![]()

引言
Doris 向量化设计与实现
01 什么是向量化
向量化是指计算从一次对一个值进行运算转换为一次对一组值进行运算的过程, 从不同的角度来分析,我将拆分成两个方面来探讨或思考这个问题。 从CPU的角度 现代 CPU 支持将单个指令应用于多个数据(SIMD)的向量运算。例如,具有 128 位寄存器的 CP U可以保存 4 个 32 位数并进行一次计算,比一次执行一条指令快 4 倍。 
比如我们在内存当中有 4 个 32 位的 int ,进行计算时传统的 CPU 没有 SIMD,或者说没有向量化支持的 CPU 要进行四次从内存中 Load 数据,再进行 4 次乘法计算,然后把结果写回到内存当中同样要进行 4 次。假如我们能够支持 SIMD ,我们可以一次载入多个连续的内存数据,这样我们就只有一次数据的 Load ,一次的计算,然后得到 4 个结果写到 4 个寄存器里面,然后这 4 个寄存器再写回到内存当中,就完成了一次向量化的指令计算操作。这样的操作能够比传统的CPU快 4 倍。 随着 CPU 的发展,现在大家常用的都是 128 位的 SSE 的指令,后面又多了 256 位的 AVX 指令,以及英特尔现在最新的 AVX512 的指令。随着寄存器的位数不断变长,我们一次向量化运算的一组值可以变得越来越多,它的效率会越来越高。但这不一定是线性的关系,不一定随着寄存机的位数呈线性的性能增长,但是能够保证一次对一组值的操作是更多更快的。 这是在CPU角度,我们去看向量化这个问题。
从数据库的角度
从数据库角度也是计算从一次对一个值进行运算转换为一次对一组值进行运算的过程。-
数据库执行引擎:
1. 将 Next Tuple ,变成 Next Batch 。
2. 内存中 Batch 的数据不是以行的形式存在,而是以列的形式存在,算子都是在列上进行运算。
在数据库执行引擎的角度与 CPU 的角度也是类似,传统的数据库执行引擎都是一行一行处理数据的。我们可以看下面这个图。
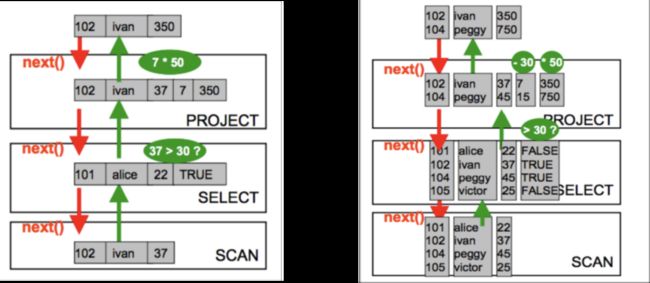
所以内存当中的数据不再以行的形式来存在,而是以列的形式存在,所有的计算都通过列的方式进行连续的计算。我们可以看右边这张图,比如我们有一个数据扫描的操作,原本按照左边这张图,一行做一个判断对一组值要判断 4 次,现在对一个列进行数据的判断。所以在数据库的角度同样也是对一个值的运算转化成对一组值的运算。
02 Doris 如何实现向量化
接下来介绍 Apache Doris 如何实现向量化,这也是我们目前正在做的工作。实现向量化核心工作主要分为这三块:-
