吴恩达机器学习:聚类与降维 (K-means & PCA)总结与作业
聚类与降维
-
- (一)聚类:简介K均值算法( K-Means Algorithm )
-
- 1.1 K-Means优化
- 1.2 随机初始化
- 1.3 选择聚类数
- (二)K-means聚类作业
-
- 2.1 计算K-均值
-
- 2.1.1 寻找最近的质心
- 2.1.2计算质心平均值
- 2.1.3可视化处理
- 2.2寻找最优K
-
- 2.2.1随机初始化
- 2.2.2 中心点的选择
- 2.2.3 决定聚类数K
- (三) 用scikit-learn学习K-Means聚类
-
- 3.1 参数介绍
- 3.2 K值的评估标准
- 3.3 K-Means应用实例
- 3.4 作业: 使用 k-means 压缩图像
- (四)降维:简介PCA
-
- 4.1 PCA 的思想
- 4.2 PCA 的步骤
- 4.3 PCA反向压缩——原始数据重现
- 4.4 如何选择主成分的数量
- (五)PCA降维实现
-
- 5.1 测试PCA将数据从2D减少到1D
- 5.2 PCA降维
- 5.3 PCA处理人脸图像数据
(一)聚类:简介K均值算法( K-Means Algorithm )
聚类算法将样本聚类分成不同的簇(cluster),其中K-means是最普及的一种聚类算法,它的思想其实就是迭代,假设我们想要将数据聚类成k个簇,其步骤为:
-
首先选择K个随机的点,称为聚类中心(cluster centroids);(如图a,b,以K=2为例)
-
对于数据集中的每个点,按照与聚类中心的距离,将其与距离最近的聚类中心点聚成一类;(如图c)
-
计算每一个组的平均值(重心位置),将该组所关联的中心点移动到平均值的位置;(如图d)
重复步骤 2、3 直至中心点不再变化(即算法收敛)。(图e,f为第二轮迭代)

K-means属于无监督的学习,事先不知道类别,自动将相似的对象归到同一个簇中的算法。
1.1 K-Means优化
在大多数我们已经学到的 监督学习算法中。 算法都有一个优化目标函数(代价函数),需要通过算法进行最小化 。
K均值的优化目标为:
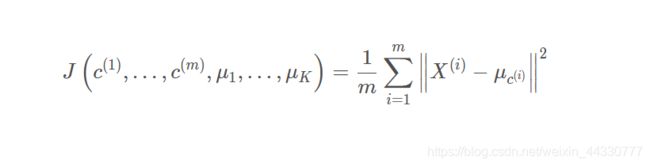 其中:
其中:
c(i) 表示当前样本点 x ( i ) x^{(i)} x(i)对应聚类中心的索引;
μ k \mu_k μk表示第 k 个聚类中心;
μ c ( i ) \mu_{c^{(i)}} μc(i) 代表与样本点 x ( i ) x^{(i)} x(i)最近的聚类中心点。
理解公式我们可以发现,k均值的优化目标就是让每一个样本点找到最优的聚类中心。 找出使得代价函数最小的 c ( 1 ) , c ( 2 ) , … , c ( m ) c^{(1)}, c^{(2)}, \ldots, c^{(m)} c(1),c(2),…,c(m) 和 μ 1 , μ 2 , … , μ K \mu_{1}, \mu_{2}, \ldots, \mu_{K} μ1,μ2,…,μK 即:
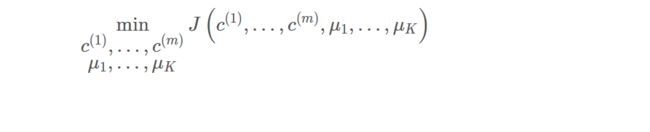
1.2 随机初始化
在运行K-均值算法的之前,我们首先要随机初始化所有的聚类中心点:
-
应该选择 K < m ,即聚类中心点的个数要小于所有训练集实例的数量;
-
随机选择 K 个样本点作为初始聚类中心。
K-均值的一个问题在于,不同的初始化位置会有不同的聚类结果,而且结果有可能会停留在一个局部最小值处,而这取决于初始化的情况。如下图三种随机初始化:

而解决方法是多次初始化聚类中心,然后计算K-Means的代价函数,根据代价函数的大小选择最优解。

缺点不足:这种方法在较小的时候还是可行的,但是如果 K 较大,这么做也可能不会有明显地改善。
1.3 选择聚类数
了解了算法原理后,面对实际问题时,我们怎么决定聚类数呢?K=?
改变 K 值,获得不同 K值和代价函数最小值的关系曲线:

理想情况下我们可能会得到图中类似 “肘部” 的额曲线,该处的 K 值即为最佳聚类数。
但是实际情况却是像由下图那样,曲线较为平滑,无法判断哪里是 “肘部”。
因此,没有所谓最好的选择聚类数的方法,通常是需要根据不同的问题需求,人工进行选择的。选择的时候思考我们运用K-均值算法聚类的动机是什么,然后选择能最好服务于该目的标聚类数。
使用注意:
K-Means算法需要用初始随机种子点来搞,这个随机种子点太重要,不同的随机种子点会有得到完全不同的结果。(K-Means++算法可以用来解决这个问题,其可以有效地选择初始点)
(二)K-means聚类作业
数据来源:
 尝试实现K-means算法,并使用它来压缩图像。
尝试实现K-means算法,并使用它来压缩图像。
给定一个二维数据集,使用kmeans进行聚类。
首先准备必要的库:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import scipy.optimize as opt
from scipy.io import loadmat
2.1 计算K-均值
2.1.1 寻找最近的质心
在K-means算法的分配簇的阶段,算法将每一个训练样本 x ( i ) x^{(i)} x(i) 分配给最接近的簇中心。对于每一个例子 i 都设为:
c ( i ) : = k t h a t m i n i m i z e s ∥ x ( i ) − μ k ∥ 2 c^{(i)}:=k that minimizes∥ x^{(i)}−\mu _{k}∥^{2} c(i):=kthatminimizes∥x(i)−μk∥2
其中, c ( i ) c^{(i)} c(i) 是最靠近 x ( i ) x^{(i)} x(i) 簇的索引(即聚类中心), μ k \mu _{k} μk 是第 k 个聚类中心点的位置(值)。
定义函数:输入训练点和几个中心,得到这些点分别离哪个中心最近:
def findClosestCentroids(X, centroids):
idx = []
for i in range(len(X)):
minus = X[i] - centroids #X[i]是(1,2),然而centroids是三个点即(3,2),这里做减法的话X直接自动变成三行再减,结果是(3,2)
dist = minus[:,0]**2 + minus[:,1]**2 #将(3,2)的每行求平方和,生成一维含三个数的array,这三个数是分别到三个中心的平方和
ci = np.argmin(dist) #获取dist最小值的索引,即哪个中心离该样本最近
idx.append(ci)
return np.array(idx) #最后输出一个array,里面是这所有的训练集的点分别离哪个中心最近
mat = loadmat('D:\机器学习\作业\K-means和PCA主成分分析\数据文件\ex7data2.mat') # print(mat.keys())查看一下
X = mat['X']
init_centroids = np.array([[3, 3], [6, 2], [8, 5]]) #随便定义三个中心
idx = findClosestCentroids(X, init_centroids)
print(idx[0:3])
详细解释见代码标注
运行结果:[0 2 1]
2.1.2计算质心平均值
将分配好每一个数据对应的聚类中心后,第二阶段是需要重新计算每个聚类中心,该值为这个聚类中心所有点位置的均值。对于每一个聚类中心 k 都设为:
μ ( k ) : = 1 ∣ C k ∣ ∑ i ∈ C k x ( i ) μ^{(k)}:=\frac{1}{∣Ck∣} \sum_{i∈C_{k}}^{}x(i) μ(k):=∣Ck∣1i∈Ck∑x(i)
其中, C k C_{k} Ck 分配给聚类中心 k 的样本集。
定义函数:重新计算中心,为该中心所有点坐标的平均值(比如如果上一步所有点都是离2中心最近,那么这步的结果就是nan。中心初始化还是有些点不行的):
def computeCentroids(X, idx):
centroids = []
for i in range(len(np.unique(idx))): # np.unique()是idx里除去重复的有哪些,得到0,1,2即那三个k
u_k = X[idx==i].mean(axis=0) # 求每列的平均值。X[idx==1]的意思就是X[idx里等于1的索引]。idx本身是可以与X没有关联的
centroids.append(u_k)
return np.array(centroids)
computeCentroids(X, idx)
2.1.3可视化处理
将样本分配给最近的簇并重新计算簇的聚类中心。画图,不同颜色代表不同簇的分类,以及画出中心点移动轨迹:
def plotData(X, centroids, idx=None):
colors = ['b','g','gold','darkorange','salmon','olivedrab',
'maroon', 'navy', 'sienna', 'tomato', 'lightgray', 'gainsboro'
'coral', 'aliceblue', 'dimgray', 'mintcream', 'mintcream'] #这行和下面那行就是检查颜色够不够用而已
assert len(centroids[0]) <= len(colors), 'colors not enough '
subX = [] # 分号类的样本点
if idx is not None: #
