2W字长文吐血整理 Docker&云原生
Docker 和 云原生
一、概念介绍
1.1 Docker
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的 Linux或Windows操作系统的机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。
- Docker历史
软件开发最大的麻烦事之一,就是环境配置。用户计算机的环境都不相同,你怎么知道自家的软件,能在那些机器跑起来
- 比如你编写了一个Web应用,本地调试没有问题,想发给你的朋友看看或者部署到远程服务器。那么首先你需要配置相同的环境(数据库、Web服务器),不一定保证能够启动起来
- 开发和测试同学最常反馈的:“它在我的本地是可以的”,言下之意就是,其他机器很可能跑不了。
为了解决这个问题,出现以物理机和虚拟机为主体的开发运维环境,向以容器为核心的基础设施的转变过程
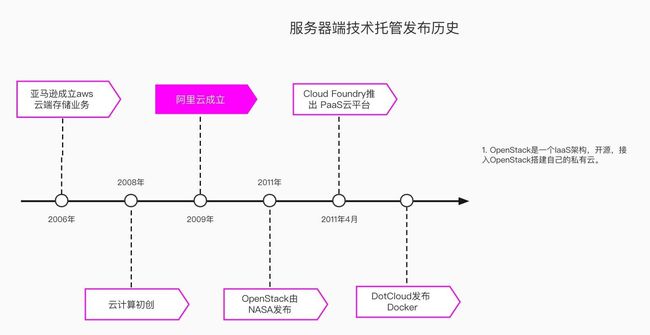
半个世纪以前,集装箱发挥了巨大的力量,改变了整个运输产业(集装箱化作业的兴起)。可以说是“没有集装箱,就不会有全球化”。
而Docker横空出世,是云服务市场的重要拐点。Docker,相当于云服务市场的“箱子”,对Container(容器)技术的运用代表新的时代来临。DockerLogo:鲸鱼就是操作系统,通过身上的集装箱(Container)来将不同种类的货物进行隔离;而不是通过生出很多小鲸鱼(Guest OS)来承运不同种类的货物。

那么物理机/虚拟机为什么会被容器替代?
虚拟机(VM)和Docker经常在一个上下文出现,因为它们都是用于隔离环境
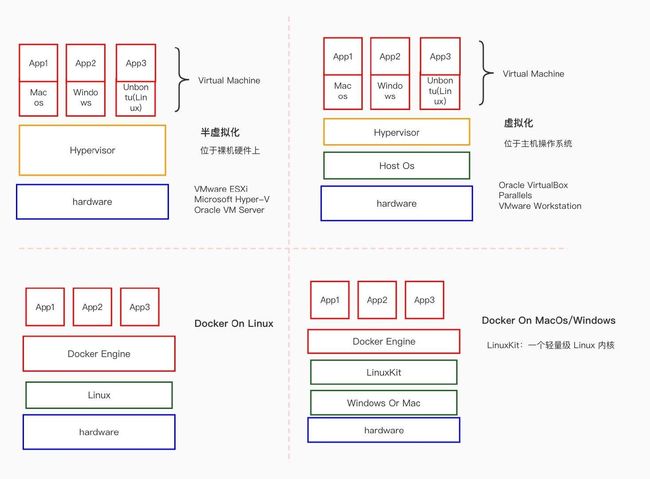
从上图可以看出,和平时使用中总结下来,虚拟机和 Docker 容器的差异。虚拟机需要模拟硬件,运行整个操作系统,不但体积臃肿还内存占用高,程序性能也会受到影响
| 虚拟机 | Docker |
|---|---|
| 硬件级进程隔离 | 操作系统级进程隔离 |
| 每个虚拟机都有一个单独的操作系统 | 每个容器可以共享操作系统 |
| 在几分钟内启动 | 在几秒钟内启动 |
| 虚拟机只有几 GB | 容器是轻量级的 (KBs/MBs) |
| 更多资源使用 | 更少的资源使用 |
| 虚拟机可以轻松迁移到新主机 | 容器被销毁并重新创建而不是移动 |
| 创建VM需要相对较长的时间 | 容器可以在几秒钟内创建 |

Docker打包机制
但是容器取代虚拟机真正的原因还是Docker发明的镜像。例如PaaS大规模部署应用到集群,需要为每种语言、框架甚至每一个版本的应用维护一个打好的包,必须要做很多修改和配置工作才能在PaaS里面运行起来。虽然能一键部署,但是为应用打包可是一波三折
而Docker 镜像解决的,恰恰就是打包这个根本性的问题。所谓 Docker 镜像,其实就是一个压缩包。但是这个压缩包里的内容,比 PaaS 的应用可执行文件 + 启停脚本的组合要丰富多了。实际上,大多数 Docker 镜像是直接由一个完整操作系统的所有文件和目录构成的,所以这个压缩包里的内容跟你本地开发和测试环境用的操作系统是完全一样的。
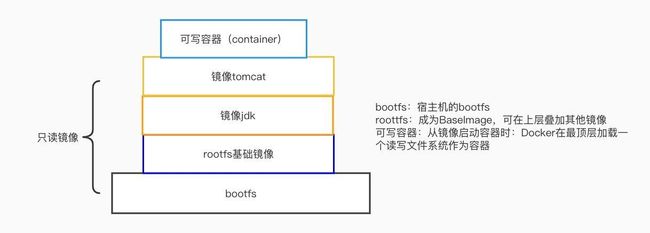
只要有这个压缩包在手,你就可以使用某种技术创建一 个“沙盒”,在“沙盒”中解压这个压缩包,然后就可以运行你的程序了。
这种机制直接打包了应用运行所需要的整个操作系统,从而保证了本地环境和云端环境的高度一致
- Docker的“沙盒”实现
容器技术的核心功能,就是通过约束和修改进程的动态表现,从而为其创造出一个"边界",对于 Docker 等大多数 Linux 容器来说,都是使用 Cgroups 和 Namespace 机制创建出来的 隔离环境,基于AUFS(Advance Union File System) 文件系统进行打包

- cgroup:资源分配和管理
- namspsce:隔离(用户/网络/进程等)隔离
- aufs:镜像打包机制
Cgroups
Linux Cgroups 的全称是 Linux Control Group。它最主要的作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。
此外,Cgroups 还能够对进程进行优先级设置、审计,以及将进程挂起和恢复等操作。在今天的分享中,只重点探讨它与容器关系最紧密的“限制”能力。在 Linux 中,Cgroups 给用户暴露出来的操作接口是文件系统,即它以文件和目录的方式组织在操作系统的 /sys/fs/cgroup 路径下。可以用 mount 指令把它们展示出来,这条命令是:
[root@k8s-demo-master ~]# mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls,net_prio)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/rdma type cgroup (rw,nosuid,nodev,noexec,relatime,rdma)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
在 /sys/fs/cgroup 下面有很多诸如 cpuset、cpu、 memory 这样的子目录, 也叫子系统。这些都是我这台机器当前可以被 Cgroups 进行限制的资源种类
[root@k8s-demo-master ~]# cd /sys/fs/cgroup/cpu
[root@k8s-demo-master cpu]# ls
aegis cgroup.procs cpuacct.usage cpuacct.usage_percpu_sys cpuacct.usage_user cpu.rt_period_us cpu.stat release_agent
assist cgroup.sane_behavior cpuacct.usage_all cpuacct.usage_percpu_user cpu.cfs_period_us cpu.rt_runtime_us kubepods system.slice
cgroup.clone_children cpuacct.stat cpuacct.usage_percpu cpuacct.usage_sys cpu.cfs_quota_us cpu.shares notify_on_release tasks
[root@k8s-demo-master cpu]# cat cpuacct.usage
34538850584425
[root@k8s-demo-master cpu]# cat cpu.cfs_quota_us
20
它意味着在每 100 ms 的时间里,被该 控制组限制的进程只能使用 20 ms 的 CPU 时间,也就是说这个进程只能使用到 20% 的 CPU 带宽。如果在sys/fs/cgroup/cpu目录下创建一个目录,视为”控制组“,并且新建cpu.cfs_quota_us的限制文件和tasks对应的进程id文件,就能够达到对指定的进程id进行限制
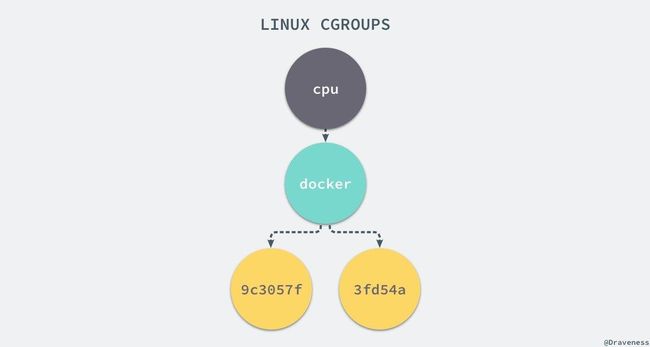
Linux Cgroups 的设计还是比较易用的,简单粗暴地理解呢,它就是一个子系统目录加上一组资源限制文件的组合。而对于 Docker 等 Linux 容器项目来说,它们只需要在每个子系统下面,为每个容器创建一个控制组(即创建一个新目录),然后在启动容器进程之后, 把这个进程的 PID 填写到对应控制组的 tasks 文件中就可以了。
Namspace机制
我们在 Docker 里最开始执行的 /bin/sh,就是这个容器内部的第 1 号进程 (PID=1),而这个容器里一共只有两个进程在运行。这就意味着,前面执行的 /bin/sh, 以及我们刚刚执行的 ps。已经被 Docker 隔离在了一个跟宿主机完全不同的世界当中。
# wangjun @ LPT004412 in ~ [17:03:04]
$ docker exec -it 9bf2d02c1236 /bin/sh
/ # ps
PID USER TIME COMMAND
1 root 0:00 sh
24 root 0:00 /bin/sh
31 root 0:00 ps
/ # exit
# wangjun @ LPT004412 in ~ [17:04:06] C:130
$ ps -ef
UID PID PPID C STIME TTY TIME CMD
0 1 0 0 1:14下午 ?? 0:32.45 /sbin/launchd
0 294 1 0 1:14下午 ?? 0:28.60 /usr/libexec/logd
命名空间 (namespaces) 是 Linux 为我们提供的用于分离进程树、网络接口、挂载点以及进程间通信等资源的方法。
| 分类 | 系统调用参数 | 相关内核版本 | 隔离内容 |
|---|---|---|---|
| Mount namespaces | CLONE_NEWNS | Linux 2.4.19 | 挂载点(文件系统) |
