数据结构初阶---时间复杂度&&空间
目录
1.什么是数据结构
1.1考考你?
2.算法
2.1什么是算法
2.2算法的复杂度
3.时间复杂度
3.1常见的时间复杂度计算
实例1
实例2
实例3
实例4--冒泡排序的复杂度
实例5----二分查找的复杂度
实例6----阶乘递归的时间复杂度
实例6----阶乘递归的时间复杂度
4.空间复杂度
4.1 冒泡排序的空间复杂度
4.2 阶乘的空间复杂度
4.3 斐波那契数列(递归)的空间复杂度
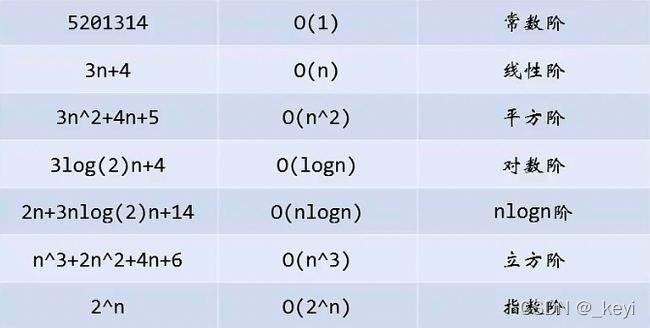
4.4常见的复杂度分析
1.什么是数据结构
数据结构(Data Structure)是计算机存储、组织数据的方式,指相互之间存在一种或多种特定关系的数据元素的集合
比如 通讯录,输入信息的时候需要存储,而数据以什么结构存储呢?
有顺序表,链表,树,哈希表等各种结构,但是每一种结构都有各自的优点和缺点
1.1考考你?
你知道数据库和数据结构的区别吗?
数据库和数据结构的本质都是存储管理数据
但是 但是!!
数据结构 :在内存中存储管理数据 内存:带电存储(断电容易丢失)
数据库 :在磁盘里存储管理数据---->持久化管理
➡️但其实也可以使用文件形式来存储到磁盘 但是在项目中为了方便查找 一般使用数据库
2.算法
2.1什么是算法
算法与数据结构不分家:
一些算法中要用到一些数据结构
某种数据结构的可能要用某种算法来辅助解决
通俗理解:
算法:按要求对数据进行处理,如查找、排序、推荐算法等
二者关系:
你中有我,我中有你 不分家!
2.2算法的复杂度
算法的复杂度:
用来衡量一个算法的好坏,一般从时间和空间两个维度衡量
时间复杂度是主要衡量一个算法的运行快慢
空间复杂度主要衡量为了实现一个算法而需要的额外空间
现在,一般以时间复杂度为主要衡量因素,因为硬件发展太快了
如摩尔定律所说:
集成电路上可以容纳的晶体管数目在大约每经过18个月便会增加一倍。换言之,处理器的性能每隔两年翻一倍
3.时间复杂度
时间复杂度的定义:
在计算机科学中,算法的时间复杂度是一个函数,它定量描述了该算法的运行时间。一
个算法执行所耗费的时间,从理论上说,是不能算出来的,只有你把你的程序放在机器上跑起来,才能知道。但是我们需要每个算法都上机测试吗?是可以都上机测试,但是这很麻烦,所以才有了时间复杂度这个分析方式。一个算法所花费的时间与其中语句的执行次数成正比例,算法中的基本操作的执行次数,为算法的时间复杂度。
即:找到某条基本语句与问题规模N之间的数学表达式,就是算出了该算法的时间复杂度。
接下来看几个例子:
计算一下Func1中++count语句总共执行了多少次?
void Func1(int N)
{
int count = 0;
for (int i = 0; i < N; ++i)
{
for (int j = 0; j < N; ++j)
{
++count;
}
}
for (int k = 0; k < 2 * N; ++k)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
printf("%d\n",count);
}Func1执行的基本操作次数是:
![]()
N = 10-----> F(N) = 130
N = 100 ------> F(N) = 10210
N = 1000 ----> F(N) = 1002010
但实际上我们计算时间复杂度的时候,并不需要计算精确的执行次数,而只需要大概执行次数,那么这里使用大O 的渐进表示法
大O符号(Big O notation):是用于描述函数渐进行为的数学符号。
推导大O阶方法:
1、用常数1取代运行时间中的所有加法常数。
2、在修改后的运行次数函数中,只保留最高阶项。
3、如果最高阶项存在且不是1,则去除与这个项目相乘的常数。得到的结果就是大O阶。
使用大O的渐进表示法以后,Func1的时间复杂度为:O(N^2)
N = 10 F(N) = 100
N = 100 F(N) = 10000
N = 1000 F(N) = 1000000
通过上面我们会发现大O的渐进表示法去掉了那些对结果影响不大的项,简洁明了的表示出了执行次数。
另外有些算法的时间复杂度存在最好、平均和最坏情况:
最坏情况:任意输入规模的最大运行次数(上界)
平均情况:任意输入规模的期望运行次数
最好情况:任意输入规模的最小运行次数(下界)
例如:在一个长度为N数组中搜索一个数据x
最好情况:1次找到
最坏情况:N次找到
平均情况:N/2次找到
在实际中一般情况关注的是算法的最坏运行情况,所以数组中搜索数据时间复杂度为O(N)
3.1常见的时间复杂度计算
实例1

