【深度学习】cs224n 自然语言处理
传统NLP(2012年以前)
未加入神经网络,在传统NLP里,我们把words看作是离散的符号,这样在英语中基本有无限多的词语,也就代表每一个向量是无限大的;
并且无法表示单词之间的关系;

Word2vec algorithm(word vector)
想法来源:
- 拥有了一大堆文本;
- 每一个单词在一个固定的词汇表里都可以用一个向量one-hot表示;
- 对于文本中的每一个位置,都存在一个中心词center和一个上下文(context)词outside;
- 利用两个单词词向量(center和outside)的相似性去计算通过c得到o的概率;
- 不断调整词向量去最大化这种概率。


Word Vectors and Word Senses

- 为什么不直接构造一个共现矩阵?

一个是基于奇异值分解(SVD)的LSA算法,该方法对term-document矩阵(矩阵的每个元素为tf-idf)进行奇异值分解,从而得到term的向量表示和document的向量表示。此处使用的tf-idf主要还是term的全局统计特征。
另一个方法是word2vec算法,该算法可以分为skip-gram 和 continuous bag-of-words(CBOW)两类,但都是基于局部滑动窗口计算的。即,该方法利用了局部的上下文特征(local context)
- 基于窗口法的共现矩阵:
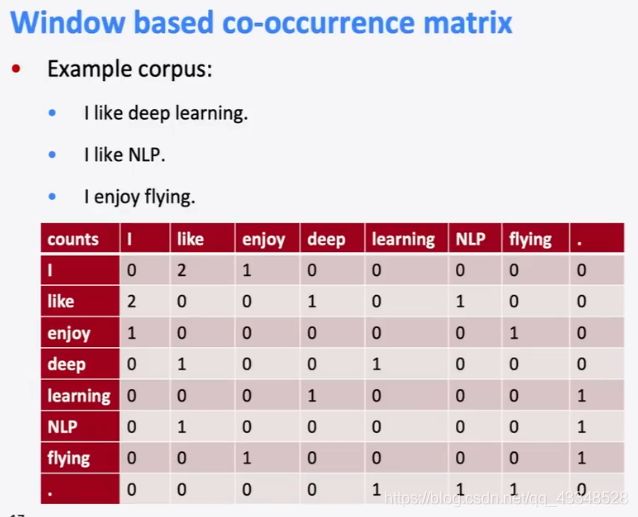
- 得到的这个大的共现矩阵,可以通过SVD(奇异值分解)的手段,转换成3个小的矩阵相乘;
- 由于这个重要的性质,SVD可以用于PCA降维,来做数据压缩和去噪。也可以用于推荐算法,将用户和喜好对应的矩阵做特征分解,进而得到隐含的用户需求来做推荐。同时也可以用于NLP中的算法,比如潜在语义索引(LSI)。下面我们就对SVD用于PCA降维做一个介绍。
- 基于计数原则和直接预测的方式的对比:
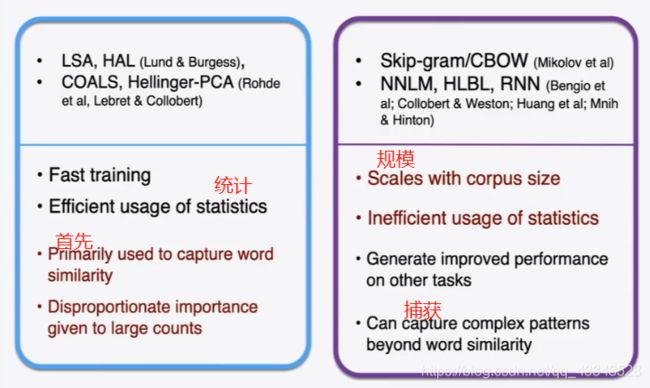
disproportionate:不成比例的
GloVe:通过共生矩阵概率的比率值/比例值(做除法) 能够 编码出词向量的相关性意义成分
一个是基于奇异值分解(SVD)的LSA(latent semantic analysis潜在语义分析)算法,该方法对term-document矩阵(矩阵的每个元素为tf-idf)进行奇异值分解,从而得到term的向量表示和document的向量表示。此处使用的tf-idf主要还是term的全局统计特征。
另一个方法是word2vec算法,该算法可以分为skip-gram 和 continuous bag-of-words(CBOW)两类,但都是基于局部滑动窗口计算的。即,该方法利用了局部的上下文特征(local context)
- LSA和word2vec作为两大类方法的代表,一个是利用了全局特征的矩阵分解方法,一个是利用局部上下文的方法。
- GloVe模型就是将这两中特征合并到一起的,即使用了语料库的全局统计(overall statistics)特征,也使用了局部的上下文特征(即滑动窗口)。为了做到这一点GloVe模型引入了Co-occurrence Probabilities Matrix。


