Java技术总结
文章目录
- - - -计算机技术演化- - -
- 1 编程语言演化
-
- 1.1 写在最前
- 1.2 汇编
- 1.3 VB->C->C++
- 1.4 Java(Sun公司)
- 1.5 Java演变
- 2 技术思想
- - - -Java技术基础- - -
- 1 知识拓扑
- 2 面向对象
-
- 2.1 面向对象
- 2.2 类&对象
- 2.3 封装
- 2.4 继承
- 2.5 多态
- 3 反射
-
- 3.1 反射机制
-
- 3.1.1 Java代码运行过程
- 3.1.2 反射机制概念
- 3.2 Class对象及其方法
-
- 3.2.1 获取字节码对象
- 3.2.2 常用方法
- 3.3 反射机制应用a
-
- 3.3.1 案例分析
- 3.3.2 代码实现
- 3.4 反射机制应用b
- 4 异常&泛型&序列化&复制
-
- 4.1 异常
-
- 4.1.1 异常概念
- 4.1.2 异常分类
- 4.1.3 异常处理
- 4.1.4 使用@controllerAdvice处理异常
- 4.2 泛型
-
- 4.2.1 泛型概述
- 4.2.2 泛型使用
- 4.3 序列化
- 4.4 复制
- 5 数据结构与集合
-
- 5.1 数据结构
- 5.2 Java集合
-
- 5.2.1 集合类型及其特性
- 5.2.2 常见集合的特点
- - - -Java技术深入- - -
- 1 JVM内存区域
-
- 1.1 内存区域分类
- 1.2 内存区域图解
- 1.3 对象的内存布局
- 2 垃圾收集
-
- 2.1 对象已死判定
- 2.2 垃圾收集算法
- 2.3 内存分配与回收策略
- 3 调优案例分析
- 4 类加载机制
-
- 4.1 类加载时机
- 4.2 类加载过程
- 4.3 类加载器
- 5 Java内存模型与线程
-
- 5.1 硬件效率于一致性
- 5.2 Java内存模型
-
- 5.2.1 主内存和工作内存
- 5.2.2 内存间交互操作
- 5.2.3 volatile变量特殊规则
- 5.2.4 long、double数据类型非原子协定
- 5.2.5 原子性、可见性和有序性
- 5.2.6 先行发生原则
- 5.3 Java与线程
-
- 5.3.1 线程实现
- 5.3.2 线程调度
- 5.3.3 状态转换
- 5.4 Java与协程
- 6 线程安全与锁优化
-
- 6.1 线程安全
-
- 6.1.1 Java中线程安全
- 6.1.2 线程安全实现方法
- 6.2 锁优化
-
- 6.2.1 自旋锁
- 6.2.2 锁消除
- 6.2.3 锁粗化
- 6.2.4 轻量级锁
- 6.2.5 偏向锁
- 6.3 synchronized底层原理
-
- 6.3.1 Mark Word
- 6.3.2 monitor
- 6.3.3 synchronized锁优化
- 7 Tomcat
- 8 计算机原理
- - - -Spring技术- - -
- 1 知识拓扑
- 2 Mybatis
-
- 2.1 Mybatis工作原理
- 2.2 一级缓存和二级缓存
-
- 2.2.1 一级缓存
- 2.2.2 二级缓存
- 3 Vue与react
- 4 Ajax->Java/Servlet->DB
- 5 Restful思想
- 6 SpringBoot
- 7 AOP
- 8 IOC
- 9 注解
-
- 9.1 概述
- 9.2 元注解
- 9.1 常用注解
- - - -DataBase- - -
- 1 知识拓扑
- 2 文件与日志
- 3 关系型数据库
- 4 NoSQL
- 5 非关系型数据库
- 6 MySQL
-
- 6.1 存储引擎
-
- 6.1.1 数据库连接
- 6.1.2 MySQL结构
- 6.1.3 存储引擎概念
- 6.1.4 存储引擎区别
- 6.2 索引
-
- 6.2.1 索引
- 6.2.2 索引分类及使用
- 6.2.3 B树
- 6.2.4 B+树
- 6.2.5 聚簇索引
- 6.2.6 非聚簇索引
- 6.2.7 索引优化
- 6.3 事务
-
- 6.3.1 事务概念
- 6.3.2 事务特性
- 6.3.3 事务隔离级别
- 6.4 锁
-
- 6.4.1 锁分类
- 6.4.2 MyISAM的锁
- 6.4.3 InnoDB的锁
- 6.4.4 悲观锁&乐观锁
- 6.5 MVCC
-
- 6.5.1 定义及工作原理
- 6.5.2 快照
- 6.6 执行计划explain
-
- 6.6.1 执行计划explain
- 6.6.2 参数详解
- 6.7 优化技术
-
- 6.7.1 优化技术总结
- 6.7.2 表设计合理化
- 6.7.3 Sql语句优化
- 6.7.4 适当添加索引
- 6.7.5 分库分表技术
- 6.7.6 读写分离
- 7 集群
- - - -常用中间件- - -
- 1 Redis
- 2 MongDB
- 3 Nginx
-
- 3.1 概述
-
- 3.1 正向代理&反向代理
- 3.2 Nginx的作用
- 3.2 事件驱动架构
-
- 3.2.1 IO模型
- 3.2.2 多路复用器
- 3.2.3 Nginx事件驱动架构
- 3.3 可预见式进程模型
- 4 MongoDB
- - - -问题集锦- - -
- 1 MySQL相关问题
- 2 Java基础相关问题
- 3 常用组件相关问题
- - -计算机技术演化- - -
1 编程语言演化
1.1 写在最前
此文用于个人总结,串接知识点,其整体结构为:
① 计算机技术演化;
② Java技术基础;
③ Java技术深入;
④ Spring技术;
⑤ DataBase;
⑥ 常用中间件。
1.2 汇编
举例:mov 、add
特点:程序量很大,几百行、几千行乃至几万行
1.3 VB->C->C++
面向过程->面向对象
特点:goto关键字、指针、内存管理、数据类型
1.4 Java(Sun公司)
特性:封装(封装成class)、继承(object)、多态(工厂模式、代理模式等)
JVM:编译流程、堆栈、类生成过程
GC:新生代、老年代、GC算法
1.5 Java演变
Applet,C/S架构的桌面程序
JSP + servlet,B/S架构
JavaEE、JavaSE,比较笨重,体量大
Spring,轻量化(高内聚 + 低耦合)
SSH,Struts、Spring和Hibernate(ORM框架)
SSI,Struts、Spring和iBatis(半ORM框架、轻量、灵活)
SSM,Spring、SpringMVC、Mybatis
SpringBoot
SpingCloud
2 技术思想
NoSQL思想:Redis、MongoDB
微服务思想:RPC、SpringCloud、Dubbo、Zookeeper
MQ思想:RocketMQ、RabbitMQ
心跳思想:Socket
- - -Java技术基础- - -
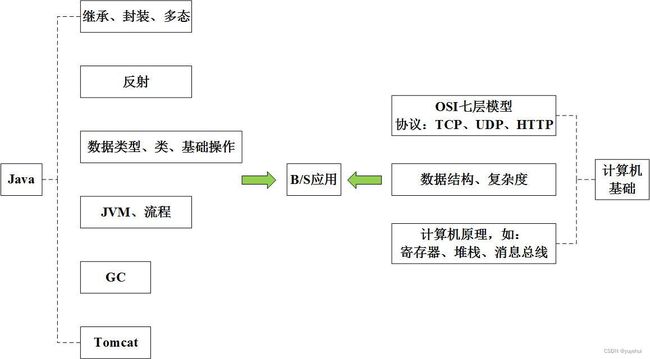
1 知识拓扑
Java知识拓扑
2 面向对象
2.1 面向对象
① 事物 -> 对象,万物皆对象;
② 把数据及其操作方法封装成一个整体,即对象;
③ 面向对象的思想为:A做XX事、B做XX事、C做XX事;
④ 面向过程的思想为:第1步做XX事、第2步做XX事、第3步做XX事。
2.2 类&对象
① 同类对象抽象出其共性,形成类;
② 类是对象的模板;
③ 对象是类的实例。
2.3 封装
① 定义:将对象的属性和行为封装成一个整体;
② 作用:封装私有成员数据,提供成员方法修改数据。
2.4 继承
① 定义:子类继承父类的特征和行为,class 子类 extends 父类 { };
② 特点:Java不支持多继承,支持多重继承;
③ 作用:提高了代码的复用性和维护性;
④ 作用:类和类产生了关系,是多态的前提。
2.5 多态
① 定 义:同一行为具有不同的表现形式,包括“方法多态”与“对象多态”;;
② 方法多态:包括“重载”和“重写”;
重载:单个类中,相同方法,参数不同,其功能不同;
重写:继承父类的多个子类中,相同方法,子类不同,其功能不同;
③ 对象多态:父类子类对象的转换,具体有“向上转型”和“向下转型”;
向上转型:子类对象变为父类对象,格式:父类 父类对象 = 子类实例;
向下转型:父类对象变为子类对象,格式:子类 子类对象 = (子类)父类实例;
④ 多态条件:继承、重写、父类引用指向子类对象;
⑤ 实现方式:重载与重写,抽象类与抽象方法,接口。
3 反射
3.1 反射机制
3.1.1 Java代码运行过程

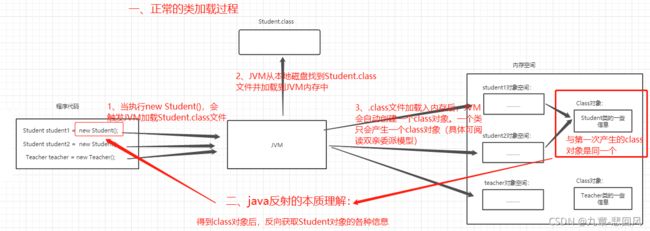
如上图,Java代码在计算机中运行的三个阶段
① Source源代码阶段,java被编译成class文件;
② Class类对象阶段,类加载器将class文件加载进内存,并封装成Class类对象,将成员变量封装成Field[],将构造函数封装成Construction[],将成员方法封装成Method[];
③ RunTime运行时阶段,使用new创建对象的过程。
3.1.2 反射机制概念
1. 定义
在程序运行状态中,对于任意类或对象,都能获取其属性和方法(包括私有属性和方法),这种动态获取信息以及动态调用对象方法的功能就称为反射机制。
2. 优点
① 可以在程序运行过程中,操作这些对象;
② 可以解耦,提高程序的可扩展性。
3.2 Class对象及其方法
3.2.1 获取字节码对象
【Source源代码阶段】Class.forName(“全类名”):将字节码文件加载进内存,返回Class对象,多用于配置文件,将类名定义在配置文件中,读取配置文件加载类;
【Class类对象阶段】类名.class:通过类名的属性class获取,多用于参数的传递;
【Runtime运行时阶段】对象.getClass():该方法定义在Objec类中,所有的类都会继承此方法,多用于对象获取字节码。
3.2.2 常用方法
1. 获取包名 类名
clazz.getPackage().getName()//包名
clazz.getSimpleName()//类名
clazz.getName()//完整类名
2. 获取成员变量
getFields()//获取所有公开的成员变量,包括继承变量
getDeclaredFields()//获取本类定义的成员变量,包括私有,但不包括继承的变量
getField(变量名)
getDeclaredField(变量名)
3. 获取构造方法
getConstructor(参数类型列表)//获取公开的构造方法
getConstructors()//获取所有的公开的构造方法
getDeclaredConstructors()//获取所有的构造方法,包括私有
getDeclaredConstructor(int.class,String.class)
4. 获取成员方法
getMethods()//获取所有可见的方法,包括继承的方法
getMethod(方法名,参数类型列表)
getDeclaredMethods()//获取本类定义的的方法,包括私有,不包括继承的方法
getDeclaredMethod(方法名,int.class,String.class)
5. 反射新建实例
clazz.newInstance();//执行无参构造创建对象
clazz.newInstance(666,”海绵宝宝”);//执行含参构造创建对象
clazz.getConstructor(int.class,String.class)//获取构造方法
6. 反射调用成员变量
clazz.getDeclaredField(变量名);//获取变量
clazz.setAccessible(true);//使私有成员允许访问
f.set(实例,值);//为指定实例的变量赋值,静态变量,第一参数给null
f.get(实例);//访问指定实例变量的值,静态变量,第一参数给null
7. 反射调用成员方法
Method m = Clazz.getDeclaredMethod(方法名,参数类型列表);
m.setAccessible(true);//使私有方法允许被调用
m.invoke(实例,参数数据);//让指定实例来执行该方法
3.3 反射机制应用a
3.3.1 案例分析
1. 需求
实现"框架",要求不改变该类的任何代码,可以创建任意类的对象,并且执行类的任意方法。
2. 实现
① 配置文件;
② 反射机制.
3. 步骤
① 将需要创建的对象的全类名和需要执行的方法定义在配置文件中;
② 在程序中加载读取配置文件;
③ 使用反射技术把类文件加载进内存;
④ 创建对象;
⑤ 执行方法.
3.3.2 代码实现
1. 实体类
public class Person {
public void eat(){
System.out.println("eat...");
}
}
public class Student {
public void study(){
System.out.println("I am a Student");
}
}
2. 两种配置文件
//配置文件1
className = zzuli.edu.cn.Person
methodName = eat
//配置文件2
//className = zzuli.edu.cn.Student
//methodName = study
3. 框架
public class ReflectTest {
public static void main(String[] args) throws Exception {
//1.加载配置文件
//1.1创建Properties对象
Properties pro = new Properties();
//1.2加载配置文件
//1.2.1获取class目录下的配置文件(使用类加载器)
ClassLoader classLoader = ReflectTest.class.getClassLoader();
InputStream inputStream = classLoader.getResourceAsStream("pro.properties");
pro.load(inputStream);
//2.获取配置文件中定义的数据
String className = pro.getProperty("className");
String methodName = pro.getProperty("methodName");
//3.加载该类进内存
Class cls = Class.forName(className);
//4.创建对象
Object obj = cls.newInstance();
//5.获取方法对象
Method method = cls.getMethod(methodName);
//6.执行方法
method.invoke(obj);
}
}
4. 两种运行结果

