【C语言详解】——指针详解
文章目录
- 一、 指针是什么?
- 二、指针和指针类型
- 三、野指针
- 四、指针运算
- 五、指针和数组
- 六、二级指针
- 七、指针数组
- 八、字符指针
- 八、数组指针
- 八、数组参数、指针参数
- 九、函数指针
- 十、函数指针数组
- 十一、指向函数指针数组的指针
- 十二、回调函数
- 十三、指针和数组常见题解析
- 结尾:
一、 指针是什么?
指针理解的2个要点:
- 指针是内存中一个最小单元的编号,也就是地址
- 平时口语中说的指针,通常指的是指针变量,是用来存放内存地址的变量
总结:指针就是地址,口语中说的指针通常指的是指针变量。内存编号=地址=指针
32位虚拟地址空间:CPU——32位地址——地址线传输—>内存
64位虚拟地址空间:CPU——64位地址——地址线传输—>内存
对于32位的机器,假设有32根地址线,那么假设每根地址线在寻址的时候产生高电平(高电压)和低电平(低电压)就是(1或者0)。那么32根地址线产生的地址就有2的32次方个地址。

这里我们就明白:在32位的机器上,地址是32个0或者1组成二进制序列,那地址就得用4个字节的空间来存储,所以一个指针变量的大小就应该是4个字节。
那如果在64位机器上,如果有64个地址线,那一个指针变量的大小是8个字节,才能存放一个地址。
指针变量: 我们可以通过&(取地址操作符)取出变量的内存起始地址,把地址可以存放到一个变量中,这个变量就是指针变量。
#include 
注意: 存放在指针中的值都被当成地址处理。
注意: 一个字节给一个对应的地址。
注意: 指针的大小在32位平台是4个字节,在64位平台是8个字节
二、指针和指针类型
我们都知道,变量有不同的类型,整形,浮点型等。那指针有没有类型呢?
准确的说:有的。
char* 类型的指针是为了存放 char 类型变量的地址。
short* 类型的指针是为了存放 short 类型变量的地址。
int* 类型的指针是为了存放 int 类型变量的地址。
举例:

在64位平台下,指针都是存放地址的,都是64个01的序列,pa pc大小一样那么为什么要区分类型?
其实指针类型有着非常重要的作用:
我们来看一个例子:
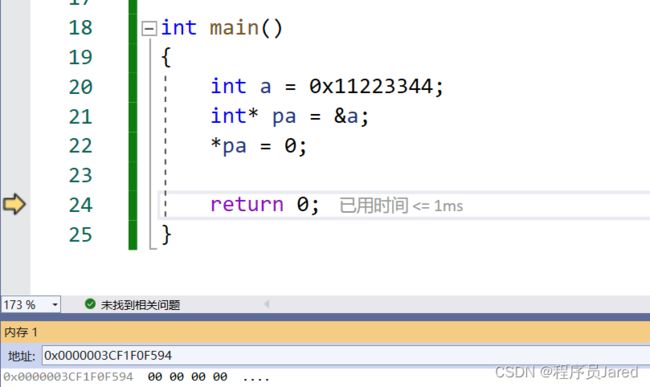
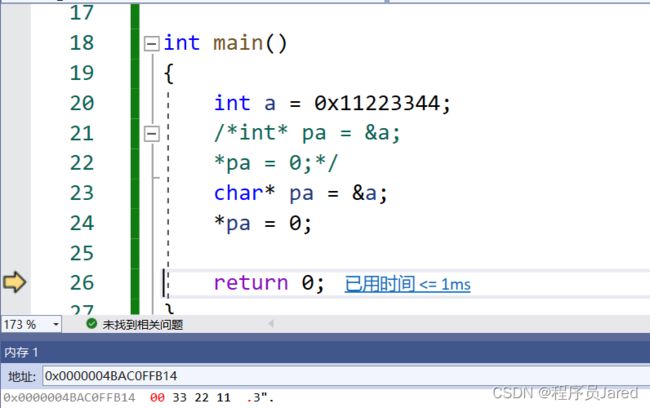
通过对不同类型的指针就行解引用并赋值,可以发现使用int类型的指针进行解引用操作可以改变4个字节大小的内容,而使用char类型时只能改变一个字节大小的内容。
举例:
我们可以发现,整形指针+1跳过一个整形(4个字节)。字符指针+1跳过一个字符(1个字节),所以指针类型决定了,指针向前或者向后走一步,走多大的距离。
整形指针+1跳过一个整形(4个字节),int* +1——>+1sizeof(int)== +4
字符指针+1跳过一个字符(1个字节),char +1——>+1*sizeof(char) ==+1
注意: 指针类型决定了,指针在被解引用的时候,访问的权限。
注意: 整形指针解引用访问了4个字节,字符指针解引用访问了1个字节。
注意: 指针变量的类型决定了看内存的视角。
注意: 整型和浮点数在内存中的存储完全不同,所以int*类型的指针接收float类型的数据后再解引用访问到的数字不可知。
float n = 3.14f;
int* p = &n;
*p;//???
