Mybatis常见的面试题
高频面经汇总:https://blog.csdn.net/qq_40262372/article/details/116075528
8.2 MyBatis面试题总结
8.2.1 #{}与${}的区别
#{}:是sql的参数占位符,Mybatis会将sql中的#{}替换为?,按序给sql的?占位符设置参数值。

这个是根据参数变化不是动态sql(是有if语句之类的sql)
${}:是在数据库配置文件中的变量占位符,属于静态文本替换,比如${Driver}会被静态替换为com.mysql.jdbc.Driver。
8.2.2 Xml映射文件中,除了常见的select/Inserct/update/delete标签之外,还有那些标签?
还有
8.2.3 最佳实践中,通常一个Xml映射文件,都会写一个Dao接口与之对应,请问,这个Dao接口的工作原理是什么?Dao接口里的方法,参数不同时,方法能重载吗?
Dao接口,就是人们常说的Mapper接口,接口的全限名,就是映射文件中的namespace的值,接口的方法名,就是映射文件中MappedStatement的id值,接口方法内的参数,就是传递给sql的参数。Mapper接口是没有实现类的,当调用接口方法时,接口全限名+方法名拼接字符串作为key值,可唯一定位一个MappedStatement。
Dao接口里的方法,是不能重载的,因为是全限名+方法名的保存和寻找策略。
Dao接口的工作原理是JDK动态代理,MyBatis运行时会使用JDK动态代理为Dao接口生成代理proxy独享,代理对象proxy会拦截接口方法,转而执行MappedStatement所代表的sql,然后将sql执行结果返回。
8.2.4 Mybatis是如何进行分页的?分页插件的原理是什么?
1.Mybatis使用RowBounds对象进行分页,它是针对ResultSet结果集执行的内存分离,而非物理分页;
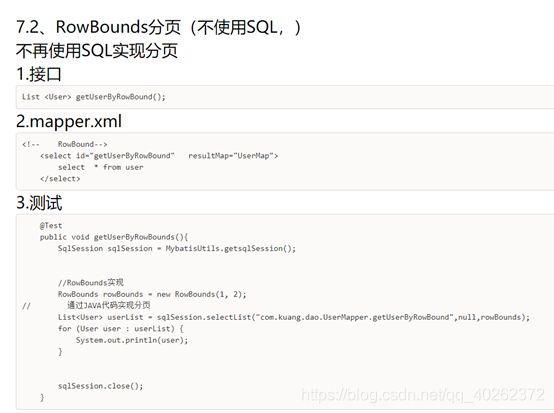
2.直接在sql内直接书写limit进行分页;

3.使用分页插件来完成物理分页。
8.2.5Mybatis动态sql是做什么?都有哪些动态sql?能简述一下动态sql的执行原理不?
Mybatis动态sql可以让我们在xml映射文件内,以标签的形式编写动态sql,完成逻辑判断和动态拼接sql的功能,Mybatis提供了9种动态sql标签
其执行原理为,使用OGNL从sql参数对象中计算表达式的值,根据表达式的值动态拼接sql,以此来完成动态sql的功能。
8.2.6Mybatis是如何将sql执行结果封装为目标对象并返回的?都有那些映射形式?
第一种是用

第二种是使用sql列的别名功能,将列名书写为对象属性名。

有了列名和属性名的映射关系后,Mybatis通过反射创建对象,同时使用反射给对象的属性逐一赋值并返回,那些找不到映射关系的属性,是无法完成赋值的。
8.2.7 Mybatis能执行一对一、一对多的关联查询吗?都有那些实现方式,以及他们之间的区别?
能,Mybatis不仅可以执行一对一、一对多的关联查询,还可以执行多对一,多对多的关联查询,多对一查询,其实就是一对一查询,只需要把selectOne()修改为selectList()即可;多对多查询,其实就是一对多查询,只需要把selectOne()修改为selectList()即可。
关联对象查询,有两种方式:
一种是单独发送一个sql去查询关联对象resultMap,赋给主对象,然后返回主对象;

另一种是使用嵌套查询,嵌套查询的含义为使用join查询,一部分列是A对象的属性值,另外一部分是关联对象B的属性值,好处是只发一个sql查询,就可以把主对象和其关联对象查出来。

