特征工程之数据预处理
目录
1 简介
2 非数值类型数据处理
2.1 Get_dummies哑变量处理
2.2 Label Encoding编号处理
补充知识点:pandas库中的replace()函数
3 重复值、缺失值及异常值处理
3.1 重复值处理
3.2 缺失值处理
3.3 异常值处理
4 数据标准化
4.1 min-max标准化
4.2 Z-score标准化
5 数据分箱
6 特征筛选:WOE值与IV值
6.1 WOE值的定义与计算
6.2 IV值的定义与计算
补充知识点:使用IV值而不直接使用WOE值的原因
6.3 WOE值与IV值的代码实现
6.3.1 数据分箱
6.3.2 统计各个分箱的样本总数、坏样本数和好样本数
6.3.3 统计各分箱的坏样本比率和好样本比率
6.3.4 计算WOE值
6.3.5 计算IV值
6.4 案例:客户流失预警模型的IV值计算
7 多重共线性的分析与处理
7.1 多重共线性的定义
7.2 多重共线性的分析与检验
8 过采样和欠采样
8.1 过采样
8.1.1 过采样的原理
8.1.2 过采样的代码实现
8.2 欠采样
8.2.1 欠采样的原理
8.2.2 欠采样的代码实现
参考书籍
1 简介
在实际工作中获取到的数据往往不那么理想,可能会存在非数值类型的文本数据、重复值、缺失值、异常值及数据分布不均衡等问题,因此,在进行数学建模前还需要对这些问题进行处理,这项工作称为特征工程。
特征工程通常分为特征使用方案、特征获取方案、特征处理、特征监控几大部分,其中特征处理是特征工程的核心内容,有时称为数据预处理。
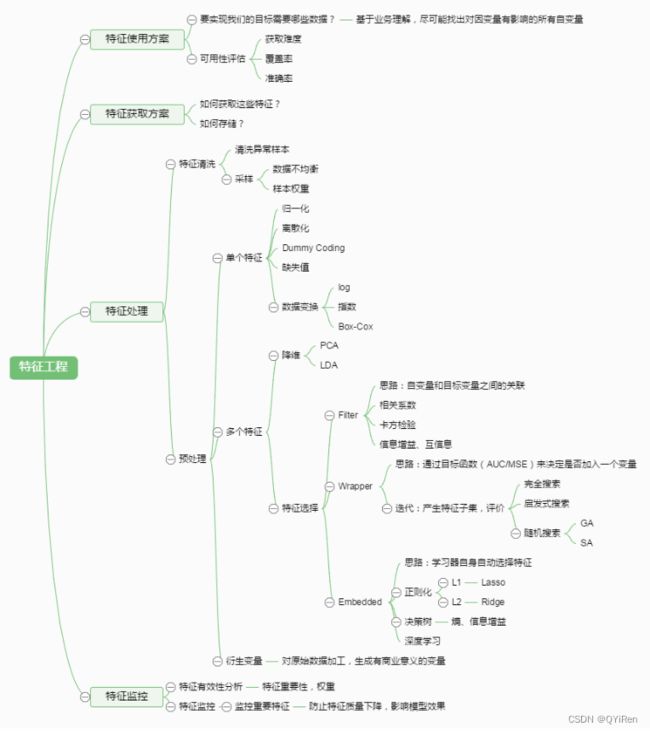
2 非数值类型数据处理
机器学习建模时处理的都是数值类型的数据,然而实际工作中获取的数据往往会包含非数值类型的数据,其中最常见的就是文本类型的数据,例如,性别中的“男”和“女”,处理时可以用查找、替换的思路,分别转换为数字1和0。但如果类别有很多,又该如何处理呢?
介绍Python中两种常用的非数值类型数据处理方法——Get_dummies哑变量处理和Label Encoding编号处理。
2.1 Get_dummies哑变量处理
哑变量也叫虚拟变量,通常取值为0或1,上面提到的将性别中的“男”和“女”分别转换成数字1和0就是哑变量最经典的应用。
在Python中,通常利用pandas库中的get_dummies()函数进行哑变量处理,它不仅可以处理“男”和“女”这种只有两个分类的简单问题,还可以处理含有多个分类的问题。
下面通过两个示例演示get_dummies()函数的基本用法。
1.简单的示例:“男”和“女”的数值转换
初始数据如下所示:

接着用get_dummies()函数对文本类型的数据进行处理:
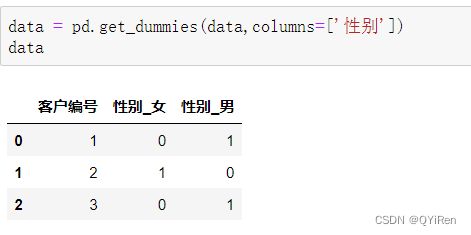
获得的新数据的内容见上表。可以看到,原来的“性别”列变为“性别_女”和“性别_男”两列,这两列中的数字1表示符合列名,数字0表示不符合列名。
单独看“性别_女”这一列就是:数字0代表男,数字1代表女。
单独看“性别_男”这一列就是:数字0代表女,数字1代表男。
所以之后需要的操作就是删除其中一列并重命名另一列:

2.稍复杂的示例:房屋朝向的数值转换
房屋朝向的数值转换。先通过如下代码构造演示数据。

用get_dummies()函数构造哑变量,代码如下。
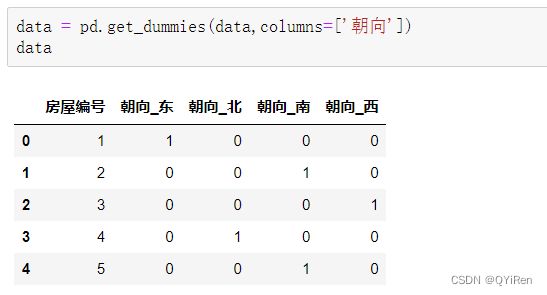
同样存在多重共线性(即根据3个朝向的数字就能判断第4个朝向的数字是0还是1),因此需要从新构造出来的4个哑变量中删去1个,假设删去“朝向_西”列,代码如下。

这样便通过哑变量处理将分类变量转化为数值变量,为后续构建模型打好了基础。构造哑变量容易产生高维数据,因此,哑变量常和PCA(主成分分析)一起使用,即构造哑变量产生高维数据后采用PCA进行降维。
2.2 Label Encoding编号处理
除了使用get_dummies()函数进行非数值类型数据处理外,还可以使用LabelEncoding进行编号处理,具体来说,是使用LabelEncoder()函数将文本类型的数据转换成数字。
示例:
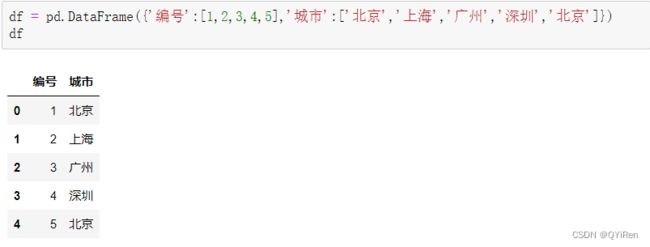
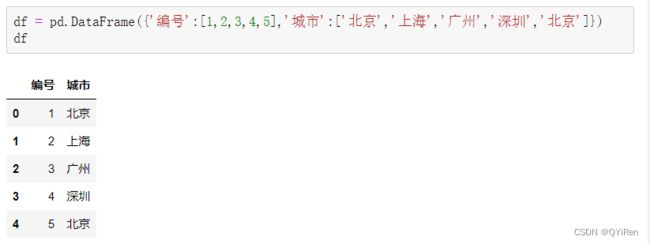
通过如下代码即可将“城市”列的文本内容转换为不同的数字。

可以看到,“北京”被转换成数字1,“上海”被转换成数字0,“广州”被转换成数字2,“深圳”被转换成数字3。
通过如下代码可以用转换结果替换原来的列内容。
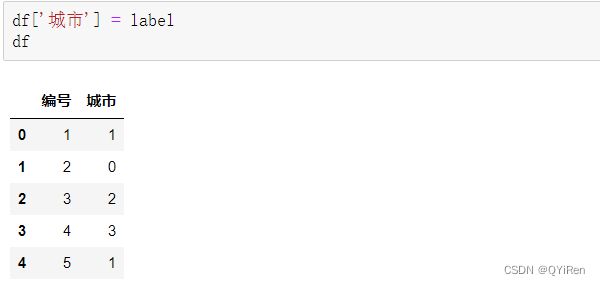
上述示例中使用Label Encoding处理后产生了一个奇怪的现象:上海和广州的平均值是北京,这个现象其实是没有现实意义的,这也是Label Encoding的一个缺点——可能会产生一些没有意义的关系。不过树模型(如决策树、随机森林及XGBoost等集成算法)能很好地处理这种转化,因此对于树模型来说,这种奇怪的现象是不会影响结果的。
补充知识点:pandas库中的replace()函数
LabelEncoder()函数生成的数字是随机的,如果想按特定内容进行替换,可以使用replace()函数。这两种处理方式对于建模效果不会有太大影响。
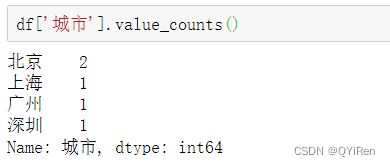
在使用replace()函数之前,先利用value_counts()函数查看“城市”列有哪些内容需要替换(因为有时数据量很大,通过人眼判断可能会遗漏某些内容),代码如下。
用replace()函数按“北上广深”的顺序进行数字编号,代码如下。
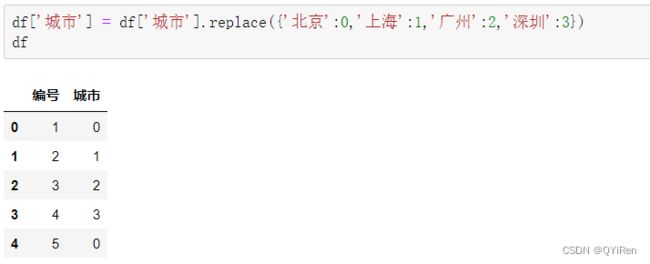
可以看到,LabelEncoder()函数是对文本内容进行随机编号,而用replace()函数可将文本内容替换成自定义的值。不过当分类较多时,还需要先用value_counts()函数获取每个分类的名称,步骤会稍微烦琐一些。
总结:
总结来说,Get_dummies的优点是它的值只有0和1,缺点是当类别的数量很多时,特征维度会很高,此时可以配合使用PCA(主成分分析)来减少维度。如果类别数量不多,可以优先考虑使用Get_dummies,其次考虑使用Label Encoding或replace()函数;但如果是基于树模型的机器学习模型,用LabelEncoding也没有太大关系。
3 重复值、缺失值及异常值处理
3.1 重复值处理
初始数据:
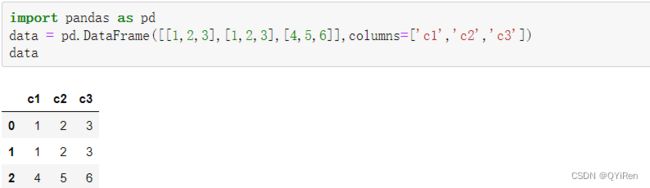
重复值相关操作:

删除重复行,注意,drop_duplicates()函数并不改变原表格结构,所以需要进行重新赋值,或者在其中设置inplace参数为True。
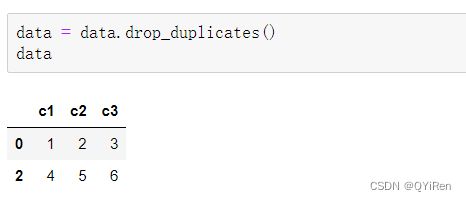
3.2 缺失值处理
初始数据:

用isnull()函数或isna()函数(两者作用类似)来查看空值,代码如下。

对单列查看空值,代码如下。

如果数据量较大,可以通过如下代码筛选出某列中内容为空值的行。

对于空值有两种常见的处理方式:删除空值和填补空值。
用dropna()函数可以删除空值,代码如下。
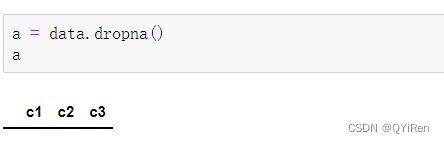
这种删除方法是只要含有空值的行都会被删除。运行结果如下,可以看到,因为每行都有空值,所以都被删除了。
可以设置thresh参数,例如将其设置为n,表示如果一行中的非空值少于n个则删除该行,演示代码如下。

该代码的含义是:如果一行中的非空值少于2个则删除该行。构造的演示数据中,第1行和第3行都有2个非空值,因此不会被删除,而第2行只有1个非空值,少于2个,因此会被删除。
用fillna()函数可以填补空值,演示代码如下。这里采用的是均值填补法,用每列的均值对该列的空值进行替换,也可以把其中的data.mean()换成data.median(),变为中位数填补。

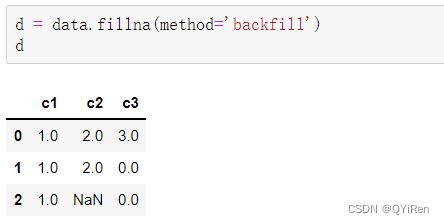
空值填补还可以采取用空值上方或下方的值替换空值的方式,演示代码如下。
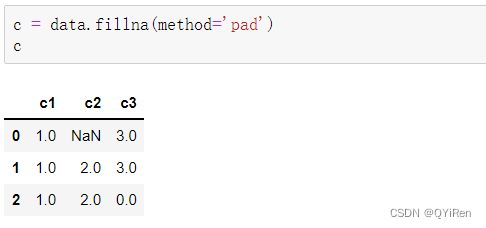
此处的method='pad'表示用空值上方的值来替换空值,如果上方的值不存在或也为空值,则不替换。
还可以设置method='backfill'或method='bfill'(两者效果一样),表示用空值下方的值来替换空值,如果下方的值不存在或也为空值,则不替换,代码如下。
3.3 异常值处理
初始数据:

可以看到,第1列的数字69、第2列的数字100、第3列的数字120为比较明显的异常值,那么该如何利用Python检测异常值呢?
介绍两种检测方法——利用箱体图观察和利用标准差检测。
1.利用箱体图观察
箱体图是一种用于显示一组数据分散情况资料的统计图,可以通过设定标准,将大于或小于箱体图上下界的数值识别为异常值。
如下图所示,将数据的下四分位数记为Q1,即样本中仅有25%的数据小于Q1;将数据的上四分位数记为Q3,即样本中仅有25%的数据大于Q3;将上四分位数和下四分位数的差值记为IQR,即IQR=Q3-Q1;令箱体图上界为Q3+1.5×IQR,下界为Q1-1.5×IQR。

在Python中可以用DataFrame的boxplot()函数绘制箱体图,代码如下。

可以明显看到每列数据各有一个异常值。
2.利用标准差检测
当数据服从标准正态分布时,99%的数值与均值的距离应该在3个标准差之内,95%的数值与均值的距离应该在2个标准差之内,如下图所示。因为3个标准差过于严格,此处将阈值设定为2个标准差,即认为当数值与均值的距离超出2个标准差,则可以认为它是异常值。

根据标准差检测异常值的代码如下。

第1行代码建立一个空DataFrame;
第2行代码通过for循环依次对数据的每列进行操作;
第3行代码用mean()函数(获取均值)和std()函数(获取标准差)将每列数据进行Z-score标准化;
第4行代码进行逻辑判断,如果Z-score标准化后的数值大于标准正态分布的标准差1的2倍,那么该数值为异常值,返回布尔值True,否则返回布尔值False。
Z-score标准化公式如下。

检测到异常值后,如果异常值较少或影响不大,也可以不处理。如果需要处理,可以采用如下几种常见的方式:
·删除含有异常值的记录;
·将异常值视为缺失值;
·利用第5节讲解的数据分箱方法进行处理。
4 数据标准化
数据标准化(也称为数据归一化),它的主要目的是消除不同特征变量量纲级别相差太大造成的不利影响。
对于以特征距离为算法基础的机器学习算法(如K近邻算法),数据标准化尤为重要。
4.1 min-max标准化
min-max标准化(Min-Max Normalization)也称离差标准化,它利用原始数据的最大值和最小值把原始数据转换到[0,1]区间内,转换公式如下。
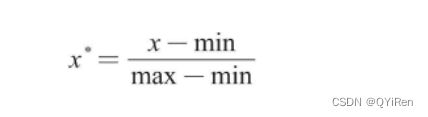
其中x、x*分别为转换前和转换后的值,max、min分别为原始数据的最大值和最小值。
例如,一个样本集中最大值为100,最小值为40,若此时x为50,则min-max标准化后的值如下。
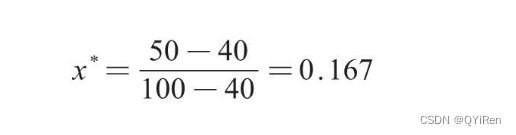
代码演示:

其中第1列为“酒精含量”标准化后的值,第2列为“苹果酸含量”标准化后的值,可以看到它们都在[0,1]区间内。
在实际应用中,通常将所有数据都标准化后,再进行训练集和测试集划分。
4.2 Z-score标准化
Z-score标准化(Mean Normaliztion)也称均值归一化,通过原始数据的均值(mean)和标准差(standard deviation)对数据进行标准化。标准化后的数据符合标准正态分布,即均值为0,标准差为1。转换公式如下。
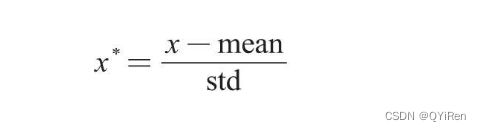
其中x和x*分别为转换前和转换后的值,mean为原始数据的均值,std为原始数据的标准差。
代码演示:

其中第1列为“酒精含量”标准化后的值,第2列为“苹果酸含量”标准化后的值,此时它们是均值为0、标准差为1的标准正态分布。
总结来说,数据标准化并不复杂,两三行代码就能避免很多问题,因此,对一些量纲相差较大的特征变量,实战中通常会先进行数据标准化,再进行训练集和测试集划分。
除了K近邻算法模型,还有一些模型也是基于距离的,所以量纲对模型影响较大,就需要进行数据标准化,如支持向量机模型、KMeans聚类分析、PCA(主成分分析)等。此外,对于一些线性模型,如线性回归模型和逻辑回归模型,有时也需要进行数据标准化处理。
对于树模型则无须做数据标准化处理,因为数值缩放不影响分裂点位置,对树模型的结构不造成影响。因此,决策树模型及基于决策树模型的随机森林模型、AdaBoost模型、GBDT模型、XGBoost模型、LightGBM模型通常都不需要进行数据标准化处理,因为它们不关心变量的值,而是关心变量的分布和变量之间的条件概率。
在实际工作中,如果不确定是否要做数据标准化,可以先尝试做一做数据标准化,看看模型预测准确度是否有提升,如果提升较明显,则推荐进行数据标准化。
5 数据分箱
数据分箱就是将一个连续型变量离散化,可分为等宽分箱和等深分箱。
等宽分箱是指每个分箱的差值相等,以“年龄”这一连续型特征变量为例,其取值范围为0~100的连续数值,可以将“年龄”分为0~20、20~40、40~60、60~80、80~100共5个分箱,这5个分箱就可以当成离散的分类变量,每个分箱的年龄差相等(都相差20岁)。
等深分箱是指每个分箱中的样本数一致,同样按“年龄”这一特征变量进行分箱,例如,500个样本分成5箱,那么每个分箱中都是100人,此时对应的5个分箱可能就是0~20、20~25、25~30、30~50、50~100,确保每个分箱中的人数一致。
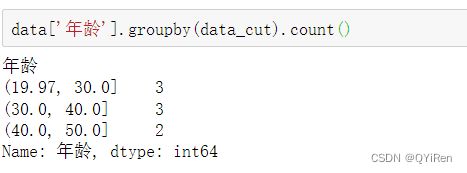
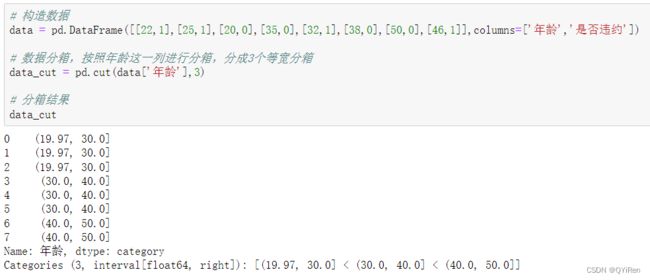
等宽分箱,使用pandas中的cut函数:

“年龄”列中数据的范围是20~50岁,分为3组恰好为20~30岁(19.97近似为20)、30~40岁、40~50岁,可以看到,每个分箱的年龄差都是10岁,这就是等宽分箱。
用groupby()函数进行分组,用count()函数进行计数,可以获取每个分箱中的样本数,代码如下。
对特征变量年龄进行离散化可以使建立的模型更稳定,例如,将20~30岁作为一个类别,如果客户从25岁增长为26岁,也不会因此成为完全不同类别的人。但是,年龄位于类别区间边界点的客户则会因为增长1岁而被分到另一个类别,因此,在分箱时要谨慎选取类别间的界限。
数据分箱还有一个好处就是可以剔除异常值的影响,也是异常值处理的一个手段。
6 特征筛选:WOE值与IV值
在使用逻辑回归、决策树等模型算法构建分类模型时,经常需要对特征变量进行筛选。因为有时可能会获得100多个候选特征变量,通常不会直接把这些特征变量放到模型中去进行拟合训练,而是从这些特征变量中挑选一些放进模型,构成入模变量列表。那么该如何挑选入模变量呢?
挑选入模变量需要考虑很多因素,如变量的预测能力、简单性(容易生成和使用)、可解释性等。其中最主要的衡量标准是变量的预测能力,对分类模型来说,即希望变量具有较好的特征区分度,可以较准确地将样本进行分类。
WOE值和IV值就是这样的指标,它们可以用来衡量特征变量的预测能力,或者说特征变量的特征区分度,类似的指标还有基尼系数和信息增益。对于决策树等树模型来说,可以通过基尼系数或信息增益来衡量变量的特征区分度,而对于逻辑回归等没有基尼系数等指标的模型而言,可以通过WOE值和IV值进行变量选择。
IV值的计算是以WOE值为基础的,而要计算一个变量的WOE值,需要先用上一节所讲的知识对这个变量进行分箱处理。
6.1 WOE值的定义与计算
WOE是Weight of Evidence(证据权重)的缩写,其反映了某一变量的特征区分度。
要计算一个变量的WOE值,需要先对这个变量进行分箱处理。
分箱后,第i个分箱内数据的WOE值的计算公式如下。
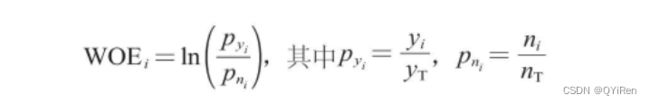
以客户违约预测模型(预测客户是否会违约)为例来解释各个变量的含义:
是第i个分箱中违约客户(即模型中目标变量“是否违约”取值为1的个体)占整个样本中所有违约客户的比例;
是第i个分箱中未违约客户(即模型中目标变量“是否违约”取值为0的个体)占整个样本中所有未违约客户的比例;
yi是第i个分箱中违约客户的数量;
yT是整个样本中所有违约客户的数量;
ni是第i个分箱中未违约客户的数量;
nT是整个样本中所有未违约客户的数量。
假设整个样本中共有10个违约客户(yT)、10个未违约客户(nT),然后根据特征变量“年龄”将整个样本分成4个分箱,其中第1个分箱里有2个违约客户、2个未违约客户,因此,
=2/10=0.2,
=2/10=0.2,那么该分箱的WOE值为ln(0.2/0.2)=ln(1)=0。
还可以对公式进行变换,得到如下公式。
变换以后,WOE值也可以理解为:分箱后第i个分箱中违约客户和未违约客户的比值与整个样本中该比值的差异。其中整个样本的违约客户和未违约客户的比值yT/nT是一个固定值,所以WOE值反映的就是分箱后第i个分箱中违约客户和未违约客户的比值yi/ni,这其实就反映了特征区分度。

将下表中的“年龄”这一特征变量分成3个分箱后,每个分箱的WOE值的绝对值都很大,那么说明“年龄”这一特征变量的特征区分度很高,能很好地区分违约与未违约客户,因此这类问题应该重点考虑“年龄”这一特征变量。

实际应用中,因为数据量通常较大,所以不太可能出现WOE值为+∞或-∞的情况,如果出现了无穷大的WOE值,也是不希望看到的,这样会导致基于WOE值的IV值也变成无穷大,不利于进行特征筛选。此时的处理方法有两种:第一种方法是对数据重新进行更合理的分箱,使各个分箱的WOE值不再无穷大;第二种方法是忽略这些无穷大的值,直接让它变为0。
6.2 IV值的定义与计算
IV是Information Value(信息量)的缩写。
在进行特征筛选时,IV值能较好地反映特征变量的预测能力,特征变量对预测结果的贡献越大,其价值就越大,对应的IV值就越大,因此,可根据IV值的大小筛选出需要的特征变量。
计算一个特征变量的IV值前,需要先计算该变量各个分箱的IV值,计算公式如下。
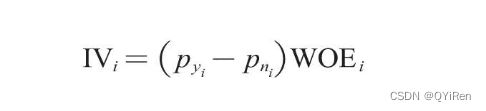
对各个分箱的IV值进行简单求和,就得到这个特征变量的IV值,计算公式如下。

其中i为分箱号,n为分箱的总数。
仍然使用上一小节的演示数据。先根据上一小节的计算结果计算各个分箱的IV值,计算过程如下。
有了各个分箱的IV值,就可以计算出“年龄”这一特征变量的IV值,计算过程如下。
汇总所有数据,可以得到下表。

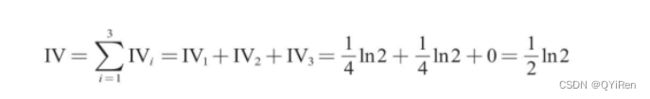

通过这种方式对样本数据的每个特征变量进行IV值计算并排序后,就可以获得特征变量的决策能力强弱信息。
补充知识点:使用IV值而不直接使用WOE值的原因
可能会有疑问:既然已经有了WOE值,为什么还要创造一个IV值呢?主要原因有两方面。
原因1:人们习惯用一个大于等于0的数值去衡量预测能力,而WOE值是有可能为负值的。
在计算IV值时通过乘以![]() ,保证了IV值一定大于0。
,保证了IV值一定大于0。
而分组的WOE值恰好为0时,![]() 取值也为0,这样就保证了IV值永远非负。
取值也为0,这样就保证了IV值永远非负。
原因2:如果是因为数值正负的问题,那么为什么不可以将各个分箱的WOE值的绝对值相加,作为该特征变量的整体WOE值来衡量预测能力呢?这是因为以 作为权重因子可以体现分箱的数据量占整体的比例,更精确地体现变量的预测能力。
作为权重因子可以体现分箱的数据量占整体的比例,更精确地体现变量的预测能力。
对原因2进一步解释:

从上表可以看出,第1个分箱的WOE值很低,第2个分箱的WOE值很高,如果将这2个WOE值的绝对值相加,整体的WOE值为4.4,仍然很高,这主要是由第2个分箱的WOE值很高导致的。但是需要注意的是,第2个分箱的总人数才10人,占10000个总样本的比例只有0.1%,可见样本数据落在第2个分箱的概率本身就比较低,所以对于整体样本来说,变量的预测能力并没有那么强。
而在WOE值的前面乘上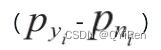 后,其对应的IV值变得很低,相当于乘上了一个权重系数,即考虑了分箱的数据量占整体的比例,因此,IV值很好地体现了分箱比例的影响。
后,其对应的IV值变得很低,相当于乘上了一个权重系数,即考虑了分箱的数据量占整体的比例,因此,IV值很好地体现了分箱比例的影响。
一个特征变量的IV值越高,说明该特征变量越具有区分度。不过IV值也不是越大越好,如果一个特征变量的IV值大于0.5,有时需要对这个特征变量持有疑问,因为它有点过好而显得不够真实。通常会选择IV值在0.1~0.5这个范围内的特征变量。不同应用场景的取值也会有所不同,例如,有些风控团队会将IV值大于0.5的特征变量也纳入考量,这个其实也需要根据实际的建模效果来做进一步判断。
6.3 WOE值与IV值的代码实现
6.3.1 数据分箱
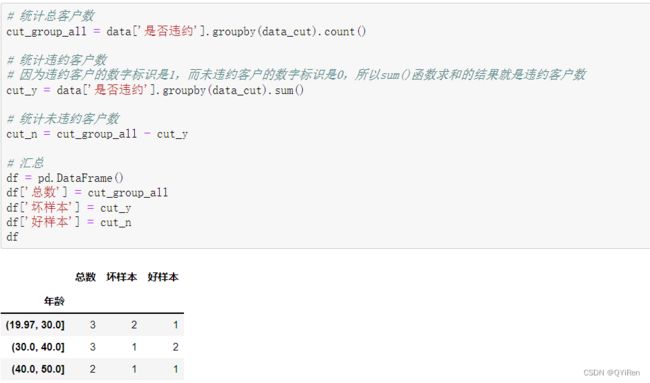
6.3.2 统计各个分箱的样本总数、坏样本数和好样本数
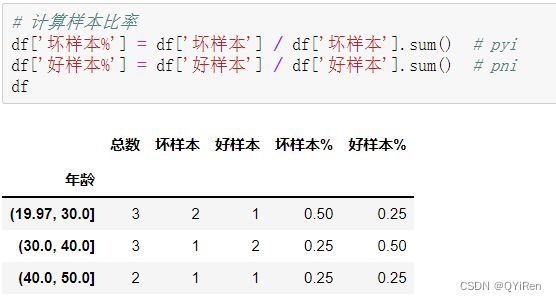
6.3.3 统计各分箱的坏样本比率和好样本比率
6.3.4 计算WOE值
利用上述公式计算。

6.3.5 计算IV值
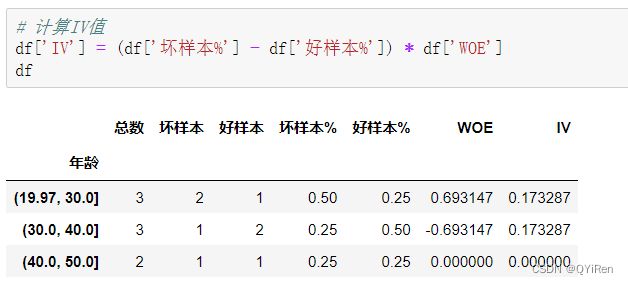
对各个分箱的IV值进行求和,得到这一特征变量的IV值:
在实际应用中,通过类似上面的代码计算出各个特征变量的IV值,然后根据IV值从高到低排序,即可筛选出需要的特征变量。
6.4 案例:客户流失预警模型的IV值计算
为了提高代码的通用性,这里将上一节的代码稍加修改,写成如下的自定义函数形式。该函数共有4个参数:data(原始数据集)、cut_num(数据分箱步骤中分箱的个数)、feature(需要计算IV值的特征变量名称)、target(目标变量名称)。有了这个函数,就能方便地对任意一个数据集计算各个特征变量的IV值。
import numpy as np
import pandas as pd
def cal_iv(data,cut_num,feature,target):
# 1.数据分箱
data_cut = pd.cut(data[feature],cut_num)
# 2.统计各个分箱的总样本数,坏样本数,好样本数
cut_group_all = data[target].groupby(data_cut).count()
cut_y = data[target].groupby(data_cut).sum()
cut_n = cut_group_all - cut_y
df = pd.DataFrame()
df['总数'] = cut_group_all
df['坏样本'] = cut_y
df['好样本'] = cut_n
# 3.统计样本比率
df['坏样本%'] = df['坏样本'] / df['坏样本'].sum() # pyi
df['好样本%'] = df['好样本'] / df['好样本'].sum() # pni
# 4.计算WOE值
df['WOE'] = np.log(df['坏样本%'] / df['好样本%'])
df = df.replace({'WOE':{np.inf:0,-np.inf:0}})
# 5.计算各个分箱的IV值
df['IV'] = (df['坏样本%'] - df['好样本%']) * df['WOE']
# 6.计算总IV值
iv = df['IV'].sum()
print(iv) 通过如下代码读取客户流失预警模型的相关数据。
此时的data如下图所示,“是否流失”列为目标变量,其余列为特征变量。为了简化问题,这里删除了“累计交易佣金(元)”列。

