深度学习-图像分类篇 P4.1 VGG网络-pytorch
哔哩哔哩视频链接
up主附的代码链接
(一)VGG网络详解
1.1 VGG网络简介
1、VGG亮点
 通过堆叠多个3X3的卷积核可以替代大尺度的卷积核,它们拥有相同的感受野。以此减少所需的参数。
通过堆叠多个3X3的卷积核可以替代大尺度的卷积核,它们拥有相同的感受野。以此减少所需的参数。
1.2 感受野
1、感受野的定义
在卷积神经网络中,决定某一层输出结果中一个元素所对应的输入层的区域大小,被称作感受野。
通俗的解释是,输出feature map上的一个单元对应输入层上的区域大小。
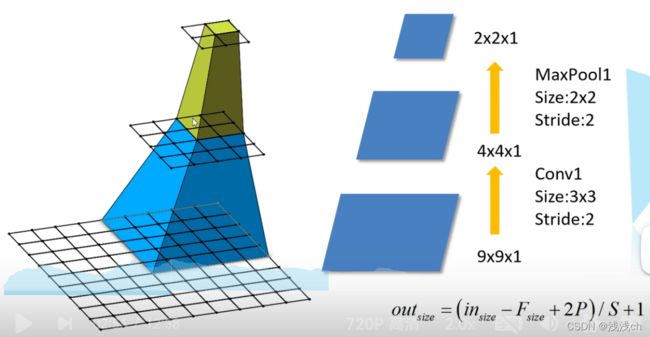
就是说,假设输入的特征层是9X9X1,经过Conv1后,N=(9-3+0)/2+1=4,输出4X4X1;再经过下采样层MaxPool1后N=(4-2+0)/2+1=2,输出2X2X1。如左图所示,最上层的一个格子就对应着第二层的2X2个格子,同时对应第1层的5X5。
2、感受野的计算公式
 最上面一层,也就是F(3)=1,代表1X1的感受野,求F(2)=(1-1)X2+2=2,所以第二层的感受野是2X2的。
最上面一层,也就是F(3)=1,代表1X1的感受野,求F(2)=(1-1)X2+2=2,所以第二层的感受野是2X2的。
3、举例,在VGG网络中所说的3个3X3的卷积核替代7X7的卷积核,两个3X3的卷积核替代5X5的卷积核。
因为VGG中的步距stride=1,所以计算如下:

4、比较3个3X3卷积核与1个7X7卷积核所需的参数个数
7X7的卷积核的channel=C,那么对应的卷积核个数也是C(因为输入输出的channel都等于C),那么对应的是49CXC
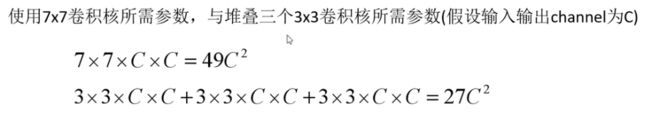 确实是所需要的参数更少。
确实是所需要的参数更少。

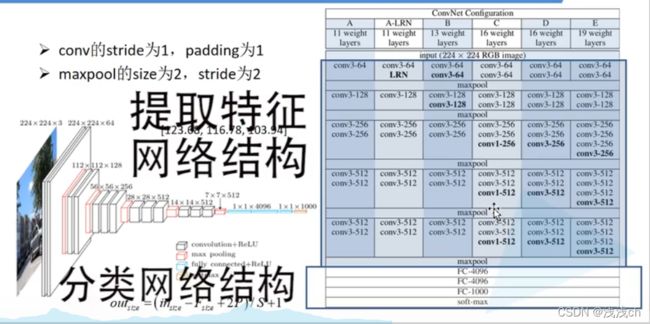
1.3 VGG网络结构图
最常见的是D种结构,左边画的图也是D结构,可以综合着看。因为conv的步距为1,padding为1,所以经过卷积层后计算得到的N不变,也就是宽、高不变。

