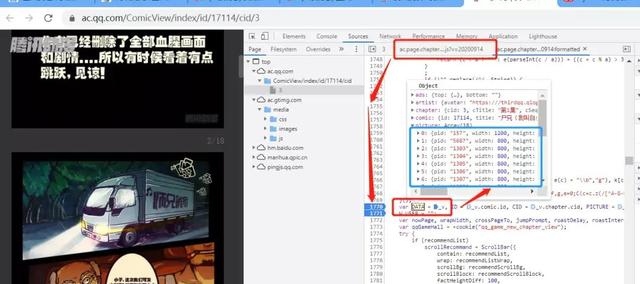
如上图,可以看到所有的图片地址都在_v变量的下面,继续在全局中搜索_v变量,也是要区分大小写。
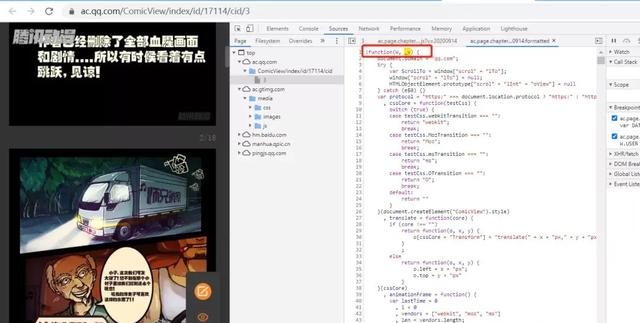
搜索到13个内容,简单的过了一遍,发现除了取值,函数变量以及一些其他的字符串包含这个,剩下的一个在第一个DATA变量上面的立即执行函数里面。
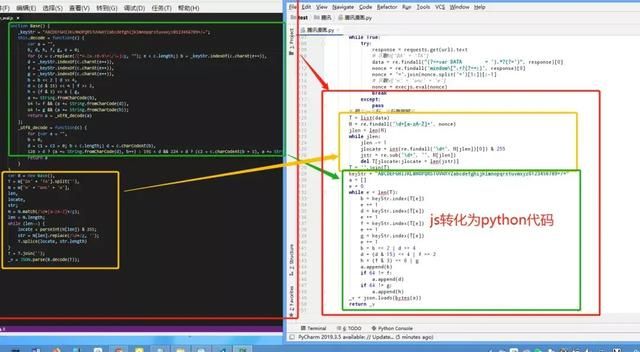
1eval(function(p, a, c, k, e, r) {2 e =function(c) {3 return (c < a ? "" : e(parseInt(c / a))) + ((c = c % a) > 35 ? String.fromCharCode(c + 29) : c.toString(36))4}5;6 if (!"".replace(/^/, String)) {7 while (c--)8 r[e(c)] = k[c] ||e(c);9 k =[function(e) {10 returnr[e]11}12];13 e =function() {14 return "\\w+"
15}16;17 c = 1
18}19 while (c--)20 if(k[c])21 p = p.replace(new RegExp("\\b" + e(c) + "\\b","g"), k[c]);22 returnp23 }("p y(){i=\"J+/=\";O.D=p(c){s a=\"\",b,d,h,f,g,e=0;C(c=c.z(/[^A-G-H-9\\+\\/\\=]/g,\"\");e>4,d=(d&15)<<4|f>>2,h=(f&3)<<6|g,a+=7.5(b),w!=f&&(a+=7.5(d)),w!=g&&(a+=7.5(h));v a=u(a)};u=p(c){C(s a=\"\",b=0,d=17=8=0;bd?(a+=7.5(d),b++):Rd?(8=c.o(b+1),a+=7.5((d&F)<<6|8&r),b+=2):(8=c.o(b+1),x=c.o(b+2),a+=7.5((d&15)<<12|(8&r)<<6|x&r),b+=3);v a}}s B=I y(),T=W['K'+'L'].M(''),N=W['n'+'P'+'e'],j,t,q;N=N.U(/\\d+[a-V-Z]+/g);j=N.k;X(j--){t=Y(N[j])&10;q=N[j].z(/\\d+/g,'');T.11(t,q.k)}T=T.13('');14=16.E(B.D(T));", 62, 70, "|||||fromCharCode||String|c2||||||||||_keyStr|len|length|indexOf|charAt||charCodeAt|function|str|63|var|locate|_utf8_decode|return|64|c3|Base|replace|||for|decode|parse|31|Za|z0|new|ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789|DA|TA|split||this|onc|128|191|224||match|zA||while|parseInt||255|splice||join|_v||JSON|c1".split("|"), 0, {}))
接着先将这一段立即执行函数解密一下,使用的是 ~解密网址~ ,可以得到下面的js代码。
1#解密网址
2#https://wangye.org/tools/scripts/eval/
3function Base() {4 _keyStr = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=";5 this.decode =function(c) {6 var a = "",7 b, d, h, f, g, e =0;8 for (c = c.replace(/[^A-Za-z0-9\+\/\=]/g, ""); e < c.length;) b = _keyStr.indexOf(c.charAt(e++)),9 d = _keyStr.indexOf(c.charAt(e++)),10 f = _keyStr.indexOf(c.charAt(e++)),11 g = _keyStr.indexOf(c.charAt(e++)),12 b = b << 2 | d >> 4,13 d = (d & 15) << 4 | f >> 2,14 h = (f & 3) << 6 |g,15 a +=String.fromCharCode(b),16 64 != f && (a +=String.fromCharCode(d)),17 64 != g && (a +=String.fromCharCode(h));18 return a =_utf8_decode(a)19};20 _utf8_decode =function(c) {21 for (var a = "",22 b =0,23 d = c1 = c2 = 0; b < c.length;) d =c.charCodeAt(b),24 128 > d ? (a += String.fromCharCode(d), b++) : 191 < d && 224 > d ? (c2 = c.charCodeAt(b + 1), a += String.fromCharCode((d & 31) << 6 | c2 & 63), b += 2) : (c2 = c.charCodeAt(b + 1), c3 = c.charCodeAt(b + 2), a += String.fromCharCode((d & 15) << 12 | (c2 & 63) << 6 | c3 & 63), b += 3);25 returna26}27}