3.4 反射机制应用b
通过反射创建任意类的对象,并且执行类的任意方法。
package com.yuEntity;
import lombok.Data;
@Data
public class Student {
public Student() {
}
public void show(){
System.out.println("I am a student!");
}
}
package com.yuEntity;
import lombok.Data;
@Data
public class Teacher {
private String name;
private int age;
public Teacher(String name, int age) {
this.name = name;
this.age = age;
}
public void show(){
System.out.println("I am a teacher!");
}
}
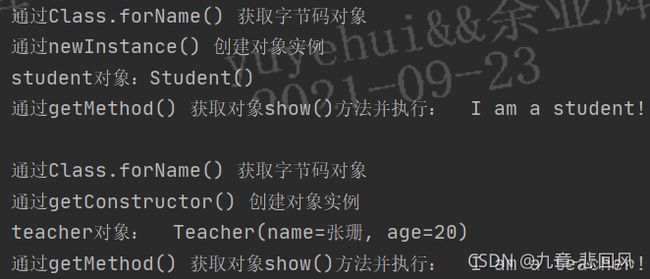
public class TestReflection {
@Test
public void testReflection() throws Exception {
System.out.println("通过Class.forName() 获取字节码对象");
Class clsStudent = Class.forName("com.yuEntity.Student");
System.out.println("通过newInstance() 创建对象实例");
Object student = clsStudent.newInstance();
System.out.println("student对象:" + student);
System.out.print("通过getMethod() 获取对象show()方法并执行: ");
Method method = clsStudent.getMethod("show");
method.invoke(student);
System.out.println("");
System.out.println("通过Class.forName() 获取字节码对象");
Class clsTeacher = Class.forName("com.yuEntity.Teacher");
Class[] teacherCls = new Class[]{String.class, int.class};
System.out.println("通过getConstructor() 创建对象实例");
Object teacher = clsTeacher.getConstructor(teacherCls).newInstance("张珊",20);
System.out.println("teacher对象: " + teacher);
System.out.print("通过getMethod() 获取对象show()方法并执行: ");
method = clsTeacher.getMethod("show");
method.invoke(teacher);
}
}
4 异常&泛型&序列化&复制
4.1 异常
4.1.1 异常概念
定义:程序运行过程中出现的错误,称为异常。
原因:
输入非法数据;
要打开的文件不存在;
网络通信时连接中断,或者JVM内存溢出。
4.1.2 异常分类
1. 分类

2. Error
JVM相关错误,无法处理,如系统崩溃,内存不足,方法调用栈溢等。
3. Exception
可处理的异常,可捕获且可能恢复。
4.1.3 异常处理

注意:
try/catch后面的finally块非强制性要求;
try后不能既没catch也没finally;
try, catch, finally块之间不能添加任何代码;
finally代码一定会执行(除了JVM退出)。
4.1.4 使用@controllerAdvice处理异常
4.2 泛型
4.2.1 泛型概述
1. 定义
泛型,即参数化类型。定义类、接口和方法时,其数据类型可被指定为参数。
2. 类型擦除
泛型在编译阶段有效,不进入运行阶段,编译生成的字节码文件不包含泛型中的类型信息,该过程称为类型擦除。如定义List< Object >和 List< String >,编译后变成List。
4.2.2 泛型使用
1. 泛型类
//在实例化泛型类时,必须指定T的具体类型
public class Generic<T>{
private T key;
public Generic(T key) {
this.key = key;
}
public T getKey(){
return key;
}
}
//泛型的类型参数是类类型(包括自定义类)
Generic<Integer> genericInteger = new Generic<Integer>(123456);
Generic<String> genericString = new Generic<String>("key_vlaue");
2. 泛型接口
//泛型接口
public interface Generator<T> {
public T next();
}
//未传入泛型实参,需将泛型的声明加到类中
class FruitGenerator<T> implements Generator<T>{
@Override
public T next() {
return null;
}
}
//传入泛型实参,T换成实参类型
public class FruitGenerator implements Generator<String> {
private String[] fruits = new String[]{"Apple", "Banana", "Pear"};
@Override
public String next() {
Random rand = new Random();
return fruits[rand.nextInt(3)];
}
}
3. 泛型通配符
操作类型时,若不使用类型具体功能,只使用Object类的功能,可用通配符“?”定义未知类型。
public void showKeyValue(Generic<Number> obj){
Log.d("泛型测试","key value is " + obj.getKey());
}
public void showKeyValue1(Generic<?> obj){
Log.d("泛型测试","key value is " + obj.getKey());
}
//Integer是Number的子类
Generic<Integer> gInteger = new Generic<Integer>(123);
Generic<Number> gNumber = new Generic<Number>(456);
showKeyValue(gNumber);
showKeyValue(gInteger);// 报错
showKeyValue1(gNumber);
showKeyValue1(gInteger);
4. 泛型方法
①基本泛型方法
public class GenericTest {
//泛型类
public class Generic<T>{
private T key;
public Generic(T key) {
this.key = key;
}
//getKey使用泛型,但不是泛型方法,普通的成员方法
public T getKey(){
return key;
}
/* setKey错误,类中并未声明泛型E
public E setKey(E key){
this.key = keu
}*/
}
/* showKeyName为泛型方法
public与返回值之间的必不可少,泛型数量可为多个,如:
public K showKeyName(Generic container){
}*/
public <T> T showKeyName(Generic<T> container){
System.out.println("container key :" + container.getKey());
T test = container.getKey();
return test;
}
//showKeyValue1为普通方法
public void showKeyValue1(Generic<Number> obj){
Log.d("泛型测试","key value is " + obj.getKey());
}
//showKeyValue2为普通方法
public void showKeyValue2(Generic<?> obj){
Log.d("泛型测试","key value is " + obj.getKey());
}
/*showKeyName错误,未声明泛型E
public T showKeyName(Generic container){
...
}*/
/*showkey错误,未声明泛型T
public void showkey(T genericObj){
...
}*/
public static void main(String[] args) {
}
}
②泛型类中的泛型方法
//泛型类
public class Generic<T>{
public void show_1(T t){
System.out.println(t.toString());
}
//泛型类中泛型方法,泛型E可与类中T不同
public <E> void show_2(E e){
System.out.println(e.toString());
}
//泛型类中泛型方法,泛型T是新类型,可以和泛型类中T不同
public <T> void show_3(T t){
System.out.println(t.toString());
}
}
③泛型方法的可变参数
public <T> void printMsg( T... args){
for(T t : args){
Log.d("泛型测试","t is " + t);
}
}
printMsg("111",222,"aaaa","2323.4",55.55);
④静态方法要使用泛型,必须定义成泛型方法
public class StaticGenerator<T> {
public static <T> void show1(T t){
}
//show2方法错误
public static void show2(T t){
}
}
5. 泛型上下边界
① 泛型方法的上下边界,必须与泛型声明在一起
//泛型方法添加上下边界时,必须在上添加上下边界
public <T extends Number> T showKeyName(Generic<T> container){
System.out.println("container key :" + container.getKey());
T test = container.getKey();
return test;
}
②泛型上边界,例1
public class Generic<T>{
private T key;
public Generic(T key) {
this.key = key;
}
public T getKey(){
return key;
}
}
public void showKeyValue1(Generic<? extends Number> obj){
Log.d("泛型测试","key value is " + obj.getKey());
}
Generic<String> generic1 = new Generic<String>("11111");
Generic<Integer> generic2 = new Generic<Integer>(2222);
Generic<Float> generic3 = new Generic<Float>(2.4f);
Generic<Double> generic4 = new Generic<Double>(2.56);
showKeyValue1(generic1);//报错,String不是Number的子类
showKeyValue1(generic2);
showKeyValue1(generic3);
showKeyValue1(generic4);
②泛型上边界,例2
public class Generic<T extends Number>{
private T key;
public Generic(T key) {
this.key = key;
}
public T getKey(){
return key;
}
}
Generic<String> generic1 = new Generic<String>("11111");//报错,String不是Number子类
4.3 序列化
1. 定义
Java序列化是指把Java对象转换为字节流,便于传输和保存;Java反序列化是指把字节流恢复为Java对象。
2. 实现
实现 java.io.Serializable接口。
4.4 复制
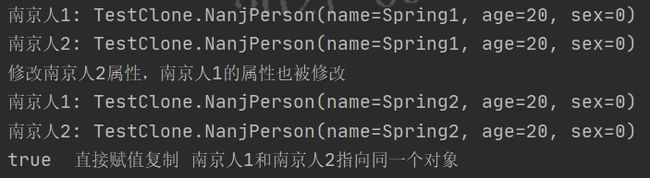
1. 直接赋值复制
直接赋值时, A a1 = a2; 实际上复制的是引用,也就是说a1和a2指向的是同一个对象,当a1变化时,a2的成员变量也会跟着变化。
@Data
public class NanjPerson{
private String name;
private int age;
private int sex;
public NanjPerson(String name, int age, int sex) {
this.name = name;
this.age = age;
this.sex = sex;
}
}
/*@description 一般复制*/
@Test
public void testNanjPersonClone(){
NanjPerson person1 = new NanjPerson("Spring1",20,0);
NanjPerson person2 = person1;
System.out.println("南京人1: " + person1.toString());
System.out.println("南京人2: " + person2.toString());
person2.setName("Spring2");
System.out.println("修改南京人2属性,南京人1的属性也被修改");
System.out.println("南京人1: " + person1.toString());
System.out.println("南京人2: " + person2.toString());
System.out.print( person1 == person2);
if(person1 == person2){
System.out.println(" 直接赋值复制 南京人1和南京人2指向同一个对象");
}else {
System.out.println(" 直接赋值复制 南京人1和南京人2指向不同的对象");
}
}
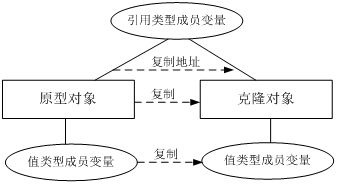
2. 浅拷贝
浅拷贝中,当对象被复制时只复制它本身和其中包含的值类型的成员变量,而引用类型的成员对象并没有复制。
@Data
public class AddressA{
private String addr;
public AddressA(String addrIn) {
this.addr = addrIn;
}
}
@Data
public class WuxPersonA implements Cloneable{
private String name;
private int age;
private int sex;
private AddressA address;
public WuxPersonA(String name, int age, int sex, AddressA address) {
this.name = name;
this.age = age;
this.sex = sex;
this.address = address;
}
@Override
public Object clone() {
WuxPersonA person = null;
try {
person = (WuxPersonA)super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return person;
}
}
/*浅拷贝*/
@Test
public void testWuxPersonAClone(){
WuxPersonA personA1 = new WuxPersonA("SpringA1",20,0,new AddressA("无锡A1"));
WuxPersonA personA2 = (WuxPersonA) personA1.clone();
System.out.println("无锡人A1: " + personA1.toString());
System.out.println("无锡人A2: " + personA2.toString());
personA2.setName("SpringA2");
personA2.address.setAddr("无锡A2");
System.out.println("修改无锡人A2属性 ,无锡人A1的属性里 WuxPersonA中AddressA类有问题 其他属性无问题");
System.out.println("无锡人A1: " + personA1.toString());
System.out.println("无锡人A2: " + personA2.toString());
System.out.print( personA1 == personA2);
if(personA1 == personA2){
System.out.println(" 浅拷贝 对象里面含有另一对象 无锡人A1和无锡人A2指向同一个对象");
}else {
System.out.println(" 浅拷贝 对象里面含有另一对象 无锡人A1和无锡人A2的WuxPersonA不是同一个对象 AddressA是同一个对象 ");
}
}

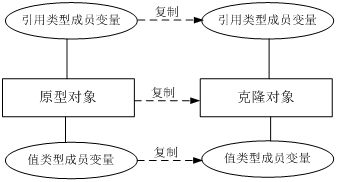
3. 深拷贝
深拷贝中,除了对象本身被复制外,对象所包含的所有成员变量也将复制。
@Data
public class AddressB implements Cloneable{
private String addr;
public AddressB(String addrIn) {
this.addr = addrIn;
}
@Override
public Object clone() {
AddressB addr = null;
try {
addr = (AddressB) super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return addr;
}
}
@Data
public class WuxPersonB implements Cloneable{
private String name;
private int age;
private int sex;
private AddressB addressB;
public WuxPersonB(String name, int age, int sex, AddressB addressB) {
this.name = name;
this.age = age;
this.sex = sex;
this.addressB = addressB;
}
@Override
public Object clone() {
WuxPersonB person = null;
try {
person = (WuxPersonB)super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
person.addressB = (AddressB) addressB.clone();
return person;
}
}
/*深拷贝*/
@Test
public void testWuxPersonBClone(){
WuxPersonB personB1 = new WuxPersonB("SpringB1",20,0,new AddressB("无锡B1"));
WuxPersonB personB2 = (WuxPersonB) personB1.clone();
System.out.println("无锡人B1: " + personB1.toString());
System.out.println("无锡人B2: " + personB2.toString());
personB2.setName("SpringB2");
personB2.addressB.setAddr("无锡B2");
System.out.println("修改无锡人B2属性,无锡人B1的属性保持不变 包括WuxPersonA中AddressA类无问题");
System.out.println("无锡人B1: " + personB1.toString());
System.out.println("无锡人B2: " + personB2.toString());
System.out.print( personB1 == personB2);
if(personB1 == personB2){
System.out.println(" 深拷贝 无锡人B1和无锡人B2指向同一个对象");
}else {
System.out.println(" 深拷贝 无锡人B1和无锡人B2指向不同的对象 包括WuxPersonA对象中AddressA对象");
}
}

