【数据结构第二讲(链表中的老大哥----带头双向循环链表)】
小伙伴们好啊!
今天开始数据结构第二讲----带头双向循环链表的学习。
之前我们介绍了顺序表和单链表,但是也知道了它们都有各自的缺点,使用起来总感觉不太完善
没关系,我们今天就来学习一种更加完善的方法!
精彩预告:这种方法可谓是目前所有链表中优点最多,缺点最少的了❗️❗️❗️
打起精神,开始学习吧!
文章目录
- 一、链表的分类
-
- 1.1带头或不带头
- 1.2单向或双向
- 1.3循环或非循环
- 二、带头双向循环链表的优点
- 三、带头双向循环链表接口的实现
-
- 3.1链表的初始化
- 3.2创建新的结点
- 3.3打印链表内容
- 3.4链表的头插
- 3.5链表的头删
- 3.6链表的尾插
- 3.7链表的尾删
- 3.8在指定位置插入
- 3.9在指定位置删除
- 3.10在链表中查找
- 3.11链表的销毁
- 四、总结
一、链表的分类
实际中链表的结构非常多样,以下情况组合起来就有8种链表结构
1.1带头或不带头
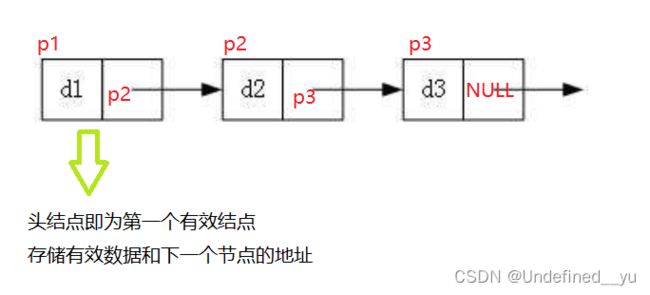
带头是指在第一个存储有效数据的结点的前面还存在一个结点,这个结点并不存储有效数据,它充当的是一个哨兵位的角色,它的任务就是存储第一个有效结点的地址。

