doirs数据库连接及数据导入
doris 客户端连接
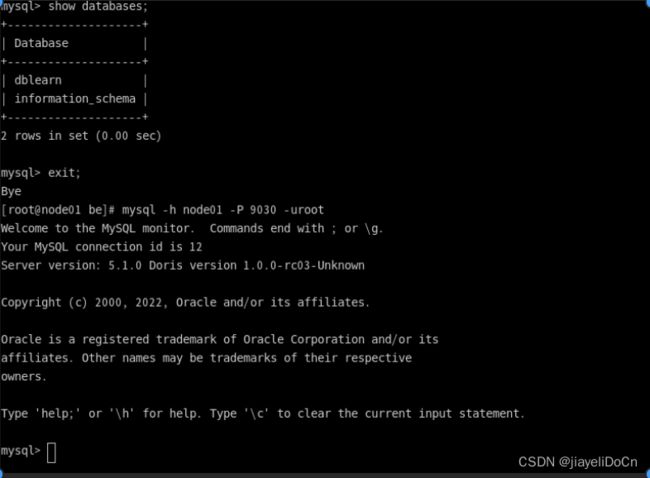
Doris 采用 MySQL 协议进行通信,用户可通过 MySQL client 或者 MySQL JDBC连接到 Doris 集群。选择 MySQL client 版本时建议采用5.1 之后的版本,因为 5.1 之前不能支持长度超过 16 个字符的用户名。
Doris 内置 root 和 admin 用户,密码默认都为空。启动完 Doris 程序之后,可以通过 root 或 admin 用户连接到 Doris 集群。
mysqlClient
mysql -H hostname -P 9030 -uroot
[root@node01 ~]# mysql -h node01 -P 9030 -uroot -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 1
Server version: 5.1.0 Doris version 1.0.0-rc03-Unknown
Copyright (c) 2000, 2022, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
dbeaver | naviecate
doris 实现了mysql协议,故理论上所有支持mysql的客户端都支持doris的连接。
创建库和表,并进行数据导入
创建数据库和表
create database dblearn;
use create database dblearn;
-- 单分区聚合模型表,1个副本,10个table
create table if not exists dblearn.tb_aggsp(
siteid INT DEFAULT '10',
citycode SMALLINT,
username VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(siteid, citycode, username)
DISTRIBUTED BY HASH(siteid) BUCKETS 10
PROPERTIES("replication_num" = "1")
;
-- 多分区聚合模型表
CREATE TABLE `tb_aggmp` (
`envnet_day` date NULL COMMENT "",
`siteid` int(11) NULL DEFAULT "10" COMMENT "",
`citycode` smallint(6) NULL COMMENT "",
`username` varchar(32) NULL DEFAULT " " COMMENT "",
`pv` bigint(20) SUM NULL DEFAULT "0" COMMENT ""
)
ENGINE=OLAP
AGGREGATE KEY(`envnet_day`, `siteid`, `citycode`, `username`)
COMMENT "OLAP"
PARTITION BY RANGE(`envnet_day`)
(
PARTITION p201706 VALUES [('0000-01-01'), ('2017-07-01')),
PARTITION p201707 VALUES [('2017-07-01'), ('2017-08-01')),
PARTITION p201708 VALUES [('2017-08-01'), ('2017-10-01'))
)
DISTRIBUTED BY HASH(`siteid`) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 2",
"in_memory" = "false",
"storage_format" = "V2"
)
导入数据
流式导入
curl --location-trusted -u 用户名:密码 \
-H "label:表名_分区字段" -H "column_separator:分割符" \
-T 数据所在位置 http://fe_host:8030/api/数据库名/表名/_stream_load
导入数据到tbaggmp
数据demo:
2017-07-03|1|1|jim|2
2017-07-05|2|1|grace|2
2017-07-12|3|2|tom|2
2017-07-15|4|3|bush|3
2017-07-12|5|3|helen|3
[root@node01 ~]# curl --location-trusted -u root:root.123 -H "label:tbappmp_20170707" -H "column_separator:|" -T gbaggmp.csv http://127.0.0.1:8030/api/dblearn/tb_aggmp/_stream_load
{
"TxnId": 30,
"Label": "tbappmp_20170707",
"TwoPhaseCommit": "false",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 5,
"NumberLoadedRows": 5,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 110,
"LoadTimeMs": 222,
"BeginTxnTimeMs": 7,
"StreamLoadPutTimeMs": 127,
"ReadDataTimeMs": 0,
"WriteDataTimeMs": 27,
"CommitAndPublishTimeMs": 58
}
mysql> select * from tb_aggmp;
+------------+--------+----------+----------+------+
| envnet_day | siteid | citycode | username | pv |
+------------+--------+----------+----------+------+
| 2017-07-12 | 5 | 3 | helen | 3 |
| 2017-07-03 | 1 | 1 | jim | 2 |
| 2017-07-05 | 2 | 1 | grace | 2 |
| 2017-07-12 | 3 | 2 | tom | 2 |
