【神经网络】(20) GhostNet 代码复现,网络解析,附TensorFlow完整代码
大家好,今天和各位分享一下如何使用 TensorFlow 构建 GhostNet 轻量化卷积神经网络模型。
GhostNet 相比于普通的卷积神经网络在生成特征图时使用了更少的参数。它提出的动机是为了改善神经网络中特征图存在着冗余的现象。神经网络中的特征图存在着一定程度上的冗余,这些冗余的特征图一定程度上来说,也增强了网络对特征理解的能力,对于一个成功的模型来说这些冗余的特征图也是必不可少的。相比于有些轻量化网络去除掉这些冗余的特征图,GhostNet 选择低成本的办法来保留它们。
GhostNet 的结构类似 MobileNetV3,感兴趣的可以看一下:https://blog.csdn.net/dgvv4/article/details/123476899
1. Ghost 基本单元
虽然 Shufflenet 和 Mobilenet 为了减少参数量使用了 1*1 的逐点卷积方式,但是 Ghonstnet 的作者认为 1*1 卷积还是会产生一定的计算量,并且发现许多的卷积神经网络并没有考虑到经过多次卷积后会存在特征冗余的现象。为了解决上述两个问题,作者提出了 Ghost 基本单元。
Ghost 基本单元采用了一系列的线性变换来生成特征图而不是采用卷积的方式生成特征图,这样可以减少网络的计算量。图 a 为传统的卷积生成特征图的方式,图 b 为 Ghost 模块产生特征图的方式。
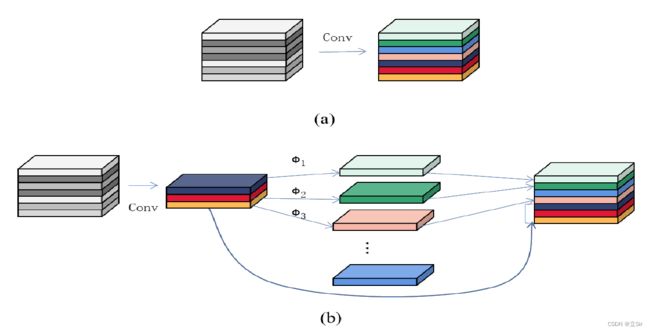
如图 b 所示,假设输入特征图的 shape 为 [5,5,6],首先对输入特征图使用 1*1 卷积下降通道数,shape 变为 [5,5,3];再使用 3*3 深度卷积对每个通道特征图提取特征,shape 为 [5,5,3],可以看作是经过前一层的一系列线性变换得到的;最后将两次卷积的输出特征图在通道维度上堆叠,shape 变为 [5,5,6]
GhostNet 模块在计算复杂度低,参数量少的情况下生成了和标准卷积一样大小的特征图。
代码如下:
#(2)Ghost模块
'''
inputs: 代表输入特征图
exp: 代表该模块的最终的输出通道数
ratio: 1*1卷积通道数下降的倍数, 一般为2,
保证1*1卷积和3*3深度卷积后的堆叠结果的通道数等于最终的输出通道数
'''
def ghost_module(inputs, exp, ratio, relu=True):
# 第一次卷积需要下降的通道数
out_channel = math.ceil(exp / ratio)
# 1*1卷积下降通道数,浓缩特征信息
conv_x = layers.Conv2D(out_channel, kernel_size=(1,1), strides=1, padding='same', use_bias=False)(inputs)
# 批标准化
conv_x = layers.BatchNormalization()(conv_x)
# 是否需要做激活函数
if relu is True:
conv_x = layers.Activation('relu')(conv_x)
# 3*3深度卷积(线性变换)获得相似的特征图
linear_x = layers.DepthwiseConv2D(kernel_size=(3,3), strides=1, padding='same', use_bias=False)(conv_x)
# 批标准化
linear_x = layers.BatchNormalization()(linear_x)
# 是否需要激活函数
if relu is True:
linear_x = layers.Activation('relu')(linear_x)
# 将1*1卷积得到的特征图和3*3深度卷积线性变换得到的特征图在通道维度上堆叠
x = layers.concatenate([conv_x, linear_x], axis=-1)
return x2. SE注意力机制
SE 注意力机制通过关注网络中各个通道之间的关系来提升了网络的性能。首先建立了各个通道的关联性,之后通过对不同通道特征的不同的响应完成自适应的校准后,学习到了各个通道的重要程度,以此来加强重要通道的权重,降低不重要通道的权重,提升网络的性能,让神经网络使用全局的信息来加强有用的特征,同时抑制无用的特征。
计算步骤如下:
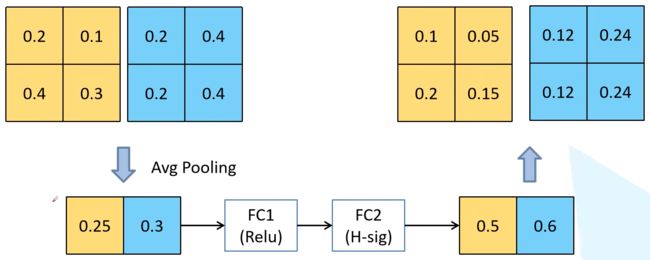
(1)先将特征图进行全局平均池化,特征图有多少个通道,那么池化结果(一维向量)就有多少个元素,[h, w, c]==>[None, c]。
(2)然后经过两个全连接层得到输出向量。第一个全连接层的输出通道数等于原输入特征图的通道数的1/4;第二个全连接层的输出通道数等于原输入特征图的通道数。即先降维后升维。
(3)全连接层的输出向量可理解为,向量的每个元素是对每张特征图进行分析得出的权重关系。比较重要的特征图就会赋予更大的权重,即该特征图对应的向量元素的值较大。反之,不太重要的特征图对应的权重值较小。
(4)第一个全连接层使用ReLU激活函数,第二个全连接层使用 hard_sigmoid 激活函数
(5)经过两个全连接层得到一个由channel个元素组成的向量,每个元素是针对每个通道的权重,将权重和原特征图的对应相乘,得到新的特征图数据
