机器学习实战(基于Scikit-Learn和TensorFlow)(Ⅱ)
机器学习实战(基于Scikit-Learn和TensorFlow)(Ⅱ)
本文参考书籍:《机器学习实战(基于Scikit-Learn和TensorFlow)》
目录
- 机器学习实战(基于Scikit-Learn和TensorFlow)(Ⅱ)
-
- 5.支持向量机
-
- 线性SVM分类
-
- 软间隔分类
- 非线性SVM分类
-
- 多项式核
- 添加相似特征
- 高斯RBF核函数
- 计算复杂度
- SVM回归
- 工作原理
-
- 决策函数和预测
- 训练目标
-
- 二次规划
- 对偶问题
- 核化SVM
- 在线SVM
- 6.决策树
-
- 决策树训练和可视化
- 作出预测
- 估算类别概率
- CART训练算法
- 计算复杂度
- 基尼不纯度还是信息熵
- 正则化超参数
- 回归
- 不稳定性
- 7.集成学习和随机森林
-
- 投票分类器
- bagging 和 pasting
-
- Scikit-Learn的bagging和pasting
- 包外评估
- Random Patches和随机子空间
- 随机森林
-
- 极端随机树
- 特征重要性
- 提升法
-
- AdaBoost
- 梯度提升
- 堆叠法
- 8.降维
-
- 维度的诅咒
- 数据降维的主要方法
-
- 投影
- 流形学习
- PCA
-
- 保留差异性
- 主成分
- 低维度投影
- 使用Scikit-Learn
- 方差解释率
- 选择正确数量的维度
- PCA压缩
- 增量PCA
- 随机PCA
- 核主成分分析
-
- 选择核函数和调整超参数
- 局部线性嵌入
- 其他降维技巧
5.支持向量机
SVM能执行线性或非线性分类、回归,或异常值检测任务。SVM特别适用于中小型复杂数据集的分类
线性SVM分类
SVM对特征缩放非常敏感
软间隔分类
若我们严格地让所有实例都不在间隔内,并且位于正确的一边,这就是硬间隔分类。硬间隔分类只在数据是线性可分的时候才有效,且对异常值非常敏感。
要避免这些问题,最好使用更灵活的模型。目标是尽可能在保持间隔宽阔和限制间隔违例(即位于间隔之内,甚至在错误的一边的实例)之间找到平衡,这就是软间隔分类。
在Scikit-learn的SVM类中,可通过超参数C来控制这个平衡:C越小,间隔越宽,但间隔违例也越多。
若SVM模型过拟合,可以试试通过降低C来进行正则化
加载鸢尾花数据集,缩放特征,训练一个线性SVM模型(使用LinearSVC类,C=0.1,使用hinge损失函数)用来检测Virginica鸢尾花:
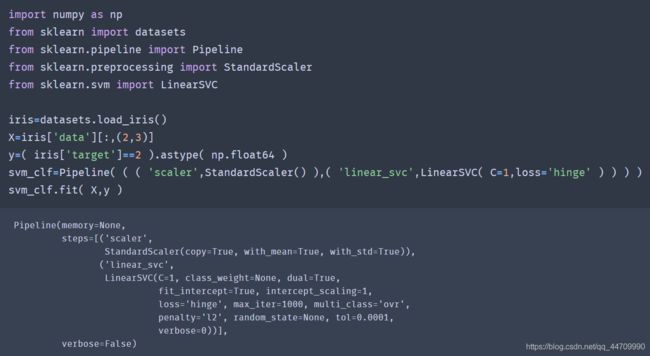

与Logistic回归分类器不同的是,SVM分类器不会输出每个类别的概率
非线性SVM分类
处理非线性数据集的方法之一是添加更多特征,如多项式特征,某些情况下,这可能导致数据集变得线性可分离
可搭建一条流水线:一个PolynomialFeatures转换器,接着一个StandardScaler,然后是LinearSVC。
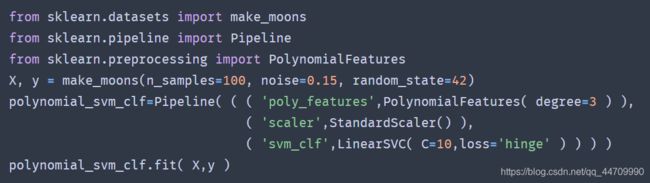