三、野指针
野指针就是指针指向的位置是不可知的(随机的、不正确的、没有明确限制的)
野指针成因:
1.指针未初始化

2. 指针越界访问

3. 指针指向的空间释放
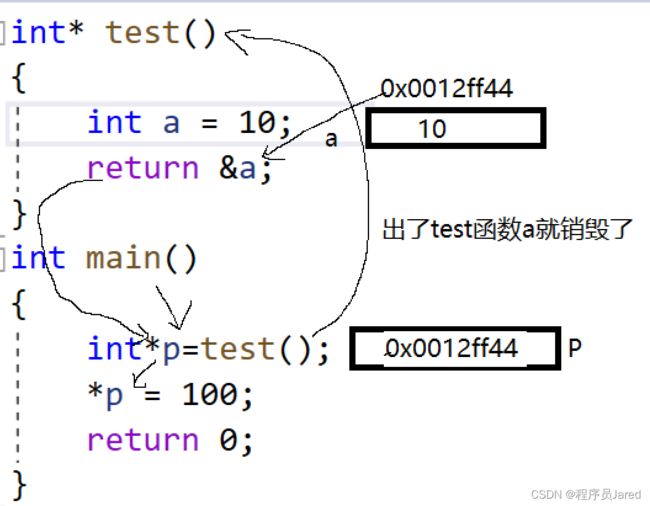
如何规避野指针
4. 指针初始化
野指针相当于野狗,把野狗栓到树上

5. 小心指针越界
6. 指针指向空间释放即使置NULL
7. 避免返回局部变量的地址,如上例
8. 指针使用之前检查有效性(指针不为空才去使用它)
四、指针运算
1.指针± 整数

2.指针-指针
指针-指针的绝对值得到的是指针和指针之间元素的个数
前提:两个指针必须指向同一块空间
#include//模拟实现strlen
int my_strlen(char* s)
{
char* p = s;
while (*p != '\0')//while(*s)
p++;
return p - s;
}
3.指针的关系运算
标准规定:
允许指向数组元素的指针与指向数组最后一个元素后面的那个内存位置的指针比较,但是****不允许与指向第一个元素之前的那个内存位置的指针进行比较。
五、指针和数组
举例:

得到:

可见数组名和数组首元素的地址是一样的。
结论:数组名表示的是数组首元素的地址。(2种情况除外,数组章节讲解了)
//那么这样写代码是可行的
int arr[10] = {1,2,3,4,5,6,7,8,9,0};
int *p = arr;//p存放的是数组首元素的地址
注意: 数组是一块连续的空间
注意: 指针是存放地址的变量,可以通过指针访问数组
注意: p+i 其实计算的是数组 arr 下标为i的地址。我们就可以直接通过指针来访问数组。
int main()
{
int arr[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 0 };
int* p = arr; //指针存放数组首元素的地址
int sz = sizeof(arr) / sizeof(arr[0]);
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", *(p + i));
}
return 0;
}
六、二级指针
指针变量也是变量,是变量就有地址,那指针变量的地址存放在哪里?
这就是二级指针 。

对于二级指针的运算有:*ppa 通过对ppa中的地址进行解引用,这样找到的是 pa , *ppa 其实访问的就是 pa。
可以这么理解,a,pa,ppa都是抽屉,打开a都钥匙放到了pa里面,打开pa的钥匙放到了ppa里面 。通过ppa能打开pa,在通过pa里面的钥匙找到a。
七、指针数组
指针数组是指针还是数组?
答案:是数组。是存放指针的数组。
举例:
int* arr3[5];//arr3是一个数组,有五个元素,每个元素是一个整形指针。
char *arr2[4]; //一级字符指针的数组
char **arr3[5];//二级字符指针的数组
应用:用来模拟实现一个二维数组。
但是不同的是二维数组中的元素在内存中是连续存放的,用指针数组模拟的二维数组,如下data1的5 和data2中的2并不是连续存放的。

注意:
arr[i][j]=*(arr[i]+j)= *(*(arr+i)+j);
八、字符指针
在指针的类型中我们知道有一种指针类型为字符指针 char*
举例:
char ch = 'w';
char* pc = &ch;
*pc = 'w';
字符指针也可以用于存储字符串,但是有一些差异
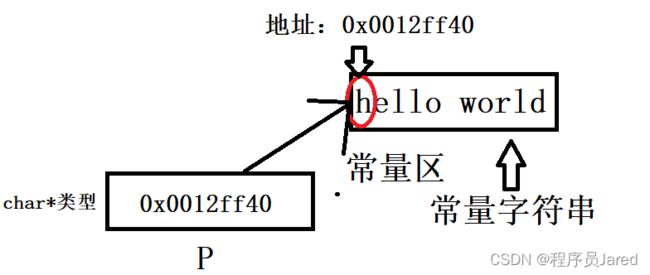
char* pstr = "hello world.";//这里是把一个字符串第一个字母的地址存放到char*类型的指针pstr中
*pstr = 'w';//err
//并且hello world字符串是常量字符串,开辟在常量区,所以我们想更改字符串的内容是不被允许的
具体储存方式如下图:
一道经典题目:
const char* p1 = "abcdef";
const char* p2 = "abcdef";
char arr1[] = "abcdef";
char arr2[] = "abcdef";
if (p1 == p2)
{
printf("p1 == p2\n");
}
else
{
printf("p1 != p2\n");
}
if (arr1 == arr2)
{
printf("arr1 == arr2\n");
}
else
{
printf("arr1 != arr2\n");
}
最终输出的结果为:p1 == p2 arr1 != arr2
主要原因是当执行const char* p1 = “abcdef”;这条语句的时候,会在常量区存放常量字符串(abcdef是常量字符串,存放到常量区),而计算机为了节省内存空间,在常量区不需要在开辟另一块空间去存放该常量字符串,所以 p1 和 p2(p1和p2是局部变量、放在栈区)指向的是同一块区域(a的地址)。数组1和数组2会在栈区开辟不同的空间来存放a的地址,两块空间没有练习,所以arr1 != arr2。
八、数组指针
数组指针的定义:
int a = 10;
int *p = &a;//整型指针 - 指向整型的指针, 存放整型变量地址的
char ch = 'w';
char* pc= &ch;//字符指针 - 指向字符的指针,存放的是字符变量的地址
数组指针 - 指向数组的指针(不是数组首地址),存放的是数组的地址。
int* p1[10]; p1是数组,指针数组
int(*p2)[10]; p2是指针,数组指针
p先和*结合,说明p是一个指针变量,p2指向的是数组,数组里面有十个元素,每个元素的类型是int
注意:
[ ]的优先级要高与* 号,所以必须加上( )来保证p与*号结合。
数组指针是指针
&arr取出的是数组的地址, 存储数组的地址需要 int(*)[x] 数组指针类型,x表示数组中元素的个数。
int arr[10] = {0};
printf("%p\n", arr);//int* 整形指针类型
printf("%p\n", &arr[0]);//int* 整形指针类型
printf("%p\n", &arr);//int(*)[10] 数组指针类型
char* arr[5];
char* (*p)[5]=&arr;
&数组名VS数组名
数组名该怎么理解呢?
通常情况下,我们说的数组名都是数组首元素的地址 但是有2个例外:
- sizeof(数组名),这里的数组名表示整个数组,sizeof(数组名)计算的是整个数组的大小
- &数组名,这里的数组名表示整个数组,&数组名,取出的是整个数组的地址
数组指针的使用
//这不是推荐的写法
void print1(int (*p)[10], int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
//*p 相当于数组名,数组名又是首元素的地址,所以*p就是&arr[0]
printf("%d ", *(*p + i));
}
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
//写一个函数打印arr数组的内容
int sz = sizeof(arr) / sizeof(arr[0]);
print1(&arr, sz);
return 0;
}
p变量里面是&arr , * p 相当于数组名,数组名又是首元素的地址,所以*p就是&arr[0],但是这种写法不常见,不推荐使用。
在一维数组很少使用数组指针,二维数组比较常见,在用的时候也是用指向一维数组的指针。
void print2(int(*p)[5], int c, int r)
{
int i = 0;
for (i = 0; i < c; i++)
{
int j = 0;
for (j = 0; j < r; j++)
{
//p+i是指向第i行的
//*(p+i)相当于拿到了第i行,也相当于第i行的数组名
//数组名表示首元素的地址,*(p+i) 就是第i行第一个元素的地址
printf("%d ", *(*(p + i) + j));
//printf("%d ", p[i][j]);也可以这么写
}
printf("\n");
}
}
int main()
{
int arr[3][5] = { {1,2,3,4,5},{2,3,4,5,6},{3,4,5,6,7} };
//写一个函数,打印arr数组
print2(arr, 3, 5);//arr是首元素的地址,在二维数组中首元素的地址是第一行的地址
return 0;
}
难点突破:
int(* parr[10])[5];
//parr 是一个数组,数组有10个元素,每个元素的类型是:int(*)[5]
//parr是存放数组指针的数组
如图所示:

八、数组参数、指针参数
一维数组传参
形参写成数组的形式:
void test(int arr[10])
{}
void test(int arr[])//形参部分数组的大小可以省略
{}
void test(int arr[100])//不建议,但是没错
{}
void test2(int *arr[20])
{}
void test2(int *arr[])//形参部分数组的大小可以省略
{}
int main()
{
int arr[10] = { 0 };
int* arr2[20] = { 0 };
test(arr);
test2(arr2);
}
形参写成指针的形式:
void test(int *p)
{}
void test2(int **p)
{}
二维数组传参
形参写成数组的形式:
void test(int arr[3][5])
{}
void test(int arr[][5])//行可以省略,但是列不能省略
{}
void test(int arr[100][5])//不建议,但是没错
{}
void test(int arr[][])//err
{}
//总结:二维数组传参,函数形参的设计只能省略第一个[]的数字。
//因为对一个二维数组,可以不知道有多少行,但是必须知道一行多少元素。
int main()
{
int arr[3][5] = { 0 };
test(arr);
}
形参写成指针的形式:
void test(int(*p)[5])//传过来第一行的地址,相当于一维数组的地址,用数组指针接收
{}
一级指针传参
void test(int* p)
{
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9 };
int* p = arr;
//一级指针p,传给函数,用一级指针接收
test(p);
return 0;
}
举例:打印数组中元素
#include 二级指针传参
void test(char** ppc)
{
}
int main()
{
char a = 'w';
char* pa = &a;
char** ppa = &pa;//ppa就是一个二级指针
test(ppa);
return 0;
}
当函数的参数为二级指针的时候,可以接收什么参数呢?
void test(char** ppc)
{
}
int main()
{
char ch = 'a';
char* pc = &ch;
char** ppc = &pc;
char* arr[4];
//以下实参可以传递给形参
test(arr);
test(&pc);
test(ppc);
return 0;
}
二维数组传参
void test1(int (*p)[5])
{
}
void test2(int(*p)[3][5])
{
*p;//代表的是第一行的地址
}
int main()
{
int arr[3][5];
test1(arr);//传递的第一行的地址
test2(&arr);//传递的是整个二维数组的地址
return 0;
}
九、函数指针
函数指针 ——指向函数的指针
int Add(int x, int y)
{
return x + y;
}
int main()
{
printf("%p\n", &Add);//00007FF6463913C0
printf("%p\n", Add);//00007FF6463913C0
int (* pf)(int, int) = Add;//就是函数指针变量
int ret = (*pf)(2,3);//通过pf这个指针解引用,调用函数,()不能省略
int ret = pf(2, 3);//这两种方法都可以,所以这*没有太大的意义
printf("%d\n", ret);
return 0;
}
可以看出&Add, Add都叫拿出函数的地址,虽然写法不同但是意义一样。(与数组不同,要注意区分)
pf就是函数指针变量,看到()说明指向的是函数,函数的参数int,int,返回类型是int。函数指针类型是int (*)(int, int)。
难点突破:
//代码1
( *( void (*)() )0 )();
//代码2
void (* signal(int , void(*)(int)) )(int);
出自《C陷阱和缺陷》
代码1
( *( void (*)() )0 )();
void (*)() 是函数指针类型
( void (*)() ) 强制类型转换
( void (*)() )0 对0进行强制类型的转换,把0强制类型转换为一个函数指针类型
( *( void (*)() )0 )();把函数指针解引用调用这个函数
总结:
1. 首先是把0强制类型转换为一个函数指针类型,这就意味着0地址处放一个返回类型是void,无参的一个函数
2. 调用0地址处的这个函数
代码2
void (* signal(int, void(*)(int)) )(int);//函数声明
signal是一个函数的声明
signal函数的参数,第一个是int类型的,第二个是void(*)(int)的函数指针类型
signal函数的返回值类型也是:void(*)(int)的函数指针
上面声明太复杂了,我们简化一下:
typedef void(* pf_t)(int) ;//给函数指针类型void(*)(int)重新起名叫:pf_t
pf_t signal(int, pf_t);//再进行函数的声明
十、函数指针数组
要把函数的地址存到一个数组中,那这个数组就叫函数指针数组
函数指针的数组定义:
int (*parr[10])();
parr先和 [ ] 结合,说明 parr1是数组,数组的内容是是 int (*)() 类型的函数指针。
用途:函数指针数组的用途:转移表
举例(计算器)
#include 十一、指向函数指针数组的指针
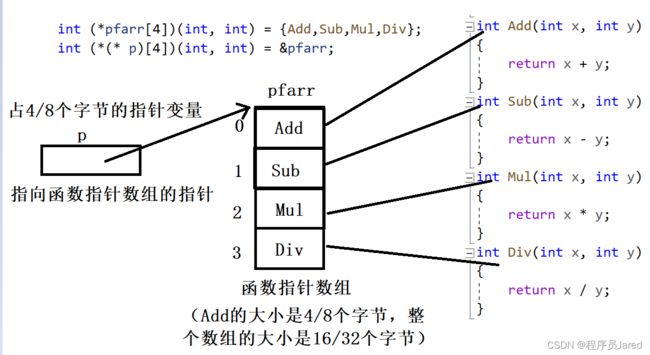
指向函数指针数组的指针是一个指针,指针指向一个数组 ,数组的元素都是函数指针。
int (*pfarr[4])(int, int) = {Add,Sub,Mul,Div};//函数指针数组
int (* (* p)[4])(int, int) = &pfarr;//p3是一个指向函数指针数组的指针
int ret = (*p)[i](3,4);//调用函数
int ret = *(*p+i)(3,4);//也可以这么调用函数
对上段代码的理解,如图所示:
十二、回调函数
回调函数就是一个通过函数指针调用的函数。如果你把函数的指针(地址)作为参数传递给另一个函数,当这个指针被用来调用其所指向的函数时,我们就说这是回调函数。回调函数不是由该函数的实现方直接调用,而是在特定的事件或条件发生时由另外的一方调用的,用于对该事件或条件进行响应。
举例:
void test()
{
printf("hehe\n");
}
void print_hehe( void (*p)() )
{
if (1)
p();
}
int main()
{
print_hehe(test);
return 0;
}
用途举例1:计算器(去掉了代码的冗余)
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
void menu()
{
printf("**************************\n");
printf("**** 1.add 2.sub ****\n");
printf("**** 3.mul 4.div ****\n");
printf("**** 0.exit ****\n");
printf("**************************\n");
}
void calc(int (*pf)(int,int))
{
int x = 0;
int y = 0;
int ret = 0;
printf("请输入2个操作数:>");
scanf("%d%d", &x, &y);
ret = pf(x, y);
printf("ret = %d\n", ret);
}
int main()
{
int input = 0;
do
{
menu();
printf("请选择:>");
scanf("%d", &input);
switch (input)
{
case 1:
calc(Add);
break;
case 2:
calc(Sub);
break;
case 3:
calc(Mul);
break;
case 4:
calc(Div);
break;
case 0:
printf("退出计算器\n");
break;
default:
printf("选择错误\n");
break;
}
} while (input);
return 0;
}
举例2:
使用qsort排序整型:
#includeqsort是一个库函数 基于快速排序算法实现的一个排序的函数,对任意类型的数据都可以排序。
这是qsort的定义:
void qsort( void *base, size_t num, size_t width, int ( *cmp)(const void *e1, const void *e2 ) );
void *base 表示待排序数据的起始位置
size_t num 表示数组的元素个数
size_t width 表示一个元素字节的大小
int ( *cmp)(const void *e1, const void *e2 ) 是函数指针,要求qsort函数的使用者,自定义一个比较函数cmp ,*e1 *e2是待比较的两个元素的地址,返回值为=0,<0, >0三种情况。具体内容可以查询qsort的定义
使用qsort排序结构体:
#include用冒泡排序的思想模拟实现qsort排序
#include十三、指针和数组常见题解析
下面的代码是考察数组和指针的常见问题,通过sizeof和strlen来区分一些常见的C语言名词,同时考察sizeof和strlen的用法与差异。
int main()
{
int a[] = { 1,2,3,4 };
printf("%d\n", sizeof(a));//4*4=16
printf("%d\n", sizeof(a + 0));//4/8,a+0是数组第一个元素的地址,是地址,大小是4/8个字节
printf("%d\n", sizeof(*a));//4,a表示数组首元素的地址,*a表示数组的第一个元素,sizeof(*a)就是第一个元素的大小
printf("%d\n", sizeof(a + 1));//4/8 ,a表示数组首元素的地址,a+1表示数组第二个元素的地址,sizeof(a+1)就是第二个元素的地址的大小
printf("%d\n", sizeof(a[1]));//4,计算的是第二个元素的大小
printf("%d\n", sizeof(&a));//4/8,&a取出的数组的地址,是地址,大小就是4/8字节
printf("%d\n", sizeof(*&a)); //16,&a取出的是整个数组的地址是数组指针,再*就是整个数组,跟第一个一样,整个数组的大小
printf("%d\n", sizeof(&a + 1));//4/8,&a是数组的地址,+1跳过整个数组,产生的是4后面位置的地址
printf("%d\n", sizeof(&a[0]));//4/8,&a[0]取出的是数组第一个元素的地址
printf("%d\n", sizeof(&a[0] + 1));//4/8,数组第二个元素的地址
---------------------------------------------------
char arr[] = { 'a','b','c','d','e','f' };//[a,b,c,d,e,f]
printf("%d\n", sizeof(arr));//6
printf("%d\n", sizeof(arr + 0));//4/8,arr+0是数组首元素的地址
printf("%d\n", sizeof(*arr));//1,*arr 首元素是一个字符 a,大小是一个字节
printf("%d\n", sizeof(arr[1]));//1,arr[1]是数组的第二个元素,大小是一个字节
printf("%d\n", sizeof(&arr));//4/8,&arr是数组的地址,地址就是4/8
printf("%d\n", sizeof(&arr + 1));//4/8,&arr+1是从数组地址开始向后跳过了整个数组而产生整个地址
printf("%d\n", sizeof(&arr[0] + 1));//4/8,&arr[0]+1是数组第二个元素的地址
printf("%d\n", strlen(arr));//随机值,arr数组中没有\0,所以stlen函数会继续向后找\0,统计\0之前出现的字符个数
printf("%d\n", strlen(arr + 0));//随机值,arr+0还是数组首元素的地址
printf("%d\n", strlen(*arr));//err、 arr数数组首元素的地址,*arr就是数组的首元素,'a'-97,传过去97,strlen函数要地址 strlen接收的参数是地址,传过去97会造成非法访问
printf("%d\n", strlen(arr[1]));//err,'b' 98创给stlen也是错误的,会造成非法访问
printf("%d\n", strlen(&arr));//随机值,向后找\0
printf("%d\n", strlen(&arr + 1));//随机值,向后找\0
printf("%d\n", strlen(&arr[0] + 1));//随机值,从b开始找\0
return 0;
}
int main()
{
char arr[] = "abcdef";//a b c d e f \0
printf("%d\n", sizeof(arr));//7,
printf("%d\n", sizeof(arr + 0));//4/8,arr+0是数组首元素的地址
printf("%d\n", sizeof(*arr));//1,*arr是数组的首元素