以下图为例,特征图经过两个全连接层之后,比较重要的特征图对应的向量元素的值就较大。将得到的权重和对应特征图中的所有元素相乘,得到新的输出特征图
代码如下,为了减小计算量,使用1*1卷积层代替全连接层
#(1)SE注意力机制
'''
第一个卷积层的输出通道数等于原输入特征图的通道数的 1/4 ;
第二个卷积层的输出通道数等于原输入特征图的通道数。即先降维后升维。
'''
def se_block(inputs):
sequeeze = inputs.shape[-1] // 4 # 第一个1*1卷积下降的通道数
excitation = inputs.shape[-1] # 第二个1*1卷积上升的通道数
# 全局平均池化[b,h,w,c]==>[b,c]
x = layers.GlobalAveragePooling2D()(inputs)
# 增加宽高维度的信息[b,c]==>[b,1,1,c]
x = layers.Reshape(target_shape=[1, 1, x.shape[-1]])(x)
# 卷积下降通道数[b,1,1,c]==>[b,1,1,c//4]
x = layers.Conv2D(sequeeze, kernel_size=(1,1), strides=1, padding='same', use_bias=False)(x)
# relu激活
x = layers.Activation('relu')(x)
# 卷积上升通道数[b,1,1,c//4]==>[b,1,1,c]
x = layers.Conv2D(excitation, kernel_size=(1,1), strides=1, padding='same', use_bias=False)(x)
# hard_sigmoid函数激活,用于权重向量归一化
x = layers.Activation('hard_sigmoid')(x)
# 将特征图通道权重向量和输入特征图逐通道相乘
out = layers.Multiply()([inputs, x])
return out3. Ghost 残差模块
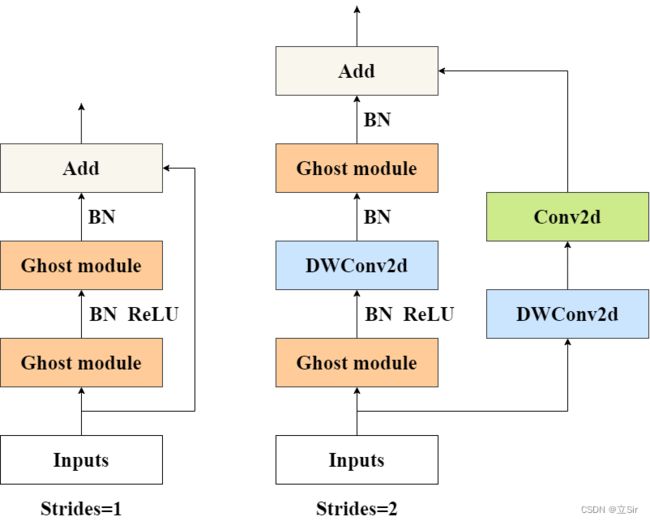
Ghost 残差模块有两种类型,strides=1 的基本模块和 strides=2 的下采样模块。
在 strides=1 的模块中,主干部分由两个 Ghost 模块串联而成,第一个 Ghost 模块上升通道数,第二个 Ghost 模块压缩通道数,使得输入特征图通道数和第二个卷积块的输出特征图的通道数相同。如果此时这两个特征图的 shape 相同,就使用残差连接输入和输出。
在 strides=2 的模块中,主干部分由两个 Ghost 模块和一个 深度卷积 组成。第一个 Ghost 模块上升通道数;在高维空间下使用深度卷积下采样,压缩特征图的宽高;第二个 Ghost 模块压缩通道数。在残差边部分,对输入特征图先使用深度卷积压缩宽高,再使用1*1卷积调整通道,使得输入和输出特征图的shape相同。
代码如下:
#(3)构建瓶颈结构
'''
inputs: 输入特征图
outputs_channel: 该模块的输出通道数
kernel: 深度卷积下采样时所需的卷积核尺寸
strides: 是否需要下采样
exp_channel: Ghost模块的输出通道数, 一般比整个模块的通道数要多, 类似于倒残差结构
ratio: Ghost模块中第一个1*1卷积下降通道数的倍数, 一般为2
se: 瓶颈模块中是否使用SE注意力机制
'''
def bneck(inputs, outputs_channel, kernel, strides, exp_channel, ratio, se):
# 经过一个Ghost模块提取特征
x = ghost_module(inputs, exp=exp_channel, ratio=ratio, relu=True)
# 是否下采样压缩宽高
if strides > 1:
# 步长为2的深度卷积
x = layers.DepthwiseConv2D(kernel_size=kernel, strides=strides, padding='same', use_bias=False)(x)
# 批标准化
x = layers.BatchNormalization()(x)
# 是否使用SE注意力机制
if se is True:
x = se_block(x)
# Ghost模块特征提取, 指定输出通道数, 降维时不需要做非线性激活会破坏特征
x = ghost_module(x, exp=outputs_channel, ratio=ratio, relu=False)
# 若不进行下采样strides=1,且输入和输出特征图的shape相同,残差连接输入和输出
if strides == 1 and inputs.shape[-1] == x.shape[-1]:
res = inputs
# 如经过了下采样strides=2,那么需要对残差边部分进行卷积压缩宽高;如果strides=1,那么只需要调整通道
else:
# 对输入特征图进行深度卷积下采样
res = layers.DepthwiseConv2D(kernel_size=kernel, strides=strides, padding='same', use_bias=False)(inputs)
# 批标准化
res = layers.BatchNormalization()(res)