28var B=new Base(),
29T= W['DA' + 'TA'].split(''),
30N= W['n' + 'onc' + 'e'],
31len,
32locate,
33str;
34N= N.match(/\d+[a-zA-Z]+/g);
35len=N.length;
36while (len--) {37 locate = parseInt(N[len]) & 255;38 str = N[len].replace(/\d+/g, '');39T.splice(locate, str.length)40}
41T= T.join('');
42_v= JSON.parse(B.decode(T));
由此可以看出第40行就是解密后的_v变量,第27行就是我们前面的DATA加密数据,那么可以肯定这段就是关键的解密函数,分析一下这段代码。
_v是调用了B的decode方法,传入的参数是T,然后T又是从前面T参数和N参数计算出来的,那么我们在console界面分别输入W['DA' + 'TA'],W['n' + 'onc' + 'e'],其中W['DA' + 'TA']就是前面的DATA加密数据,W['n' + 'onc' + 'e']可以在主页源代码中找到。
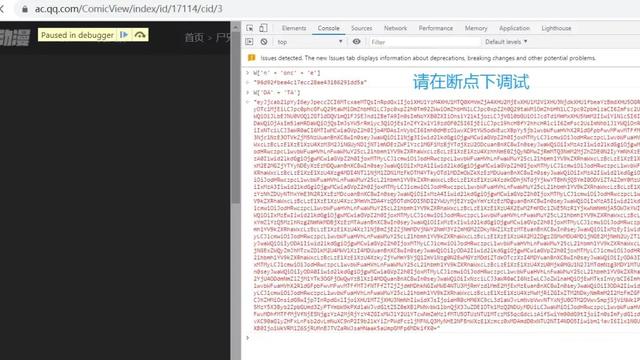
先初步尝试获取这两个数据
1defgetdata():2 importrequests3 importre4 url = 'https://ac.qq.com/ComicView/index/id/17114/cid/3'
5 response =requests.get(url).text6 data = re.findall("(?<=var DATA = ').*?(?=')", response)[0]7 nonce = re.findall('window\[".+?(?<=;)', response)[0]8 nonce = '='.join(nonce.split('=')[1:])[:-1]9 print(data)10 print(nonce)
但是nonce还是一段js代码,而不是字符串。在这我们使用execjs模块来计算,首先安装模块:
1#未安装该模块请先安装
2#pip install PyExecJS
34defgetdata():5 importrequests6 importre7 importexecjs8 url = 'https://ac.qq.com/ComicView/index/id/531490/cid/1'
9 response =requests.get(url).text10 data = re.findall("(?<=var DATA = ').*?(?=')", response)[0]11 nonce = re.findall('window\[".+?(?<=;)', response)[0]12 nonce = '='.join(nonce.split('=')[1:])[:-1]13 nonce =execjs.eval(nonce)14 print(data)15 print(nonce)
此时成功获取两个参数,然后根据js代码,那么在这里我们只需要把上面的js函数转写为python代码就可以成功的完成取参了,此时解密后的地址都是_v变量里面了。
1importrequests
2importre
3importexecjs
4importjson56defgetdata():7
8 url = 'https://ac.qq.com/ComicView/index/id/17114/cid/3'
9 whileTrue:10 try:11 response =requests.get(url).text12 data = re.findall("(?<=var DATA = ').*?(?=')", response)[0]13 nonce = re.findall('window\[".+?(?<=;)', response)[0]14 nonce = '='.join(nonce.split('=')[1:])[:-1]15 nonce =execjs.eval(nonce)16 break
17 except:18 pass
19 T =list(data)20 N = re.findall('\d+[a-zA-Z]+', nonce)21 jlen =len(N)22 whilejlen:23 jlen -= 1
24 jlocate = int(re.findall('\d+', N[jlen])[0]) & 255
25 jstr = re.sub('\d+', '', N[jlen])26 del T[jlocate:jlocate +len(jstr)]27 T = ''.join(T)28 keyStr = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/="
29 a =[]30 e =031 while e
34 d =keyStr.index(T[e])35 e += 1
36 f =keyStr.index(T[e])37 e += 1
38 g =keyStr.index(T[e])39 e += 1
40 b = b << 2 | d >> 4
41 d = (d & 15) << 4 | f >> 2
42 h = (f & 3) << 6 |g43a.append(b)44 if 64 !=f:45a.append(d)46 if 64 !=g:47a.append(h)48 _v =json.loads(bytes(a))49 print(_v)
解密步骤如下: