MySQL5.7数据库-视图&事务&索引&数据库存储引擎
文章目录
-
- SQL高级
-
- 视图
-
- 视图介绍
- 定义视图
- 视图的作用
- 视图的修改
- 事务
-
- 事务的四大特性(ACID)
- 事务的状态
- 事务命令
-
- 开启事务
- 提交事务
- 回滚命令
- 保存点
- 事务的隔离级别
-
- 隔离级别(ISOLATION LEVEL)
- 设置mysql的隔离级别
- 索引
-
- 什么是索引
- 索引的目的
- 索引使用
- 查询
- 适合建立索引的情况
- 不适合建立索引的情况
- 数据库存储引擎
-
- 服务层
-
- 连接管理器
- 查询缓存
- 解析器
- 查询优化器
- 执行器
- 存储引擎层
-
- 查看存储引擎
- MySQL引擎之MyISAM
-
- 什么是锁
- 锁的类型
- 锁的粒度
- MyISAM存储引擎特性
- 适合场景
- MySQL引擎之InnoDB
-
- 系统表空间和独立表空间如何选择?
- Innodb存储引擎的特性
- MyISAM和InnoDB对比
- MySQL引擎之csv
-
- 文件系统存储特点
- 特点
- 使用场景
- MySQL引擎之Memory
-
- 功能特点
- 如何选择存储引擎
- 参考条件
-
- 事务
- 备份
- 奔溃恢复
- 应用举例
SQL高级
视图
视图介绍
视图是一种虚拟存在的表,对于使用视图的用户来说基本上是透明的。视图并不在数据库中实际存在,行和列数据来自定义视图的查询中使用的表,并且是在使用视图时动态生成的。
定义视图
- 视图的目的:方便查询操作,减少复杂的SQL语句,增强可读性。
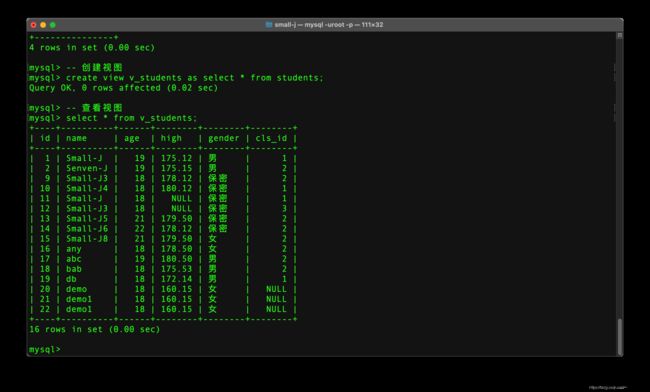
-- 创建视图
-- 视图名字一般以v开头,为什么?主要是在查看的时候方便知道这个是视图,主要是起到见名之意
create view 视图名字 as select 语句
-- 查看视图
show tables;
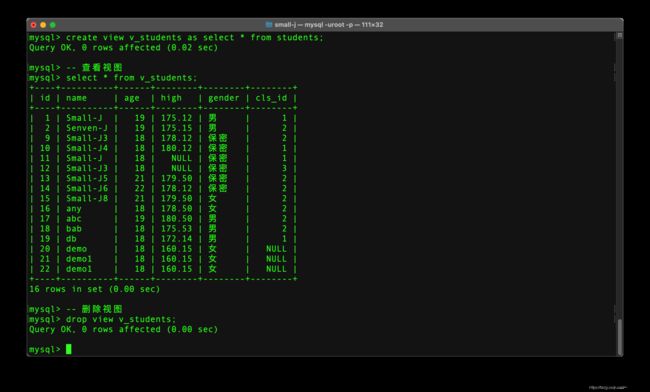
-- 删除视图
drop view 视图表名字;
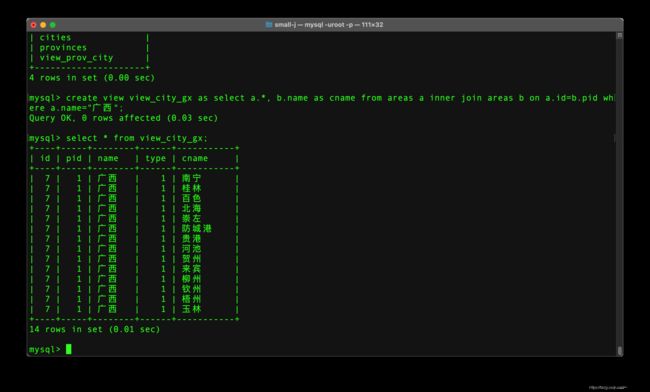
-- 城市表查询
select * from areas a inner join areas b on a.id=b.pid;
-- 当创建视图的时候报以下错误
create view view_city_gx as select * from areas a inner join areas b on a.id=b.pid;
ERROR 1060 (42S21): Duplicate column name 'id'
-- 主要是因为查询表中有两个id值,所以视图字段也是不可以重复
-- 取别名
