李宏毅机器学习 HW1批注版
Homework1: COVID-19 cases prediction
by 熠熠发光的白
来源网址:https://colab.research.google.com/github/ga642381/ML2021-Spring/blob/main/HW01/HW01.ipynb
Data part
tr_path = 'covid.train.csv' # path to training data
tt_path = 'covid.test.csv' # path to testing data
!gdown --id '19CCyCgJrUxtvgZF53vnctJiOJ23T5mqF' --output covid.train.csv
!gdown --id '1CE240jLm2npU-tdz81-oVKEF3T2yfT1O' --output covid.test.csv
下载部分,从提供的网站将文件下载下来
package import
# PyTorch
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
# For data preprocess
import numpy as np
import csv
import os
# For plotting
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
myseed = 42069 # set a random seed for reproducibility 这个可以让每次运行网络时相同输入的输出是规定的
torch.backends.cudnn.deterministic = True #保证返回的卷积算法是确定的
torch.backends.cudnn.benchmark = False #因为是false,所以不做过多介绍了,反正就是没用到
np.random.seed(myseed)
torch.manual_seed(myseed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(myseed) #cuda加速加载的seed
初始化定义功能(utilities)
def get_device(): #得到是不是能够使用GPU加速的判断条件
''' Get device (if GPU is available, use GPU) '''
return 'cuda' if torch.cuda.is_available() else 'cpu'
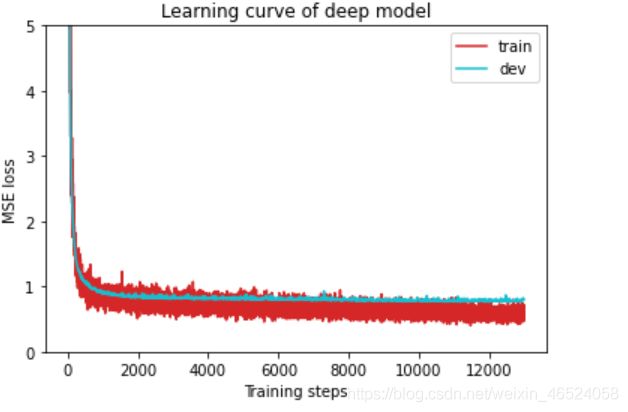
def plot_learning_curve(loss_record, title=''): #绘图功能,可以看python基础学习文件
''' Plot learning curve of your DNN (train & dev loss) '''
total_steps = len(loss_record['train'])
x_1 = range(total_steps)
x_2 = x_1[::len(loss_record['train']) // len(loss_record['dev'])]
figure(figsize=(6, 4))
plt.plot(x_1, loss_record['train'], c='tab:red', label='train')
plt.plot(x_2, loss_record['dev'], c='tab:cyan', label='dev')
plt.ylim(0.0, 5.)
plt.xlabel('Training steps')
plt.ylabel('MSE loss')
plt.title('Learning curve of {}'.format(title))
plt.legend()
plt.show()
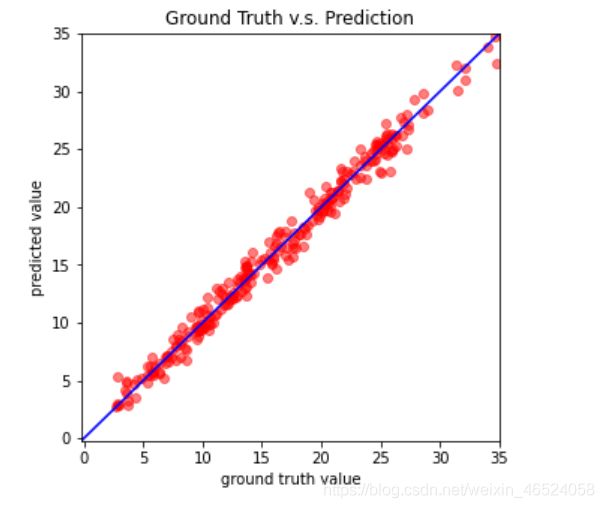
def plot_pred(dv_set, model, device, lim=35., preds=None, targets=None): #绘制DNN预测结果
''' Plot prediction of your DNN '''
if preds is None or targets is None:
model.eval()
preds, targets = [], []
for x, y in dv_set:
x, y = x.to(device), y.to(device)
with torch.no_grad():
pred = model(x)
preds.append(pred.detach().cpu())
targets.append(y.detach().cpu())
preds = torch.cat(preds, dim=0).numpy()
targets = torch.cat(targets, dim=0).numpy()
figure(figsize=(5, 5))
plt.scatter(targets, preds, c='r', alpha=0.5)
plt.plot([-0.2, lim], [-0.2, lim], c='b')
plt.xlim(-0.2, lim)
plt.ylim(-0.2, lim)
plt.xlabel('ground truth value')
plt.ylabel('predicted value')
plt.title('Ground Truth v.s. Prediction')
plt.show()
预处理&数据集定义
class COVID19Dataset(Dataset):
''' Dataset for loading and preprocessing the COVID19 dataset '''
def __init__(self,
path,
mode='train',
target_only=False):
self.mode = mode #初始状况默认为train
# Read data into numpy arrays
with open(path, 'r') as fp:
data = list(csv.reader(fp))
data = np.array(data[1:])[:, 1:].astype(float) #将读入的数据转换为float型的np数组
if not target_only:
feats = list(range(93)) #40+18+18+17
else:
# TODO: Using 40 states & 2 tested_positive features (indices = 57 & 75)
#这个我不会改我去,以后厉害了再来优化吧
pass
if mode == 'test':
# Testing data
# data: 893 x 93 (40 states + day 1 (18) + day 2 (18) + day 3 (17))
data = data[:, feats]
self.data = torch.FloatTensor(data)
else:
# Training data (train/dev sets)
# data: 2700 x 94 (40 states + day 1 (18) + day 2 (18) + day 3 (18))
target = data[:, -1] #取最后一项,即标签项作为最终目标
data = data[:, feats]
# Splitting training data into train & dev sets 这里是按照data是否能够被10整除来进行分类的,如果能的话就归入dev(测试)数据集
if mode == 'train':
indices = [i for i in range(len(data)) if i % 10 != 0]
elif mode == 'dev':
indices = [i for i in range(len(data)) if i % 10 == 0]
# Convert data into PyTorch tensors
self.data = torch.FloatTensor(data[indices]) #将数据转化为pytorch类型,indices不是train里的就是dev里的
self.target = torch.FloatTensor(target[indices])
# Normalize features (you may remove this part to see what will happen)
#标准化参数,揣测没有这个部分以后结果回更不稳定
self.data[:, 40:] = \
(self.data[:, 40:] - self.data[:, 40:].mean(dim=0, keepdim=True)) \
/ self.data[:, 40:].std(dim=0, keepdim=True)
self.dim = self.data.shape[1]
print('Finished reading the {} set of COVID19 Dataset ({} samples found, each dim = {})'
.format(mode, len(self.data), self.dim))
def __getitem__(self, index):
# Returns one sample at a time
if self.mode in ['train', 'dev']:
# For training
return self.data[index], self.target[index]
else:
# For testing (no target)
return self.data[index]
def __len__(self):
# Returns the size of the dataset
return len(self.data)
DataLoader
def prep_dataloader(path, mode, batch_size, n_jobs=0, target_only=False):
''' Generates a dataset, then is put into a dataloader. '''
dataset = COVID19Dataset(path, mode=mode, target_only=target_only) # Construct dataset
dataloader = DataLoader(
dataset, batch_size,
shuffle=(mode == 'train'), drop_last=False, #在数据集不是batch_size的整数倍的时候不考虑丢弃剩余的部分
num_workers=n_jobs, pin_memory=True)
#pin_memory这里指代的是锁页内存,将内存中的Tensor转义到GPU的显存的速度会更快一些,num_workers指的是同时工作的线程,后续会进行定义。
return dataloader
Neural Network
class NeuralNet(nn.Module):
''' A simple fully-connected deep neural network '''
def __init__(self, input_dim):
super(NeuralNet, self).__init__()
# Define your neural network here
# TODO: How to modify this model to achieve better performance?
# A:我还是不会,为什么我这么菜啊..
self.net = nn.Sequential(
nn.Linear(input_dim, 64),
nn.ReLU(),
nn.Linear(64, 1)
)
# Mean squared error loss
self.criterion = nn.MSELoss(reduction='mean')
def forward(self, x):
''' Given input of size (batch_size x input_dim), compute output of the network '''
return self.net(x).squeeze(1) #我不知道这里这么会需要squeeze第二维的
def cal_loss(self, pred, target):
''' Calculate loss '''
# TODO: you may implement L1/L2 regularization here
#以后再说
return self.criterion(pred, target)
training part
def train(tr_set, dv_set, model, config, device):
''' DNN training '''
n_epochs = config['n_epochs'] # Maximum number of epochs
#后面会有超参定义
# Setup optimizer
optimizer = getattr(torch.optim, config['optimizer'])(
model.parameters(), **config['optim_hparas'])
#这里是用于返回对象属性值的,我觉得这里可以理解为,返回torch.optim+(config['optimizer'])(后续定义)
min_mse = 1000. #设置最小的误差,这里故意设置的很大,方便之后进行覆盖操作
loss_record = {'train': [], 'dev': []} # for recording training loss
early_stop_cnt = 0
epoch = 0
while epoch < n_epochs:
model.train() # set model to training mode
for x, y in tr_set: # iterate through the dataloader
optimizer.zero_grad() # set gradient to zero
x, y = x.to(device), y.to(device) # move data to device (cpu/cuda)
pred = model(x) # forward pass (compute output)
mse_loss = model.cal_loss(pred, y) # compute loss
mse_loss.backward() # compute gradient (backpropagation)
optimizer.step() # update model with optimizer
loss_record['train'].append(mse_loss.detach().cpu().item())