| UTS namespaces | CLONE_NEWUTS | Linux 2.6.19 | 主机名和域名 |
| IPC namespaces | CLONE_NEWIPC | Linux 2.6.19 | 信号量、消息队列和共享内存 |
| PID namespaces | CLONE_NEWPID | Linux 2.6.24 | 进程编号 |
| Network namespaces | CLONE_NEWNET | 始于 Linux 2.6.24 完成于 Linux 2.6.29 | 网络设备、网络栈、端口等 |
| User namespaces | CLONE_NEWUSER | 始于 Linux 2.6.23 完成于 Linux 3.8) | 用户和用户组 |
在 Linux 系统中创建线程 的系统调用是 clone(),比如:
int pid = clone(main_function, stack_size, SIGCHLD, NULL)
这个系统调用就会为我们创建一个新的进程,并且返回它的进程号 pid。
当我们用 clone() 系统调用创建一个新进程时,就可以在参数中指定 CLONE_NEWPID 参数,比如:
int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL);
这时,新创建的这个进程将会“看到”一个全新的进程空间,在这个进程空间里,它的 PID 是 1。之所以说“看到”,是因为这只是一个“障眼法”,在宿主机真实的进程空间里,这个进程的 PID 还是真实的数值,比如 100。

所以在使用 Docker 的时候,可以发现并没有一个真正的“Docker 容器”运行在宿主机里面。Docker 项目帮助用户启动的,还是原来的应用进程,只不过在创建这些进程时,Docker 为它们加上了各种各样的 Namespace 参数。
AUFS
AUFS解决了镜像打包的问题,Docker 镜像其实本质就是一个压缩包,我们可以使用下面的命令将一个 Docker 镜像中的文件导出:
$ docker export $(docker create busybox) | tar -C rootfs -xvf -
$ ls
bin dev etc home proc root sys tmp usr var
你可以看到这个 busybox 镜像中的目录结构与 Linux 操作系统的根目录中的内容并没有太多的区别,可以说 Docker 镜像就是一个文件。

Docker 中的每一个镜像都是由一系列只读的层组成的,Dockerfile 中的每一个命令都会在已有的只读层上创建一个新的层:
AUFS 作为联合文件系统,它能够将不同文件夹中的层联合(Union)到了同一个文件夹中,这些文件夹在 AUFS 中称作分支,整个『联合』的过程被称为联合挂载(Union Mount):

dive命令下面的这张图片非常好的展示了组装的过程,每一个镜像层都是建立在另一个镜像层之上的,同时所有的镜像层都是只读的,只有每个容器最顶层的容器层才可以被用户直接读写,所有的容器都建立在一些底层服务(Kernel)上,包括命名空间、控制组、rootfs 等等,这种容器的组装方式提供了非常大的灵活性,只读的镜像层通过共享也能够减少磁盘的占用。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-usGoGDPB-1646913907755)(/Users/wangjun/Library/Application Support/typora-user-images/image-20220310193950144.png)]

- 基本概念

- Docker Client : Docker提供给用户的客户端。
- Docker Daemon : Docker服务的守护进程。Daemon会接收Docker Client发过来的指令,并对服务器的进行具体操作。
- Docker Images : 俗称Docker的镜像
- Docker Registry : 这个可认为是Docker Images的仓库
- Docker Container : 俗称Docker的容器。Container是真正跑项目程序、消耗机器资源、提供服务的地方,Container通过Images启动
Docker好比汽车引擎,
Dockerfile相当于汽车蓝图,
Docker image(镜像)就是汽车样板,
Docker container(容器)类似于汽车的零部件,
Docker Registry可以看作是4s店,
Docker Compose就像老司机,
Docker Volume就像是汽车的油箱, 如果把容器间内的io数据流比喻成汽油,
Docker Swarm(或者K8s)就是交通枢纽。
- 基本命令
首先要在宿主机上安装Docker,Docker安装参考官方安装文档。 Docker命令也比较类似Git,支持push以及pull操作上传以及下载Docker镜像。 查看当前Docker的版本
docker version
查看当前系统Docker信息
docker info
查看宿主机上的镜像,Docker镜像保存在/var/lib/docker目录下:
docker images
从Docker hub上下载某个镜像:
docker pull ubuntu:latest
docker pull ubuntu:latest
执行docker pull ubuntu会将Ubuntu这个仓库下面的所有镜像下载到本地repository。
启动一个容器使用docker run:
docker run -i -t ubuntu /bin/bash 启动一个容器
docker run -i -t --rm ubuntu /bin/bash --rm表示容器退出后立即删除该容器
docker run -t -i --name test_container ubuntu /bin/bash --name指定容器的名称,否则会随机分配一个名称
docker run -t -i --net=host ubuntu /bin/bash --net=host容器以Host方式进行网络通信
docker run -t -i -v /host:/container ubuntu /bin/bash -v绑定挂在一个Volume,在宿主机和Docker容器中共享文件或目录
查看当前有哪些容器正在运行,使用docker ps:
wangjun @ LPT004412:$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
50a1261f7a8b docker_test:latest "/bin/bash" 7 seconds ago Up 6 seconds sleepy_ptolemy
# 目前只有一个container id为50a1261f7a8b的容器正在运行
启动或停止某个container使用docker start/stop container_id:
wangjun @ LPT004412:$ docker stop 50a1261f7a8b
50a1261f7a8b
wangjun @ LPT004412:$ docker ps -a | grep 50a1261f7a8b
50a1261f7a8b docker_test:latest "/bin/bash" 2 minutes ago Exited (0) 14 seconds ago sleepy_ptolemy
#执行docker stop后,该容器的状态变更为Exited
使用docker commit可以将container的变化作为一个新的镜像,比如:
wangjun @ LPT004412:$ docker commit -m="test docker commit" 50a1261f7a8b docker_test
55831c956ebf46a1f9036504abb1b29d7e12166f18f779cccce66f5dc85de38e
wangjun @ LPT004412:$ docker images | grep docker_test
docker_test latest 55831c956ebf 10 seconds ago 290.7 MB
除了从Docker hub上下载镜像,也可以写Dockerfile创建一个镜像,Dockerfile如下所示:
wangjun @ LPT004412:/tmp/docker(0)$ cat Dockerfile
FROM ubuntu:12.04
MAINTAINER Your Name
RUN apt-get update
RUN apt-get install -y python-software-properties python-pip
ADD myproject /opt/code
RUN pip install -r /opt/code/requirement.txt
写完Dockerfile,在Dockerfile所在目录执行docker build创建镜像:
docker build -t docker_test .