for i in range(centroids[0].shape[0]): #centroids是包含了多次移动中心的记录,centroids[0]就是第一次三个中心的坐标,维度是(3,2)。shape[0]就是行数,为3即3个中心
x_i = X[idx == i]
subX.append(x_i) #subX是一个列表,含有3个元素,每个元素为每个簇的样本集,一共3个中心所以有三个元素。
else:
subX = [X] # 将整个X转化为只含一个元素的列表,每个元素为每个簇的样本集,方便下方绘图
# 分别画出每个簇的点,并着不同的颜色
plt.figure(figsize=(8,5))
for i in range(len(subX)):
xx = subX[i]
plt.scatter(xx[:,0], xx[:,1], c=colors[i], label='Cluster %d'%i)
plt.legend()
plt.grid(True)
plt.xlabel('x1',fontsize=14)
plt.ylabel('x2',fontsize=14)
plt.title('Plot of X Points',fontsize=16)
# 画出簇中心点的移动轨迹
xx, yy = [], []
for centroid in centroids:
xx.append(centroid[:,0])
yy.append(centroid[:,1])
plt.plot(xx, yy, 'rx--', markersize=8)
plt.show()
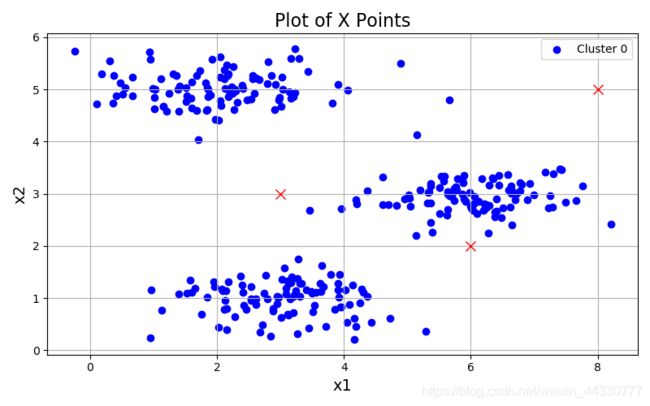
plotData(X, [init_centroids])
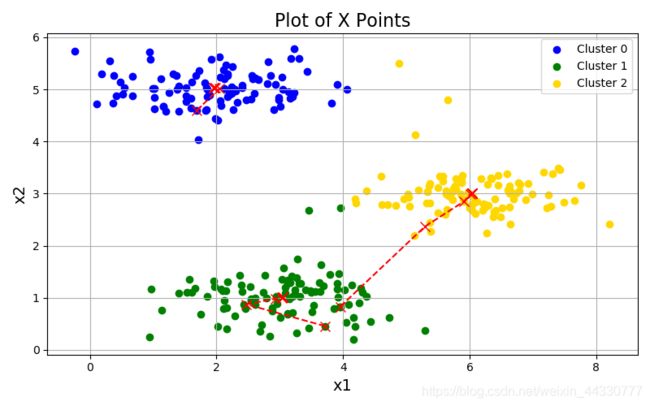
可视化数据的运行处理效果:
2.2寻找最优K
2.2.1随机初始化
在运行 K-均值算法的之前,我们首先要随机初始化所有的聚类中心点 。
我们应该选择K < m,即聚类中心点的个数要小于所有训练集实例的数量
随机选择K个训练实例,然后令K个聚类中心分别与这K个训练实例相等
K-均值的一个问题在于,它有可能会停留在一个局部最小值处,而这取决于初始化的情况。
为了解决这个问题,我们通常需要多次运行 K-均值算法,每一次都重新进行随机初始化,最后再比较多次运行 K-均值的结果,选择代价函数最小的结果。但是如果K较大,这么做也可能不会有明显地改善。
定义求K的多次循环的函数:
def runKmeans(X, centroids, max_iters): #max_iters即循环次数
K = len(centroids) #即中心的数量
centroids_all = []
centroids_all.append(centroids)
for i in range(max_iters):
idx = findClosestCentroids(X, centroids)
centroids = computeCentroids(X, idx)
centroids_all.append(centroids)
return idx, centroids_all
idx, centroids_all = runKmeans(X, init_centroids, 20)
plotData(X, centroids_all, idx)
2.2.2 中心点的选择
k-meams算法的能够保证收敛,但不能保证收敛于全局最优点,当初始中心点选取不好时,只能达到局部最优点,整个聚类的效果也会比较差。可以采用以下方法:
选择彼此距离尽可能远的那些点作为中心点;
先采用层次进行初步聚类输出k个簇,以簇的中心点的作为k-means的中心点的输入。
多次随机选择中心点训练k-means,选择效果最好的聚类结果
定义随机初始化来得到初始中心点:
def initCentroids(X, K):
m = len(X)
idx = np.random.choice(m, K)
centroids = X[idx] #列表里索引可以还是列表
return centroids
2.2.3 决定聚类数K
K-means算法存在一个问题:它有可能会停留在一个局部最小值处,这往往取决于初始化的状态。因此改进初始化的方式是进行多次随机初始化,比较多次运行K-means的结果,最终选择损失函数最小的结果。
定义行n次初始化跑程序,找到最优的那个解:
def find_best_key(n,k): #k是中心点个数
min=10000
for i in range(n):
centroids = initCentroids(X, k)
idx, centroids_all = runKmeans(X, centroids, 50)
centroid=centroids_all[50]
sum=0
for i in range(k):
subtraction = X[idx==i]-centroid[i]
sum=sum+(subtraction**2).sum()
if sum<min:
min=sum
idx_best=idx
centroids_all_best=centroids_all
return centroids_all_best, idx_best
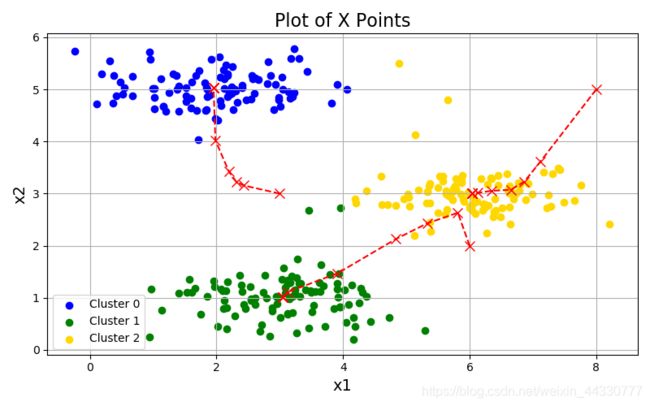
centroids_all, idx=find_best_key(30,3) #循环30次,聚成3类。2类,4类都可以
plotData(X, centroids_all, idx)
处理效果:
绘制数据集聚类结果&聚类中心的移动轨迹:
(三) 用scikit-learn学习K-Means聚类
在scikit-learn中,包括两个K-Means的算法,一个是传统的K-Means算法,对应的类是KMeans。另一个是基于采样的Mini Batch K-Means算法,对应的类是MiniBatchKMeans。一般来说,使用K-Means的算法调参是比较简单的。