不带头也就没有那个哨兵位,头结点就是第一个存储有效数据的结点
1.2单向或双向
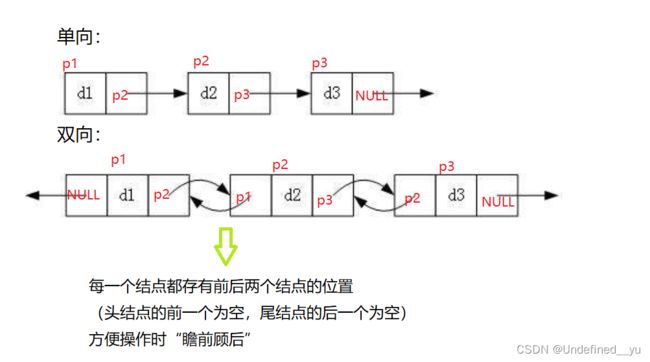
单向链表和双向链表的差异在于----单向链表中除存储有效数据外,还存储一个下一个结点的地址,可以通过地址找到下一个结点,但却不能通过地址找到上一个结点。而双向链表中分别存有上一个结点和下一个结点的地址,可以根据需要找到它们。
1.3循环或非循环
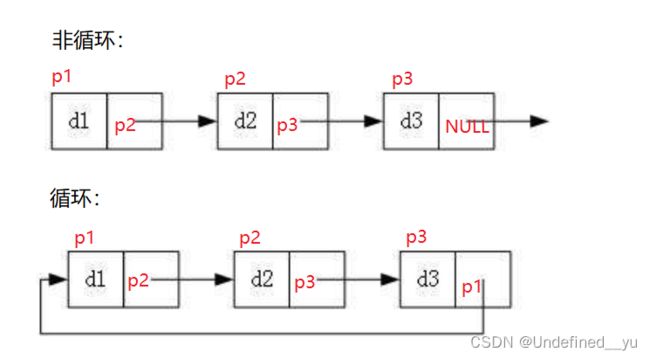
循环链表和非循环链表之间的差别在于----非循环链表的尾结点中存储的“下一个结点的地址”为空,而循环链表的尾结点中存储的“下一个结点的地址”为头结点的地址,即“首尾相连“。
上面的三种链表类型分别又分为两种链表类型,每一种类型相组合,就能得到2 * 2 * 2=8种组合链表。
而我们今天要介绍的就是看起来最复杂,逻辑性最强,但是使用起来最方便的链表----带头双向循环链表。
二、带头双向循环链表的优点
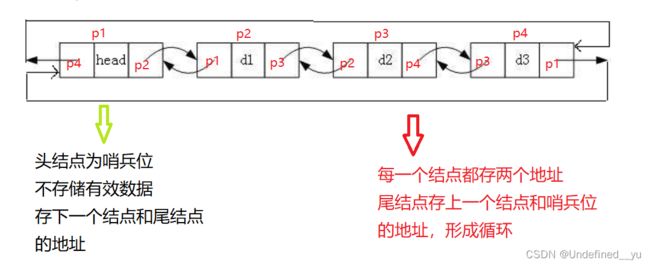
先来看一下带头双向循环链表的结构:
接下来介绍带头双向循环链表的优点:
1、进行尾插或尾删时,可以直接根据哨兵位找到最后一个结点,不用遍历所有结点,时间复杂度最低。
2、在进行链表操作时,不用考虑链表是否为空(两种情况都能用同一套操作指令完成)。
3、在任意位置插入或删除数据时,不用担心找不到相邻的两个结点的位置。
4、可以按需申请和释放空间。
接下来,就一起在接口的实现过程中体验它的优点吧
三、带头双向循环链表接口的实现
这里设定的每一个结点中存储的数据是最简单的(只有一个整形数据),为的是方便大家理解。
但是不用担心,存储的数据虽然不一样,但其核心是不变的,学会了这几个接口,就能应对任何数据在链表中的存储了❗️❗️❗️
先来看一下接口实现索要包含的头文件、结构体定义和具体函数的声明
#define _CRT_SECURE_NO_WARNINGS
#pragma once
#include 3.1链表的初始化
带头双向循环链表的初始化就是----创建一个头结点,该结点并不存储有限数据,它只是存下一个结点和最后一个结点的地址。

ListNode* ListInit()
{
//为哨兵位开辟空间
ListNode* phead = (ListNode*)malloc(sizeof(ListNode));
if (phead == NULL)
{
printf("malloc failed!\n");
return;
}
else
{
phead->next = phead;//哨兵位的next和prev都指向自己,形成循环结构
phead->prev = phead;
}
}
3.2创建新的结点
由于初始化之后的链表只有一个头结点,所以每当要存储新的数据时,就需要再开辟一个新的结点,并把数据存入节点。
ListNode* CreateNode(LTDataType x)
{
ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));
if (newnode == NULL)
{
printf("malloc failed!\n");
return;
}
newnode->data = x;
return newnode;
}
创建结点完毕之后,要将该结点返回,以便可以将该结点尾插到链表的最后。
3.3打印链表内容
打印链表中所存数据,就需要对所有有效结点遍历
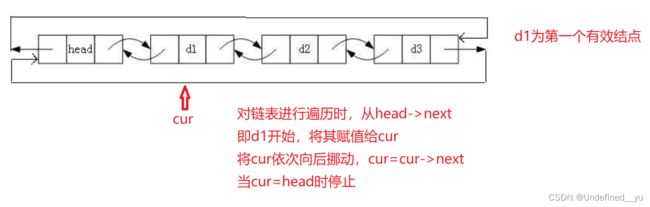
void ListPrint(ListNode* phead)
{
assert(phead);
if (phead->next == phead)
{
printf("链表为空!\n");
return;
}
ListNode* cur = phead->next;
while (cur != phead)
{
printf("%d ", cur->data);
cur = cur->next;
}
printf("\n");
}
3.4链表的头插
头插的本质是----在开辟一个结点之后,将其插在头结点和第一个有效结点之间(不必像顺序表一样将所有元素向后挪动)
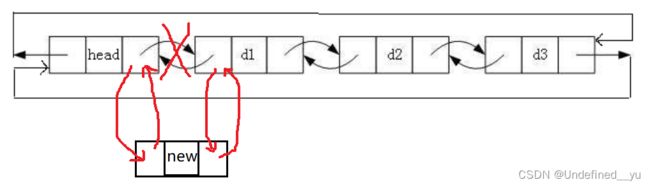
void ListPushFront(ListNode* phead, LTDataType x)
{
assert(phead);
ListNode* newnode = CreateNode(x);
newnode->next = phead->next;
phead->next->prev = newnode;
newnode->prev = phead;
phead->next = newnode;
printf("头插成功!\n");
}
3.5链表的头删
与头插相似,只需调整头结点和第一个、第二个有效结点之间的连接即可,随后再将第一个结点释放。要注意链表为空的情况