列式存储: 在 Doris 的执行引擎中引入基于列存的存储格式。在执行引擎当中, Doris 现在存储层的数据是以列存储的,但是在执行引擎当中我们还是基于行的方式来做运算的。我们前面看到那张图是基于 Tuple 运算的,每次只能运算一个值,所以我们要把它替换为一个列式存储的执行引擎,这样我们才能够实现向量化。
-
向量化函数计算框架 : 基于列式存储重新设计一套向量化/列式计算引擎。在列式存储的基础上,我们要实现一套向量化的函数计算框架。基于现有的新的列式存储格式,重新设计一套向量化列式存储的计算引擎。
-
向量化算子 : 基于前两者,重新组织SQL算子。基于列式存储和向量化的函数计算框架,我们要实现所有的向量化算子,这一块工程量其实是比较大的。
1.列式存储
改变了计算引擎对数据的组织方式,由行存的 Tuple 与 RowBatch 变为了 Column 与 Block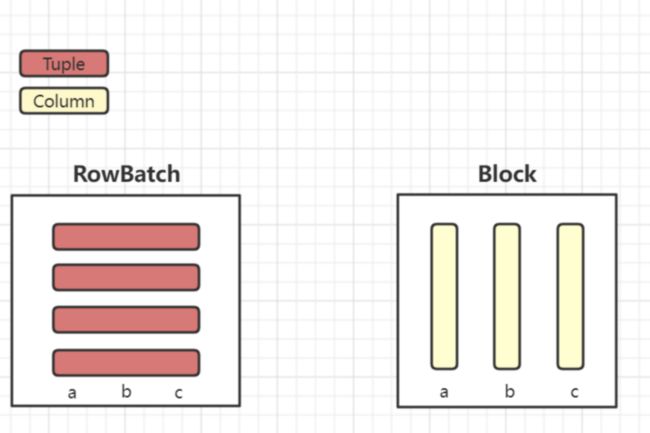
原先 Doris 在执行引擎当中的数据内存结构是左边的 RowBatch 结构,数据通过一个一个 Tuple 进行组织的,每一个 Tuple 是个连续的内存。我们可以看到左边 RowBatch 的结构分为三个列,但它每一个行是一个连续的内存结构,在组织内部处理当中也是一行一行处理的。 右边是我们新的结构 Block ,我们可以看到它的数据是按列来进行组织的,每一个列是一个连续的内存结构。 2.向量化的函数计算框架 这里我简单举一个例子
select a,abs(b) from test;
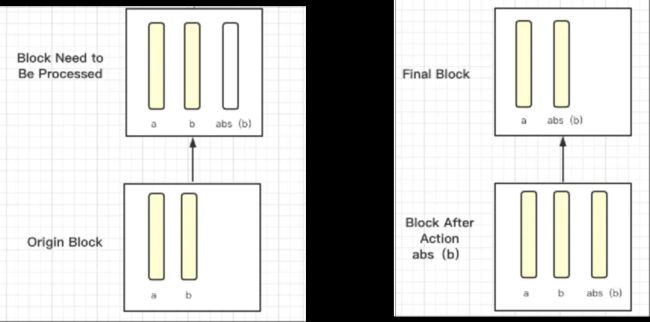
// 行存执行逻辑for(int i = 0;i < rows; ++i) {Tuple Tuple = batch->get_row(i);for(int j = 0;j < desc.slots().size();++j) {void *data = Tuple.get_data(desc.slots(j).offset); // 获取某一行的数据switch(desc.slots(j)) { // 通过desc中的描述类型来解释执行case TYPE_INT: hash_int((int*)data);case TYPE_STRING: hash_string((StringRef*)data);
较上方的这段代码是原来行存执行的逻辑,可以看到一个 Batch 输入进来之后,我们要遍历所有 Row ,每次获取一行数据,做完偏移之后才能拿到对应的列,而基于这个列,每一次还要做类型的判断,然后再确定调用什么函数进行处理。// 列存执行逻辑for i in range(types.size())switch(types[i]) {TYPE_INT:for(j = 0; j < rows < ++j) {hash_int((*(int*)column->data() + j));}TYPE_STRING: xxx;
但是我们可以看下边列存的执行逻辑,相对行存的执行逻辑更简洁。首先在整个 Block 的执行过程中只有一次类型判断,我们可以看到假如 RawBatch 或者 Block 有 1024 行,原行存执行结构对于类型的判断要走 1024 次,但对于列存来说只要一次就可以了,减少了大量类型判断。另外,从代码上可能不容易看出来其实每一次处理时列存是连续的,我们对连续的一段内存做处理, Cache 亲和度更高。 03 向量化计算优点 相对于旧的行存计算框架,列式的函数计算框架有以下优势:
-
Cache 更亲和,列式计算由于数据是按列组织的,所以更容易命中 Cache 。 比如刚才的例子中,运算 abs(b) 时没有相关的列是不会参与到计算过程当中来的。列式计算由于数据在列上连续,所以更容易命中我们需要计算的 Cache ,从 Cache 中读取数据和内存中读取数据,性能有 10 倍至 100 倍的差距。
-
减少虚函数的调用,减少分支跳转,降低 CPU 分支预测判断失败概率。 从两段代码能明显看到减少很多类型的判断,在向量化框架当中大量运用模板的方式做零成本的抽象减少虚函数调用。关于虚函数调用会有什么开销、引起什么问题,我们在后面会再详细讨论。
- 函数计算的 SIMD ,包含编译器自动 SIMD 与手动 Coding 的 SIMD指令集。 这一部分对应一开始单独提到的「从CPU角度去看向量化」,原先一次只能算一个值,现在向量化计算框架中一次可以计算多个值,这样就会有数倍的性能提升。
这边我列了下面这个表格。

2.虚函数调用的开销。 虚函数带来的开销主要是下面两点: 2.1 虚函数的动态调用是无法进行函数内联的,这会大大减少编译器可能进行的优化空间。 虚函数实际调用时需要查表,编译器无法知道当时动态状态下需要调用什么样的函数 ,所以没有办法进行内联。我们知道函数内联真正意义就是给编译器更多的优化空间,这与数据库当中的优化器是类似的,给更多的信息才能做更好的优化。编译器的角度也是同样的道理,但因为虚函数没有办法进行函数内联,所以编译器获取的信息就会大大减少,这样编译器代码优化空间就会减少。 2.2 虚函数查表带来额外的分支跳转的开销,分支预测失败会导致CPU流水线重新执行。
分支跳转在 CPU 当中是有一定开销的。下面这张图是 Pipeline 的执行流程,分为 Fetch , Decode , Executed , Write-back,这四个 Stage 。现在的 CPU 还要比这个复杂很多。
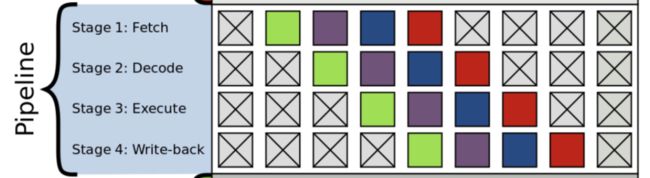
一旦 CPU 进入一个跳转流程当中,原则上来讲 Pipeline 是要暂停下来的,因为跳转指令是依赖前一个指令执行结果,完成后我们才能确定要执行什么指令。但是现在 CPU 进行分支预测不会让流水线空转。分支预测一旦成功的话,已经顺着流水线执行下去的指令能够得到很好的收益,但一旦分支预测失败会导致 CPU 流水线重新执行,这也会带来极大的性能开销 。 对于分支预测,给大家举个小例子,大家可以实际去用代码去实践一下。 假如我有个 vector 存储的指针对象有虚函数调用,我们是把不同的对象交替地放在这个
vector 当中,还是把这个 vector 基于对象类型做一次排序之后调用,哪个执行效率更高,大家可以实际写代码去验证一下。有意思的是他们实现的汇编都是一模一样,但是后者更快,这就是分支预测失败带来的一个影响。
3.函数执行如何 SIMD 3.1 Auto vectorized 自动向量化,也就是编译器自动去分析 for 循环是否能够向量化。GCC 开启的 -O3 优化便会开启自动向量化。 自动向量化 tips : (1)足够简单的 for 循环。
(2)足够简单的代码,避免:函数调用,分支跳动。
(3)规避数据依赖,即避免下一个计算结果依赖上一个循环的计算结果。
(4)连续的内存和对齐的内存。SIMD 指令本身对于内存要求是比较多的。首先前面我们讲到了 CPU 是连续载入多个数据的,数据在不连续的内存上没有办法一次做连续的载入。第二是内存对齐会影响向量化指令的执行效率。GCC 的文档上给了一个比较完整的 case ,讲到如何写代码编译器能够做自动的向量化,大家有兴趣的话可以参考 GCC 的文档 CASE:
https://gcc.gnu.org/projects/tree-ssa/vectorization.html

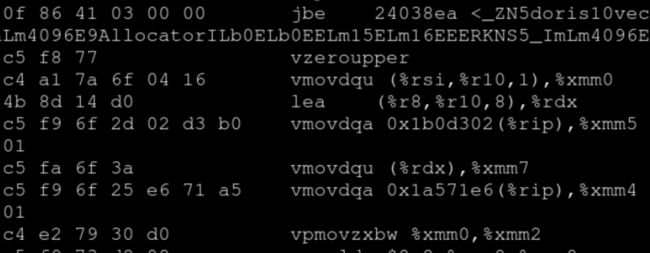
如何确认代码编译器的自动向量化生效了呢? (1)编译器的 Hint 提示。 -fopt-info-vec-all:打印所有编译器进行向量化的信息,如果循环代码被向量化了,会打印如下信息 main.cpp:5: note: LOOP VECTORIZED. -fopt-info-vec-missed:没有被向量化的原因 -fdump-tree-vect-all:进一步分析没有被向量化的原因 大家可以把 Hint 提示打开,打开后就能在编译的过程中看到编译器的提示,如果循环代码被向量化了,编译器会打印对应的信息。LOOP VECTORIZED 告诉你这个循环被向量化。如果是没有被向量化的话可以打印 vec-missed 的 Hint ,它会告诉你为什么函数没有被向量化,但通常只会提供一个简单的原因。如果要更深入分析的话,可以用最下面我给大家的 Hint 进一步分析为什么没有被向量化。大家可以实际写代码去实践一下。 (2)直接通过 perf/objdump 查看生成的汇编代码。 在一个大型程序上一个一个看 for 循环的话比较困难,我们可以把编译出来的产出通过 perf 或 objdump 直接查看生成的汇编代码,就可以看到有没有向量化了。我这边截了一张图:
Doris 向量化的当前情况
01 SQL 算子
在 0.15 版本我们发布了一个单表的向量化执行引擎,能够满足大宽表的向量化查询需求,实现向量化的 SQL 算子包括 Sort,Agg,Scan,Union。当前 Doris 的数据存储是基于列式存储,在数据进来之后的一些计算过程是基于行存来进行的,在 ScanNode 上转成列式存储,基于列式存储实现了这4种向量化的算子执行向量化的计算。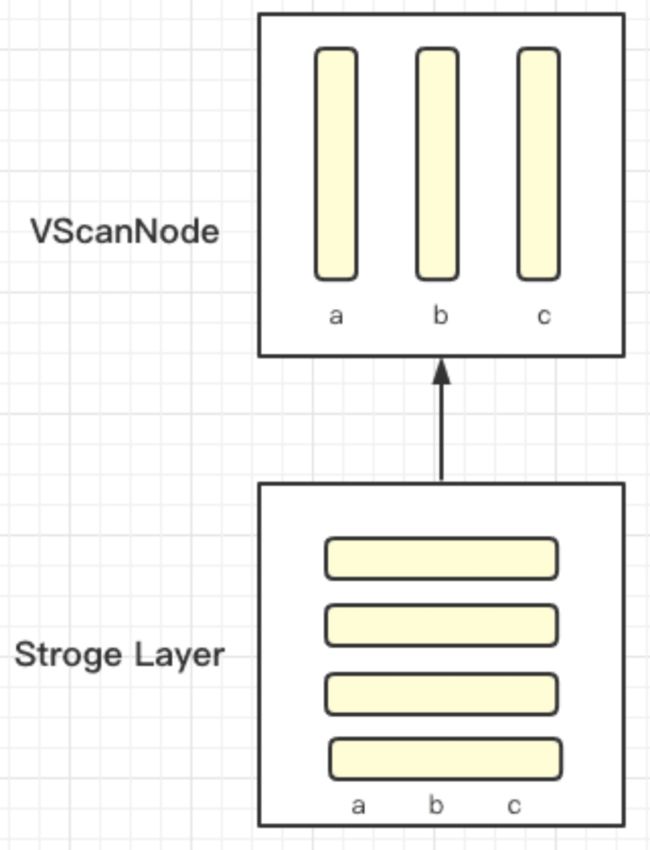
02 如何开启向量化
1.设置环境变量 set enable_vectorized_engine = true;(必须) 我们可以看到这张图,设置后的执行计划会带一个v,这其实跟汇编指令生成 SIMD 指令集是相似的,代表开启向量化。 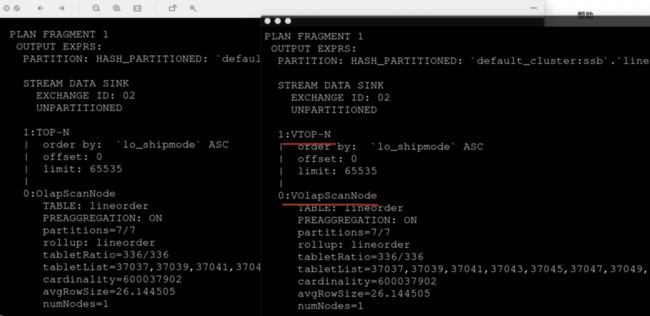
2.设置环境变量set batch_size = 4096; (推荐)
我们在实际的测试当中测试下来, 推荐设置 batch_size 为 4096 ,或者说在向量化当中应该讲 Block 实测下来设置为 4096 行性能是最好的。当然这里仅作推荐,不调整的话性能也还是不错的。
03 向量化的单表性能
这是 0.15 版本我们在单表上做的一些测试,与原来行存做了一个对比。 Q1:select count(*) FROM lineorder_flat; Q2:select min(lo_revenue) as min_revenue from lineorder_flat group by c_nation; Q3:select count(distinct lo_commitdate), count(distinct lo_discount) from lineorder_flat;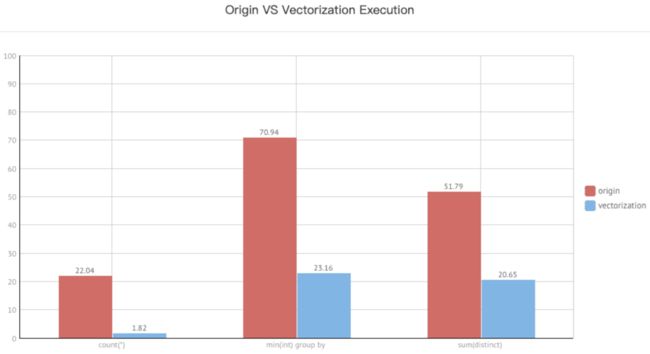 可以看到性能提升的效果还是比较可观的。这是在 0.15 版本我们实测的向量化的性能,后续的版本性能会更激动人心,值得大家期待!
可以看到性能提升的效果还是比较可观的。这是在 0.15 版本我们实测的向量化的性能,后续的版本性能会更激动人心,值得大家期待!
Doris 向量化的未来规划
接下来是向量化的未来规划,包括功能的完善与发布,以及关于后续版本的想法,这部分我想也是大家最关心的。01 SQL 算子
Join 算子是 Doris 最为核心的算子,绝大多数场景使用 Doris 其实也是看中 Doris 本身在 MPP 场景下的多表 Join 能力,所以 Join 开发也是我们向量化开发当中的重中之重。 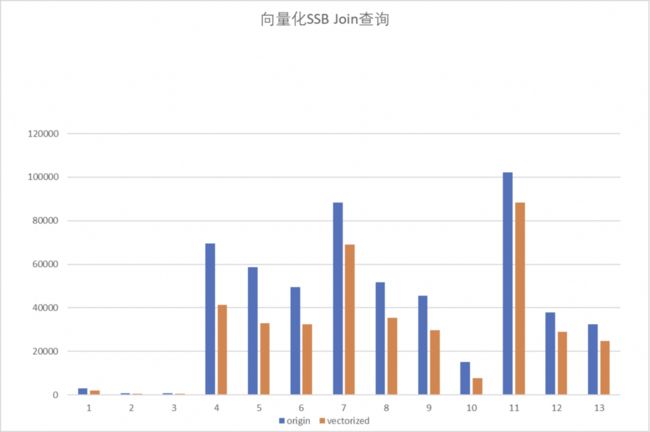
可以告诉大家我们已经实现了 Join 的向量化,只是还没有做系统的调优。这是我们基于 SSB测试集的 Join 向量化性能情况,这是第一版大家可以简单看一下,在 SSB 测试集当中 Join 性能基本有 30% 至 40% 甚至 1 倍的提升。 剩下一些 SQL 算子,除了 Join 之外大家可能还会用到的:交集,差集, cross Join,ODBC/MySQL Scan Node,窗口函数(WIP),ES Scan Node(WIP) ,这些算子其实都是当前 Doris 行存支持的SQL算子,除了部分算子还在开发中,基本都已经全部 Ready,现在还在做一些稳定性和性能调优工作。
02 存储层向量化
前面讲到目前 Doris 的数据是基于列存储在磁盘上。但我们读下来之后要对这个数据做聚合,这个过程是通过行存来表示的。这部分因为历史原因存在了很多冗余低效的代码,目前我们在实际的向量化开发中发现已经严重影响了整个向量化代码的执行逻辑与性能。主要是如下几个问题: 1.计算表达式受限制。 很多计算表达式因为内存结构不同、接口不同没有办法作用于存储层,导致表达式没有办法下推,以及无法做向量化的计算。 2.额外的转换的性能开销比较严重, 严重影响到导入和查询性能。我们实际做了一个 POC 的测试,在 DupKey 表上通过完整的向量化改造性能还能有10倍级别的提升。 3.代码可维护性降低。 因为结构不同,所以目前Doris 在执行引擎实现的聚合算子没有办法作用于存储引擎。同样的聚合代码要在存储层和查询层,也就是存储引擎和查询引擎分别实现,代码可维护性就很差。另外在查询层进行性能优化没有办法作用在存储层下,性能优化需要考虑两部分,所以也带来了一些问题。我们目前在做的一个很重要的工作就是把 Doris存储层通过行存做去重聚合的逻辑进行向量化。 

03 导入向量化
⽬前 Doris 进行数据导入时存在 Tuple 转 RowCursor ,数据行式聚合等一系列有冗余开销的工作。而我们后续希望通过导入向量化的开发实现:
- 减少额外内存格式的转换开销,提高 CPU 的利用率
- 复用计算层的算子,减少冗余低效的代码,简洁 Doris 现有的代码结构
- 利用 SIMD 加快导入过程当中的聚合计算,进一步提升 Doris 导入性能
目前向量化版本实现了一个简单的导入框架。Block 计算完成之后是以列组织的,通过向量化的计算引擎做格式的转化,但最终在发送数据时,由于接收端还没有做向量化改造,所以我们现在还是基于 RowBatch 的数据格式进行数据发送。下一步我们要规划的工作就是把通过 Tuple 转 Rowcursor 进行运算这部分全部剔除掉,转换成向量化的格式或者说列存的格式进行运算。
04 SQL函数
1.函数丰富度支持 前面讲到了目前 Doris 已有的函数是比较丰富的,但是因为向量化是基于列存实现的,函数接口包括调用的方式都有所不同,所以我们不单单要实现 SQL 算子,还要实现浩如烟海的 SQL 函数。目前我们已经实现了向量化支持的函数大概有 200 多个,其他还在不断的开发过程当中,需要尽快补齐原先行存支持但是向量化还没有支持的函数。这部分工作也欢迎大家参与进来。2.函数的 SIMD 化