很容易计算出,循环次数是 2*N+10
利用大O的渐进表示法可以知道,时间复杂度为O(N)
实例2

M和N都是未知数,所以时间复杂度是O(M+N)
当然这里我们不知道M和N的大小关系
如果知道关系的话,
- N>>M,---->O(N)
- N<
实例3

时间复杂度:O(1)
因为循环进行了常数次
实例4--冒泡排序的复杂度

可以发现
最坏的情况下,也就是每一个都需要排序,计算的总次数是 N-1+N2+....+1
也就是等差数列求和-----> (N-1)*N/2------>
冒泡排序最好的情况是O(N)--也就是只是外部循环遍历一边
所以冒泡排序的时间复杂度是O(N^2)
实例5----二分查找的复杂度
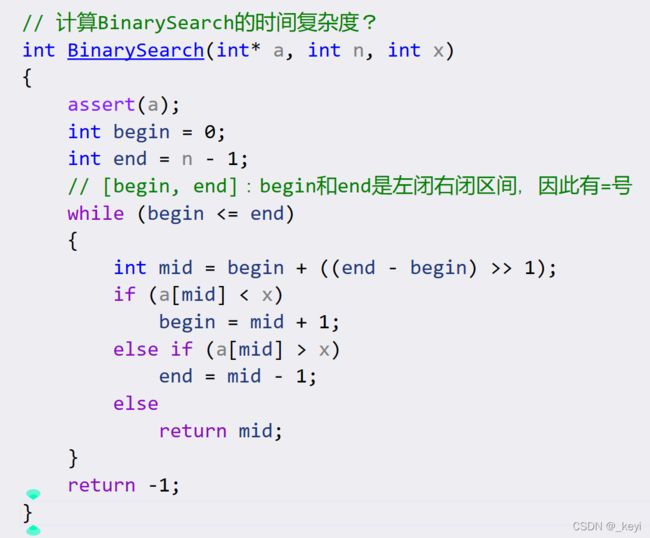
如果有一个区间为N 的查找范围
每一次查找都会舍掉一半的范围,如果查找次数为K
那么2的K次方就是N
所以 查找次数就是log2 N(一般我们写成log N
所以时间复杂度是log N
(涉及到奇偶问题可以不考虑,因为时间复杂度本来计算的就是大概次数)
实例6----阶乘递归的时间复杂度

