CS224N学习笔记(十五)Natural Language Generation
1.Recap: LMs and decoding algorithms
课程首先回顾了前面讲的语言模型和相关decode算法。
Natural Language Generation (NLG)
NLG是NLP的一大类任务类型,给定一些条件生成一些文本,NLG包括:
- Machine Translation
- (Abstractive) Summarization
- Dialogue (chit-chat and task-based)
- Creative writing: storytelling, poetry-generation
- Freeform Question Answering
- Image captioning
而语言模型Language Modeling是给出一些条件,计算概率,预测下一个单词,公式如图所示:
![]()
课程接下来回顾了如何train RNN LM以及greedy search和beam searc 算法。
Sampling-based decoding
另外两种搜索算法:
- Pure sampling:纯粹的根据概率分布 p t p_t pt随机选取下个单词
- Top-n sampling:从概率最高的n个单词中,随机选取下个单词,n=1,is greedy search, n=V,is pure sampling,增大n提高搜索的多样性,减小n会使搜索更加严格。
Softmax temperature
这种方法就是改变计算概率分布时的softmax公式,将公式改为:

- 提高参数 τ \tau τ:计算后得到的概率分布更加均匀,相当于提高了选词的多样性
- 减小参数 τ \tau τ:计算的概率分布更加尖锐,让选词的概率主要集中在几个最高概率的词中间
softmax temperature是一种调整概率分布的手段,不是decoding算法。
2.NLG tasks and neural approaches to them
课程介绍了一些常见NLG任务以及相关的问题和解决方式。
Summarization
Summarization就是总结文本,给一段文本 x x x,输出文本 y y y, y y y更短且包含 x x x的主要信息。
Summarization分为Single-document和Multi-document,区别在于是从单个文本还是多个文本总结信息。
下面是常用的数据集:
- Gigaword: 新闻文章的前一两句 —> 标题(即句子压缩)
- LCSTS (中文微博):段落 —>句子摘要
- NYT, CNN/DailyMail: 新闻文章 —> (多个)句子摘要
- Wikihow (new!): 完整的 how-to 文章 —> 摘要句子
Sentence simplification是另外一个相关的任务,将源文本改写为更简单(有时是更短)的版本。
他的常用数据集有:
- Simple Wikipedia:标准维基百科句子 —> 简单版本
- Newsela:新闻文章 —>] 为儿童写的版本
Summarization任务有两种主要的策略:Extractive summarization和Abstractive summarization
- Extractive summarization:主要是提取合并源文本的相关信息,比较有限制性,但是比较简单。
- Abstractive summarization:生成相关的文本,相比于上面的比较灵活,但是比较难。
有人把Extractive summarization比作标记笔,把Abstractive summarization手写笔。

Pre-neural summarization
在深度学习之前的 summarization基本上都是extractive,包含三个部分:
- Content selection: choose some sentences to include
- Information ordering: choose an ordering of those sentences
- Sentence realization: edit the sequence of sentences (e.g. simplify, remove parts, fix continuity issues)
算法如图所示:

Content selection算法有主要的两种: - Sentence scoring functions:通过主题关键词或者特征计算句子的得分
- Graph-based algorithms:将文本认为是视为包含一系列节点(句子)的图,的权重与句子相似度成正比,使用图算法识别图中关键句子
Summarization evaluation: ROUGE
Summarization 任务的主要的评价指标是ROUGE,类似于 BLEU,是基于 n-gram 覆盖的算法,不同之处在于:
- ROUGE没有 BLEU对较段项进行惩罚
- ROUGE基于recall而BLEU基于precision,通常precision对于MT比较重要,recall对于Summarization 比较重要,因为需要抓住重要的信息。
ROUGE的公式如图所示:
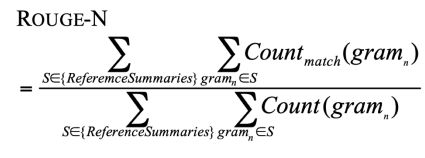
通常也将recall和precision结合起来采用F1分进行评估。
BLUE是从n=1,2,3,4,n-gram开始依次计算,但是ROUGE就是单独计算n=1到L,如图所示:

Neural summarization
从seq2seq开始,就可以将神经网络用于summarization,如图是使用seq2seq + attention NMT methods进行的总结得到的attention的可视化图表:

课程总结了在近几年的summarization的主要进展:
- 使其更容易复制,也防止太多的复制
- 分层/多层次的注意力机制
- 更多的全局/高级 的内容选择
- 使用 RL 直接最大化 ROUGE 或者其他离散目标(例如长度)
- 复兴 pre-neural 想法(例如图算法的内容选择),把它们变成神经系统
copy mechanisms
eq2seq+attention systems 善于生成流畅的输出,但是不擅长正确的复制细节(如罕见字)。因此,要对注意力机制进行改进,加入复制机制,使seq2seq系统很容易从输入复制单词和短语到输出。课程介绍了一篇论文的结构如图所示:
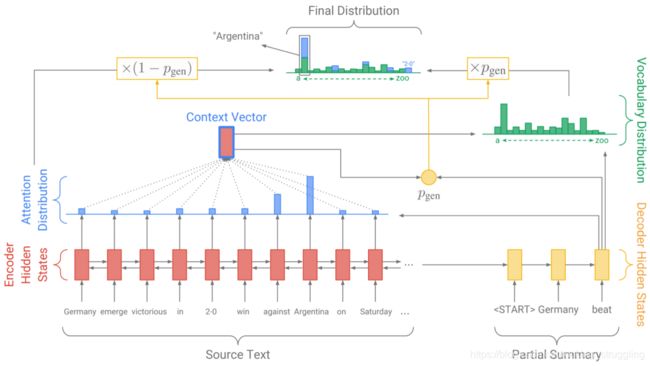
整体的思想就是在使用attention计算完成概率分布后,再去计算一个vocab的概率分布,之后将两者叠加去得到一个整体的分布,之后再去预测得到单词。主要公式如图所示:

引入copy机制又会经常出现一些问题:
- copy too much:把长短语,甚至整个句子都copy下来了。个原本应该是抽象的摘要系统,会崩溃为一个主要是抽取的系统。
- copy机制不善于整体内容的选择,特别是如果输入文档很长的情况下。
Neural summarization: better content selection
可以借鉴pre-neural的方法,实施两步,内容选择与表面实现算法,而标准seq2seq + attention 的摘要系统,这两个阶段是混合在一起的,相当于把它拆开。
课程介绍了一篇论文,采用了Bottom-up summarization方法,分为两步:
- Content selection stage:在前面的内容选择阶段,采用序列神经网络模型,把文本中的词标记为 include or don’t-include。
- Bottom-up attention stage:采用seq2seq+attention模型,但是模型排除掉don’t-include的词汇(相当于加了mask)。
原理结构如图所示:

这种方法可以有效进行整个的content的选取,而防止copy太多长句子。
Neural summarization via Reinforcement Learning
将深度强化学习应用于summarization mode,去直接优化 ROUGE-L的评价指标。与之相比,maximum likelihood (ML)并不能优化ROUGE-L,因为他们并不是一类函数。
课程介绍的论文在优化时发现,直接通过强化学习可以增加ROUGE scores,但是会减小human
judgment scores,而通过结合强化学习与神经网络的训练则可以达到很好的效果,如图所示:

Dialogue
Dialogue主要分两种:
- Task-oriented dialogue:有目标的对话,包括协助,合作,对抗等。
- Social dialogue:闲聊型的对话或者治愈型的对话
在深度学习普及之前 由于NLG的难度比较大,dialogue的产生经常使用预训练好的模板,或者直接从语料库中搜索得到对应的回答。seq2seq模型使dialogue重新恢复生机。
Seq2seq-based dialogue
简单的seq2seq模型在Dialogue上有很多的缺点,主要包括:
- 一般性/无聊的反应
- 无关的反应(与上下文不够相关)
- 重复
- 缺乏上下文(不记得谈话历史)
- 缺乏一致的角色人格
课程依次分析了上述问题。
Irrelevant response problem
首先:seq2seq经常产生与用户无关的话语,主要原因有两个:
- 问题的回答是通用的(比如:我不知道)
- 回答将话题改变成了一些不相关的
解决方法,去寻找输入输出之间的共性,先办法去保证这些特性在整个过程中不改变,或者说删除改变了这些特性的输出。提出了优化了输入S和输出T最大相关性信息Maximum Mutual Information (MMI),从而抑制模型去选择那些本来就很大概率的通用句子。公式如图:
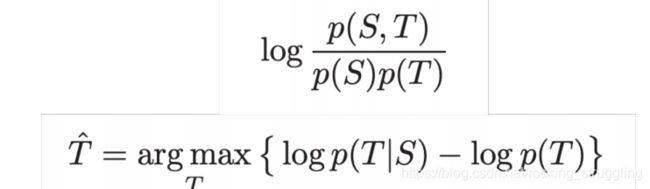
Genericness / boring response problem
简单的解决方法:
- 直接在Beam搜索中增大罕见字的概率(防止一直搜到通用性答案)
- 使用sampling 搜索方法而不是,beam search
复杂的解决方法:
- 控制它deocoer想办法加入一些另外的内容
- 训练一个retrieve-and-refine 模型而不是 generate-from-scratch 模型,就是说从预料库中挑一下相近的回答去优化,
repetition problem
简单的解决方法:
- 直接在beam search中禁止搜索和前面出现的重复的语句(非常有限)
复杂的解决方法:
- 训练一个coverage mechanism,可以防止注意力机制多次注意相同的单词
- 在训练目标中加入防止重复的单元
Storytelling
顾名思义,就是讲一个故事:
- 根据图片生成一个故事
- 根据简单的写作提示生成一个故事
- 根据故事的上一段给出下一段(故事续写)
深度学习也使这方面取得了很好的效果
Generating a story from an image
如图根据图片生成了一首类似与taylor swfit歌词类似的歌,如图所示:

这里没有采用监督图像标题,因为没有大量并行的数据。
如何解决缺乏并行数据的问题:采用一个通用的sentence 编码空间。
- 采用Skip-thought 向量这种通用的句子嵌入方法,类似于我们如何学通过预测周围的文字来学习单词的嵌入。
- 使用 COCO (图片标题数据集),学习从图像到其标题的 Skip-thought 编码的映射。
- 训练一个目标语料库(Taylor Swift lyrics),训练出一个RNN-LM可以将Skip-thought解码成raw text
- 然后通过中间的Skip-thought将两者结合到一起
Generating a story from a writing prompt
collected from Reddit’s WritingPrompts subreddit.数据集,一个故事前面有一个简短的写作提示:
如图:
相关细节见ppt

3.NLG evaluation
在NLG自动的评价机制大多是基于word overlap (BLEU, ROUGE, METEOR, F1, etc.)
对于machine translation这些评价指标并不好,对于 summarization和dialogue就更差,主要原因是这些任务的答案都比较的开放,如图可以看出,这些评价指标和人类的评价并没有线性关系。
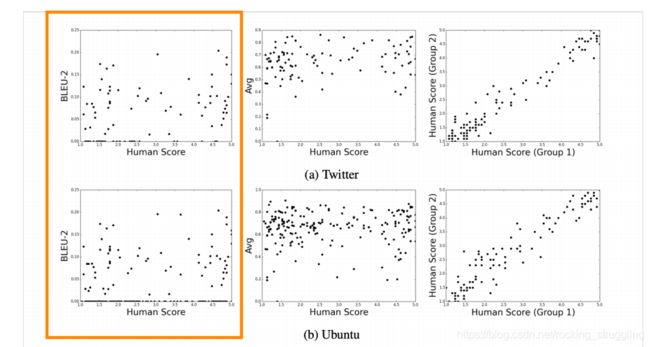
其他的一些评价指标:
- perplexity,捕捉你的LM有多强大,但是不会告诉你关于生成的任何事情(例如,如果你的perplexity是未改变的,解码算法是不好的)
- Word embedding based metrics:通过比较词嵌入的相似性来进行文本的评价,但是无法和人类的判断相关联,因为还是太开放了。
所以总结一下,很难有哪种评价机制去自动的对整体的水平进行评价,应该将其拆分成多个单个评价方法:
- 流利性(使用训练好的LM计算概率)
- 正确的风格(使用目标语料库上训练好的LM的概率
- 多样性(罕见的用词,n-grams 的独特性)
- 相关输入(语义相似性度量)
- 简单的长度和重复
- 特定于任务的指标,如摘要的压缩率
Human evaluation
人手工的评价通常被认为是黄金标准,但是人的评价通常是非常缓慢而且昂贵,还有别的很多问题,比如:
- 是不一致的
- 可能是不合逻辑的
- 失去注意力
- 误解了你的问题
- 不能总是解释为什么他们会这样做
课程根据项目经验,建立了一些人工评价的完整的体系,从具体细致到总结概括型等等,如图所示:
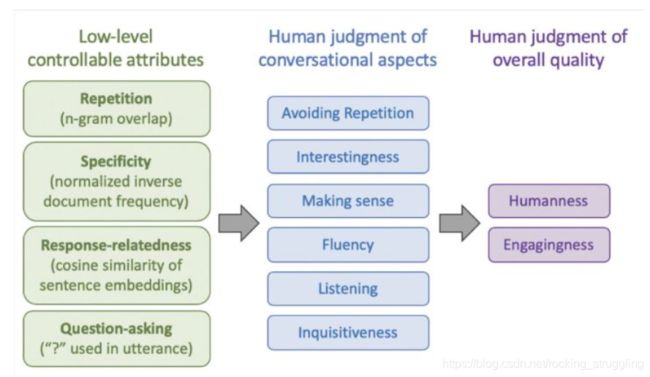
具体的细节见课程ppt。
4.NLG的趋势和展望
Exciting current trends in NLG
- 将离散潜在变量纳入NLG,可以帮助在真正需要它的任务中建模结构,例如讲故事,任务导向对话等
- 严格的从左到右生成的替代方案,并行生成,迭代细化,自上而下生成较长的文本
- 替代teacher forcing的最大可能性培训,更全面的句子级别的目标函数(而不是单词级别)
课程也给出了个人的一项想法:
- 任务越开放,一切就越困难
约束有时是受欢迎的 - 针对特定改进的目标比旨在提高整体生成质量更易于管理
- 如果你使用一个LM作为NLG:改进LM(即困惑)最有可能提高生成质量
但这并不是提高生成质量的唯一途径 - 多看看你的输出
- 你需要一个自动度量,即使它是不受影响的
您可能需要几个自动度量 - 如果你做了人工评估,让问题尽可能的集中
- 在今天的NLP + 深度学习和 NLG中,再现性是一个巨大的问题。
请公开发布所有生成的输出以及您的论文 - 在NLG工作可能很令人沮丧,但也很有趣