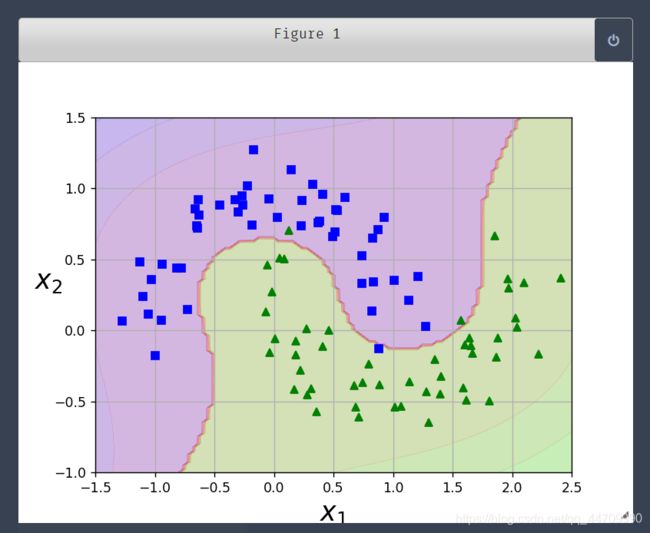
多项式核
核技巧产生的结果就跟添加了许多多项式特征甚至是非常高阶的多项式特征一样,但实际上并不需要真的添加。因为实际没有添加任何特征,所以也就不存在数量爆炸的组合特征了。核技巧由SVC类来实现

这段代码使用了一个3阶多项式内核训练SVM分类器。若模型过拟合,应降低多项式阶数;若欠拟合,可提升多项式阶数;超参数coef0控制的是模型受高阶多项式还是低阶多项式影响的程度
添加相似特征
解决非线性问题的另一种技术是添加相似特征。这些特征经过相似函数计算得出,相似函数可以测量每个实例与一个特定地标(landmark)之间的相似度。
选择地标最简单的方法是在数据集里每一个实例的位置上创建一个地标。这会创造出许多维度,因而也增加了转换后的训练集线性可分离的机会。缺点是,一个有m个实例n个特征的训练集会被转换成一个m个实例m个特征的训练集(假设抛弃了原始特征)。若训练集非常大,那就会得到同样大数量的特征
高斯RBF核函数
核技巧能够产生的结果就跟添加了许多相似特征一样,但实际上并不需要添加。使用SVC类试试高斯RBF核(高斯径向基函数):



增加gamma值会使钟形曲线变得更窄,因此每个实例的影响范围随之变小:决策边界变得更不规则,开始围着单个实例绕弯。减小gamma值使钟形曲线变得更宽,因而每个实例的影响范围增大,决策边界变得更平坦。γ就像是一个正则化的超参数:模型过拟合,就降低它的值,若欠拟合则提升它的值(类似超参数C)
选择核函数的经验法则是,永远先从线性核函数开始尝试(LinearSVC比SVC(kernel=‘linear’)快得多),特别是训练集非常大或特征非常多时。若训练集不太大,可以试试高斯RBF核,大多数情况下它都非常好用
计算复杂度

SVM回归
SVM算法不仅支持线性和非线性分类,而且还支持线性和非线性回归。诀窍在于将目标反转一下:不再是尝试拟合两个类别之间可能的最宽间隔的同时限制间隔违例,SVM回归要做的是让尽可能多的实例位于间隔内,同时限制间隔违例。间隔的宽度由超参数ε控制。
在间隔内添加更多的实例不会影响模型的预测,所以这个模型被称为ε不敏感
使用Scikit-learn的LinearSVR类来执行SVM回归:

要解决非线性回归任务,可以使用核化的SVM模型。
使用Scikit-learn的SVR类(支持核技巧)生成核化的SVM模型。SVR类是SVC类的回归等价物,LinearSVR类是LinearSVC类的回归等价物。
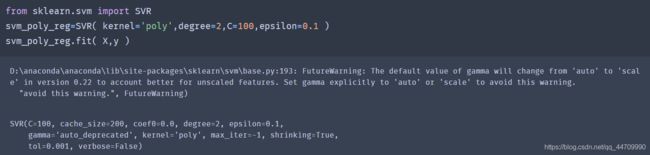
工作原理
决策函数和预测
训练目标
二次规划
对偶问题
核化SVM
在线SVM
6.决策树
与SVM一样,决策树也是一种多功能的机器学习算法,可以实现分类和回归任务,甚至是多输出任务。
决策树训练和可视化
在鸢尾花数据集上训练一个DecisionTreeClassifier:

要将决策树可视化,首先,使用export_graphviz()方法输出一个图形定义文件,命名为iris_tree.dot:

最后,可以使用graphviz包中的dot命令行工具将这个.dot文件转换为其他格式,例如pdf或png。
![]()

作出预测
决策树的特质之一就是它们需要的数据准备工作非常少。特别是,完全不需要进行特征缩放或集中
节点的samples属性统计它应用的训练实例数量。例如,有100个训练实例的花瓣长度大于2.45cm。节点的value属性说明了该节点上每个类别的训练实例数量。基尼属性衡量其不纯度:若应用的所有训练实例都属于同一个类别,那么节点就是纯的(gini=0)。
Scikit-learn使用的是CART算法,该算法仅生成二叉树。其他算法,如ID3生成的决策树其节点可以拥有两个以上的子节点
白盒与黑盒:
决策树是非常直观的,它们的决策也很容易解释,这类模型通常被称为白盒模型。与之相反的,随机森林或是神经网络是一种黑盒模型,它们能作出很棒的预测,你也可以轻松检查它们在作出预测时执行的计算,然而,通常很难解释清楚它们为什么作出这样的预测。相反,决策树提供了简单好用的分类规则
估算类别概率
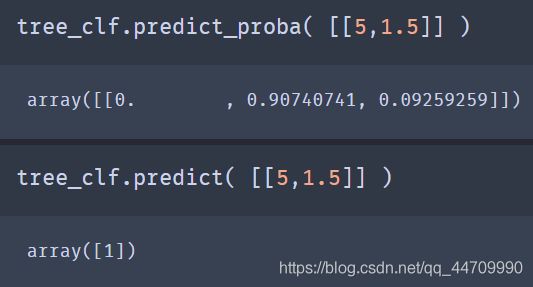
决策树同样可以估算某个实例属于特定类别k的概率:首先,跟随决策树找到该实例的叶节点,然后返回该节点中类别k的训练实例占比。
CART训练算法
计算复杂度
基尼不纯度还是信息熵
默认使用的是基尼不纯度来进行测量,可将超参数criterion设置为entropy来选择信息熵作为不纯度的测量方式。
基尼不纯度倾向于从树枝中分裂出最常见的类别,而信息熵则倾向于生产更平衡的树
正则化超参数
决策树极少对训练数据做出假设,若不加以限制,树的结构将跟随训练集变化,很可能过拟合。这种模型通常被称为非参数模型,这不是说它不包含任何参数(事实上它通常有很多参数),而是指在训练之前没有确定参数的数量,导致模型结构自由而紧密地贴近数据。相应的参数模型,如线性模型,则有预设好的一部分参数,因此其自由度受限,从而降低了过拟合的风险(增加了欠拟合的风险)
正则化超参数的选择取决于你所使用的模型,但通常来说,至少可以限制决策树的最大深度。在Scikit-learn中,这由超参数max_depth控制(默认值为None,意味着无限制)。减小max_depth可使模型正则化,从而降低过拟合的风险
DecisionTreeClassifier类还有一些其他的参数,可以限制决策树的形状:

还可以先不加约束地训练模型,然后再对不必要的结点进行剪枝。若一个结点的子节点全为叶节点,则该节点可被认为不必要,除非它所表示的纯度提升有重要的统计意义。
回归
决策树也可以执行回归任务。用Scikit-learn的DecisionTreeRegressor来构建一个回归树,在一个带噪声的二次数据集上进行训练,其中max_depth=2:

结果树如下图:

与之前的分类树相比,每个结点上不再是预测一个类别而是预测一个值。例如,若想对一个x1=0.6的新实例进行预测,那么从根节点开始遍历,最后到达预测value=0.1106的叶节点。这个预测结果是与这个叶节点关联的110个实例的平均目标值。在这110个实例上,预测产生的均方误差MSE等于0.0151
不稳定性
决策树青睐正交的决策边界(所有的分裂都与轴线垂直),这导致它们对训练集的旋转非常敏感。更概括地说,决策树的主要问题是它们对训练数据中的小变化非常敏感。随机森林通过对许多树的预测进行平均,可以限制这种不稳定性
7.集成学习和随机森林
投票分类器
要创建出一个更好的分类器,最简单的办法就是聚合每个分类器的预测,然后将得票最多的结果作为预测类别。这种大多数投票分类器被称为硬投票分类器
该投票法分类器的准确率通常比集成中最好的分类器还要高。当预测器尽可能互相独立时,集成方法的效果最优。获得多种分类器的方法之一就是使用不同的算法进行训练。这会增加它们犯不同类型错误的机会,从而提升集成的准确率
使用Scikit-learn创建并训练一个投票分类器,由三种不同的分类器组成:


看看每个分类器在测试集上的准确率:
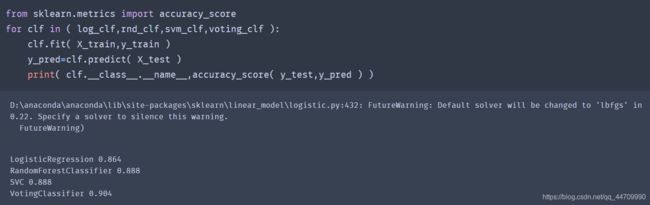
若所有分类器都能估算出类别的概率(即有predict_proba()方法),那么可以将概率在所有单个分类器上平均,然后让Scikit-Learn给出平均概率最高的类别作为预测。这被称为软投票法。通常它比硬投票法的表现更好,因为它给予那些高度自信的投票更高的权重。需用voting='soft’代替voting=‘hard’,并确保所有分类器都可以估算出概率。默认情况下,SVC类不能估算概率,需将其超参数probability设置为True(这会导致SVC使用交叉验证来估算类别概率,减慢训练速度,并会添加predict_proba()方法)。
bagging 和 pasting
获得不同种类分类器的方法之一是使用不同的训练算法。还有另一种方法是每个预测器使用的算法相同,但是在不同的训练集随机子集上进行训练。采样时如果将样本放回,这种方法叫做bagging,采样时样本不放回,叫做pasting
Scikit-Learn的bagging和pasting
Scikit-learn中的BaggingClassifier类可进行bagging和pasting(或BaggingRegressor用于回归)。
以下代码训练了一个包含500个决策树分类器的集成,每次随机从训练集中采样100个训练实例进行训练,然后放回(这是一个bagging的示例,若想使用pasting,只需设置bootstrap=False)。参数n_jobs用来指示Scikit-learn用多少CPU内核进行训练和预测(-1表示让scikit-learn使用所有可用内核):

集成预测的泛化效果很可能会比单独的决策树要好
bagging生成的模型通常比pasting好
包外评估
对于任意给定的预测器,使用bagging,有些实例可能会被采样多次,而有些实例则可能根本不被采样。BaggingClassifier默认采样m个训练实例,然后放回样本(bootstrap=True),m是训练集的大小。对于每个预测器来说,平均只对63%的训练实例进行采样,剩余37%未被采样的训练实例称为包外实例。
既然预测器在训练时从未见过这些包外实例,正好可以用这些实例进行评估,从而不需要单独的验证集或是交叉验证。将每个预测器在其包外实例上的评估结果进行平均,就可得到对集成的评估。
在Scikit-learn中,创建BaggingClassifier时,设置oob_score=True,就可请求在训练结束后自动进行包外评估。通过变量obb_score_可得到最终的评估分数:

根据包外评估结果,该BaggingClassifier分类器很可能在测试集上达到约90%的准确率,验证结果证明了这一点:

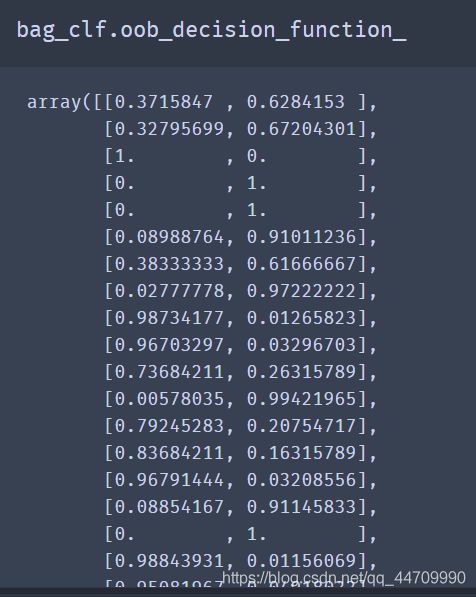
每个训练实例的包外决策函数也可通过变量oob_decision_function_获得。本例中(基础预测器具备predict_proba()方法),决策函数返回的是每个实例的类别概率。例如,包外评估估计,第三个训练实例有100%的概率属于正类
Random Patches和随机子空间
BaggingClassifier也支持对特征进行抽样,通过两个超参数控制:max_features和bootstrap_features。它们的工作方式与max_samples和bootstrap相同,只是抽样对象不再是实例,而是特征。因此,每个预测器将用输入特征的随机子集进行训练。
这对于处理高维输入(例如图像)特别有用。对训练实例和特征都进行抽样,被称为Random Patches方法。而保留所有训练实例但是对特征进行抽样称为随机子空间法
随机森林
以下代码使用所有可用的CPU内核,训练了一个拥有500颗树的随机森林分类器(每棵树限制为最多16个叶结点):

极端随机树
随机森林里单颗树的生长过程中,每个结点在分裂时仅考虑到了一个随机子集所包含的特征。若我们对每个特征使用随机阈值,而不是搜索得出的最佳阈值(如常规决策树),则可能让决策树生长得更加随机
这种极端随机的决策树组成的森林,被称为极端随机树集成。它以更高的偏差换取了更低的方差。
使用Scikit-learn的ExtraTreesClassifier可以创建一个极端随机树分类器。它的API与RandomForestClassifier相同
特征重要性
重要的特征更可能出现在靠近根节点的位置,而不重要的特征通常出现在靠近叶节点的位置(甚至不出现)。因此,通过计算一个特征在森林中所有树上的平均深度,可以估算出一个特征的重要程度。通过变量feature_importances_可以访问每个特征的重要性

若想要快速了解什么是真正重要的特征,随机森林是一个非常便利的方法,特别是当需要执行特征选择时
提升法
提升法(Boosting,最初被称为假设提升)是指可以将几个弱学习器结合成一个强学习器的任意集成方法。大多数提升法的总体思路是循环训练预测器,每次都对其前序作出一些改正。目前流行的提升法是AdaBoost(自适应提升法)和梯度提升
AdaBoost
新预测器对其前序进行纠正的办法之一,就是更多地关注前序拟合不足的训练实例。从而使新的预测器不断地越来越专注于难缠的问题,这就是AdaBoost使用的技术
使用Scikit-learn的AdaBoostClassifier训练一个AdaBoost分类器,它基于200个单层决策树:
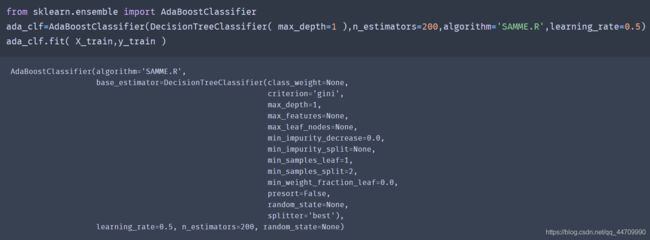
若AdaBoost集成过拟合,可以试试减少估算器数量,或提高基础估算器的正则化程度
梯度提升
梯度提升也是逐步在集成中添加预测器,每一个都对其前序作出改正。不同之处在于,它不是像AdaBoost那样在每个迭代中调整实例权重,而是让新的预测器针对前一个预测器的残差进行拟合
使用Scikit-learn的GradientBoostingRegressor类训练GBRT集成。与RandomForestRegressor类似,它具有控制决策树生长的超参数(例如max_depth、min_samples_leaf等),以及控制集成训练的超参数,如树的数量(n_estimators)