4. 序列化深拷贝
@Data
public class Car implements Serializable{
private static final long serialVersionUID = -4694790051431625830L;
private String brand;
private int price;
public Car(String brand, int price) {
this.brand = brand;
this.price = price;
}
}
@Data
public class Person implements Serializable{
private static final long serialVersionUID = 7913723651426251020L;
private String name;
private int age;
private int sex;
private Car car;
public Person(String name, int age, int sex, Car car) {
this.name = name;
this.age = age;
this.sex = sex;
this.car = car;
}
}
/*序列化拷贝工具类*/
public static class CloneUtil{
public static <T extends Serializable> T clone(T obj) throws Exception{
//序列化 将obj对象的内容进行流化,转化为字节序列写到内存的字节数组中
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(obj);
//反序列化 读取内存中字节数组的内容,重新转换为java对象返回
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
return (T) ois.readObject();
}
}
/*序列化实现深拷贝*/
@Test
public void testPersonClone() throws Exception {
Person person1 = new Person("Spring1",20,0,new Car("奥迪",300000));
Person person2 = CloneUtil.clone(person1);
System.out.println("person2: " + person2.toString());
System.out.println("person2: " + person2.toString());
person2.setName("Spring2");
person2.getCar().setBrand("奔驰");
System.out.println("修改person2的属性 person1的属性保持不变 包括Person中car类无问题");
System.out.println("person1: " + person1.toString());
System.out.println("person2: " + person2.toString());
System.out.print( person1 == person2);
if(person1 == person2){
System.out.println(" 序列化实现深拷贝 person1和person2指向同一个对象");
}else {
System.out.println(" 序列化实现深拷贝 person1和person2指向不同的对象 包括Person中car对象");
}
}

5. 反射复制对象
@Data
public class Programmer {
private String corporation;
private String university; //学校名称
private Car car;
public Programmer(String corporation, String university, Car car) {
this.corporation = corporation;
this.university = university;
this.car = car;
}
}
@Data
public class Doctor {
private String corporation;
private int university; //学校编码
private Car car;
public Doctor() {}
public Doctor(String corporation, int university, Car car) {
this.corporation = corporation;
this.university = university;
this.car = car;
}
}
/*两个对象相同属性值复制*/
public static void CopyByReflection(Object source, Object dest) throws Exception {
//获取属性
BeanInfo sourceBean = Introspector.getBeanInfo(source.getClass(), java.lang.Object.class);
PropertyDescriptor[] sourceProperty = sourceBean.getPropertyDescriptors();
BeanInfo destBean = Introspector.getBeanInfo(dest.getClass(), java.lang.Object.class);
PropertyDescriptor[] destProperty = destBean.getPropertyDescriptors();
try {
for (int i = 0; i < sourceProperty.length; i++) {
for (int j = 0; j < destProperty.length; j++) {
if (sourceProperty[i].getName().equals(destProperty[j].getName())
&& sourceProperty[i].getPropertyType().equals(destProperty[j].getPropertyType())) {
//调用source的getter方法和dest的setter方法
destProperty[j].getWriteMethod().invoke(dest, sourceProperty[i].getReadMethod().invoke(source));
break;
}
}
}
} catch (Exception e) {
throw new Exception("属性复制失败:" + e.getMessage());
}
}
/*通过反射复制对象*/
@Test
public void testCloneByReflection() throws Exception {
Programmer programmer = new Programmer("Corporation-a","北京大学",new Car("奔驰",300000));
Doctor doctor = new Doctor();
CopyByReflection(programmer,doctor);
System.out.println("programmer对象: " + programmer.toString());
System.out.println("doctor对象: " + doctor.toString());
System.out.println("programmer对象和doctor对象,university的类型不同,故复制失败");
doctor.setCorporation("Corporation-b");
doctor.car.setBrand("宝马");
System.out.println("programmer对象: " + programmer.toString());
System.out.println("doctor对象: " + doctor.toString());
System.out.println("programmer对象中,car对象的复制,属于浅复制");
}

5 数据结构与集合
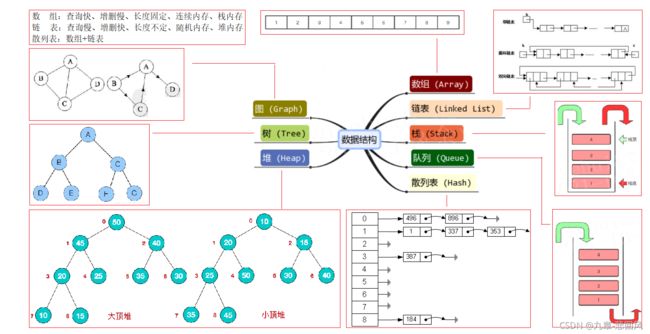
5.1 数据结构
常见数据结构包括:数组、 链表、 栈、队列、树、散列表、图、堆,其结构如下图:
5.2 Java集合
5.2.1 集合类型及其特性
数组/Array:查询快、增删慢、长度固定、连续内存、栈内存
链表/LinkList:查询慢、增删快、长度不定、随机内存、堆内存
散列表/哈希表/HashTable:数组+链表
Map/键值对:HashMap、LinkedHashMap、TreeMap、HashTable
List/动态数组:ArrayList、LinkedList、Vector
set/去重:HashSet、LinkedHashSet、TreeSet
5.2.2 常见集合的特点
| 集合类型 | 安全性 | 有序性 | 结构 | 复杂度 |
|---|---|---|---|---|
| HashMap | 线程不安全 | 数据无序 | 数组+链表+红黑树 | 增删查/O(1)、O(n)、O(log(n)) |
| LinkedHashMap | 线程不安全 | 数据有序 | HashMap+双向链表 (双向链表记录插入顺序) |
增删查/O(1)、O(n)、O(log(n)) |
| TreeMap | 线程不安全 | 数据有序 可排序 | 红黑树 (根据主键自动排序) |
增删查/O(log(n)) |
| HashTable | 线程安全 | 数据无序 | 数组+链表 | 增删查/O(1)、O(n) |
| - | ||||
| ArrayList | 线程不安全 | 数据有序 | 数组 | 查询快/O(1)、非尾部增删慢/O(n) |
| LinkedList | 线程不安全 | 数据有序 | 双向链表 | 查询慢/O(n)、增删快/O(1) |
| vector | 线程安全 | 数据有序 | 数组 | 查询快/O(1)、非尾部增删慢/O(n) |
| - | ||||
| HashSet | 线程不安全 | 数据无序 | HashTable | 增删查/O(1)、O(n) |
| LinkedHashSet | 线程不安全 | 数据有序 | HashTable+链表 (链表记录插入顺序) |
增删查/O(1)、O(n) |
| TreeSet | 线程不安全 | 数据有序 可排序 | 红黑树 (根据主键自动排序) |
增删查/O(log(n)) |
- - -Java技术深入- - -
1 JVM内存区域
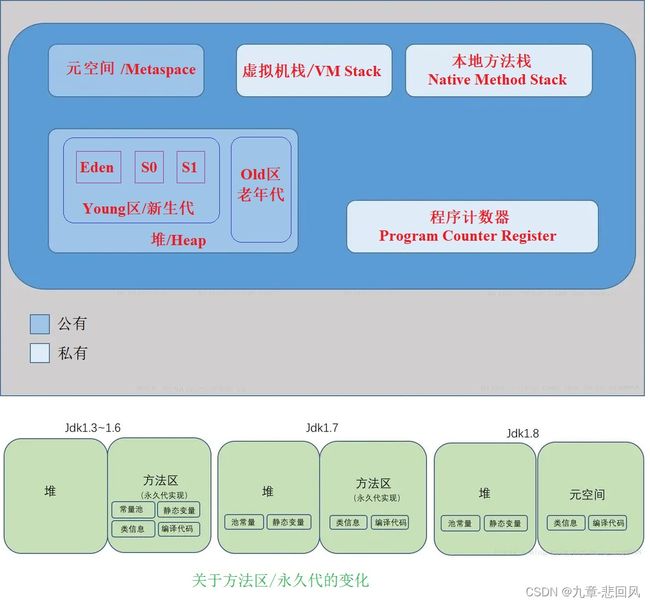
1.1 内存区域分类
JVM内存可分为堆、虚拟机栈、本地方法栈、元空间、程序计数器,各区域存储内容见下表。其中,程序计数器不会抛出“内存溢出”异常。
| 内存分类 | 属性 | 存储内容&说明 |
|---|---|---|
| 堆 | 公有 | 对象实例,可通过-Xmx、-Xms参数设定 |
| 虚拟机栈 | 私有 | Java方法 |
| 本地方法栈 | 私有 | native方法,该类方法可与操作系统交互,可理解为C/C++/汇编实现的方法 |
| 元空间 | 公有 | 类型信息(类有效名、直接父类有效名、权限修饰符、是否有实现类等) |
| 程序计数器 | 私有 | 行号指示器 |
1.2 内存区域图解
JVM内存可分为堆、虚拟机栈、本地方法栈、元空间、程序计数器,其结构如下图,包括元空间、方法区演化过程。其中堆划分为新生代和老年代,新生代:老年代的默认比值为1:2。新生代划分为Eden、From Survivor(S0)、To Survivor(S1),Eden:S0:S1的默认比值为8:1:1,各区域比值均可人为设定。
直接内存不属于JVM内存,但JDK1.4之后,引入了NIO类,使用该类会涉及到直接内存。
1.3 对象的内存布局
在HotSpot虚拟机中,对象布局可分为三个部分:对象头(Header)、实例数据(Instance Data)、对齐填充(Padding)。对象头中有两类信息,一类是运行时数据(如哈希码、GC分代年龄、线程持有的锁、偏向线程ID和偏向时间戳),也称Mark Word,另一类是类型指针(即指向类型信息的指针),通过类型指针可获得该对象是哪个类的实例。
2 垃圾收集
2.1 对象已死判定
1. 引用计数法
被引用增加一次,计数加1,
被引用减少一次,计数减1,
判定计数为0的对象已死,可回收,
该方法存在循环引用问题,
该方法基本不使用。
2. 可达性分析法
定义根对象(GC Roots)作为起始节点,
根据引用关系向下搜索,搜索路径为引用链,
判定不在引用链的对象已死,可回收,
Java、C#语言均使用该方法,不同的垃圾收集器定义的GC Roots不同。
3. 引用分类
强引用、软引用、弱引用、虚引用。
2.2 垃圾收集算法
1. 分代收集理论
按对象已死判定方法区分,垃圾收集算法可分为引用计数式垃圾收集算法和追踪式垃圾收集算法,目前主流虚拟机均使用追踪式垃圾收集,以下介绍的均属于追踪式垃圾收集算法。
垃圾收集器只管理堆内存,堆内存区域划分,分为新生代和老年代,参考1.2章节,堆内存区域划分后,垃圾收集器设计了3种垃圾回收策略:Minor GC、Major GC和Full GC,其功能分别为:清理年轻代,清理老年代,清理年轻代和老年代。
新生代中对象朝生夕死,存活率低,采用Minor GC策略,采用标记复制算法,老年代中存在长期存活对象和大对象,采用Major GC策略和Full GC策略,采用标记清除和标记整理算法。
2. 标记清除算法
标记被引用的对象,
删除未被标记的对象,
内存碎片化问题。
3. 标记复制算法
内存分两块,
从当前内存复制正在使用的对象到另一内存,
空间消耗高。
4. 标记整理算法
标记被引用的对象,
排列未被标记的对象到堆的一侧,
删除未被标记的对象。
5. 三种算法图解
标记-清除、复制、标记-整理三种GC算法图解如下:

2.3 内存分配与回收策略
1. 内存分配回收策略
对象优先在Eden区分配,
大对象直接进入老年代,
长期存活的对象将进入老年代,
动态对象年龄判定,大于等于某个年龄的对象超过了survivor空间一半,则大于等于某个年龄的对象直接进入老年代。
2. 对象生命周期
① 绝大多数对象分配在Eden区,其中大多数对象很快消亡;
② 最初一次,当Eden区满时,执行Minor GC,清理消亡的对象,复制剩余的对象到Survivor0(此时Survivor1空白,两个Survivor有一个空白);
③ 下一次Eden区满了,执行Minor GC,清理消亡的对象,复制存活的对象到Survivor1中,清空Eden区;
④ 同时,清理Survivor0中消亡的对象,将可以晋级的对象晋级到Old区,将存活的对象也复制到Survivor1区,清空Survivor0区;
⑤ 经过一次GC,对象年龄加1,对象切换多次后,仍然存活的对象,将被复制到老年代。
3. 对象生命周期小记
我是Java对象,
出生在Eden区,
长大 进入Survivor的“From”区,
自此 在“From”区和“To”区漂泊,
年满15入老年代,该年龄可配置,
再活20生命结束。
3 调优案例分析
1. 案例1
某在线文档网站,由于内存较小,用户体验欠佳,于是升级硬件,升级后网站不定期出现长时间失去响应的现象。原因:由于代码问题,业务中存在大量大对象,扩充内存后,老年代中存在的大对象比扩充内存之前更多,一次Full GC处理的大对象太多 ,导致业务停顿。
2. 案例2
某业务系统Eden区、Survivor区、老年代均运行稳定,但经常出现内存溢出。原因为:该系统使用了NIO类,使用NIO则涉及到直接内存,但虚拟机不会对直接内存进行自主回收,而是老年代回收垃圾时,顺便清理直接内存,而该系统中老年代很稳定,很少发生Full GC,因此不会清理直接内存,导致直接内存区域溢出。
3. 案例3
某业务系统,其响应速度很慢,但大量计算机资源并不是被该业务占用。原因为:业务请求使用了外部shell脚本,一次请求则会创建一个外部shell进程,多次请求过后导致系统消耗过大。
4. 案例4
某业务系统,其响应速度很慢,并出现虚拟机进程自动关闭。原因为:该系统需要和外部系统交互,而外部系统响应速度极慢,随着业务量增多,处于等待的线程和socket连接越来越多,进而导致虚拟机崩溃。
5. 案例5
某业务系统,其响应速度很慢。原因为:该系统新生代中有百万个键值对,而这些数据不是朝生夕死的,导致垃圾回收时,在两个Survivor区域内移动消耗时间较多。
4 类加载机制
4.1 类加载时机
1. 类加载定义
虚拟机将类数据从Class文件加载到内存,并对数据进行校验、转换、解析、初始化,形成可以被虚拟机使用的Java类型,这个过程称为类加载,类加载、连接、初始化是程序运行期间完成的。
2. 类生命周期
一个类型,从被加载到虚拟机内存到卸载,其整个生命周期分为7个阶段,如下图所示,其中验证、准备、解析三个部分统称为连接。