通过for循环可以快速计算出所有特征变量的IV值,代码如下。

将上述IV值从高到低排序,结果为:本券商使用时长(年)>上月交易佣金(元)>最后一次交易距今时间(天)>账户资金(元)。可得出结论:“本券商使用时长(年)”的信息量最大,而“账户资金(元)”的信息量最小,预测能力最低。这其实也是搭建逻辑回归模型时判断特征重要性的一个方式。
7 多重共线性的分析与处理
7.1 多重共线性的定义
对多元线性回归模型Y=k0+k1X1+k2X2+…+knXn而言,如果特征变量X1、X2、X3…之间存在高度线性相关关系,则称为多重共线性(multicollinearity)。例如,X1=1-X2(如:性别_男=1-性别_女),此时X1与X2存在高度的线性相关关系,则认为该模型存在多重共线性,需要删去X1和X2中的一个变量。
上面是用2个特征变量举例,如果是多个特征变量,则多重共线性可以表示成如下公式。a1X1+a2X2+…+anXn=0
如果存在ai不全为0,即某个特征变量可以用其他特征变量的线性组合表示,则称特征变量间存在完全共线性。一个极端的例子是让所有ai都为1,则X1=-(X2+X3+…+Xn),此时便认为特征变量间存在完全共线性。
除了完全共线性,还存在近似共线性,它也是多重共线性的一种情况,其公式如下。a1X1+a2X2+…+anXn+v=0。如果存在ai不全为0,v为误差随机项,则称特征变量间存在近似共线性。一个极端的例子是让所有ai都为1,v为-1,那么X1=1-(X2+X3+…+Xn),此时便认为特征变量间存在近似共线性,如果n为2,那么就是之前提到的X1=1-X2。
总体来说,在实际应用中,多重共线性会带来如下不利影响:
·线性回归估计式变得不确定或不精确;
·线性回归估计式方差变得很大,标准误差增大;
·当多重共线性严重时,甚至可能使估计的回归系数符号相反,得出错误的结论;
·削弱特征变量的特征重要性。
7.2 多重共线性的分析与检验
加载数据:

仔细观察可以发现,X2列中绝大部分数据是X1列中数据的2倍。
对数据集划分特征变量和目标变量,代码如下。
其中Y列为目标变量(即因变量),X1、X2、X3列为特征变量(即自变量)。
下面来分析与检验特征变量X1、X2、X3间是否存在多重共线性。
这里主要讲解两种判别方法——相关系数判断和方差膨胀系数法(VIF检验)。
1.相关系数判断
多重共线性是指不同特征变量间存在线性相关关系,在Python中用corr()函数(皮尔逊相关系数)可以快速计算不同变量间的相关系数,代码如下。
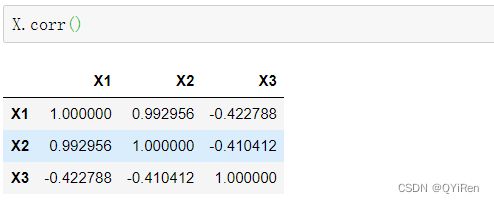
其中第i行第j列的内容表示第i个特征变量和第j个特征变量的相关系数。
例如,第1行第2列的相关系数0.99,表示的就是特征变量X1和特征变量X2的相关系数,可以看到它们的相关性还是非常强的,有理由相信它们会导致多重共线性,因此需要删去其中一个特征变量。需要说明的是,从左上角至右下角的对角线上的相关系数都为1,这个1其实没有什么意义,因为它表示的是特征变量自身与自身的相关系数,那自然是1了。
相关系数判断使用起来非常简单,结论也比较清晰,不过它有一个缺点:简单相关系数只是多重共线性的充分条件,不是必要条件。在有多个特征变量时,相关系数较小的特征变量间也可能存在较严重的多重共线性。
为了更加严谨,实战中还经常用到下面要讲解的方差膨胀系数法(VIF检验)。
2.方差膨胀系数法(VIF检验)
方差膨胀系数(Variance Inflation Factor)的计算公式如下。
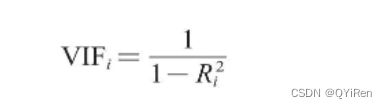
VIFi是衡量自变量Xi是否与其他自变量具有多重共线性的方差膨胀系数;
![]() 是将自变量Xi作为因变量,其他自变量作为特征变量时回归的可决系数,即R-squared值,它是用来衡量拟合程度的。
是将自变量Xi作为因变量,其他自变量作为特征变量时回归的可决系数,即R-squared值,它是用来衡量拟合程度的。
![]() 越大,VIFi就越大,表示自变量Xi与其他自变量间的多重共线性越严重。一般认为VIFi<10时,该自变量与其余自变量之间不存在多重共线性;当10≤VIFi<100时存在较强的多重共线性;当VIFi≥100时存在严重的多重共线性。
越大,VIFi就越大,表示自变量Xi与其他自变量间的多重共线性越严重。一般认为VIFi<10时,该自变量与其余自变量之间不存在多重共线性;当10≤VIFi<100时存在较强的多重共线性;当VIFi≥100时存在严重的多重共线性。
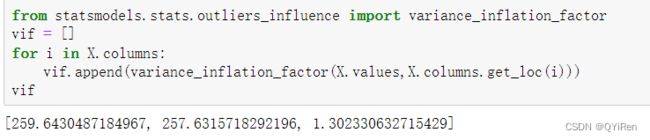
因为特征变量X2是X1的2倍,所以使用X1对X2和X3回归和使用X2对X1和X3回归时所得的方差膨胀系数会很大,从上述计算结果也可以看出,前2个VIF值均大于100,暗示多重共线性十分严重,应该删掉X1或X2。
下面删掉X2再进行一次回归和VIF检验,看看结果的变化。
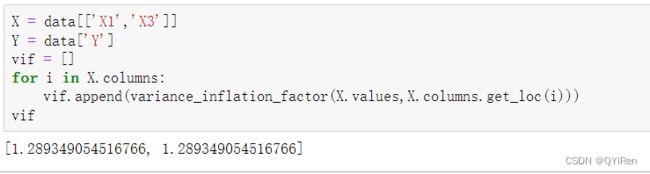
可以看到,此时两个特征变量的方差膨胀系数都小于10,说明它们之间不存在多重共线性。
总结来说,对于线性回归模型和逻辑回归模型等以线性方程表达式为基础的机器学习模型,需要注意多重共线性的影响。如果存在多重共线性,则需要进行相应处理,如删去某个引起多重共线性的特征变量。
8 过采样和欠采样
建立模型时,可能会遇到正负样本比例极度不均衡的情况。例如,建立信用违约模型时,违约样本的比例远小于不违约样本的比例,此时模型会花更多精力去拟合不违约样本,但实际上找出违约样本更为重要。这会导致模型可能在训练集上表现良好,但测试时表现不佳。为了改善样本比例不均衡的问题,可以使用过采样和欠采样的方法。假设建立信用违约模型时,样本数据中有1000个不违约样本和100个违约样本,下面分别介绍过采样和欠采样的方法。
8.1 过采样
8.1.1 过采样的原理
(1)随机过采样
随机过采样是从100个违约样本中随机抽取旧样本作为一个新样本,共反复抽取900次,然后和原来的100个旧样本组合成新的1000个违约样本,和1000个不违约样本一起构成新的训练集。因为随机过采样重复地选取了违约样本,所以有可能造成对违约样本的过拟合。
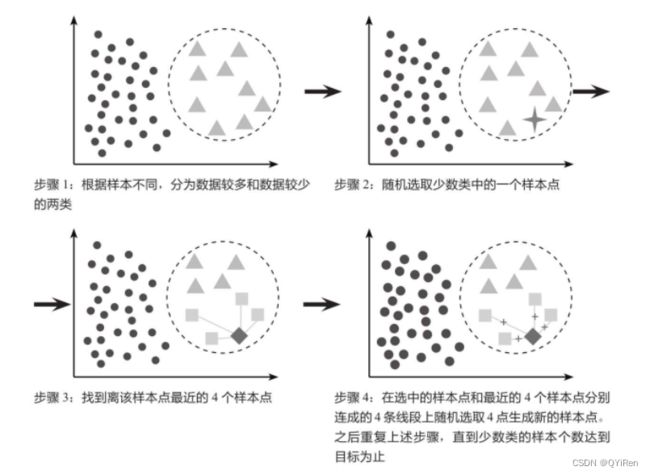
(2)SMOTE过采样
SMOTE法过采样即合成少数类过采样技术,它是一种针对随机过采样容易导致过拟合问题的改进方案。假设对少数类进行4倍过采样,通过下图来讲解SMOTE法的原理。
8.1.2 过采样的代码实现
首先用pandas库读取信用违约数据,代码如下。
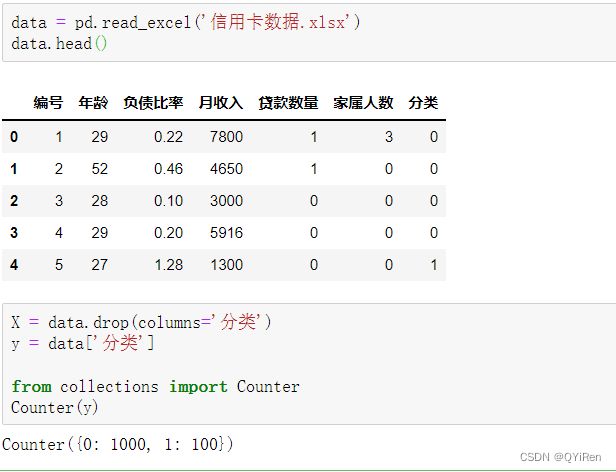
可以看到,不违约样本数为1000,远远大于违约样本数100。
为了防止建立信用违约模型时,模型着重拟合不违约样本,而无法找出违约样本,采用过采样的方法来改善样本比例不均衡的问题。这里分别对随机过采样和SMOTE法过采样进行代码实现。
1.随机过采样
from imblearn.over_sampling import RandomOverSampler
ros = RandomOverSampler(random_state=0)
X_oversampled,y_oversampled = ros.fit_resample(X,y)
Counter(y_oversampled)2.SMOTE过采样
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=0)
X_oversampled,y_oversampled = smote.fit_resample(X,y)
Counter(y_oversampled)8.2 欠采样
8.2.1 欠采样的原理
欠采样是从1000个不违约样本中随机选取100个样本,和100个违约样本一起构成新的训练集。欠采样抛弃了大部分不违约样本,在搭建模型时有可能产生欠拟合。
8.2.2 欠采样的代码实现
from imblearn.under_sampling import RandomUnderSampler
rus = RandomUnderSampler(random_state=0)
X_undersampled,y_undersampled = rus.fit_resample(X,y)
Counter(y_undersampled)在实战中处理样本不均衡问题时,如果样本数据量不大,通常使用过采样,因为这样能更好地利用数据,不会像欠采样那样很多数据都没有使用到;如果数据量充足,则过采样和欠采样都可以考虑使用。
参考书籍
《Python大数据分析与机器学习商业案例实战》