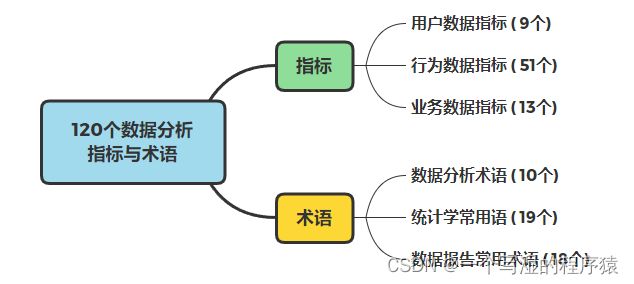
一文细数100+个数据分析指标
一文细数100+个数据分析指标
- 一、用户数据指标
-
- IP(Internet Protocol)
- UV(Unique Visitor)
- PV(Page View)
- VV(Visit View)
- DAU(Daily Active User)
- MAU(Monthly Active users)
- DNU(Day New User)
- 活跃留存率
- TGI(Target Group Index)
- 二、行为数据指标
-
- 用户访问类的指标
-
- PV(Page View)
- UV(Unigue Visitor)
- DV(Depth of Visit)
- 日新增用户数
- 获客成本
- 用户访问时长
- 人均页面访问量
- 人均浏览页数
- 平均访问页面
- 访问来源
- 平均停留时间
- 跳出率
- 搜索访问次数占比
- 用户转化类指标
-
- 最近购买间隔
- 购买频率
- 购买商品种类
- 平均每次消费额
- 单次最高消费额
- 日应用下载量
- 一次会话用户数
- 用户会话次数
- 漏斗转化一第一步进入次数
- 漏斗转化一中间步进入次数(漏 斗中)
- 进漏斗转化一进入率(漏斗中)
- 漏斗转化一进入次数(漏斗中)
- 漏斗转化一进入率(漏斗中)
- 漏斗转化一退出次数
- 漏斗转化一退出率
- 用户留存类指标
-
- 用户留存率
- 渠道留存率
- 次日留存率
- 退出率
- 活跃度
- 活动参与率
- 活跃交易用户数
- DAU(Daily Active User)
- MAU(Monthly Active Users)
- 用户回访率
- 用户流失率
- 功能使用率
- GMV(Gross Merchandise Volume)
- 复购率
- 退货率
- 三、业务数据指标
-
- 曝光量(渠道达到量)
- CPM(Cost PerMille)
- CPC(Cost Per Click)
- CPA(Cost Per Action)
- ROI(Return On Investment)
- ARPU(Average Revenue Per User)
- ARRPU(Average Revenue Per Paying User)
- CTR(Click Through Rate)
- CVR(Click Value Rate)
- CAC(Customer Acquisition Cost)
- CPR(Cost Per Response)
- ADPV(Advertisement Page View)
- ADimp(ADimpression)
- 四、数据分析术语
-
- 用户画像
- 海盗模型(AARRR)
- RARRA模型
- OSM模型(Object-Strategy-Measure)
- UJM模型(User-Journey-Map)
- RFM(Recency-Frequency-Monetary)
- ABTest
- 数据埋点
- 用户生命周期价值
- 归因分析
- 五、统计学常用语
-
- 绝对数和相对数
- 百分比和百分点
- 频数和频率
- 比例与比率
- 变量
- 连续变量
- 离散变量
- 定性变量
- 均值
- 中位数
- 缺失值
- 异常值
- 方差
- 标准差
- 皮尔森相关系数
- 六、数据报告常用术语
-
- 倍数和番数
- 同比和环比
- 增量
- 增速
- 增长率
- 增幅
- 基期和现期
- YTD(Year To Date)
- LY(Last Year)
- YoY(Year Over Year)
- MAT(Moving Annual Total)
- Q4/Q1(quarter)
- GDP(Gross Domestic Product)
- GNH(Gross National Happiness)
- GNP(Gross National Product)
一、用户数据指标
IP(Internet Protocol)
独立IP数。
UV(Unique Visitor)
独立访问客数。
PV(Page View)
页面浏览量/阅读量。
VV(Visit View)
访问次数。注:在对视频产品的数据分析中,VV(Video View)是播放类指标,是指在一个统计周期内,视频被打开的次数之和。
DAU(Daily Active User)
日活跃用户数