create view view_city_gx as select a.*, b.name as cname from areas a inner join areas b on a.id=b.pid where a.name="广西";
视图的作用
- 简单
- 提高了重用性,就像一个函数。当想使用的时候直接调用,无序查看
- 安全
- 提高了安全性能,在开发中可以针对不同的用户,设定不同的视图
- 数据独立
- 一旦视图的结构确定了,可以屏蔽表结构变化对用户的影响,源表增加列对视图没有影响;
- 源表修改列名,则可以通过修改视图来解决,不会造成对访问者的影响
- 帮助用户屏蔽真实表结构变化带来的影响
视图的修改
有下列内容之一,视图都不能做修改
- select子句中包含distinct
- select子句中包括组函数
- select语句中包含group by子句
- select语句中包含order by子句
- where子句中包含相关子查询
- from子句中包含多个表
- 如果视图中有计算列,则不能更新
- 如果基表中有某个具非空约束的列未出现在视图定义中,则不能做insert操作
事务
事务是InnoDB引擎特有的特征之一
所谓事务,它是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位
事务的四大特性(ACID)
- 原子性(Atomicity)
- 事务必须是一个自动工作的单元,要么全部执行,要么全部不执行
- 一致性(Consistency)
- 事务把数据库从一个一致状态带入到另一个一致状态,事务结束的时候,所有的内部数据都是正确的
- 隔离性(Isolation)
- 并发多个事务时,一个事务的执行不受其他事务的影响
- 持久性(Durability)
- 事务提交之后,数据是永久性的,不可再回滚,不受关机等事件的影响
事务的状态
我们现在知道事务时一个抽象的概念,它其实对应着一个或多个数据库操作,设置数据库的大神根据这些操作所执行的不同阶段把事务大致上划分成了这么几个状态:
- 活动的(active)
- 部分提交的(partially committed)
- 失败的(faied)
- 中止的(aborted)
- 提交的(committed)
事务命令
表的引擎必须是InnoDB类型才可以使用事务,这是mysql表的默认引擎
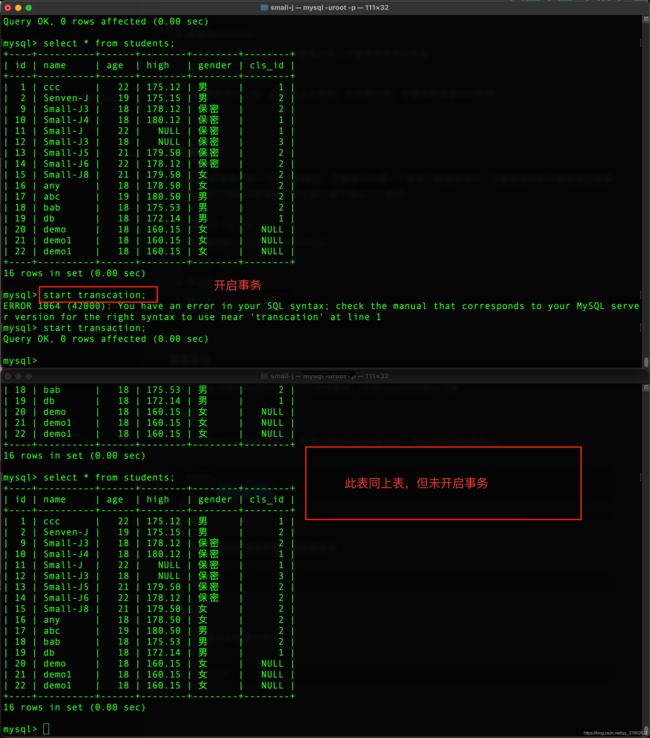
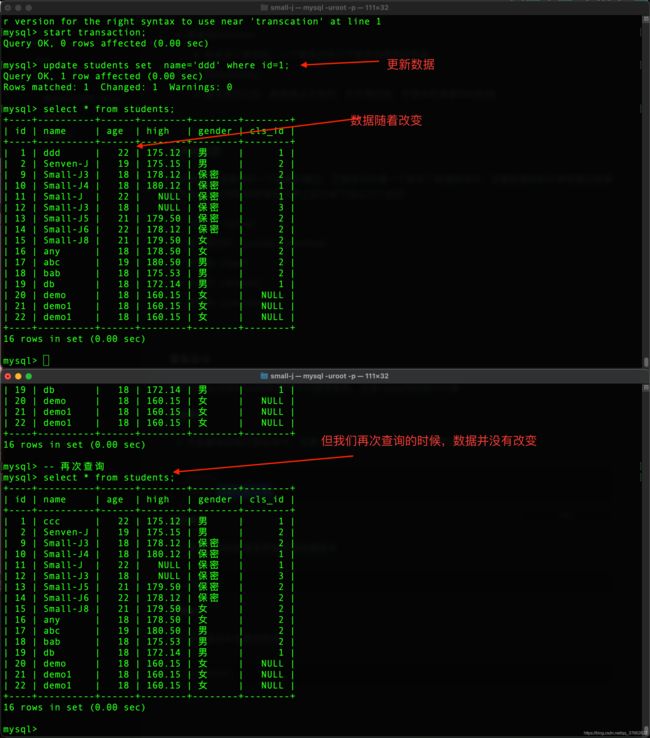
开启事务
- 开启事务后执行修改命令,变更会维护到本地缓存中,而不维护到物理表中
begin;
start transaction;
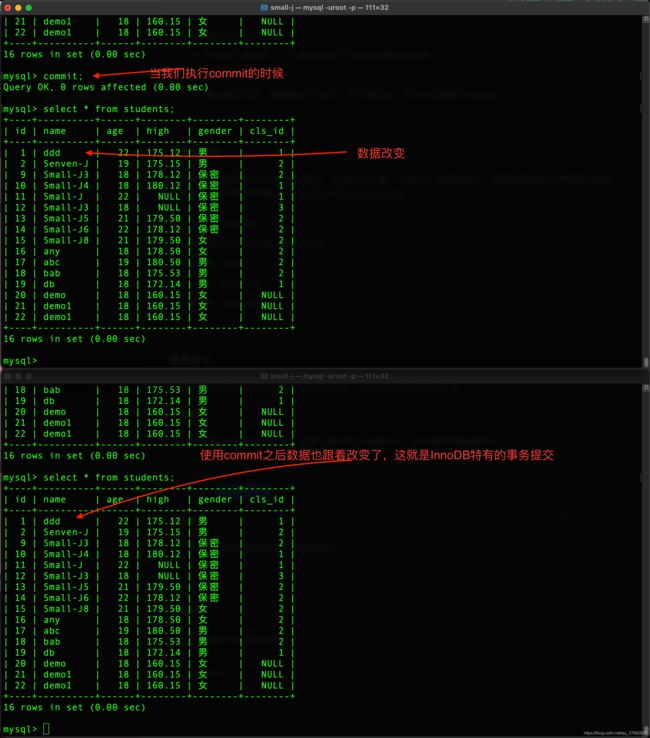
提交事务
- 将缓存中的数据变更维护到物理表中
commit;
回滚命令
- 放弃缓存中变更的数据
rollback;
保存点
