Spring微服务实战第6章 使用Spring Cloud和Zuul进行服务路由
第6章 使用Spring Cloud和Zuul进行服务路由
本章主要内容
- 结合微服务使用服务网关
- 使用Spring Cloud和Netflix Zuul实现服务网关
- 在Zuul中映射微服务路由
- 构建过滤器以使用关联ID并进行跟踪
- 使用Zuul进行动态路由
在像微服务架构这样的分布式架构中,需要确保跨多个服务调用的关键行为的正常运行,如安全、日志记录和用户跟踪。要实现此功能,开发人员需要在所有服务中始终如一地强制这些特性,而不需要每个开发团队都构建自己的解决方案。虽然可以使用公共库或框架来帮助在单个服务中直接构建这些功能,但这样做会造成3个影响。
第一,在构建的每个服务中很难始终实现这些功能。开发人员专注于交付功能,在每日的快速开发工作中,他们很容易忘记实现服务日志记录或跟踪。遗憾的是,对那些在金融服务或医疗保健等严格监管的行业工作的人来说,一致且有文档记录系统中的行为通常是符合政府法规的关键要求。
第二,正确地实现这些功能是一个挑战。对每个正在开发的服务进行诸如微服务安全的建立与配置可能是很痛苦的。将实现横切关注点(cross-cutting concern,如安全问题)的责任推给各个开发团队,大大增加了开发人员没有正确实现或忘记实现这些功能的可能性。
第三,这会在所有服务中创建一个顽固的依赖。开发人员在所有服务中共享的公共框架中构建的功能越多,在通用代码中无需重新编译和重新部署所有服务就能更改或添加功能就越困难。当应用程序中有6个微服务时,这似乎不是什么大问题,但当这个应用程序拥有更多的服务时(大概30个或更多),这就是一个很大的问题。突然间,共享库中内置的核心功能的升级就变成了一个数月的迁移过程。
为了解决这个问题,需要将这些横切关注点抽象成一个独立且作为应用程序中所有微服务调用的过滤器和路由器的服务。这种横切关注点被称为服务网关(service gatervay)。服务客户端不再直接调用服务。取而代之的是,服务网关作为单个策略执行点(Policy Enforcement Point,PEP),所有调用都通过服务网关进行路由,然后被路由到最终目的地。
在本章中,我们将看看如何使用Spring Cloud和Netflix的Zuul来实现一个服务网关。Zuul是Netflix的开源服务网关实现。具体来说,我们来看一下如何使用Spring Cloud和Zuul来完成以下操作。
- 将所有服务调用放在一个URL后面,并使用服务发现将这些调用映射到实际的服务实例。
- 将关联ID注入流经服务网关的每个服务调用中。
- 在从客户端发回的HTTP响应中注入关联ID。
- 构建一个动态路由机制,将各个具体的组织路由到服务实例端点,该端点与其他人使用的服务实例端点不同。
让我们深入了解服务网关是如何与本书中构建的整体微服务相适应的。
6.1 什么是服务网关
到目前为止,通过前面几章中构建的微服务,我们可以通过Web客户端直接调用各个服务,也可以通过诸如Eureka这样的服务发现引擎以编程方式调用它们。图6-1展示了没有服务网关的后果。

图6-1 如果没有服务网关,服务客户端将为每个服务调用不同的端点
服务网关充当服务客户端和被调用的服务之间的中介。服务客户端仅与服务网关管理的单个URL进行对话。服务网关从服务客户端调用中分离出路径,并确定服务客户端正在尝试调用哪个服务。图6-2演示了服务网关如何像交通警察一样指挥交通,将用户引导到目标微服务和相应的实例。服务网关充当应用程序内所有微服务调用的入站流量的守门人。有了服务网关,服务客户端永远不会直接调用单个服务的URL,而是将所有调用都放到服务网关上。

图6-2 服务网关位于服务客户端和相应的服务实例之间。所有服务调用(内部和外部)都应流经服务网关
由于服务网关位于客户端到各个服务的所有调用之间,因此它还充当服务调用的中央策略执行点(PEP)。使用集中式PEP意味着横切服务关注点可以在一个地方实现,而无须各个开发团队来实现这些关注点。举例来说,可以在服务网关中实现的横切关注点包括以下几个。
- 静态路由——服务网关将所有的服务调用放置在单个URL和API路由的后面。这简化了开发,因为开发人员只需要知道所有服务的一个服务端点就可以了。
- 动态路由——服务网关可以检查传入的服务请求,根据来自传入请求的数据和服务调用者的身份执行智能路由。例如,可能会将参与测试版程序的客户的所有调用路由到特定服务集群的服务,这些服务运行的是不同版本的代码,而不是其他人使用的非测试版程序的代码。
- 验证和授权——由于所有服务调用都经过服务网关进行路由,所以服务网关是检查服务调用者是否已经进行了验证并被授权进行服务调用的自然场所。
- 度量数据收集和日志记录——当服务调用通过服务网关时,可以使用服务网关来收集数据和日志信息,还可以使用服务网关确保在用户请求上提供关键信息以确保日志统一。这并不意味着不应该从单个服务中收集度量数据,而是通过服务网关可以集中收集许多基本度量数据,如服务调用次数和服务响应时间。
等等——难道服务网关不是单点故障和潜在瓶颈吗?
在第4章中介绍Eureka时,我讨论了集中式负载均衡器是如何成为单点故障和服务瓶颈的。如果没有正确地实现,服务网关会承受同样的风险。在构建服务网关实现时,要牢记以下几点。
在单独的服务组前面,负载均衡器仍然很有用。在这种情况下,将负载均衡器放到多个服务网关实例前面的是一个恰当的设计,它确保服务网关实现可以伸缩。将负载均衡器置于所有服务实例的前面并不是一个好主意,因为它会成为瓶颈。
要保持为服务网关编写的代码是无状态的。不要在内存中为服务网关存储任何信息。如果不小心,就有可能限制网关的可伸缩性,导致不得不确保数据在所有服务网关实例中被复制。
要保持为服务网关编写的代码是轻量的。服务网关是服务调用的“阻塞点”,具有多个数据库调用的复杂代码可能是服务网关中难以追踪的性能问题的根源。
我们现在来看看如何使用Spring Cloud和Netflix Zuul来实现服务网关。
6.2 Spring Cloud和Netflix Zuul简介
Spring Cloud集成了Netflix开源项目Zuul。Zuul是一个服务网关,它非常容易通过Spring Cloud注解进行创建和使用。Zuul提供了许多功能,具体包括以下几个。
- 将应用程序中的所有服务的路由映射到一个URL——Zuul不局限于一个URL。在Zuul中,开发人员可以定义多个路由条目,使路由映射非常细粒度(每个服务端点都有自己的路由映射)。然而,Zuul最常见的用例是构建一个单一的入口点,所有服务客户端调用都将经过这个入口点。
- 构建可以对通过网关的请求进行检查和操作的过滤器——这些过滤器允许开发人员在代码中注入策略执行点,以一致的方式对所有服务调用执行大量操作。
要开始使用Zuul,需要完成下面3件事。
(1)建立一个Zuul Spring Boot项目,并配置适当的Maven依赖项。
(2)使用Spring Cloud注解修改这个Spring Boot项目,将其声明为Zuul服务。
(3)配置Zuul以便Eureka进行通信(可选)。
6.2.1 建立一个Zuul Spring Boot项目
如果读者在本书中按顺序读了前几章,应该会对接下来要做的工作很熟悉。要构建一个Zuul服务器,需要建立一个新的Spring Boot服务并定义相应的Maven依赖项。读者可以在本书的GitHub存储库中找到本章的项目源代码。幸运的是,在Maven中建立Zuul只需要很少的步骤,只需要在zuulsvr/pom.xml文件中定义一个依赖项:
org.springframework.cloud
spring-cloud-starter-zuul
这个依赖项告诉Spring Cloud框架,该服务将运行Zuul,并适当地初始化Zuul。
6.2.2 为Zuul服务使用Spring Cloud注解
在定义完Maven依赖项后,需要为Zuul服务的引导类添加注解。Zuul服务实现的引导类可以在zuulsvr/src/main/java/com/thoughtmechanix/zuulsvr/Application.java中找到。代码清单6-1展示了如何为Zuul服务的引导类添加注解。
代码清单6-1 创建Zuul服务器引导类
package com.thoughtmechanix.zuulsvr;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.zuul.EnableZuulProxy;
import org.springframework.context.annotation.Bean;
@SpringBootApplication
@EnableZuulProxy ⇽--- 使服务成为一个Zuul服务器
public class ZuulServerApplication {
public static void main(String[] args) {
SpringApplication.run(ZuulServerApplication.class, args);
}
}
就这样,这里只需要一个注解:@EnableZuulProxy。
注意
如果读者浏览过文档或启用了自动补全,那么可能会注意到一个名为
@EnableZuulServer的注解。使用此注解将创建一个Zuul服务器,它不会加载任何Zuul反向代理过滤器,也不会使用Netflix Eureka进行服务发现(我们将很快进入Zuul和Eureka集成的主题)。开发人员想要构建自己的路由服务,而不使用任何Zuul预置的功能时会使用@EnableZuulServer,举例来讲,当开发人员需要使用Zuul与Eureka之外的其他服务发现引擎(如Consul)进行集成的时候。本书只会使用@EnableZuulProxy注解。
6.2.3 配置Zuul与Eureka进行通信
Zuul代理服务器默认设计为在Spring产品上工作。因此,Zuul将自动使用Eureka来通过服务ID查找服务,然后使用Netflix Ribbon对来自Zuul的请求进行客户端负载均衡。
注意
我经常不按顺序阅读书中的章节,而是会跳到我最感兴趣的主题上。如果读者也这么做,并且不知道Netflix Eureka和Ribbon是什么,那么,我建议读者先阅读第4章,然后再进行下一步。Zuul大量采用这些技术进行工作,因此了解Eureka和Ribbon带来的服务发现功能会更容易理解Zuul。
配置过程的最后一步是修改Zuul服务器的zuulsvr/src/main/resources/application.yml文件,以指向Eureka服务器。代码清单6-2展示了Zuul与Eureka通信所需的Zuul配置。代码清单6-2中的配置应该看起来很熟悉,因为它与第4章中介绍的配置相同。
代码清单6-2 配置Zuul服务器与Eureka通信
eureka:
instance:
preferIpAddress: true
client:
registerWithEureka: true
fetchRegistry: true
serviceUrl:
defaultZone: http://localhost:8761/eureka/
6.3 在Zuul中配置路由
Zuul的核心是一个反向代理。反向代理是一个中间服务器,它位于尝试访问资源的客户端和资源本身之间。客户端甚至不知道它正与代理之外的服务器进行通信。反向代理负责捕获客户端的请求,然后代表客户端调用远程资源。
在微服务架构的情况下,Zuul(反向代理)从客户端接收微服务调用并将其转发给下游服务。服务客户端认为它只与Zuul通信。Zuul要与下游服务进行沟通,Zuul必须知道如何将进来的调用映射到下游路由。Zuul有几种机制来做到这一点,包括:
- 通过服务发现自动映射路由;
- 使用服务发现手动映射路由;
- 使用静态URL手动映射路由。
6.3.1 通过服务发现自动映射路由
Zuul的所有路由映射都是通过在zuulsvr/src/main/resources/application.yml文件中定义路由来完成的。但是,Zuul可以根据其服务ID自动路由请求,而不需要配置。如果没有指定任何路由,Zuul将自动使用正在调用的服务的Eureka服务ID,并将其映射到下游服务实例。例如,如果要调用organizationservice并通过Zuul使用自动路由,则可以使用以下URL作为端点,让客户端调用Zuul服务实例:
http://localhost:5555/organizationservice/v1/organizations/e254f8c-c442-4ebe-
➥ a82a-e2fc1d1ff78a
Zuul服务器可通过http://localhost:5555进行访问。该服务中的端点路径的第一部分表示正在尝试调用的服务(organizationservice)。
图6-3阐明了该映射的实际操作。
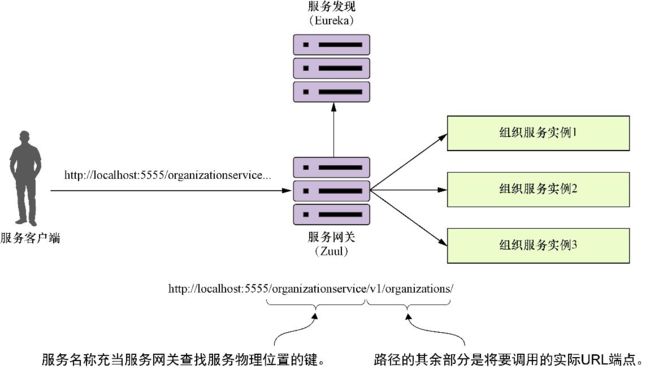
图6-3 Zuul将使用organizationservice应用程序名称来将请求映射到组织服务实例
使用带有Eureka的Zuul的优点在于,开发人员不仅可以拥有一个可以发出调用的单个端点,有了Eureka,开发人员还可以添加和删除服务的实例,而无须修改Zuul。例如,可以向Eureka添加新服务,Zuul将自动路由到该服务,因为Zuul会与Eureka进行通信,了解实际服务端点的位置。
如果要查看由Zuul服务器管理的路由,可以通过Zuul服务器上的/routes端点来访问这些路由,这将返回服务中所有映射的列表。图6-4展示了访问http://localhost:5555/routes的输出结果。
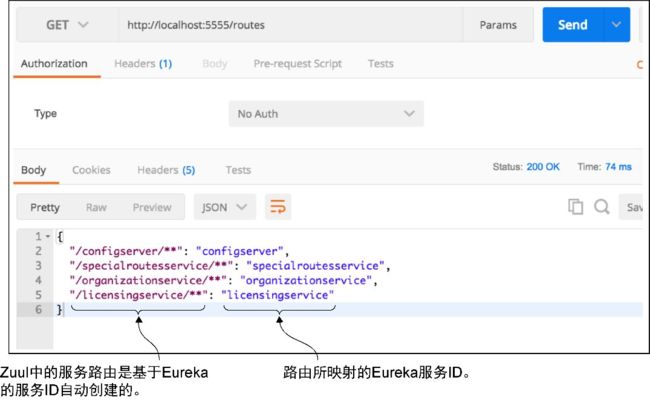
图6-4 在Eureka中映射的每个服务现在都将被映射为Zuul路由
在图6-4中,通过zuul注册的服务的映射展示在从/route调用返回的JSON体的左边,路由映射到的实际Eureka服务ID展示在其右边。
6.3.2 使用服务发现手动映射路由
Zuul允许开发人员更细粒度地明确定义路由映射,而不是单纯依赖服务的Eureka服务ID创建的自动路由。假设开发人员希望通过缩短组织名称来简化路由,而不是通过默认路由/organizationservice/v1/organizations/{organization-id}在Zuul中访问组织服务。
开发人员可以通过在zuulsvr/src/main/resources/application.yml中手动定义路由映射来做到这一点。
zuul:
routes:
organizationservice: /organization/**
通过添加上述配置,现在我们就可以通过访问/organization/v1/organizations/ {organization-id}路由来访问组织服务了。如果再次检查Zuul服务器的端点,读者应该会看到图6-5所示的结果。
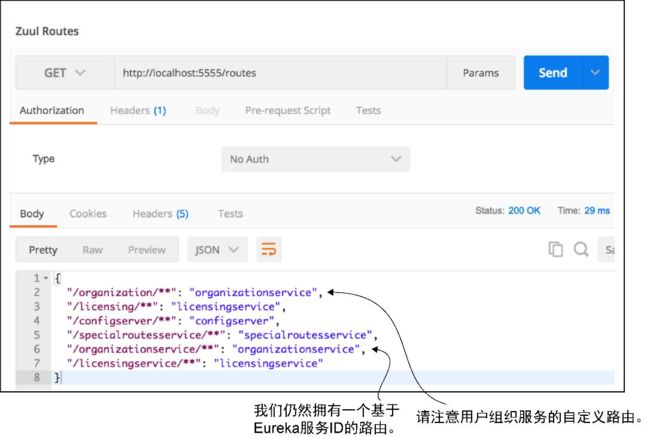
图6-5 将组织服务进行手动映射后Zuul /routes的调用结果
如果仔细查看图6-5,读者会注意到有两个条目代表组织服务。第一个服务条目是在application.yml文件中定义的映射"organization/**": "organizationservice"。第二个服务条目是由Zuul根据组织服务的Eureka ID创建的自动映射"/organizationservice/**":"organizationservice"。
注意
在使用自动路由映射时,Zuul只基于Eureka服务ID来公开服务,如果服务的实例没有在运行,Zuul将不会公开该服务的路由。然而,如果在没有使用Eureka注册服务实例的情况下,手动将路由映射到服务发现ID,那么Zuul仍然会显示这条路由。如果尝试为不存在的服务调用路由,Zuul将返回500错误。
如果想要排除Eureka服务ID路由的自动映射,只提供自定义的组织服务路由,可以向application.yml文件添加一个额外的Zuul参数ignored-services。
以下代码片段展示了如何使用ignored-services属性从Zuul完成的自动映射中排除Eureka服务ID organizationservice。
zuul:
ignored-services: 'organizationservice'
routes:
organizationservice: /organization/**
ignored-services属性允许开发人员定义想要从注册中排除的Eureka服务ID的列表,该列表以逗号进行分隔。现在,在调用/routes端点时,应该只能看到自定义的组织服务映射。图6-6展示了此映射的结果。
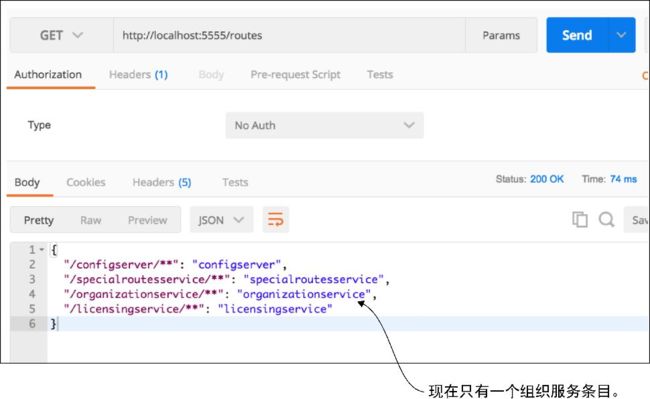
图6-6 Zuul中现在只定义了一个组织服务
如果要排除所有基于Eureka的路由,可以将ignored-services属性设置为“*”。
服务网关的一种常见模式是通过使用/api之类的标记来为所有的服务调用添加前缀,从而区分API路由与内容路由。Zuul通过在Zuul配置中使用prefix属性来支持这项功能。图6-7在概念上勾画了这种映射前缀的样子。
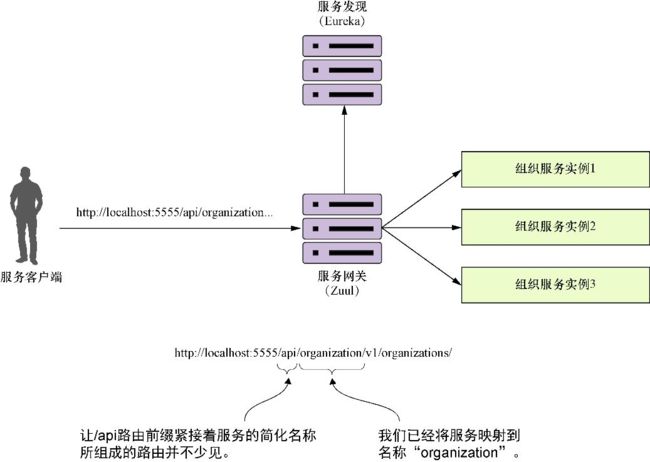
图6-7 通过使用前缀,Zuul会将/api前缀映射到它管理的每个服务
在代码清单6-3中,我们将看到如何分别为组织服务和许可证服务建立特定的路由,排除所有Eureka生成的服务,并使用/api前缀为服务添加前缀。
代码清单6-3 使用前缀建立自定义路由
zuul:
ignored-services: '*' ⇽--- ignored-services被设置为*,以排除所有基于Eureka服务ID的路由的注册
prefix: /api ⇽--- 所有已定义的服务都将添加前缀/api
routes:
organizationservice: /organization/** ⇽--- organizationservice和licensingservice分别映射到organization和licensing
licensingservice: /licensing/**
完成此配置并重新加载Zuul服务后,访问/routes端点时应该会看到以下两个条目:/api/organization和/api/licensing。图6-8展示了这些路由条目。
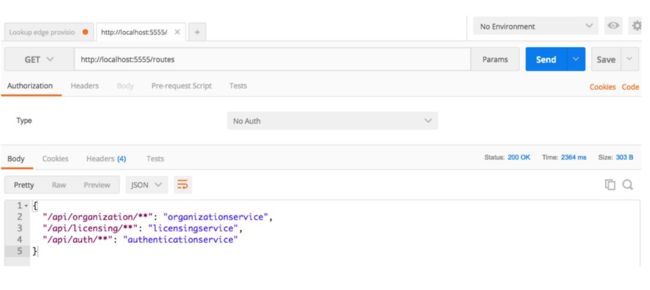
图6-8 Zuul中的路由现在添加了/api前缀
现在让我们来看看如何使用Zuul来映射到静态URL。静态URL是指向未通过Eureka服务发现引擎注册的服务的URL。
6.3.3 使用静态URL手动映射路由
Zuul可以用来路由那些不受Eureka管理的服务。在这种情况下,可以建立Zuul直接路由到一个静态定义的URL。例如,假设许可证服务是用Python编写的,并且仍然希望通过Zuul进行代理,那么可以使用代码清单6-4中的Zuul配置来达到此目的。
代码清单6-4 将许可证服务映射到静态路由
zuul:
routes:
licensestatic: ⇽--- Zuul用于在内部识别服务的关键字
path: /licensestatic/** ⇽--- 许可证服务的静态路由
url: http://licenseservice-static:8081 ⇽--- 已建立许可证服务的静态实例,它将被直接调用,而不是由Zuul通过Eureka调用
完成这一配置更改后,就可以访问/routes端点来看添加到Zuul的静态路由。图6-9展示了/routes端点的结果。
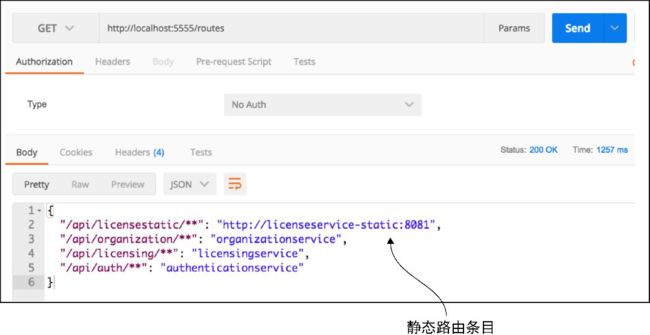
图6-9 现在已经将静态路由映射到许可证服务
现在,licensestatic端点不再使用Eureka,而是直接将请求路由到http:// licenseservice-static:8081端点。这里存在一个问题,那就是通过绕过Eureka,只有一条路径可以用来指向请求。幸运的是,开发人员可以手动配置Zuul来禁用Ribbon与Eureka集成,然后列出Ribbon将进行负载均衡的各个服务实例。代码清单6-5展示了这一点。
代码清单6-5 将许可证服务静态映射到多个路由
zuul:
routes:
licensestatic:
path: /licensestatic/**
serviceId: licensestatic ⇽--- 定义一个服务ID,该服务ID将用于在Ribbon中查找服务
ribbon:
eureka:
enabled: false ⇽--- 在Ribbon中禁用Eureka支持
licensestatic:
ribbon:
listOfServers: http://licenseservice-static1:8081,
http://licenseservice-static2:8082 ⇽--- 指定请求会路由到的服务器列表
配置完成后,调用/routes端点现在将显示/api/licensestatic路由已被映射到名为licensestatic的服务ID。图6-10展示了这一点。

图6-10 /api/licensestatic现在映射到名为licensestatic的服务ID
处理非JVM服务
静态映射路由并在Ribbon中禁用Eureka支持会造成一个问题,那就是禁用了对通过Zuul服务网关运行的所有服务的Ribbon支持。这意味着Eureka服务器将承受更多的负载,因为Zuul无法使用Ribbon来缓存服务的查找。记住,Ribbon不会在每次发出调用的时候都调用Eureka。相反,它将在本地缓存服务实例的位置,然后定期检查Eureka是否有变化。缺少了Ribbon,Zuul每次需要解析服务的位置时都会调用Eureka。
在本章早些时候,我们讨论了如何使用多个服务网关,根据所调用的服务类型来执行不同的路由规则和策略。对于非JVM应用程序,可以建立单独的Zuul服务器来处理这些路由。然而,我发现对于非基于JVM的语言,最好是建立一个Spring Cloud “Sidecar”实例。Spring Cloud Sidecar允许开发人员使用Eureka实例注册非JVM服务,然后通过Zuul进行代理。我没有在本书中介绍Spring Sidecar,因为本书不会让读者编写任何非JVM服务,但是建立一个Sidecar实例是非常容易的。读者可以在Spring Cloud网站上找到相关指导。
6.3.4 动态重新加载路由配置
接下来我们要在Zuul中配置路由来看看如何动态重新加载路由。动态重新加载路由的功能非常有用,因为它允许在不回收Zuul服务器的情况下更改路由的映射。现有的路由可以被快速修改,以及添加新的路由,都无需在环境中回收每个Zuul服务器。在第3章中,我们介绍了如何使用Spring Cloud配置服务来外部化微服务配置数据。读者可以使用Spring Cloud Config来外部化Zuul路由。在EagleEye示例中,我们可以在configrepo(http://github.com/carnellj/config-repo)中创建一个名为zuulservice的新应用程序文件夹。就像组织服务和许可证服务一样,我们将创建3个文件(即zuulservice.yml、zuulservice-dev.yml和zuulservice-prod.yml),它们将保存路由配置。
为了与第3章配置中的示例保持一致,我已经将路由格式从层次化格式更改为“.”格式。初始的路由配置将包含一个条目:
zuul.prefix=/api
如果访问/routes端点,应该会看到在Zuul中显示的所有基于Eureka的服务,并带有/api的前缀。现在,如果想要动态地添加新的路由映射,只需对配置文件进行更改,然后将配置文件提交回Spring Cloud Config从中提取配置数据的Git存储库。例如,如果想要禁用所有基于Eureka的服务注册,并且只公开两个路由(一个用于组织服务,另一个用于许可证服务),则可以修改zuulservice-*.yml文件,如下所示:
zuul.ignored-services: '*'
zuul.prefix: /api
zuul.routes.organizationservice: /organization/**
zuul.routes.organizationservice: /licensing/**
接下来,将更改提交给GitHub。Zuul公开了基于POST的端点路由/refresh,其作用是让Zuul重新加载路由配置。在访问完refresh端点之后,如果访问/routes端点,就会看到两条新的路由,所有基于Eureka的路由都不见了。
6.3.5 Zuul和服务超时
Zuul使用Netflix的Hystrix和Ribbon库,来帮助防止长时间运行的服务调用影响服务网关的性能。在默认情况下,对于任何需要用超过1 s的时间(这是Hystrix默认值)来处理请求的调用,Zuul将终止并返回一个HTTP 500错误。幸运的是,开发人员可以通过在Zuul服务器的配置中设置Hystrix超时属性来配置此行为。
开发人员可以使用hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds属性来为所有通过Zuul运行的服务设置Hystrix超时。例如,如果要将默认的Hystrix超时设置为2.5 s,就可以在Zuul的Spring Cloud配置文件中使用以下配置:
zuul.prefix: /api
zuul.routes.organizationservice: /organization/**
zuul.routes.licensingservice: /licensing/**
zuul.debug.request: true
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds: 2500
如果需要为特定服务设置Hystrix超时,可以使用需要覆盖超时的服务的Eureka服务ID名称来替换属性的default部分。例如,如果想要将licensingservice的超时更改为3 s,并让其他服务使用默认的Hystrix超时,可以在配置中添加与下面类似的内容:
hystrix.command.licensingservice.execution.isolation.thread.timeoutInMilliseconds:
➥ 3000
最后,读者需要知晓另外一个超时属性。虽然已经覆盖了Hystrix的超时,Netflix Ribbon同样会超时任何超过5 s的调用。尽管我强烈建议读者重新审视调用时间超过5 s的调用的设计,但读者可以通过设置属性servicename.ribbon.ReadTimeout来覆盖Ribbon超时。例如,如果想要覆盖licensingservice超时时间为7 s,可以使用以下配置:
hystrix.command.licensingservice.execution.
➥ isolation.thread.timeoutInMilliseconds: 7000
licensingservice.ribbon.ReadTimeout: 7000
注意
对于超过5 s的配置,必须同时设置Hystrix和Ribbon超时。
6.4 Zuul的真正威力:过滤器
虽然通过Zuul网关代理所有请求确实可以简化服务调用,但是在想要编写应用于所有流经网关的服务调用的自定义逻辑时, Zuul的真正威力才发挥出来。在大多数情况下,这种自定义逻辑用于强制执行一组一致的应用程序策略,如安全性、日志记录和对所有服务的跟踪。
这些应用程序策略被认为是横切关注点,因为开发人员希望将它们应用于应用程序中的所有服务,而无需修改每个服务来实现它们。通过这种方式,Zuul过滤器可以按照与J2EE servlet过滤器或Spring Aspect类似的方式来使用。这种方式可以拦截大量行为,并且在原始编码人员意识不到变化的情况下,对调用的行为进行装饰或更改。servlet过滤器或Spring Aspect被本地化为特定的服务,而使用Zuul和Zuul过滤器允许开发人员为通过Zuul路由的所有服务实现横切关注点。
Zuul允许开发人员使用Zuul网关内的过滤器构建自定义逻辑。过滤器可用于实现每个服务请求在执行时都会经过的业务逻辑链。
Zuul支持以下3种类型的过滤器。
- 前置过滤器——前置过滤器在Zuul将实际请求发送到目的地之前被调用。前置过滤器通常执行确保服务具有一致的消息格式(例如,关键的HTTP首部是否设置妥当)的任务,或者充当看门人,确保调用该服务的用户已通过验证(他们的身份与他们声称的一致)和授权(他们可以做他们请求做的)。
- 后置过滤器——后置过滤器在目标服务被调用并将响应发送回客户端后被调用。通常后置过滤器会用来记录从目标服务返回的响应、处理错误或审核对敏感信息的响应。
- 路由过滤器——路由过滤器用于在调用目标服务之前拦截调用。通常使用路由过滤器来确定是否需要进行某些级别的动态路由。例如,本章的后面将使用路由级别的过滤器,该过滤器将在同一服务的两个不同版本之间进行路由,以便将一小部分的服务调用路由到服务的新版本,而不是路由到现有的服务。这样就能够在不让每个人都使用新服务的情况下,让少量的用户体验新功能。
图6-11展示了在处理服务客户端请求时,前置过滤器、后置过滤器和路由过滤器如何组合在一起。
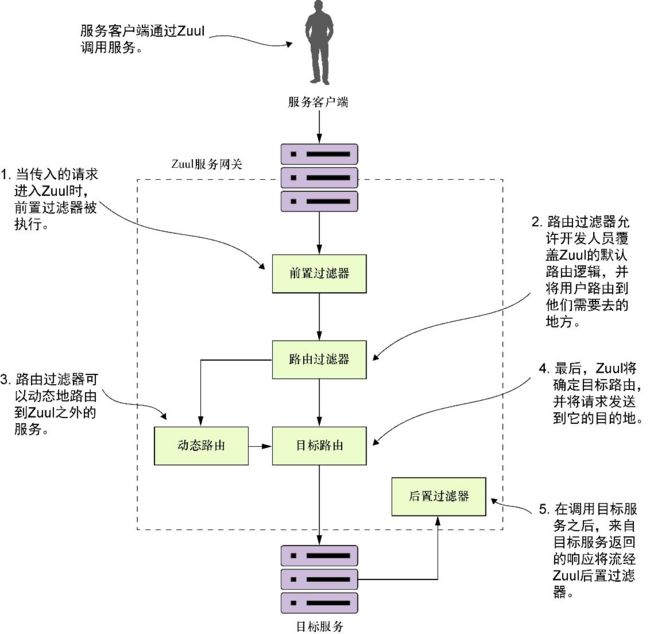
图6-11 前置过滤器、路由过滤器和后置过滤器组成了客户端请求流经的管道。随着请求进入Zuul,这些过滤器可以处理传入的请求
如果遵循图6-11中所列出的流程,将会看到所有的事情都是从服务客户端调用服务网关公开的服务开始的。从这里开始,发生了以下活动。
(1)在请求进入Zuul网关时,Zuul调用所有在Zuul网关中定义的前置过滤器。前置过滤器可以在HTTP请求到达实际服务之前对HTTP请求进行检查和修改。前置过滤器不能将用户重定向到不同的端点或服务。
(2)在针对Zuul的传入请求执行前置过滤器之后,Zuul将执行已定义的路由过滤器。路由过滤器可以更改服务所指向的目的地。
(3)路由过滤器可以将服务调用重定向到Zuul服务器被配置的发送路由以外的位置。但Zuul路由过滤器不会执行HTTP重定向,而是会终止传入的HTTP请求,然后代表原始调用者调用路由。这意味着路由过滤器必须完全负责动态路由的调用,并且不能执行HTTP重定向。
(4)如果路由过滤器没有动态地将调用者重定向到新路由,Zuul服务器将发送到最初的目标服务的路由。
(5)目标服务被调用后,Zuul后置过滤器将被调用。后置过滤器可以检查和修改来自被调用服务的响应。
了解如何实现Zuul过滤器的最佳方法就是使用它们。为此,在接下来的几节中,我们将构建前置过滤器、路由过滤器和后置过滤器,然后通过它们运行服务客户端请求。
图6-12展示了如何将这些过滤器组合在一起以处理对EagleEye服务的请求。

图6-12 Zuul过滤器提供对服务调用、日志记录和动态路由的集中跟踪。Zuul过滤器允许开发人员针对微服务调用执行自定义规则和策略
按照图6-12所示的流程,读者会看到以下过滤器被使用。
(1)TrackingFilter——TrackingFilter是一个前置过滤器,它确保从Zuul流出的每个请求都具有相关的关联ID。关联ID是在执行客户请求时执行的所有微服务中都会携带的唯一ID。关联ID用于跟踪一个调用经过一系列微服务调用发生的事件链。
(2)SpecialRoutesFilter——SpecialRoutesFilter是一个Zuul路由过滤器,它将检查传入的路由,并确定是否要在该路由上进行A/B测试。A/B测试是一种技术,在这种技术中,用户(在这种情况下是服务)随机使用同一个服务提供的两种不同的服务版本。A/B测试背后的理念是,新功能可以在推出到整个用户群之前进行测试。在我们的例子中,同一个组织服务将具有两个不同的版本。少数用户将被路由到较新版本的服务,与此同时,大多数用户将被路由到较旧版本的服务。
(3)ResponseFilter——ResponseFilter是一个后置过滤器,它将把与服务调用相关的关联ID注入发送回客户端的HTTP响应首部中。这样,客户端就可以访问与其发出的请求相关联的关联ID。
6.5 构建第一个生成关联ID的Zuul前置过滤器
在Zuul中构建过滤器是非常简单的。我们首先将构建一个名为TrackingFilter的Zuul前置过滤器,该过滤器将检查所有到网关的传入请求,并确定请求中是否存在名为tmx-correlation-id的HTTP首部。tmx-correlation-id首部将包含一个唯一的全局通用ID(Globally Universal ID,GUID),它可用于跨多个微服务来跟踪用户请求。
注意
我们在第5章中讨论了关联ID的概念。在这里我们将更详细地介绍如何使用Zuul来生成一个关联ID。如果读者跳过了此内容,我强烈建议读者查看第5章并阅读5.9节的内容。关联ID的实现将使用
ThreadLocal变量实现,而要让ThreadLocal变量与Hystrix一起使用需要做额外的工作。
如果在HTTP首部中不存在tmx-correlation-id,那么Zuul TrackingFilter将生成并设置该关联ID。如果已经存在关联ID,那么Zuul将不会对该关联ID进行任何操作。关联ID的存在意味着该特定服务调用是执行用户请求的服务调用链的一部分。在这种情况下,TrackingFilter类将不执行任何操作。
我们来看看代码清单6-6中的TrackingFilter的实现。这段代码也可以在本书示例的zuulsvr/src/main/java/com/thoughtmechanix/zuulsvr/filters/TrackingFilter.java中找到。
代码清单6-6 用于生成关联ID的Zuul前置过滤器
package com.thoughtmechanix.zuulsvr.filters;
import com.netflix.zuul.ZuulFilter;
import org.springframework.beans.factory.annotation.Autowired;
// 为了简洁,省略了其他import语句
@Component
public class TrackingFilter extends ZuulFilter{ ⇽--- 所有Zuul过滤器必须扩展ZuulFilter类,并覆盖4个方法,即filterType()、filterOrder()、shouldFilter()和run()
private static final int FILTER_ORDER = 1;
private static final boolean SHOULD_FILTER=true;
private static final Logger logger =
➥ LoggerFactory.getLogger(TrackingFilter.class);
@Autowired
FilterUtils filterUtils; ⇽--- 在所有过滤器中使用的常用方法都封装在FilterUtils类中
@Override
public String filterType() { ⇽--- filterType()方法用于告诉Zuul,该过滤器是前置过滤器、路由过滤器还是后置过滤器
return FilterUtils.PRE_FILTER_TYPE;
}
@Override
public int filterOrder() { ⇽--- filterOrder()方法返回一个整数值,指示不同类型的过滤器的执行顺序
return FILTER_ORDER;
}
public boolean shouldFilter() { ⇽--- shouldFilter()方法返回一个布尔值来指示该过滤器是否要执行
return SHOULD_FILTER;
}
private boolean isCorrelationIdPresent(){ ⇽--- shouldFilter()方法返回一个布尔值来指示该过滤器是否要执行
if (filterUtils.getCorrelationId() !=null){
return true;
}
return false;
}
private String generateCorrelationId(){ ⇽--- 该辅助方法实际上检查tmx- correlation-id是否存在,并且可以生成关联ID的GUID值
return java.util.UUID.randomUUID().toString();
}
public Object run() { ⇽--- run()方法是每次服务通过过滤器时执行的代码。run()方法检查tmx-correlation-id是否存在,如果不存在,则生成一个关联值,并设置HTTP首部tmx-correlation-id
if (isCorrelationIdPresent()) {
logger.debug("tmx-correlation-id found in tracking filter: {}.",
➥ filterUtils.getCorrelationId());
}
else{
filterUtils.setCorrelationId(generateCorrelationId());
logger.debug("tmx-correlation-id generated in tracking filter: {}.",
➥ filterUtils.getCorrelationId());
}
RequestContext ctx = RequestContext.getCurrentContext();
logger.debug("Processing incoming request for {}.",
➥ ctx.getRequest().getRequestURI());
return null;
}
}
要在Zuul中实现过滤器,必须扩展ZuulFilter类,然后覆盖4个方法,即filterType()、filterOrder()、shouldFilter()和run()方法。代码清单6-6中的前三个方法描述了Zuul正在构建什么类型的过滤器,与这个类型的其他过滤器相比它应该以什么顺序运行,以及它是否应该处于活跃状态。最后一个方法run()包含过滤器要实现的业务逻辑。
我们已经实现了一个名为FilterUtils的类。这个类用于封装所有过滤器使用的常用功能。FilterUtils类位于zuulsvr/src/main/java/com/thoughtmechanix/zuulsvr/ FilterUtils.java中。本书不会详细解释整个FilterUtils类,在这里讨论的关键方法是getCorrelationId()和setCorrelationId()。代码清单6-7展示了FilterUtils类的getCorrelationId()方法的代码。
代码清单6-7 从HTTP首部检索tmx-correlation-id
public String getCorrelationId(){
RequestContext ctx = RequestContext.getCurrentContext();
if (ctx.getRequest().getHeader(CORRELATION_ID) != null) {
return ctx.getRequest().getHeader(CORRELATION_ID);
}
else{
return ctx.getZuulRequestHeaders().get(CORRELATION_ID);
}
}
在代码清单6-7中要注意的关键点是,首先要检查是否已经在传入请求的HTTP首部设置了tmx-correlation-ID。这里使用ctx.getRequest().getHeader(CORRELATION_ID)调用来做到这一点。
注意
在一般的Spring MVC或
Spring Boot服务中,RequestContext是org.springframework.web.servletsupport.RequestContext类型的。然而,Zuul提供了一个专门的RequestContext,它具有几个额外的方法来访问Zuul特定的值。该请求上下文是com.netflix.zuul.context包的一部分。
如果tmx-correlation-ID不存在,接下来就检查ZuulRequestHeaders。Zuul不允许直接添加或修改传入请求中的HTTP请求首部。如果想要添加tmx-correlation-id,并且以后在过滤器中能够再次访问到它,实际上在ctx.getRequestHeader()调用的结果中并不会包含它。为了解决这个问题,可以使用FilterUtils的getCorrelationId()方法。读者可能还记得,在TrackingFilter类的run()方法中,我们使用了以下代码片段:
else{
filterUtils.setCorrelationId(generateCorrelationId());
logger.debug("tmx-correlation-id generated in tracking filter: {}.",
➥ filterUtils.getCorrelationId());
}
tmx-correlation-id的设置发生在FilterUtils的setCorrelationId()方法中:
public void setCorrelationId(String correlationId){
RequestContext ctx = RequestContext.getCurrentContext();
ctx.addZuulRequestHeader(CORRELATION_ID, correlationId);
}
在FilterUtils的setCorrelationId()方法中,要向HTTP请求首部添加值时,应使用RequestContext的addZuulRequestHeader()方法。该方法将维护一个单独的HTTP首部映射,这个映射是在请求通过Zuul服务器流经这些过滤器时添加的。当Zuul服务器调用目标服务时,包含在ZuulRequestHeader映射中的数据将被合并。
在服务调用中使用关联ID
既然已经确保每个流经Zuul的微服务调用都添加了关联ID,那么如何确保:
- 正在被调用的微服务可以很容易访问关联ID;
- 下游服务调用微服务时可能也会将关联ID传播到下游调用中。
要实现这一点,需要为每个微服务构建一组3个类。这些类将协同工作,从传入的HTTP请求中读取关联ID(以及稍后添加的其他信息),并将它映射到可以由应用程序中的业务逻辑轻松访问和使用的类,然后确保关联ID被传播到任何下游服务调用。
图6-13展示了如何使用许可证服务来构建这些不同的部分。
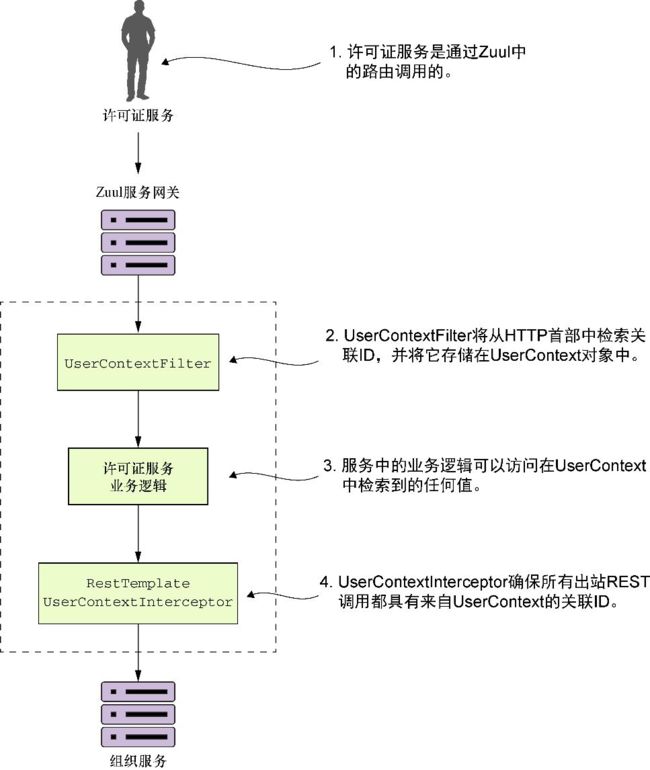
图6-13 使用一组公共类,以便将关联ID传播到下游服务调用
我们来看一下图6-13中发生了什么。
(1)当通过Zuul网关对许可证服务进行调用时,TrackingFilter会为所有进入Zuul的调用在传入的HTTP首部中注入一个关联ID。
(2)UserContextFilter类是一个自定义的HTTP servlet过滤器。它将关联ID映射到UserContext类。UserContext存储在本地线程存储中,以便稍后在调用中使用。
(3)许可证服务业务逻辑需要执行对组织服务的调用。
(4)RestTemplate用于调用组织服务。RestTemplate将使用自定义的Spring拦截器类(UserContextInterceptor)将关联ID作为HTTP首部注入出站调用。
重复代码与共享库对比
是否应该在微服务中使用公共库的话题是微服务设计中的一个灰色地带。微服务纯粹主义者会告诉你,不应该在服务中使用自定义框架,因为它会在服务中引入人为的依赖。业务逻辑的更改或bug修正可能会对所有服务造成大规模的重构。但是,其他微服务实践者会指出,纯粹主义者的方法是不切实际的,因为会存在这样一些情况(如前面的
UserContextFilter例子),在这些情况下构建公共库并在服务之间共享它是有意义的。我认为这里存在一个中间地带。在处理基础设施风格的任务时,是很适合使用公共库的。但是,如果开始共享面向业务的类,就是在自找麻烦,因为这样是在打破服务之间的界限。
在本章的代码示例中,我似乎违背了自己的建议,因为如果查看本章中的所有服务,读者就会发现它们都有自己的
UserContextFilter、UserContext和UserContextInterceptor类的副本。在这里我之所以采用无共享的方法,是因为我不希望通过创建一个必须发布到第三方Maven存储库的共享库来将代码示例复杂化。因此,该服务的utils包中的所有类都在所有服务之间共享。
1.UserContextFilter:拦截传入的HTTP请求
要构建的第一个类是UserContextFilter类。这个类是一个HTTP servlet过滤器,它将拦截进入服务的所有传入HTTP请求,并将关联ID(和其他一些值)从HTTP请求映射到UserContext类。代码清单6-8展示了UserContext类的代码。这个类的源代码可以在licensing-service/src/main/java/com/thoughtmechanix/licenses/utils/UserContextFilter.java中找到。
代码清单6-8 将关联ID映射到UserContext类
package com.thoughtmechanix.licenses.utils;
// 为了简洁,省略了import语句
@Component
public class UserContextFilter implements Filter { ⇽--- 这个过滤器是通过使用Spring的@Component注解和实现一个 javax.servler.Filter 接口来被Spring注册与获取的
private static final Logger logger =
➥ LoggerFactory.getLogger(UserContextFilter.class);
@Override
public void doFilter(ServletRequest servletRequest,
➥ ServletResponse servletResponse,
➥ FilterChain filterChain)
throws IOException, ServletException {
HttpServletRequest httpServletRequest = (HttpServletRequest)
➥ servletRequest;
UserContextHolder
.getContext()
.setCorrelationId(httpServletRequest ⇽--- 过滤器从首部中检索关联ID,并将值设置在UserContext类
.getHeader(UserContext.CORRELATION_ID));
UserContextHolder.getContext().setUserId(httpServletRequest
.getHeader(UserContext.USER_ID)); ⇽--- 如果使用在代码的README文件中定义的验证服务示例,那么从HTTP首部中获得的其他值将发挥作用
UserContextHolder
.getContext()
.setAuthToken(httpServletRequest.getHeader(UserContext.AUTH_TOKEN));
UserContextHolder
.getContext()