# 1*1卷积调整通道数
res = layers.Conv2D(filters=outputs_channel, kernel_size=(1,1), strides=1, padding='same', use_bias=False)(res)
# 批标准化
res = layers.BatchNormalization()(x)
# 残差连接
out = layers.Add()([x, res])
return out4. 完整代码展示
4.1 网络结构
GhostNet 的网络结构如下图所示,exp 代表残差结构中第一个 Ghost 模块上升的通道数,out 代表一个残差结构的输出通道数,SE 代表是否使用SE注意力模块。

4.2 代码展示
根据网络结构图把每一层搭建出来,代码如下:
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import math
from keras_flops import get_flops # 用于计算浮点运算量,安装:pip install keras_flops
#(1)SE注意力机制
'''
第一个卷积层的输出通道数等于原输入特征图的通道数的 1/4 ;
第二个卷积层的输出通道数等于原输入特征图的通道数。即先降维后升维。
'''
def se_block(inputs):
sequeeze = inputs.shape[-1] // 4 # 第一个1*1卷积下降的通道数
excitation = inputs.shape[-1] # 第二个1*1卷积上升的通道数
# 全局平均池化[b,h,w,c]==>[b,c]
x = layers.GlobalAveragePooling2D()(inputs)
# 增加宽高维度的信息[b,c]==>[b,1,1,c]
x = layers.Reshape(target_shape=[1, 1, x.shape[-1]])(x)
# 卷积下降通道数[b,1,1,c]==>[b,1,1,c//4]
x = layers.Conv2D(sequeeze, kernel_size=(1,1), strides=1, padding='same', use_bias=False)(x)
# relu激活
x = layers.Activation('relu')(x)
# 卷积上升通道数[b,1,1,c//4]==>[b,1,1,c]
x = layers.Conv2D(excitation, kernel_size=(1,1), strides=1, padding='same', use_bias=False)(x)
# hard_sigmoid函数激活,用于权重向量归一化
x = layers.Activation('hard_sigmoid')(x)
# 将特征图通道权重向量和输入特征图逐通道相乘
out = layers.Multiply()([inputs, x])
return out
#(2)Ghost模块
'''
inputs: 代表输入特征图
exp: 代表该模块的最终的输出通道数
ratio: 1*1卷积通道数下降的倍数, 一般为2,
保证1*1卷积和3*3深度卷积后的堆叠结果的通道数等于最终的输出通道数
'''
def ghost_module(inputs, exp, ratio, relu=True):
# 第一次卷积需要下降的通道数
out_channel = math.ceil(exp / ratio)
# 1*1卷积下降通道数,浓缩特征信息
conv_x = layers.Conv2D(out_channel, kernel_size=(1,1), strides=1, padding='same', use_bias=False)(inputs)
# 批标准化
conv_x = layers.BatchNormalization()(conv_x)
# 是否需要做激活函数
if relu is True:
conv_x = layers.Activation('relu')(conv_x)
# 3*3深度卷积(线性变换)获得相似的特征图
linear_x = layers.DepthwiseConv2D(kernel_size=(3,3), strides=1, padding='same', use_bias=False)(conv_x)
# 批标准化
linear_x = layers.BatchNormalization()(linear_x)
# 是否需要激活函数
if relu is True:
linear_x = layers.Activation('relu')(linear_x)
# 将1*1卷积得到的特征图和3*3深度卷积线性变换得到的特征图在通道维度上堆叠
x = layers.concatenate([conv_x, linear_x], axis=-1)
return x
#(3)构建瓶颈结构
'''
inputs: 输入特征图
outputs_channel: 该模块的输出通道数
kernel: 深度卷积下采样时所需的卷积核尺寸
strides: 是否需要下采样
exp_channel: Ghost模块的输出通道数, 一般比整个模块的通道数要多, 类似于倒残差结构
ratio: Ghost模块中第一个1*1卷积下降通道数的倍数, 一般为2
se: 瓶颈模块中是否使用SE注意力机制
'''
def bneck(inputs, outputs_channel, kernel, strides, exp_channel, ratio, se):