3. 类加载时机
类的“加载”时机,由虚拟机自由把握。类的“初始化”时机,在一下6种情况,如果类型未初始化,需触发其初始化,分别为:
① 遇到new、get static、put static、invoke static四种指令;
② 使用java.lang.reflect包的方法对类型进行反射调用;
③ 初始化某个类,如果其父类未初始化,则需要触发其父类初始化;
④ 虚拟机启动时,用户指定执行的主类(包括main方法的类),虚拟机会先初始化该类;
⑤ 使用JDK7的动态语言中某种特殊情况;
⑥ 使用JDK8的某种特殊情况。
4.2 类加载过程
1. 加载
① 通过全限定类名获取类的二进制字节流;
② 将字节流所代表的静态存储结构转化为方法区的运行时数据结构;
③ 在内存中生成该类的java.lang.Class对象,作为方法区该类的访问入口。
2. 验证
① 文件格式验证,检验字节流是否符合Class文件格式的规范;
② 元数据验证,对字节码描述的信息进行语义分析,保证其符合《Java语言规范》;
③ 字节码验证,通过数据流分析和控制流分析,确定程序语义的合法性和逻辑性;
④ 符号引用验证,检验该类是否缺少依赖的外部类、方法和字段等资源。
3. 准备
① 给类中的静态变量分配内存;
② 设置类中成员变量初始值。
4. 解析
① 将常量池内的符号引用替换为直接引用,符号引用是一种描述引用目标的符号,符号可以为任何形式的字面量,直接引用是指向目标的指针、指向目标的相对偏移量、或者是能定位到目标的句柄;
② 类或接口解析,将类中类或者接口的符号引用解析为直接引用;
③ 字段解析,将类中字段的符号引用解析为直接引用;
④ 方法解析,将类中方法的符号引用解析为的直接引用;
⑤ 接口方法解析,将类中接口方法的符号引用解析为的直接引用。
5. 初始化
加载、验证、准备和解析4个阶段,均为虚拟机控制,初始化阶段才执行Java代码,该阶段执行类的构造器方法,即方法,方法是编译生成的。
4.3 类加载器
1. 类与类加载器
① 实现“通过全限定类名获取类二进制字节流”功能的代码即为“类加载器”;
② 对于任意类,由类本身和类加载器确定该类在虚拟机中的唯一性,来源于不同类的实例,类得eauals()、isInstance()等方法不能返回正确结果;
③ 从虚拟机角度看,类加载器分为两种,一为虚拟机自带的启动类加载器,C++实现,二为其他类加载器,Java实现,这种类加载器继承java.lang.ClassLoader;
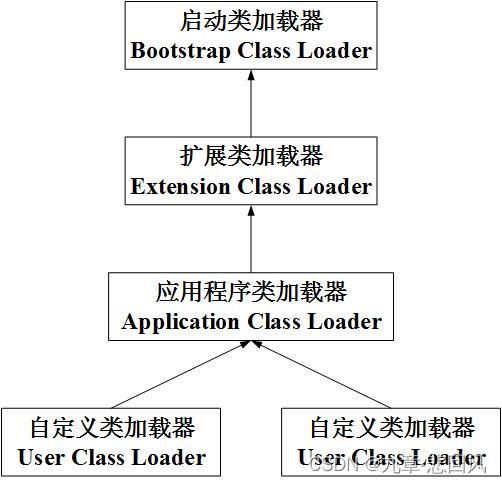
④ 从开发角度看,JDK1.2以后类加载器分为三种,分别为启动类加载器、扩展类加载器和应用程序类加载器。
2. 双亲委派模型
双亲委派模型,其工作过程为:如果一个类加载器收到类加载请求,首先会把请求委派给父类加载器完成,父类加载器无法完成加载请求时,子类加载器完成加载,因此所有加载请求均会到达启动类加载器。双亲委派模型如下图所示。
双亲委派模型能较好地适配Java中子类、父类的关系,如java.lang.Object是所有类的父类,无论哪个子类加载Object,都是由启动类加载器完成加载,因此可保证不同类加载的Object类是同一个Object类。
3. 类加载过程图解
如下图,类的加载过程。
5 Java内存模型与线程
5.1 硬件效率于一致性
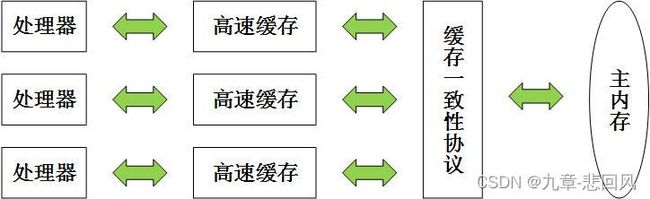
存储设备运算慢,1s执行约106条指令,处理器运算速度快,1s执行约109条指令,现代计算机系统通过引入高速缓存,可提高CPU效率,并设计缓存一致性协议解决一致性问题,该类架构为“CPU多级缓存架构”,处理器、高速缓存和主内存关系如下图。
5.2 Java内存模型
5.2.1 主内存和工作内存
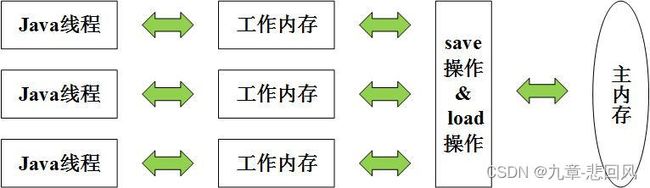
Java内存模型的主要目的是定义程序中各种变量的访问规则,即在虚拟机中把变量存储到内存和从内存中取变量。此处变量定义与Java编码有所区别,它包括实例字段、静态字段和数组对象,但不包括线程私有的局部变量和方法参数。
如下图,在Java内存模型中
① 变量存储在主内存(虚拟机内存的一部分);
② 线程有私有工作内存,工作内存中保存了线程所属变量的主内存副本;
③ 线程在工作内存中读写所属变量;
④ 工作内存中变量私有,线程间传递变量值需通过主内存完成。
此处Java内存模型中工作内存、主内存和Java内存结构中堆、栈、元空间属于不同层次上的划分,两种划分没有联系。若需对应,主内存属于堆中实例数据,工作内存属于虚拟机栈中。
5.2.2 内存间交互操作
关于主内存和工作内存数据交互,Java内存模型定义8种原子操作,分别为:
① lock\锁定,锁定主内存变量;
② unlock\解锁,解锁占有的主内存变量;
③ read\读取,读取主内存变量并传至工作内存;
④ load\载入,将读取到的主内存变量写入工作内存;
⑤ use\使用,虚拟机使用工作内存变量;
⑥ assign\赋值,虚拟机对工作内存变量赋值;
⑦ store\存储,读取工作内存变量并传至主内存;
⑧ write\写入,将读取到的工作内存变量写入主内存。
注意,read、load操作需按顺序执行,但不要求连续执行,store、write操作相同。
对于上述8种操作,Java内存模型中定义8中规则:
① 不允许read和load、store和write单独出现;
② 不允许线程丢弃最近的assign操作,即变量变化后需从工作内存同步到主内存;
③ 不允许线程无原因(无assign)同步工作内存变量到主内存;
④ 新变量在主内存中诞生,不允许在工作内存中使用未初始化(load和assign)的变量;
⑤ 一个变量同一时刻只能被一个线程lock,但可被lock多次,执行相同次数unlock变量才能解锁;
⑥ lock某变量,则工作内存中该变量清空,未load或assign不可use;
⑦ 若变量为lock,则不能unlock;
⑧ unlock变量之前,需将变量同步到主内存。
鉴于8种操作过于复杂,JDK将8种简化为read、write、lock、unlock四种。
5.2.3 volatile变量特殊规则
关键字volatile是虚拟机中轻量级的同步机制,不容易被完整理解,使用频率不及synchronized。当变量被定义成volatile后,该变量具有两个特性。
① 特性1,volatile变量具有可见性,即某线程修改该变量的值,其他线程可立即得知,但volatile型变量不是线程安全的;
② 特性2,volatile变量有序性,禁止重排序优化,普通变量仅能保证在方法的执行中所依赖赋值结果的地方能获取到正确结果,不能保证变量的赋值操作和代码中执行顺序一致;
③ 可见性、有序性的实现,依赖特殊指令,这类指令功能包括:读共享变量时必须读取主内存、修改共享变量时必须刷新主内存,禁止指令重排序等,统称为内存屏障指令;
④ 由于volatile仅能保证可见性,在不符合以下两条规则时,需通过加锁(synchronized关键字)保证原子性,规则1为运算结果不依赖当前变量值或者只有单一线程修改变量值,规则2为变量不需要其他状态变量共同参与不变约束。
5.2.4 long、double数据类型非原子协定
Java内存模型中lock、unlock、read、load、assign、use、store、write八种操作具有原子性,但是对于64位数据类型(long和double)有较为宽松的规定,允许虚拟机将未被volatile修饰的64位数据类型分两次进行读写,即允许虚拟机决定是否支持64位数据类型read、load、store、write操作是否具有原子性。
5.2.5 原子性、可见性和有序性
1. 原子性
Java内存模型保证read、load、use、assign、store、write六种操作的原子性,基本数据类型读写操作具有原子性(long和double除外)。更大范围的原子性可以用lock、unlock实现,这两个操作对应synchronized关键字。
2. 可见性
某线程修改共享变量的值,其他线程能够立即获得,通过volatile、synchronized实现可见性,final也可以。
3. 有序性
有序性可理解为:在线程内观察,所有操作是有序的,即线程内表现为串行,在线程之间观察,所有操作是无序的,即“指令重排序”和“工作内存和主内存同步延迟”。volatile和synchronized关键字可实现有序性,volatile禁止指令重排序,synchronized规定同一时刻只有单一线程可以lock。
4. volatile和synchronized
volatile关键字具有可见性和有序性,synchronized关键字具有原子性、可见性和有序性,可见性和有序性均采用内存屏障指令实现,参考5.2.3 章节,synchronized存在加锁过程,加锁成功后不会中断,天然具有原子性。
5.2.6 先行发生原则
1. 先行发生定义
先行发生是Java内存模型中定义的两项操作之间的偏序关系,比如操作A先行发生于操作B,则 操作B发生前,操作A的所有影响可被操作B看到,影响包括修改共享变量的值、发送的消息和调用方法。
2. Java内存模型中存在的先行发生
① 程序次序规则,线程内,按照控制流,前面的操作先行发生于后面的操作;
② 管程锁定规则,一个unlock操作先行发生于后面对一个锁的lock操作;
③ volatile变量规则,对volatile变量的写操作先行发生于后面对该变量的读操作;
④ 线程启动规则,Thread对象的start方法先行发生于线程的每一个动作;
⑤ 线程终止规则,线程所有操作先行发生于该线程的终止检测,通过Thread::join()方法是否结束、Thread::isAlive()方法返回值可判断线程是否终止;
⑥ 线程中断规则,线程的interrupt()方法调用先行发生于检测到中断事件的发生,通过Thread::interrupted()方法检测中断发生;
⑦ 对象终结规则,对象初始化结束(构造函数结束)先行发生于finalize()方法开始;
⑧ 传递性,若操作A先行发生于操作B,操作B先行发生于操作C,则操作A先行发生于操作C。
5.3 Java与线程
5.3.1 线程实现
1. 线程概述
① 进程具有独立功能的程序关于数据的运行过程,是资源分配和调度的基本单位。
② 线程是比进程更轻量级的调度执行单位,是CPU调度基本单位,线程引入,可把进程的资源分配和执行调度分开。
③ 线程实现由3种方式,内核线程实现(1:1实现)、用户线程实现(1:N实现)、用户线程加轻量级进程混合实现(N:M实现)。
2. 内核线程实现
内核线程(Kernel-Level Thread,KLT)是由操作系统内核(Kernel)支持的线程,内核通过调度器(Schedule)调度线程,并将线程任务映射到CPU。应用程序一般不直接使用内核线程,而是使用内核线程的高级接口-轻量级进程(Light Weight Process,LWP),LWP即通常意义上讲的线程,LWP与内核线程数量比值为一对一,如下图所示。
LWP局限性,首先,LPR由内核线程实现,其线程创建、同步、销毁和调度需进行系统调用,系统调用需要在用户态(User Mode)和内核态(Kennel Mode)相互切换,调用代价较高。其次,单个LWP需要一个内核线程支撑,因此LWP消耗内核资源,因此内核支撑的LWP数量有限。