MAU(Monthly Active users)
月活跃用户数
DNU(Day New User)
日新增用户。
活跃留存率
指某日新增用户在其后N日仍启动该APP的用户数,占所选日期新增用户数的比例。

TGI(Target Group Index)
目标群体指数。

TGI指数高于100,代表该类用户该特征比例高于整体水平,即具有更高的相关倾向或偏好;小于100,则说明该类用户相关倾向较弱;等于100表示在平均水平。
TGI指数常用于用户画像的评判中,它可以清晰地反映不同群体某一特征的关联程度,并进行直观的比较,挖掘更多潜在的用户价值。

二、行为数据指标
用户访问类的指标
用户访问类的指标有13个:PV、UV、DV、日新增用户数、获客成本、用户访问时长、人均页面访问量、人均浏览页数、平均访问页面、访问来源、平均停留时间、跳出率、搜索访问次数占比。
PV(Page View)
即页面浏览量,是衡量网络新闻的主要指标
UV(Unigue Visitor)
即独立用户,是指通过互联网访问、浏览某网页的自然人
DV(Depth of Visit)
即访问深度,是指用户在一次浏览网站的过程中浏览了网站的页数
日新增用户数
在某个时间段内使用网站或应用的新用户总数(统计周期一般为天)
获客成本
获取一个客户所花费的平均成本
用户访问时长
一次会话持续的时间
人均页面访问量
人均页面访问量=通过浏览器访问的Session来记录的访问数/UV
人均浏览页数
每个唯一身份访问者(UV)页面浏览量(PV)的平均数量,人均浏览页数=PV/UV
平均访问页面
平均每次访问浏览的页面数量,平均访问页数=浏览量/访问次数
访问来源
也称为“推荐来源”,通常互联网用户会通过各种渠道进入某网站访问,这里的“渠道” 就是“访问来源”
平均停留时间
访客在一次访问中,平均打开网站的时长,即每次访问中,打开第一个页面到关闭最后 一个页面的平均值
跳出率
只访问了入口页面(如网站首页)就离开的访问量与所产生总访问量的百分比。 跳出率 = 访问一个页面后离开网站的次数 / 总访问次数
搜索访问次数占比
搜索访问次数就是访客点击搜索结果到达网站的次数。搜索访问次数占比 = 搜索访问次数 /总访问次数
用户转化类指标
用户转化类指标共有15个:最近购买间隔、购买频率、购买商品种类、平均每次消费额、单次最高消费额、日应用下载量、一次会话用户数、用户会话次数、漏斗转化—第一步进入次数、漏斗转化—中间步进入次数(漏斗中)、进漏斗转化—进入率(漏斗中)、漏斗转化—进入次数(漏斗中)、漏斗转化—进入率(漏斗中)、漏斗转化—退出次数、漏斗转化—退出率。
最近购买间隔
用户最近一次购买距离当前的天数
购买频率
用户在一段时间内购买的次数
购买商品种类
用户在一段时间内购买的商品种类
平均每次消费额
也称为客单价,计算公式:平均每次消费额=用户在一段时间内的消费总额/ 消费次数
单次最高消费额
用户在一段时间内购买的单次最高支付金额
日应用下载量
单个用户账户下载的应用数量
一次会话用户数
即下载完App,仅打开过产品一次,且该次使用时长在2分钟以内的新用户 数量
用户会话次数
用户会话(Session),是用户在时间窗口内的所有行为集合。用户打开App、 搜索商品、浏览商品、下单并且支付、最后退出的整个流程算作一次会话
漏斗转化一第一步进入次数
第一步进入次数=含有此页面的访问次数
漏斗转化一中间步进入次数(漏 斗中)
在漏斗上一步进入次数中以上一步为前链进入此步的次数
进漏斗转化一进入率(漏斗中)
进入率=在漏斗上一步进入次数中以上一步为前链进入此步的次数/上一步进 入次数
漏斗转化一进入次数(漏斗中)
在当前步骤的进入次数中,没有进入漏斗下一步而去了其他页面的次数