用KMeans类的话,一般要注意的仅仅就是k值的选择,即参数n_clusters;如果是用MiniBatchKMeans的话,也仅仅多了需要注意调参的参数batch_size,即我们的Mini Batch的大小。
3.1 参数介绍
KMeans类的主要参数 :
- n_clusters: 即我们的k值,一般需要多试一些值以获得较好的聚类效果。k值好坏的评估标准在下面会讲。
- max_iter:
最大的迭代次数,一般如果是凸数据集的话可以不管这个值,如果数据集不是凸的,可能很难收敛,此时可以指定最大的迭代次数让算法可以及时退出循环。
- n_init:用不同的初始化质心运行算法的次数。由于K-Means是结果受初始值影响的局部最优的迭代算法,因此需要多跑几次以选择一个较好的聚类效果,默认是10,一般不需要改。如果你的k值较大,则可以适当增大这个值。
- init:
即初始值选择的方式,可以为完全随机选择’random’,优化过的’k-means++‘或者自己指定初始化的k个质心。一般建议使用默认的’k-means++’。
- algorithm:有“auto”, “full” or “elkan”三种选择。“full"就是我们传统的K-Means算法,
“elkan”是我们原理篇讲的elkan
K-Means算法。默认的"auto"则会根据数据值是否是稀疏的,来决定如何选择"full"和“elkan”。一般数据是稠密的,那么就是
“elkan”,否则就是"full”。一般来说建议直接用默认的"auto"
MiniBatchKMeans类主要参数
MiniBatchKMeans类的主要参数比KMeans类稍多,主要有:
- n_clusters: 即我们的k值,和KMeans类的n_clusters意义一样。
- max_iter:最大的迭代次数, 和KMeans类的max_iter意义一样。
- n_init:用不同的初始化质心运行算法的次数。这里和KMeans类意义稍有不同,KMeans类里的n_init是用同样的训练集数据来跑不同的初始化质心从而运行算法。而MiniBatchKMeans类的n_init则是每次用不一样的采样数据集来跑不同的初始化质心运行算法。
- batch_size:即用来跑Mini Batch
KMeans算法的采样集的大小,默认是100.如果发现数据集的类别较多或者噪音点较多,需要增加这个值以达到较好的聚类效果。
- init: 即初始值选择的方式,和KMeans类的init意义一样。
- init_size: 用来做质心初始值候选的样本个数,默认是batch_size的3倍,一般用默认值就可以了。
- reassignment_ratio:
某个类别质心被重新赋值的最大次数比例,这个和max_iter一样是为了控制算法运行时间的。这个比例是占样本总数的比例,乘以样本总数就得到了每个类别质心可以重新赋值的次数。如果取值较高的话算法收敛时间可能会增加,尤其是那些暂时拥有样本数较少的质心。默认是0.01。如果数据量不是超大的话,比如1w以下,建议使用默认值。如果数据量超过1w,类别又比较多,可能需要适当减少这个比例值。具体要根据训练集来决定。
- max_no_improvement:即连续多少个Mini Batch没有改善聚类效果的话,就停止算法, 和reassignment_ratio, max_iter一样是为了控制算法运行时间的。默认是10.一般用默认值就足够了。
3.2 K值的评估标准
不像监督学习的分类问题和回归问题,无监督聚类没有样本输出,也就没有比较直接的聚类评估方法。但是我们可以从簇内的稠密程度和簇间的离散程度来评估聚类的效果。常见的方法有轮廓系数Silhouette Coefficient和Calinski-Harabasz Index。 计算简单直接,得到的Calinski-Harabasz分数值s越大则聚类效果越好。
Calinski-Harabasz分数值s的数学计算公式是:
s ( k ) = t r ( B k ) t r ( W k ) m − k k − 1 s(k) = \frac{tr(B_k)}{tr(W_k)} \frac{m-k}{k-1} s(k)=tr(Wk)tr(Bk)k−1m−k
其中m为训练集样本数,k为类别数。Bk为类别之间的协方差矩阵,Wk为类别内部数据的协方差矩阵。tr为矩阵的迹。
也就是说,类别内部数据的协方差越小越好,类别之间的协方差越大越好,这样的Calinski-Harabasz分数会高。
3.3 K-Means应用实例
下面用一个实例来讲解用KMeans类和MiniBatchKMeans类来聚类。
首先我们随机创建一些二维数据作为训练集,选择二维特征数据,主要是方便可视化。代码如下:
从输出图可以我们看看我们创建的数据如下:
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets.samples_generator import make_blobs
# X为样本特征,Y为样本簇类别, 共1000个样本,每个样本2个特征,共4个簇,簇中心在[-1,-1], [0,0],[1,1], [2,2], 簇方差分别为[0.4, 0.2, 0.2]
X, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1,-1], [0,0], [1,1], [2,2]], cluster_std=[0.4, 0.2, 0.2, 0.2],
random_state =9)
plt.scatter(X[:, 0], X[:, 1], marker='o')
plt.show()
从输出图观察创建的数据如下:

用K-Means聚类方法来做聚类,首先选择k=2,代码如下:
from sklearn.cluster import KMeans
y_pred = KMeans(n_clusters=2, random_state=9).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()
k=2聚类的效果图输出如下:

现在k=3来看看聚类效果,代码如下:
from sklearn.cluster import KMeans
y_pred = KMeans(n_clusters=3, random_state=9).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()
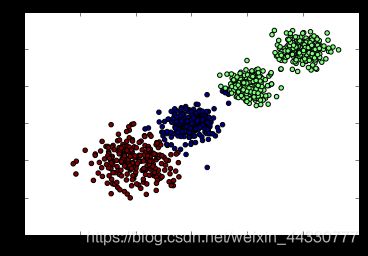
现在我们看看k=4时候的聚类效果:
from sklearn.cluster import KMeans
y_pred = KMeans(n_clusters=4, random_state=9).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()
k=4的聚类的效果图输出如下:

对比之下,可见k=4的聚类分数比k=2和k=3都要高,这也符合我们的预期,我们的随机数据集也就是4个簇。
现在我们再看看用MiniBatchKMeans的效果,我们将batch size设置为200. 由于我们的4个簇都是凸的,所以其实batch size的值只要不是非常的小,对聚类的效果影响不大。
for index, k in enumerate((2,3,4,5)):
plt.subplot(2,2,index+1)
y_pred = MiniBatchKMeans(n_clusters=k, batch_size = 200, random_state=9).fit_predict(X)
score= metrics.calinski_harabaz_score(X, y_pred)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.text(.99, .01, ('k=%d, score: %.2f' % (k,score)),
transform=plt.gca().transAxes, size=10,
horizontalalignment='right')
plt.show()
对于k=2,3,4,5对应的输出图为:

可见使用MiniBatchKMeans的聚类效果也不错,当然由于使用Mini Batch的原因,同样是k=4最优。
3.4 作业: 使用 k-means 压缩图像
有一幅24位颜色的小鸟图像,每一个像素被表示为三个8位的无符号整数(0~255),并指定了红、绿和蓝的亮度值。 使用 k-means 压缩图像将会把图像的颜色数量减少到16种。这可以有效地压缩图像,具体操作是只要存储所选择的16种RGB的值,对于图像中的每一个像素,只需要将这个颜色的索引存储在这个颜色的位置(即,只需要4 bits就能表示16种可能性)。下面,用K-means算法选择16种颜色,用于图像压缩。具体地,要把原始图像的每个像素看成一个数据样本,并使用K-means算法找出在RGB中分组最好的16种颜色。
-
原始图像:24位真彩色图像,每个像素有RGB三个通道,每个通道有256个强度值(每个像素可以有 2 8 ∗ 2 8 ∗ 2 8 = 2 24 2^8*2^8*2^8=2^{24} 28∗28∗28=224
种色彩)。 -
压缩目标:将每个像素通道的强度值压缩为16种
首先导入所需要的库:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import scipy.optimize as opt
from scipy.io import loadmat
#from skimage import io
from PIL import Image
from pylab import *
import k_means
导入数据集的代码,并显示其维数:
img = array(Image.open('D:\\机器学习\\作业\\K-means和PCA主成分分析\\数据文件\\bird_small.png'))
image = loadmat('D:\\机器学习\\作业\\K-means和PCA主成分分析\\数据文件\\bird_small.png')
A = image['A']
print('A.shape:',A.shape)
plt.imshow(img)
plt.title('Orginal Image')
#数据归一化(除以255,使所有值都在0-1范围内)
A = A / 255
# 重置矩阵大小
#reshape(-1,3)含义是将A的矩阵转换为3列,尚不知多少行,用-1代替
X = A.reshape(-1, 3)
print('X.shape:',X.shape)
显示:

原始图像数据集:
# 原始图像数据集
data = sio.loadmat('D:\\机器学习\\作业\\K-means和PCA主成分分析\\数据文件\\bird_small.png')
>>> data.keys()
> dict_keys(['__header__', '__version__', '__globals__', 'A'])
A = data['A']
>>> A.shape
> (128, 128, 3) #128×128个像素点,每个像素点有3个通道强度值(范围是0-255)
k-means 压缩:
def findClosestCentroids(X, centroids): #之前定义的函数做一下修改,加上一个维度
idx = []
for i in range(len(X)):
minus = X[i] - centroids
dist = minus[:,0]**2 + minus[:,1]**2 +minus[:,2]**2 #加上minus[:,2]**2
ci = np.argmin(dist) #获取dist最小值的索引,即哪个中心离该样本最近
idx.append(ci)
return np.array(idx)
centroids = initCentroids(X, K)
idx, centroids_all = runKmeans(X, centroids, 10)
img = np.zeros(X.shape)
centroids = centroids_all[-1]
for i in range(len(centroids)):
img[idx == i] = centroids[i]
img = img.reshape((128, 128, 3))
fig, axes = plt.subplots(1, 2, figsize=(12,6))
axes[0].imshow(A)
axes[1].imshow(img)
plt.show()
最终结果:

KMeans聚类中,为了降低计算时间,KMeans算法的变种Mini Batch KMeans算法应运而生, Mini Batch是指每次训练算法时随机抽取的数据子集,采用这些随机选取的数据进行训练,大大的减少了计算的时间,减少的KMeans算法的收敛时间,但要比标准算法略差一点,建议当样本量大于一万做聚类时,就需要考虑选用Mini Batch KMeans算法。
该算法的迭代步骤有两步:
-
从数据集中随机抽取一些数据形成小批量,把他们分配给最近的质心
-
更新质心
与K均值算法相比,数据的更新是在每一个小的样本集上。对于每一个小批量,通过计算平均值得到更新质心,并把小批量里的数据分配给该质心,随着迭代次数的增加,这些质心的变化是逐渐减小的,直到质心稳定或者达到指定的迭代次数,停止计算
(四)降维:简介PCA
PCA 算法也叫主成分分析(principal components analysis),主要是用于数据降维的。关于降维,可以这样理解,一组数据有n个feature(客户年龄,收入,每个月消费额度等等),每一个feature有一系列的观测点。而这n个feature中有一些存在线性相关,比如对于某些群体而言,收入和消费是线性相关的。此时我们进行多维度数据分析时只需要考虑其中一个参数就可以足够了,这样就能减少一个feature(维度),PCA方法就是用严谨的数据方法实现了这一过程。
简言降维就是降低特征的维数,例如每个样本点有1000个特征,通过降维,可以用100个特征来替代原来的1000个特征。
降维的好处在于:
-
Data compression 数据压缩,可以提高运算速度和减少存储空间。
-
Data Visualization 数据可视化,得到更直观的视图
如下图是一个将 3 维特征转换为 2 维特征的例子:
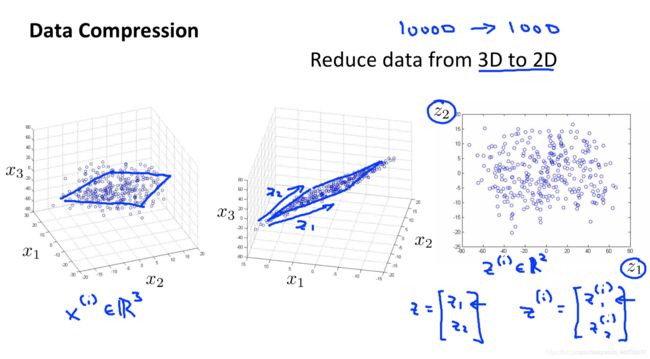
应用PCA实现特征的降维小结:
-
定义:高维数据转化为低维数据的过程,在此过程中可能会舍弃原有数据、创造新的变量
-
作用:是数据维散压缩,尽可能降低原数据的维数(复杂度),损失少量信息。
-
应用:回归分析或者聚类分析当中
4.1 PCA 的思想
对于降维问题来说,目前最流行最常用的算法是 主成分分析法 (Principal Componet Analysis, PCA)
PCA是寻找到一个 低维的空间 对数据进行 投影 ,以便 最小化投影误差的平方( 最小化每个点 与投影后的对应点之间的距离的平方值 ),例如:
-
2维→1维:点到直线的垂直距离
-
3维→2维:点到平面的垂直距离
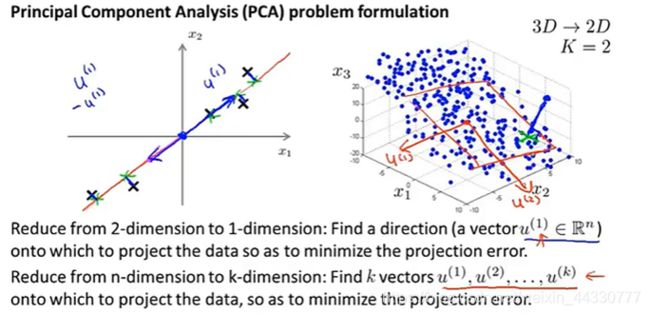
如上图所示,低维空间是由其中的特征向量 u ( i ) u^{(i)} u(i)来确定的,因此PCA算法的核心就是寻找 低维空间的特征向量。
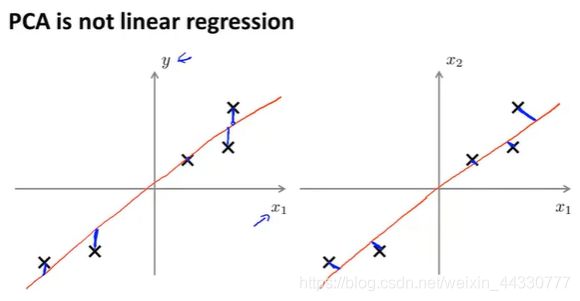
PCA与LR的区别:
线性回归(Linear Regression,LR)与 2维PCA的区别:虽然都是找一条直线去拟合,但是计算 loss (损失/代价函数)的方式不同。
-
PCA计算的是投影误差(垂直距离),而LR计算的是预测值与实际值的误差(竖直距离);
-
PCA中只有特征没有标签数据y(非监督学习),LR中既有特征样本也有标签数据(监督学习)。
4.2 PCA 的步骤
利用 PCA 将 n维 降到 k维 的步骤:
- 特征缩放(均值归一化),使得特征的数值在可比较的范围之内。
- 计算协方差矩阵(covariance matrix),用 Σ \Sigma Σ表示(大写的Sigma,不是求和符号):
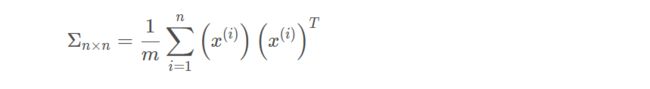
- 利用奇异值分解(SVD)来分解协方差矩阵,得到的特征向量 U n × n U_{n×n} Un×n 是一个具有与数据之间最小投射误差的方向向量构成的矩阵:
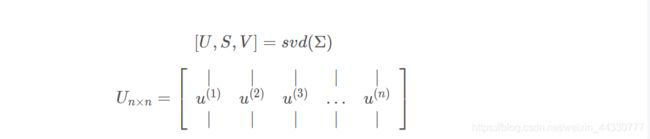
- 出 U n × n U_{n×n} Un×n 的前 k k k 个向量作为降维后的特征矩阵 U r e d u c e U_{reduce} Ureduce ,将原始样本 x ( 1 ) , x ( 2 ) , x ( 3 ) , … … … x ( m ) ( x ∈ R n ) x^{(1)}, x^{(2)}, x^{(3)}, \ldots \ldots \ldots x^{(m)}\left(x \in R^{n}\right) x(1),x(2),x(3),………x(m)(x∈Rn) 转化为新的特征向量下的新样本点 z ( 1 ) , z ( 2 ) , z ( 3 ) , … … . . z ( m ) z^{(1)}, z^{(2)}, z^{(3)}, \ldots \ldots . . z^{(m)} z(1),z(2),z(3),……..z(m)