printf("%d\n", sizeof(arr[1]));//1,arr[1]是数组的第二个元素
printf("%d\n", sizeof(&arr));//4/8,&arr是数组的地址,是地址就是4/8
printf("%d\n", sizeof(&arr + 1));// 4/8,&arr+1是\0后面的地址
printf("%d\n", sizeof(&arr[0] + 1));//4/8,是数组第二个元素的地址
printf("%d\n", strlen(arr)); //6,
printf("%d\n", strlen(arr + 0));//6,arr是数组名是首元素地址,arr+0还是首元素地址
printf("%d\n", strlen(*arr));//err, 非法访问内存
printf("%d\n", strlen(arr[1]));//err, 非法访问内存
printf("%d\n", strlen(&arr));//6,
printf("%d\n", strlen(&arr + 1));//随机值
printf("%d\n", strlen(&arr[0] + 1));//5
//----------------------------------------------------------
char* p = "abcdef";//p存的是a的地址
printf("%d\n", sizeof(p));//4/8,p是指针变量,计算的是指针变量的大小
printf("%d\n", sizeof(p + 1));//4/8,p+1是’b'的地址。计算的是指向b的指针变量的大小
printf("%d\n", sizeof(*p));//1 ,*p就是'a'
printf("%d\n", sizeof(p[0]));//1, p[0]=*(p+0)=*p
printf("%d\n", sizeof(&p));//4/8, &p是指针变量p在内存中的地址,&p是cahr**类型的二级指针
printf("%d\n", sizeof(&p + 1));//4/8,&p+1是跳过p之后的地址
printf("%d\n", sizeof(&p[0] + 1));//4/8,&p[0]是a的地址,&p[0]+1是b的地址
printf("%d\n", strlen(p));//6
printf("%d\n", strlen(p + 1));//5,从b的位置开始向后数字符
printf("%d\n", strlen(*p));//err
printf("%d\n", strlen(p[0]));//err
printf("%d\n", strlen(&p));//随机值
printf("%d\n", strlen(&p + 1));//随机值
printf("%d\n", strlen(&p[0] + 1));//5 从b的位置开始向后数字符
//-------------------------------------------------------------------
int a[3][4] = { 0 };
printf("%d\n", sizeof(a));//3*4*4=48,计算的是整个数组的大小,单位是字节
printf("%d\n", sizeof(a[0][0]));//4,第一行第一个元素的大小
printf("%d\n", sizeof(a[0]));//16,a[0]是第一行的数组名,sizeof(a[0])就是第一行的数组名单独放在sizeof内部,计算的是第一行的大小
printf("%d\n", sizeof(a[0] + 1));//4/8,a[0]作为第一行的数组名,并没有单独放在sizeof内部,也没有取地址,所以a[0]就是首元素的地址,也就是第一个行第一个元素的地址,那么a[0]+1也就是第一行第二个元素的地址
printf("%d\n", sizeof(*(a[0] + 1)));//4,*(a[0] + 1)表示的是第一行第二个元素
printf("%d\n", sizeof(a + 1));//4/8 ,a表示首元素地址,a是二维数组,首元素的地址就是第一行的地址,所以a+1就是第二行的地址
printf("%d\n", sizeof(*(a + 1)));//16,对第二行的地址解引用访问到的就是第二行 *(a + 1)就是a[1]
printf("%d\n", sizeof(&a[0] + 1));//4/8,a[0]是第一行的数组名,&a[0]取出的就是第一行的地址,&a[0] + 1就是第二行的地址
printf("%d\n", sizeof(*(&a[0] + 1)));//16,对第二行的地址解引用访问就是第二行
printf("%d\n", sizeof(*a));//16,a就是首元素的地址,就是第一行的地址,*a就是第一行 *a=*(a+0)=a[0]
printf("%d\n", sizeof(a[3]));//16,类型是int[4],不会去访问空间,sizeof里面不计算,只看大小实际上a[3]是没有的,但是a[3]的类型是int[4]
return 0;
}
代码题:
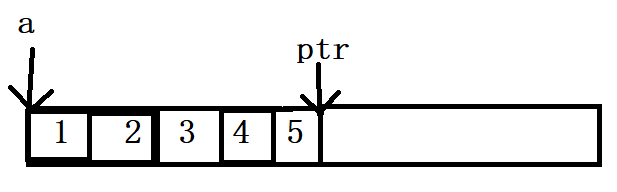
题1:
int main()
{
int a[5] = { 1, 2, 3, 4, 5 };
int* ptr = (int*)(&a + 1);
printf("%d,%d", *(a + 1), *(ptr - 1));
return 0;
}//程序的结果是什么?