如果你开启一个事务,并且以已经敲了很多语句,忽然发现上一条语句有点问题,你只好使用rollback语句来让数据库状态恢复到事务执行之前的样子,然后一切从头再来,总有一种一夜回到解放前的感觉,所有设计数据库的大神们提出了一个保存点(英文:savepoint)的概念。,我们在调用rollback语句时可以指定会滚到哪个点,而不是最初的点。
savepoint 保存点名字
- 当我们想回滚到某个保存点时
rollback to 保存点名字
- 如果我们想删除某个保存点
release savepoint 保存点名字
事务的隔离级别
隔离级别(ISOLATION LEVEL)
隔离性其实比想象要复杂。在SQL中定义了四种隔离的级别,每一种隔离级别都规定了一个事务中的修改,哪些是在事务内和事务间是可见的,哪些是不可见的。较低级别的隔离通常来说能承受更高的并发,系统的开销也会更小。
查看当前的事务级别
SELECT @@tx_isolation;
设置mysql的隔离级别
set session transaction isolation level 隔离级别;
-
READ UNCOMMITTED(读未提交)
所有事务都可以看到其他未提交事务的执行结果,会产生脏读(读取未提交的数据
-
READ COMMITTED(读提交)
一个事务职能看见已经提交事务所做的改变,会产生不可重复读问题
-
REPEATABLE READ (可重读)
这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读
-
SERIALIZABLE(串行化)
这是最高的隔离级别,读取共享锁,写加排他锁,读写互斥,从而解决幻读问题。在这个级别。可能导致大量的超时现象和锁竞争
索引
什么是索引
- 索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里的所有记录的引用指针。
- 更通俗的说,数据库索引好比是一本书前面的目录,能加快数据库的查询数据
- 索引分单列索引和组合索引。单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。组合索引,即一个索引包含多个列。
索引的目的
- MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度
索引使用
- 查看索引
-- 方法一
show index from 表名;
-- 方法二
show index from 表名\G
- 创建索引
- 如果指定字段是字符串,需要指定长度,建议长度与定义字段时的长度一致
- 字段类型如果不是字符串,可以不填写长度部分
create index 索引名称 on 表名(字段名称(长度))
创建一个测试表,使用python写入数据进行测试
use Job;
create table test(name varchar(30));