# 经过一个Ghost模块提取特征
x = ghost_module(inputs, exp=exp_channel, ratio=ratio, relu=True)
# 是否下采样压缩宽高
if strides > 1:
# 步长为2的深度卷积
x = layers.DepthwiseConv2D(kernel_size=kernel, strides=strides, padding='same', use_bias=False)(x)
# 批标准化
x = layers.BatchNormalization()(x)
# 是否使用SE注意力机制
if se is True:
x = se_block(x)
# Ghost模块特征提取, 指定输出通道数, 降维时不需要做非线性激活会破坏特征
x = ghost_module(x, exp=outputs_channel, ratio=ratio, relu=False)
# 若不进行下采样strides=1,且输入和输出特征图的shape相同,残差连接输入和输出
if strides == 1 and inputs.shape[-1] == x.shape[-1]:
res = inputs
# 如经过了下采样strides=2,那么需要对残差边部分进行卷积压缩宽高;如果strides=1,那么只需要调整通道
else:
# 对输入特征图进行深度卷积下采样
res = layers.DepthwiseConv2D(kernel_size=kernel, strides=strides, padding='same', use_bias=False)(inputs)
# 批标准化
res = layers.BatchNormalization()(res)
# 1*1卷积调整通道数
res = layers.Conv2D(filters=outputs_channel, kernel_size=(1,1), strides=1, padding='same', use_bias=False)(res)
# 批标准化
res = layers.BatchNormalization()(x)
# 残差连接
out = layers.Add()([x, res])
return out
#(4)主干网络
'''
input_shape: 代表输入特征图的尺寸
classes: 代表分类类别数量
ratio: Ghost模块中第一个1*1卷积下降通道数的倍数, 一般为2
'''
def ghostnet(input_shape, classes, ratio=2):
# 构造输入层[224,224,3]
inputs = keras.Input(shape=input_shape)
# 标准卷积[224,224,3]==>[112,112,16]
x = layers.Conv2D(filters=16, kernel_size=(3,3), strides=2, padding='same', use_bias=False)(inputs)
# 批标准化
x = layers.BatchNormalization()(x)
# relu激活
x = layers.Activation('relu')(x)
# [112,112,16]==>[112,112,16]
x = bneck(x, outputs_channel=16, kernel=(3,3), strides=1, exp_channel=16, ratio=ratio, se=False)
# [112,112,16]==>[56,56,24]
x = bneck(x, outputs_channel=24, kernel=(3,3), strides=2, exp_channel=48, ratio=ratio, se=False)
# [56,56,24]==>[56,56,24]
x = bneck(x, outputs_channel=24, kernel=(3,3), strides=1, exp_channel=72, ratio=ratio, se=False)
# [56,56,24]==>[28,28,40]
x = bneck(x, outputs_channel=40, kernel=(5,5), strides=2, exp_channel=72, ratio=ratio, se=True)
# [28,28,40]==>[28,28,40]
x = bneck(x, outputs_channel=40, kernel=(5,5), strides=1, exp_channel=120, ratio=ratio, se=True)
# [28,28,40]==>[14,14,80]
x = bneck(x, outputs_channel=80, kernel=(3,3), strides=2, exp_channel=240, ratio=ratio, se=False)
# [14,14,80]==>[14,14,80]
x = bneck(x, outputs_channel=80, kernel=(3,3), strides=1, exp_channel=200, ratio=ratio, se=False)
# [14,14,80]==>[14,14,80]
x = bneck(x, outputs_channel=80, kernel=(3,3), strides=1, exp_channel=184, ratio=ratio, se=False)