我们保证在列存上能够利用前面提到的几个优势使分支跳转变少,Cache 亲和度更高。但目前很多实现向量化的函数没有考虑 SIMD 化。尤其对于热点的核心函数,我们后续规划尽量通过各种可能的方式进行 SIMD 化,包括我们前面提到手写 SIMD 。我自己在开发过程当中手写了一些 SIMD 的函数。目前在 Apache 的 Master 库也能看到我自己手写的一些在字符串实现的SIMD 的函数。3.向量化的 UDF 的框架设计和实现。
UDF 也是大家经常用到一个功能,向量化上需要重新设计一个 UDF 框架,这也是我们后续要做的。
05 代码重构
1.基础类型的重构 。目前 Doris 向量化上所有的数据类型都能够支持,但是有这几个问题:-
Data / Datatime:更小的内存占用,对 SIMD 更友好的内存布局。 Doris 现在的 Data 和 DataTime 类型复用了行存,毫秒的数据其实在现在的 Doris 当中没有在用了。 现在 Data 和 DataTime 占用 16 字节,而毫秒就占了 8 字节,这八字节完全没有用到,额外占用了很大的内存。 这部分内存占用在原来函数当中还不明显,但在向量化当中8个字节的占用就会带来很大的内存开销,对 SIMD 不友好。 另外目前 Data / DataTime 内存布局还有待优化,在做 SIMD 时会有各种各样的问题。 所以我们准备重构 Data / DataTime,实现在向量化版本有更小的内存占用,对 SIMD 更友好的内存布局。
-
Decimal:根据精度切换内存占用,解决 Doris 中当前精度浪费的问题。 当前的Doris在精度上没有根据实际用户设置的精度切换内存占用,统一占用 16 字节的内存,造成很大一部分开销。 我们准备对 Decimal 的这一问题进行重构。
- HLL:减少 HLL 类型无效的序列化的开销。 目 前我们已经把 Bitmap 重构完成,用了一个新的结构表示 Bitmap ,减少了大量的序列化开销,整体性能表现也很不错。 减少 HLL 在计算时无效的序列化开销就是下个阶段我们要做的事情。
写在最后
01 感谢 Clickhouse 社区 Doris 在进行向量化代码开发时,在列存模型和函数框架上引用了部分 Clickhouse 19.16.2.2 版本的代码,我们在引用代码的 License 上注明了相应的工作,同时与 Clickhouse 社区进行了对应的沟通。十分感谢 Clickhouse 在 Doris 向量化代码开发上给予的帮助。
02 版本发布 如果顺利的话 1 月底或 2 月初我们就会带来下一版的向量化执行引擎了,前面所提到的很多后续规划内容将在下一版本中落地。希望大家届时多多试用捧场~
—— End ——
欢迎关注:

Apache Doris(incubating)官方公众号
凡是过往,皆为序章|Apache Doris 社区 2021 年终回顾
社区人物志|魏祚:道阻且长,行则将至,做有温度的开源项目
从NoSQL到Lakehouse,Apache Doris的13年技术演进之路
相关链接:
Apache Doris官方网站:
http://doris.incubator.apache.org
Apache Doris Githu b:
https://github.com/apache/incubator-doris
Apache Doris 开发者邮件组:
本文分享自微信公众号 - ApacheDoris(gh_80d448709a68)。
如有侵权,请联系 [email protected] 删除。
本文参与“ OSC源创计划 ”,欢迎正在阅读的你也加入,一起分享。