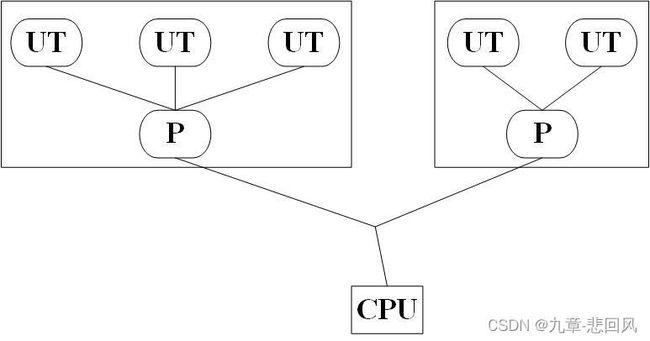
3. 用户线程实现
狭义的用户线程(User Thread,UT)指在用户空间线程库上建立的线程,系统内核不能感知这类线程的生命,用户线程创建、同步、销毁和调度不需要进行系统调用,若线程功能得当,则无需进入内核态,其进程与线程数量比值为1:N,如下图所示。
由于操作系统只CPU资源分配到进程,用户线程调度需要应用程序处理,因此存在线程阻塞、多核处理器线程映射等难题。
4. 混合实现
除内核线程实现、用户线程实现之外,将内核线程和用户线程混合使用也可实现线程。线程创建、同步和销毁在用户态完成,通过轻量级进程作为桥梁,使用内核的线程调度和处理器映射,可减少线程阻塞问题。该模式中,用户线程和轻量级进程之间数量比值为N:M,如下图。
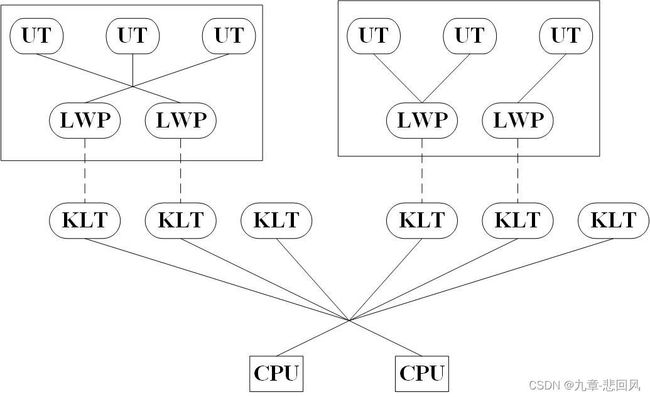
5. Java线程实现
主流的Java虚拟机线程模型为基于操作系统的原生线程模型,即1:1线程模型。
5.3.2 线程调度
线程调度,指系统为线程分配处理器使用权的过程。调度方式有两种,分别为协同式和抢占式,Java虚拟机使用抢占式调度方式。协同式方式中,线程执行和线程切换由线程本身控制,其线程执行时间不可控制,单一线程故障可能阻塞进程。抢占式方式中,线程执行和线程切换由系统决定,单一线程故障不会阻塞进程。
线程优先级,Java语言给线程设置了10个级别的优先级,两个处于等待状态得线程,优先级越高越容易被系统执行。但是,线程优先级不是稳定的调节手段,因为Java的线程优先级和各类操作系统的线程优先级并不能一一对应。
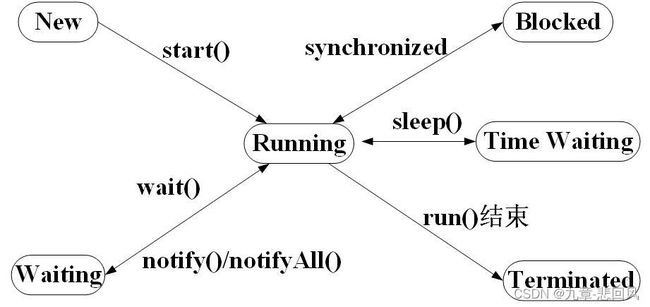
5.3.3 状态转换
Java语言定义了6种线程状态,分别是:
① 新建(New):创建后尚未启动的线程属于该状态;
② 运行(Runnable):操作系统中Running和Ready状态的线程属于该状态,即该状态的线程为执行状态或则等待被分配CPU执行时间;
③ 无限期等待(Waiting):该状态的线程不会被分配CPU执行时间,等待被其他线程显式唤醒;
④ 限期等待(Time Waiting):该状态的线程不会被分配CPU执行时间,一定时间后由系统自动唤醒;
⑤ 阻塞(Blocked):线程阻塞,等待获取排它锁,
⑥ 结束(Terminated):线程终止,结束执行。
以上六种状态在特定事件发生时可以互相转换,转换关系如下图:
5.4 Java与协程
内核线程局限性;
协程复苏。
6 线程安全与锁优化
6.1 线程安全
6.1.1 Java中线程安全
线程“安全程度”由强到弱排序,分别为:不可变、绝对线程安全、相对线程安全、线程兼容和线程对立。
1. 不可变
不可变对象一定是线程安全的,例如final关键字修饰的对象。
2. 绝对线程安全
一个类,不管运行时环境如何,调用者都不需要任何同步措施,则该类绝对线程安全,Vector不是绝对线程安全。
3. 相对线程安全
相对线程安全,即为通常意义上的线程安全,若能保证对象单次操作是线程安全的,则调用的时候不需要采取同步手段,对于特定顺序地连续调用,需要在调用端采取同步手段,Vector、HashTable属于该类型。
4. 线程兼容
线程兼容指对象本身不是线程安全的,在调用端采取同步手段可以保证对象在并发环境中安全使用,即通常意义上的线程不安全,ArrayList、HashMap属于该类型。
5. 线程对立
线程对立指不管在调用是否采取同步手段,对象都不能在多线程环境中并发使用,该类型对象很少,。
6.1.2 线程安全实现方法
1. 互斥同步
互斥同步(Mutual Exclusion&Synchronization)是最常见、最主要的并发同步保障手段,互斥是方法,同步是目的。同步指同一时刻只有单一线程访问共享数据,互斥是实现同步的手段,临界区(Critical Section)、互斥量(Mutex)、信号量(Semaphore)是常见的互斥实现方式。
synchronized关键字是一种常见的互斥同步手段,JDK5之后提供的Java.util.concurrent.Lock接口也是一种互斥同步手段,重入锁(ReentrantLock)是该接口的一种实现。相比synchronized而言,ReentrantLock具有三个高级功能,分别为:等待可中断、公平锁和锁绑定多个条件。
2. 非阻塞同步
互斥同步是一种阻塞同步,涉及线程阻塞和唤醒,有性能开销。从解决问题方式上看,不管恭喜数据是否存在竞争,互斥同步都会加锁,存在无效性能开销,是一种悲观并发策略。
随着硬件指令集发展,基于冲突检测的乐观并发策略可以实现线程安全。其原则为:先操作,无冲突则操作成功,有冲突则采取补偿措施,这种同步手段即为非阻塞同步。基于硬件指令的发展,操作+冲突检测也具有原子性,乐观并发同步策略发展起来,这类指令包括:
① 测试并设置(Test-and-Set);
② 获取并增加(Fetch-and-Increment);
③ 交换(Swap);
④ 比较并交换(Compare-and-Swap,简称CAS);
⑤ 加载链接/条件存储(Load-Linked/Store-Conditional,简称LL/SC)。
3. 无同步方案
若某个类,在多线程之间没有共享数据竞争,则不需要采取同步手段。具有这种特征的应用包括:可重入代码、线程本地存储和基于消费队列(生产者:消费者)架构的应用。
6.2 锁优化
JDK6及之后,HotSpot虚拟机提供了一系列锁优化技术,如适应性自旋(Adaptive Spinning)、锁消除(Lock Elimination)、锁粗化(Lock Coarsening)、轻量级锁(Lightweight Locking)、偏向锁(Biased Locking)等。
6.2.1 自旋锁
多核处理器系统可以多线程并行,若某线程请求加锁失败,可让该线程等待,方法是执行一个忙循环(自旋),该技术即为自旋锁。
6.2.2 锁消除
锁消除,指虚拟机即时编译器在运行时检测到某段需要同步的代码不存在共享数据竞争,虚拟机则删除对应的锁,判断依据来源于逃逸分析技术。
6.2.3 锁粗化
锁粗化,指虚拟机检测到一系列操作都对同一对象加锁,虚拟机会将加锁范围扩大覆盖到一系列操作。
6.2.4 轻量级锁
要理解轻量级锁,需了解HotSpot虚拟机对象(尤其是对象头)的内存布局,轻量级锁是基于对象头中的锁标志位实现的,其性能消耗少于重量级锁(互斥方法实现的锁),但也存在使用局限。
6.2.5 偏向锁
轻量级锁原则是在共享数据无竞争情况下,使用CAS消除互斥量,偏向锁原则是在共享数据无竞争情况下消除同步,偏向锁是基于对象头中的锁标志位实现的,其功能为会偏向第一个获得他的线程。若只有单一线程获取共享数据,则第二次以后不会采取加锁,一旦出现多个线程竞争共享数据,偏向锁模式及失效。
6.3 synchronized底层原理
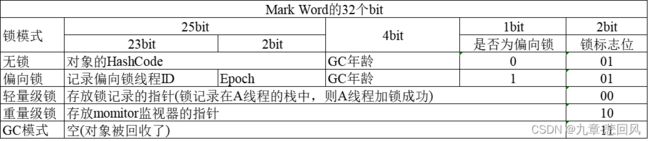
6.3.1 Mark Word
虚拟机中对象的对象头,其结构和各比特位的作用如下图。monitor监视器提供monitorenter指令和monitorexit指令进行加锁和解锁,synchronized同步就是基于monitor监视器实现的。
6.3.2 monitor
monitor对象监视器,JVM中每个java对象都有对应的monitor对象,其底层使用C++实现的,monitor是ObjectMonitor类的实例,ObjectMonitor的结构如下,其中,_count字段值表示是否加锁,_owner字段表示锁拥有者,_EntryList字段存储等待加锁的线程,_SpinFreq和_SpinClock字段表示自旋功能。
ObjectMonitor() {
_header = NULL;
_count = 0; //锁计数器,_count=0表示未加锁,_count>0表示加锁次数
_waiters = 0,
_recursions = 0;
_object = NULL;
_owner = NULL; //指向加锁成功的线程 _owner=null表示未加锁
_WaitSet = NULL; //wait线程的集合,在synchorized代码块中调用wait()方法的线程会加入该集合,等待唤醒
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ; //多线程竞争锁进入时的单向链表
_cxq = NULL ;
FreeNext = NULL ; //_owner从该双向循环链表中唤醒线程结点,_EntryList是第一个节点
_EntryList = NULL ; //等待队列,加锁失败的线程会加入该等待队列,等待再次加锁
_SpinFreq = 0 ; //获取锁之前的自旋的次数
_SpinClock = 0 ; //获取之前每次锁自旋的时间
OwnerIsThread = 0 ;
_previous_owner_tid = 0;
}
6.3.3 synchronized锁优化
1. 锁重入
持有锁的线程可再次加锁,不会出现锁死现象。
2. 锁消除
不存在竞争的同步代码块,JVM会自动消除该锁,例如内部类。
3. 锁升级
对不同的变量竞争情况,JVM会采取不同的锁,原则为花费最小代价达到并发安全。根据Mark Word中锁标志位,可判断锁类型,具体参见6.3.1章节。
4. 偏向锁
同步代码块第一次被进入(设为线程A),当前为无锁状态,则加指向线程A的偏向锁,同步代码块第N次被进入(设为线程A),若当前为指向线程A的偏向锁状态,则不加锁,直接执行。
5. 偏向锁之重偏向
同步代码块第N次被进入(设为线程B),当前为指向线程A的偏向锁状态,若线程A已挂起或者已执行完,则将代码块加指向线程B的偏向锁,偏向锁不释放。
6. 偏向锁升级轻量级锁
同步代码块第N次被进入(设为线程B),当前为指向线程A的偏向锁状态,若线程A正在执行,则偏向锁升级为轻量级锁。换言之,偏向锁不具有线程互斥性,同步代码块存在竞争时,偏向锁状态升级为轻量级锁状态。
7. 轻量级锁
同步代码块第N次被进入(设为线程B),当前为指向线程A的偏向锁状态,若线程A正在执行,则将线程A暂停,给线程A创建锁记录,复制Mark Word数据到锁记录,将锁记录放入线程A的虚拟机栈中,将锁记录指针存入Mark Word前30位,唤醒线程A,至此偏向锁升级为轻量级锁,线程A持有该同步代码段的轻量级锁。
轻量级锁释放,恢复Mark Word前30位,若恢复成功,即解锁成功。
8. 轻量级锁升级为重量级锁&自旋
线程A持有轻量级锁,线程B自旋等待加锁,若线程B自旋结束未获取到锁,或者线程C加入获取锁,则轻量级锁升级为重量级锁。
9. 重量级锁
线程A持有重量级锁,其他线程加锁则阻塞,线程A解锁后唤醒其他线程竞争锁,重量级锁基于monitor实现,monitor具体细节参考6.3.2章节。
10. synchronized锁优化总结
synchronized锁升级原则是为了花费最小的代价能达到加锁的目的。
无竞争时使用偏向锁,首次执行CAS操作获取偏向锁之后,后面进入同步代码块不重复加锁。
存在线程竞争时偏向锁升级为轻量级锁,轻量级锁的加锁、解锁都需要执行CAS操作,对比偏向锁来说性能低一点,但还是比较轻量级的。为提升线程获取锁的机会,避免线程陷入获取锁失败则阻塞(线程阻塞后再唤醒涉及上下文切换,用户态内核态切换,费时间),故设计自旋等待,线程自旋之后重试获取锁。
当竞争非常激烈,并发很高,或者同步代码块执行耗时较长,则大量线程都在自旋,由于自旋是空耗费CPU资源,自旋一定次数之后,线程挂起,升级为重量级锁。
7 Tomcat
你好
8 计算机原理
你好
- - -Spring技术- - -
1 知识拓扑
Spring技术知识拓扑
2 Mybatis
2.1 Mybatis工作原理
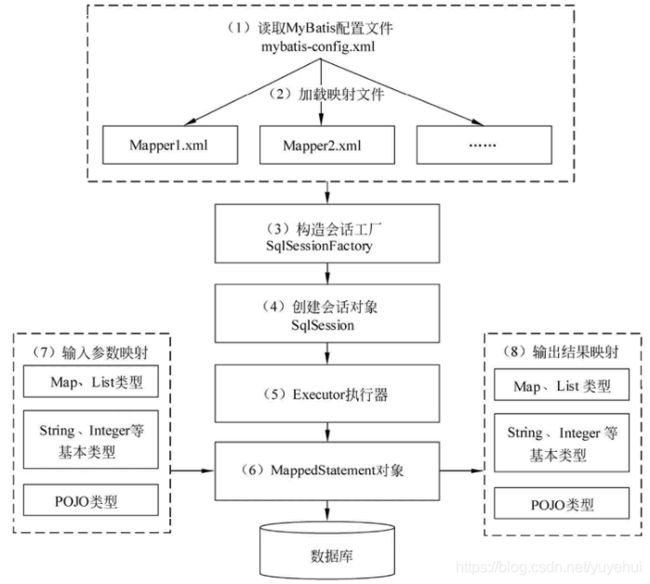
① 读取mybatis-config.xml配置文件;
② 加载SQL映射文件(在mybatis-config.xml中加载);
③ 构造会话工厂SqlSessionFactory对象;
④ 根据会话工厂创建SqlSession对象,该对象有Executor执行器;
⑤Executor执行器接口中,其成员方法有MappedStatement参数,该参数用来存储映射的SQL语句的id、参数等信息;
⑥ Executor执行器,根据SqlSession传递的参数生成SQL语句,维护查询缓存。
2.2 一级缓存和二级缓存
2.2.1 一级缓存
一级缓存是SqlSession范围的缓存,调用SqlSession修改,添加,删除,commit(),close()方法时,会清空一级缓存。
如下图,查询id为1的信息,先查询缓存,若缓存中不存在,则查询数据库,并将信息存到一级缓存。若执行commit操作,则清空一级缓存,让缓存中存储最新信息,避免脏读。