&a是数组指针,类型是
int(*)5,&a拿到的是整个数组的地址,&a + 1会跳过整个数组指向后面的内存空间,再将(&a + 1)强制转换为整型指针类型赋值给ptr指针,所以ptr-1向前移动一个整型,指向的是5所在的内存空间,解引用得到5。a是数组名表示首元素的地址,是1的地址,加1跳过一个整形是2的地址,在解引用得到了2。
题2:
#include00100014,结构体指针 +1加的是1*sizeof(这个结构体的大小),这个题,p +0x1就是p+20转换为16进制就是00100014
00100001 ,p被强制转换为unsigned long 是整型类型,整型+1就是+的一个字节
00100004,p被强制转换为unsigned int* 是整型指针类型,整型指针+1在32位条件下就是+4
考察的是指针的类型,指针的类型决定了指针走的步长
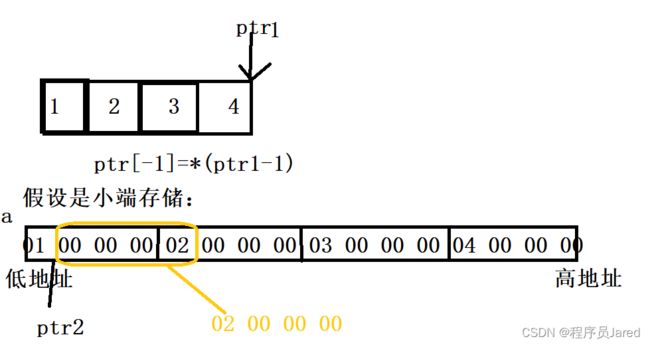
题3:
int main()
{
int a[4] = { 1, 2, 3, 4 };
int* ptr1 = (int*)(&a + 1);
int* ptr2 = (int*)((int)a + 1);
printf("%x,%x", ptr1[-1], *ptr2);
return 0;
}
结果:4 , 2000000
a表示数组首元素的地址,将a强制转换为int类型再+1就是跳过一个字节,所以ptr2指向的是01后面一个字节位置的地址。
题4:
#include 注意 这是一个逗号表达式,比较坑,所以数组的内容第一行为1、3,第二行为5、0,第三行为0、0。 a[0]表示第一行的数组,p[0]就表示第一行第一个元素的地址,所以是1
题5:
int main()
{
int a[5][5];
int(*p)[4];
p = a;
printf("%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
return 0;
}
打印的结果是 FFFFFFFC, -4
指针-指针得到的指针中间元素的个数

题6:
int main()
{
int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int* ptr1 = (int*)(&aa + 1);
int* ptr2 = (int*)(*(aa + 1));
printf("%d,%d", *(ptr1 - 1), *(ptr2 - 1));
return 0;
}
答案是10,5
aa是一个二维数组,第一行是(1,2,3,4,5),第二行是(6,7,8,9,10)
&aa是整个二维数组的地址,+1就会跳过整个二维数组,指向10后面位置的地址。再强制转化为整型指针 ptr1,ptr1 - 1会在ptr的位置向后跳4个字节,一个元素占4个字节,所以*(ptr1 - 1)就找到了元素10。
aa是数组名,在二维数组中是第一行的地址,aa + 1是第二行的地址,(aa + 1)对第二行的地址进行解引用相当于拿到了第二行的数组名,表示第二行的第一个元素(6)地址,ptr2指向6,ptr2 - 1向前挪一个整型所以(ptr2 - 1)拿到元素5。
题7:
#include 具体逻辑关系如下图所示:

pa++就会让pa指向数组a中下标为1的地址,对pa解引用就得到数组a中下标为1存放的内容,存放的是at中的a的地址,所以以字符串形式打印就会得到at。
题8:
int main()
{
char* c[] = { "ENTER","NEW","POINT","FIRST" };
char** cp[] = { c + 3,c + 2,c + 1,c };
char*** cpp = cp;
printf("%s\n", **++cpp);
printf("%s\n", *-- * ++cpp + 3);
printf("%s\n", *cpp[-2] + 3);
printf("%s\n", cpp[-1][-1] + 1);
return 0;
}
结果是
POINT
ER
ST
EW
对于题干的解析如图所示:

1、 ++cpp会让cpp的位置发生变化,此时cpp指向的是c+2的起始地址。对cpp解引用会让cpp找到c+2存放的内容,在解引用会得到p的地址,以%s的形式打印会得到POINT。
2、 ++的优先级比+的优先级高,先算++,此时cpp指向c+1的起始地址,*的优先级更比+高,所以先对cpp解引用得到c+1,再 – 就是就是对c+1里面的值进行减1,变为了c,相当于存放c+1的空间变为存放c。再解引用得到E的地址,再+3得到E的地址,以字符串的形式打印为ER。
3、*cpp[-2] + 3 在编译器中相当于**(cpp-2)+3。刚开始cpp指向的是c+1的起始地址,cpp-2指向的是c+3的起始地址,对它两次解引用得到的是F的地址,再加3得到的S的地址,以字符串打印是ST。
4、cpp[-1][-1]在编译器中相当于*((*cpp-1)-1))+1,刚开始cpp指向的是c+1的起始地址,cpp-1指向的是c+2的起始地址,解引用找到了c+2,再减一,相当于把c+2变为了c+1,在解引用得到了N的地址,再+1找到了E的地址,以字符串打印是EW。
结尾:
指针是一把双刃剑,用得好所向披靡,如果用的不好,则会让你的程序出现各种各样的问题,最终导致程序崩溃。
以上就是我对于指针的了解,希望对于刚读完此博客的你有所帮助。