- 向表中插入了百万条数据
# -*- coding: utf-8 -*-
# Author : Small-J
# 2021/2/1 11:53 上午
import pymysql
class Test(object):
def __init__(self):
self.connect = pymysql.Connect(user='root', password='root', host='localhost', port=3306, database='Job')
self.cursor = self.connect.cursor()
def add_data(self):
for i in range(1000000):
self.cursor.execute("insert into test(name) values ('small-%s')" % i)
self.connect.commit()
self.cursor.close()
self.connect.close()
def run(self):
self.add_data()
if __name__ == '__main__':
t = Test()
t.run()
查询
- 开启运行时间监测
set profiling=1;
- 查找第1万条数据
select * from test where name='small-100000';
- 查看执行的时间
show profiles
- 为表test的name列创建索引
-- create index 索引的名称 on 表 (列名)
create index index_test_name on test(name varchar(30));
- 再次查看执行的时间
show profiles
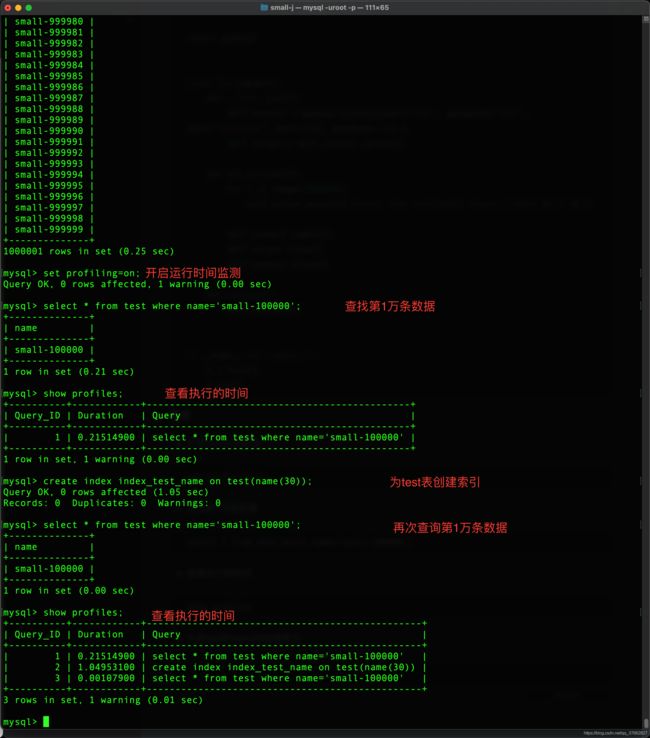
总结:从图中可以看出创建索引是可以大大的缩短时间的
适合建立索引的情况
- 主键自动建立索引
- 频繁作为查询条件的字段应该建立索引
- 查询中与其他表关联的字段,外键关系建立索引
- 在高并发的情况下创建复合索引
- 查询中排序的字段,排序字段若通过索引器访问将大大提高排序速度
不适合建立索引的情况
- 频繁更新的字段不适合建立索引
- Where条件里面用不到的字段不创建索引
- 表记录太少,当表中的数据量超过三百万跳数据,可以考虑建立索引
- 数据重复且平均的表字段
数据库存储引擎
服务层
第二层服务层是MySQL的核心,MySQL的核心服务层都在这一层,查询解析,SQL执行计划分析,SQL执行计划优化,查询缓存。以及跨存储引擎的功能都在这一层实现:存储过程,触发器,视图等。通过下图来观察服务层的内部结构

连接管理器
- 连接管理器的作用是管理和维持所有MySQL客户端的请求连接,当我们向MySQL发起请求时,连接管理器会负责创建连接并校验用户的权限。