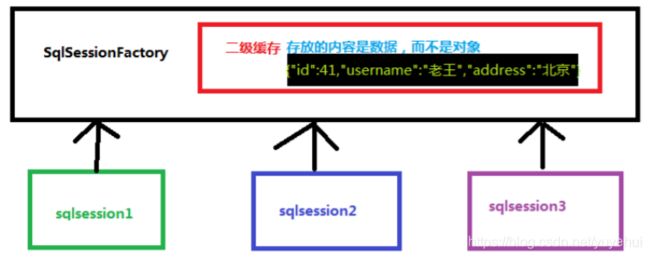
2.2.2 二级缓存
二级缓存是mapper映射级别的缓存,多个SqlSession操作一个sql语句,共用其二级缓存,mybatis二级缓存默认为开启,修改参数cacheEnabled可设置关闭。
如下图,sqlsession1查询用户信息,并存到二级缓存中。sqlsession2查询相同信息,首先查询缓存,如果存在则从缓存中取数据。sqlsession3执行相同sql,执行commit提交,将会清空二级缓存区域的数据。
3 Vue与react
你好
4 Ajax->Java/Servlet->DB
你好
5 Restful思想
你好
6 SpringBoot
你好
7 AOP
你好
8 IOC
你好
9 注解
9.1 概述
1. 定义
注解,也叫元数据,即一种描述数据的数据。本质上来说,注解一种特殊的注释。
2. 用途
① 生成文档,生成javadoc文档;
② 编译检查,编译期间进行检查验证;
③ 编译时动态处理,例如动态生成代码;
④ 运行时动态处理,例如使用反射注入实例。
3. 分类
① Java自带注解,包括@Override、@Deprecated和@SuppressWarnings;
② 元注解,用于定义注解的注解,包括@Retention、@Target、@Inherited、@Documented;
③ 自定义注解。
9.2 元注解
| 元注解 | 作用 |
|---|---|
| @ResponseBody | 描述注解的生命周期 |
| @Retention | 将注解中元素输出到Javadoc |
| @Target | 描述注解的修饰范围 |
| @Inherited | 类继承时,子类会继承父类使用的注解中被@Inherited修饰的注解 |
9.1 常用注解
| 注解 | 作用 |
|---|---|
| @ResponseBody | 将返回的Java对象转换为JSON格式 |
| @Documented | |
| @RequestBody | 将读到的内容(json数据)转换为java对象并绑定到Controller方法的参数上。 |
| @RequestMapping | 标识 http 请求地址与 Controller 类的方法之间的映射。 |
| @Transactional | 用于给service方法添加事务,其事务的开启需要基于接口或者类的代理被创建 ,同一个类中方法A调用有事务的方法B,事务不会起作用。 |
| @Param | 限定mapper中的变量名,起规范作用。 |
- - -DataBase- - -
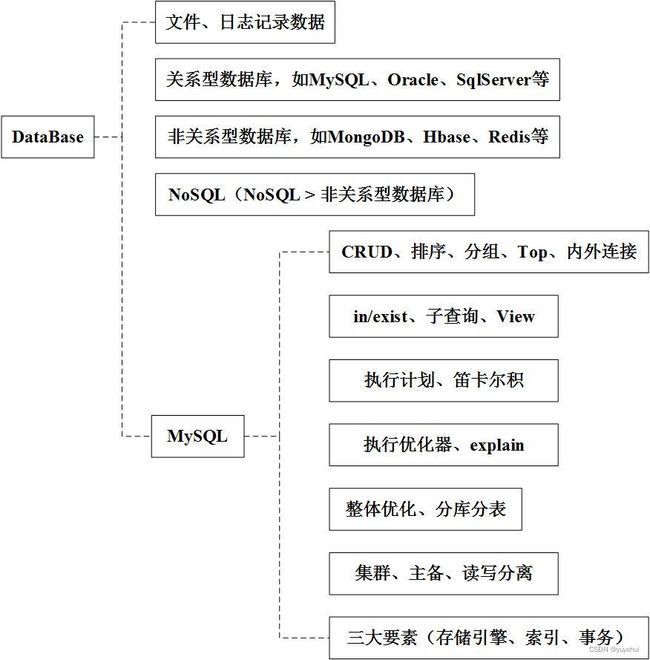
1 知识拓扑
如下图,DataBase知识拓扑。
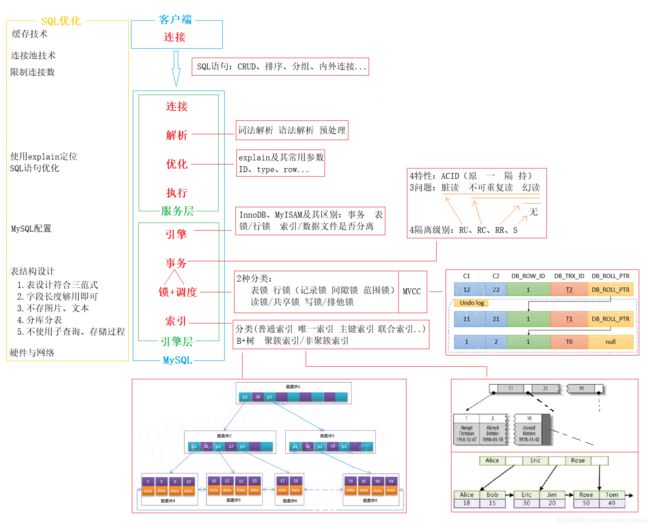
如下图,MySQL知识拓扑。
2 文件与日志
你好
3 关系型数据库
你好
4 NoSQL
你好
5 非关系型数据库
你好
6 MySQL
6.1 存储引擎
6.1.1 数据库连接
1. 连接
① 通信类型:同步、异步
② 连接方式:长连接、短连接
③ 通信协议:TCP/IP、UDP
④ 通信方式:单工、半双工、双工
⑤ MySQL使用同步通信、长连接、TCP/IP协议和半双工通信方式。
2. JDBC
JDBC(Java DataBase Connectivity)是Java和数据库之间的桥梁,是一组用Java语言编写的类和接口。

6.1.2 MySQL结构
如下图,MySQL可分为两层架构,第一层SQLLayer,功能包括权限判断,sql解析,执行计划优化,querycache处理等;第二层存储引擎层,是底层数据存取操作实现部分。

MySQL两层架构中,服务层、存储引擎层中涉及的知识点如下图。其中,CRUD过程中,MySQL服务层中的步骤可分为连接、解析、优化、执行。

6.1.3 存储引擎概念
存储引擎是数据存储、数据索引、数据CRUD、是否支持事务等技术的实现方式,不同存储引擎的特性有一定差别。
6.1.4 存储引擎区别
| 特点 | InnoDB | MyISAM | MEMORY | FEDERATED |
|---|---|---|---|---|
| 支持事务 | 是 | 否 | 否 | 否 |
| 锁机制 | 行锁(适合高并发) | 表锁 | 表锁 | - |
| 支持外键 | 是 | 否 | 否 | - |
| 支持索引 | B树索引 全文索引 集群索引 数据索引 |
B树索引 全文索引 |
B树索引 哈希索引 数据索引 |
B树索引 |
| 其他 | 索引和数据文件不分离 | 索引和数据文件分离 | - | 适用于分布式场景,连接多个MySQL服务器 |
6.2 索引
6.2.1 索引
1. 定义
索引是对数据库中数据排序的一种数据结构,存储在内存或磁盘中,使用索引可快速访问数据库中的指定数据。
2. 优点
① 减少数据查询行数,提高效率;
② 建立唯一索引或者主键索引,保证数据字段的唯一性;
③ 检索时有分组和排序需求时,减少服务器排序的时间。
3. 缺点
① 创建和维护索引存在时间及内存消耗;
② 索引字段过多,数据量过大时,索引占据空间可能比表更大;
③ 更新数据时,也需要维护索引,增加数据维护复杂度。
4. 建立索引的原则
① 离散度高;
② 有序性好;
③ 索引数目不要多。
6.2.2 索引分类及使用
1. 单列索引
一个单列索引只包含单个列,但一个表中可以有多个单列索引。
普通索引:MySQL中基本索引类型,允许在定义索引的列中插入重复值和空值。
唯一索引:索引列中的值是唯一的,但是允许为空值,
主键索引:是一种特殊的唯一索引,不允许有空值。
2. 组合索引
基于多个字段组合创建的索引,使用组合索引时遵循最左匹配原则。
3. 全文索引
在MyISAM引擎上才能使用,只能在CHAR、VARCHAR、TEXT类型字段上使用。
4. 空间索引
空间索引是对空间数据类型的字段建立的索引,MySQL中的空间数据类型有四种,GEOMETRY、POINT、LINESTRING、POLYGON。使用SPATIAL关键字,引擎为MyISAM。
6.2.3 B树
1. B树定义
① 树中每个结点最多含有m个孩子( m >= 2 );
② 除根结点和叶子结点外,其他每个结点至少 m/2 个孩子。
③ 若根结点不是叶子,至少2个孩子。
④ 有j个孩子的非叶节点恰好有 j-1 个关键码,关键码按递增次序排序。
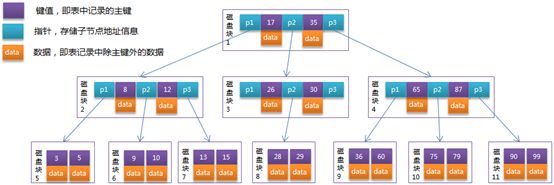
6.2.4 B+树
1. B+树定义
① 非叶子节点的值会以最大或最小值出现在其子节点中,即叶子节点包含所有元素;
② 非叶子节点带有索引数据和指向叶子节点的指针,不包含实际数据信息,叶子节点有所有元素信息;
③ 所有叶子节点形成一个有序链表。
2. B+树优势
① B+树磁盘读写代价低,B树存储元素数据,B+只存储索引,可以存储更多节点;
② B+树查询效率稳定,非终结点只是关键字的索引,查找数据必须走到叶子节点;
③ B+树中叶子结点是一个链表,所以B+树在面对范围查询时比B树更加高效。
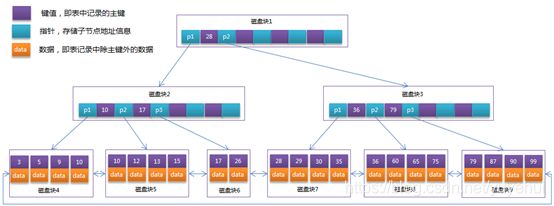
6.2.5 聚簇索引
1. 定义
聚簇索引,叶子节点存储的是数据。索引类型依赖存储引擎,Innodb使用的是聚簇索引。
2. 优点
① 减少磁盘IO次数,查询数据时,索引节点和数据被同时载入内存;
② 无需维护辅助索引,当出现数据页分裂时,无需更新索引中的数据块指针。
3. Innodb的主键索引和辅助索引
如图为Innodb存储引擎生成的主键索引结构,非叶子节点存储主键,叶子节点存储主键和行数据。