超参数learning_rate对每棵树的贡献进行缩放。若将其设置为低值,例如0.1,则需要更多的树来拟合训练集,但预测的泛化效果通常更好。这是一种被称为收缩的正则化技术。
要找到树的最佳数量,可以使用早期停止法。设置warm_start=True,当fit()方法被调用时,Scikit-learn会保留现有的树,从而允许增量训练。以下代码会在验证误差连续5次迭代未改善时,直接停止训练:
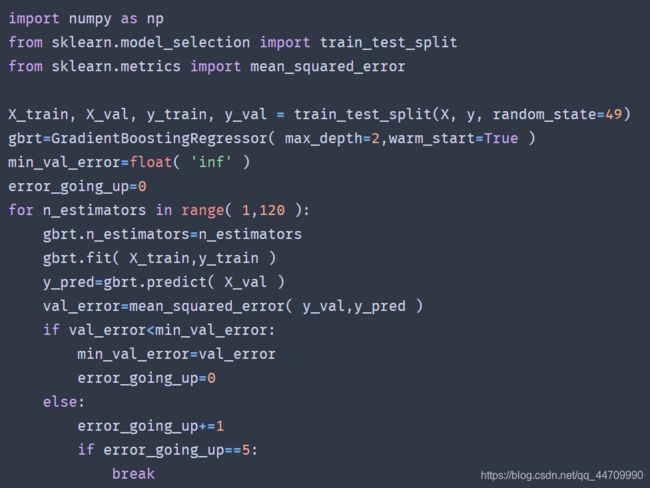
GradientBoostingRegressor类还可支持超参数subsample,指定用于训练每棵树的实例的比例。例如,若subsample=0.25,则每棵树用25%的随机选择的实例进行训练。这种技术称为随机梯度提升
堆叠法
堆叠法(stacking),又称层叠泛化法。它基于一个简单的想法:与其使用一些简单的函数(比如硬投票)来聚合集成中所有预测器的预测,为什么不训练一个模型来执行这个聚合呢?
最终的预测器称为混合器或元学习器,训练混合器的常用方法是使用留存集。首先,将训练集分为两个子集,第一个子集用来训练第一层的预测器,然后,用第一层的预测器在第二个(留存)子集上进行预测。可以使用这些预测值作为输入特征,创建一个新的训练集,并保留目标值。在这个新的训练集上训练混合器,让它学习根据第一层的预测来预测目标值
8.降维
维度的诅咒
训练集的维度越高,过拟合的风险就越大
数据降维的主要方法
投影
流形学习
简单地说,2D流形就是一个能够在更高维空间里面弯曲和扭转的2D形状。d维流形就是n(d 许多降维算法是通过对训练实例进行流形建模来实现的,这被称为流形学习。它依赖于流形假设,也称为流形假说,认为大多数现实世界的高维度数据集存在一个低维度的流形来重新表示。这个假设通常是凭经验观察的。 简而言之,在训练模型之前降低训练集的维度,肯定可以加快训练速度,但这并不总是会导致更好或更简单的解决方案,它取决于数据集 PCA先识别出最接近数据的超平面,然后将数据投影其上 主成分分析(PCA)可以在训练集中识别出哪条轴对差异性的贡献度最高。 Scikit-learn的PCA类使用SVD分解来实现主成分分析。以下代码应用PCA将数据集的维度降到二维(它会自动处理数据集中): 每个主成分的方差解释率可以通过变量explained_variance_ratio_获得。它表示每个主成分轴对整个数据集的方差的贡献度。 可以将n_components设置为0.0到1.0之间的浮点数,表示希望保留的方差比: 以下代码将MNIST数据集压缩到154维,然后使用inverse_transform()方法将其解压缩回784维: 增量主成分分析(IPCA)算法:可以将训练集分成一个个小批量,一次给IPCA算法喂一个。 随机PCA是一个随机算法,可以快速找到前d个主成分的近似值 核主成分分析(kPCA)可使复杂的非线性投影降维成为可能。 下面的代码创建了一个两步流水线,首先使用kPCA将维度降至二维,然后应用逻辑回归进行分类。接下来使用GridSearchCV为kPCA找到最佳的核和gamma值,从而在流水线最后获得最准确的分类: 局部线性嵌入(LLE)是另一种非常强大的非线性降维技术。它是一种流形学习技术。简单来说,LLE首先测量每个算法如何与其最近的邻居线性相关,然后为训练集寻找一个能最大程度保留这些局部关系的低维表示。这使得它特别擅长展开弯曲的流形,特别是没有太多噪声时。 PCA
保留差异性
主成分
低维度投影
使用Scikit-Learn
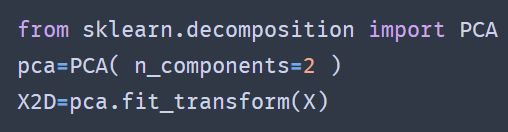
将PCA转换器应用到数据集之后,可以通过变量components_来访问主成分(它包含的主成分是水平向量,因此举例来说,第一个主成分即等于pca.components_.T[:,0])方差解释率