调用函数也是一种时间的消耗
调用N-1次函数 所以时间复杂度是O(N)
实例6----阶乘递归的时间复杂度

分析:
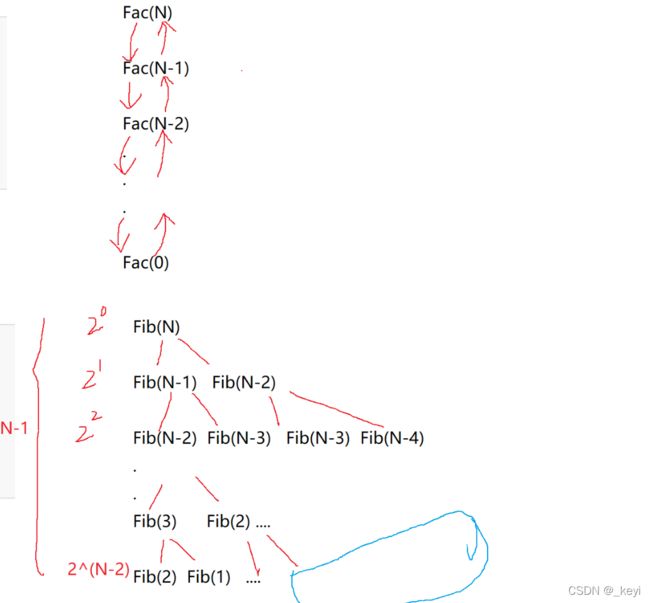
如果忽略右边的提前到达fib(1)和fib(2)的部分,那么计算次数就是
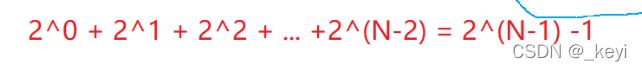
实际上 去掉右边那一部分 也不会造成多大影响,
所以是时间复杂度是O(2^N)----->指数爆炸‘
如果用循环来求斐波那契 时间复杂度为O(N)
瞬间优化了好多!
总结:求解时间复杂度的时候,不要去纠结代码,而要去想这个算法是怎么实现的!
4.空间复杂度
空间复杂度也是一个数学表达式,是对一个算法在运行过程中临时占用存储空间大小的量度
空间复杂度不是程序占用了多少bytes的空间,因为这个也没太大意义,所以空间复杂度算的是变量的个数。
空间复杂度计算规则基本跟实践复杂度类似,也使用大O渐进表示法。
注意:函数运行时所需要的栈空间(存储参数、局部变量、一些寄存器信息等)在编译期间已经确定好了,因此空间复杂度主要通过函数在运行时候显式申请的额外空间来确定。
4.1 冒泡排序的空间复杂度
分析:冒泡排序只是开辟了几个变量,也就是常数个额外空间,所以空间复杂度为O(1)
4.2 阶乘的空间复杂度
分析:利用递归计算阶乘,实际上一直在调用函数,而调用函数会创建临时空间(函数栈帧)
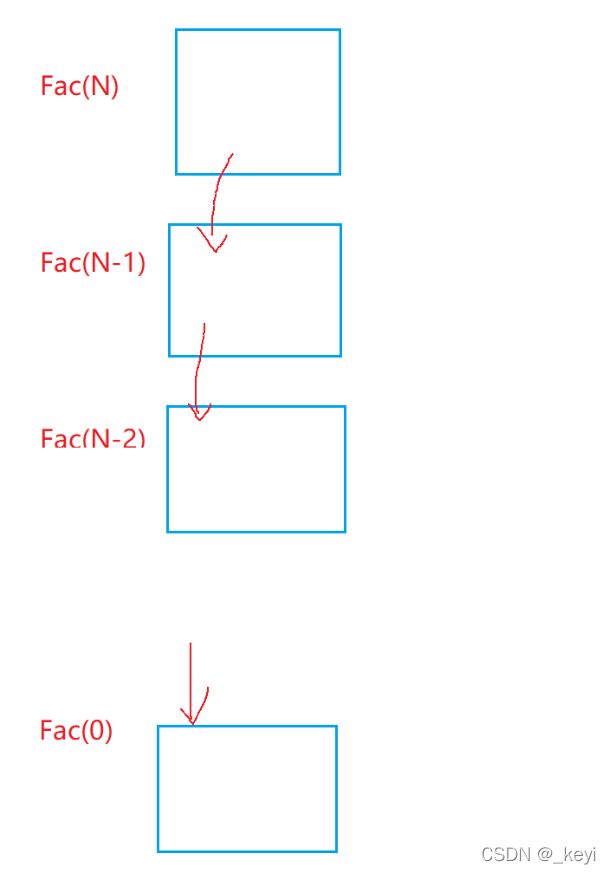
所以空间复杂度为O(N)
4.3 斐波那契数列(递归)的空间复杂度
上面我们分析了斐波那契数列的时间复杂度为O(2^N)
但是这里容易误认为 调用几次函数 那么空间复杂度就是几
但是,注意:!时间会累积,空间不累计!
所以,每一次调用F(5) 使用的是一块空间 所以空间复杂度并没有因为频繁调用F(5)而增加
所以 从F(N).....F(1)一共调用了N 种函数,所以空间复杂度是O(N)!
4.4常见的复杂度分析