如下图为Innodb存储引擎生成的辅助索引结构。叶子节点存储索引字段和对应的主键值,索引到主键值后,根据主键值再去主键索引中查找对应的数据。 
6.2.6 非聚簇索引
非聚簇索引,叶子节点中存储的是指向数据块指针,MyISAM使用非聚簇索引。
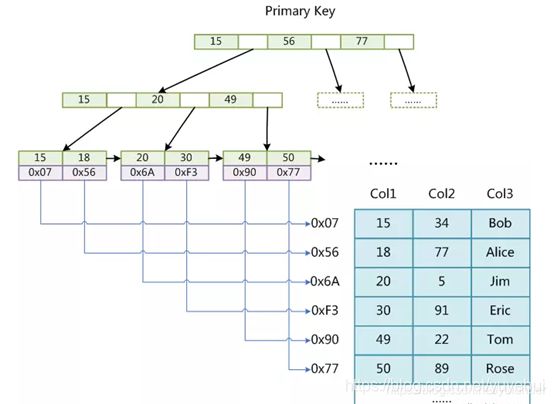
6.2.7 索引优化
(1) like语句前导模糊查询不使用索引
select address from t where name like ‘%xx’; - 不使用索引
select address from t where name like ‘xx%’; - 可使用索引
(2) 负向条件查询不使用索引
select name from t where status != 1 and status != 2; - 不使用索引
select name from t where status in (0,3,4); - 优化为in可使用索引
负向条件有!=,<>,not in,not exists,not like等(设status为0 1 2 3 4)。
(3) 范围条件右边的列不使用索引
select name from t where no < 10010 and title=‘xxx’ and date between ‘1986-01-01’ and ‘1986-12-31’;
范围条件有<,<=,>,>=,between等,索引最多用于一个范围列,如上联合索引 (no,title,date),SQL中no使用索引,title date不适用索引。
(4) 在索引列做任何操作(计算、函数、表达式)不使用索引
select name from t where YEAR(create_time) <= ‘2016’; - 不使用索引
select name from t where create_time<= ‘2016-01-01’; - 可使用索引
select name from order where date < = CURDATE(); - 不使用索引
select name from order where date < = ‘2018-01-2412:00:00’; - 可使用索引
select id from t where substring(name,1,3)=’abc’; - 不使用索引
select id from t where name like ‘abc%’ ; - 可使用索引
select id from t where num/2=100; - 不使用索引
select id from t where num=100*2; - 可使用索引
(5) where中索引列使用参数会导致索引失效
select id from t where num=@num; - 不使用索引
select id from t with(index) where num=@num; - 可以改为强制查询使用索引
SQL在运行时解析局部变量,优化程序是在编译时选择访问计划,但在编译时,变量值是未知的。
(6) 强制类型转换会导致全表扫描
select name from t where phone=13800001234; - 不使用索引
select name from t where phone=‘13800001234’; - 可使用索引
字符串类型不加单引号时索引失效,因为mysql会做类型转换。
(7) is null, is not null无法使用索引,mysql的高版本允许使用索引
select id from t where num is null; - mysql低版本不使用索引
select id from t where num=0; - 可在num设置默认值0,确保num列没有null值
(8) 使用联合索引时,要符合最左原则
建立联合索引,字段数一般少于5个,如果在a b c上建立联合索引,会自动建立a、(a,b)、(a,b,c) 三组索引。
① 建立联合索引时,区分度最高的字段在最左边。
② 存在等号和非等号混合条件时,建立索引应把等号条件的列前置,如where a > ? and b= ?,即使a区分度更高,也把b放在索引最前列。
③ 最左前缀查询时,不是指where条件顺序必须和联合索引一致,但建议保持一致。
④ 假如index(a,b,c), where a=3 and b like ‘abc%’ and c=4,a能用,b能用,c不能用。
6.3 事务
6.3.1 事务概念
数据库的事务是指一组sql语句组成的逻辑处理单元,在这组sql操作中,要么全部执行成功,要么全部执行失败。
6.3.2 事务特性
原子性(Atomic):指事务的原子性操作,要么同时成功,要么同时失败;
一致性(Consistent):事务操作前后,状态要一致;
隔离性(Isolated):多个事务之间,相互隔离;
持久性(Durable):当事务提交或回滚后,数据的新增、修改会持久化到数据库中。
6.3.3 事务隔离级别
1. 事务隔离级别
| 问题 | 问题描述 |
|---|---|
| 脏读 | 事务a,读取到事务b中没有提交的数据 |
| 不可重复读(虚读) | 事务a中,针对某条数据,两次读到的结果不同 |
| 幻读 | 事务a按相同条件检索数据,事务b添加满足该条件的数据,则事务a两次检索到的数据记录数不同 |
| 隔离级别 | 备注 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|---|
| Read uncommitted/0 | 未提交读 | 可能 | 可能 | 可能 |
| Read committed/1 | 已提交读(Oracle默认) | 否 | 可能 | 可能 |
| Repeatable read/2 | 可重复读(MySQL默认) | 否 | 否 | 可能 |
| Serializable/3 | 串行化 | 否 | 否 | 否 |
| 2. 未提交读执行过程图 | ||||
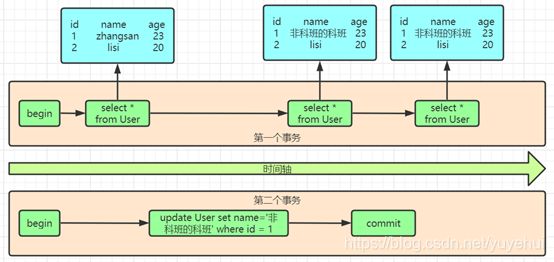 |
||||
| 3. 已提交读执行过程图 | ||||
 |
6.4 锁
6.4.1 锁分类
1. 按粒度划分
| 锁 | 优缺点 | 支持引擎 |
|---|---|---|
| 表锁 | 开销小,加锁快,不出现死锁,粒度大,发生锁冲突概率高,并发度低 | MyISAM、MEMORY、InnoDB |
| 行锁 | 开销大,加锁慢,会出现死锁,粒度小,发生锁冲突概率低,并发度高 | InnoDB |
| 2. 按类型划分 | ||
| 锁 | 优缺点 | |
| :– | :– | :– |
| 共享锁/读锁 | 多个事务对同一数据可共享一把锁,均可访问数据,只能读不能修改。 | |
| 排他锁/写锁 | 事务A获取某数据行的排他锁,则其他事务不能获取该行的其他锁,包括共享锁和排他锁,获取排他锁的事务是可以对数据就行读取和修改 | |
| 3. MySQL调度策略 | ||
| ① 写入请求应按其到达的次序进行处理; | ||
| ② 写入具有比读取更高的优先权。 |
6.4.2 MyISAM的锁
1. 支持表锁
① Select操作加共享锁,Update、Delete、Insert操作加排它锁;
② 读写之间、写写之间是串行的,读读之间是并行的;
③ 由于表锁粒度大,读写是串行的,若更新操作较多,可能出现严重的锁等待。
2. 并发锁
MyISAM的系统变量concurrent_insert(默认设置为1)。
6.4.3 InnoDB的锁
1. 支持行锁
|行锁分类| 操作说明|
|:–|:–|:–|
|记录锁/Record lock|对索引项加锁,即锁定一条记录|
|间隙锁/Gap lock|对索引项之间的‘间隙’、对第一条记录前的间隙或最后一条记录后的间隙加锁,即锁定一个范围的记录,不包含记录本身 |
|范围锁/Next-key Lock|锁定一个范围的记录并包含记录本身(上面两者的结合)|
2. 行锁导致的死锁
(1) 死锁原理
MySQL中,行锁不是锁数据,而是锁索引;索引分为主键索引和非主键索引,若sql语句操作了主键索引,MySQL会锁定该主键索引;若语句操作了非主键索引,MySQL会先锁定该非主键索引,再锁定相关的主键索引。在update、delete操作时,MySQL不仅锁定where条件扫描的索引记录,同时会锁定相邻的键值,即next-key locking。
(2) 死锁原因
当两个事务同时执行,事务a锁住了主键索引,在等待其他相关索引;事务b锁定了非主键索引,在等待主键索引,则发生死锁。
(3) 降低死锁
① 不同程序并发存取多个表,尽量以相同的顺序访问表;
② 一个事务,尽可能一次锁定需要的所有资源;
③ 对于容易产生死锁的业务,可使用粒度较大的锁,如表锁;
④ 若程序以批量方式处理数据,可事先对数据排序,保证每个线程按固定的顺序处理记录。
3. 行锁的间隙锁
用法:select * from 表名 where 字段名>** for update;使用范围条件(所示方法)检索数据时,InnoDB除了给索引记录加锁,还会给不存在的记录(间隙)加锁。
目的:防止幻读,避免其他事务插入数据。
6.4.4 悲观锁&乐观锁
1. 悲观锁
(1) 悲观锁流程及使用场景
① 修改记录前,先加排他锁,加锁失败则等待或者抛出异常,加锁成功则进行修改,事务完成后解锁;
② 行锁、表锁、读锁、写锁都属于悲观锁。
③ 悲观并发控制主要用于数据争用激烈的环境;
(2) 优缺点
① 优点 悲观并发控制使用“先取锁再访问”的策略,可保证数据处理的安全性;
② 缺点 (a)效率低,处理加锁有额外开销,增加死锁概率;
③ 缺点 (b)只读事务不涉及数据修改,无需加锁。
2. 乐观锁
如果系统并发量非常大,悲观锁会带来非常大的性能问题,可选择使用乐观锁,乐观锁的实现方法有版本控制机制和时间戳。
(1) 版本控制机制
标志:每行数据增加version字段,每次更新数据对应版本号+1,
原理:读出数据,将版本号一同读出,之后更新,版本号+1,提交数据版本号大于数据库当前版本号,则予以更新,否则认为是过期数据,重新读取数据。
(2) 使用时间戳实现
标志:每行数据增加time字段;
原理:读出数据,将时间戳一同读出,之后更新,提交数据时间戳等于数据库当前时间戳,则予以更新,否则认为是过期数据,重新读取数据。
6.5 MVCC
6.5.1 定义及工作原理
1. 定义
Multi-Version Concurrency Control ,一种多版本并发控制协议,只在数据库引擎为InnoDB、隔离级别为RC、RR的情况下存在。MVCC是通过版本号和快照/一致性视图,实现了事务隔离性,但只在事务级别为已提交读和可重复读时有效。MVCC最大的好处是:读不加锁,读写不冲突。
2. 工作原理
InnoDB引擎中,每行数据都有三个隐藏字段,唯一行号(DB_ROW_ID字段)、事务ID(DB_TRX_ID字段)和回滚指针(DB_ROLL_PTR字段)。开启事务时,会生成一个事务版本号,被操作的数据会生成新的数据行,但在提交前对其他事务不可见。数据更新之后,事务提交成功后,将该事务版本号赋值给数据行的创建版本号,图解如下。
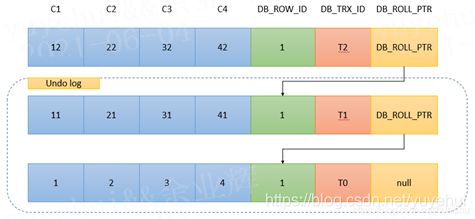
6.5.2 快照
1. 快照创建策略
|隔离级别| 创建快照策略|
|:–|:–|:–|
|read committed级别|事务开启,每个select操作,都会创建快照(Read View),保持最新快照|
|repeatable read级别|事务开启,首个select操作之后,创建快照(Read View),之后均使用该快照 |
2. 快照工作原理
如下图,版本1、版本2并非实际物理存在的,而图中的U1和U2实际就是undo log,这v1和v2版本是根据当前v3和undo log计算出来的。
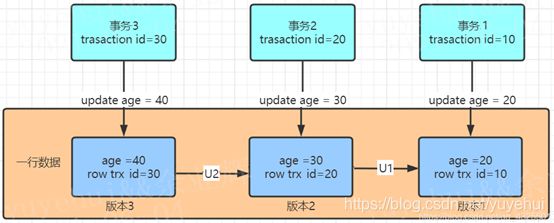
快照遵循原则如下:自己更新的数据总是可见,其他事务更新的数据有三种情况:版本未提交的,都不可见;版本已经提交,但是是在创建视图之后提交的也不可见;版本已经提交,但是是在创建视图之前提交的是可见的。
6.6 执行计划explain
6.6.1 执行计划explain
explain执行计划包含信息如下图,其中,比较重要的字段为包含id、type、key、rows。

