手撕Alexnet卷积神经网络-pytorch-详细注释版(可以直接替换自己数据集)-直接放置自己的数据集就能直接跑。跑的代码有问题的可以在评论区指出,看到了会回复。训练代码和预测代码均有。
Alexnet网络详解代码:手撕Alexnet卷积神经网络-pytorch-详细注释版(可以直接替换自己数据集)-直接放置自己的数据集就能直接跑。跑的代码有问题的可以在评论区指出,看到了会回复。训练代码和预测代码均有。_小馨馨的小翟的博客-CSDN博客_alexnet神经网络代码
VGG网络详解代码: 手撕VGG卷积神经网络-pytorch-详细注释版(可以直接替换自己数据集)-直接放置自己的数据集就能直接跑。跑的代码有问题的可以在评论区指出,看到了会回复。训练代码和预测代码均有。_小馨馨的小翟的博客-CSDN博客
Resnet网络详解代码: 手撕Resnet卷积神经网络-pytorch-详细注释版(可以直接替换自己数据集)-直接放置自己的数据集就能直接跑。跑的代码有问题的可以在评论区指出,看到了会回复。训练代码和预测代码均有。_小馨馨的小翟的博客-CSDN博客
Googlenet网络详解代码:手撕Googlenet卷积神经网络-pytorch-详细注释版(可以直接替换自己数据集)-直接放置自己的数据集就能直接跑。跑的代码有问题的可以在评论区指出,看到了会回复。训练代码和预测代码均有。_小馨馨的小翟的博客-CSDN博客_cnn测试集准确率低
集成学习模型融合网络详解代码:
集成学习-模型融合(Lenet,Alexnet,Vgg)三个模型进行融合-附源代码-宇宙的尽头一定是融合模型而不是单个模型。_小馨馨的小翟的博客-CSDN博客_torch模型融合
深度学习常用数据增强,数据扩充代码数据缩放代码:
深度学习数据增强方法-内含(亮度增强,对比度增强,旋转图图像,翻转图像,仿射变化扩充图像,错切变化扩充图像,HSV数据增强)七种方式进行增强-每种扩充一张实现7倍扩)+ 图像缩放代码-批量_小馨馨的小翟的博客-CSDN博客_训练数据增强
Alexnet卷积神经网络是由谷歌Hinton率领的团队在2010年的Imagnet图像识别大赛获得冠军的一个卷积神经网络,该网络放到现在可能相对比较简单,但是也不失为用于入门深度学习的卷积神经网络。
对于网上很多的Alexnet的代码写的不够详细,比如没有详细的写出同时画出训练集的loss accuracy 和测试集的loss和accuracy的折线图,因此这些详细的使用pytorch框架复现了一下Alexnet代码,并且对于我们需要的loss和accuracy的折线图用matplotlib进行了绘制。
Alexnet卷积神经网络的结构图如下:
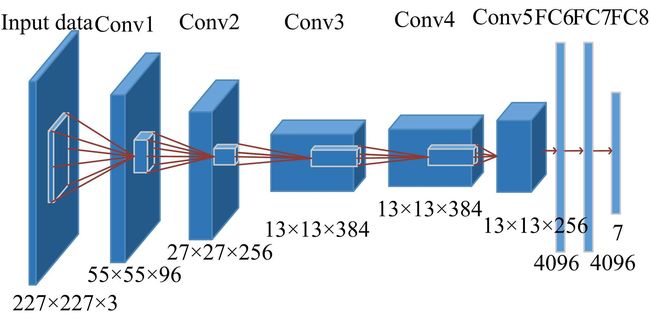
导入库
import torch
import torchvision
import torchvision.models
from matplotlib import pyplot as plt
from tqdm import tqdm
from torch import nn
from torch.utils.data import DataLoader
from torchvision.transforms import transforms
from PIL import ImageFile
图像预处理-缩放裁剪等等
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(120),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((120, 120)), #这种预处理的地方尽量别修改,修改意味着需要修改网络结构的参数,如果新手的话请勿修改
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}导入自己的数据,自己的数据放在跟代码相同的文件夹下新建一个data文件夹,data文件夹里的新建一个train文件夹用于放置训练集的图片。同理新建一个val文件夹用于放置测试集的图片。
train_data = torchvision.datasets.ImageFolder(root = "./data/train" , transform = data_transform["train"])
traindata = DataLoader(dataset= train_data , batch_size= 32 , shuffle= True , num_workers=0 )
# test_data = torchvision.datasets.CIFAR10(root = "./data" , train = False ,download = False,
# transform = trans)
test_data = torchvision.datasets.ImageFolder(root = "./data/val" , transform = data_transform["val"])
train_size = len(train_data)#求出训练集的长度
test_size = len(test_data) #求出测试集的长度
print(train_size) #输出训练集的长度
print(test_size) #输出测试集的长度
testdata = DataLoader(dataset = test_data , batch_size= 32 , shuffle= True , num_workers=0 )#windows系统下,num_workers设置为0,linux系统下可以设置多进程设置调用GPU,如果有GPU就调用GPU,如果没有GPU则调用CPU训练模型
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))Alexnet卷积神经网络
class alexnet(nn.Module):
def __init__(self):
super(alexnet , self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 120, 120] output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
nn.Flatten(),
nn.Dropout(p=0.5),
nn.Linear(512, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, 7), #自己的数据集是几种,这个7就设置为几
)
def forward(self , x):
x = self.model(x)
return x
启动模型,将模型放入GPU
alexnet1 = alexnet()
print(alexnet1)
alexnet1.to(device) #将模型放入GPU
test1 = torch.ones(64, 3, 120, 120) #输入数据测试一下模型能不能跑
test1 = alexnet1(test1.to(device))
print(test1.shape)设置训练需要的参数,epoch,学习率learning 优化器。损失函数。
epoch = 10#这里是训练的轮数
learning = 0.0001 #学习率
optimizer = torch.optim.Adam(alexnet1.parameters(), lr = learning)#优化器
loss = nn.CrossEntropyLoss()#损失函数设置四个空数组,用来存放训练集的loss和accuracy 测试集的loss和 accuracy
train_loss_all = []
train_accur_all = []
test_loss_all = []
test_accur_all = []开始训练:
for i in range(epoch):
train_loss = 0
train_num = 0.0
train_accuracy = 0.0
alexnet1.train()
train_bar = tqdm(traindata)
for step , data in enumerate(train_bar):
img , target = data
optimizer.zero_grad()
outputs = alexnet1(img.to(device))
loss1 = loss(outputs , target.to(device))
outputs = torch.argmax(outputs, 1)
loss1.backward()
optimizer.step()
train_loss += abs(loss1.item())*img.size(0)
accuracy = torch.sum(outputs == target.to(device))
train_accuracy = train_accuracy + accuracy
train_num += img.size(0)
print("epoch:{} , train-Loss:{} , train-accuracy:{}".format(i+1 , train_loss/train_num , train_accuracy/train_num))
train_loss_all.append(train_loss/train_num)
train_accur_all.append(train_accuracy.double().item()/train_num)开始测试:
test_loss = 0
test_accuracy = 0.0
test_num = 0
alexnet1.eval()
with torch.no_grad():
test_bar = tqdm(testdata)
for data in test_bar:
img , target = data
outputs = alexnet1(img.to(device))
loss2 = loss(outputs, target.to(device))
outputs = torch.argmax(outputs, 1)
test_loss = test_loss + abs(loss2.item())*img.size(0)
accuracy = torch.sum(outputs == target.to(device))
test_accuracy = test_accuracy + accuracy
test_num += img.size(0)
print("test-Loss:{} , test-accuracy:{}".format(test_loss / test_num, test_accuracy / test_num))
test_loss_all.append(test_loss/test_num)
test_accur_all.append(test_accuracy.double().item()/test_num)
开始测试:
test_loss = 0
test_accuracy = 0.0
test_num = 0
alexnet1.eval()
with torch.no_grad():
test_bar = tqdm(testdata)
for data in test_bar:
img , target = data
outputs = alexnet1(img.to(device))
loss2 = loss(outputs, target.to(device))
outputs = torch.argmax(outputs, 1)
test_loss = test_loss + abs(loss2.item())*img.size(0)
accuracy = torch.sum(outputs == target.to(device))
test_accuracy = test_accuracy + accuracy
test_num += img.size(0)
print("test-Loss:{} , test-accuracy:{}".format(test_loss / test_num, test_accuracy / test_num))
test_loss_all.append(test_loss/test_num)
test_accur_all.append(test_accuracy.double().item()/test_num)绘制训练集loss和accuracy图 和测试集的loss和accuracy图
plt.figure(figsize=(12,4))
plt.subplot(1 , 2 , 1)
plt.plot(range(epoch) , train_loss_all,
"ro-",label = "Train loss")
plt.plot(range(epoch), test_loss_all,
"bs-",label = "test loss")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("Loss")
plt.subplot(1, 2, 2)
plt.plot(range(epoch) , train_accur_all,
"ro-",label = "Train accur")
plt.plot(range(epoch) , test_accur_all,
"bs-",label = "test accur")
plt.xlabel("epoch")
plt.ylabel("acc")
plt.legend()
plt.show()
torch.save(alexnet1.state_dict(), "alexnet.pth")
print("模型已保存")
全部train训练代码:
import torch
import torchvision
import torchvision.models
from matplotlib import pyplot as plt
from tqdm import tqdm
from torch import nn
from torch.utils.data import DataLoader
from torchvision.transforms import transforms
from PIL import ImageFile
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(120),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((120, 120)), # cannot 224, must (224, 224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
# train_data = torchvision.datasets.CIFAR10(root = "./data" , train = True ,download = True,
# transform = trans)
def main():
train_data = torchvision.datasets.ImageFolder(root = "./data/train" , transform = data_transform["train"])
traindata = DataLoader(dataset= train_data , batch_size= 128 , shuffle= True , num_workers=0 )
# test_data = torchvision.datasets.CIFAR10(root = "./data" , train = False ,download = False,
# transform = trans)
test_data = torchvision.datasets.ImageFolder(root = "./data/val" , transform = data_transform["val"])
train_size = len(train_data)
test_size = len(test_data)
print(train_size)
print(test_size)
testdata = DataLoader(dataset = test_data , batch_size= 128 , shuffle= True , num_workers=0 )
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
class alexnet(nn.Module):
def __init__(self):
super(alexnet , self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 120, 120] output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
