C++之string
我等必将复起,古木已发新枝

文章目录
- 1.为什么C++要出string类?
- 2.标准库中的string类
- 3.编码问题
- ☀️4 string类的常用接口说明
-
- ⚡️4.1. string类对象的常见构造
- 4.2. string类对象的赋值
- 4.3. string类对象的修改操作
- 4.4. string类对象的容量操作
- 4.5 string类对象的访问及遍历操作
- 4.6. at和operator[]的区别
- 4.7 四种迭代器
- 5. 总结
1.为什么C++要出string类?
C++中我们要熟悉的第一个类就是string类,它是一个非常常用的类。
C++为什么要给出一个string类呢?
因为C语言有很多用字符串不方便的地方:
字符串是以’\0’结尾的一些字符的集合。为了操作方便,C标准库中提供了一些str系列的库函数,但是这些库函数与字符串是分离开的,不太符合OOP的思想,而且底层空间需要用户自己管理,稍不留神可能还会越界访问。
C++为了方便管理字符串就给出了string类。
2.标准库中的string类
string是表示字符序列的对象。
标准string类通过类似于标准字节容器的接口为此类对象提供支持,但添加了专门设计用于操作单字节字符串的特性。string类是basic_string类模板的一个实例化,它使用char(即bytes)作为其字符类型,其默认的char_traits和allocator类型(参见basic_string了解模板的更多信息)。注意,这类使用的独立处理字节编码:如果用于处理多字节序列或变长字符(比如utf- 8),这个类的所有成员(如长度或大小),以及它的迭代器,还是操作的字节(而不是实际的编码字符)。
要使用string就得包含string的头文件,且string定义在std这个命名空间内。定义一个string对象时有同学或多或少见过以下的代码:
#include有同学就要问了,不是说是string类吗,它又不是模板,为什么能这么玩?
ok,string表面上不是模板,实际上它是模板实例化来的,它是被typedef过的。

string是这个类模板实例化后类的其中之一,模板参数给的char:basic_string。
这个类模板实例化后其实有四种类:

3.编码问题
basic_string模板实例化后为什么有四种呢?这其实涉及到编码问题。
计算机里面只有0和1,为了能让计算机显示各个国家的文字,人们就设计了不同的编码表。常见的编码分为ASCII、Unicode(utf-8、utf-16、utf-32)、gbk等等。
这些编码表其实就是一种映射,映射再具体一点讲就是计算机底层存的值和显示值的映射表。
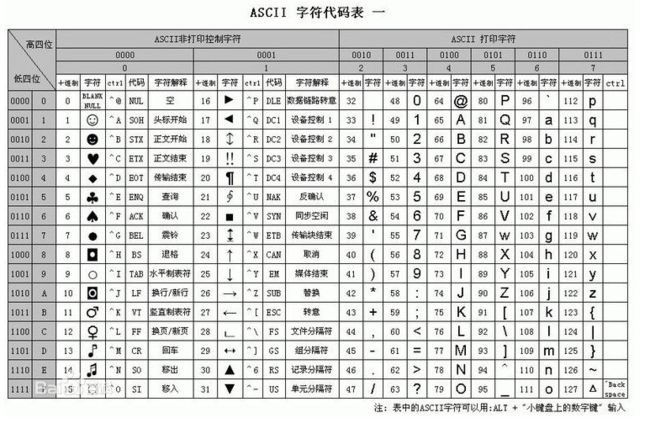
比如我们表示字母A:
int main()
{
char ch1 = 'A';
char ch2 = 65;
return 0;
}
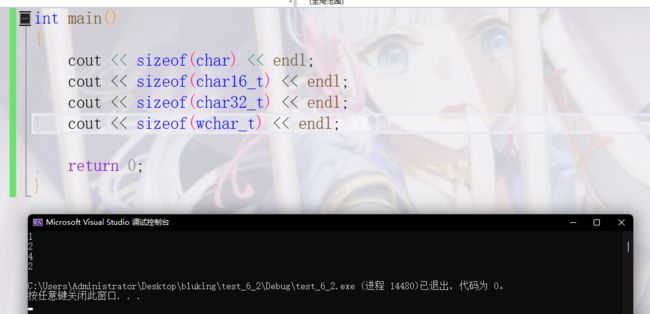
ch1、ch2这两个变量的大小都是一个字节,那这个一个字节在内存里面存的值是什么?