- 对于已经建立的连接,如果没有太久没有发送请求,连接管理器会自动断开连接,我们可以通过设置变量wait_timeout决定多久断开不活跃的连接。
查询缓存
- 当我们与连接器建立连接后,如果我们执行的是SELECT语句,那么连接器会先从查询缓存中查询,看看之前是否执行过这条语句,如果没有再往走,如果有则判断相应的权限,符合权限,则直接返回结果。
- 查询缓存其实是把查询语句当作一个key,查询结果当用value,建立起来的key-value缓存结构。
- 不过,当数据表的数据发生变化时,其所对应的查询缓存则会失败,因此很多时候往往不能命中查询缓存,所以一般建议不要使用查询缓存。
- 可能MySQL官方团队也意识到查询缓存的作用不大,在MySQL 8.0版本中已经将查询缓存的整块功能删掉了,所以如果你用的是MySQL 8.0的版本,查询缓存的功能就不存在了
解析器
- 当在查询缓存中没有命令查询时,则需要真正执行语句,这时候就交给解析器先进行词法分析,对我们输入的语句进行拆解,折解后再进行语法分析,判断我们输入的语句是不是符合MySQL的语法规则,如果输入的语句不符合MySQL语法规则,则停止执行并提示错误。
查询优化器
- 我们输入的语句,经过分析器的词法和语法分析,MySQL服务器已经知道我们要查询什么了,不过,在开始查询前,还要交由查询优化器进行优化。
- 在优化的过程,优化器会根据SQL语句的查询条件决定使用哪一个索引,如果有连接(join),会决定表的查询顺序,最终会根据优化的结果生成一个执行计划交由下面的执行器去执行。
执行器
- SQL语句在经过查询优化器的优化后,接下来就交由执行器开始执行,不过执行器在开始执行前,会判断用户对相应的数据表是否有权限。
- 如果用户有权限,则开始调用数据,与其数据库不同的,MySQL的数据存储与调用交由存储实现,当我们调用时,执行器通过存储引擎API向底层的存储发送相应的指令,存储引擎负责具体执行,并将执行结果告诉执行器,然后再返回给客户端。
存储引擎层
- 负责MySQL中数据的存储与提取。 服务器中的查询执行引擎通过API与存储引擎进行通信,通过接口屏蔽了不同存储引擎之间的差异。MySQL采用插件式的存储引擎。MySQL为我们提供了许多存储引擎,每种存储引擎有不同的特点。我们可以根据不同的业务特点,选择最适合的存储引擎。如果对于存储引擎的性能不满意,可以通过修改源码来得到自己想要达到的性能。例如阿里巴巴的X-Engine,为了满足企业的需求facebook与google都对InnoDB存储引擎进行了扩充。
查看存储引擎
show engines\G
MySQL引擎之MyISAM
- Mysql5.5之前的版本默认存储引擎
- MyISAM存储引擎表由MYD(数据文件)和MYI(索引文件)组成
- MyISAM该引擎不支持事务和保存点
什么是锁
- 锁主要作用是管理共享资源的并发访问