# After each epoch, test your model on the validation (development) set.
dev_mse = dev(dv_set, model, device)
if dev_mse < min_mse:
# Save model if your model improved
min_mse = dev_mse
print('Saving model (epoch = {:4d}, loss = {:.4f})'
.format(epoch + 1, min_mse))
torch.save(model.state_dict(), config['save_path']) # Save model to specified path
early_stop_cnt = 0
else:
early_stop_cnt += 1
epoch += 1
loss_record['dev'].append(dev_mse) #展成一维的进行记录
if early_stop_cnt > config['early_stop']:
# Stop training if your model stops improving for "config['early_stop']" epochs.
break
print('Finished training after {} epochs'.format(epoch))
return min_mse, loss_record
validation part
def dev(dv_set, model, device):
model.eval() # set model to evalutation mode
total_loss = 0
for x, y in dv_set: # iterate through the dataloader
x, y = x.to(device), y.to(device) # move data to device (cpu/cuda)
with torch.no_grad(): # disable gradient calculation
pred = model(x) # forward pass (compute output)
mse_loss = model.cal_loss(pred, y) # compute loss
total_loss += mse_loss.detach().cpu().item() * len(x) # accumulate loss
total_loss = total_loss / len(dv_set.dataset) # compute averaged loss
return total_loss
testing part
def test(tt_set, model, device):
model.eval() # set model to evalutation mode
preds = []
for x in tt_set: # iterate through the dataloader
x = x.to(device) # move data to device (cpu/cuda)
with torch.no_grad(): # disable gradient calculation
pred = model(x) # forward pass (compute output)
preds.append(pred.detach().cpu()) # collect prediction
preds = torch.cat(preds, dim=0).numpy() # concatenate all predictions and convert to a numpy array
return preds
超参设置
device = get_device() # get the current available device ('cpu' or 'cuda')
os.makedirs('models', exist_ok=True) # The trained model will be saved to ./models/
target_only = False # TODO: Using 40 states & 2 tested_positive features
# TODO: How to tune these hyper-parameters to improve your model's performance?
config = {
'n_epochs': 3000, # maximum number of epochs
'batch_size': 270, # mini-batch size for dataloader
'optimizer': 'SGD', # optimization algorithm (optimizer in torch.optim)
'optim_hparas': { # hyper-parameters for the optimizer (depends on which optimizer you are using)
'lr': 0.001, # learning rate of SGD
'momentum': 0.9 # momentum for SGD
},
'early_stop': 200, # early stopping epochs (the number epochs since your model's last improvement)
'save_path': 'models/model.pth' # your model will be saved here
}
其实都写的很清楚了,我这里能够想到的一个改法是把batch_size改到256(什么取整),然后把lr改低一点,或者是把early stop改高一点,因为我从来没做过这种优化问题,所以暂时就想到这么多。
加载数据和模型
tr_set = prep_dataloader(tr_path, 'train', config['batch_size'], target_only=target_only)
dv_set = prep_dataloader(tr_path, 'dev', config['batch_size'], target_only=target_only)
tt_set = prep_dataloader(tt_path, 'test', config['batch_size'], target_only=target_only)
#之前都有定义过的,不多赘述了
model = NeuralNet(tr_set.dataset.dim).to(device) # Construct model and move to device
#同样的,也是参考之前的代码进行调用设置
REAL training
model_loss, model_loss_record = train(tr_set, dv_set, model, config, device)
#train函数中自己带有输出部分,所以不需要进行冗余的输出
plot_learning_curve(model_loss_record, title='deep model')
#绘制图像
del model #解除引用功能,这样model就是“空指针”,可以重新被用来引用起来的东西
model = NeuralNet(tr_set.dataset.dim).to(device)
ckpt = torch.load(config['save_path'], map_location='cpu') # Load your best model
model.load_state_dict(ckpt)
plot_pred(dv_set, model, device) # Show prediction on the validation set
Testing
def save_pred(preds, file): #定义了一个写入的程序,将结果写入进去,保存为csv,便于提交
''' Save predictions to specified file '''
print('Saving results to {}'.format(file))
with open(file, 'w') as fp:
writer = csv.writer(fp)
writer.writerow(['id', 'tested_positive'])
for i, p in enumerate(preds):
writer.writerow([i, p])
preds = test(tt_set, model, device) # predict COVID-19 cases with your model
save_pred(preds, 'pred.csv') # save prediction file to pred.csv
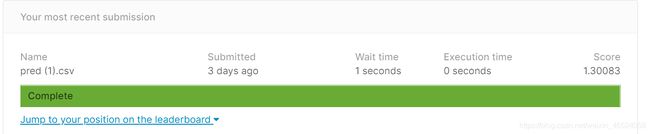
总结
从这个作业就已经能看出我是多菜了(,虽然是第二次写这个文件,但是还是写不出来,呜呜。希望之后能够进行改进。