选择正确数量的维度

PCA压缩

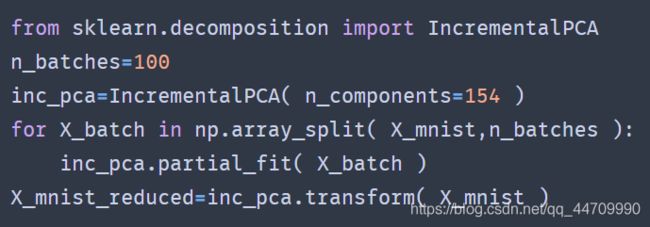
增量PCA
以下代码将MNIST数据集分成100个小批量(使用Numpy的array_split()函数),将它们提供给Scikit-learn的IncrementalPCA,将数据集降到154维。注意,必须为每个小批量调用partial_fit()方法,而不是之前整个训练集的fit()方法:
或者,可以使用Numpy的memmap类,它允许你操控一个存储在磁盘二进制文件里的大型数组,就好似它也完全在内存里一样,而这个类(memmap)仅在需要时加载内存中需要的数据。由于IncrementalPCA在任何时间都只使用数组的一小部分,因此内存的使用情况仍然受控,这时可以调用fit()方法

随机PCA

核主成分分析
下面的代码使用Scikit-learn的KernelPCA,执行带有RBF核函数的kPCA:

选择核函数和调整超参数
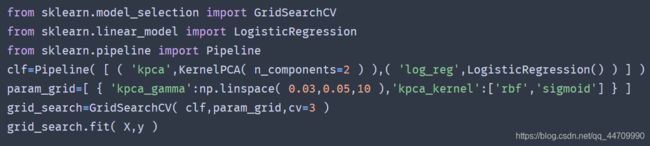
最佳的核和超参数可以通过变量best_params_获得:

还有一种完全不受监督方法,就是选择重建误差最低的核和超参数。我们可以在原始空间中找到一个点,使其映射接近于重建点。这被称为重建原像。一旦有了这个原像,你就可以测量它到原始实例的平方距离。最后,便可选择使这个重建原像误差最小化的核和超参数
要怎么执行这个重建呢?方法之一是训练一个监督式回归模型,以投影后的实例作为训练集,并以原始实例作为目标。若设置fit_inverse_transform=True,Scikit-learn会自动执行该操作:

默认情况下为fit_inverse_transform=False,且KernelPCA没有inverse_transform()方法。只有在设置fit_inverse_transform=True时才会创建该方法
然后就可计算重建原像误差:
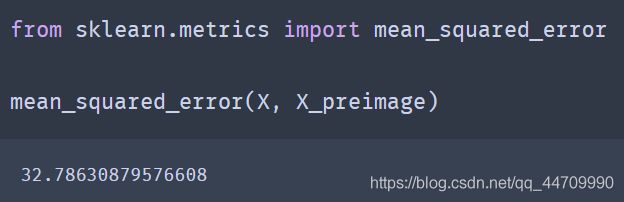
现在,可以使用交叉验证的网格搜索,来寻找使这个原像重建误差最小的核和超参数局部线性嵌入

其他降维技巧