一文帮你更好地理解指标
背景概述
随着市场竞争进入白热化,越来越多的公司由原来的增长黑客转变为精细化运营,不管是增长还是留存,我们都需要对产品的表现进行量化。 数据指标,就是量化信息的别名,科学的决策离不开构建精良的指标体系。
本文重点从技术视角,给大家介绍指标的定义和实现。文中会有部分简单的 SQL 示例。
01 一个例子讲清楚指标的定义
小明看到自己喜欢喝的一款高端酸奶标价 8 元,他连忙拿了一瓶去买单。结果店员告诉他,本次活动第一瓶是原价,第二瓶才是 8 块的半价 。

上面的例子中,单纯一个数字,是没有意义的,必须要相应的解释,人们才能理解。“买满两瓶,第二瓶酸奶的单价是 8 块”,这才是真正完整的指标。
用一个简单的公式给出指标的定义:
指标 = 数字 + 解释
其中解释包含两方面:
1 ) 业务上的解释 2 ) 技术上的解释
业务解释通常是图文,意在给指标使用者解释指标从何处来,怎么算。
技术解释通常是用程序语言定义的计算逻辑,比如用 SQL 语句定义人数为 count(user_id),均价为 avg(price) 。
其实理解了元数据,就能理解指标,大家可以参考文末的元数据文章。
02 | 如何设定合理的指标
互联网发展到现在,很多行业或公司都有了成熟的指标体系,而最初构建指标体系,都要围绕关键指标(北极星指标)展开。
社交类产品,关键指标是 DAU ,因为社交产品的核心是希望更多人能更频繁地用它沟通交流。
电商类产品,关键指标是 GMV ,因为电商平台希望能承载更多的线上交易。
视频类产品,关键指标是用户观看时长,因为这类产品的目的就是为了帮助用户杀时间。
不同行业,业务不同,核心关键指标也不同。
而不同之中有相同之处:关键指标都能反映产品表现,且能衡量产品的直接或间接商业价值。
**指标体系的构建,要基于业务展开,尤其是核心业务。**基于核心业务流程,进行层层拆解,逐渐构建起企业的业务指标体系。
拿电商行业的 AARRR 漏斗模型举例,每个业务阶段,都会有相应的北极星指标。

想要构建科学的指标体系,必须花时间深入了解公司、部门的关键业务。通常来说,经营性业务指标是业务型产品经理重点关注对象。
不过,公司对人才的综合能力要求越来越高, T 型人才的说法广为流传,产品经理也被越来越多地要求具备数据分析能力,所以了解下指标的管理与实现,对我们会有很大的增益。
03 指标该怎么管,要解决哪些问题
公司业务多,则指标多,如此多的指标,怎么管才好呢?
起初,很多公司会用 Excel 管理,构建一本“指标字典”,如果不明白某个指标什么意思,就去翻翻字典。毕竟,先上车后补票,让业务跑起来最重要。
公司业务发展好,人更多了,离线 Excel 文档不便于多人协同的问题就暴露了,在线文档出现后,离线文档逐渐被替代。
也有的公司也会用脑图来管理指标,不过这一类的工具,都算作是在线文档。但文档内容还是差不多,大体如下:

因为数据通常都是存在关系型数据库中的,所以定义指标时,也需要技术人员基于业务的数据模型给出技术口径,即指标的计算方式。
统一的指标共享文档,解决了指标业务口径一致性的问题,但还有 2 个问题没有解决:
1)业务口径和技术口径的关联
2)技术口径的复用性
先说第一个问题。假设系统中有一张用于记录用户登录的记录表,其结构如下:

起初,每日活跃用户定义为每天登录的用户数,日活用户数的取数SQL表达式为:
select count(*) from user_login where is_login = 1
业务发展一段时间,日活指标的定义修改为“每日停留时长达到 1 个小时的用户”。业务定义变了,技术定义也要随之变动也会变动。假定有另一张用户行为记录表,结构如下:
| user_id | oline_min | date |
|---|---|---|
| 001 | 60 | 2021-01-28 |
那么日活用户数的取数的SQL表达式为:
left join user_behavior on user_login.user_id = user_behavior.user_id
where user_login.is_login = 1 # 用户登录
and user_behavior.online_time > 60 # 用户在线时间大于60min
而作为产品的运营者,我们监测用户活跃度,往往还会得到更细的数据,比如近 1 天活跃用户数、近 7 天活跃用户数、近 14 天活跃用户数。
left join user_behavior on user_login.user_id = user_behavior.user_id
where user_login.is_login = 1 # 用户登录
and user_behavior.online_time > 60 # 用户在线时间大于60min
and date = 2021-01-27 # 最近 1 天
每一个业务口径都对应着特定的分析条件,业务口径可有修改其中的分析条件组合方式,所以会对应很多种具体的技术逻辑(比如 SQL 语句)。
而且,当指标的业务口径变化时,技术定义为了保证数据的准确性,也要随之变更。如果每一种组合都写定一个逻辑,那么工作量是浩大的。
为了降低技术对业务支撑的难度,聪明的工程师们就想出了办法:对指标进行分层管理。
04 指标,具体如何分层
如果你看过指标管理的文章或书籍,或者体验过指标管理系统,那你肯定这个结论:指标要分层,通常分 2-3 层。
按照阿里的分法,指标有两层:原子指标(有一个小中间层:衍生原子指标)、派生指标。按照华为的分法有三层,分别是:原子指标、衍生指标、复合指标。
当我们接触一个新东西, 我们通常最先会看到演进的最终结果。如果我们忽视演进过程不去探究,会有一个问题,我们回答不清楚为什么是这样。
上文其实已经给出了指标分层管理的背景,那指标到底为什么要分层?
答案就是为了方便复用和重新组合。
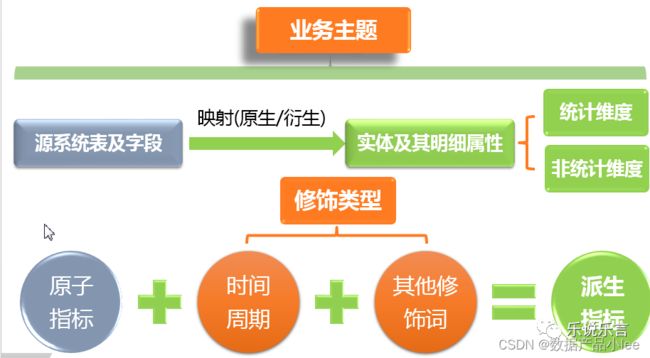
第一节中,我们知道指标是由数值和解释组成。假设我们知道了一个数值的业务含义,接下来,我们就会关心这个数值从何而来,以及数值是怎么计算得出的。
而原子指标,就承担了这样的角色。原子指标定义了数值从哪里取得,如何计算。
比如活跃人数,是从用户登录表根据对 user_id 进行计数而得来。也就是上面表格里面的 count (user_id)。
为了识别和区分,我们会对事物进行归类。比如性别:男/女,时代:当代/近现代/古代,地区:国内/国外。
**这些区分事物的“东西”,我们称其为维度。**维度还可以拆得更细,且不同维度之间是可以组合的。
阿里对派生指标的定义为:
衍生/派生指标 = 原子指标 + 时间周期 + 修饰词
其中的时间周期,我们也可以理解为时间维度,因为大多数时候,我们业务分析上都是用的离散的时间值,比如近 1 天、近 3 天、截止当前等。
修饰词,可以理解为不同的维度,或者是维度中特定某个值。比如地区维度,且维度值为北京。
抽象的东西,通过例子来理解:
近 1 个月北京市的活跃用户数 = 活跃用户数(原子指标) + 近 1 个月(时间周期) + 北京市(修饰词)
将原子指标、时间周期、修饰词、维度等分别定义出来,就好像乐高积木,工程师将最细粒度的标准化零件构建出来,并且设定好零件之间的组合规则,用户可以根绝自身业务需求进行组合,组合完成后,系统自动生成对应的 SQL 语句。
一方面减少了重复劳动,另一方面,对某个原子指标进行改动的时候,其他依赖该原子指标的衍生指标对应的逻辑系统也会自动更新。
05 建设指标管理系统的认知层次
如果你同为数据平台的产品经理,也要为公司建设指标管理系统,可以从如下三个层次进行认知突破。
第 1 层次:
掌握一些常识概念,了解基础流程
通过查阅各个竞品,知道原子指标、派生指标、复合指标、业务限定等基础概念,大概知道指标的需要哪些属性(要是要做系统,可以先照猫画虎)
第 2 层次:
明白数仓分层,以及指标体系
对数据仓库(维度建模、分层)、业务数据库(范式建模尤其是 3NF)、数据库基础(聚合函数和group by)、元数据等有一定的理解
第 3 层次:
深入业务,服务业务,优化业务
深入了解业务,知道业务方关心哪些核心指标,核心指标建设的优先级、怎么管、怎么运营,指标如何帮助业务部门解决问题。毕竟,数据价值最终要在业务上体现~
写在最后
本人作为数据平台产品经理,现在重点参与部分是数据中台的指标系统建设,对于业务方的指标需求认知还有许多不足之处。
从我的视角出发,给有不同需求的小伙伴一些建议。
如果你是业务型产品(前台),平时要负责产品的规则和玩法设计,需要观测产品的各项用户指标,那你应该侧重掌握业务逻辑,定义运营指标,并拆解出业务指标体系。
如果你是平台型产品(中后台),要更多考虑是为业务赋能,降本增效。建议你熟悉掌握相关技术知识和底层概念,构建全面的技术认知,再深入了解业务需求。
学以致用,祝各位都能用好指标,管好指标,共同创建美好的数据时代。