.setOrgId(httpServletRequest.getHeader(UserContext.ORG_ID));
filterChain.doFilter(httpServletRequest, servletResponse);
}
// 没有显示空的初始化方法和销毁方法
}
最终,UserContextFilter用于将我们感兴趣的HTTP首部的值映射到Java类UserContext中。
2.UserContext:使服务易于访问HTTP首部
UserContext类用于保存由微服务处理的单个服务客户端请求的HTTP首部值。它由getter和setter方法组成,用于从java.lang.ThreadLocal中检索和存储值。代码清单6-9展示了UserContext类中的代码。这个类的源代码可以在licensing-service/src/main/java/com/thoughtmechanix/-licenses/utils/UserContext.java中找到。
代码清单6-9 将HTTP首部值存储在UserContext类中
@Component
public class UserContext {
public static final String CORRELATION_ID = "tmx-correlation-id";
public static final String AUTH_TOKEN = "tmx-auth-token";
public static final String USER_ID = "tmx-user-id";
public static final String ORG_ID = "tmx-org-id";
private String correlationId= new String();
private String authToken= new String();
private String userId = new String();
private String orgId = new String();
public String getCorrelationId() { return correlationId;}
public void setCorrelationId(String correlationId) {
this.correlationId = correlationId;}
public String getAuthToken() { return authToken;}
public void setAuthToken(String authToken) { this.authToken = authToken;}
public String getUserId() { return userId;}
public void setUserId(String userId) { this.userId = userId;}
public String getOrgId() { return orgId;}
public void setOrgId(String orgId) {this.orgId = orgId;}
}
现在UserContext类只是一个POJO,它保存从传入的HTTP请求中获取的值。使用一个名为UserContextHolder的类(在zuulsvr/src/main/java/com/thoughtmechanix/zuulsvr/filters/ UserContextHolder.java中)将UserContext存储在ThreadLocal变量中,该变量可以在处理用户请求的线程调用的任何方法中访问。UserContextHolder的代码如代码清单6-10所示。
代码清单6-10 UserContextHolder类将UserContext存储在ThreadLocal中
public class UserContextHolder {
private static final ThreadLocal userContext =
➥ new ThreadLocal();
public static final UserContext getContext(){
UserContext context = userContext.get();
if (context == null) {
context = createEmptyContext();
userContext.set(context);
}
return userContext.get();
}
public static final void setContext(UserContext context) {
Assert.notNull(context,
➥ "Only non-null UserContext instances are permitted");
userContext.set(context);
}
public static final UserContext createEmptyContext(){
return new UserContext();
}
}
3.自定义RestTemplate和UserContextInteceptor:确保关联ID被传播
我们要看的最后一段代码是UserContextInterceptor类。这个类用于将关联ID注入基于HTTP的传出服务请求中,这些服务请求由RestTemplate实例执行。这样做是为了确保可以建立服务调用之间的联系。
要做到这一点,需要使用一个Spring拦截器,它将被注入RestTemplate类中。让我们看看代码清单6-11中的UserContextInterceptor。
代码清单6-11 所有传出的微服务调用都会注入关联ID
package com.thoughtmechanix.licenses.utils;
// 为了简洁,省略了import语句
public class UserContextInterceptor
implements ClientHttpRequestInterceptor { ⇽--- UserContextIntercept实现了Spring框架的ClientHttpRequestInterceptor
@Override
public ClientHttpResponse intercept( ⇽--- intercept()方法在RestTemplate发生实际的HTTP服务调用之前被调用
➥ HttpRequest request, byte[] body,
➥ ClientHttpRequestExecution execution)
➥ throws IOException {
HttpHeaders headers = request.getHeaders();
headers.add(
➥ UserContext.CORRELATION_ID,
➥ UserContextHolder
.getContext()
.getCorrelationId()); ⇽--- 为传出服务调用准备HTTP请求首部,并添加存储在UserContext中的关联ID
headers.add(
➥ UserContext.AUTH_TOKEN,
➥ UserContextHolder
.getContext()
.getAuthToken());
return execution.execute(request, body);
}
}
为了使用UserContextInterceptor,我们需要定义一个RestTemplate bean,然后将UserContextInterceptor添加进去。为此,我们需要将自己的RestTemplate bean定义添加到licensing-service/src/main/java/com/thoughtmechanix/licenses/Application.java中的Application类中。代码清单6-12展示了添加到这个类中的方法。
代码清单6-12 将UserContextInterceptor添加到RestTemplate类
@LoadBalanced ⇽--- @LoadBalanced注解表明这个RestTemplate将要使用Ribbon
@Bean
public RestTemplate getRestTemplate(){
RestTemplate template = new RestTemplate();
List interceptors = template.getInterceptors();
if (interceptors==null){ ⇽--- 将UserContextInterceptor添加到已创建的RestTemplate实例中
template.setInterceptors(
➥ Collections.singletonList(
➥ new UserContextInterceptor()));
}
else{
interceptors.add(new UserContextInterceptor());
template.setInterceptors(interceptors);
}
return template;
}
有了这个bean定义,每当使用@Autowired注解将RestTemplate注入一个类,就会使用代码清单6-12中创建的RestTemplate,它附带了UserContextInterceptor。
日志聚合和验证等
既然已经将关联ID传递给每个服务,那么就可以跟踪事务了,因为关联ID流经所有涉及调用的服务。要做到这一点,需要确保每个服务都记录到一个中央日志聚合点,该聚合点将从所有服务中捕获日志条目到一个点。在日志聚合服务中捕获的每个日志条目将具有与每个条目关联的关联ID。实施日志聚合解决方案超出了本章的讨论范围,在第9章中,我们将了解如何使用Spring Cloud Sleuth。Spring Cloud Sleuth不会使用本章构建的
TrackingFilter,但它将使用相同的概念——跟踪关联ID,并确保在每次调用中注入它。
6.6 构建接收关联ID的后置过滤器
记住,Zuul代表服务客户端执行实际的HTTP调用。Zuul有机会从目标服务调用中检查响应,然后修改响应或以额外的信息装饰它。当与以前置过滤器捕获数据相结合时,Zuul后置过滤器是收集指标并完成与用户事务相关联的日志记录的理想场所。我们将利用这一点,通过将已经传递给微服务的关联ID注入回用户。