https://zhuanlan.zhihu.com/p/42073620 该文章里面有GloVe的详细过程
- 词频共现矩阵的方式获得每一个词语的向量后,画图,其中直线距离越近的2个词含义越接近
- wordvec得到每个词的向量后,画图,通过词语之间的角度来确定相似性
Assignment 2
- word2vec.py
import numpy as np
import random
from utils.gradcheck import gradcheck_naive
from utils.utils import normalizeRows, softmax
def sigmoid(x):
"""
Compute the sigmoid function for the input here.
Arguments:
x -- A scalar or numpy array.
Return:
s -- sigmoid(x)
"""
### YOUR CODE HERE
s = 1.0 / (1.0 + np.exp(-x))
### END YOUR CODE
return s
def naiveSoftmaxLossAndGradient(
centerWordVec,
outsideWordIdx,
outsideVectors,
dataset
):
""" Naive Softmax loss & gradient function for word2vec models
Implement the naive softmax loss and gradients between a center word's
embedding and an outside word's embedding. This will be the building block
for our word2vec models.
Arguments:
centerWordVec -- numpy ndarray, center word's embedding
(v_c in the pdf handout)
outsideWordIdx -- integer, the index of the outside word
(o of u_o in the pdf handout)
outsideVectors -- outside vectors (rows of matrix) for all words in vocab
(U in the pdf handout)
dataset -- needed for negative sampling, unused here.
Return:
loss -- naive softmax loss
gradCenterVec -- the gradient with respect to the center word vector
(dJ / dv_c in the pdf handout)
gradOutsideVecs -- the gradient with respect to all the outside word vectors
(dJ / dU)
"""
### YOUR CODE HERE
### Please use the provided softmax function (imported earlier in this file)
### This numerically stable implementation helps you avoid issues pertaining
### to integer overflow.
# centerWordVec: (embedding_dim, 1)
# outsideVectors: (vocab_size, embedding_dim)
scores = np.dot(outsideVectors, centerWordVec) # (vocab_size, 1)
probs = softmax(scores) # y_hat (vocab_size, 1)
loss = - np.log(probs[outsideWordIdx])
dscores = probs.copy()
dscores[outsideWordIdx] = dscores[outsideWordIdx] - 1
gradCenterVec = np.dot(outsideVectors.T, dscores) # (embedding_dim, 1)
gradOutsideVecs = np.outer(dscores, centerWordVec) # (vacab_size, embedding_dim)
### END YOUR CODE
return loss, gradCenterVec, gradOutsideVecs
def getNegativeSamples(outsideWordIdx, dataset, K):
""" Samples K indexes which are not the outsideWordIdx """
negSampleWordIndices = [None] * K
for k in range(K):
newidx = dataset.sampleTokenIdx()
while newidx == outsideWordIdx:
newidx = dataset.sampleTokenIdx()
negSampleWordIndices[k] = newidx
return negSampleWordIndices
def negSamplingLossAndGradient(
centerWordVec,
outsideWordIdx,
outsideVectors,
dataset,
K=10
):
""" Negative sampling loss function for word2vec models
Implement the negative sampling loss and gradients for a centerWordVec
and a outsideWordIdx word vector as a building block for word2vec
models. K is the number of negative samples to take.
Note: The same word may be negatively sampled multiple times. For
example if an outside word is sampled twice, you shall have to
double count the gradient with respect to this word. Thrice if
it was sampled three times, and so forth.
Arguments/Return Specifications: same as naiveSoftmaxLossAndGradient
"""
# Negative sampling of words is done for you. Do not modify this if you
# wish to match the autograder and receive points!
negSampleWordIndices = getNegativeSamples(outsideWordIdx, dataset, K)
indices = [outsideWordIdx] + negSampleWordIndices
### YOUR CODE HERE
### Please use your implementation of sigmoid in here.
# centerWordVec: (embedding_dim, 1)
# outsideVectors: (vocab_size, embedding_dim)
gradCenterVec = np.zeros(centerWordVec.shape)
gradOutsideVecs = np.zeros(outsideVectors.shape)
loss = 0.0
u_o = outsideVectors[outsideWordIdx]
z = sigmoid(np.dot(u_o, centerWordVec))
loss = loss - np.log(z)
gradCenterVec += u_o * (z - 1)
gradOutsideVecs[outsideWordIdx] = centerWordVec * (z - 1)
for i in range(K):
neg_idx = indices[i + 1]
u_k = outsideVectors[neg_idx]
z = sigmoid(-np.dot(u_k, centerWordVec))
loss = loss - np.log(z)
gradCenterVec += (1 - z) * u_k
gradOutsideVecs[neg_idx] += (1 - z) * centerWordVec
### END YOUR CODE
return loss, gradCenterVec, gradOutsideVecs
def skipgram(currentCenterWord, windowSize, outsideWords, word2Ind,
centerWordVectors, outsideVectors, dataset,
word2vecLossAndGradient=naiveSoftmaxLossAndGradient):
""" Skip-gram model in word2vec
Implement the skip-gram model in this function.
Arguments:
currentCenterWord -- a string of the current center word
windowSize -- integer, context window size
outsideWords -- list of no more than 2*windowSize strings, the outside words
word2Ind -- a dictionary that maps words to their indices in
the word vector list
centerWordVectors -- center word vectors (as rows) for all words in vocab
(V in pdf handout)
outsideVectors -- outside word vectors (as rows) for all words in vocab
(U in pdf handout)
word2vecLossAndGradient -- the loss and gradient function for
a prediction vector given the outsideWordIdx
word vectors, could be one of the two
loss functions you implemented above.
Return:
loss -- the loss function value for the skip-gram model
(J in the pdf handout)
gradCenterVecs -- the gradient with respect to the center word vectors
(dJ / dV in the pdf handout)
gradOutsideVectors -- the gradient with respect to the outside word vectors
(dJ / dU in the pdf handout)
"""
loss = 0.0
gradCenterVecs = np.zeros(centerWordVectors.shape)
gradOutsideVectors = np.zeros(outsideVectors.shape)
### YOUR CODE HERE
center_idx = word2Ind[currentCenterWord]
centerWordVec = centerWordVectors[center_idx]
for word in outsideWords:
outside_idx = word2Ind[word]
loss_mini, gradCenter_mini, gradOutside_mini = word2vecLossAndGradient(centerWordVec=centerWordVec,outsideWordIdx=outside_idx,outsideVectors=outsideVectors,dataset=dataset)
loss += loss_mini
gradCenterVecs[center_idx] += gradCenter_mini
gradOutsideVectors += gradOutside_mini
### END YOUR CODE
return loss, gradCenterVecs, gradOutsideVectors
- sgd.py
def sgd(f, x0, step, iterations, postprocessing=None, useSaved=False,
PRINT_EVERY=10):
""" Stochastic Gradient Descent
Implement the stochastic gradient descent method in this function.
Arguments:
f -- the function to optimize, it should take a single
argument and yield two outputs, a loss and the gradient
with respect to the arguments
x0 -- the initial point to start SGD from
step -- the step size for SGD
iterations -- total iterations to run SGD for
postprocessing -- postprocessing function for the parameters
if necessary. In the case of word2vec we will need to
normalize the word vectors to have unit length.
PRINT_EVERY -- specifies how many iterations to output loss
Return:
x -- the parameter value after SGD finishes
"""
# Anneal learning rate every several iterations
ANNEAL_EVERY = 20000
if useSaved:
start_iter, oldx, state = load_saved_params()
if start_iter > 0:
x0 = oldx
step *= 0.5 ** (start_iter / ANNEAL_EVERY)
if state:
random.setstate(state)
else:
start_iter = 0
x = x0
if not postprocessing:
postprocessing = lambda x: x
exploss = None
for iter in range(start_iter + 1, iterations + 1):
# You might want to print the progress every few iterations.
loss = None
### YOUR CODE HERE
loss, each_gradient = f(x)
x = x - each_gradient * step
### END YOUR CODE
x = postprocessing(x)
if iter % PRINT_EVERY == 0:
if not exploss:
exploss = loss
else:
exploss = .95 * exploss + .05 * loss
print("iter %d: %f" % (iter, exploss))
if iter % SAVE_PARAMS_EVERY == 0 and useSaved:
save_params(iter, x)
if iter % ANNEAL_EVERY == 0:
step *= 0.5
return x
Neural Dependency Parser
实现一个neural dependency parser。通俗点讲,给定一个句子,你的parser可以分析出它的语法结构,最终输出一个类似ast的东西。
parser(解析器)词语之间的依赖关系,主要是用来给一个句子做语法分析,分析出它的语法结构。
Dependency Structure展示了词语之前的依赖关系,通常用箭头表示其依存关系,有时也会在箭头上标出其具体的语法关系,如是主语还是宾语关系等。
1. 两种linguidtic structure(语言结构):
(1)constituency(选区) = phrase structure grammer(短语结构语法) = context-free grammars(上下文无关文法)(CFGs) : 短语结构将单词组织成嵌套的选区;
先将单词依照词性分组,然后就是依照相应的词性语法,从一个单词,变成一个短语,然后再连接,不断连接,最后形成整句。
(2) dependency structure(依赖结构)
依存结构显示哪些词依赖(修饰或是其参数)哪些其他词;
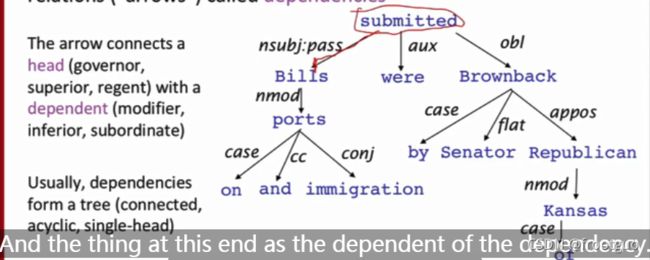

- 依赖解析的信息来源是什么?
- 双词的亲缘关系 : plausible合理的
- 依赖距离:通常是较为靠近的单词
- 介入材料:依赖很少会跨越介入动词或者标点符号
- 头数:一个头通常在哪一边有多少依赖
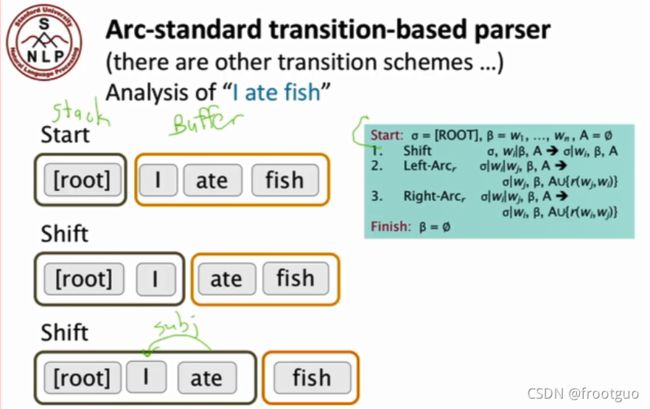
- 较为广泛运用的解析器 Greedy transition-based parsing:
以下为该解析器原理的一个简单例子:

-
产生机器学习概念后的解析器:MaltParser
分类器会告诉我下一步的操作,是shift,还是向右,还是向左
传统解析器的缺点在于:1. 人需要手工去设计这些词之间的feature,导致这些feature之间是非常稀疏的,2. 这些feature中的每一个feature都匹配到很少的东西,代表匹配通常是不完整的,3. 很大的计算量。 -
如果用神经网络整个dependency parser的过程:
(1)初始化: 通过load_and_preprocess_data函数,得到parser,embeddings,train_data,dev_set, test_data
(2)建立模型PaeserModel
(3)train and eval
Language models and RNN
language model: a system that predicts the next word
1. n-gram language models
一个n-gram就是一组n个连续的词语。
目的:主要是利用n-gram来预测下一个单词

举一个简单的例子:

(1)针对分子是0的情况下,就会直接使得结果变成稀疏的分布,可是我们不希望它直接变成0,而是应该有一个较小的概率,这种一般就是进行平滑了,smoothing。
(2)针对分母为0,解决办法,你需要去要调整为n-1作为分母,而不是n作为分母
如果只是简单的不断增加n,其实是会加重稀疏问题的
2. neural language model
(1)fixed window-based neural model

相对于n-gram model的优势:
(1)没有稀疏性问题;
(2)你不需要去储存所有你见过的n-grams
问题:
(1)fixed window太小了,涉及到的上下文信息有限
(2)增大window,就需要增大W(weight矩阵)
(3)weight矩阵中每个词之间不存在相关性,不存在嵌入共享
(2)recurrent neural networks(RNN)
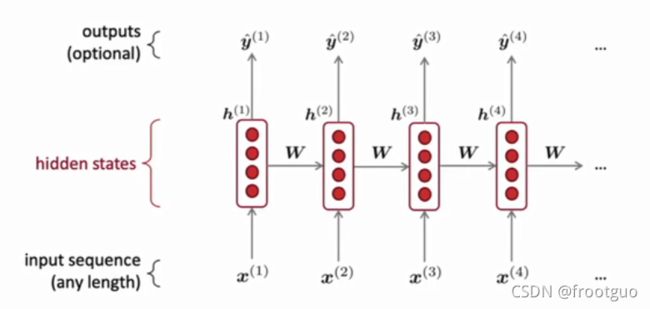

