「PyTorch深度学习入门」4. 使用张量表示真实世界的数据(下)
来源 | Deep Learning with PyTorch
作者 | Stevens, et al.
译者 | 杜小瑞
校对 | gongyouliu
编辑 | auroral-L
全文共5736字,预计阅读时间35分钟。
第四章 使用张量表示真实世界的数据(下)
1. 使用图像
1.1 添加颜色通道
1.2 加载一个图片文件
1.3 改变布局
1.4 数据标准化
2. 三维图像:体积数据
2.1 加载专用格式
3. 表示表格数据
3.1 使用真实数据集
3.2 加载葡萄酒数据张量
3.3 表示分数
3.4 one-hot 编码
3.5 何时进行分类
3.6 找到阈值
4. 使用时间序列
4.1 添加一个时间维度
4.2 按时间段构造数据
4.3 准备训练
5. 表示文本
5.1 将文本转化为数字
5.2 one-hot 编码字符
5.3 one-hot 编码整个单词
5.4 文本嵌入
5.5 作为蓝图的文本嵌入
6. 结论
7. 练习
8. 总结
5. 表示文本
深度学习(Deep learning)在自然语言处理(natural language processing,NLP)领域掀起了一股风暴,尤其是反复使用新输入和先前模型输出组合的模型,这些模型被称为递归神经网络(RNNs),并在文本分类、文本生成和自动翻译系统中得到了成功的应用。最近,一类名为“transformer”的网络以更灵活的方式整合了过去的信息,引起了轰动。以前的NLP工作负载的特点是复杂的多级管道,其中包括编码语言语法的规则。现在,最先进的技术将网络端到端地训练大型语料库,从头开始,让这些规则从数据中浮现出来。在过去的几年里,互联网上最常用的自动翻译系统都是以深度学习为基础的。
本节的目标是将文本转化为神经网络可以处理的东西:数字张量,就像我们前面的例子一样。如果我们能做到这一点,然后为我们的文本处理工作选择合适的体系结构,我们就可以使用PyTorch进行NLP了。
我们马上就能看到这一切是多么强大:我们可以用相同的PyTorch工具在不同领域的许多任务上实现最先进的性能;我们只需要用正确的方式来解决问题。这项工作的第一部分是重塑数据。
5.1 将文本转化为数字
网络对文本的操作有两个特别直观的层次:在字符层次,一次处理一个字符;在单词层次,单个单词是网络可以看到的最细粒度实体。将文本信息编码成张量形式的技术,无论是在字符级还是在单词级,都是相同的。这不是什么魔法,而是在很早之前就发现的one-hot编码实现的。
让我们从一个字符级的示例开始。首先,让我们来处理一些文本。古腾堡计划是一个惊人的资源(www.gutenberg.org),这是一项将文化与艺术作品数字化和存档的志愿工作,并使其以开放格式(包括纯文本文件)免费提供。如果我们的目标是更大规模的语料库,维基百科语料库非常合适:它是维基百科文章的完整集合,包含19亿个单词和超过440万篇文章。其他几个语料库可以在英语语料库网站上找到(www.english-corpora.org)。
让我们从古腾堡计划网站中载入简·奥斯汀的《傲慢与偏见》:www.gutenberg.org/files/1342/1342-0.txt. 我们只需保存文件并将其读入(code/p1ch4/5_text_jane_austen.ipynb)。

5.2 one-hot编码字符
在我们继续之前,还有一个细节需要注意:编码。这是一个相当广泛的主题,我们将简要的谈论一下这方面内容。每一个书写的字符都由一个代码来表示:一个适当长度的位序列,这样每个字符都可以被唯一地识别。最简单的这种编码是ASCII(美国信息交换标准码),它可以追溯到20世纪60年代。ASCII使用128个整数对128个字符进行编码。例如,字母a对应于二进制1100001或十进制97,字母b对应于二进制1100010或十进制98,依此类推。这种编码适合8位,这在1965年时是一个很大的优势。
注意
128个字符显然不足以解释所有的字形、重音符号、连字等等,这些符号是用英语以外的语言正确表示书面文本所必需的。为此,已经开发了许多编码,这些编码使用更大数量的位数(bits)作为更大范围字符的代码。更大范围的字符被标准化为Unicode,它将所有已知字符映射到数字,这些数字的位表示由特定编码提供。常用的编码是UTF-8、UTF-16和UTF-32,其中数字分别是8位、16位或32位整数的序列。python3.x中的字符串是Unicode字符串。
我们将对我们的字符进行one-hot编码。将one-hot限制为对要分析的文本有用的字符集很有用。在我们的例子中,因为我们加载的是英文文本,所以使用ASCII和处理少量编码是安全的。我们还可以将所有字符都设置为小写,以减少编码中不同字符的数量。同样,我们可以筛选出标点符号、数字或其他与预期文本类型无关的字符。这可能对神经网络产生实际影响,也可能不会,这取决于手头的任务。
此时,我们需要解析文本中的字符,并为每个字符提供one-hot编码。每个字符将由长度等于编码中不同字符数的向量表示。此向量中除了编码中字符位置对应的索引处为1,其他元素都是0。
我们首先将文本拆分为一系列行,然后选择一行作为重点:

让我们创建一个张量,它可以容纳整行的one-hot编码字符的总数:

请注意,letter_t每行包含one-hot编码字符。现在我们只需要在每一行的正确位置设置为1,这样每一行就代表了正确的字符。必须设置的索引对应于编码中字符的索引:

5.3 one-hot编码整个单词
我们使用one-hot将一个句子编码成神经网络可以理解的内容。单词级编码可以通过同样的方法来完成,即建立一个词汇表和one-hot编码句子,沿着我们的张量行对单词序列进行编码。因为一个词汇表有很多单词,这将产生非常大的编码向量,这可能是不实际的。我们将在下一节中看到,有一种更有效的方法来表示单词级别的文本,即使用嵌入。现在,让我们继续使用one-hot编码,看看会发生什么。
我们将定义clean_words函数,它接受文本并以小写形式返回,去掉标点符号。当我们对“Impossible, Mr. Bennet ”行调用函数时,我们得到了以下信息:

接下来,让我们在编码中构建单词到索引的映射:

请注意,word2index_dict现在是一个字典,单词作为键,整数作为值。当我们对一个单词进行one-hot编码时,我们将使用它来有效地找到它的索引。现在让我们关注我们的句子:我们将它分解成单词,然后对它进行one-hot编码,也就是说,我们用每个单词的one-hot编码向量填充一个张量。我们创建一个空向量,并为句子中的单词指定one-hot编码值:

此时,张量表示一个长度为11的句子,其编码空间为7261,即我们词典中的字数。图4.6比较了拆分文本的两个选项的要点(使用嵌入我们将在下一节中介绍)。
字符级编码和单词级编码之间的选择留给我们进行权衡。在许多语言中,字符明显少于单词:表示字符使我们只能表示几个类,而表示单词则要求我们表示大量的类,并且在任何实际应用中,需要处理字典中没有的单词。另一方面,单词比单个字符传达更多的意义,因此单词本身的表达信息量要大得多。鉴于这两种选择之间的鲜明对比,中间方法的寻求、发现和应用都取得了巨大成功,这也许并不奇怪:例如,字节对编码方法(byte pair encoding)从单个字母的字典开始,然后迭代地将最常观察到的对添加到字典中,直到达到指定的字典大小。我们的示例语句可能会被分成如下标记:
![]()
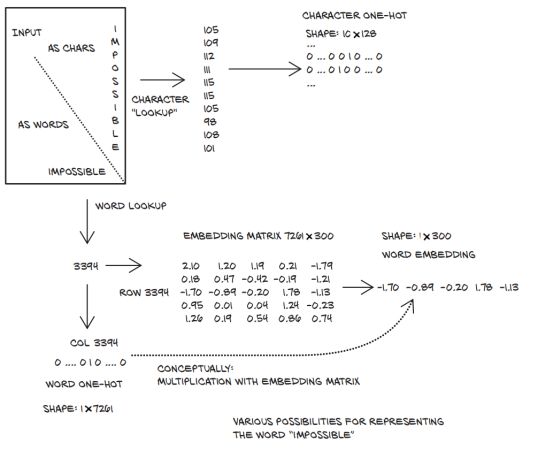
图 4.6 三种编码单词的方法
对于大多数情况,我们的映射只是将单词分割。但是,比较少见的是(大写的Impossible和名字Bennet)由子单元组成。
5.4 文本嵌入
One-hot编码是用张量表示分类数据的非常有用的技术。然而,正如我们所预期的,当要编码的项目数量过大时,one-hot编码开始崩溃,就像语料库中的单词一样。在一本书中,我们有超过7000个单词!
我们当然可以做一些工作来消除单词的重复,压缩可替代的拼写(即一个单词可能有多种写法),把过去和将来的时态压缩成一个标记,诸如此类的事情。不过,通用的英语编码将是巨大的。更糟糕的是,每当我们遇到一个新词时,我们就必须向向量中添加一个新的列,这意味着要向模型中添加一组新的权重,以解释新的词汇条目,从训练的角度来看,这将是痛苦的。
我们如何将编码压缩到一个更易于管理的大小,并限制大小的增长?好吧,我们可以用浮点数的向量来代替多个0和一个1的向量。例如,一个由100个浮点数组成的向量确实可以表示大量的单词。诀窍是找到一种有效的方法,将单个单词映射到这个100维空间中,以便于下游学习。这叫做嵌入。
原则上,我们可以简单地遍历词汇表,为每个单词生成一组100个随机浮点数。这是可行的,因为我们可以将一个非常大的词汇塞进100个数字中,但它会放弃任何基于意义或上下文的词与词之间距离的概念。使用这种词嵌入的模型必须处理其输入向量中非常小的结构。理想的解决方案是生成嵌入的方式,使相似上下文中使用的单词映射到嵌入的附近区域。
好吧,如果我们要手工设计一个解决这个问题的方法,我们可能会决定通过选择沿着轴映射基本的名词和形容词来构建嵌入空间。我们可以生成一个二维空间,其中轴映射到名词水果(0.0-0.33)、花(0.33-0.66)和狗(0.66-1.0)以及形容词红色(0.0-0.2)、橙色(0.2-0.4)、黄色(0.4-0.6)、白色(0.6-0.8)和棕色(0.8-1.0)。我们的目标是取得实际的水果,鲜花和狗,并将他们生成嵌入。
当我们开始嵌入单词时,我们可以将苹果映射到水果和红色象限中的一个数字。同样地,我们可以很容易地绘制出橘子、柠檬、荔枝和猕猴桃的映射(以完善我们的五颜六色水果列表)。然后我们可以从花开始,分配玫瑰,罂粟花,水仙花,百合花,还有…嗯,棕色的花好像不多。向日葵可以看成黄色和棕色的花,然后雏菊可以看成白色和黄色的花。也许我们应该更新猕猴桃映射,使其接近水果、棕色和绿色。至于狗和颜色,我们可以在红色附近嵌入redbone(一种狗);呃,狐狸也许是橘色的;金色的猎犬代表黄色,贵宾犬代表白色,还有……大多数狗都是棕色的。
现在我们的嵌入如图4.7所示。虽然对于一个大型语料库来说,手动执行这一操作并不是真正可行的,但是请注意,尽管我们的嵌入大小为2,但是除了基数8之外,我们还描述了15个不同的单词,如果我们花时间对其进行创造的话,可能会塞进更多的单词。
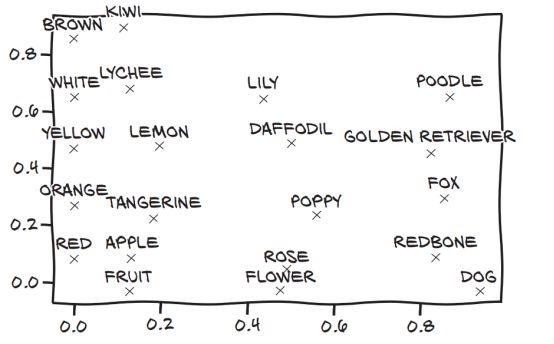
图 4.7 我们的手动单词嵌入
你可能已经猜到了,这种工作是可以自动化的。通过处理大量的文本,可以生成与我们刚才讨论的相似的嵌入。主要区别在于嵌入向量中有100到1000个元素,并且轴不直接映射到概念:相反,概念上相似的词映射到嵌入空间的相邻区域,其轴是任意浮点维数。
虽然所使用的精确算法有点超出了我们在这里要重点讨论的范围,但我们只想提到,嵌入通常是使用神经网络生成的,试图从句子中邻近的单词(上下文)预测单词。在这种情况下,我们可以从one-hot编码字符开始,使用一个(通常相当浅的)神经网络来生成嵌入。一旦嵌入可用,我们就可以将其用于下游任务。