| 2017-07-15 | 4 | 3 | bush | 3 |
+------------+--------+----------+----------+------+
5 rows in set (0.09 sec)
mysql>
注意事项:
- 采用流式导入建议文件大小限制在 10GB 以内,过大的文件会导致失败重试代价变大。
- 每一批导入数据都需要取一个 Label,Label 最好是一个和一批数据有关的字符串,方便阅读和管理。Doris 基于 Label 保证在一个Database 内,同一批数据只可导入成功一次。失败任务的 Label 可以重用。
- 流式导入是同步命令。命令返回成功则表示数据已经导入,返回失败表示这批数据没有导入。
broker导入
data demo:
1,1,jim,2
2,1,grace,2
3,2,tom,2
4,3,bush,3
5,3,helen,3
将上面的文件导入tb_aggsp;
LOAD LABEL dblearn.tb_aggsp_201707081
(
DATA INFILE("hdfs://node01:8020/tmp/brokerload.data")
INTO TABLE `tb_aggsp` COLUMNS TERMINATED BY ","
)WITH BROKER broker_name
(
"username"="root",
"password"="root"
)
PROPERTIES
(
"timeout"="3600",
"max_filter_ratio"="0.1"
);
mysql> show broker;
+-------------+-----------------+------+-------+---------------------+---------------------+--------+
| Name | IP | Port | Alive | LastStartTime | LastUpdateTime | ErrMsg |
+-------------+-----------------+------+-------+---------------------+---------------------+--------+
| broker_name | 192.168.122.210 | 8000 | true | 2022-05-28 08:43:50 | 2022-05-28 09:17:54 | |
| broker_name | 192.168.122.211 | 8000 | true | 2022-05-28 08:43:50 | 2022-05-28 09:17:54 | |
| broker_name | 192.168.122.212 | 8000 | true | 2022-05-28 08:43:50 | 2022-05-28 09:17:54 | |
+-------------+-----------------+------+-------+---------------------+---------------------+--------+
3 rows in set (0.00 sec)
mysql> LOAD LABEL dblearn.tb_aggsp_201707081
-> (
-> DATA INFILE("hdfs://node01:8020/tmp/brokerload.data")
-> INTO TABLE `tb_aggsp` COLUMNS TERMINATED BY ","
-> )WITH BROKER broker_name
-> (
-> "username"="root",
-> "password"="root"
-> )
-> PROPERTIES
-> (
-> "timeout"="3600",
-> "max_filter_ratio"="0.1"
-> );
Query OK, 0 rows affected (0.02 sec)
mysql> show load where label = "tb_aggsp_201707081";
+-------+--------------------+-----------+---------------------+--------+-----------------------------------------------------+---------------------------------------------------------+-------------------------------------------------------------------------------+---------------------+---------------------+---------------------+---------------------+---------------------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------+--------------+
| JobId | Label | State | Progress | Type | EtlInfo | TaskInfo | ErrorMsg | CreateTime | EtlStartTime | EtlFinishTime | LoadStartTime | LoadFinishTime | URL | JobDetails | TransactionId | ErrorTablets |
+-------+--------------------+-----------+---------------------+--------+-----------------------------------------------------+---------------------------------------------------------+-------------------------------------------------------------------------------+---------------------+---------------------+---------------------+---------------------+---------------------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------+--------------+ | 3005 | |