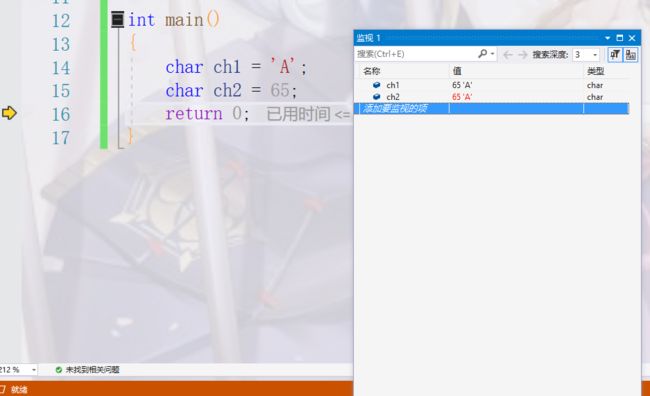
ok,存的是二进制的65,给A就去编码表找到对应的值存储起来。显示的时候也是通过用65去查这个编码表然后显示A。计算机中只有0和1。
有了ASCII表就可以显示英文。
但是计算机要显示中文怎么办?不仅是中文,要显示各个国家的文字怎么办?
ok,我们先不谈其他国家的文字,我们就谈中文。
英文是比较简洁的语言,用char(256)类型就完全够表示了。但是汉字博大精深,博主上网查了一下汉字有85568个,肯定不能用char类型存储,两个字符(256*256)大概是6万多也不够,3个字符就有点浪费了。所以咱们国家针对中文也写了一个编码表,叫gbk(国标)。Unicode的视角就更大了,它针对是全世界的文字,它的编码就十分复杂。
Windows显示汉字一般用gbk,Linux用utf-8。但是都要兼容ASCII。
常见的汉字用2个字节表示,不常见的汉字可能用3个或者4个字节:
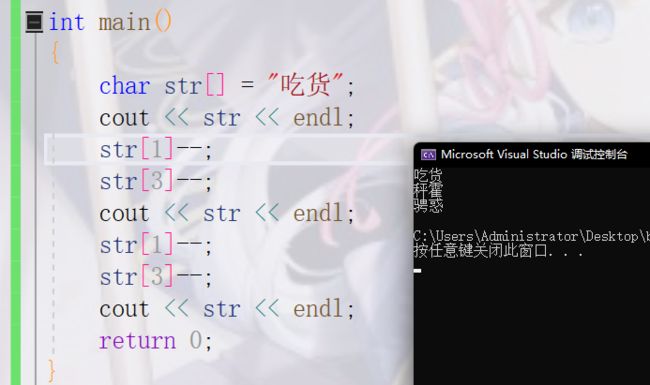
同音字编码时是编到一起的,王者荣耀把脏话屏蔽掉就会用到这一点。
大家再想一想string为什么要设计成模板?ok,就是因为编码问题。
☀️4 string类的常用接口说明
博主只会讲几种常用的接口,想了解更多请查看文档。
⚡️4.1. string类对象的常见构造
| (constructor)函数名称 | 功能说明 |
|---|---|
| string() (重点) | 构造空的string类对象,即空字符串 |
| string(const char* s) (重点) | 用C-string来构造string类对象 |
| string(size_t n, char c) | string类对象中包含n个字符c |
| string(const string&s) (重点) | 拷贝构造函数 |
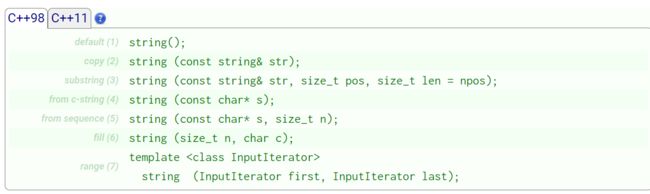
第七个要用到迭代器,暂时不讲。
string管理动态增长的字符数组,这个字符串以"\0"结尾。所以可以用字符串来构造且能实现增删查改等功能。
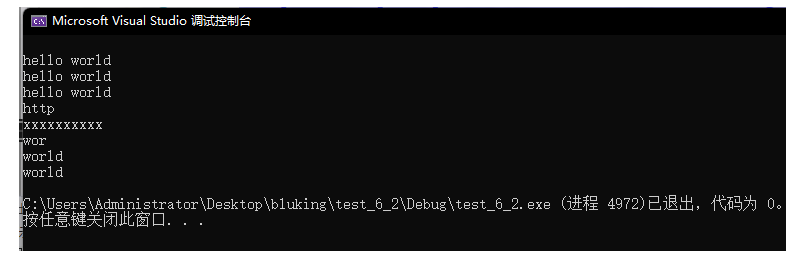
void test_string1()
{
string s1;
string s2("hello world");
string s3(s2);
string s4 = s2;
//前4个初始化
string s5("http://m.cplusplus.com/reference/string/string/string/", 4);
//用n个C初始化
string s6(10, 'x');
//string (const string& str, size_t pos, size_t len = npos);
//static const size_t npos = -1;
//npos表示如果取的字符超过剩余的字符数量,有多少取多少
//从s2的第6个字符起,取3个字符初始化
string s7(s2, 6, 3);
//超过剩余的字符数量,有多少取多少
string s8(s2, 6, 100);
//不给第三个参数,默认参数是npos
string s9(s2, 6);
}
运行结果:
4.2. string类对象的赋值
早期string的设计没有经验,设计了很多冗余的。
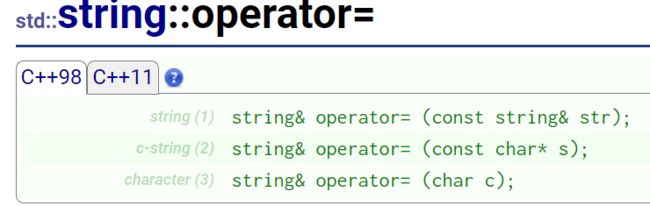
void test_string2()
{
string s1("hello");
string s2("xxx");
s1 = s2;
s1 = "yyy";
s1 = 'y';
}
4.3. string类对象的修改操作
| 函数名称 | 功能说明 |
|---|---|
| push_back | 在字符串后尾插字符c |
| append | 在字符串后追加一个字符串 |
| operator+= (重点) | 在字符串后追加字符串str |
| c_str | 返回C格式字符串 |
| find+ npos(重点) | 从字符串pos位置开始往后找字符c,返回该字符在字符串中的位置 |
| rfind | 从字符串pos位置开始往前找字符c,返回该字符在字符串中的位置 |
| substr | 在str中从pos位置开始,截取n个字符,然后将其返回 |
void test_string6()
{
string s;
s.push_back('x');
s.append("hello");
string str("world");
s.append(str);
cout << s << endl;
s += 'x';
s += "hello";
s += str;
cout << s << endl;
}
运行结果:

4.4. string类对象的容量操作
| 函数名称 | 功能说明 |
|---|---|
| size(重点) | 返回字符串有效字符长度 |
| length | 返回字符串有效字符长度 |
| capacity | 返回空间总大小 |
| empty (重点) | 检测字符串释放为空串,是返回true,否则返回false |
| clear (重点) | 清空有效字符 |
| reserve (重点) | 为字符串预留空间 |
| resize (重点) | 将有效字符的个数该成n个,多出的空间用字符c填充 |
string先于STL设计,所以string严格意义上不属于STL。length也是早期设计string类产生的。到了STL的出现,人们发现string和STL具有相同的性质,又设计了size接口。(而且后面的树还叫length就不合适了),所以都推荐大家去用size。
push_back扩容问题:
void test_string6()
{
string s;
size_t sz = s.capacity();
cout << "making s grow:\n";
cout << "capacity changed: " << sz << '\n';
for (int i = 0; i < 1000; ++i)
{
s.push_back('c');
if (sz != s.capacity())
{
sz = s.capacity();
cout << "capacity changed: " << sz << '\n';
}
}
}
运行结果:
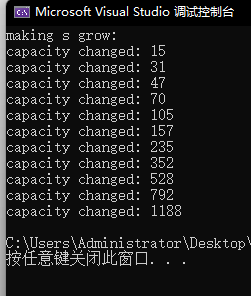
扩容是有代价的,开新的空间要释放旧的空间,因为不一定都能原地扩容。那有没有什么方法可以减少扩容?有,reserve(提前把空间开好)。
void test_string6()
{
string s;
//因为对齐的原因,可能会多开一点,申请空间都会自然对齐的
s.reserve(1000);
size_t sz = s.capacity();
cout << "making s grow:\n";
cout << "capacity changed: " << sz << '\n';
for (int i = 0; i < 1000; ++i)
{
s.push_back('c');
if (sz != s.capacity())
{
sz = s.capacity();
cout << "capacity changed: " << sz << '\n';
}
}
}
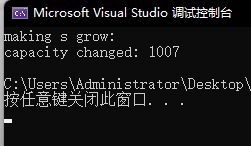
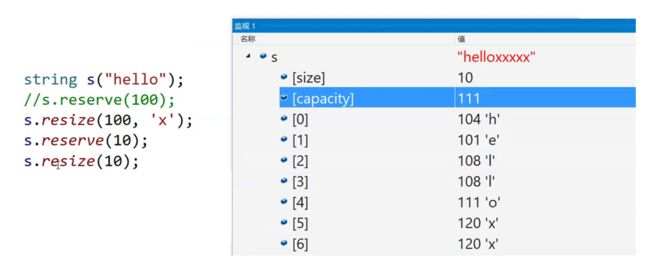
resize不仅会扩容还会改变size,还会初始化(如果不给第二个参数默认初始化为\0):
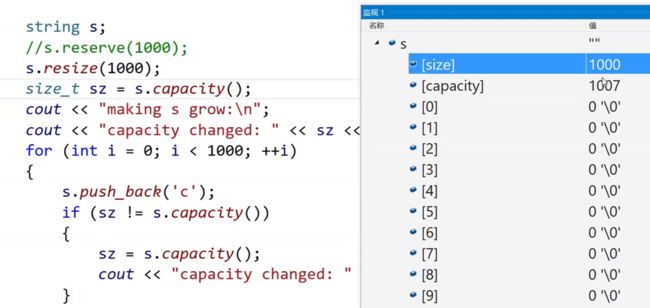
如果string已经有数据了,resize还有其他用法:不会改变原始数据,会在后面补上初始化的值(95个x)。
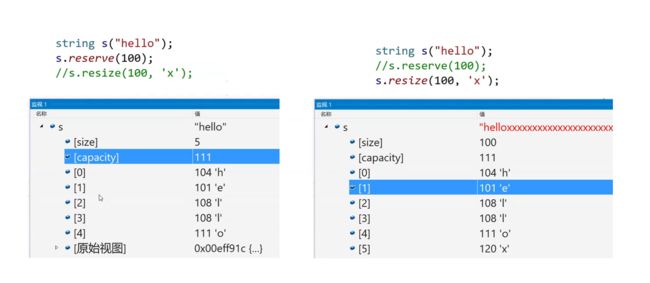
VS下reserve和resize都不会缩小容量,但是resize会缩小size:
4.5 string类对象的访问及遍历操作
string管理动态增长的字符数组,我们能像数组一样对string对象进行访问和遍历。
| 函数名称 | 功能说明 |
|---|---|
| operator[] (重点) | 返回pos位置的字符,const string类对象调用 |
| begin+ end | begin获取一个字符的迭代器 + end获取最后一个字符下一个位置的迭代器 |
| rbegin+ rend | begin获取一个字符的迭代器 + end获取最后一个字符下一个位置的迭代器 |
| 范围for | C++11支持更简洁的范围for的新遍历方式 |
迭代器是类似指针的东西或者它就是指针,具体要看它的底层实现。

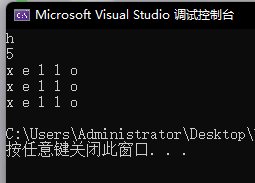
void test_string3()
{
// 遍历string的每一个字符
string s1("hello");
cout << s1[0] << endl;
s1[0] = 'x';
cout << s1.size() << endl;
// 第一种方式,下标+[]
for (size_t i = 0; i < s1.size(); i++)
{
// s1.operator[](i);
cout << s1[i] << " ";
}
cout << endl;
//const char* s2 = "world";
//s2[i]; // *(s2+i)
// 迭代器
string::iterator it = s1.begin();
while (it != s1.end())
{
cout << *it << " ";
++it;
}
cout << endl;
// 范围for -- 原理:替换成迭代器
for (auto ch : s1)
{
cout << ch << " ";
}
cout << endl;
}
运行结果:
我们再随便找一道题来看:
利用快排单排排序的思想,但这里不是找大找小,这里是找字母,然后交换。
class Solution
{
public:
bool isLetter(char ch)
{
if(ch >= 'a' && ch <= 'z')
return true;
else if(ch >= 'A' && ch <= 'Z')
return true;
else
return false;
}
string reverseOnlyLetters(string s)
{
int left = 0, right = s.size()-1;