(二)代码构建VGG网络
我们将构建图中的A、B、D、E四种网络,并分为提取特征网络结构、分类网络结构(也就是下面的3层全连接层)两个部分完成。
2.1 构建网络model.py
1、首先定义cfgs,其中key的值’vgg11’、‘vgg13’、‘vgg16’、'vgg19’分别对应A、B、D、E四种网络结构,'M’对应的是下采样层,其他数字代表3X3的卷积层的卷积核数量。
以’vgg11’为例,首先是1个3X3的卷积层,有64个卷积核;然后是下采样层;然后是1个3X3的卷积层,有128个卷积核;然后又是下采样层;然后是2个3X3的卷积层,有256个卷积核;然后是下采样层;然后是2个3X3的卷积层,有512个卷积核;然后又是下采样层;然后是2个3X3的卷积层,有512个卷积核;最后是下采样层。
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
2、然后对此生成提取特征函数make_features()
首先定义一个空列表layers,因为是GRB图片,所以输入通道in_channels=3;然后遍历传入的cfgs列表,如果是“M”,就传入size=2,步距stride=2的最大下采样层给layers;
如果不是,就传入对应的卷积层(in_channels是输入特征矩阵的深度=3或上一层的输出特征矩阵深度;v表示输出特征矩阵的channel,是从cfg字符串中截取的)。在每个卷积层后面添加一个ReLU激活函数,然后一起加到layers列表后面
最后调用nn.Sequential()方法将列表以非关键字方式传入,打包成一个新的网络结构。
def make_features(cfg: list):
layers = []
in_channels = 3
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(True)]
in_channels = v
return nn.Sequential(*layers)
3、定义类VGG
(1)定义初始化函数init(),将定义好的特征层结构传入,然后定义包含3个全连接层的分类器classifier,使用nn.Sequential()方法打包成一个新的网络结构。首先用Dropout以50%的比例失活一部分神经元,然后线性展平(原图结构的FC1=4096,我们为了减小参数就只输入一半),然后用relu()激活函数处理;然后将上一次线性展平的第二个参数作为输入2048,FC2=2048,传入线性展平函数Linear()。。。
如果init_weights为真,就调用initialize_weights()方法初始化权重。
def __init__(self, features, num_classes=1000, init_weights=False):
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(512*7*7, 2048),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(True),
nn.Linear(2048, num_classes)
)
if init_weights:
self._initialize_weights()
(2)定义_initialize_weights()函数
遍历所有子模块modules()也就是所有层结构,如果模型是Conv2d卷积层,那么调用xavier_uniform_()函数初始化权重,其中如果采用了偏置bias,就将偏置初始化为0;如果模型是Linear全连接层,那么调用xavier_uniform_()函数初始化权重,并初始化偏置为0。
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
# nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
(3)接下来定义前向传播函数forward():
将x传入特征层,展平后传入分类器,最后返回预测标签。
def forward(self, x):
# N x 3 x 224 x 224
x = self.features(x)
# N x 512 x 7 x 7
x = torch.flatten(x, start_dim=1)
# N x 512*7*7
x = self.classifier(x)
return x
(4)定义vgg()函数实例化给定的配置模型
model_name用来实例化哪个模型,比如传入的model_name=“vgg16”,那么将cfgs中这个key对应的列表传入cfg;然后将cfg传入make_features()特征层,**kwargs表示可变长度的字典变量(可以包括分类种类的数量class_num、以及是否初始化权重init_weight)。
def vgg(model_name="vgg16", **kwargs):
try:
cfg = cfgs[model_name]
except:
print("Warning: model number {} not in cfgs dict!".format(model_name))
exit(-1)
model = VGG(make_features(cfg), **kwargs)
return model
2.2 训练网络train.py
训练网络train.py和预测图片的predict.py的代码与上一期AlexNet网络的几乎一样,在此不多赘述。
而且这个网络训练过程比较长,在此也不做演示了,如果可以的话,最好是做成迁移学习,训练自己的网络,这样比较快。