我们将使用Zuul后置过滤器将关联ID注入HTTP响应首部中,该HTTP响应首部传回给服务调用者。这样,就可以将关联ID传回给调用者,而无需接触消息体。代码清单6-13展示了构建后置过滤器的代码。这段代码可以在zuulsvr/src/main/java/com/thoughtmechanix/zuulsvr/filters/ResponseFilter.java中找到。
代码清单6-13 将关联ID注入HTTP响应中
package com.thoughtmechanix.zuulsvr.filters;
// 为了简洁,省略了import语句
@Component
public class ResponseFilter extends ZuulFilter {
private static final int FILTER_ORDER = 1;
private static final boolean SHOULD_FILTER = true;
private static final Logger logger =
➥ LoggerFactory.getLogger(ResponseFilter.class);
@Autowired
FilterUtils filterUtils;
@Override
public String filterType() { ⇽--- 要构建一个后置过滤器,需要设置过滤器的类型为POST_FILTER_TYPE
return FilterUtils.POST_FILTER_TYPE;
}
@Override
public int filterOrder() {
return FILTER_ORDER;
}
@Override
public boolean shouldFilter() {
return SHOULD_FILTER;
}
@Override
public Object run() {
RequestContext ctx = RequestContext.getCurrentContext();
logger.debug("Adding the correlation id to the outbound headers. {}",
➥ filterUtils.getCorrelationId());
ctx.getResponse().addHeader( ⇽--- 获取原始HTTP请求中传入的关联ID,并将它注入响应中
➥ FilterUtils.CORRELATION_ID,
➥ filterUtils.getCorrelationId());
logger.debug("Completing outgoing request for {}.", ⇽--- 记录传出的请求URI,这样就有了“书挡”,它将显示进入Zuul的用户请求的传入和传出条目
➥ ctx.getRequest().getRequestURI());
return null;
}
}
实现完ResponseFilter之后,就可以启动Zuul服务,并通过它调用EagleEye许可证服务。服务完成后,就可以在调用的HTTP响应首部上看到一个tmx-correlation-id。图6-14展示了从调用中发回的tmx-correlation-id。
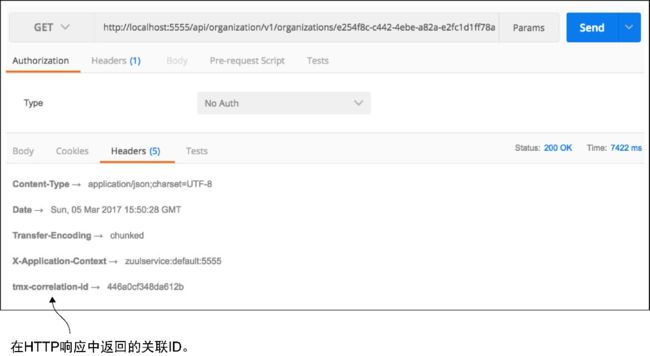
图6-14 tmx-correlation-id已被添加到发送回服务客户端的响应首部中
到目前为止,我们所有的过滤器示例都是在路由到目的地之前或之后对服务客户端调用进行操作。对于最后一个过滤器示例,让我们看看如何动态地更改用户要到达的目标路径。
6.7 构建动态路由过滤器
本章要介绍的最后一个Zuul过滤器是Zuul路由过滤器。如果没有自定义的路由过滤器,Zuul将根据本章前面的映射定义来完成所有路由。通过构建Zuul路由过滤器,可以为服务客户端的调用添加智能路由。
在本节中,我们将通过构建一个路由过滤器来学习Zuul的路由过滤器,从而允许对新版本的服务进行A/B测试。A/B测试是推出新功能的地方,在这里有一定比例的用户能够使用新功能,而其余的用户仍然使用旧服务。在本例中,我们将模拟出一个新的组织服务版本,并希望50%的用户使用旧服务,另外50%的用户使用新服务。
为此,需要构建一个名为SpecialRoutesFilter的路由过滤器。该过滤器将接收由Zuul调用的服务的Eureka服务ID,并调用另一个名为SpecialRoutes的微服务。SpecialRoutes服务将检查内部数据库以查看服务名称是否存在。如果目标服务名称存在,它将返回服务的权重以及替代位置的目的地。SpecialRoutesFilter将接收返回的权重,并根据权重随机生成一个值,用于确定用户的调用是否将被路由到替代组织服务或Zuul路由映射中定义的组织服务。图6-15展示了使用SpecialRoutesFilter时所发生的流程。
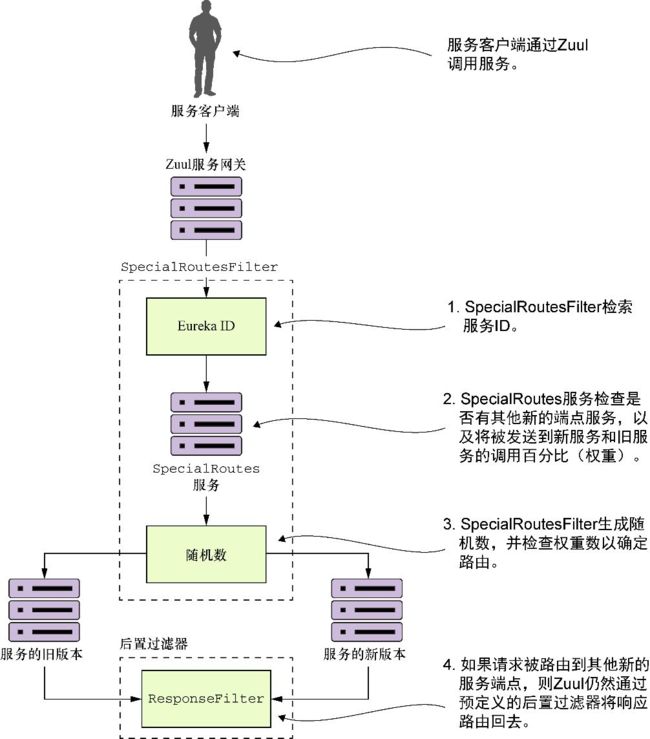
图6-15 通过SpecialRoutesFilter调用组织服务的流程
在图6-15中,在服务客户端调用Zuul背后的服务时,SpecialRoutesFilter会执行以下操作。
(1)SpecialRoutesFilter检索被调用服务的服务ID。
(2)SpecialRoutesFilter调用SpecialRoutes服务。SpecialRoutes服务将查询是否有针对目标端点定义的替代端点。如果找到一条记录,那么这条记录将包含一个权重,它将告诉Zuul应该发送到旧服务和新服务的服务调用的百分比。
(3)然后SpecialRoutesFilter生成一个随机数,并将它与SpecialRoutes服务返回的权重进行比较。如果随机生成的数字大于替代端点权重的值,那么SpecialRoutesFilter会将请求发送到服务的新版本。
(4)如果SpecialRoutesFilter将请求发送到服务的新版本,Zuul会维持最初的预定义管道,并通过已定义的后置过滤器将响应从替代服务端点发送回来。
6.7.1 构建路由过滤器的骨架
本节将介绍用于构建SpecialRoutesFilter的代码。在迄今为止所看到的所有过滤器中,实现Zuul路由过滤器所需进行的编码工作最多,因为通过路由过滤器,开发人员将接管Zuul功能的核心部分——路由,并使用自己的功能替换掉它。本节不会详细介绍整个类,而会讨论相关的细节。
SpecialRoutesFilter遵循与其他Zuul过滤器相同的基本模式。它扩展ZuulFilter类,并设置了filterType()方法来返回“route”的值。本节不会再进一步解释filterOrder()和shouldFilter()方法,因为它们与本章前面讨论过的过滤器没有任何区别。代码清单6-14展示了路由过滤器的骨架。
代码清单6-14 路由过滤器的骨架
package com.thoughtmechanix.zuulsvr.filters;
@Component
public class SpecialRoutesFilter extends ZuulFilter {
@Override
public String filterType() {
return filterUtils.ROUTE_FILTER_TYPE;
}
@Override
public int filterOrder() {}
@Override
public boolean shouldFilter() {}
@Override
public Object run() {}
}
6.7.2 实现run()方法
SpecialRoutesFilter的实际工作从代码的run()方法开始。代码清单6-15展示了此方法的代码。
代码清单6-15 SpecialRoutesFilter的run()方法是工作开始的地方
public Object run() {
RequestContext ctx = RequestContext.getCurrentContext();
AbTestingRoute abTestRoute =
➥ getAbRoutingInfo( filterUtils.getServiceId() ); ⇽--- 执行对SpecialRoutes服务的调用,以确定该服务ID是否有路由记录
if (abTestRoute!=null &&useSpecialRoute(abTestRoute)) { ⇽--- useSpecialRoute()方法将会接受路径的权重,生成一个随机数,并确定是否将请求转发到替代服务
String route = ⇽--- 如果有路由记录,则将完整的URL(包含路径)构建到由specialroutes服务指定的服务位置
➥ buildRouteString(
➥ ctx.getRequest().getRequestURI(),
➥ abTestRoute.getEndpoint(),
➥ ctx.get("serviceId").toString());
forwardToSpecialRoute(route); ⇽--- forwardToSpecialRoute()方法完成转发到其他服务的工作
}
return null;
}
代码清单6-15中代码的一般流程是,当路由请求触发SpecialRoutesFilter中的run()方法时,它将对SpecialRoutes服务执行REST调用。该服务将执行查找,并确定是否存在针对被调用的目标服务的Eureka服务ID的路由记录。对SpecialRoutes服务的调用是在getAbRoutingInfo()方法中完成的。getAbRoutingInfo()方法如代码清单6-16所示。
代码清单6-16 调用SpecialRouteservice以查看路由记录是否存在
private AbTestingRoute getAbRoutingInfo(String serviceName){
ResponseEntity restExchange = null;
try {
restExchange = restTemplate.exchange( ⇽--- 调用SpecialRoutesService端点
➥ "http://specialroutesservice/v1/route/abtesting/{serviceName}",
➥ HttpMethod.GET,null, AbTestingRoute.class, serviceName);