| 12004 | tb_aggsp_201707081 | FINISHED | ETL:100%; LOAD:100% | BROKER | unselected.rows=0; dpp.abnorm.ALL=0; dpp.norm.ALL=6 | cluster:N/A; timeout(s):3600; max_filter_ratio:0.1 | NULL | 2022-05-28 09:13:50 | 2022-05-28 09:13:57 | 2022-05-28 09:13:57 | 2022-05-28 09:13:57 | 2022-05-28 09:13:59 | NULL | {"Unfinished backends":{"80387aaa2a3645f1-af17f9f6b37a4432":[]},"ScannedRows":6,"TaskNumber":1,"LoadBytes":215,"All backends":{"80387aaa2a3645f1-af17f9f6b37a4432":[10004]},"FileNumber":1,"FileSize":65} | 3006 | {} |
+-------+--------------------+-----------+---------------------+--------+-----------------------------------------------------+---------------------------------------------------------+-------------------------------------------------------------------------------+---------------------+---------------------+---------------------+---------------------+---------------------+------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------+--------------+
2 rows in set (0.01 sec)
mysql> select * from tb_aggsp;
+--------+----------+----------+------+
| siteid | citycode | username | pv |
+--------+----------+----------+------+
| 3 | 2 | tom | 2 |
| 6 | 4 | spj | 6 |
| 2 | 1 | grace | 2 |
| 4 | 3 | bush | 3 |
| 1 | 1 | jim | 2 |
| 5 | 3 | helen | 3 |
+--------+----------+----------+------+
6 rows in set (0.04 sec)
支持的数据导入方式及说明
Palo 目前支持以下4种导入方式:
1. Hadoop Load:基于 MR 进行 ETL 的导入。
2. Broker Load:使用 broker 进行进行数据导入。
3. Mini Load:通过 http 协议上传文件进行批量数据导入。
4. Stream Load:通过 http 协议进行流式数据导入。
5. S3 Load: 通过S3协议直接访问支持S3协议的存储系统进行数据导入, 导入的语法与Broker Load 基本相同。
本帮助主要描述第一种导入方式,即 Hadoop Load 相关帮助信息。其余导入方式可以使用以下命令查看帮助:
!!!该导入方式可能在后续某个版本即不再支持,建议使用其他导入方式进行数据导入。!!!
1. help broker load;
2. help mini load;
3. help stream load;
Hadoop Load 仅适用于百度内部环境。公有云、私有云以及开源环境无法使用这种导入方式。
该导入方式必须设置用于 ETL 的 Hadoop 计算队列,设置方式可以通过 help set property 命令查看帮助。
语法:
LOAD LABEL load_label
(
data_desc1[, data_desc2, ...]
)
[opt_properties];
1. load_label
当前导入批次的标签。在一个 database 内唯一。
语法:
[database_name.]your_label
2. data_desc
用于描述一批导入数据。
语法:
DATA INFILE
(
"file_path1"[, file_path2, ...]
)
[NEGATIVE]
INTO TABLE `table_name`
[PARTITION (p1, p2)]
[COLUMNS TERMINATED BY "column_separator"]
[FORMAT AS "file_type"]
[(column_list)]
[COLUMNS FROM PATH AS (columns_from_path)]
[SET (k1 = func(k2))]
说明:
file_path:
文件路径,可以指定到一个文件,也可以用 * 通配符指定某个目录下的所有文件。通配符必须匹配到文件,而不能是目录。
PARTITION:
如果指定此参数,则只会导入指定的分区,导入分区以外的数据会被过滤掉。
如果不指定,默认导入table的所有分区。
NEGATIVE:
如果指定此参数,则相当于导入一批“负”数据。用于抵消之前导入的同一批数据。
该参数仅适用于存在 value 列,并且 value 列的聚合类型仅为 SUM 的情况。
column_separator:
用于指定导入文件中的列分隔符。默认为 \t
如果是不可见字符,则需要加\\x作为前缀,使用十六进制来表示分隔符。
如hive文件的分隔符\x01,指定为"\\x01"
file_type:
用于指定导入文件的类型,例如:parquet、orc、csv。默认值通过文件后缀名判断。
column_list:
用于指定导入文件中的列和 table 中的列的对应关系。
当需要跳过导入文件中的某一列时,将该列指定为 table 中不存在的列名即可。
语法:
(col_name1, col_name2, ...)