docker run -i -t docker_test /bin/bash -c "cd /opt/code;python manage.py runserver 0.0.0.0:8080"
将制作的镜像上传到private registry:
docker tag test docker.example.com/test
docker push docker.example.com/test
经过长时间使用,主机上存储了很多已无用的镜像,想将它们删除则用docker rm或者docker rmi,比如:
docker rm container_id
docker rmi image_id
实战练习一下~举个例子
1.2 Kubernetes
女朋友也能看懂的 Kubernetes
https://developers.redhat.com/blog/2018/06/28/why-kubernetes-is-the-new-application-server
https://mp.weixin.qq.com/s/FEG8kaJRqB0LdvPQ7W-tJQ
云原生操作系统,声明式 API 是它的核心,Operator 操控万物。
Kubernetes 这个名字起源于古希腊,是「舵手」的意思,所以它的 Logo 既像一张渔网,又像一个罗盘。如果 Docker 把自己定位为驮着集装箱在大海上遨游的鲸鱼,那么 Kubernetes 就是掌舵大航海时代话语权的舵手,指挥着这条鲸鱼按照主人设定的路线巡游。

Kubernetes在2014年成立,在谷歌的内部集装箱集群管理者Borg和Omega的帮助下,拥有超过十多年的生产工作量管理经验。为整个云原生生态系统铺平了道路。
Kubernetes一个用于容器集群的自动化部署、扩容以及运维的开源平台。通过Kubernetes,你可以快速有效地响应用户需求;快速而有预期地部署你的应用;极速地扩展你的应用;无缝对接新应用功能;节省资源,优化硬件资源的使用。为容器编排管理提供了完整的开源方案。
容器
我们现在常说的容器一般是指Docker容器,通过容器隔离的特性和宿主机进行解耦,使我们的服务不需要依赖于宿主机而运行,与宿主机互不影响,Docker容器十分轻量。而kubernetes则负责管理服务中所有的Docker容器,创建、运行、重启与删除容器。
快速响应
个人理解为两个方面。一、新增或者修改需求时,可以快速进行部署测试(CICD);二、kubernetes可以根据不同条件进行动态扩缩容,举个栗子,用户访问量突然由1000人上升到100000人时,现有的服务已经无法支撑,kubernetes会自动将用户服务模块增加更多实例以保证当前的系统访问量。
扩展
在快速响应的特点中已经有所提及,这里再补充一点: Kubernetes内部有完善的注册发现机制,当某个服务的实例增加时,kubernetes会自动将其加入服务列表中,免除在传统运维中需要人工维护服务列表的问题。
对接新应用
kubernetes是一个通用的容器编排框架,支持不同类型的语言,或者是语言无关的,新增加的应用都会以一个新的对象进行接入。
硬件资源
这一点我觉得是kubernetess很基本但是非常重要的一个优点了,kubernetes在部署应用时会自动检查各个服务器的cpu与内存使用量,同时会根据服务申请的cpu与内存资源,将服务部署到最合适的服务器。(其实这就是容器调度的核心功能了)
Kubernetes历史
CNCF:https://landscape.cncf.io/