漏斗转化一进入率(漏斗中)
进入率=在当前步骤的进入次数中没有进入漏斗下一步而去了其他页面的次 数/当前步骤的进入次数
漏斗转化一退出次数
在当前步骤的进入次数中,没有进入漏斗下一步直接退出网站的次数
漏斗转化一退出率
退出率=当前步骤退出次数/当前步骤进入次数
用户留存类指标
用户留存类指标共有15个:用户留存率、渠道留存率、次日留存率、退出率、活跃度、活动参与率、活跃交易用户数、DAU、MAU、用户回访率、用户流失率、功能使用率、GMV、复购率、退货率。
用户留存率
留存用户数占当时新增用户数的比例(这里的“当时”指的是用户首次使用网站或App 的时间点,一般统计周期为天)
渠道留存率
不同用户渠道的用户留存率
次日留存率
计算公式:次日留存率=当时新増用户中在第2天依然使用网站或App的用户数/当时 新增用户数, 次日留存分析需要结合产品的新手引导设计和新用户转化路径等一起进行
退出率
计算公式:退出率=从该页退出的页面访问数/进入该页的页面访问数。 如,某商品页进入PV为1000,该页直接关闭的访问数为300,则退出率为30%
活跃度
线上产品的用户在线时长以及登录频次
活动参与率
参加活动人数占总人数的比重
活跃交易用户数
和活跃用户一样,活跃交易用户也可以区分成首单用户(第一次消费)、忠诚消费用 户、流失消费用户等
DAU(Daily Active User)
日活跃用户数量(Daily Active User),指的是一个统计日内登录或使用某个产品、独立不重复的用户数
MAU(Monthly Active Users)
即月活跃用户人数(Monthly Active Users)
用户回访率
用户回访率=回访用户数/统计周期内流失的用户数*100%
用户流失率
如果在某段时间内消费的人群中,一部分人在一个流失周期后变为流失人群,那么流 失人群人数与消费人群的总人数之比被定义为流失率。首先要确定如何定义客户流失行 为,不同运营人员对流失行为的定义不同
功能使用率
产品重要功能的使用指标,如收藏率、点赞率、评论率等
GMV(Gross Merchandise Volume)
一段时间内的成交总额
复购率
计算复购率有两种方法。
-
复购率=重复购买客户数量/客户样本数量。例如,客户样本100人,其中60人重 复购买(不用考虑重复购买了几次),复购率 = 60 / 100即60% -
复购率=客户购买行为次数(或交易次数)/客户样本数星。例如,客户样本100人, 其中60人重复购买,这60人中有40人重复购买1次(即购买2次),有20人重复购 买2次(即购买3次),复购率=(40*1+20*2) / 100即80%
退货率
计算公式:退货率=产品售出后由于各种原因被退回的数副同期售出的产品总数星
三、业务数据指标
互联网线上推广渠道总体上可以分为5种类型:原生广告类社交媒体、普通社交媒体、搜索引擎、软件商店、换量联盟。
曝光量(渠道达到量)
即产品推广页中有多少用户浏览
CPM(Cost PerMille)
指每千人成本,即每一千人看到广告的费用
CPC(Cost Per Click)
指每位用户点击成本,按每位用户的点击计价
CPA(Cost Per Action)
指每次行动成本,按每位用户的每一次行为计价
ROI(Return On Investment)
即投资回报比,投资回收率
ARPU(Average Revenue Per User)
每用户平均收入。
ARRPU(Average Revenue Per Paying User)
每付费用户平均收益。
CTR(Click Through Rate)
点击率,是衡量广告效果非常重要的一个指标:内容被点击的次数/内容展现的次数。