# [14,14,80]==>[14,14,80]
x = bneck(x, outputs_channel=80, kernel=(3,3), strides=1, exp_channel=184, ratio=ratio, se=False)
# [14,14,80]==>[14,14,112]
x = bneck(x, outputs_channel=112, kernel=(3,3), strides=1, exp_channel=480, ratio=ratio, se=True)
# [14,14,112]==>[14,14,112]
x = bneck(x, outputs_channel=112, kernel=(3,3), strides=1, exp_channel=672, ratio=ratio, se=True)
# [14,14,112]==>[7,7,160]
x = bneck(x, outputs_channel=160, kernel=(5,5), strides=2, exp_channel=672, ratio=ratio, se=True)
# [7,7,160]==>[7,7,160]
x = bneck(x, outputs_channel=160, kernel=(5,5), strides=1, exp_channel=960, ratio=ratio, se=False)
# [7,7,160]==>[7,7,160]
x = bneck(x, outputs_channel=160, kernel=(5,5), strides=1, exp_channel=960, ratio=ratio, se=True)
# [7,7,160]==>[7,7,160]
x = bneck(x, outputs_channel=160, kernel=(5,5), strides=1, exp_channel=960, ratio=ratio, se=False)
# [7,7,160]==>[7,7,160]
x = bneck(x, outputs_channel=160, kernel=(5,5), strides=1, exp_channel=960, ratio=ratio, se=True)
# 1*1卷积降维[7,7,160]==>[7,7,960]
x = layers.Conv2D(filters=960, kernel_size=(1,1), strides=1, padding='same', use_bias=False)(x)
# 批标准化
x = layers.BatchNormalization()(x)
# relu激活
x = layers.Activation('relu')(x)
# [7,7,960]==>[None,960]
x = layers.GlobalAveragePooling2D()(x)
# 增加宽高维度[None,960]==>[1,1,960]
x = layers.Reshape(target_shape=(1,1,x.shape[-1]))(x)
# 1*1卷积[1,1,960]==>[1,1,1280]
x = layers.Conv2D(filters=1280, kernel_size=(1,1), strides=1, padding='same', use_bias=False)(x)
# 批标准化
x = layers.BatchNormalization()(x)
# relu激活
x = layers.Activation('relu')(x)
# 1*1卷积分类[1,1,1280]==>[1,1,classes]
x = layers.Conv2D(filters=classes, kernel_size=(1,1), strides=1, padding='same', use_bias=False)(x)
# 删除宽高维度[b,1,1,classes]==>[b,classes]
outputs = tf.squeeze(x, axis=[1,2])
# 构建模型
model = keras.Model(inputs, outputs)
# 返回模型
return model
#(5)接收模型
if __name__ == '__main__':
input_shape = [224,224,3] # 输入图像shape
classes = 1000 # 分类数
# 接收模型结构
model = ghostnet(input_shape, classes)
# 查看模型结构及参数量 5,164,488
model.summary()
# 查看浮点计算量 277905264
print('flops:', get_flops(model, batch_size=1))
查看网络的参数量和计算量
_________________________________________________________________
Total params: 5,164,488
Trainable params: 5,140,504
Non-trainable params: 23,984
flops: 277905264
_________________________________________________________________