8.2.8 Mybatis是否支持延迟加载?如果支持,它的实现原理是什么?
Mybatis仅支持association关联对象和collection关联集合对象的延迟加载,association指的是一对一,collection值的就是一对多查询。在Mybatis配置文件中,可以配置是否启用延迟加载lazyLoadingEnabled=truefalse。
它的原理是,使用CGLIB创建目标的代理对象,当调用目标方法时,进入拦截器方法,比如调用a.getB.getName(),拦截器invoke()方法a.getB()是null值,那么就会单独发送事先保存好的查询关联B对象的sql,把B查询上来,然后调用a.setB(b),于是a的对象b属性就有值了,接着完成a.getB().getName()方法的调用。这就是延迟加载的基本原理。
8.2.9Mybatis的XML映射文件中,不同的XML映射文件,id是否可以重复?
不同的XML映射文件,如果配置了Namespace,那么Id可以重复;如果没有配置namespace,那么Id不能重复;毕竟Namespace不是必须加的,只是最佳实践而已。
原因就是namespace+id是Map
8.2.10Mybatis都有哪些Executor执行器?他们之间的区别是什么?
有三种:SimpleExecutor、ReuseExector、BatchExector。
SimpleExecutor:每执行一次update或select,就会开启Statement对象,用完立刻关闭Statement对象。
ReuseExecutor:执行update或select,以sql作为key查找Statement对象,存在就使用,不存在就创建,用完后,不关闭Statement对象,而是放置于Map
BatchExecutor:执行Update(没有select,JDBC批处理不支持select),将所有sql都添加到批处理中(addBatch),等待统一执行(executorBatch()),它缓存了多个Statement对象,每个Statement对象都是addBatch()完毕后,等待逐一执行executeBatch()批处理,与JDBC批处理相同。
8.2.11 Mybatis中如何制定使用哪一种Executor执行器?
在Mybatis配置文件中,可以指定默认的ExecutorType执行器类型,也可以手动给DefalutSqlSessionFactory的创建SqlSession的方法传递ExecutorType类型参数。
8.2.12Mybatis是否可以映射Enum枚举类?
Mybatis可以映射枚举类,不但可以映射枚举类,Mybatis可以映射任何对象到表的一列上。映射方法为自定义一个TypeHandler,实现TypeHandler的setParameter()和getResult()接口方法。TypeHandler有两个作用,一是完成从javaType至jdbcType的转换,二是完成jdbcType至javaType的转换,体现为setParameter()和getResult()两个方法,分别代表设置sql问好占位符参数和获取列查询结果。
8.2.13 Mybatis映射文件中,如果A标签通过include引用了B标签的内容,请问B标签的内容是否定义在A标签之后,还是必须定义为A之前?
虽然Mybatis解析Xml映射文件是按顺序接续的,但是,被引用的B标签依然可以定义在任何地方,Mybatis都可以正确识别。
原理是,当我A包含了B的时候,Mybatis解析到A的时候,发现B还没有,会将A设置为未解析状态,然后继续解析下面的标签,待所有标签都解析完全后,再去解析一次未解析的标签。
8.2.14 Mybatis与Spring dataJpa的区别
首先,SprigData JPA可以理解为对Jpa规范再次封装抽象,底层还是使用hibernate框架的JPA技术实现。
JPA默认使用Hibernate技术实现,所以,一般使用Springdata JPA也就是hibernate。
Hibernate是一个开放源代码的对象关系映射框架,他对JDBC进行非常轻量级的对象封装。它将POJO与数据库表建立映射关系,是一个全自动的orm框架,hibernate可以自动生成SQL语句,使得Java成员可以随心所欲的使用对象编程思维来操纵数据库。
Mybatis是一款优秀的持久层框架,它支持定制化SQL、储存过程以及高级映射。Mybatis避免了几乎所有的JDBC代码和手动设置参数以及获取结果集。Mybatis可以使用简单的XML或者注解来配置和映射原生信息,将接口和Java的entity对象映射成数据库中的记录。
所以,我们说jpa和mybatis的区别也就说hibernate和mybatis的区别。
Mybatis学习门槛低,简单易学,程序员直接编写sql,可严格控制sql执行性能,灵活度高,非常适合对关系数据模型要求不高的软件开发,例如互联网软件、企业运营类软件等,因为这类软件需求变化频繁,一但需求变化要求成果输出迅速。
Hibernate对象/关系映射能力强,数据库无关性好,对于关系模型要求高的软件(例如需求固定的定制化软件),用Hibernate开发可以节省很多代码,提高效率。但是学习门槛高,要精通门槛更高,而且还要满足设计O/R(Object/Relation)映射,在性能和对象模型之间如何权衡,我实习中看powerdesigner中的数据模型,的确挺多表。多对多的表中,中间又有一个关联表,因此我这边写代码pojo的时候也会多一个类。
总的来说,Mybatis可以进行更细致的SQL优化,查询必要的字段,但是需要维护SQL和查询结果集的映射。数据库的移植性较差,针对不同的数据库编写不同的SQL。
Hibernate对数据库提供了较为完整的封装,封装了基本的DAO层操作,有较好的数据库移植性,但是学习周期长,开发难度大于Mybatis。