}
catch(HttpClientErrorException ex){ ⇽--- 如果路由服务没有找到记录(它将返回HTTP状态码404),该方法将返回空值
if (ex.getStatusCode() == HttpStatus.NOT_FOUND){
return null;
throw ex;
}
}
return restExchange.getBody();
}
一旦确定目标服务的路由记录存在,就需要确定是否应该将目标服务请求路由到替代服务位置,或者路由到由 Zuul 路由映射静态管理的默认服务位置。为了做出这个决定,需要调用useSpecialRoute()方法。代码清单6-17展示了这个方法。
代码清单6-17 决定是否使用替代服务路由
public boolean useSpecialRoute(AbTestingRoute testRoute){
Random random = new Random();
if (testRoute.getActive().equals("N")) ⇽--- 检查路由是否为活跃状态
return false;
int value = random.nextInt((10 - 1) + 1) + 1; ⇽--- 确定是否应该使用替代服务路由
if (testRoute.getWeight()这个方法做了两件事。首先,该方法检查从SpecialRoutes服务返回的AbTestingRoute记录中的active字段。如果该记录设置为"N",则useSpecialRoute()方法不应该执行任何操作,因为现在不希望进行任何路由。其次,该方法生成1到10之间的随机数。然后,该方法将检查返回路由的权重是否小于随机生成的数。如果条件为true,则useSpecialRoute()方法将返回true,表示确实希望使用该路由。
一旦确定要路由进入SpecialRoutesFilter的服务请求,就需要将请求转发到目标服务。
6.7.3 转发路由
SpecialRoutesFilter中出现的大部分工作是到下游服务的路由的实际转发。虽然Zuul确实提供了辅助方法来使这项任务更容易,但开发人员仍然需要负责大部分工作。forwardToSpecialRoute()方法负责转发工作。该方法中的代码大量借鉴了Spring Cloud的SimpleHostRoutingFilter类的源代码。虽然本章不会介绍forwardToSpecialRoute()方法中调用的所有辅助方法,但是会介绍该方法中的代码,如代码清单6-18所示。
代码清单6-18 forwardToSpecialRoute调用替代服务
private ProxyRequestHelper helper = ⇽--- helper变量是类ProxyRequestHelper类型的一个实例变量。这是Spring Cloud提供的类,带有用于代理服务请求的辅助方法
➥ new ProxyRequestHelper ();
private void forwardToSpecialRoute(String route) {
RequestContext context =
➥ RequestContext.getCurrentContext();
HttpServletRequest request = context.getRequest();
MultiValueMapheaders =
➥ helper.buildZuulRequestHeaders(request); ⇽--- 创建将发送到服务的所有HTTP请求首部的副本
MultiValueMap params =
➥ helper.buildZuulRequestQueryParams(request); ⇽--- 创建所有HTTP请求参数的副本
String verb = getVerb(request);
InputStream requestEntity = getRequestBody(request); ⇽--- 创建将被转发到替代服务的HTTP主体的副本
if (request.getContentLength() < 0)
context.setChunkedRequestBody();
this.helper.addIgnoredHeaders();
CloseableHttpClient httpClient = null;
HttpResponse response = null;s
try {
httpClient = HttpClients.createDefault();
response = forward( ⇽--- 使用forward()辅助方法(未显示)调用替代服务
➥ httpClient,
➥ verb,
➥ route,
➥ request,
➥ headers,
➥ params,
➥ requestEntity);
setResponse(response); ⇽--- 通过setResponse()辅助方法将服务调用的结果保存回Zuul服务器
}
catch (Exception ex ) {// 为了简洁,省略了其余的代码}
}
代码清单6-18中的关键要点是,我们将传入的HTTP请求(首部参数、HTTP动词和主体)中的所有值复制到将在目标服务上调用的新请求。然后forwardToSpecialRoute()方法从目标服务返回响应,并将响应设置在Zuul使用的HTTP请求上下文中。上述过程通过setResponse()辅助方法(未显示)完成。Zuul使用HTTP请求上下文从调用服务客户端返回响应。
6.7.4 整合
既然已经实现了SpecialRoutesFilter,我们就可以通过调用许可证服务来查看它的动作。读者可能还记得,在前面的几章中,许可证服务调用组织服务来检索组织的联系人数据。
在代码示例中,specialroutesservice具有用于组织服务的数据库记录,该数据库记录指示有50%的概率把对组织服务的请求路由到现有的组织服务(Zuul中映射的那个),50%的概率路由到替代组织服务。从SpecialRoutes服务返回的替代组织服务路径是http://orgservice-new,并且不能直接从Zuul访问。为了区分这两个服务,我修改了组织服务,将文本“OLD::”和“NEW::”添加到组织服务返回的联系人姓名的前面。
如果现在通过Zuul访问许可证服务端点,应该看到从许可证服务调用返回的contactName在OLD::和NEW::值之间变化。
http://localhost:5555/api/licensing/v1/organizations/e254f8c-c442-4ebe-a82a-
➥ e2fc1d1ff78a/licenses/f3831f8c-c338-4ebe-a82a-e2fc1d1ff78a
图6-16展示了这一点。
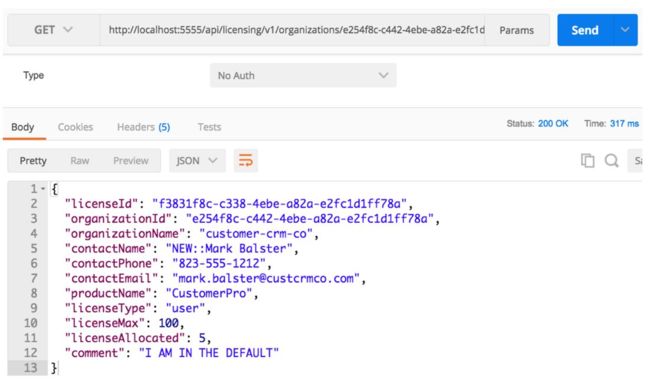
图6-16 当访问替代组织服务时,将会看到NEW被添加到contactName前面
实现Zuul路由过滤器确实比实现前置过滤器或后置过滤器需要更多的工作,但它也是Zuul最强大的部分之一,因为开发人员可以轻松地让服务路由方式变得智能。
6.8 小结
-
Spring Cloud使构建服务网关变得十分简单。
-
Zuul服务网关与Netflix的Eureka服务器集成,可以自动将通过Eureka注册的服务映射到Zuul路由。
-
Zuul可以对所有正在管理的路由添加前缀,因此可以轻松地给路由添加
/api之类的前缀。 -
可以使用Zuul手动定义路由映射。这些路由映射是在应用程序配置文件中手动定义的。
-
通过使用Spring Cloud Config服务器,可以动态地重新加载路由映射,而无须重新启动Zuul服务器。
-
可以在全局和个体服务水平上定制Zuul的Hystrix和Ribbon的超时。
-
Zuul允许通过Zuul过滤器实现自定义业务逻辑。Zuul有3种类型的过滤器,即前置过滤器、后置过滤器和路由过滤器。
-
Zuul前置过滤器可用于生成一个关联ID,该关联ID可以注入流经Zuul的每个服务中。
-
Zuul后置过滤器可以将关联ID注入服务客户端的每个HTTP服务响应中。
-
自定义Zuul路由过滤器可以根据Eureka服务ID执行动态路由,以便在同一服务的不同版本之间进行A/B测试。
,并且不能直接从Zuul访问。为了区分这两个服务,我修改了组织服务,将文本“OLD::”和“NEW::”添加到组织服务返回的联系人姓名的前面。
如果现在通过Zuul访问许可证服务端点,应该看到从许可证服务调用返回的contactName在OLD::和NEW::值之间变化。
http://localhost:5555/api/licensing/v1/organizations/e254f8c-c442-4ebe-a82a-
➥ e2fc1d1ff78a/licenses/f3831f8c-c338-4ebe-a82a-e2fc1d1ff78a
图6-16展示了这一点。
[外链图片转存中…(img-nSWNMRyQ-1631001378097)]
图6-16 当访问替代组织服务时,将会看到NEW被添加到contactName前面
实现Zuul路由过滤器确实比实现前置过滤器或后置过滤器需要更多的工作,但它也是Zuul最强大的部分之一,因为开发人员可以轻松地让服务路由方式变得智能。
6.8 小结
-
Spring Cloud使构建服务网关变得十分简单。
-
Zuul服务网关与Netflix的Eureka服务器集成,可以自动将通过Eureka注册的服务映射到Zuul路由。
-
Zuul可以对所有正在管理的路由添加前缀,因此可以轻松地给路由添加
/api之类的前缀。 -
可以使用Zuul手动定义路由映射。这些路由映射是在应用程序配置文件中手动定义的。
-
通过使用Spring Cloud Config服务器,可以动态地重新加载路由映射,而无须重新启动Zuul服务器。
-
可以在全局和个体服务水平上定制Zuul的Hystrix和Ribbon的超时。
-
Zuul允许通过Zuul过滤器实现自定义业务逻辑。Zuul有3种类型的过滤器,即前置过滤器、后置过滤器和路由过滤器。
-
Zuul前置过滤器可用于生成一个关联ID,该关联ID可以注入流经Zuul的每个服务中。
-
Zuul后置过滤器可以将关联ID注入服务客户端的每个HTTP服务响应中。
-
自定义Zuul路由过滤器可以根据Eureka服务ID执行动态路由,以便在同一服务的不同版本之间进行A/B测试。