Kubernetes 集群包含一个 master 和很多 node。Master 是控制集群的中心,node 是提供 CPU、内存和存储资源的节点。Master 上运行着多个进程,包括面向用户的 API 服务、负责维护集群状态的 Controller Manager、负责调度任务的 Scheduler 等。每个 node 上运行着维护 node 状态并和 master 通信的 kubelet,以及实现集群网络服务的 kube-proxy。
Kubernetes的架构
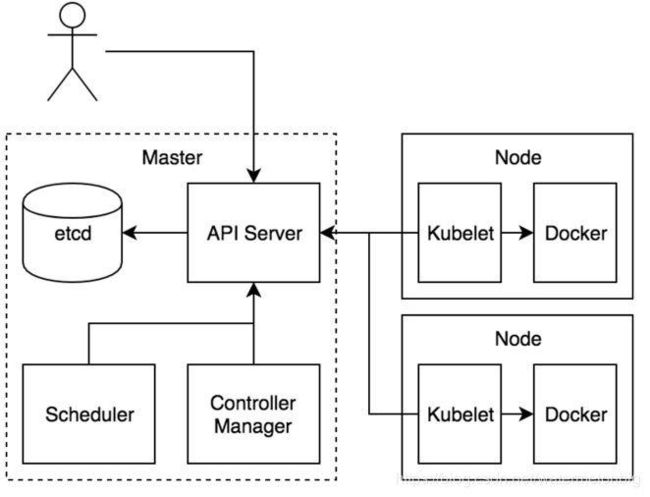
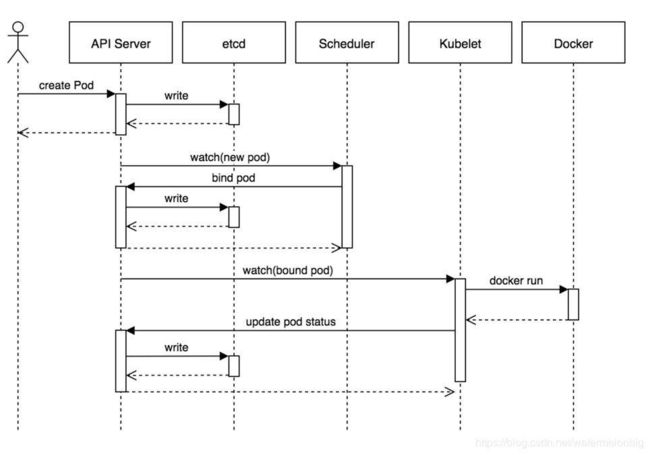
- etcd是Kubernetes的存储状态的分布式数据库,采用raft协议作为一致性算法(raft协议原理可参见一个动画演示http://thesecretlivesofdata.com/raft/)。
- API Server组件主要提供认证与授权、运行一组准入控制器以及管理API版本等功能,通过REST API向外提供服务,允许各类组件创建、读取、写入、更新和监视资源(Pod, Deployment, Service等)。
- Scheduler组件,根据集群资源和状态选择合适的节点用于创建Pod。
- Controller Manager组件,实现ReplicaSet的行为。
- Kubelet组件,负责监视绑定到其所在节点的一组Pod,并且能实时返回这些Pod的运行状态。
部署 - Deployment
类似于Docker中的镜像Image,也就是容器(Pods)实例的模板,容器实例是根据Deploy创建出来的。在Deployment对象中会写明容器的镜像,容器的版本,容器要部署的数量等信息。
容器组 - Pods
Pods是Kubernetes中的最小管理单元,Pods和Docker中的容器可以理解为包含关系,在Pods中可以包含有多个Docker容器,例如有ServiceA和ServiceB,ServiceA高度依赖ServiceB(需要共享主机的相同文件),这时就可以将ServiceA与ServiceB放在同一个Pods中,当做一个整体来管理。如果分开部署当然也可以,不过会小号额外的资源或者产生其他不必要的麻烦。
服务 - Service
Service是一个对象,这个对象有自己的IP,也就是ClusterIP,可以理解为就是下层服务的负载均衡。
路由 - Ingress
无论是容器组还是Service,外网都是无法直接访问的,Ingress就可以通过一个负载IP与Kubernetes集群内部进行通讯,一般会和Service对象进行配合使用。
配置项 - ConfigMap
简单理解为一个管理配置的对象,可以将项目的配置写入到ConfgiMap中,项目中的配置使用相应的变量名就可以读取相应的变量值。
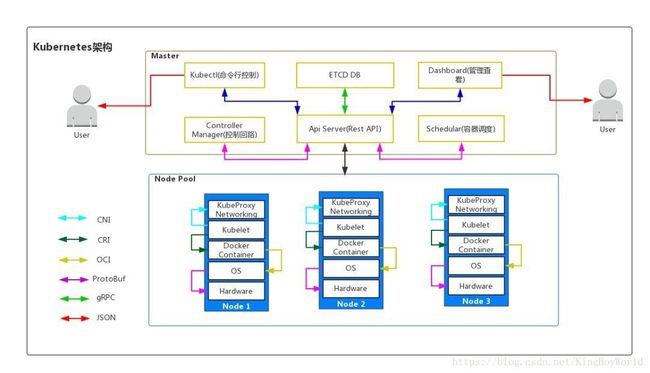
Kubernetes由Master节点和Worker节点组成。master节点是Kubernetes的大脑,而woker节点则是kubernetes中实际运行服务的劳动者。
Master主要由ETCD/Controller Manager/Api Server/Schedular能成,
ETCD
主要负责存储各个woker节点的状态和其它相关数据,可以理解为kubernetes的数据库。
Controller Manager
负责维护集群的状态,比如故障检测、自动扩展、滚动更新等
Scheduler
负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上
Worker主要由kubelet和kube-proxy组成,一般还会安装kube-dns组件。