Wh和We是复用的;
RNN优点:
(1)能够计算任何长度的输入;
(2)计算当前步骤能够用到之前很多步骤的信息
(3)对于较长的输入,模型的大小不会增大(因为Wh和We是复用的)
(4) 相似的权重应用在每一步,因此对于处理输入具有对称性
缺点:
(1)计算很慢(因为没办法并行,依赖于上一个timestep的h)
(2)在实践中,也并不能用到很多之前步骤的信息
Vanishing Gradients, Fancy RNNs
vanishing gradients:消失的梯度
NMT(neural machine translation)
Vanishing gradients
-
梯度消失定义:
因为RNN存在累计梯度,而累计梯度是所有中间梯度的乘积,当你乘以很小的数字时,就会导致结果越来越小;如果你乘以很大的数字时,也同样很容易导致梯度爆炸; -
为什么梯度消失是一个问题?
当你更新模型权重时,你从附近得到的信号(signal,激活)是远远超出从远端得到的信号的。 -
为什么梯度爆炸是一个问题?
如果你的梯度变得很大,那么你的SGD更新步骤将会变得很大,直接影响你的参数

-
解决梯度爆炸的方法:梯度裁剪
该方法中的阈值是人为设定的

-
如何解决梯度消失问题?
LSTM被提出了

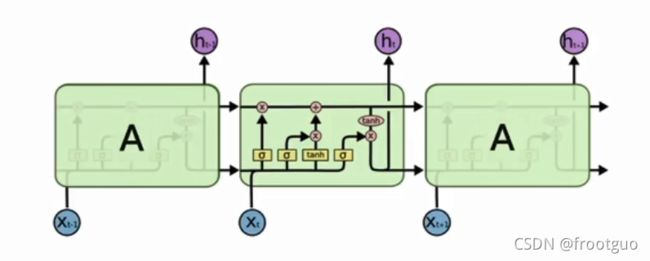
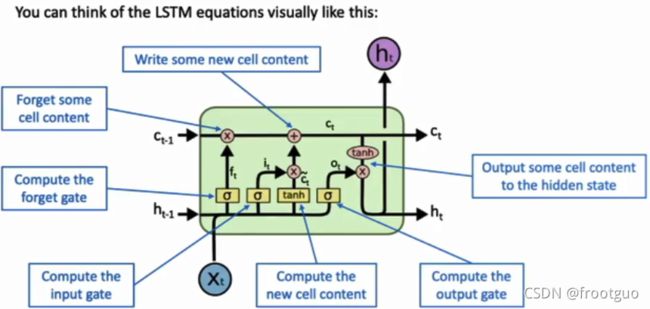
GRU(gated recurrent units)
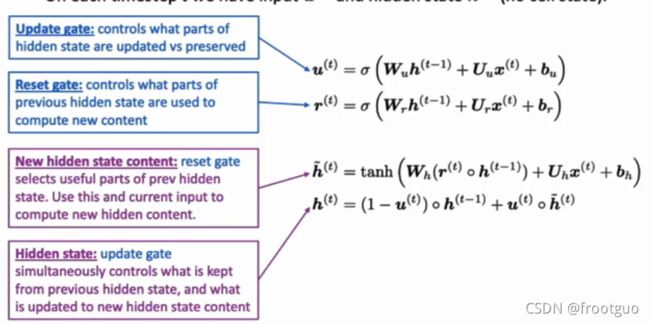
把update gate想象成shortcut
把reset gate考虑为只采用前面一部分的值,忽略前面的一些内容
Machine translation
NMT(neural machine translation)
translation, Seq2Seq, Attention
machine translation is a major use-case of sequence-to-sequence.
1. pre-neural machine translation
- 一直到2013:SMT(statistical machine translation)
2. NMT(neural machine translation)
- 2014:NMT(neural machine translation)
the neural network architecture is called sequence-to-sequence,包含两个RNN

许多其他的NLP任务也都可以称作是sequence-to-sequence问题:
(1)概述(long text->short text)
(2)对话问题
(3)parsing问题
(4)代码生成问题
- 如何训练NMT
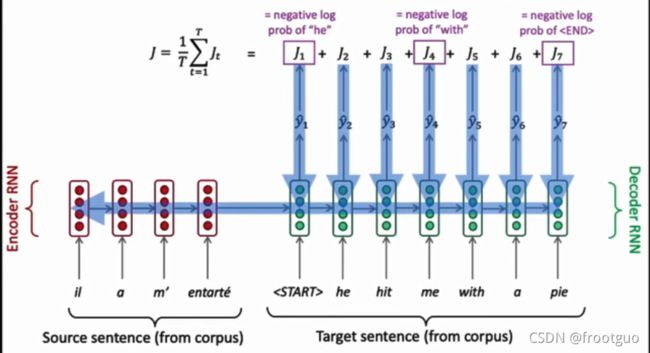
训练的过程中target sentence是直接规定好了的,是已知的,而不像预测过程中是由前一个预测出来的单词作为下一个输入再得到的。
- greedy decoding(在预测的时候)
每一次只选择最好的结果
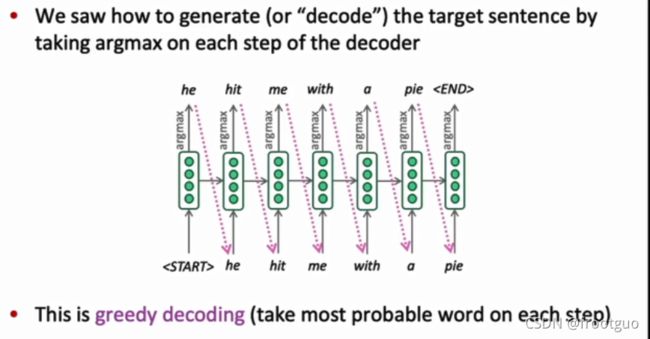
这种方式的问题:
每一步softmax最大的值组成的句子,在全局来说,概率不一定是最大的
同时也意味着greedy decoding不能够回溯,一旦预测出的下一个词是错误的也没有办法回溯,回头去重新预测对的
每一步最优并不一定意味着全局最优
但是如果我们将每一步得出后一步的概率都乘起来来找全局最优,虽然可以找到全局最优,但是又会出现计算量过大的问题,因此,考虑的手段如下:
-
Beam search decoding(也是在预测的时候):
在decoder的每一步保持跟踪k个最有可能的翻译(称作翻译假设)
beam search 也无法保证能够找到最佳的解决方案。