4.3 PCA反向压缩——原始数据重现
既然PCA可以将高维数据压缩到低维,那么反着使用PCA则可以将低维数据恢复到高维。
因为 z = U reduce T x z=U_{\text {reduce}}^{T} x z=UreduceTx,那么反过来: x a p p o x = U r e d u c e ⋅ z ≈ x x_{a p p o x}=U_{r e d u c e} \cdot z ≈x xappox=Ureduce⋅z≈x
注意这里的 x a p p o x x_{a p p o x} xappox只是近似值。

4.4 如何选择主成分的数量
在 PCA 算法中,我们把 n n n 维特征变量 降维到 k k k 维特征变量 。这个数字 k k k 也被称作 主成分的数量 或者说是我们保留的主成分的数量 。
首先来看看以下两个值:
- PCA 的 投射平均均方误差 (Average Squared Projection Error) :

- 训练集的方差,它的意思是 平均来看 我的训练样本 距离零向量多远:

我们希望在平均均方误差与训练集方差的比例尽可能小的情况下选择尽可能小的 k 值:
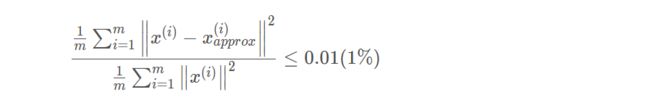
我们把两个数的比值作为衡量PCA算法的有效性,例如比值小于 1 % 1\% 1% 时,说明PCA算法保留了原始数据 99 % 99% 99% 的差异性。(一般选择保留90%即可)
因此我们可以先定义一个阈值,然后不断实验 k,直到获得满足阈值的最小 k 值。
此外,还可以利用奇异值 S i j S_{ij} Sij 来计算平均均方误差与训练集方差的比例。 [ U , S , V ] = s v d ( Σ ) [U, S, V]= svd(\Sigma) [U,S,V]=svd(Σ) 其中的 S n × n S_{n×n} Sn×n 为对角矩阵:
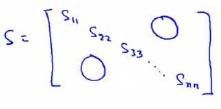 写作:
写作:

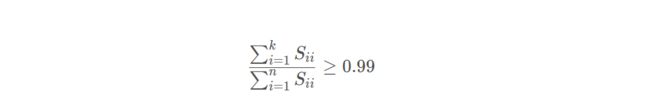
应用 PCA 的建议
PCA主要用在以下情况:
-
数据压缩,可以提高运算速度和减少存储空间。
-
数据可视化,得到更直观的视图
有些人觉的PCA也可以用来防止过拟合,但是这是不对的。应该用正则化。正则化使用y标签最小化损失函数,使用了y标签信息。而PCA只单纯的看x的分部就删除了一些特征,损失了很多信息。
另一个常见的错误是,默认地将主要成分分析作为学习过程中的一部分,这虽然很多时候有效果,最好还是从所有原始特征开始,只在有必要的时候(算法运行太慢或者占用太多内存)才考虑采用主要成分分析。
(五)PCA降维实现
再总结一下PCA的算法步骤:
设有m条n维数据。
-
将原始数据按列组成n行m列矩阵X
-
将X的每一行(代表一个属性字段)进行零均值化,即减去这一行的均值
-
求出协方差矩阵 C = 1 / m ∗ X ∗ X T C=1/m*X*X^T C=1/m∗X∗XT
-
求出协方差矩阵的特征值及对应的特征向量
-
将特征向量按对应特征值大小从上到下按行排列成矩阵,取前k行组成矩阵P
-
Y=PX 即为降维到k维后的数据
下面通过一个2D数据集进行实验,感受PCA工作的过程,然后在一个5000张脸的数据集中进行使用。
5.1 测试PCA将数据从2D减少到1D
首先导入需要的库,然后载入数据集并可视化数据集,最后输出数据集的维数:
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import scipy.optimize as opt
from scipy.io import loadmat
data = loadmat('D:\机器学习\作业\K-means和PCA主成分分析\数据文件\ex7data1.mat')
X = data['X']
print('X.shape:',X.shape)
#plt.axis('equal')
plt.scatter(X[:,0], X[:,1], facecolors='none', edgecolors='b',s = 15)
处理效果:

输出:
5.2 PCA降维
先标准化:
def featureNormalize(X):
means = X.mean(axis=0)
stds = X.std(axis=0, ddof=1)
X_norm = (X - means) / stds
return X_norm, means, stds
定义协方差sgima,并做svd得到U,S,V:
def pca(X):
sigma = np.dot(X.T,X) / len(X)
U, S, V = np.linalg.svd(sigma)
return U, S, V
X_norm, means, stds = featureNormalize(X)
U, S, V = pca(X_norm)
定义降维函数:
def projectData(X, U, K):
Z = np.dot(U[:,:K].T , X.T)
return Z
Z = projectData(X_norm, U, 1) #Z是一个2维数组,只有一行(1,50)
定义恢复维度函数(重建数据):
def recoverData(Z, U, K):
X_rec = np.dot(U[:,:K],Z) #此时X是(2,50)的
X_rec=X_rec.T #调一下维度,每一行代表一个样本。(50,2)
return X_rec
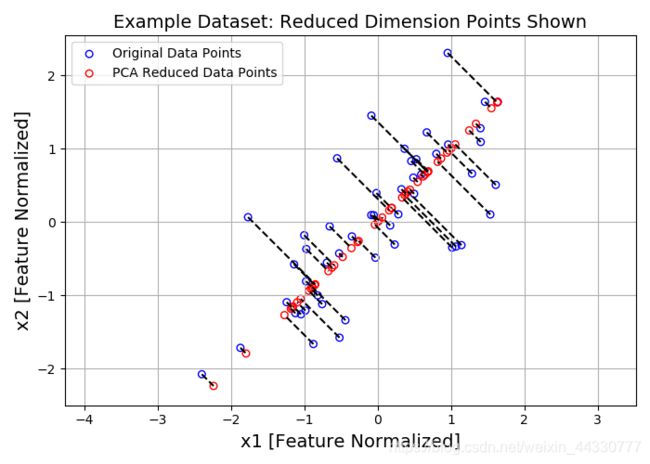
画出原来点与降维后再恢复维度的点:
X_rec = recoverData(Z, U, 1)
plt.figure(figsize=(7,5))
plt.axis("equal")
plot = plt.scatter(X_norm[:,0], X_norm[:,1], s=30, facecolors='none',
edgecolors='b',label='Original Data Points')
plot = plt.scatter(X_rec[:,0], X_rec[:,1], s=30, facecolors='none',
edgecolors='r',label='PCA Reduced Data Points')
plt.title("Example Dataset: Reduced Dimension Points Shown",fontsize=14)
plt.xlabel('x1 [Feature Normalized]',fontsize=14)
plt.ylabel('x2 [Feature Normalized]',fontsize=14)
plt.grid(True)
for x in range(X_norm.shape[0]):
plt.plot([X_norm[x,0],X_rec[x,0]],[X_norm[x,1],X_rec[x,1]],'k--') #输入第一项是两个X坐标,第二项是两个Y坐标,这种可以画出两点的连线
plt.legend()
plt.show()
处理效果:
红色的点代表数据点投影后的点,蓝色的点代表原始的数据点。
5.3 PCA处理人脸图像数据
接在4.2之后继续导入需使用的库及人脸数据集:
mat = loadmat('D:\机器学习\作业\K-means和PCA主成分分析\数据文件\ex7faces.mat')
X = mat['X']
print(X.shape) #(5000, 1024) 一共5000个样本,一个样本1024个像素
先图片可视化:
def displayData(X, row, col):
fig, axs = plt.subplots(row, col, figsize=(8,8))
for r in range(row):
for c in range(col):
axs[r][c].imshow(X[r*col + c].reshape(32,32).T, cmap = 'Greys_r')
axs[r][c].set_xticks([]) #去除x,y轴
axs[r][c].set_yticks([])
plt.show()
displayData(X, 10, 10)
数据可视化显示如下:

对人脸数据进行标准化和PCA处理:
X_norm, means, stds = featureNormalize(X)
U, S, V = pca(X_norm)
U.shape, S.shape #(1024, 1024), (1024,)
压缩成36个像素,再解压缩成1024像素。解压后数据有损失,最后画出解压后的图:
z = projectData(X_norm, U, K=36)
X_rec = recoverData(z, U, K=36)
displayData(X_rec, 10, 10)
处理效果:
压缩前:

解压缩后:

对比再运行一组实验,将所需要降的维数设置为K=10:
压缩前/后:

 对比再运行一组实验,将所需要降的维数设置为K=100:
对比再运行一组实验,将所需要降的维数设置为K=100:
压缩前后:


将所需要降的维数设置为K=1000:
压缩前/后:


说明:当实验中选择的主成分越小时,那么从降维后恢复出原始图像的效果就越差,反之,当主成分越大,就能够很好地恢复出原始图像。很明显得看出,当K=10时,基本上恢复出来的图像能还原轮廓,但是眼睛嘴巴等细节就没有能够很好地还原回来;当K=1000时,复原的图像能很好的重构眼睛、嘴巴等细节 。