- 锁用于实现事务的隔离性
锁的类型
- 共享锁(也称读锁),针对同一份数据,多个读操作可以同时进行而不会互相影响
- 独占锁(也称写锁),当前写操作没有完成前,它会阻断其他写锁和读锁
锁的粒度
- 表级锁
- 行级锁
MyISAM存储引擎特性
- 并发性与锁级别
- 表损坏修复
- MyISAM表支持数据压缩
myisampack -b -f myIsam.MYI
适合场景
非事务型应用
只读类应用
MySQL引擎之InnoDB
- MySQL5.5 及之后版本默认存储引擎,支持事务的ACID特性
- Innodb使用表空间进行数据存储
系统表空间和独立表空间如何选择?
- 系统表空间会产生IO瓶颈,刷新数据的时候是顺序进行的所以会产生文件的IO瓶颈
- 独立表空间可以同时向多个文件刷新数据
Innodb存储引擎的特性
- 支持事务的ACID特性
- Innodb支持行级锁,可以最大程度的支持并发
MyISAM和InnoDB对比
| 对比项 | MyISAM | InnoDB |
|---|---|---|
| 主外键 | 不支持 | 支持 |
| 事务 | 不支持 | 支持 |
| 行表锁 | 表锁,即使操作一条记录也会锁住整个表,不适合高并发的操作 | 行锁,操作时只锁某一行,不对其他行有影响。适合高并发的操作 |
| 缓存 | 只缓存索引,不缓存真实数据 | 对内存要求较高,而且内存大小对性能有决定性的影响 |
| 表空间 | 小 | 大 |
| 关注点 | 性能 | 事务 |
MySQL引擎之csv
文件系统存储特点
- 数据以文本方式存储在文件中
- csv文件存储表内容
- .CSM文件存储表的元数据如表状态和数据量
- .frm文件存储表结构信息
特点
- 以csv格式进行数据存储
使用场景
- 适合做为数据交换的中间表
MySQL引擎之Memory
- 也称HEAP存储引擎,所以数据保存在内存中,如果MySQL服务重启数据会丢失,但是表结构会保存下来
功能特点
- 支持hash索引和btree索引
- 所有字段都为固定长度
- 不支持BLOB和TEXT等大字段
- Memory存储引擎使用表级锁
如何选择存储引擎
- 大部分情况下,InnoDB都是正确的选择,可以简单地归纳为一句话“除非需要用某些InnoDB不具备的特性”,并且没有其他办法可以替代,否则都应该优先考虑InnoDB引擎
参考条件
事务
如果应用需要事务支持,那么InnoDB(或者XtraDB)是目前最稳定并且经过验证的选择
备份
如果可以定期地关闭服务器来执行备份,那么备份的因素可以忽略。反之,如果需要在线热备份,那么选择InnoDB就是基本的要求
奔溃恢复
MyISAM崩溃后发生损坏的概率比InnoDB要高很多,而且恢复速度也要慢
应用举例
- 日志型应用
- MyISAM
- 只读或者大部分情况下只读的表
- MyISAM
- 订单处理
- InnoDB