一个简单的beam search 的例子:

对于beam search decoding来说什么时候停止:

停止后,如何选择优先级最高的(得分最高)的结果:
翻译假设(hypotheses)越长就意味着得分越低,解决这个问题只需要normalize by length就行了(就是将每个假设总的得分除以这个假设的长度就行了) -
NMT 的优势:
(1)更好的performance
(2)可以进行端到端训练,更方便
(3)工程量相对较少
缺陷:
(1)缺少解释性
(2)黑箱操作,不容易控制
3. 如何评估一个machine translation:
BLEU(bilingual evaluation understudy)

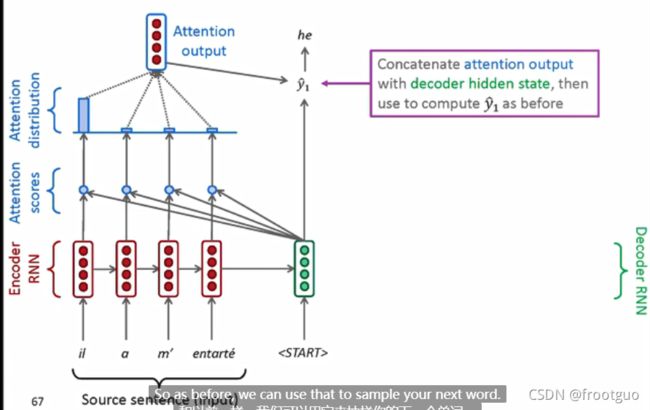
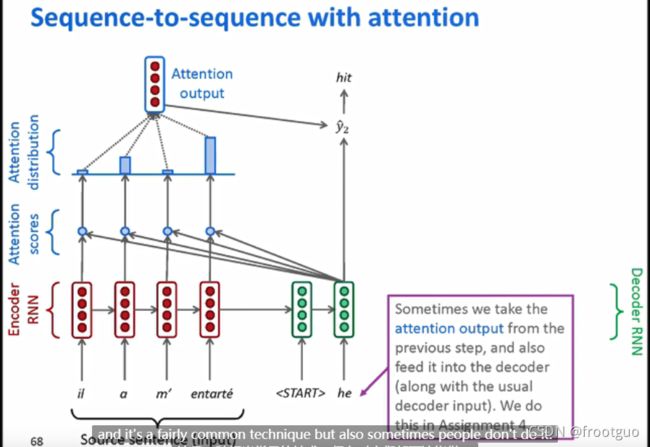
4. 对原始seq2seq的一个重要改进:Attention
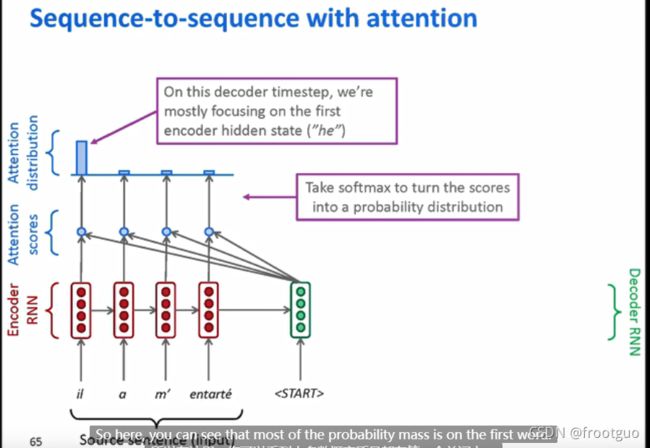
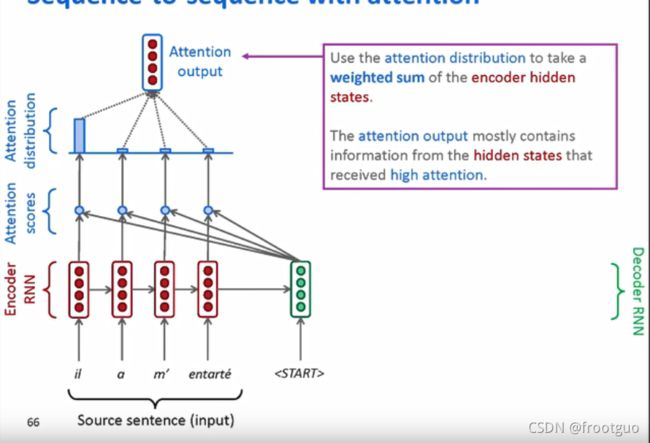
-
需要attention的原因:最后仅仅是一个向量代表了encoder的全部输入到decoder中,存在信息瓶颈
-
attention的核心思想:在decoder的每一步,直接连接到encoder为了聚焦在源序列的重要部分