nn.Flatten(),
nn.Dropout(p=0.5),
nn.Linear(512, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, 7), #自己的数据是几种,这里的7就改成几
)
def forward(self , x):
x = self.model(x)
return x
alexnet1 = alexnet()
print(alexnet1)
alexnet1.to(device)
test1 = torch.ones(64, 3, 120, 120)
test1 = alexnet1(test1.to(device))
print(test1.shape)
epoch = 10
learning = 0.0001
optimizer = torch.optim.Adam(alexnet1.parameters(), lr = learning)
loss = nn.CrossEntropyLoss()
train_loss_all = []
train_accur_all = []
test_loss_all = []
test_accur_all = []
for i in range(epoch):
train_loss = 0
train_num = 0.0
train_accuracy = 0.0
alexnet1.train()
train_bar = tqdm(traindata)
for step , data in enumerate(train_bar):
img , target = data
optimizer.zero_grad()
outputs = alexnet1(img.to(device))
loss1 = loss(outputs , target.to(device))
outputs = torch.argmax(outputs, 1)
loss1.backward()
optimizer.step()
train_loss += abs(loss1.item())*img.size(0)
accuracy = torch.sum(outputs == target.to(device))
train_accuracy = train_accuracy + accuracy
train_num += img.size(0)
print("epoch:{} , train-Loss:{} , train-accuracy:{}".format(i+1 , train_loss/train_num , train_accuracy/train_num))
train_loss_all.append(train_loss/train_num)
train_accur_all.append(train_accuracy.double().item()/train_num)
test_loss = 0
test_accuracy = 0.0
test_num = 0
alexnet1.eval()
with torch.no_grad():
test_bar = tqdm(testdata)
for data in test_bar:
img , target = data
outputs = alexnet1(img.to(device))
loss2 = loss(outputs, target.to(device))
outputs = torch.argmax(outputs, 1)
test_loss = test_loss + abs(loss2.item())*img.size(0)
accuracy = torch.sum(outputs == target.to(device))
test_accuracy = test_accuracy + accuracy
test_num += img.size(0)
print("test-Loss:{} , test-accuracy:{}".format(test_loss / test_num, test_accuracy / test_num))
test_loss_all.append(test_loss/test_num)
test_accur_all.append(test_accuracy.double().item()/test_num)
plt.figure(figsize=(12,4))
plt.subplot(1 , 2 , 1)
plt.plot(range(epoch) , train_loss_all,
"ro-",label = "Train loss")
plt.plot(range(epoch), test_loss_all,
"bs-",label = "test loss")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("Loss")
plt.subplot(1, 2, 2)
plt.plot(range(epoch) , train_accur_all,
"ro-",label = "Train accur")
plt.plot(range(epoch) , test_accur_all,
"bs-",label = "test accur")
plt.xlabel("epoch")
plt.ylabel("acc")
plt.legend()
plt.show()
torch.save(alexnet1.state_dict(), "alexnet.pth")
print("模型已保存")
if __name__ == '__main__':
main()
全部predict代码:
import torch
from PIL import Image
from torch import nn
from torchvision.transforms import transforms
image_path = "1.JPG"#将要预测的图片放到跟predict同一个文件夹下
trans = transforms.Compose([transforms.Resize((120 , 120)),
transforms.ToTensor()])
image = Image.open(image_path)
image = image.convert("RGB")
image = trans(image)
image = torch.unsqueeze(image, dim=0)
classes = ["1" , "2" , "3" , "4" , "5" , "6" , "7"]#自己是几种,这里就改成自己种类的字符数组
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
class alexnet(nn.Module):
def __init__(self):
super(alexnet, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 120, 120] output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
nn.Flatten(),
nn.Dropout(p=0.5),
nn.Linear(512, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, 7),#这里就用train把你网络结构代码复制过来即可
)
def forward(self, x):
x = self.model(x)
return x
alexnet1 = alexnet()
alexnet1.load_state_dict(torch.load("alexnet.pth", map_location=device))#train代码保存的模型要放在跟predict同一个文件夹下
outputs = alexnet1(image)
ans = (outputs.argmax(1)).item()
print(classes[ans]) #输出的是那种即为预测结果Alexnet代码下载链接:链接:https://pan.baidu.com/s/1fc3dSBZN7WsxEjwMxelAwA
提取码:3dzb
有用的话麻烦点一下关注,博主后续会开源更多代码,非常感谢支持!