kubelet
负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理;
kube-proxy
负责为Service提供cluster内部的服务发现和负载均衡;
kube-dns
负责为整个集群提供DNS服务,通过Service名称访问相应的服务
Kubernetes命令行示例例子:https://mp.weixin.qq.com/s/bij0kiYK_C6ppcINV0z43g
Kubernetes官方例子:https://mp.weixin.qq.com/s/FWxnDcgCVvVDoStoI3IqbQ https://kubernetes.io/docs/tutorials/kubernetes-basics/
1.3 云原生
CNCF给出了云原生应用的三大特征:
- **容器化封装:**以容器为基础,提高整体开发水平,形成代码和组件重用,简化云原生应用程序的维护。在容器中运行应用程序和进程,并作为应用程序部署的独立单元,实现高水平资源隔离。
- **动态管理:**通过集中式的编排调度系统来动态的管理和调度。
- **面向微服务:**明确服务间的依赖,互相解耦。
云原生包含了一组应用的模式,用于帮助企业快速,持续,可靠,规模化地交付业务软件。云原生由微服务架构,DevOps 和以容器为代表的敏捷基础架构组成。

SercieMesh
服务网格(Service Mesh)是处理服务间通信的基础设施层。它负责构成现代云原生应用程序的复杂服务拓扑来可靠地交付请求。在实践中,Service Mesh 通常以轻量级网络代理阵列的形式实现,这些代理与应用程序代码部署在一起,对应用程序来说无需感知代理的存在。
如果用一句话来解释什么是 Service Mesh,可以将它比作是应用程序或者说微服务间的 TCP/IP,负责服务之间的网络调用、限流、熔断和监控。对于编写应用程序来说一般无须关心 TCP/IP 这一层(比如通过 HTTP 协议的 RESTful 应用),同样使用 Service Mesh 也就无须关心服务之间的那些原本通过服务框架实现的事情,比如 Spring Cloud、Netflix OSS 和其他中间件,现在只要交给 Service Mesh 就可以了。

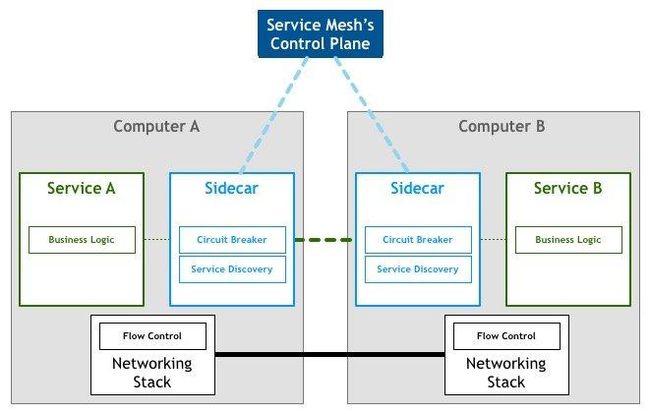
下面以 Istio 为例讲解 Service Mesh 如何工作,后续文章将会详解 Istio 如何在 Kubernetes 中工作。
- Sidecar(Istio 中使用 Envoy 作为 sidecar 代理)将服务请求路由到目的地址,根据请求中的参数判断是到生产环境、测试环境还是 staging 环境中的服务(服务可能同时部署在这三个环境中),是路由到本地环境还是公有云环境?所有的这些路由信息可以动态配置,可以是全局配置也可以为某些服务单独配置。这些配置是由服务网格的控制平面推送给各个 sidecar 的,
- 当 sidecar 确认了目的地址后,将流量发送到相应服务发现端点,在 Kubernetes 中是 service,然后 service 会将服务转发给后端的实例。
- Sidecar 根据它观测到最近请求的延迟时间,选择出所有应用程序的实例中响应最快的实例。
- Sidecar 将请求发送给该实例,同时记录响应类型和延迟数据。
- 如果该实例挂了、不响应了或者进程不工作了,sidecar 会将把请求发送到其他实例上重试。
- 如果该实例持续返回 error,sidecar 会将该实例从负载均衡池中移除,稍后再周期性得重试。