-
步骤如下:
Question answering
(cs276是跟网页搜索相关的)
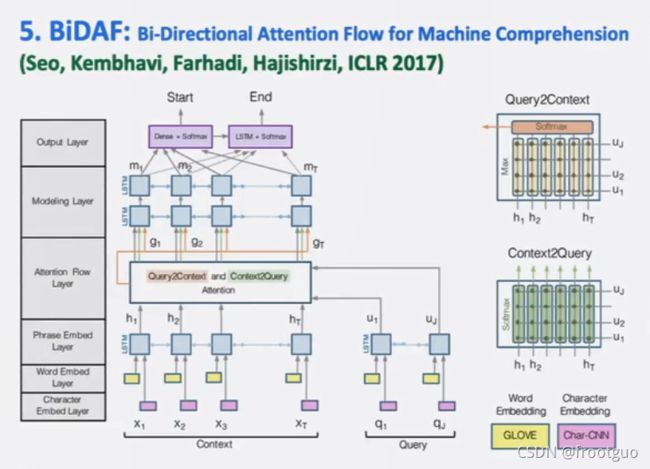
最初的问答问题更接近于阅读理解,后期出现了开放领域问答系统

question answering 的经典之作:
Convolutional networks for NLP


可以通过很深的CNN(类似于视觉中的)来获得另一种word vectors,一般叫做character embedding
Subword models

characte-level models

- OOV是词表外词
(1)完全的character-level模型
就是一个字母一个向量
(2)word piece models
混合的感觉

bert就是在word-piece的基础上
Contextual word Embeddings
1. reflections on word representations

对于的单词没有任何区别
不在意一个单词所在上下文的具体语义,一个单词,任何状态下都采用同一个向量
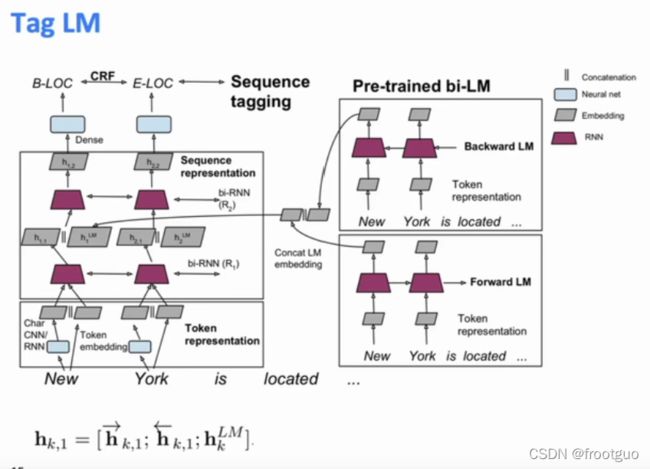
2. pre-ELMo and ELMo
tag LM == pre-ELMo
ELMo(Embeddings from Language Models):