6.6.2 参数详解
1. id
select查询的序列号,表示执行select子句或操作表的顺序,包括三种情况。
① id相同,执行顺序由上至下;
② id不同,如果是子查询,id序号会递增,id值越大优先级越高,越先被执行;
③ id相同又不同(两种情况同时存在),id如果相同,则为一组,从上往下顺序执行,在所有组中,id值越大,优先级越高,越先执行 。
2. select_type
查询类型,用于区分普通查询、联合查询、子查询等复杂的查询。其值包含SIMPLE、PRIMARY、SUBQUERY、DERIVED、UNION、UNION RESULT。
3. type
访问类型,sql查询优化的重要指标,结果值从好到坏依次是:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL,一般来说,sql查询至少达到range级别,最好能达到ref。
|type值类型| 意义|
|:–|:–|:–|
|system|表中只有一行记录匹配,是const类型特例|
|const|通过索引一次即可查询到数据,const用于比较primary key或者unique索引|
|eq_ref |唯一性索引扫描,表中只有一条记录匹配,常见于主键或唯一索引扫描|
|ref|非唯一性索引扫描,返回匹配某个单独值的所有行|
|range |检索给定范围的行,使用一个索引来选择行,一般是在where语句中出现bettween、<、>、in等的查询。|
|index |Full Index Scan,遍历索引树(Index与ALL都是读全表,但index是从索引中读取,而ALL是从硬盘读取)|
|ALL|Full Table Scan,遍历全表以找到匹配的行|
4. possible_keys
查询涉及到的字段上存在索引,则该索引将被列出,但不一定被查询实际使用>
5. key
实际使用的索引,如果为NULL,则没有使用索引;查询中如果使用了覆盖索引,则该索引仅出现在key列表中 。
6. key_len
表示索引中使用的字节数,查询中使用的索引的长度(最大可能长度),并非实际使用长度,理论上长度越短越好,key_len是根据表定义计算而得的,不是通过表内检索出的。
7. ref
显示索引的那一列被使用,如果可能,是一个常量const。
8. rows
根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数。
6.7 优化技术
6.7.1 优化技术总结
① 表设计合理化(符合“三范式”,兼顾“反范式”);
② 适当添加索引(包括普通索引、主键索引、唯一索引、全文索引);
③ SQL语句优化(包括避免全表扫描、避免嵌套子查询等);
④ 分表技术(水平分割、垂直分割);
⑤ 读写分离(其中写包括update/delete/add);
⑥ 存储过程(模块化编程,可提高速度,但迁移性差,服务器压力也会逐渐增大);
⑦ mysql参数调优(修改my.ini配置文件的参数);
⑧ mysql服务器硬件升级;
⑨ 定时清除不需要的数据,定时进行碎片整理(特别是使用MyISAM)。
6.7.2 表设计合理化
1. 第一范式
每列属性都是不可再分,确保每列原子性;
两列属性相同或相似,尽量合并属性一样的列,确保不产生冗余数据。
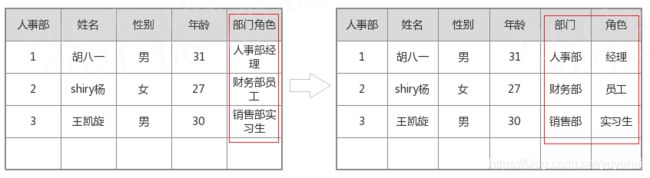
2. 第二范式
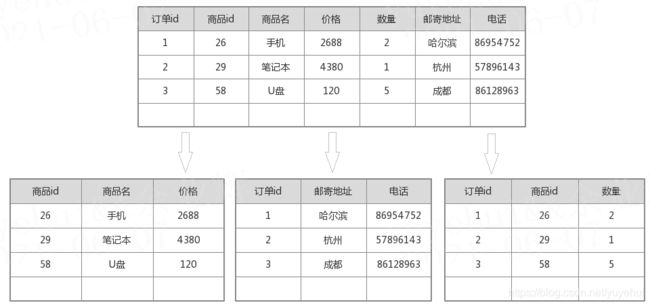
表中每列都只和主键相关,即一张表中只保存一种数据。
3. 第三范式
表中每列只能依赖于主键,非主键依赖数据用外键做关联。
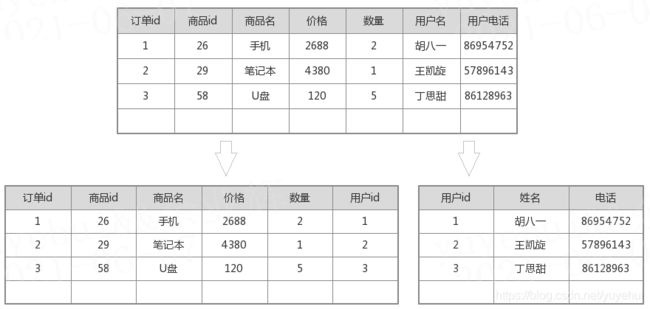
4. 反范式
若业务所涉及的表非常多,经常会有多表联查,其查询效率就会大打折扣,可考虑使用“反范式”。增加必要的,有效的冗余字段,用空间来换取时间,在查询时减少或者是避免过多表之间的联查。
6.7.3 Sql语句优化
1. Sql执行效率排查方法
① SHOW [ SESSION|GLOBAL ] STATUS指令;
② 慢查询定位与记录。
2. 常用Sql优化方法
① group by 分组查询涉及到排序,使用order by null禁止排序;
② 使用左/右连接替代多表联查,因为MySQL使用JOIN不需要在内存中创建临时表;
③ 含or的查询语句,每个条件列都尽量使用索引,没有索引可考虑增加索引;
④ 选择合适的存储引擎,MyISAM引擎不支持事务,其查询和添加效率高,INNODB引擎支持事务,其数据一致性较好。
6.7.4 适当添加索引
索引知识,具体见6.2章节,索引技术可大大提高查询速度,其代价是降低插入、更新、删除的速度。
6.7.5 分库分表技术
1. 垂直分表
将一张表的若干列,提取成子表。如下图,商品描述信息访问频次低,占用存储空间大,商品基本信息访问频次高,占用存储空间小。采用垂直分表规则,将商品基本信息存放在表1中,访问商品描述信息放在表2中。
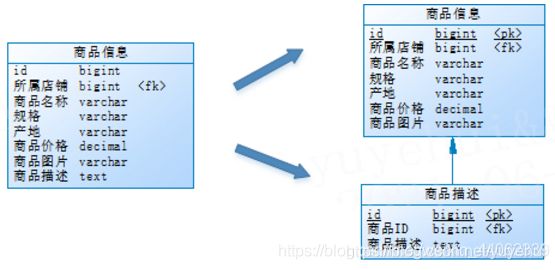
2. 水平分表
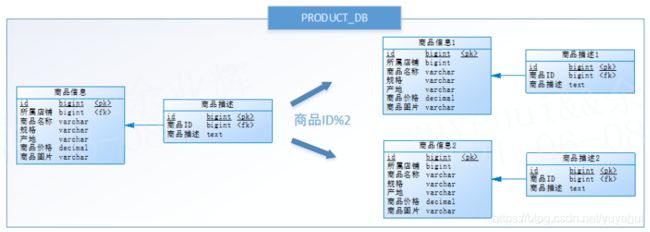
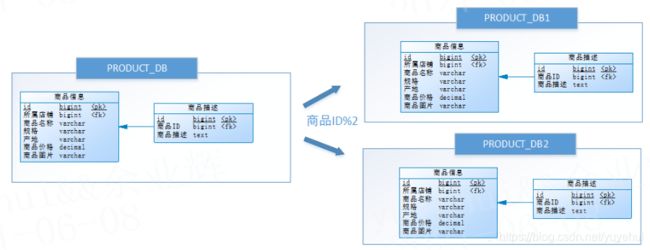
将一张表分割成多个相同的子表,在访问时,根据事先定义好的规则操作对应的子表。如下图,商品信息及商品描述被分成了两套表,如果商品ID为双数,将此操作映射至表1,如果商品ID为单数,将操作映射至表2。
3. 垂直分库
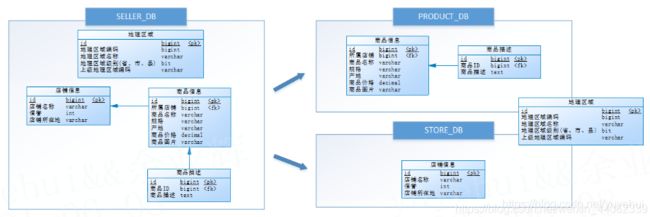
如下图,将SELLER_DB(卖家库),分为了PRODUCT_DB(商品库)和STORE_DB(店铺库),并把这两个库分散到不同服务器。
4. 水平分库
如下图,将店铺ID为单数的和店铺ID为双数的商品信息分别放在两个库中。
5. 其他分表分库技术
① mysql集群,其作用和分表相同,集群可将任务分担到多台数据库,可进行读写分离,减少读写压力。
② 自定义规则分表/库,按照业务规则来分解为多个表/库,常用规则包括Range(范围)、Hash(哈希)等,也可自定义规则。
6.7.6 读写分离
1. 读写分离原理
读写分离,即在主服务器上增删改,在从服务器上读,同时将数据从主服务器同步到从服务器。实现了数据备份、优化了数据库性能。
2. 常用分离技术
① 基于程序代码内部实现;
② 基于中间代理层实现,其结构如下图所示,流行的代理中间件有mysql_proxy、Atlas、Amoeba。

7 集群
你好
- - -常用中间件- - -
1 Redis
直接输入
2 MongDB
你好
3 Nginx
3.1 概述
3.1 正向代理&反向代理
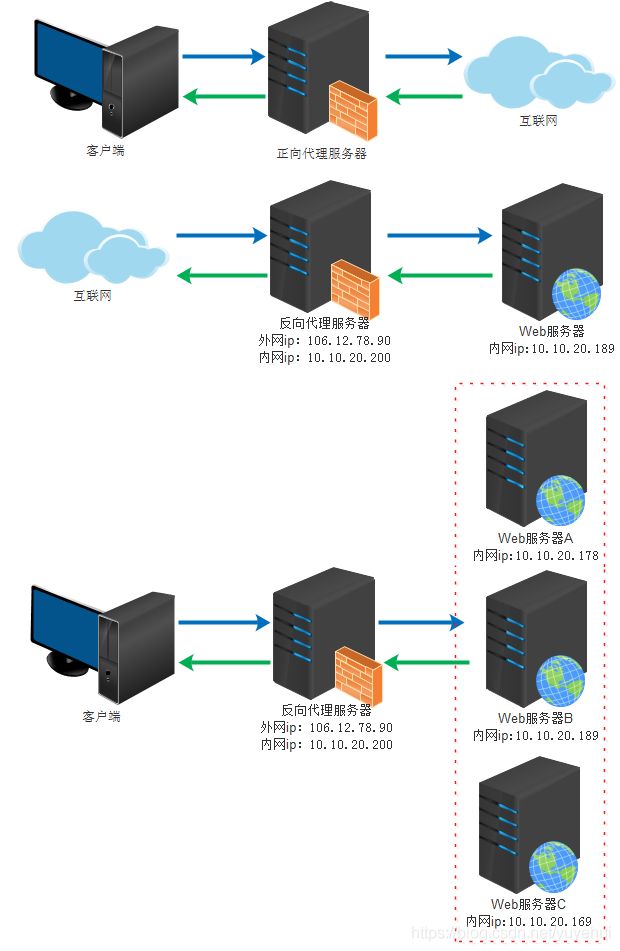
1. 正向代理
定义:正向代理用来代理客户端
作用:
① 访问原来无法访问的资源;
② 用作缓存,加速访问速度;
③ 对客户端访问授权,上网进行认证;
④ 代理可以记录用户访问记录(上网行为管理),对外隐藏用户信息。
2. 反向代理
定义:反向代理用来代理服务端
作用:
① 保护内网安全;
② 负载均衡;
③ 缓存,减少服务器的压力。
3.2 Nginx的作用
① 反向代理,将多台服务器代理成一台服务器;
② 负载均衡,将多个请求分配到多台服务器上,减轻单台服务器压力,提高服务吞吐量;
③ 动静分离,nginx可用作静态文件的缓存服务器,提高访问速度。
3.2 事件驱动架构
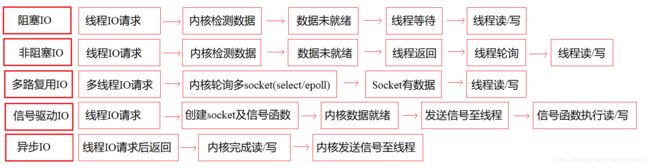
3.2.1 IO模型
1. IO请求两步骤(读)
内核查看数据是否就绪
数据拷贝(磁盘->内核缓冲区->用户缓冲区)
2. IO分类及其原理
3.2.2 多路复用器
多路复用器有三种模式select、poll、epoll,三种模式的优缺点如下表。
| select | poll | epoll | |
|---|---|---|---|
| 操作方式 | 轮询 | 轮询 | 回调 |
| 就绪队列 | 数组 | 链表 | 链表 |
| IO效率 | 调用方式为线性遍历,复杂度为O(n) | 调用方式为线性遍历,复杂度为O(n) | 事件通知方式,若fd就绪,系统注册的回调函被调用,复杂度O(1) |
3.2.3 Nginx事件驱动架构
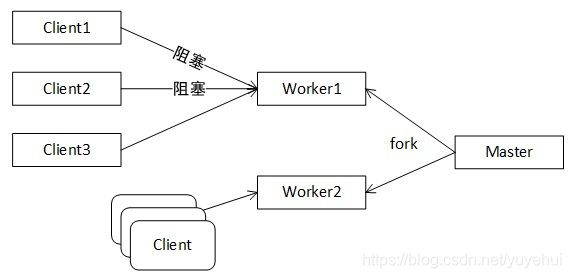
Nginx采用epoll模型,实现异步非阻塞的事件处理机制。如下图,当多个client请求worker1,假设client1请求阻塞,由于异步非阻塞机制,worker1仍可以处理其他客户端请求。
3.3 可预见式进程模型
Nginx启动后,包含一个master进程和多个worker进程,其结构如下图,worker进程数量一般配置为内核数量。
master进程功能包括接收信号,向worker进程发信号,监控worker进程状态,重启worker进程等;worker进程功能为处理基本的网络事件。

4 MongoDB
你好
- - -问题集锦- - -
1 MySQL相关问题
1. InnoDB存储引擎,三层B+树,单表能存储多少数据
MySQl存储单元为1页,1页为16K,即16384Byte
非叶子节点存储单元为主键+指针,大小为8+6=14Byte
单页可存储16384/14 ≈ 1170个单元,即可存储1170个子节点
每个存储单元可标记1页,则前两层可标记1170x1170页
第三层叶子节点存储数据,每条数据约1K,单页则可存储16/1=16个数据
三层 B+树,单表可存数据约为1170x1170x16=21902400条数据
2. between and查询,MySQL如何优化查询速度
假设针对where条件列已建立索引
扫描索引树时,获取最大值和最小值
然后从叶子结点的链表读取数据
3. 覆盖索引与回表
假设有表t(id PK, name KEY, sex, flag),其中,id是聚集索引,name是普通索引,表中有4条数据(1, shenjian, m, A)、(3, zhangsan, m, A)、(5, lisi, m, A)、(9, wangwu, f, B),若有查询操作“select * from t where name=‘lisi’”,则执行如下图
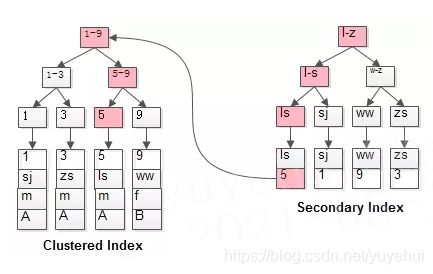
如上图粉红色路径,先定位主键值,再定位行记录,即回表操作,性能相较扫一遍索引树更低;覆盖索引将被查询的字段,建立到联合索引里去,不需要回表,一次扫描索引即可获得数据。
4. SQL执行慢,如何优化
执行过程:客户端->连接->缓存->解析器->优化器->执行器->服务端
连接优化:限制连接数;使用连接池(降低消耗、管理简单)。
缓存优化:修改架构,即加缓存。
使用优化器:使用慢查询;使用show profiles查询sql效率;explain;sql优化。
表设计优化:使用合适的引擎;字段长度够用即可;不要使用视图和存储过程;不要存图片、文本等信息;表设计合理,符合三范式。
优化方向总结:SQL语句和索引;存储引擎和表结构;数据库架构;MySQL配置;硬件与操作系统。
5. 索引下推
******
2 Java基础相关问题
1. Data注解是否有问题
A类继承B类,使用@Data注解的A类自动生成的toString()函数无法打印B类的成员变量
2. 切面编程如何理解
在运行时,动态地将代码切入到类的指定方法、指定位置上的编程思想就是面向切面的编程。
3. spring容器中,实例加载顺序
******
4. Inherit组合注解使用
******
5. 注解如何起作用的
******
3 常用组件相关问题
1. 某现场升级后Nginx问题
进程配置:主进程 + hms用户进程 + hcs用户进程,
配置文件:hms用户配置文件和hcs用户配置文件,
问题现象:hms用户进程、hcs用户进程不能同时工作,其中一个会挂死,
解决办法:将hcs用户配置文件合并到hms用户配置文件后,解决了该问题,
原因:?