void ListPopFront(ListNode* phead)
{
assert(phead);
if (phead->next == phead)
{
printf("链表为空!\n");
return;
}
ListNode* newfirst = phead->next->next;
free(phead->next);
phead->next = NULL;
phead->next = newfirst;
newfirst->prev = phead;
printf("头删成功!\n");
}
3.6链表的尾插
尾插和尾删的原理与前面头插头删的相似,这里就不赘述了。

void ListPushBack(ListNode* phead, LTDataType x)
{
assert(phead);
ListNode* newnode = CreateNode(x);
newnode->prev = phead->prev;
phead->prev->next = newnode;
newnode->next = phead;
phead->prev = newnode;
printf("尾插成功!\n");
}
3.7链表的尾删

void ListPopBack(ListNode* phead)
{
assert(phead);
if (phead->next == phead)
{
printf("链表为空!\n");
return;
}
ListNode* tail = phead->prev;
phead->prev = tail->prev;
tail->prev->next = phead;
free(tail);
tail = NULL;
printf("尾删成功!\n");
}
3.8在指定位置插入
插入分为三种情况,当在第一个结点插入时就相当于头插,在最后一个结点插入时,就相当于尾插,这两种情况直接调用相应的头插尾插函数即可。这里只实现第三种情况----在链表的中间位置插入
void ListInsert(ListNode* pos, LTDataType x)
{
assert(pos);
ListNode* newnode = CreateNode(x);
ListNode* posprev = pos->prev;
pos->prev = newnode;
newnode->next = pos;
newnode->prev = posprev;
posprev->next = newnode;
printf("插入成功!\n");
}
3.9在指定位置删除
跟插入相同,删除也分为头删、尾删和一般情况,这里同样只实现一般情况。
void ListErase(ListNode* pos)
{
assert(pos);
ListNode* posnext = pos->next;
ListNode* posprev = pos->prev;
posnext->prev = posprev;
posprev->next = posnext;
free(pos);
pos = NULL;
printf("删除成功!\n");
}
3.10在链表中查找
查找也要对链表进行遍历,原理比较简单,这里就不赘述了。
void ListFind(ListNode* phead, LTDataType x)
{
assert(phead);
if (phead->next == phead)
{
printf("链表为空!\n");
return;
}
ListNode* cur = phead->next;
while (cur != phead)
{
if (cur->data == x)
{
printf("找到了!\n");
return;
}
cur = cur->next;
}
printf("没找到!\n");
}
3.11链表的销毁
所谓的销毁就是释放空间,短短几行代码,相信大家都能理解,我就不再多说了。
void ListDestory(ListNode* phead)
{
assert(phead);
free(phead);
phead = NULL;
printf("销毁成功!\n");
}
四、总结
带有双向循环链表的名字听起来是链表中最复杂的,但是它的逻辑确实最简单的。熟练之后使用起来也非常方便,所以小伙伴们还是要认真将其中的道理屡清楚,在以后的学习中会非常有用的!
加油吧❗️❗️❗️