columns_from_path:
用于指定需要从文件路径中解析的字段。
语法:
(col_from_path_name1, col_from_path_name2, ...)
SET:
如果指定此参数,可以将源文件某一列按照函数进行转化,然后将转化后的结果导入到table中。
目前支持的函数有:
strftime(fmt, column) 日期转换函数
fmt: 日期格式,形如%Y%m%d%H%M%S (年月日时分秒)
column: column_list中的列,即输入文件中的列。存储内容应为数字型的时间戳。
如果没有column_list,则按照palo表的列顺序默认输入文件的列。
time_format(output_fmt, input_fmt, column) 日期格式转化
output_fmt: 转化后的日期格式,形如%Y%m%d%H%M%S (年月日时分秒)
input_fmt: 转化前column列的日期格式,形如%Y%m%d%H%M%S (年月日时分秒)
column: column_list中的列,即输入文件中的列。存储内容应为input_fmt格式的日期字符串。
如果没有column_list,则按照palo表的列顺序默认输入文件的列。
alignment_timestamp(precision, column) 将时间戳对齐到指定精度
precision: year|month|day|hour
column: column_list中的列,即输入文件中的列。存储内容应为数字型的时间戳。
如果没有column_list,则按照palo表的列顺序默认输入文件的列。
注意:对齐精度为year、month的时候,只支持20050101~20191231范围内的时间戳。
default_value(value) 设置某一列导入的默认值
不指定则使用建表时列的默认值
md5sum(column1, column2, ...) 将指定的导入列的值求md5sum,返回32位16进制字符串
replace_value(old_value[, new_value]) 将导入文件中指定的old_value替换为new_value
new_value如不指定则使用建表时列的默认值
hll_hash(column) 用于将表或数据里面的某一列转化成HLL列的数据结构
3. opt_properties
用于指定一些特殊参数。
语法:
[PROPERTIES ("key"="value", ...)]
可以指定如下参数:
cluster: 导入所使用的 Hadoop 计算队列。
timeout: 指定导入操作的超时时间。默认超时为3天。单位秒。
max_filter_ratio:最大容忍可过滤(数据不规范等原因)的数据比例。默认零容忍。
load_delete_flag:指定该导入是否通过导入key列的方式删除数据,仅适用于UNIQUE KEY,
导入时可不指定value列。默认为false。
5. 导入数据格式样例
整型类(TINYINT/SMALLINT/INT/BIGINT/LARGEINT):1, 1000, 1234
浮点类(FLOAT/DOUBLE/DECIMAL):1.1, 0.23, .356
日期类(DATE/DATETIME):2017-10-03, 2017-06-13 12:34:03。
(注:如果是其他日期格式,可以在导入命令中,使用 strftime 或者 time_format 函数进行转换)
字符串类(CHAR/VARCHAR):"I am a student", "a"
NULL值:\N
6. S3等对象存储导入参数
fs.s3a.access.key 用户AK,必填
fs.s3a.secret.key 用户SK,必填
fs.s3a.endpoint 用户终端,必填
fs.s3a.impl.disable.cache 是否启用缓存,默认true,可选
Examples:
1. 导入一批数据,指定超时时间和过滤比例。指定导入队列为 my_cluster。
LOAD LABEL example_db.label1
(
DATA INFILE("hdfs://hdfs_host:hdfs_port/user/palo/data/input/file")
INTO TABLE `my_table`
)
PROPERTIES
(
"cluster" = "my_cluster",
"timeout" = "3600",
"max_filter_ratio" = "0.1"
);
其中 hdfs_host 为 namenode 的 host,hdfs_port 为 fs.defaultFS 端口(默认9000)
2. 导入一批数据,包含多个文件。导入不同的 table,指定分隔符,指定列对应关系