while(left < right)
{
//cout<
while(left < right && !isLetter(s[left]))
++left;
while(left < right && !isLetter(s[right]))
--right;
swap(s[left], s[right]);
++left;
--right;
}
return s;
}
};
4.6. at和operator[]的区别
at也是string类早期设计的接口,它与operator[]的区别是:operator[]会报越界的检查(assert),at会抛异常。
实际工作中,一般用operator[]用的多

void test_string4()
{
string s1("hello");
const string s2("hello");
//s1[6];
//s2[6];
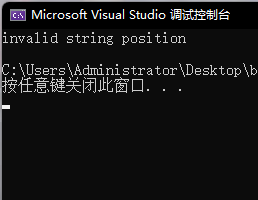
s1.at(6);
s2.at(6);
s1[0] = 'x';
//s2[0] = 'x';
s1.at(0) = 'y';
}
int main()
{
try
{
test_string4();
}
catch (const exception& e)
{
cout << e.what() << endl;
}
return 0;
}
运行结果:
operator[]:
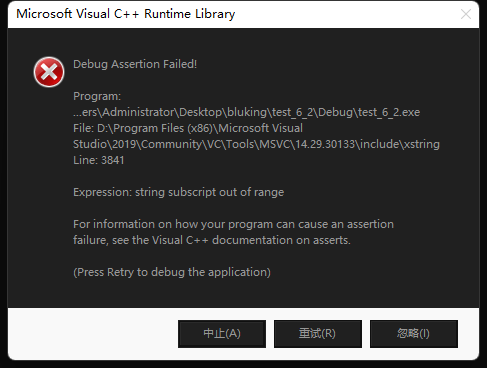
at:
4.7 四种迭代器


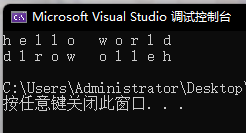
void test_string5()
{
// 正向迭代器
string s("hello world");
string::iterator it = s.begin();
while (it != s.end())
{
cout << *it << " ";
++it;
}
cout << endl;
// 反向迭代器
string::reverse_iterator rit = s.rbegin();
while (rit != s.rend())
{
cout << *rit << " ";
++rit;
}
cout << endl;
}
运行结果:
如果是const对象会调用相应的const迭代器:返回一个只读的迭代器对象。
void Func(const string& rs)
{
string::const_iterator it = rs.begin();
while (it != rs.end())
{
//*it += 1;
cout << *it << " ";
++it;
}
cout << endl;
//string::const_reverse_iterator rit = rs.rbegin();
auto rit = rs.rbegin();
while (rit != rs.rend())
{
//(*rit) -= 1;
cout << *rit << " ";
++rit;
}
cout << endl;
}

5. 总结
今天博主把string类常用的接口简单介绍了下,其余大家看文档应该也可以搞懂。大家尽量参考英文文档,不要有畏惧心理(如果你想吃这碗饭)。像STL中的vector、lsit、stack、queue大家都可以边查文档边练习,博主认为这是最高效的学习方法。
关于string的剩下内容和它的底层原理,博主会在下一篇模拟实现string的博客中讲解。