CVR(Click Value Rate)
转化率【衡量CPA广告效果的指标】
CAC(Customer Acquisition Cost)
获客成本【获取一个客户所花费的成本】
CPR(Cost Per Response)
每回应成本【以浏览者的每一个回应计费】
ADPV(Advertisement Page View)
载有广告的pa-geview流量
ADimp(ADimpression)
单个广告的展示次数
四、数据分析术语
用户画像
简单来说,用户画像是根据用户的社会属性、生活习惯、消费行为等信息而抽象得出的一个标签化用户模型。勾画用户画像的核心在于给用户贴“标签”。(涉及的元素比如用户的姓名、年龄、收入、喜好、购物习惯等等)

海盗模型(AARRR)
获取用户(Acquisition)、提高活跃度(Activation)、提高留存率(Retention)、获取收入(Reve-nue)、自传播(Refer),这个五个单词的缩写,分别对应用户生命周期中的5个重要环节。
RARRA模型
AARRR模型的核心在于获客,而在RARRA的模型下,专注用户的留存。

OSM模型(Object-Strategy-Measure)
OSM模型(Object-Strategy-Measure)就是把宏大的目标拆解,对应到部门内各个小组具体的、可落地、可度量的行为上,从保证执行计划没有偏离大方向。
UJM模型(User-Journey-Map)
UJM模型(User Journey Map,用户旅程地图)就是我们在设计一款产品的过程中,必须要去梳理的用户生命旅程。

RFM(Recency-Frequency-Monetary)
根据客户的交易频次和交易额衡量客户的价值,对客户进行细分。RFM是衡量客户价值的三个维度,分别为R(Recency)交易间隔、F(Frequency)交易频度、M(Monetary)交易金额组成。
ABTest
AB测试是为APP或Web的界面/流程制作两个(A/B)或多个(A/B/n)版本,在同一时间维度中,分别让组成成分相同/相似的访客群组(目标人群)随机的访问这些版本,收集各群组的用户体验数据和业务数据,最后分析、评估出最优版本,正式采用。

数据埋点
数据埋点是一种常用的数据采集方法,是数据产品经理、数据运营以及数据分析师,基于业务需求或产品需求对用户在应用内产生行为的每一个事件对应的页面和位置植入相关代码,并通过采集工具上报统计数据,以便相关人员追踪用户行为和应用使用情况,推动产品优化或指导运营的一项工程。
用户生命周期价值
LTV(life time value)也就是用户生命周期价值,是产品从用户获取到流失所得到的全部收益的总和。LTV用于衡量用户对产品所产生的价值,是所有用户运营手段为了改善的终极指标,同时LTV也应该是所有运营手段的最终衡量指标。
归因分析
在数据时代,广告的投放效果评估往往会产生很多的问题。而归因分析(Attribution Analysis)要解决的问题就是广告效果的产生,其功劳应该如何合理的分配给哪些渠道。
五、统计学常用语
绝对数和相对数
绝对数:是反应客观现象总体在一定时间、一定地点下的总规模、总水平的综合性指标,也是数据分析中常用的指标。比如年GDP,总人口等等。
相对数:是指两个有联系的指标计算而得出的数值,它是反应客观现象之间的数量联系紧密程度的综合指标。相对数一般以倍数、百分数等表示。相对数的计算公式:相对数=比较值(比数)/ 基础值(基数)
百分比和百分点
百分比:是相对数中的一种,它表示一个数是另一个数的百分之几,也称为百分率或百分数。百分比的分母是100,也就是用1%作为度量单位,因此便于比较。
百分点:是指不同时期以百分数的形式表示的相对指标的变动幅度,1%等于1个百分点。