LOAD LABEL example_db.label2
(
DATA INFILE("hdfs://hdfs_host:hdfs_port/user/palo/data/input/file1")
INTO TABLE `my_table_1`
COLUMNS TERMINATED BY ","
(k1, k3, k2, v1, v2),
DATA INFILE("hdfs://hdfs_host:hdfs_port/user/palo/data/input/file2")
INTO TABLE `my_table_2`
COLUMNS TERMINATED BY "\t"
(k1, k2, k3, v2, v1)
);
3. 导入一批数据,指定hive的默认分隔符\x01,并使用通配符*指定目录下的所有文件
LOAD LABEL example_db.label3
(
DATA INFILE("hdfs://hdfs_host:hdfs_port/user/palo/data/input/*")
NEGATIVE
INTO TABLE `my_table`
COLUMNS TERMINATED BY "\\x01"
);
4. 导入一批“负”数据
LOAD LABEL example_db.label4
(
DATA INFILE("hdfs://hdfs_host:hdfs_port/user/palo/data/input/old_file)
NEGATIVE
INTO TABLE `my_table`
COLUMNS TERMINATED BY "\t"
);
5. 导入一批数据,指定分区
LOAD LABEL example_db.label5
(
DATA INFILE("hdfs://hdfs_host:hdfs_port/user/palo/data/input/file")
INTO TABLE `my_table`
PARTITION (p1, p2)
COLUMNS TERMINATED BY ","
(k1, k3, k2, v1, v2)
);
6. 导入一批数据,指定分区, 并对导入文件的列做一些转化,如下:
表结构为:
k1 datetime
k2 date
k3 bigint
k4 varchar(20)
k5 varchar(64)
k6 int
假设数据文件只有一行数据,5列,逗号分隔:
1537002087,2018-08-09 11:12:13,1537002087,-,1
数据文件中各列,对应导入语句中指定的各列:
tmp_k1, tmp_k2, tmp_k3, k6, v1
转换如下:
1) k1:将 tmp_k1 时间戳列转化为 datetime 类型的数据
2) k2:将 tmp_k2 datetime 类型的数据转化为 date 的数据
3) k3:将 tmp_k3 时间戳列转化为天级别时间戳
4) k4:指定导入默认值为1
5) k5:将 tmp_k1、tmp_k2、tmp_k3 列计算 md5 值
6) k6:将导入文件中的 - 值替换为 10
LOAD LABEL example_db.label6
(
DATA INFILE("hdfs://hdfs_host:hdfs_port/user/palo/data/input/file")
INTO TABLE `my_table`
PARTITION (p1, p2)
COLUMNS TERMINATED BY ","
(tmp_k1, tmp_k2, tmp_k3, k6, v1)
SET (
k1 = strftime("%Y-%m-%d %H:%M:%S", tmp_k1),
k2 = time_format("%Y-%m-%d %H:%M:%S", "%Y-%m-%d", tmp_k2),
k3 = alignment_timestamp("day", tmp_k3),
k4 = default_value("1"),
k5 = md5sum(tmp_k1, tmp_k2, tmp_k3),
k6 = replace_value("-", "10")
)
);
7. 导入数据到含有HLL列的表,可以是表中的列或者数据里面的列
LOAD LABEL example_db.label7
(
DATA INFILE("hdfs://hdfs_host:hdfs_port/user/palo/data/input/file")
INTO TABLE `my_table`
PARTITION (p1, p2)
COLUMNS TERMINATED BY ","
SET (
v1 = hll_hash(k1),
v2 = hll_hash(k2)
)
);