- 如果请求的截止时间已过,sidecar 主动标记该请求为失败,而不是再次尝试添加负载。
- SIdecar 以 metric 和分布式追踪的形式捕获上述行为的各个方面,这些追踪信息将发送到集中 metric 系统。
https://capa-cloud.github.io/capa.io/blog/2022/01/18/capa-mecha-sdk-of-cloud-application-api/
ServiceMesh带来的新的挑战
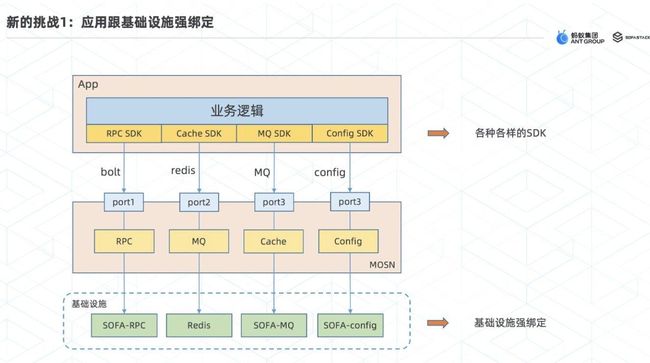
Severless
拿部署一套博客来说,常见的 Node.js MVC 架构,需要购买云服务商的 Linux 虚拟机、RDS 关系型数据库,做得好的话还要购买 Redis 缓存、负载均衡、CDN 等等。再考虑容灾和备份,这么算下来一年最小开销都在 1 万元左右。但如果你用 Serverless 的话,这个成本可以直接降到 1000 元以下。
可预见时间内的云原生的终极形式,真正的按需使用和按量付费。
Serverless架构能够让开发者在构建应用的过程中无需关注计算资源的获取和运维,由平台来按需分配计算资源并保证应用执行的SLA(服务等级协议),按照调用次数进行计费,有效的节省应用成本。ServerLess的架构如上图所示。其优点如下所示:
低运营成本/更快的开发速度/提升可维护性/简化设备运维
二、如何CICD
持续集成(Continuous integration) / 持续部署(Continuous Deployment)
美团经验:https://tech.meituan.com/2019/08/22/kubernetes-cluster-management-practice.html
2.2 自己做CICD
[Gitee-Jenkins插件]https://gitee.com/help/articles/4193#article-header0

三、平时开发中使用Docker
3.1 环境搭建
https://nystudio107.com/blog/dock-life-using-docker-for-all-the-things
四、扩展阅读
4.1 其他
- Docker官方文档 Docker中文社区 Docker-从入门到实践 Docker-For-Beginnings
- Docker如何运行MacOS Docker-搭建树莓派
- Kubernetes 中文官方文档 免费学习 Kubernetes 利器
- Kubernetes中文指南/云原生应用架构实践手册
- Kuboard - Kubernetes 多集群管理界面
- 语雀文档 - Kubernetes运维整理
- Kubernetes 工程师资料合辑,书籍推荐,面试题,精选文章,开源项目,PPT,视频,大厂资料
- 和我一步步部署 kubernetes 集群 一条命令部署 Kubernetes 高可用集群
- Kubernetes 学习笔记
- Jenkins 与 Kubernetes 的 CI 与 CD & Git + Maven + Docker+Kubectl
- Service Mesh 在中国的布道者和领航者
- Serverless Handbook—无服务架构实践手册
4.3 技术分享
- 技术中心-分享Docker
- GCOS 全球云原生及开源峰会2022·上海站
- CNCF x Alibaba 云原生技术公开课 - 云原生教程
- 用Prometheus监控K8S
- 使用Prometheus完成Kubernetes集群监控
- 用 Prometheus 监控 Kubernetes