频数和频率
频数:一个数据在整体中出现的次数。
频率:某一事件发生的次数与总的事件数之比。频率通常用比例或百分数表示。
比例与比率
比例:是指在总体中各数据占总体的比重,通常反映总体的构成和比例,即部分与整体之间的关系。
比率:是样本(或总体)中各不同类别数据之间的比值,由于比率不是部分与整体之间的对比关系,因而比值可能大于1。
变量
变量来源于数学,是计算机语言中能储存计算结果或能表示值抽象概念。变量可以通过变量名访问。
连续变量
在统计学中,变量按变量值是否连续可分为连续变量与离散变量两种。在一定区间内可以任意取值的变量叫连续变量,其数值是连续不断的,相邻两个数值可作无限分割,即可取无限个数值。如:年龄、体重等变量。
离散变量
离散变量的各变量值之间都是以整数断开的,如人数、工厂数、机器台数等,都只能按整数计算。离散变量的数值只能用计数的方法取得。
定性变量
又名分类变量:观测的个体只能归属于几种互不相容类别中的一种时,一般是用非数字来表达其类别,这样的观测数据称为定性变量。可以理解成可以分类别的变量,如学历、性别、婚否等。
均值
即平均值,平均数是表示一组数据集中趋势的量数,是指在一组数据中所有数据之和再除以这组数据的个数。
中位数
对于有限的数集,可以通过把所有观察值高低排序后找出正中间的一个作为中位数。如果观察值有偶数个,通常取最中间的两个数值的平均数作为中位数。
缺失值
它指的是现有数据集中某个或某些属性的值是不完全的。
异常值
指一组测定值中与平均值的偏差超过两倍标准差的测定值,与平均值的偏差超过三倍标准差的测定值,称为高度异常的异常值。
方差
是衡量随机变量或一组数据时离散程度的度量。概率论中方差用来度量随机变量和其数学期望(即均值)之间的偏离程度。统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数。在许多实际问题中,研究方差即偏离程度有着重要意义。方差是衡量源数据和期望值相差的度量值。
标准差
又常称均方差,是离均差平方的算术平均数的平方根,用σ表示。标准差是方差的算术平方根。标准差能反映一个数据集的离散程度。平均数相同的两组数据,标准差未必相同。
皮尔森相关系数
皮尔森相关系数是用来反映两个变量线性相关程度的统计量。相关系数用r表示,其中n为样本量,分别为两个变量的观测值和均值。r描述的是两个变量间线性相关强弱的程度。r的绝对值越大表明相关性越强。
六、数据报告常用术语
倍数和番数
倍数:用一个数据除以另一个数据获得,倍数一般用来表示上升、增长幅度,一般不表示减少幅度。
翻n番:指原来数量的2的n次方。
同比和环比
同比:指的是与历史同时期的数据相比较而获得的比值,反应事物发展的相对性。
环比:指与上一个统计时期的值进行对比获得的值,主要反映事物的逐期发展的情况。
增量
增长的绝对量 = 现期量 - 基期量
增速
增长速度=(现期量-基期量)÷ 基期量
增长率
增量与基期量之比。
增幅
即增长的幅度,也可理解为增量。
基期和现期
基期:被用作参照物的时期称为基期,描述基期的量即为基期量。
现期:相对于基期的称为现期,描述现期的量即为现期量。
YTD(Year To Date)
截止到今天为止今年的
LY(Last Year)
last year去年
YoY(Year Over Year)
跟上年相比
MAT(Moving Annual Total)
年度动态变化总值
Q4/Q1(quarter)
4季度/1季度
GDP(Gross Domestic Product)
国内生产总值
GNH(Gross National Happiness)
国民幸福指数
GNP(Gross National Product)
国民生产总值