结果嵌入的一个有趣的方面是,相似的单词不仅聚集在一起,而且与其他单词具有一致的空间关系。举个例子,如果我们把苹果的嵌入向量加上或者减去其他的向量,我们就可以开始进行类似的运算,比如苹果-红-甜+黄+酸,最后得到一个非常类似于柠檬的向量。
BERT和GPT-2是更加现代化的复杂嵌入模型,并且是上下文敏感的:也就是说,词汇表中的单词到向量的映射不是固定的,而是取决于周围的句子。然而,就像我们在这里提到的更简单的经典嵌入方法一样,它们现在也经常被使用。
5.5 作为蓝图的文本嵌入
当词汇表中的大量条目必须用数字向量表示时,嵌入是一个必不可少的工具。但是我们不会在这本书中使用文本和文本嵌入,所以你可能想知道为什么我们在这里介绍它们。我们认为,文本的表示和处理方式也可以看作是处理一般类别数据的一个例子。当one-hot编码变得麻烦时,嵌入是有用的。实际上,在前面描述的形式中,它们是表示one-hot编码紧接着与包含作为行的嵌入向量的矩阵相乘的有效方法。
在非文本应用程序中,我们通常不具备事先构造嵌入的能力,但我们将从先前回避的随机数开始,并考虑在学习问题中改进它们。这是一种标准技术,因此对于任何分类数据,嵌入都是one-hot编码的一个突出替代方案。另一方面,即使我们在处理文本时,在解决手头的问题的同时改进嵌入已经成为一种常见的做法。
当我们对观察值的共同出现感兴趣时,我们前面看到的单词嵌入也可以作为一个蓝图。例如,推荐系统(如喜欢我们的书的客户也购买了...)使用客户已经互动过的项目作为上下文来预测还有什么会引起兴趣。同样地,处理文本可能是处理序列的最常见、最深入的任务;因此,例如,在处理时间序列任务时,我们可能会从自然语言处理中寻找灵感。
6. 结论
在这一章中我们讲了很多内容。我们学会了加载最常见的数据类型,并通过神经网络对它们进行处理。当然,一些不规范的数据格式比我们在这章中描述的要多。诸如病史这样的数据太过复杂,这里无法完全涵盖。其他的,如音频和视频,我们认为对这本书的学习路径来说不那么重要。但是,如果你感兴趣,我们在本书的网站(www.manning.com/books/deep-learning-with-pytorch)和我们的代码存储库(https://github.com/deep-learning-with-pytorch/dlwpt-code/tree/master/p1ch4)中提供音频,视频张量创建的简短示例的Jupyter Notebook代码。
既然我们已经熟悉了张量以及如何在张量中存储数据,我们就可以进入本书目标的下一步:教你训练深层神经网络!下一章将介绍简单线性模型的学习机制。
7. 练习
1、用手机或其他数码相机拍摄几张红色、蓝色和绿色物品的照片(如果没有相机,也可以从网上下载一些照片)。
A. 加载每个图像,并将其转换为张量。
B. 对于每个图像张量,使用.mean()方法来获得图像亮度。
C. 取图像每个通道的平均值。你能从通道平均值中识别红、绿、蓝图像吗?
2、选择一个包含Python源代码的相对较大的文件。
A. 为源文件中的所有单词建立一个索引(你可以随意地使你的标记变得简单或复杂;我们建议先用空格替换r“[^a-zA-Z0-9_]+”)。
B. 把你的索引和我们为《傲慢与偏见》制作的索引比较一下。哪个更大?
C. 为源代码文件创建one-hot编码。
D. 这种编码会丢失哪些信息?这些信息与《傲慢与偏见》中丢失的信息相比如何?
8. 总结
√ 神经网络需要将数据表示为多维数值张量,通常是32位浮点。
√ 一般来说,PyTorch期望数据按照模型架构(例如,卷积和循环)沿着特定维度进行布局。我们可以用PyTorch张量API有效地重塑数据。
√ 由于PyTorch库与Python标准库和周围的生态系统交互非常容易,加载最常见的数据类型并将其转换为PyTorch张量非常方便。
√ 图像可以有一个或多个通道。最常见的是典型数码照片的红-绿-蓝通道。
√ 许多图像的每通道位深度为8,但每通道12位和16位并不少见。这些位深度都可以存储在一个32位浮点数中,而不会丢失精度。
√ 单通道数据格式有时会忽略显式通道维度。
√ 立体数据与二维图像数据类似,只是添加了第三维(深度)。
√ 将电子表格转换为张量非常简单。分类值列和序数值列的处理方式应不同于区间值列。
√ 通过使用字典,可以将文本或分类数据编码为one-hot表示。通常,嵌入提供了良好、有效的表示。