3.ULMfit and onward
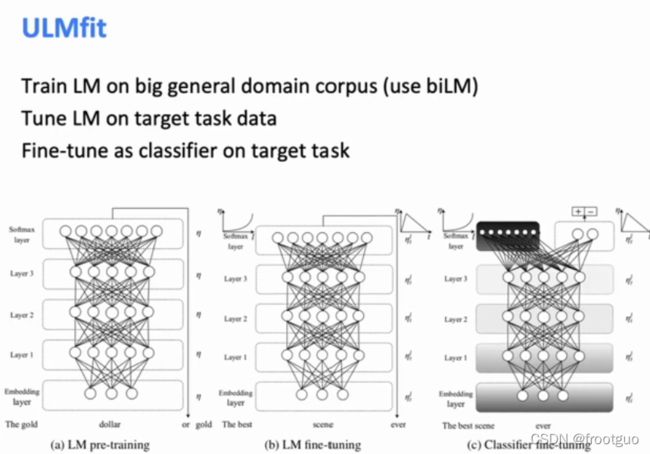

4. Transformaer architectures
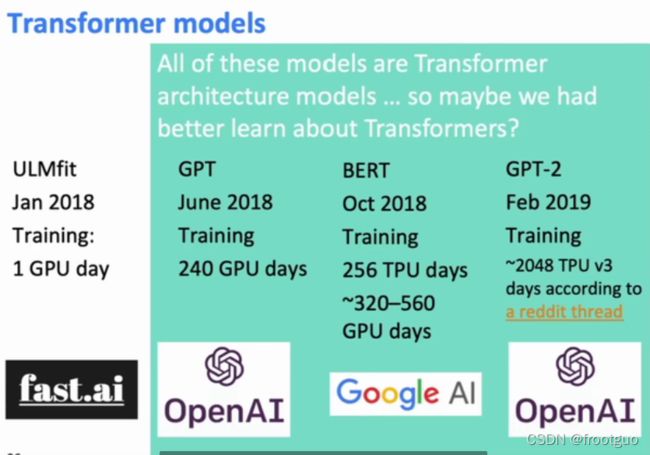
解决rnn无法并行化的问题
Transformers and Self-Attention
解决rnn无法并行化的问题
看李沐的论文讲解
Natural Language Generation

1. recap what we already know about NLG



2. more on decoding algorithms
(1)sampling-based decoding

3. NLG tasks and neural approaches to them
(1)summarization



(2)dialogue

(3)storytelling

4. NLG evaluation: a tricky situation
(1) summarization evaluation:ROUGE


- 重点:

Coreference resolution
1. what is coreference resolution
identify all mentions that refer to the same real-world entity(世界实体)
就是要找到一段话中代表同一个实体的 多个表示

2. mention detection



4. rule-based(Hobbs Algorithm)
5. mention-pair models
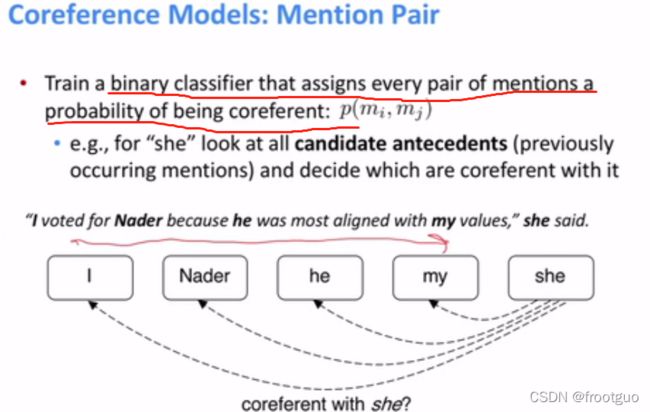
6. mention ranking models
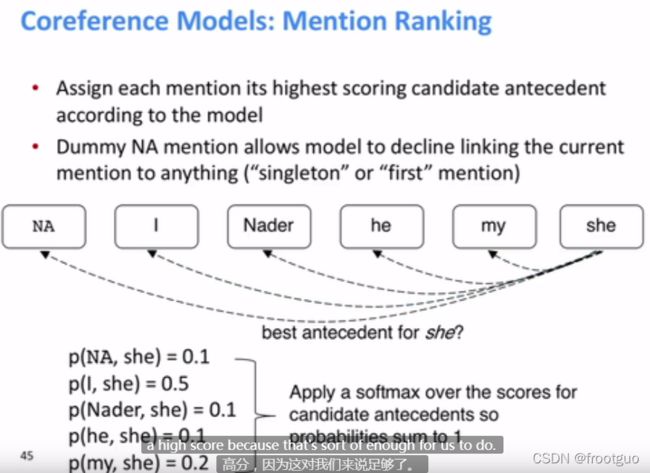
Multitask learning
提出了个统一NLP领域多任务模型
相比于bert bert还需要针对不同任务,对一些top layers进行训练调参或者修改最后输出的模型结构,他们这个直接就是一个模型,不换参数,不换结构,针对多个NLP任务。
Tree recursive neural networks, Constituency parsing, and Sentiment
语言也是由多各部分组成的,递归的理解每一个部分
例如:知道一个句子中的每一个单词的词向量,利用这些词向量和parsing分析能够得到一些短语的空间向量,最后得到整个句子的空间向量